







分布式系统本质是通过低廉的硬件攒在一起以获得更好的吞吐量、性能以及可用性等。一台设备坏了,可以通过负载均衡和路由到其他设备上。分布式系统有一些通用的设计策略,首先要解决心跳问题。一台服务器判定存活状态,才能执行任务,否则则不能。在分布式环境下,有几个问题是普遍关心的,我们称之为设计策略:
- 如何监测你还活着?
- 如何保障高可用?
- 容错处理。
- 重试机制。
- 负载均衡。
心跳检测
在分布式环境中,存在非常多的节点(Node),其实质是这些节点分担任务的运行、计算或者程序逻辑处理。那么就有一个非常重要的问题,如何监测一个节点出现了故障乃至无法工作了?具体的场景可以是主备服务之间的切换,也可以是一个管理服务器来管理具体的工作节点。无论怎样,都需要解决“判定某节点无法工作”这一命题。
传统解决这一命题是采用心跳检测的手段,如同通过仪器对病人进行一些检测诊断一样。
如下图所示,当Server没有收到节点Node3发送的心跳时,Server认为Node3失联。失联代码并不确定是否是Node3故障,有可能是Node3处于繁忙状态,导致调用检测超时;也有可能是Server与节点C之间链路出现故障或闪断。所以心跳不是万能的,收到心跳可以确认节点正常,但是收不到心跳却不能确认该节点已经宣告“死亡”。
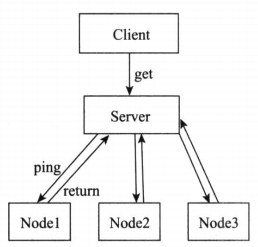
Client请求Server,则Server需要和需要分派的Node1-3保持连接,得到返回,说明状态没问题,可以分派。我们刚才已经说过了,没有返回不代表宕机,有一些具体的做法来帮助我们做决定,一般分为两类:周期检测心跳机制、累计失效检测机制。这里简单说一下周期检测心跳机制。Server端每间隔t秒向Node集群发起检测请求,设定超时时间,如果超过超时时间,则判断“死亡”。这里的超时时间设置带有随意性,容易误判。进一步,可以统计实际检测Node的返回时间,包括得到一定周期内的最长时间。那么可以根据现有没有正确返回的时间在历史统计的分布中计算得到“死亡”概率,同时对于宣告濒临死亡的节点可以发起有限次数的重试,以作进一步判定。心跳检测本身也是有效资源利用和成本之间的一种权衡,如果迟迟不能判断节点是否“死亡”,会影响业务逻辑的处理。通过周期检测心跳机制、累计失效检测机制可以帮助判断节点是否“死亡”,如果判断“死亡”,可以把该节点踢出集群。
高可用设计
系统高可用性的常用设计模式包括三种:主备(Master-Slave)、互备(Active-Active)和集群(Cluster)模式。
主备模式
主备模式就是Active-Standby模式,当主机宕机时,备机接管主机的一切工作,待主机恢复正常后,按使用者的设定以自动(热备)或手动(冷备)方式将服务切换到主机上运行。在数据库部分,习惯称之为MS模式。MS模式即Master/Slave模式,这在数据库高可用性方案比较常用,如下图所示。
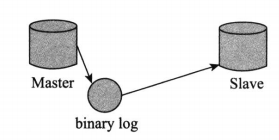
此类方案比较成熟,比如MySQL很早就具备相应的软件套装。但存在Master到Slave的数据延迟风险,尤其是跨地域复制。
互备模式
互备模式指两台主机同时运行各自的服务工作且相互检测情况。在数据库高可用部分,常见的互备是MM模式。MM模式即Multi-Master模式,指一个系统存在多个master,每个master都具有read-write能力,需根据时间戳或业务逻辑合并版本。比如分布式版本管理系统git可以理解成multi-master模式,具备最终一致性。
机房级异常的示例,也是一种Master-Master的解决方案,如下图所示。机房H、K同时具备全套服务能力(读能力和写能力),而数据库之间需要通过同步来保障一致性。当然对于K机房的备库则在机房不可用的时候发挥作用。

