







上一期指路
我们上一期分析完了如下代码的getStreamGraph函数,这一期主要从execute起分析作业的生成。
public JobExecutionResult execute(String jobName) throws Exception {
Preconditions.checkNotNull(jobName, "Streaming Job name should not be null.");
return execute(getStreamGraph(jobName));
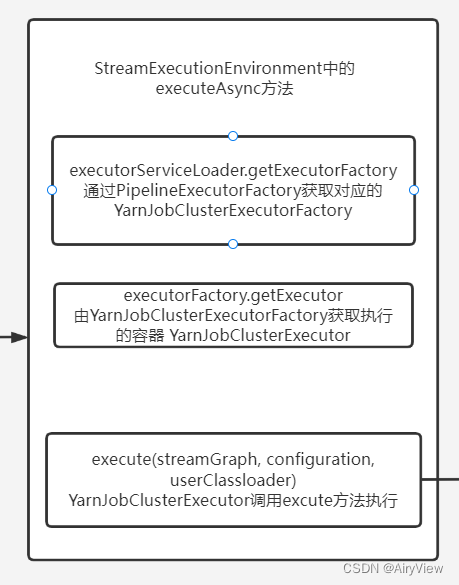
}1.StreamExecutionEnvironment#execute(StreamGraph streamGraph)->executeAsync(streamGraph)
public JobClient executeAsync(StreamGraph streamGraph) throws Exception {
checkNotNull(streamGraph, "StreamGraph cannot be null.");
checkNotNull(configuration.get(DeploymentOptions.TARGET), "No execution.target specified in your configuration file.");
final PipelineExecutorFactory executorFactory =
executorServiceLoader.getExecutorFactory(configuration);
checkNotNull(
executorFactory,
"Cannot find compatible factory for specified execution.target (=%s)",
configuration.get(DeploymentOptions.TARGET));
CompletableFuture<JobClient> jobClientFuture = executorFactory
.getExecutor(configuration)
.execute(streamGraph, configuration, userClassloader);
try {
JobClient jobClient = jobClientFuture.get();
jobListeners.forEach(jobListener -> jobListener.onJobSubmitted(jobClient, null));
return jobClient;
} catch (ExecutionException executionException) {
final Throwable strippedException = ExceptionUtils.stripExecutionException(executionException);
jobListeners.forEach(jobListener -> jobListener.onJobSubmitted(null, strippedException));
throw new FlinkException(
String.format("Failed to execute job '%s'.", streamGraph.getJobName()),
strippedException);
}
}
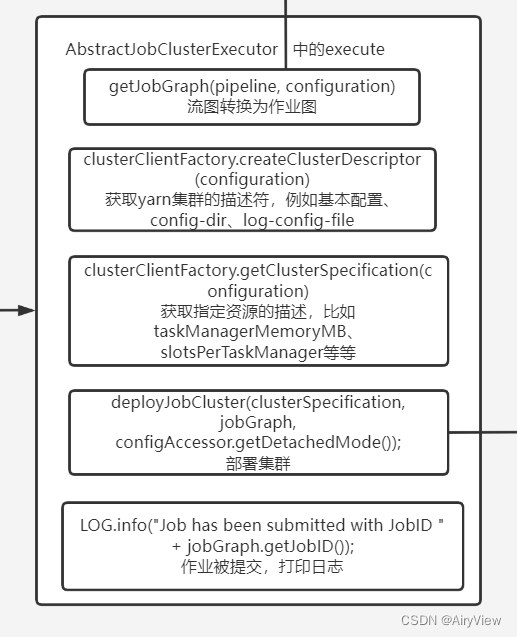
2.AbstractJobClusterExecutor#execute
public CompletableFuture<JobClient> execute(@Nonnull final Pipeline pipeline, @Nonnull final Configuration configuration, @Nonnull final ClassLoader userCodeClassloader) throws Exception {
final JobGraph jobGraph = PipelineExecutorUtils.getJobGraph(pipeline, configuration);
try (final ClusterDescriptor<ClusterID> clusterDescriptor = clusterClientFactory.createClusterDescriptor(configuration)) {
final ExecutionConfigAccessor configAccessor = ExecutionConfigAccessor.fromConfiguration(configuration);
final ClusterSpecification clusterSpecification = clusterClientFactory.getClusterSpecification(configuration);
final ClusterClientProvider<ClusterID> clusterClientProvider = clusterDescriptor
.deployJobCluster(clusterSpecification, jobGraph, configAccessor.getDetachedMode());
