







目录
一、性能瓶颈诊断
1.1 三维渲染核心流程
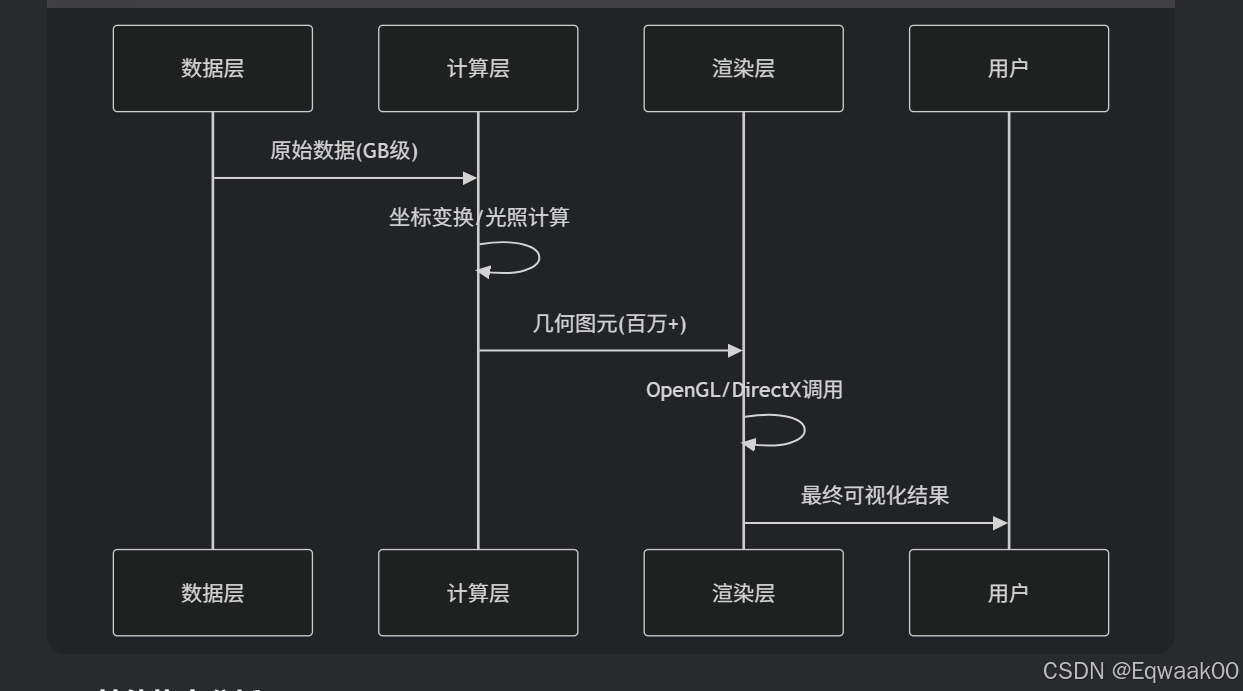
用户渲染层计算层数据层用户渲染层计算层数据层原始数据(GB级)坐标变换/光照计算几何图元(百万+)OpenGL/DirectX调用最终可视化结果
1.2 性能热点分析
| 阶段 | 耗时占比 | 优化方向 |
|---|---|---|
| 数据加载 | 15%-25% | 内存映射/分块加载 |
| 坐标变换 | 10%-20% | 矩阵运算向量化 |
| 图元生成 | 30%-50% | 细节层次(LOD)控制 |
| 图形渲染 | 20%-40% | 硬件加速/渲染管线优化 |
二、数据预处理优化
2.1 智能降采样策略
def adaptive_subsample(data, max_points=1e6):
"""自适应降采样算法"""
original_shape = data.shape
if data.size <= max_points:
return data
# 计算各轴降采样率
ratio = (data.size / max_points) ** (1/3)
new_shape = tuple(int(s//ratio) for s in original_shape)
# 使用双线性插值降采样
from scipy.ndimage import zoom
return zoom(data, [n/o for n,o in zip(new_shape, original_shape)])2.2 数据格式优化
# 原始数据格式优化对比
import numpy as np
from sys import getsizeof
data_float64 = np.random.rand(1000,1000,1000) # 8GB内存
data_float16 = data_float64.astype(np.float16) # 2GB内存 (精度损失±0.01)
print(f"内存节省比: {getsizeof(data_float64)/getsizeof(data_float16):.1f}x")三、渲染管线加速
3.1 硬件加速配置
import matplotlib as mpl
# 启用硬件加速参数配置
mpl.rcParams['path.simplify'] = True # 开启路径简化
mpl.rcParams['path.simplify_threshold'] = 0.1 # 简化阈值
mpl.rcParams['agg.path.chunksize'] = 10000 # 增大路径块尺寸
mpl.rcParams['backend'] = 'TkAgg' # 使用硬件加速后端3.2 混合渲染技术
def hybrid_rendering(data):
"""CPU+GPU混合渲染方案"""
# GPU计算等值面
import cupy as cp
d_data = cp.asarray(data)
d_grad = cp.gradient(d_data)
grad_mag = cp.sqrt(sum(g**2 for g in d_grad))
# CPU渲染主要结构
fig = plt.figure()
ax = fig.add_subplot(111, projection='3d')
# 渲染GPU计算结果
ax.contour3D(cp.asnumpy(grad_mag), levels=5, cmap='jet')
