









上一期指路:
上一期我们分析完了用户代码,其核心是把相关算子加入transformations中,这个对于生成流图很重要。我们在编写用户代码时,最后一步肯定会写env.execute这一步,如果不写的话,那么程序其实并没有真正意义上的运行。于是我们接着从execute函数开始进行源码分析
1.StreamExecutionEnvironment#execute
public JobExecutionResult execute(String jobName) throws Exception {
Preconditions.checkNotNull(jobName, "Streaming Job name should not be null.");
return execute(getStreamGraph(jobName));
}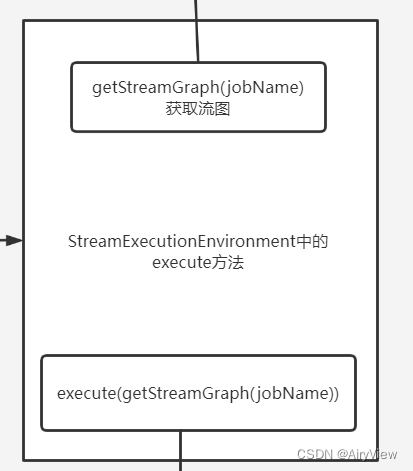
由于我们这一期只分析生成流图,所以这一期主要分析getStreamGraph函数,下一期就分析获取到流图后继续执行execute的过程。
2.StreamExecutionEnvironment#getStreamGraph->StreamExecutionEnvironment#getStreamGraph
public StreamGraph getStreamGraph(String jobName, boolean clearTransformations) {
StreamGraph streamGraph = getStreamGraphGenerator().setJobName(jobName).generate();
if (clearTransformations) {
this.transformations.clear();
}
return streamGraph;
}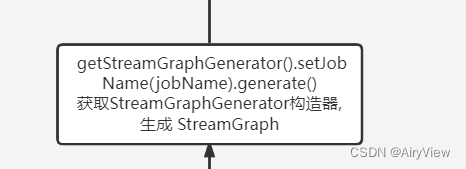
3.StreamGraphGenerator#generate
public StreamGraph generate() {
streamGraph = new StreamGraph(executionConfig, checkpointConfig, savepointRestoreSettings);
shouldExecuteInBatchMode = shouldExecuteInBatchMode(runtimeExecutionMode);
configureStreamGraph(streamGraph);
alreadyTransformed = new HashMap<>();
for (Transformation<?> transformation: transformations) {
transform(transformation);
}
final StreamGraph builtStreamGraph = streamGraph;
alreadyTransformed.clear();
alreadyTransformed = null;
streamGraph = null;
return builtStreamGraph;
}重点关注transform(transformation),点击进入
private Collection<Integer> transform(Transformation<?> transform) {
if (alreadyTransformed.containsKey(transform)) {
return alreadyTransformed.get(transform);
}
LOG.debug("Transforming " + transform);
if (transform.getMaxParallelism() <= 0) {
// if the max parallelism hasn't been set, then first use the job wide max parallelism
// from the ExecutionConfig.
int globalMaxParallelismFromConfig = executionConfig.getMaxParallelism();
if (globalMaxParallelismFromConfig > 0) {
transform.setMaxParallelism(globalMaxParallelismFromConfig);
}
}
// call at least once to trigger exceptions about MissingTypeInfo
transform.getOutputType();
@SuppressWarnings("unchecked")
final TransformationTranslator<?, Transformation<?>> translator =
(TransformationTranslator<?, Transformation<?>>) translatorMap.get(transform.getClass());
Collection<Integer> transformedIds;
if (translator != null) {
transformedIds = translate(translator, transform);
} else {
transformedIds = legacyTransform(transform);
}
// need this check because the iterate transformation adds itself before
// transforming the feedback edges
if (!alreadyTransformed.containsKey(transform)) {
alreadyTransformed.put(transform, transformedIds);
}
return transformedIds;
}遍历所有transformations并转换,转换成 StreamGraph 中的 StreamNode 和 StreamEdge;返回值为该 transform 的 id 集合。
