







三、Slope One协同过滤
1、Slope One原理
为了大大减少过适(过拟合)的发生,提升算法简化实现, Slope One 系列易实现的Item-based协同过滤算法被提了出来。本质上,该方法运用更简单形式的回归表达式( ) 和单一的自由参数,而不是一个项目评分和另一个项目评分间的线性回归 (
) 和单一的自由参数,而不是一个项目评分和另一个项目评分间的线性回归 (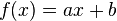 )。 该自由参数只不过就是两个项目评分间的平均差值。甚至在某些实例当中,它比线性回归的方法更准确[2],而且该算法只需要一半(甚至更少)的存储量。
)。 该自由参数只不过就是两个项目评分间的平均差值。甚至在某些实例当中,它比线性回归的方法更准确[2],而且该算法只需要一半(甚至更少)的存储量。

例:
- User A 对 Item I 评分为1 对Item J.评分为1.5
- User B 对 Item I 评分为2.
- 你认为 User B 会给 Item J 打几分?
- Slope One 的答案是:2.5 (1.5-1+2=2.5).
举个更实际的例子,考虑下表:
| 顾客 | 项目 1 | 项目 2 | 项目 3 |
|---|---|---|---|
| John | 5 | 3 | 2 |
| Mark | 3 | 4 | 未评分 |
| Lucy | 未评分 | 2 | 5 |
在本例中,项目2和1之间的平均评分差值为 (2+(-1))/2=0.5. 因此,item1的评分平均比item2高0.5。同样的,项目3和1之间的平均评分差值为3。因此,如果我们试图根据Lucy 对项目2的评分来预测她对项目1的评分的时候,我们可以得到 2+0.5 = 2.5。同样,如果我们想要根据她对项目3的评分来预测她对项目1的评分的话,我们得到 5+3=8.
如果一个用户已经评价了一些项目,可以这样做出预测:简单地把各个项目的预测通过加权平均值结合起来。当用户两个项目都评价过的时候,权值就高。在 上面的例子中,项目1和项目2都评价了的用户数为2,项目1和项目3 都评价了的用户数为1,因此权重分别为2和1. 我们可以这样预测Lucy对项目1的评价:
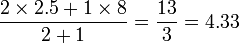 于是,对“n”个项目,想要实现 Slope One,只需要计算并存储“n”对评分间的平均差值和评价数目即可。
于是,对“n”个项目,想要实现 Slope One,只需要计算并存储“n”对评分间的平均差值和评价数目即可。
2、mahout对Slope One的实现
调用代码很简单:
//In-Memory Recommender DiffStorage diffStorage = new MemoryDiffStorage(model, Weighting.UNWEIGHTED, false, Long.MAX_VALUE)); Recommender recommender = new SlopeOneRecommender(model, Weighting.UNWEIGHTED, Weighting.UNWEIGHTED, diffStorage); //Database-based Recommender AbstractJDBCDataModel model = new MySQLJDBCDataModel(); DiffStorage diffStorage = new MySQLJDBCDiffStorage(model); Recommender recommender = new SlopeOneRecommender(model, Weighting.WEIGHTED, Weighting.WEIGHTED, diffStorage);
下边详细的分析代码
先看SlopeOneRecommender的主要功能函数:
@Override
public List<RecommendedItem> recommend(long userID, int howMany, IDRescorer rescorer) throws TasteException {
Preconditions.checkArgument(howMany >= 1, "howMany must be at least 1");
log.debug("Recommending items for user ID '{}'", userID);
//先得到在DiffStorage中的分差计算中,所有计算到的物品列表
//在这个列表中再将userID用户评过分的物品去掉,得到可能的物品列表
FastIDSet possibleItemIDs = diffStorage.getRecommendableItemIDs(userID);
//又是一个评估器
TopItems.Estimator<Long> estimator = new Estimator(userID);
//最后是获取得分最高的howMany个item
List<RecommendedItem> topItems = TopItems.getTopItems(howMany, possibleItemIDs.iterator(), rescorer,
estimator);
log.debug("Recommendations are: {}", topItems);
return topItems;
}
1、计算物品间平均分差
DiffStorage接口类,这里以MemoryDiffStorage为例分析,这个类的主要作用是对源数据进行处理,计算出每一个物品对其他物品的平均分差:
//
private void buildAverageDiffs() throws TasteException {
log.info("Building average diffs...");
try {
buildAverageDiffsLock.writeLock().lock();
averageDiffs.clear();
long averageCount = 0L;
//获取数据源中的所有用户
LongPrimitiveIterator it = dataModel.getUserIDs();
while (it.hasNext()) {
//对每一个用户进行分析,计算物品间的分差
averageCount = processOneUser(averageCount, it.nextLong());
}
pruneInconsequentialDiffs();
updateAllRecommendableItems();
} finally {
buildAverageDiffsLock.writeLock().unlock();
}
}
具体计算平均分差的函数为processOneUser() :
其中 RunningAverage是一个存储平均分差和统计分差个数的类
//这个类一是计算各物品间的平均分差,二是统计各物品的平均得分
private long processOneUser(long averageCount, long userID) throws TasteException {
log.debug("Processing prefs for user {}", userID);
// Save off prefs for the life of this loop iteration
PreferenceArray userPreferences = dataModel.getPreferencesFromUser(userID);
int length = userPreferences.length();
for (int i = 0; i < length - 1; i++) {
float prefAValue = userPreferences.getValue(i);//评分
long itemIDA = userPreferences.getItemID(i);//物品id
//获取tiemIDA物品与其他物品的评分差Map(key是itemID,value是平均分差)
FastByIDMap<RunningAverage> aMap = averageDiffs.get(itemIDA);
if (aMap == null) {
aMap = new FastByIDMap<RunningAverage>();
averageDiffs.put(itemIDA, aMap);
}
//itemIDA物品对物品列表中排位于自己之后的所有物品计算评分差,并逐个加入到RunningAverage中
for (int j = i + 1; j < length; j++) {
// This is a performance-critical block
long itemIDB = userPreferences.getItemID(j);
RunningAverage average = aMap.get(itemIDB);//获取itemIDA对itemIDB的平均分差类