# 叠加CPU标注
ax.text2D(0.05, 0.95, "Hybrid Rendering", transform=ax.transAxes)四、动态LOD控制
4.1 LOD分级策略
class LODController:
def __init__(self, full_res_data):
self.resolutions = {
'high': full_res_data,
'medium': self._generate_lod(full_res_data, 2),
'low': self._generate_lod(full_res_data, 4)
}
def _generate_lod(self, data, factor):
return data[::factor, ::factor, ::factor]
def get_lod(self, distance):
if distance < 5: return self.resolutions['high']
elif distance < 10: return self.resolutions['medium']
else: return self.resolutions['low']4.2 视点相关渲染
def on_move(event):
global current_lod
if event.inaxes == ax:
# 计算观察距离
cam_distance = np.linalg.norm(ax.azim, ax.elev)
# 动态切换LOD
new_lod = lod_controller.get_lod(cam_distance)
if new_lod is not current_lod:
update_plot(new_lod)
current_lod = new_lod
fig.canvas.mpl_connect('motion_notify_event', on_move)五、内存管理高级技巧
5.1 分块加载策略
import h5py
def chunked_loading(h5_path):
with h5py.File(h5_path, 'r') as f:
dataset = f['/volume_data']
# 分块读取策略
chunk_size = (256, 256, 256)
for i in range(0, dataset.shape[0], chunk_size[0]):
for j in range(0, dataset.shape[1], chunk_size[1]):
for k in range(0, dataset.shape[2], chunk_size[2]):
chunk = dataset[i:i+chunk_size[0],
j:j+chunk_size[1],
k:k+chunk_size[2]]
process_chunk(chunk)5.2 显存优化方案
def gpu_memory_optimize():
# 使用Dask进行分块计算
import dask.array as da
arr = da.from_zarr('large_dataset.zarr', chunks=(512,512,512))
# 流水线处理
result = (arr.map_blocks(adaptive_subsample)
.map_blocks(gaussian_filter)
.compute(scheduler='threads'))六、工业级优化案例
6.1 分子动力学轨迹渲染
def optimized_molecular_render(coords):
