









假设我们有一个表Student,包括以下字段与数据:
- drop table student;
- create table student
- (
- id int primary key,
- name nvarchar2(50) not null,
- score number not null
- );
- insert into student values(1,'Aaron',78);
- insert into student values(2,'Bill',76);
- insert into student values(3,'Cindy',89);
- insert into student values(4,'Damon',90);
- insert into student values(5,'Ella',73);
- insert into student values(6,'Frado',61);
- insert into student values(7,'Gill',99);
- insert into student values(8,'Hellen',56);
- insert into student values(9,'Ivan',93);
- insert into student values(10,'Jay',90);
- commit;
首先,我们来看一下UNION的例子:
- SQL> select *
- 2 from student
- 3 where id<4
- 4 union
- 5 select *
- 6 from student
- 7 where id>2 and id<6
- 8 ;
- ID NAME SCORE
- ---------- ------------------------------ ----------
- 1 Aaron 78
- 2 Bill 76
- 3 Cindy 89
- 4 Damon 90
- 5 Ella 73
- SQL>
如果换成Union All连接两个结果集,则结果如下:
- SQL> select *
- 2 from student
- 3 where id<4
- 4 union all
- 5 select *
- 6 from student
- 7 where id>2 and id<6
- 8 ;
- ID NAME SCORE
- ---------- ------------------------------ ----------
- 1 Aaron 78
- 2 Bill 76
- 3 Cindy 89
- 3 Cindy 89
- 4 Damon 90
- 5 Ella 73
- 6 rows selected.
可以看到,Union和Union All的区别之一在于对重复结果的处理。
接下来,我们交换一个两个SELECT语句的顺序,看看结果是怎样的。
- SQL> select *
- 2 from student
- 3 where id>2 and id<6
- 4 union
- 5 select *
- 6 from student
- 7 where id<4
- 8 ;
- ID NAME SCORE
- ---------- ------------------------------ ----------
- 1 Aaron 78
- 2 Bill 76
- 3 Cindy 89
- 4 Damon 90
- 5 Ella 73
- SQL> select *
- 2 from student
- 3 where id>2 and id<6
- 4 union all
- 5 select *
- 6 from student
- 7 where id<4
- 8 ;
- ID NAME SCORE
- ---------- ------------------------------ ----------
- 3 Cindy 89
- 4 Damon 90
- 5 Ella 73
- 1 Aaron 78
- 2 Bill 76
- 3 Cindy 89
- 6 rows selected.
可以看到,对于UNION来说,交换两个SELECT语句的顺序后结果仍然是一样的,这是因为UNION会自动排序。而UNION ALL在交换了SELECT语句的顺序后结果则不相同,因为UNION ALL不会对结果自动进行排序。
那么这个自动排序的规则是什么呢?我们交换一下SELECT后面选择字段的顺序(前面使用SELECT *相当于SELECT ID,NAME,SCORE),看看结果如何:
- SQL> select score,id,name
- 2 from student
- 3 where id<4
- 4 union
- 5 select score,id,name
- 6 from student
- 7 where id>2 and id<6
- 8 ;
- SCORE ID NAME
- ---------- ---------- ------------------------------
- 73 5 Ella
- 76 2 Bill
- 78 1 Aaron
- 89 3 Cindy
- 90 4 Damon
可是看到,此时是按照字段SCORE来对结果进行排序的(前面SELECT *的时候是按照ID进行排序的)。
那么有人会问,如果我想自行控制排序,能不能使用ORDER BY呢?当然可以。不过在写法上有需要注意的地方:
- select score,id,name
- from student
- where id > 2 and id < 7
- union
- select score,id,name
- from student
- where id < 4
- union
- select score,id,name
- from student
- where id > 8
- order by id desc
order by子句必须写在最后一个结果集里,并且其排序规则将改变操作后的排序结果。对于Union、Union All、Intersect、Minus都有效。
其他的集合操作符,如Intersect和Minus的操作和Union基本一致,这里一起总结一下:
Union,对两个结果集进行并集操作,不包括重复行,同时进行默认规则的排序;
Union All,对两个结果集进行并集操作,包括重复行,不进行排序;
Intersect,对两个结果集进行交集操作,不包括重复行,同时进行默认规则的排序;
Minus,对两个结果集进行差操作,不包括重复行,同时进行默认规则的排序。
可以在最后一个结果集中指定Order by子句改变排序方式。
原文地址:http://blog.csdn.net/wanghai__/article/details/4712555/
自己理解
可能存在问题:
当查询的第一个字段不是数字的时候,排序会有问题。union的自动排序规则,有待进一步学习。
我是在MySQL数据库中测试的
测试数据表和数据
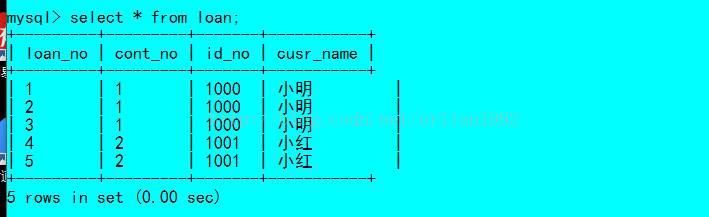
使用
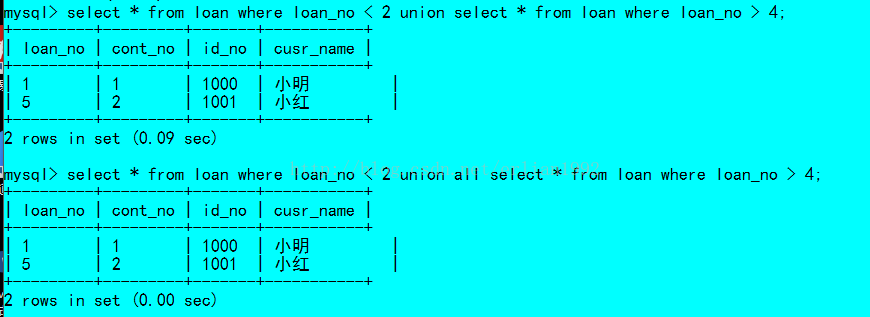
调换顺序

从上面测试的结果来看,第一个字段是varchar类型,但是不管是使用union还是union all都是没有差别的。
如果非要排序就要使用order by子句了


















 1129
1129

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









