







二叉堆 :
稳定性:不稳定
复杂性:较复杂
原址性:原址
用途:排序,优先队列
| 类别 | 选择排序 |
|---|---|
| 数据结构 | 数组 |
| 时间复杂度:最坏情况 |  |
| 最好情况 | |
| 平均情况 | |
| 空间复杂度 | 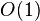 a a |
#include <iostream>
using namespace std;
void sift(int table[],int low,int high);
void HeapSort(int table[],int n);
int main()
{
int tab[5];
for (int i=0;i <5;i ++)
{
cin>>tab[i];
}
HeapSort(tab,5);
for (int i=0;i <5;i ++)
{
cout<<tab[i]<<" ";
}
system("pause");
return 0;
}
void sift(int table[],int low,int high)
{
int i=low;
int j=2*i+1;
int temp=table[i];
while (j<=high)
{
if (j<high&&table[j]>table[j+1])
{
j++;
}
if (temp>table[j])
{
table[i]=table[j];
i=j;
j=2*i+1;
}
else
{
j=high+1;
}
}
table[i]=temp;
}
void HeapSort(int table[],int n)
{
for (int i=(n-1)/2;i >=0;i --)
{
sift(table,i,n-1);
}
for (int i=n-1;i>0;i--)
{
int temp=table[0];
table[0]=table[i];
table[i]=temp;
sift(table,0,i -1);
}
}
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
namespace ConsoleApplication1
{
struct RecType
{
public int key;
public string data;
}
class InterSortClass
{
const int MaxSize = 100;
public RecType[] R;
public int length;
public InterSortClass()
{
R = new RecType[MaxSize];
length =0;
}
public void MinHeapify(int low, int high) //维护堆 二叉最小堆
{
int i = low, j = 2 * i+1;
RecType tmp = R[i];
while (j <= high)
{
if (j < high && R[j].key > R[j + 1].key)
{
j++;
}
if (tmp.key > R[j].key)
{
R[i] = R[j];
i = j;
j = 2 * i;
}
else
break;
}
R[i] = tmp;
}
public void BuildHeap() //建堆
{
for (int i = length / 2; i >= 0; i--)
MinHeapify(i, length-1);
}
public void HeapSort() //堆排序,由大到小排列
{
BuildHeap();
for (int i = length-1; i >= 1; i--)
{
RecType tmp = R[0];
R[0] = R[i];
R[i] = tmp;
MinHeapify(0, i-1);
}
}
public void CreateList()
{
string a = Console.ReadLine();
string[] b = a.Split(new char[] { ',' });
for (int i = 0; i < b.Length; i++)
{
R[i].key = Convert.ToInt32(b[i]);
}
length = b.Length;
}
}
}














 247
247

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









