







MapReduce架构
在hadoop1.x版本中MapReduce架构如下图所示:
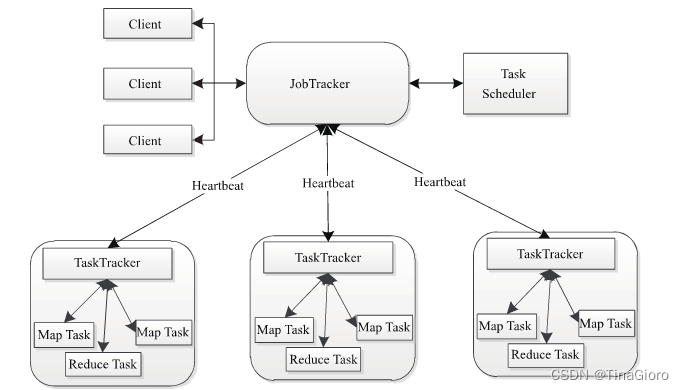
整个集群采用master/slave模式:1个JobTracker和多个TaskTracker。
1)Client client
每一个 Job 都会在用户端通过 Client 类将应用程序以及配置參数 Configuration 打包成 JAR 文件存储在 HDFS,并把路径提交到 JobTracker 的 master 服务,然后由 master 创建每一个 Task(即 MapTask 和 ReduceTask) 将它们分发到各个 TaskTracker 服务中去执行。
2)JobTracker职责:
负责整个集群的资源管理:JobTracker通过定期收集TaskTracker节点资源使用情况以确定下一个任务在哪个TaskTracker节点上运行。
负责作业调度:定期收集TaskTracker节点job运行情况,对于运行失败的job则会下发到另外的节点上运行。
3)TaskTracker职责:
定期向JobTracker汇报本节点的健康情况,资源使用情况,job运行情况。
接受TaskTracker的指令:启动job,杀死job等。















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