LOG.info("Job has been submitted with JobID " + jobGraph.getJobID());
return CompletableFuture.completedFuture(
new ClusterClientJobClientAdapter<>(clusterClientProvider, jobGraph.getJobID(), userCodeClassloader));
}
} 
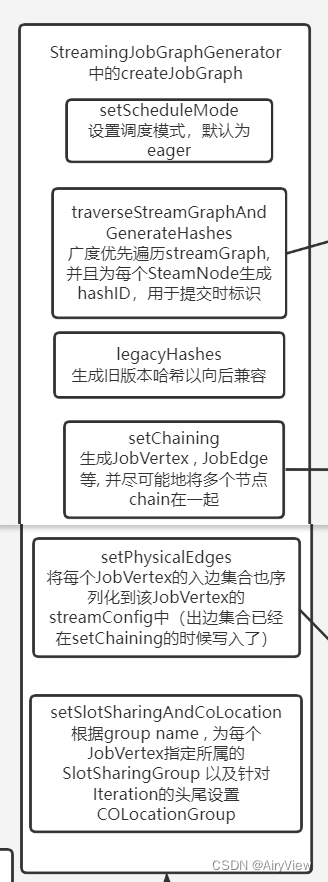
3.PipelineExecutorUtils#getJobGraph->FlinkPipelineTranslationUtil#getJobGraph->StreamGraphTranslator#translateToJobGraph->StreamGraph#getJobGraph->StreamingJobGraphGenerator#createJobGraph->StreamingJobGraphGenerator中的createJobGraph
总之经过上面一系列复杂的跳转,到了如下函数:
private JobGraph createJobGraph() {
preValidate();
// make sure that all vertices start immediately
jobGraph.setScheduleMode(streamGraph.getScheduleMode());
jobGraph.enableApproximateLocalRecovery(streamGraph.getCheckpointConfig().isApproximateLocalRecoveryEnabled());
// Generate deterministic hashes for the nodes in order to identify them across
// submission iff they didn't change.
Map<Integer, byte[]> hashes = defaultStreamGraphHasher.traverseStreamGraphAndGenerateHashes(streamGraph);
// Generate legacy version hashes for backwards compatibility
List<Map<Integer, byte[]>> legacyHashes = new ArrayList<>(legacyStreamGraphHashers.size());
for (StreamGraphHasher hasher : legacyStreamGraphHashers) {
legacyHashes.add(hasher.traverseStreamGraphAndGenerateHashes(streamGraph));
}
setChaining(hashes, legacyHashes);
setPhysicalEdges();
setSlotSharingAndCoLocation();
setManagedMemoryFraction(
Collections.unmodifiableMap(jobVertices),
Collections.unmodifiableMap(vertexConfigs),
Collections.unmodifiableMap(chainedConfigs),
id -> streamGraph.getStreamNode(id).getManagedMemoryOperatorScopeUseCaseWeights(),
id -> streamGraph.getStreamNode(id).getManagedMemorySlotScopeUseCases());
configureCheckpointing();
jobGraph.setSavepointRestoreSettings(streamGraph.getSavepointRestoreSettings());
JobGraphUtils.addUserArtifactEntries(streamGraph.getUserArtifacts(), jobGraph);
// set the ExecutionConfig last when it has been finalized
try {
jobGraph.setExecutionConfig(streamGraph.getExecutionConfig());
}
catch (IOException e) {
throw new IllegalConfigurationException("Could not serialize the ExecutionConfig." +
"This indicates that non-serializable types (like custom serializers) were registered");
}
return jobGraph;
}
①其中调度模式eager适用于流计算。一次性申请需要的所有资源,如果资源不足,则作业启动失败。
②对于traverseStreamGraphAndGenerateHashes补充说明:
为所有节点生成一个唯一的 hash id,如果节点在多次提交中没有改变(包括并发度、上下游等),那么这个 id 就不会改变,这主要用于故障恢复;
以此提出以下疑问
为什么不用StreamNode的Id呢?非要生成hashId?
