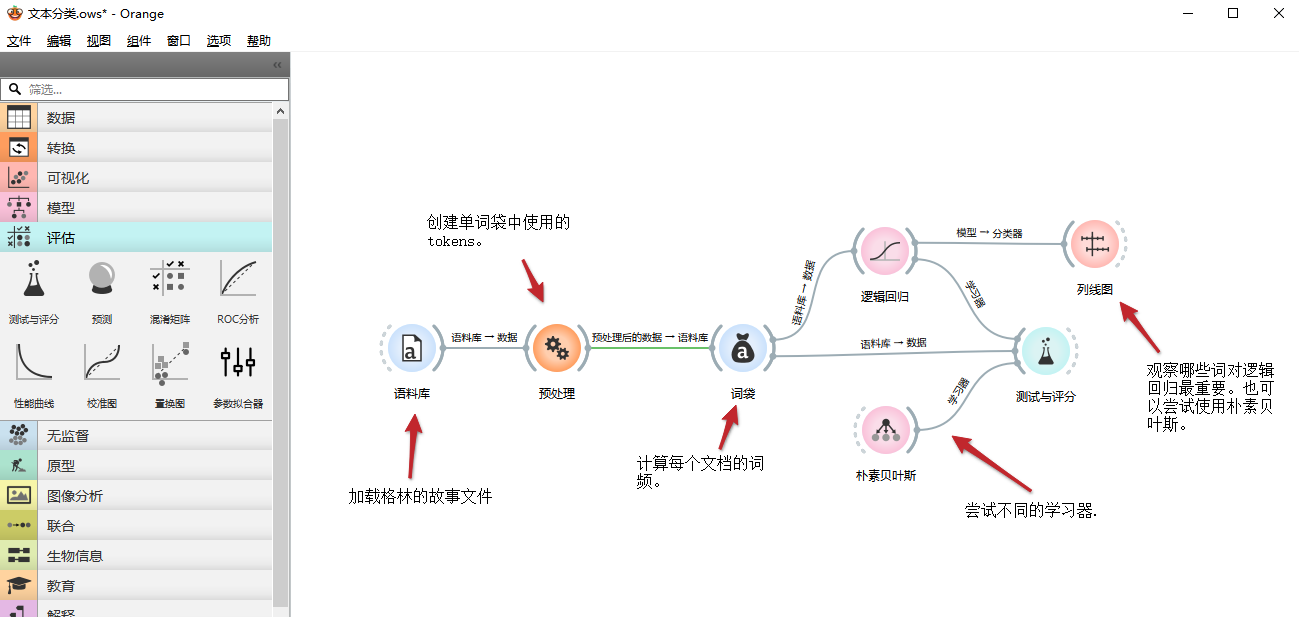
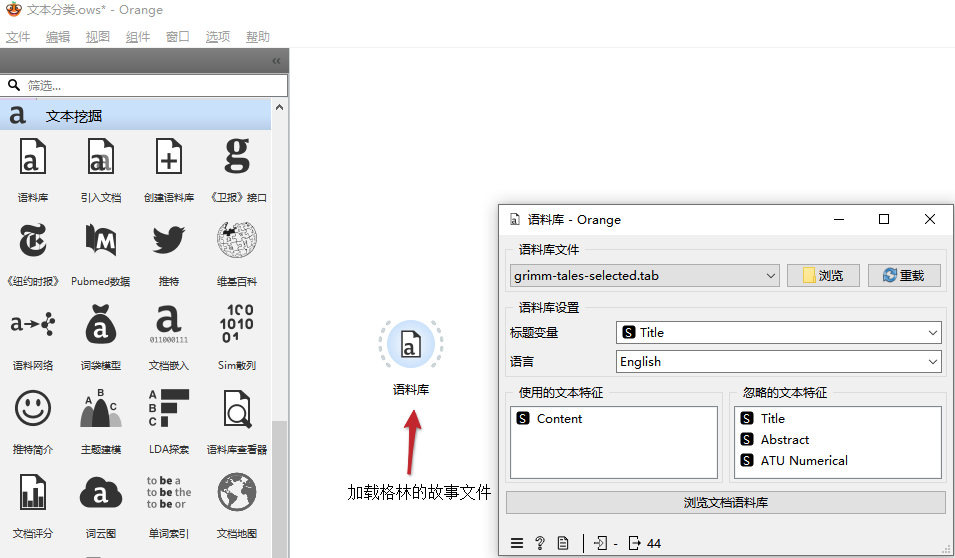
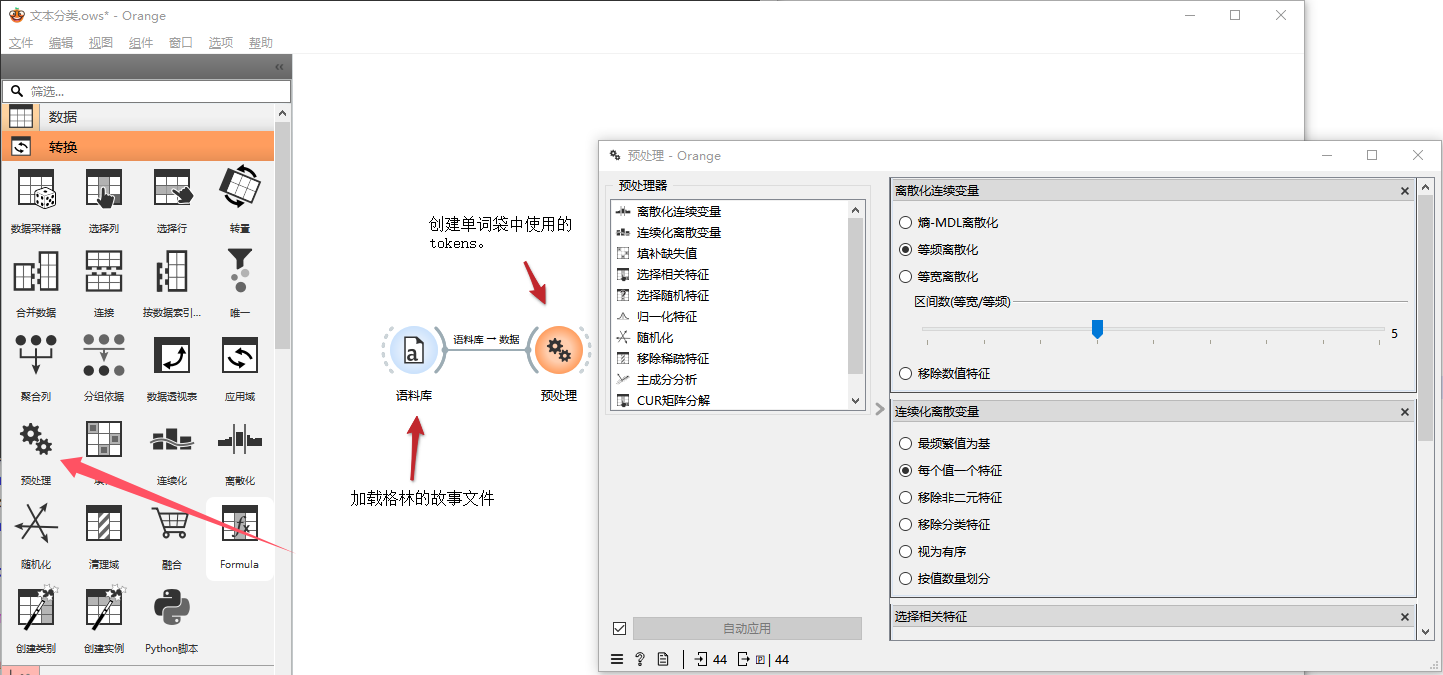
文本分类 我们可以使用预测模型按作者、类型、情感等对文档进行分类。在此工作流中,我们根据文档的Aarne Thompshon Uther索引对文档进行归类,这是故事的主题定义。我们使用两个简单的学习器,Logistic回归和朴素贝叶斯,两者都可以在诺谟图中检查。 完整的流程如下: 步骤1:加载文件 在文本挖掘分类中找到语料库组件,拖动工作台,并加载格林的故事文件: 步骤2:预处理 拖动转换分类里的预处理组件并连接,创建词袋的tokens: 步骤3:词袋模型








 超级会员免费看
超级会员免费看

 订阅专栏 解锁全文
订阅专栏 解锁全文




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


 被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言
被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言








