







1.线性预测模型构建步骤
数据预处理 -> 建立模型 -> 训练模型 -> 模型评估-> 模型预测
2.代码呈现
import pandas as pd
import numpy as np
import torch
from torch.utils.data import Dataset,DataLoader
from sklearn.model_selection import train_test_split
import torch.nn as nn
import torch.optim as optim
from tqdm import tqdm
class MyDataset(Dataset):
def __init__(self,x,y=None):
self.x = x
self.y = y if y is not None else None
def __len__(self):
return len(self.x)
def __getitem__(self,idx):
if self.y is not None:
return self.x[idx],self.y[idx]
else:
return self.x[idx]
class MyModel(nn.Module):
def __init__(self, input_dim):
super(MyModel,self).__init__()
self.model = nn.Sequential(
nn.Linear(input_dim, 64),
nn.ReLU(),
nn.Linear(64,16),
nn.ReLU(),
nn.Linear(16,1)
)
def forward(self, x):
return self.model(x).squeeze(1)
def main():
device = "cuda" if torch.cuda.is_available() else "cpu"
# data load
test_data = pd.read_csv("covid.test.csv").values.astype(np.float32)
train_data = pd.read_csv("covid.train.csv").values.astype(np.float32)
train_data,val_data = train_test_split(train_data, test_size=0.2, random_state=42)
train_x = train_data[:,:-1]
train_y = train_data[:,-1]
val_x = val_data[:,:-1]
val_y = val_data[:,-1]
train_dataset = MyDataset(train_x, train_y)
val_dataset = MyDataset(val_x, val_y)
train_loader = DataLoader(train_dataset, batch_size = 16, shuffle=True)
val_loader = DataLoader(val_dataset, batch_size = 16, shuffle = True)
# model
input_dim = train_x.shape[1]
model = MyModel(input_dim).to(device)
# loss function and optimizer
loss_fn = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
scheduler = optim.lr_scheduler.ReduceLROnPlateau(
optimizer,
mode='min', # 监控最小化指标(验证loss)
factor=0.5, # 学习率降低为原来的0.5倍
patience=10, # 等待10个epoch验证loss无改善才降低学习率
verbose=True # 打印学习率变化信息
)
# train
train_losses = []
val_losses = []
best_loss = float('inf')
epochs = 200
early_stop_count = 0
for epoch in range(epochs):
model.train()
total_loss = 0
loop = tqdm(train_loader, desc = f'Epoch{epoch+1}/{epochs}')
for x,y in loop:
x, y = x.to(device), y.to(device)
optimizer.zero_grad()
pred = model(x)
loss = loss_fn(pred,y)
loss.backward()
optimizer.step()
total_loss += loss.item()
loop.set_postfix({'loss':loss.item()})
train_losses.append(total_loss/len(train_loader))
print(f"Epoch:{epoch+1}, Loss:{total_loss/len(train_loader):.4f}")
# val
model.eval()
val_loss = 0
with torch.no_grad():
for x,y in val_loader:
x, y = x.to(device), y.to(device)
pred = model(x)
loss = loss_fn(pred,y)
val_loss += loss.item()
val_losses.append(val_loss/len(val_loader))
print(f"[val] Epoch:{epoch+1}, Loss:{val_loss/len(val_loader):.4f}")
scheduler.step(val_loss/len(val_loader))
if val_loss<best_loss:
best_loss = val_loss
torch.save(model.state_dict(),r"model_new.pth")
early_stop_count = 0
else:
early_stop_count += 1
if early_stop_count == 50:
break
# picture
import matplotlib.pyplot as plt
plt.figure(figsize=(10,6))
plt.plot(range(1,len(train_losses)+1), train_losses, label='Train Loss')
plt.plot(range(1,len(val_losses)+1), val_losses, label='Val Loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.title('Train and Val Loss')
plt.legend()
plt.grid(True)
plt.savefig("loss_curve.png")
plt.close()
def predict():
device = "cuda" if torch.cuda.is_available() else "cpu"
test_data = pd.read_csv("covid.test.csv").values.astype(np.float32)
test_dataset = MyDataset(test_data)
test_loader = DataLoader(test_dataset, batch_size=16, shuffle=False)
input_dim = test_data.shape[1]
model = MyModel(input_dim).to(device)
model.load_state_dict(torch.load("model_new.pth", weights_only=False))
model.eval()
with torch.no_grad():
predictions = []
for x in test_loader:
x = x.to(device)
pred = model(x)
predictions.extend(pred.cpu().numpy().flatten())
output_path = "pred_new.csv"
df = pd.DataFrame(predictions, columns = ['tested_positive'])
df.to_csv(output_path, index_label="id")
if __name__ == "__main__":
predict()
3.模型效果
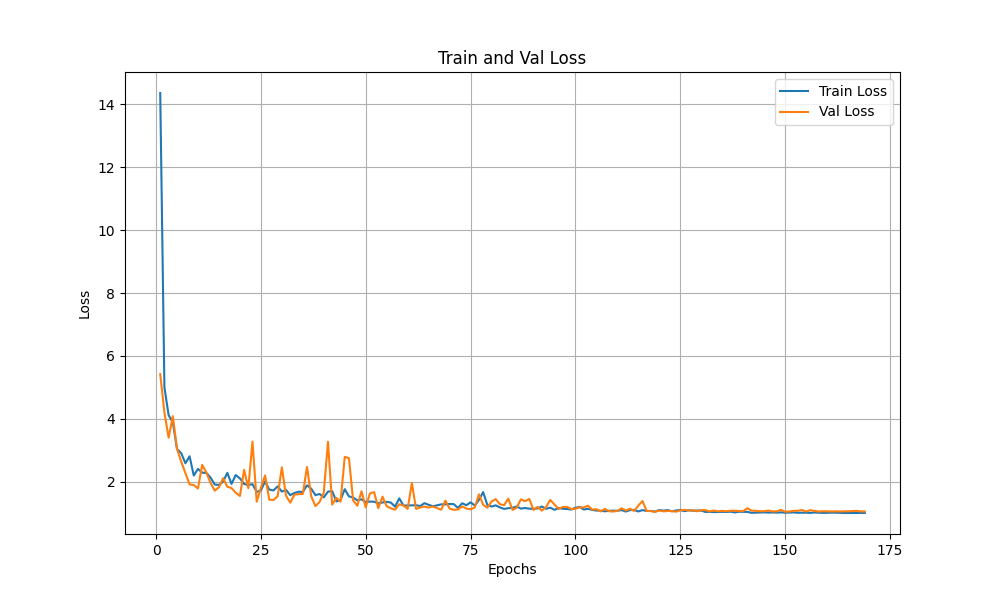
目前在kaggle上的评分:

4.写在最后
目前还没做到0.4左右的Score,有任何优化建议,欢迎大家在评论中提出
邮箱:2719516788@qq.com


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









