









根据维基百科上的定义,负载均衡(Load Balance)是一种相当常见的计算机网络技术,用来对多个计算机(计算机集群)、网络连接、CPU、磁盘驱动器或其他资源进行分配负载,以达到优化资源使用、最大化吞吐率、最小化响应时间和避免过载的目的。通常负载均衡可以分为硬件和软件负载均衡两类,本文主要讨论的是ZooKeeper在“软”负载均衡中的应用场景。
在分布式系统中,负载均衡更是一种普遍的技术,基本上每一个分布式系统都需要使用负载均衡。分布式系统具有对等性,为了保证系统的高可用性,通常采用副本的方式来对数据和服务进行部署。而对于消费者而言,则需要在这些对等的服务提供方中选择一个来执行相关的业务逻辑,其中比较典型的就是DNS服务。
一种动态的DNS服务
DNS是域名系统(Domain Name System)的缩写,是因特网中使用最广泛的核心技术之一。DNS系统可以看做是一个超大规模的分布式映射表,用于将域名和IP地址进行一一映射,进而方便人们通过域名来访问互联网站点。
通常情况下,我们可以向域名注册服务商申请域名注册,但是这种方式最大的缺陷在于只能注册有限的域名:
因此,在实际开发中,往往使用本地HOST绑定来实现域名解析的工作。使用本地HOST绑定的方法,可以很容易解决域名紧张的问题,基本上每一个系统都可以自行确定系统的域名与目标IP地址。同时,这种方法对于开发人员最大的好处就是可以随时修改域名与IP的映射,大大提高了开发调试效率。然而,这种看上去完美的方案,也有其致命的缺陷:日常开发过程中,经常会碰到这样的情况,在一个Company1公司内部,需要给一个App1应用的服务器集群及其配置一个域名解析。相信有过一线开发经验的读者一定知道,这个时候通常会需要有类似于app1.company1.com的一个域名,其对应的就是一个服务器地址。如果系统数量不多,那么通过这种传统的DNS配置方式还可以应付,但是,一旦公司规模变大,各类应用层出不穷,那么就很难再通过这种方式来进行统一的管理了。
现在,我们来介绍一种基于ZooKeeper实现的动态DNS方案(以下简称该方案为“DDNS”,Dynamic DNS)。当应用的机器规模在一定范围内,并且域名的变更不是特别频繁时,本地HOST绑定是非常高效且简单地方式。然而一旦及其规模变大后,就常常会碰到这样的情况:我们在应用上线的时候,需要在应用的每台机器上去绑定域名,但是在机器规模相当庞大的情况下,这种做法就相当不方便。另外,如果想要临时变更新域名,还需要到每个机器上去逐个进行变更,要消耗大量时间,因此完全无法保证实时性。
域名配置
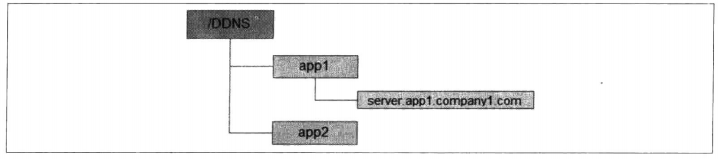
和配置管理一样,我们首先需要在ZooKeeper上创建一个节点来进行域名配置,例如/DDNS/app1/server.app1.company1.com(以下简称“域名节点”),如下图所示。
从上图中我们看到,每个应用都可以创建一个属于自己的数据节点作为域名配置的根节点,例如/DDNS/app1,在这个节点上,每个应用都可以将自己的域名配置上去,下图是一个配置实例。

域名解析
在传统的DNS解析中,我们都不需要关心域名的解析过程,所有这些工作都交给了操作系统的域名和IP地址映射机制(本地HOST绑定)或是专门的域名解析服务器(由域名注册服务商提供)。因此,在这点上,DDNS方案和传统的域名解析有很大的区别——在DDNS中,域名的解析过程都是由每一个应用自己负责的。通常应用都会首先从域名节点中获取一份IP地址和端口的配置,进行自行解析。同时,每个应用还会在域名节点上注册一个数据变更Watcher监听,以便及时收到域名变更的通知。
域名变更
在运行过程中,难免会碰上域名对应的IP地址或是端口变更,这个时候就需要进行域名变更操作。在DDNS中,我们只需要对指定的域名节点进行更新操作,ZooKeeper就会向订阅的客户端发送这个事件通知,应用在接收到这个事件通知后,就会再次进行域名配置的获取。
上面我们介绍了如何使用ZooKeeper来实现一种动态的DNS系统。通过ZooKeeper来实现动态DNS服务,一方面,可以避免域名数量无限增长带来的集中式维护的成本;另一方面,在域名变更的情况下,也能够避免因逐台机器更新本地HOST而带来的繁琐工作。
自动化的DNS服务
根据上面的讲解,相信读者基本上已经能够使用ZooKeeper来实现一个动态的DNS服务了。但是我们仔细看一下上面的实现就会发现,在域名变更环节中,当域名对应的IP地址发生变更的时候,我们还是需要人为的介入去修改域名节点上的IP地址和端口。接下来我们看看下面这种使用ZooKeeper实现的更为自动化的DNS服务。自动化的DNS服务系统主要是为了实现服务的自动化定位,整个系统架构如下图所示。
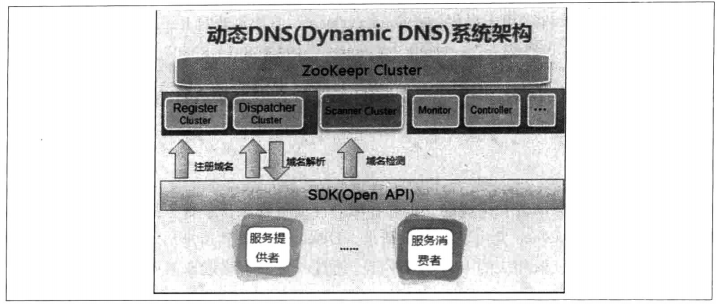
首先来介绍整个动态DNS系统的架构体系中几个比较重要的组件及其职责。
- Register 集群负责域名的动态注册。
- Dispatcher 集群负责域名解析。
- Scanner 集群负责检测以及维护服务状态(探测服务的可用性、屏蔽异常服务节点等)。
- SDK 提供各种语言的系统接入协议,提供服务注册以及查询接口。
- Monitor 负责收集服务信息以及对DDNS自身状态的监控。
- Controller 是一个后台管理的Console,负责授权管理、流量控制、静态配置服务和手动屏蔽服务等功能,另外,系统的运维人员也可以在上面管理Register、Dispatcher和Scanner等集群。
域名注册
- 服务提供者通过SDK提供的API接口,将域名、IP地址和端口发送给Register集群。例如,A及其用于提供serviceA.xxx.com,于是他就向Register发送一个“域名→IP:PORT”的映射:“serviceA.xxx.com→192.168.0.1:8080”。
- Register获取到域名、IP地址和端口配置后,根据域名将信息写入相对应的ZooKeeper域名节点中。















 286
286

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