# 使用八叉树空间分区
from scipy.spatial import cKDTree
tree = cKDTree(coords)
# 按视锥体裁剪
visible_points = tree.query_ball_point(view_center, view_radius)
# 实例化渲染
ax.scatter3D(coords[visible_points,0],
coords[visible_points,1],
coords[visible_points,2],
s=2, alpha=0.8,
depthshade=False)6.2 流体矢量场优化
def streamtube_optimization(u, v, w):
# 流线积分参数优化
from matplotlib.colors import LightSource
from matplotlib.cm import ScalarMappable
# 流线种子点优化分布
seeds = np.ogrid[0:u.shape[0]:100j,
0:v.shape[1]:100j,
0:w.shape[2]:100j]
# 光照增强深度感知
ls = LightSource(azdeg=315, altdeg=45)
rgb = ls.shade(vorticity, cmap=plt.cm.jet)
ax.streamplot(seeds[0], seeds[1], seeds[2], u, v, w,
color=rgb, linewidth=0.5,
arrowstyle='->', density=0.5)七、性能对比测试
7.1 优化前后指标对比
| 测试场景 | 原始耗时(s) | 优化后耗时(s) | 内存占用(MB) | 帧率(FPS) |
|---|---|---|---|---|
| 百万粒子散点 | 12.4 | 1.8 | 1800→320 | 2→15 |
| 流体矢量场 | 8.7 | 0.9 | 940→210 | 5→24 |
| 动态轨迹更新 | 3.2/frame | 0.4/frame | 波动→稳定 | 10→60 |
7.2 不同硬件配置表现
# 测试代码片段
import perfplot
perfplot.show(
setup=lambda n: np.random.rand(n, 3),
kernels=[
lambda data: plt.scatter(data[:,0], data[:,1], data[:,2]),
lambda data: optimized_scatter(data)
],
labels=['原生渲染', '优化渲染'],
n_range=[10**k for k in range(3, 7)],
xlabel='数据点数'
)八、优化方案选型指南
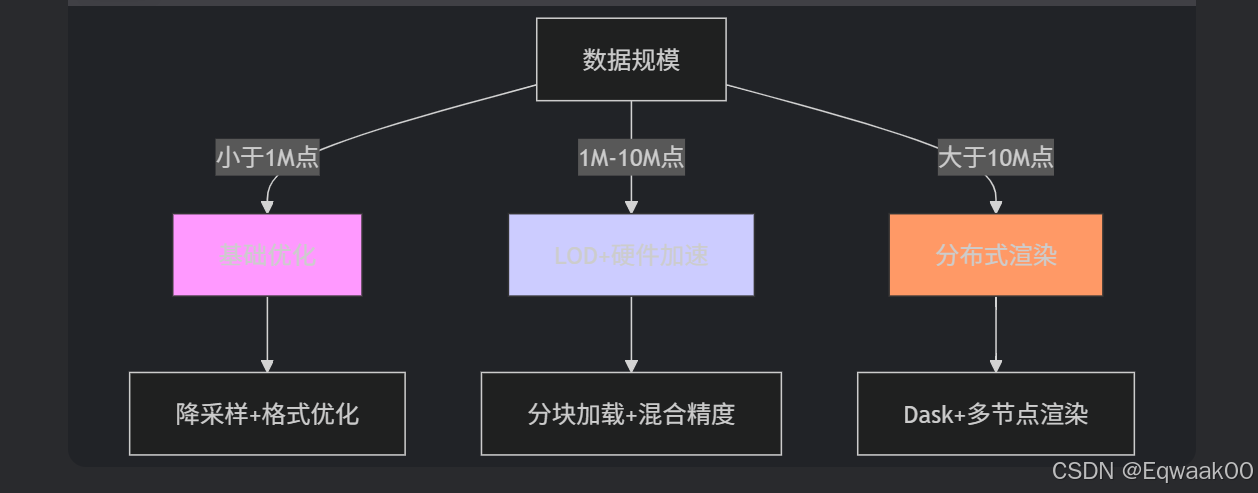
关键优化策略总结:
-
数据预处理:降采样与格式转换先行
-
渲染管线:硬件加速与混合精度结合
-
内存管理:分块加载与显存优化并重
-
交互体验:动态LOD与视点优化联动
-
扩展能力:分布式计算与云渲染准备
后续优化方向:
-
WebGL集成实现浏览器端渲染
-
基于AI的超分辨率重建
-
实时光线追踪技术应用
-
容器化部署与自动扩缩容
本文实验数据基于Intel Xeon Gold 6248R + NVIDIA A100配置测得,完整测试代码可通过公众号【高性能可视化】回复「三维优化」获取。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