关注translate(translator, transform),点击并进入
private Collection<Integer> translate(
final TransformationTranslator<?, Transformation<?>> translator,
final Transformation<?> transform) {
checkNotNull(translator);
checkNotNull(transform);
final List<Collection<Integer>> allInputIds = getParentInputIds(transform.getInputs());
// the recursive call might have already transformed this
if (alreadyTransformed.containsKey(transform)) {
return alreadyTransformed.get(transform);
}
final String slotSharingGroup = determineSlotSharingGroup(
transform.getSlotSharingGroup(),
allInputIds.stream()
.flatMap(Collection::stream)
.collect(Collectors.toList()));
final TransformationTranslator.Context context = new ContextImpl(
this, streamGraph, slotSharingGroup, configuration);
return shouldExecuteInBatchMode
? translator.translateForBatch(transform, context)
: translator.translateForStreaming(transform, context);
}
我们直接看最后几行,我们是流模式,所以执行translator.translateForStreaming(transform, context),点击进入
public Collection<Integer> translateForStreaming(final T transformation, final Context context) {
checkNotNull(transformation);
checkNotNull(context);
final Collection<Integer> transformedIds =
translateForStreamingInternal(transformation, context);
configure(transformation, context);
return transformedIds;
}
点击translateForStreamingInternal,要分情况,加入是keyBy的话,会执行PartitionTransformationTranslator中的translateForStreamingInternal,如果是flatMap,会执行OneInputTransformationTranslator中的translateForStreamingInternal。
4.PartitionTransformationTranslator#translateForStreamingInternal
protected Collection<Integer> translateForStreamingInternal(
final PartitionTransformation<OUT> transformation,
final Context context) {
return translateInternal(transformation, context);
}点击translateInternal进入
private Collection<Integer> translateInternal(
final PartitionTransformation<OUT> transformation,
final Context context) {
checkNotNull(transformation);
checkNotNull(context);
final StreamGraph streamGraph = context.getStreamGraph();
final List<Transformation<?>> parentTransformations = transformation.getInputs();
checkState(
parentTransformations.size() == 1,
"Expected exactly one input transformation but found " + parentTransformations.size());
final Transformation<?> input = parentTransformations.get(0);
List<Integer> resultIds = new ArrayList<>();
for (Integer inputId: context.getStreamNodeIds(input)) {
final int virtualId = Transformation.getNewNodeId();
streamGraph.addVirtualPartitionNode(
inputId,
virtualId,
transformation.getPartitioner(),
transformation.getShuffleMode());
resultIds.add(virtualId);
}
return resultIds;
}
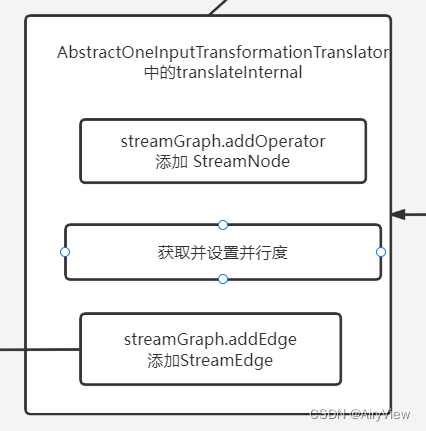
5.OneInputTransformationTranslator#translateForStreamingInternal
public Collection<Integer> translateForStreamingInternal(