因为这是一个从 1 开始的静态计数变量,同样的 Job可能会得到不一样的 id。由于声明的顺序的问题可能会出现两个 job 是完全一样的, 但是 source 的 id 却不一样的情况
③对于setPhysicalEdges补充:
每个 JobVertex 都会对应一个可序列化的 StreamConfig, 用来发送给 JobManager 和 TaskManager。最后在 TaskManager 中起 Task 时,需要从这里面反序列化出所需要的配置信息, 其中就包括了含有用户代码的 StreamOperator
4.StreamingJobGraphGenerator#setChaining->StreamingJobGraphGenerator#createChain
private List<StreamEdge> createChain(
final Integer currentNodeId,
final int chainIndex,
final OperatorChainInfo chainInfo,
final Map<Integer, OperatorChainInfo> chainEntryPoints) {
Integer startNodeId = chainInfo.getStartNodeId();
if (!builtVertices.contains(startNodeId)) {
List<StreamEdge> transitiveOutEdges = new ArrayList<StreamEdge>();
List<StreamEdge> chainableOutputs = new ArrayList<StreamEdge>();
List<StreamEdge> nonChainableOutputs = new ArrayList<StreamEdge>();
StreamNode currentNode = streamGraph.getStreamNode(currentNodeId);
for (StreamEdge outEdge : currentNode.getOutEdges()) {
if (isChainable(outEdge, streamGraph)) {
chainableOutputs.add(outEdge);
} else {
nonChainableOutputs.add(outEdge);
}
}
for (StreamEdge chainable : chainableOutputs) {
transitiveOutEdges.addAll(
createChain(chainable.getTargetId(), chainIndex + 1, chainInfo, chainEntryPoints));
}
for (StreamEdge nonChainable : nonChainableOutputs) {
transitiveOutEdges.add(nonChainable);
createChain(
nonChainable.getTargetId(),
1, // operators start at position 1 because 0 is for chained source inputs
chainEntryPoints.computeIfAbsent(
nonChainable.getTargetId(),
(k) -> chainInfo.newChain(nonChainable.getTargetId())),
chainEntryPoints);
}
chainedNames.put(currentNodeId, createChainedName(currentNodeId, chainableOutputs, Optional.ofNullable(chainEntryPoints.get(currentNodeId))));
chainedMinResources.put(currentNodeId, createChainedMinResources(currentNodeId, chainableOutputs));
chainedPreferredResources.put(currentNodeId, createChainedPreferredResources(currentNodeId, chainableOutputs));
OperatorID currentOperatorId = chainInfo.addNodeToChain(currentNodeId, chainedNames.get(currentNodeId));
if (currentNode.getInputFormat() != null) {
getOrCreateFormatContainer(startNodeId).addInputFormat(currentOperatorId, currentNode.getInputFormat());
}
if (currentNode.getOutputFormat() != null) {
getOrCreateFormatContainer(startNodeId).addOutputFormat(currentOperatorId, currentNode.getOutputFormat());
}
StreamConfig config = currentNodeId.equals(startNodeId)
? createJobVertex(startNodeId, chainInfo)
: new StreamConfig(new Configuration());
setVertexConfig(currentNodeId, config, chainableOutputs, nonChainableOutputs, chainInfo.getChainedSources());
if (currentNodeId.equals(startNodeId)) {
config.setChainStart();
config.setChainIndex(chainIndex);
config.setOperatorName(streamGraph.getStreamNode(currentNodeId).getOperatorName());
for (StreamEdge edge : transitiveOutEdges) {
connect(startNodeId, edge);
}
config.setOutEdgesInOrder(transitiveOutEdges);