if (average == null && averageCount < maxEntries) {
average = buildRunningAverage();
aMap.put(itemIDB, average);
averageCount++;
}
if (average != null) {
average.addDatum(userPreferences.getValue(j) - prefAValue);
}
}
//averageItemPref是个Map(key是itemID,value是该物品的平均得分)
//计算itemIDA的平均得分
RunningAverage itemAverage = averageItemPref.get(itemIDA);
if (itemAverage == null) {
itemAverage = buildRunningAverage();
averageItemPref.put(itemIDA, itemAverage);
}
itemAverage.addDatum(prefAValue);
}
return averageCount;
}
2、评估器Estimator
对于userID的用户,给定某个itemID的物品,要想获得此物品的评估分的话,首先获取itemID与userID用户所评价过的所有的物品之间的平均评分差,然后逐个加权,然后再取平均值,这个平均值就是itemID的评估分
private final class Estimator implements TopItems.Estimator<Long> {
@Override
public double estimate(Long itemID) throws TasteException {
return doEstimatePreference(userID, itemID);
}
}
private float doEstimatePreference(long userID, long itemID) throws TasteException {
double count = 0.0;
double totalPreference = 0.0;
PreferenceArray prefs = getDataModel().getPreferencesFromUser(userID);
//获取itemID与userID用户所评价过的所有的物品之间的 平均评分差
RunningAverage[] averages = diffStorage.getDiffs(userID, itemID, prefs);
int size = prefs.length();
//将userID用户所评价过的物品与itemID物品之间的平均评分差,逐个加权(加权之前还要加上该评价过物品的得分)
//然后再取平均值,这个平均值就是itemID的评估分
for (int i = 0; i < size; i++) {
RunningAverage averageDiff = averages[i];
if (averageDiff != null) {
double averageDiffValue = averageDiff.getAverage();
if (weighted) {
double weight = averageDiff.getCount();
if (stdDevWeighted) {
double stdev = ((RunningAverageAndStdDev) averageDiff).getStandardDeviation();
if (!Double.isNaN(stdev)) {
weight /= 1.0 + stdev;
}
}
//加权(weight),权值就是参与RunningAverage的个数,其实就是同时对这两个物品进行过评价的用户个数
totalPreference += weight * (prefs.getValue(i) + averageDiffValue);
count += weight;
} else {
totalPreference += prefs.getValue(i) + averageDiffValue;
count += 1.0;
}
}
}
if (count <= 0.0) {
RunningAverage itemAverage = diffStorage.getAverageItemPref(itemID);
return itemAverage == null ? Float.NaN : (float) itemAverage.getAverage();
} else {
return (float) (totalPreference / count);
}
}
3、获取得分最高的howMany个item
跟物品CF和用户CF一样,最后一步都是调用TopItems.getTopItems()
public static List<RecommendedItem> getTopItems(int howMany,
LongPrimitiveIterator possibleItemIDs,
IDRescorer rescorer,
Estimator<Long> estimator) throws TasteException {
Preconditions.checkArgument(possibleItemIDs != null, "argument is null");
Preconditions.checkArgument(estimator != null, "argument is null");
Queue<RecommendedItem> topItems = new PriorityQueue<RecommendedItem>(howMany + 1,
Collections.reverseOrder(ByValueRecommendedItemComparator.getInstance()));
boolean full = false;
double lowestTopValue = Double.NEGATIVE_INFINITY;
while (possibleItemIDs.hasNext()) {
long itemID = possibleItemIDs.next();
if (rescorer == null || !rescorer.isFiltered(itemID)) {
double preference;
try {
//得到该item的平均得分作为user的预测评分
preference = estimator.estimate(itemID);
} catch (NoSuchItemException nsie) {
continue;
}
double rescoredPref = rescorer == null ? preference : rescorer.rescore(itemID, preference);
if (!Double.isNaN(rescoredPref) && (!full || rescoredPref > lowestTopValue)) {
topItems.add(new GenericRecommendedItem(itemID, (float) rescoredPref));
if (full) {
topItems.poll();
} else if (topItems.size() > howMany) {
full = true;
topItems.poll();
}
lowestTopValue = topItems.peek().getValue();
}
}
}
int size = topItems.size();
if (size == 0) {
return Collections.emptyList();
}
List<RecommendedItem> result = Lists.newArrayListWithCapacity(size);
result.addAll(topItems);
Collections.sort(result, ByValueRecommendedItemComparator.getInstance());
return result;
}
最后加上几句从别人文章中抄过来的话:
其实Slope one推荐算法很流行,被很多网站使用,包括一些大型网站;我个人认为最主要的原因是它具备如下优势:
1. 实现简单并且易于维护。
2. 响应即时(只要用户做出一次评分,它就能有效推荐,根据上面代码很容易理解),并且用户的新增评分对推荐数据的改变量较小,应为在内存中存储的是物品间的平均差值,新增的差值只需累加一下,切范围是用户评分过的产品。
3. 由于是基于项目的协同过滤算法,适用于当下火热的电子商务网站,原因电子商务网站用户量在几十万到上百万,产品量相对于之则要小得多,所以对产品归类从性能上讲很高效。















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