final OneInputTransformation<IN, OUT> transformation,
final Context context) {
return translateInternal(transformation,
transformation.getOperatorFactory(),
transformation.getInputType(),
transformation.getStateKeySelector(),
transformation.getStateKeyType(),
context
);
}点击translateInternal进入
protected Collection<Integer> translateInternal(
final Transformation<OUT> transformation,
final StreamOperatorFactory<OUT> operatorFactory,
final TypeInformation<IN> inputType,
@Nullable final KeySelector<IN, ?> stateKeySelector,
@Nullable final TypeInformation<?> stateKeyType,
final Context context) {
checkNotNull(transformation);
checkNotNull(operatorFactory);
checkNotNull(inputType);
checkNotNull(context);
final StreamGraph streamGraph = context.getStreamGraph();
final String slotSharingGroup = context.getSlotSharingGroup();
final int transformationId = transformation.getId();
final ExecutionConfig executionConfig = streamGraph.getExecutionConfig();
streamGraph.addOperator(
transformationId,
slotSharingGroup,
transformation.getCoLocationGroupKey(),
operatorFactory,
inputType,
transformation.getOutputType(),
transformation.getName());
if (stateKeySelector != null) {
TypeSerializer<?> keySerializer = stateKeyType.createSerializer(executionConfig);
streamGraph.setOneInputStateKey(transformationId, stateKeySelector, keySerializer);
}
int parallelism = transformation.getParallelism() != ExecutionConfig.PARALLELISM_DEFAULT
? transformation.getParallelism()
: executionConfig.getParallelism();
streamGraph.setParallelism(transformationId, parallelism);
streamGraph.setMaxParallelism(transformationId, transformation.getMaxParallelism());
final List<Transformation<?>> parentTransformations = transformation.getInputs();
checkState(
parentTransformations.size() == 1,
"Expected exactly one input transformation but found " + parentTransformations.size());
for (Integer inputId: context.getStreamNodeIds(parentTransformations.get(0))) {
streamGraph.addEdge(inputId, transformationId, 0);
}
return Collections.singleton(transformationId);
}
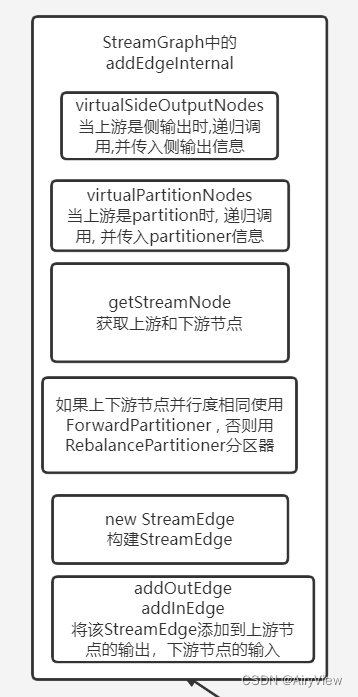
6.StreamGraph#addEdge->StreamGraph#addEdgeInternal
private void addEdgeInternal(Integer upStreamVertexID,
Integer downStreamVertexID,
int typeNumber,
StreamPartitioner<?> partitioner,
List<String> outputNames,
OutputTag outputTag,
ShuffleMode shuffleMode) {
if (virtualSideOutputNodes.containsKey(upStreamVertexID)) {
int virtualId = upStreamVertexID;
upStreamVertexID = virtualSideOutputNodes.get(virtualId).f0;
if (outputTag == null) {
outputTag = virtualSideOutputNodes.get(virtualId).f1;
}
addEdgeInternal(upStreamVertexID, downStreamVertexID, typeNumber, partitioner, null, outputTag, shuffleMode);
} else if (virtualPartitionNodes.containsKey(upStreamVertexID)) {