config.setTransitiveChainedTaskConfigs(chainedConfigs.get(startNodeId));
} else {
chainedConfigs.computeIfAbsent(startNodeId, k -> new HashMap<Integer, StreamConfig>());
config.setChainIndex(chainIndex);
StreamNode node = streamGraph.getStreamNode(currentNodeId);
config.setOperatorName(node.getOperatorName());
chainedConfigs.get(startNodeId).put(currentNodeId, config);
}
config.setOperatorID(currentOperatorId);
if (chainableOutputs.isEmpty()) {
config.setChainEnd();
}
return transitiveOutEdges;
} else {
return new ArrayList<>();
}
}①transitiveOutEdges
过滤用的出边集合,用来生成最终的jobEdge, 注意不包括chain内部的边
②chainableOutputs
可以链接的出边集合
③nonChainableOutputs
不可以链接的出边集合
④getStreamNode(currentNodeId)
获取当前节点
⑤isChainable
判断当前节点的出边是否可以链接并分别放入前面定义的对应集合中,具体规则可以看源码,我这里通过分析源码总结出来的:
⑥transitiveOutEdges.addAll
递归调用获取所有chainable的出边加入transitiveOutEdges集合,所有nonChainable的出边也加入transitiveOutEdges集合
⑦chainedNames.put
生成当前节点的显示名,如:"Keyed Aggregation -> Sink: Unnamed"
⑧currentNodeId.equals(startNodeId)
如果当前节点是起始节点, 则直接创建 JobVertex 并返回 StreamConfig, 否则先创建一个空的 StreamConfig
⑨setVertexConfig
设置 JobVertex 的 StreamConfig, 基本上是序列化 StreamNode 中的配置到 StreamConfig中
⑩currentNodeId.equals(startNodeId)
如果当前不是 chain 中的子节点,
⑾connect(startNodeId, edge)
通过StreamEdge构建出JobEdge,创建 IntermediateDataSet,用来将JobVertex和JobEdge相连
⑿如果是 chain 中的子节点
chainedConfigs.get(startNodeId).put
将当前节点的StreamConfig添加到该chain的config集合中

对于⑾和⑿的补充:
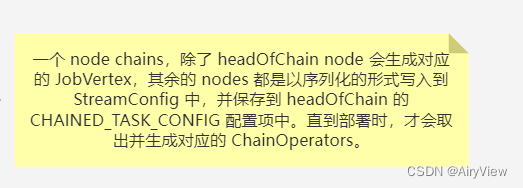
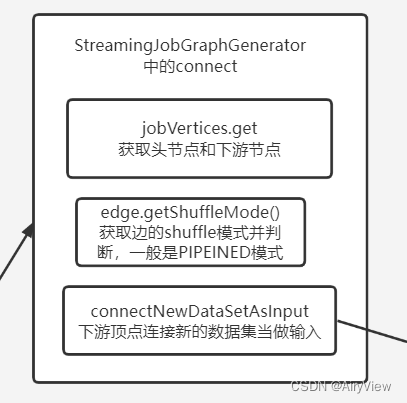
5.StreamingJobGraphGenerator#connect
private void connect(Integer headOfChain, StreamEdge edge) {
physicalEdgesInOrder.add(edge);
Integer downStreamVertexID = edge.getTargetId();
JobVertex headVertex = jobVertices.get(headOfChain);
JobVertex downStreamVertex = jobVertices.get(downStreamVertexID);
StreamConfig downStreamConfig = new StreamConfig(downStreamVertex.getConfiguration());
downStreamConfig.setNumberOfNetworkInputs(downStreamConfig.getNumberOfNetworkInputs() + 1);
StreamPartitioner<?> partitioner = edge.getPartitioner();
ResultPartitionType resultPartitionType;
switch (edge.getShuffleMode()) {
case PIPELINED:
resultPartitionType = ResultPartitionType.PIPELINED_BOUNDED;
break;
case BATCH:
resultPartitionType = ResultPartitionType.BLOCKING;
break;
case UNDEFINED:
resultPartitionType = determineResultPartitionType(partitioner);
break;
default:
throw new UnsupportedOperationException("Data exchange mode " +
edge.getShuffleMode() + " is not supported yet.");
}
checkAndResetBufferTimeout(resultPartitionType, edge);
JobEdge jobEdge;
if (isPointwisePartitioner(partitioner)) {
jobEdge = downStreamVertex.connectNewDataSetAsInput(
headVertex,
DistributionPattern.POINTWISE,
resultPartitionType);
} else {
jobEdge = downStreamVertex.connectNewDataSetAsInput(
headVertex,
DistributionPattern.ALL_TO_ALL,
resultPartitionType);
}
// set strategy name so that web interface can show it.