集群模式
集群模式是指有多个节点在运行,同时可以通过主控节点分担服务请求,比如zookeeper。集群模式要特别解决主控节点本身的高可用问题。下面是TFS案例,如下图所示。

TFS涉及到NameServer、DataServer两类节点。NameServer存放了元数据,而具体的业务数据存放于DataServer。多个DataServer就是集群模式的运行状态。另外为了保障NameServer的高可用,通过Heart Agent机制做心跳检测来负责NameServer的主备切换。
容错性
容错顾名思义就是IT系统对于错误包容的能力,这里的容错确切的说是容故障(Fault),而并非容错误(Error)。
以前文提及的TFS为例,TFS集群需要容错(一个集群宕掉咋办?)、NameServer需要容错、DataServer的容错。NameServer的容错机制是通过主备切换来完成。NameServer主要管理了DataServer和Block之间的关系。如每个DataServer拥有哪些Block,每个Block存放在哪些DataServer上等。同时,NameServer采用了HA结构,一主一备,主NameServer上的操作会重放至备NameServer。如果主NameServer出现问题,可以实时切换到备NameServer。
另外NameServer和DataServer之间也会有定时的heartbeat,DataServer会把自己拥有的Block发送给NameServer。NameServer会根据这些信息重建DataServer和Block的关系。
容错的处理是保障分布式环境下相应系统的高可用性或者健壮性,一个典型的案例就是对于缓存失效雪崩问题的解决方案。
假设有一个业务,用户查询不到数据,可能是数据库没有,也可能是未知异常,用户可以间隔一定时间后重试,那么可以这样设计缓存容错方案。我们来具体看一下这个例子,如下3个图所示。


上图三个图会有什么问题呢?我们在项目中使用缓存通常都是缓存通常都是先检查缓存中是否存在,如果存在直接返回缓存内容,如果不存在就直接查询数据库然后再缓存查询结果返回。这个时候如果我们查询得某一个数据在缓存中一直不存在,就会造成每一次请求都查询DB,这样缓存就失去了意义,在流量大时,可能DB就挂掉了。
那这种问题有什么好办法解决呢?要是有人利用不存在的key频繁攻击我们的应用,这就是漏洞。一个比较巧妙的方法是,可以将这个不存在的key预先设定一个值。比如,key="&&"。在返回这个&&值的时候,我们的应用就可以认为这是不存在的key预先设定一个值。比如,key="&&"。在返回这个&&值的时候,我们的应用就可以认为这时不存在的key,那我们的应用就可以决定是否继续等待继续访问,还是放弃掉这次操作。如果继续等待访问,过一个时间轮询点后,再次请求这个key,如果取得值不再是&&,则可以认为这时候key有值了,从而避免了透传到数据库,把大量的类似请求挡在了缓存之中。
负载均衡
负载均衡集群:其关键在于使用多台集群服务器共同分担计算任务,把网络请求及计算分配到集群可用服务器上去,从而达到可用性及较好的用户操作体验。下图所示就是一个示意图,不同的用户User1、User2、User3访问应用,通过负载均衡器分配到不同的节点。
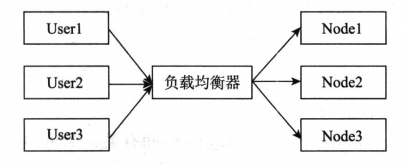
负载均衡器有硬件解决方案,也有软件解决方案。硬件解决方案有著名的F5,软件有LVS、HAproxy、Nginx等。
以Nginx为例,负载均衡有以下几种策略:
- 轮询:即Round Robin,根据Nginx配置文件中的顺序,依次把客户端的Web请求分发到不同的后端服务器。
- 最少连接:当前谁连接最少,分发给谁。
- IP地址哈希:确定相同IP请求可以转发给同一个后端节点处理,以方便session保持。
- 基于权重的负载均衡:配置Nginx把请求更多的分发到高配置的后端服务器上,把相对较少的请求分发到低配服务器。















 323
323











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