int virtualId = upStreamVertexID;
upStreamVertexID = virtualPartitionNodes.get(virtualId).f0;
if (partitioner == null) {
partitioner = virtualPartitionNodes.get(virtualId).f1;
}
shuffleMode = virtualPartitionNodes.get(virtualId).f2;
addEdgeInternal(upStreamVertexID, downStreamVertexID, typeNumber, partitioner, outputNames, outputTag, shuffleMode);
} else {
StreamNode upstreamNode = getStreamNode(upStreamVertexID);
StreamNode downstreamNode = getStreamNode(downStreamVertexID);
// If no partitioner was specified and the parallelism of upstream and downstream
// operator matches use forward partitioning, use rebalance otherwise.
if (partitioner == null && upstreamNode.getParallelism() == downstreamNode.getParallelism()) {
partitioner = new ForwardPartitioner<Object>();
} else if (partitioner == null) {
partitioner = new RebalancePartitioner<Object>();
}
if (partitioner instanceof ForwardPartitioner) {
if (upstreamNode.getParallelism() != downstreamNode.getParallelism()) {
throw new UnsupportedOperationException("Forward partitioning does not allow " +
"change of parallelism. Upstream operation: " + upstreamNode + " parallelism: " + upstreamNode.getParallelism() +
", downstream operation: " + downstreamNode + " parallelism: " + downstreamNode.getParallelism() +
" You must use another partitioning strategy, such as broadcast, rebalance, shuffle or global.");
}
}
if (shuffleMode == null) {
shuffleMode = ShuffleMode.UNDEFINED;
}
StreamEdge edge = new StreamEdge(upstreamNode, downstreamNode, typeNumber,
partitioner, outputTag, shuffleMode);
getStreamNode(edge.getSourceId()).addOutEdge(edge);
getStreamNode(edge.getTargetId()).addInEdge(edge);
}
}
7.最终StreamGraph效果
Nodes的数据如下:
{
"nodes": [
{
"id": 1,
"type": "Source: Socket Stream",
"pact": "Data Source",
"contents": "Source: Socket Stream",
"parallelism": 1
},
{
"id": 2,
"type": "Flat Map",
"pact": "Operator",
"contents": "Flat Map",
"parallelism": 4,
"predecessors": [
{
"id": 1,
"ship_strategy": "REBALANCE",
"side": "second"
}
]
},
{
"id": 4,
"type": "Window(TumblingProcessingTimeWindows(5000), ProcessingTimeTrigger, ReduceFunction$1, PassThroughWindowFunction)",
"pact": "Operator",
"contents": "Window(TumblingProcessingTimeWindows(5000), ProcessingTimeTrigger, ReduceFunction$1, PassThroughWindowFunction)",
"parallelism": 4,
"predecessors": [
{
"id": 2,
"ship_strategy": "HASH",
"side": "second"
}
]
},
{
"id": 5,
"type": "Sink: Print to Std. Out",
"pact": "Data Sink",
"contents": "Sink: Print to Std. Out",
"parallelism": 1,
"predecessors": [
{
"id": 4,
"ship_strategy": "REBALANCE",
"side": "second"
}
]
}
]
}画图如下

总览
本期涉及到的代码部分流程图总览如下:
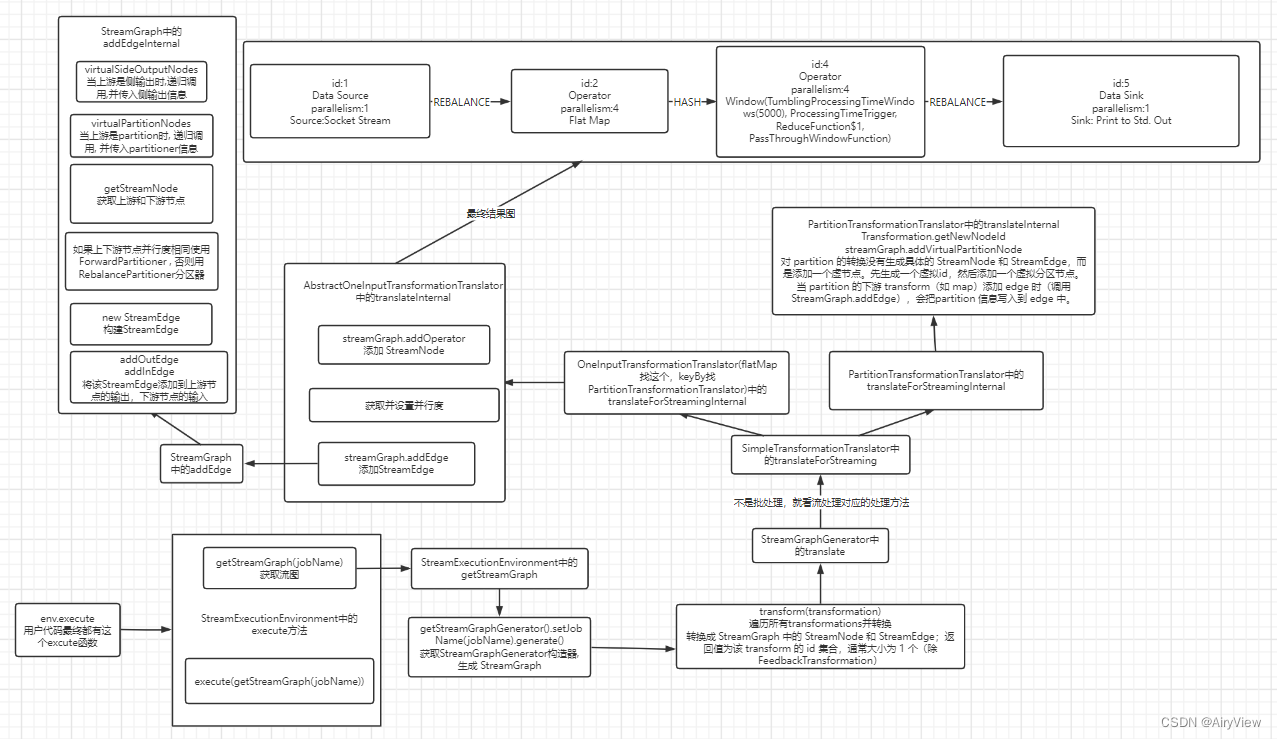
我们下期见!















 1464
1464











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









