









线性分类模型之感知机
以下是本文的思路:
- 思想
- 模型
- 策略
- 算法
- 例子
- 结语
1.思想:错误驱动
已知线性可分数据: Data = {
(
X
i
,
y
i
)
{(X_{i},y_i)}
(Xi,yi)} 其中 (i = 1,2,…,N);N个样本,p个特征。
假设数据线性可分:如图。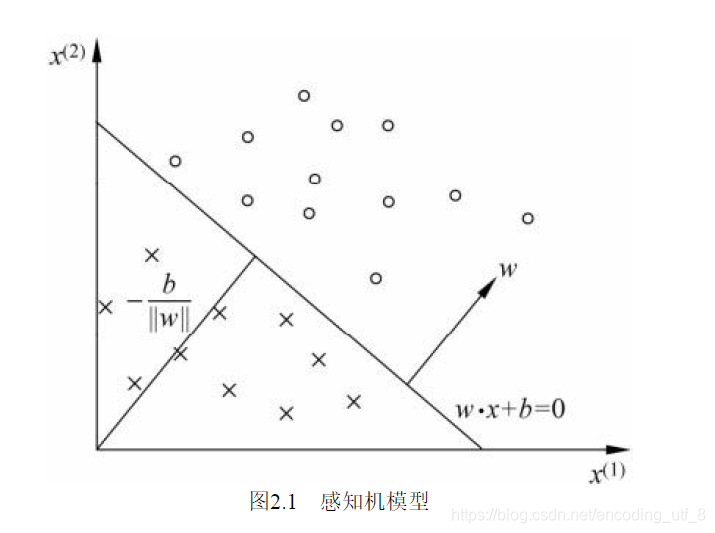
设 D = {被错误分类的样本}
2.模型
f ( x ) = S i g n ( w T x ) , x ∈ R p , w ∈ R p , 其 中 S i g n ( a ) = { 1 a ⩾ 0 − 1 a < 0 \boxed{f(x) = Sign(w^Tx) ,x\in R^p,w\in R^p,其中Sign(a) = \begin{cases}1&a\geqslant0\\-1&a<0\end{cases}} f(x)=Sign(wTx),x∈Rp,w∈Rp,其中Sign(a)={1−1a⩾0a<0
3.策略:(loss function)
思路一:我们使用被错误分类的点的个数为loss function:
L
(
w
)
=
∑
i
=
1
N
I
{
y
i
w
T
<
0
}
\boxed{L(w) = \sum\limits_{i=1}^NI\{y_i w^T<0\}}
L(w)=i=1∑NI{yiwT<0}
由于这个loss function 不可导,不方便对它进行优化,所以我们采用思路二。
思路二:我们发现
−
∑
i
=
1
N
y
i
w
T
{-\sum\limits_{i=1}^Ny_iw^T}
−i=1∑NyiwT刚好可以作为loss function
L
(
w
)
=
−
∑
x
i
∈
D
N
y
i
w
T
{L(w) = -\sum\limits_{x_i\in D}^Ny_iw^T}
L(w)=−xi∈D∑NyiwT ,这个loss function 刚好是可导而且可以完成分类任务。
想想为什么? L ( w ) = − ∑ x i ∈ D N y i w T \boxed{L(w) = -\sum\limits_{x_i\in D}^Ny_iw^T} L(w)=−xi∈D∑NyiwT表示错误的点到平面的距离和。
4.算法:(SGD–随机梯度下降法)
W
(
t
+
1
)
⟵
W
(
t
)
−
λ
∇
(
L
)
\boxed{W^{(t+1)} \longleftarrow W^{(t)} - \lambda\nabla (L)}
W(t+1)⟵W(t)−λ∇(L)
其中,
λ
为
步
长
,
∇
(
L
)
为
梯
度
,
∇
(
L
)
=
−
y
i
x
i
。
{\lambda 为步长,\nabla (L) 为梯度,\nabla (L) = -y_ix_i 。}
λ为步长,∇(L)为梯度,∇(L)=−yixi。
5.例子:
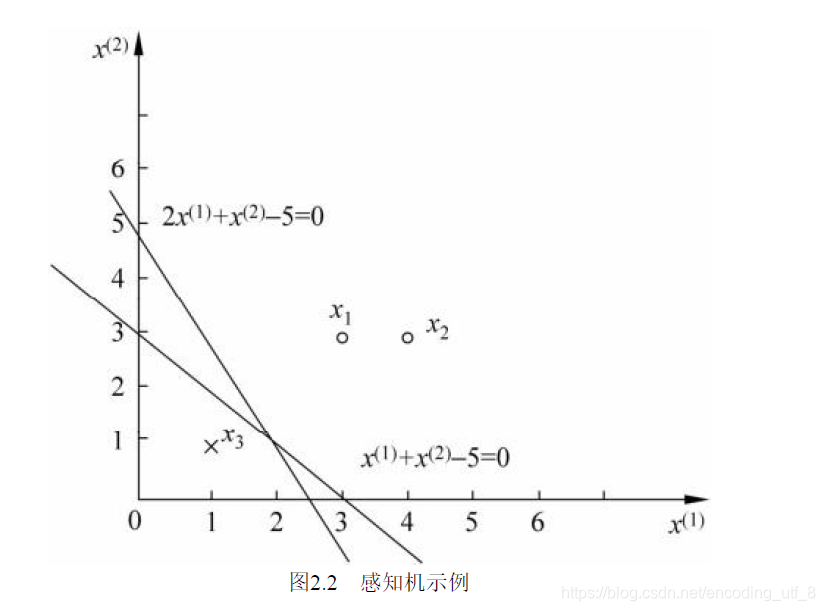
例2.1 如图2.2所示的训练数据集,其正实例点是x1=(3,3)T,x2=(4,3)T,负实例点是x3=(1,1)T,试用感知机学习算法的原始形式求感知机模型f(x)=sign(w·x+b)。这里,w=(w(1),w(2))T,x=(x(1),x(2))T。

