







本文通过对Apache Commons Collections 项目中LRUMap这个集合类的源代码进行详细解读,为帮助大家更好的了解这个集合类的实现原理以及使用如何该集合类。
首先介绍一下LRU算法. LRU是由Least Recently Used的首字母组成,表示最近最少使用的含义,一般使用在对象淘汰算法上。也是比较常见的一种淘汰算法。
LRUMap 则是实现的LRP算法的Map集合类,它继承于AbstractLinkedMap 抽象类。LRUMap的使用说明如下:
LRUMap的初始化时需要指定最大集合元素个数,新增的元素个数大于允许的最大集合个数时,则会执行LRU淘汰算法。所有的元素在LRUMap中会根据最近使用情况进行排序。最近使用的会放在元素的最前面(LRUMap是通过链表来存储元素内容). 所以LRUMap进行淘汰时只需要删除链表最后一个即可(即header.after所指的元素对象)
那么那些操作会影响元素的使用情况:
1. put 当新增加一个集合元素对象,则表示该对象是最近被访问的
2. get 操作会把当前访问的元素对象作为最近被访问的,会被移到链接表头
注:当执行containsKey和containsValue操作时,不会影响元素的访问情况。
LRUMap也是非线程安全。在多线程下使用可通过 Collections.synchronizedMap(Map)操作来保证线程安全。
LRUMap的一个简单使用示例:
public static void main(String[] args) {
Map lru = new LRUMap(3);
lru.put("1", 1);
lru.put("2", 2);
lru.get("1");
lru.put("3", 3);
lru.put("4", 4);
System.out.println(lru);
}
上面的示例,当增加”3”和“4”值时,会淘汰最近最少使用的”2”, 最后输出的结果为:
{1=1, 3=3, 4=4}
下面根据LRUMap的源码来解读一下LRUMap的实现原理
整体类图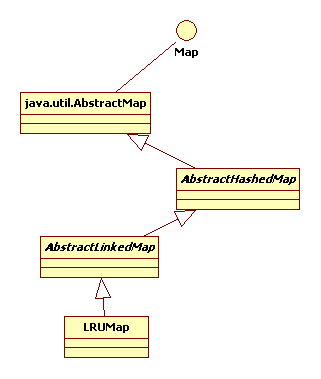
真实类图:
LRUMap类的关键代码说明如下:
1. get操作:
moveToMRU方法代码如下
protected void moveToMRU(final LinkEntry<K, V> entry) {
if (entry.after != header) {
modCount++;
// remove
if(entry.before == null) {
thrownew IllegalStateException("Entry.before is null." +
" Please check that your keys are immutable, and that you have used synchronization properly." +
" If so, then please report this to dev@commons.apache.org as a bug.");
}
entry.before.after = entry.after;
entry.after.before = entry.before;
// add first
entry.after = header;
entry.before = header.before;
header.before.after = entry;
header.before = entry;
} elseif (entry == header) {
thrownew IllegalStateException("Can't move header to MRU" +
" (please report this to dev@commons.apache.org)");
}
}
2. put新增操作
由于继承的AbstractLinkedMap,所以put操作会调用addMapping 方法,完整代码如下:
@Override
protectedvoid addMapping(finalinthashIndex, finalinthashCode, final K key, final V value) {
if (isFull()) {
LinkEntry<K, V> reuse = header.after;
booleanremoveLRUEntry = false;
if (scanUntilRemovable) {
while (reuse != header && reuse != null) {
if (removeLRU(reuse)) {
removeLRUEntry = true;
break;
}
reuse = reuse.after;
}
if (reuse == null) {
thrownew IllegalStateException(
"Entry.after=null, header.after" + header.after + " header.before" + header.before +
" key=" + key + " value=" + value + " size=" + size + " maxSize=" + maxSize +
" Please check that your keys are immutable, and that you have used synchronization properly." +
" If so, then please report this to dev@commons.apache.org as a bug.");
}
} else {
removeLRUEntry = removeLRU(reuse);
}
if (removeLRUEntry) {
if (reuse == null) {
thrownew IllegalStateException(
"reuse=null, header.after=" + header.after + " header.before" + header.before +
" key=" + key + " value=" + value + " size=" + size + " maxSize=" + maxSize +
" Please check that your keys are immutable, and that you have used synchronization properly." +
" If so, then please report this to dev@commons.apache.org as a bug.");
}
reuseMapping(reuse, hashIndex, hashCode, key, value);
} else {
super.addMapping(hashIndex, hashCode, key, value);
}
} else {
super.addMapping(hashIndex, hashCode, key, value);
}
}
当集合的个数超过指定的最大个数时,会调用 reuseMapping函数,把要删除的对象的key和value更新为新加入的值,并再次加入到链接表中,并重新排定次序。
reuseMapping函数代码如下:
protectedvoid reuseMapping(final LinkEntry<K, V> entry, finalinthashIndex, finalinthashCode,final K key, final V value) {
// find the entry before the entry specified in the hash table
// remember that the parameters (except the first) refer to the new entry,
// not the old one
try {
finalintremoveIndex = hashIndex(entry.hashCode, data.length);
final HashEntry<K, V>[] tmp = data; // may protect against some sync issues
HashEntry<K, V> loop = tmp[removeIndex];
HashEntry<K, V> previous = null;
while (loop != entry && loop != null) {
previous = loop;
loop = loop.next;
}
if (loop == null) {
thrownew IllegalStateException(
"Entry.next=null, data[removeIndex]=" + data[removeIndex] + " previous=" + previous +
" key=" + key + " value=" + value + " size=" + size + " maxSize=" + maxSize +
" Please check that your keys are immutable, and that you have used synchronization properly." +
" If so, then please report this to dev@commons.apache.org as a bug.");
}
// reuse the entry
modCount++;
removeEntry(entry, removeIndex, previous);
reuseEntry(entry, hashIndex, hashCode, key, value);
addEntry(entry, hashIndex);
} catch (final NullPointerException ex) {
thrownew IllegalStateException(
"NPE, entry=" + entry + " entryIsHeader=" + (entry==header) +
" key=" + key + " value=" + value + " size=" + size + " maxSize=" + maxSize +
" Please check that your keys are immutable, and that you have used synchronization properly." +
" If so, then please report this to dev@commons.apache.org as a bug.");
}
}
上面的代码中:
removeEntry 方法是删除最近最少使用的节点在链接中的引用
reuseEntry方法则把该节点的key和value赋新加入的节点的key和value值
addEntry 方法则把该节点加入到链接表,并保障相关的链接顺序
/**
* Adds an entry into this map, maintaining insertion order.
* <p>
* This implementation adds the entry to the data storage table and
* to the end of the linked list.
*
* @param entry the entry to add
* @param hashIndex the index into the data array to store at
*/
@Override
protectedvoid addEntry(final HashEntry<K, V> entry, finalinthashIndex) {
final LinkEntry<K, V> link = (LinkEntry<K, V>) entry;
link.after = header;
link.before = header.before;
header.before.after = link;
header.before = link;
data[hashIndex] = link;
}
LRUMap的主要源码实现就解读到这里,实现思路还是比较好理解的。
LRUMap的使用场景会比较多,例如可以很方便的帮我们实现基于内存的 LRU 缓存服务实现。
转载于:http://www.blogjava.net/xmatthew/archive/2012/06/28/380150.html——大牛(xmatthew)















 471
471











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









