







Pandas Series 类似表格中的一个列(column),类似于一维数组,可以保存任何数据类型。
DataFrame 是 Pandas 中的另一个核心数据结构,用于表示二维表格型数据。
DataFrame 是一个表格型的数据结构,它含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔型值)。
目录
转换数据类型:使用 astype 方法将 Series 转换为另一种数据类型:
Series 特点:
-
一维数组:Series是一维的,这意味着它只有一个轴(或维度),类似于 Python 中的列表。
-
索引: 每个
Series都有一个索引,它可以是整数、字符串、日期等类型。如果不指定索引,Pandas 将默认创建一个从 0 开始的整数索引。 -
数据类型:
Series可以容纳不同数据类型的元素,包括整数、浮点数、字符串、Python 对象等。 -
大小不变性:Series 的大小在创建后是不变的,但可以通过某些操作(如 append 或 delete)来改变。
-
操作:Series 支持各种操作,如数学运算、统计分析、字符串处理等。
-
缺失数据:Series 可以包含缺失数据,Pandas 使用NaN(Not a Number)来表示缺失或无值。
实例1:
import pandas as pd
mydataset={
'sites':['Google','Runoob','wiki'],
'number':[1,2,3]
}
myvar=pd.DataFrmae(mydataset)
print(myvar)运行结果:

实例2:
import pandas as pd
a=[1,2,3]
myvar=pd.Series(a,index=[1,2,3],name="RUNOOB-Series-TEST")
print(myvar)运行结果:
下面出现了name:参数,和数据类型

基本操作:
import pandas as pd
s=pd.Series([1,2,3,4],index=['a','b','c','d'])
print(s['a'])#返回‘a’对应的元素
s['a']=10
print(s['a'])#把‘a’里面的元素改为10
del s['a']#删除‘a’的元素使用布尔表达式:根据条件过滤 Series:
import pandas as pd
s=pd.Series([1,2,3,4],index=['a','b','c','d'])
print(s>2)

返回了布尔类型
转换数据类型:使用 astype 方法将 Series 转换为另一种数据类型:
import pandas as pd
s=pd.Series([1,2,3,4],index=['a','b','c','d'])
s=s.astype('float64')
print(s)
注意事项:
Series中的数据是有序的。- 可以将
Series视为带有索引的一维数组。 - 索引可以是唯一的,但不是必须的。
- 数据可以是标量、列表、NumPy 数组等。
DataFrame 特点:
-
二维结构:
DataFrame是一个二维表格,可以被看作是一个 Excel 电子表格或 SQL 表,具有行和列。可以将其视为多个Series对象组成的字典。 -
列的数据类型: 不同的列可以包含不同的数据类型,例如整数、浮点数、字符串或 Python 对象等。
-
索引:
DataFrame可以拥有行索引和列索引,类似于 Excel 中的行号和列标。 -
大小可变:可以添加和删除列,类似于 Python 中的字典。
-
自动对齐:在进行算术运算或数据对齐操作时,
DataFrame会自动对齐索引。 -
处理缺失数据:
DataFrame可以包含缺失数据,Pandas 使用NaN(Not a Number)来表示。 -
数据操作:支持数据切片、索引、子集分割等操作。
-
时间序列支持:
DataFrame对时间序列数据有特别的支持,可以轻松地进行时间数据的切片、索引和操作。 -
丰富的数据访问功能:通过
.loc、.iloc和.query()方法,可以灵活地访问和筛选数据。
..............

实例1:
import pandas as pd
data=[['Google',10],['Runoob',12],['Wiki',13]]
df=pd.DataFrame(data,columns=['Site','Age'])
df['Site']=df['Site'].astype(str)
df['Age']=df['Age'].astype(float)
print(df)运行结果:

实例2:
import pandas as pd
import numpy as np
ndarray_data=np.array([
['Google',10],
['Runoob',12],
['Wiki',13]
])
df=pd.DataFrame(ndarray_data,columns=['Site','Age'])
print(df)运行结果:
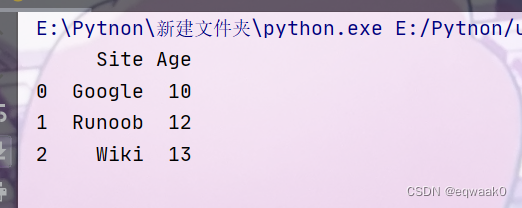
实例3:
import pandas as pd
data=[{'a':1,'b':2},{'a':5,'b':10,'c':20}]
df=pd.DataFrame(data)
print(df)
无值的地方变为NaN

实例4:
import pandas as pd
import numpy as np
import pandas
data = {
"calories": [420, 380, 390],
"duration": [50, 40, 45]
}
df=pd.DataFrame(data)
print(df.loc[0])
print(df.loc[1])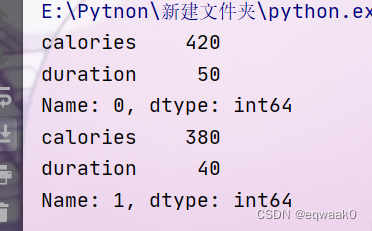
基本操作:
创建 DataFrame:
从字典创建:字典的键成为列名,值成为列数据。
import pandas as pd
# 通过字典创建 DataFrame
df = pd.DataFrame({'Column1': [1, 2, 3], 'Column2': [4, 5, 6]})从列表的列表创建:外层列表代表行,内层列表代表列。
# 通过列表的列表创建 DataFrame
df = pd.DataFrame([[1, 2, 3], [4, 5, 6], [7, 8, 9]],
columns=['Column1', 'Column2', 'Column3'])从 NumPy 数组创建:提供一个二维 NumPy 数组。
import numpy as np
# 通过 NumPy 数组创建 DataFrame
df = pd.DataFrame(np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]]))从 Series 创建 DataFrame:通过 pd.Series() 创建。
# 从 Series 创建 DataFrame
s1 = pd.Series(['Alice', 'Bob', 'Charlie'])
s2 = pd.Series([25, 30, 35])
s3 = pd.Series(['New York', 'Los Angeles', 'Chicago'])
df = pd.DataFrame({'Name': s1, 'Age': s2, 'City': s3})注意事项
DataFrame是一种灵活的数据结构,可以容纳不同数据类型的列。- 列名和行索引可以是字符串、整数等。
DataFrame可以通过多种方式进行数据选择、过滤、修改和分析。- 通过对
DataFrame的操作,可以进行数据清洗、转换、分析和可视化等工作。

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