jobEdge.setShipStrategyName(partitioner.toString());
jobEdge.setDownstreamSubtaskStateMapper(partitioner.getDownstreamSubtaskStateMapper());
jobEdge.setUpstreamSubtaskStateMapper(partitioner.getUpstreamSubtaskStateMapper());
if (LOG.isDebugEnabled()) {
LOG.debug("CONNECTED: {} - {} -> {}", partitioner.getClass().getSimpleName(),
headOfChain, downStreamVertexID);
}
} 
6.JobVertex#connectNewDataSetAsInput
public JobEdge connectNewDataSetAsInput(
JobVertex input,
DistributionPattern distPattern,
ResultPartitionType partitionType) {
IntermediateDataSet dataSet = input.createAndAddResultDataSet(partitionType);
JobEdge edge = new JobEdge(dataSet, this, distPattern);
this.inputs.add(edge);
dataSet.addConsumer(edge);
return edge;
}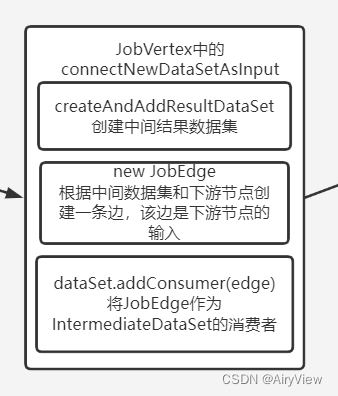
连接完后如下图:

总览
本期设计到的源码流程图如下:
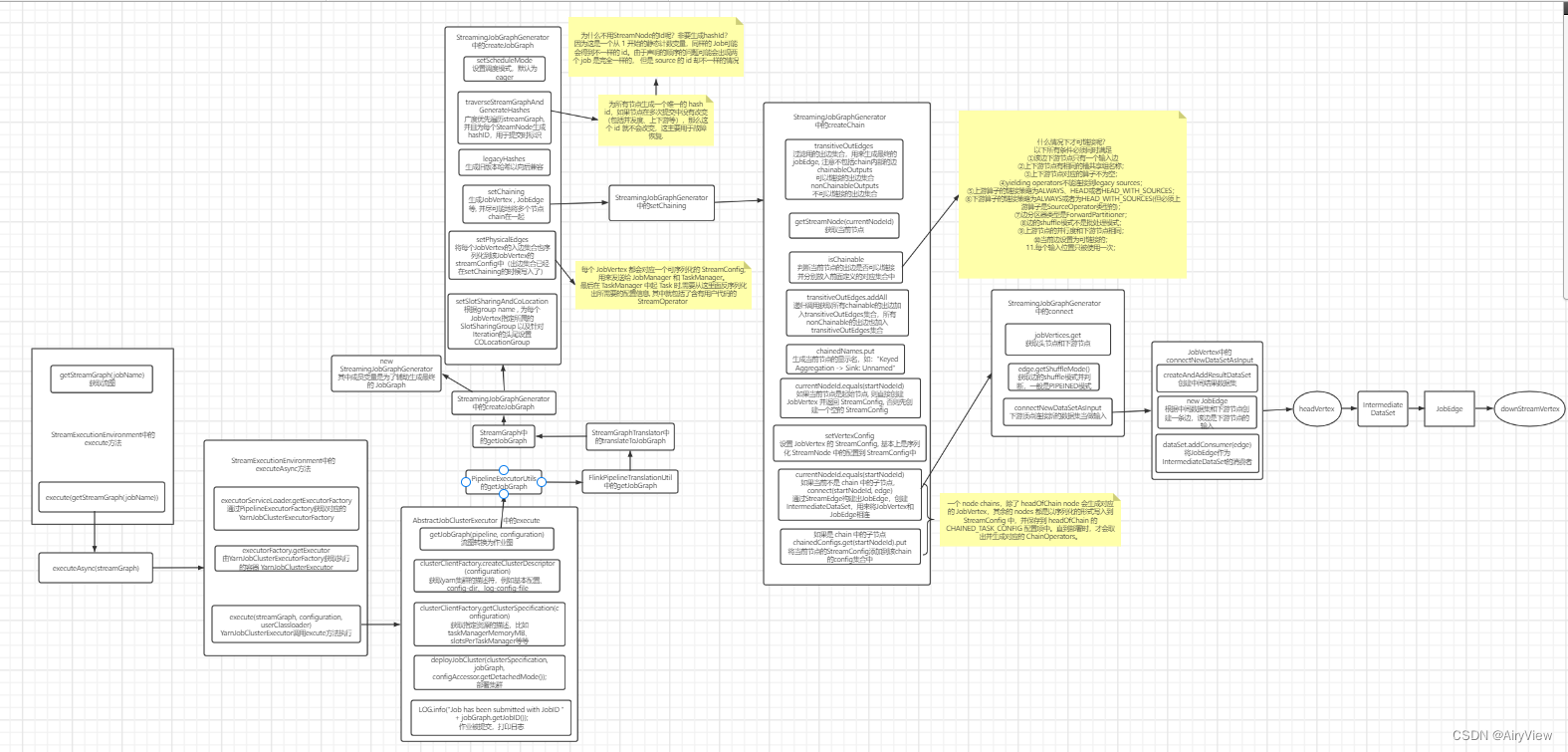
我们下期见!















 7304
7304











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