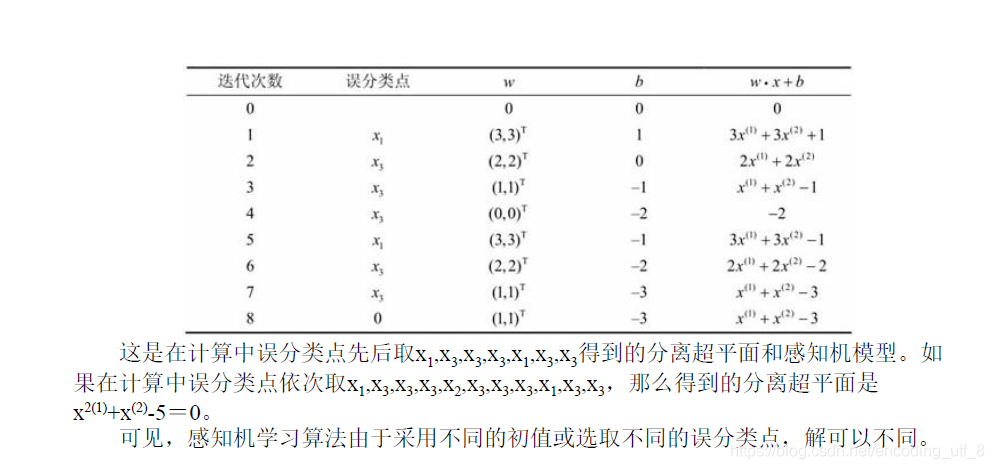
6.结语:
经过一番努力,我们终于完成了感知机的模型与算法推导,希望大家能够自己多多动手,自己总结,能够掌握感知机模型。
参考内容:
1.白板推导之线性分类模型
2.李航《统计学习方法》


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









