







目录
本文大多内容来自深度好文: 这儿。
一 概念
正则表达式(Regular Expression)是用于描述一组字符串特征的模式,用来匹配特定的字符串,能够大幅提高处理效率。通过特殊字符+普通字符来进行模式描述,从而达到文本匹配目的工具。主要使用 grep 和 notepad++ 来验证。
二 基本要素
(1)字符类;(2)数量限定符;(3)位置限定符;(4)特殊符号。
三 正则表达式()、[]、{}的区别
正则表达式的 ()、[]、{} 有着不同的意思。
() 是为了提取匹配字符串的,表达式中有几个()就有几个相应的匹配字符串,(\s*)表示连续空格的字符串;圆括号()是组,主要应用在限制多选结构的范围/分组/捕获文本/环视/特殊模式处理。
[] 是定义匹配的字符范围。比如[a-zA-Z0-9]表示相应位置的字符要匹配英文字符和数字。[\s*表示空格或者*号];
{}一般是用来匹配的长度。比如\s{3}表示匹配三个空格,\s[1,3]表示匹配1到3个空格;
(0-9)匹配’0-9’本身。[0-9]*匹配数字(注意后面有*,可以为空)[0-9]+匹配数字(注意后面有+,不可以为空),{0-9}写法是错误的,
[0-9]{0,9}表示长度为0到9的数字字符串。
示例:
1(abc|bcd|cde),表示这一段是abc、bcd、cde三者之一,顺序也必须一致;
2、(abc)? 表示这一组要么一起出现,要么不出现,出现那则按顺序出现;
3、(?:abc)表示找到一样abc的一组,但是不记录,不保存到变量中,否则可以通过x取第几个括号所匹配道德项;
,比如:
(aaa)(bbb)(ccc)(?:ddd)(eee)可以用1获取(aaa)匹配到的内容,而3则获取到了(ccc)匹配到的内容,而$4则获取的是由(eee)
匹配到的内容,因为前一对括号没有保存变量
4.a(?=bbb)顺序环视 表示a后面必须紧跟3个连续的b
5、(?i:xxxx)不区分大小写 (?s:.*)跨行匹配,可以匹配回车符
方括号是单个匹配 字符集/排除字符集/命名字符集
示例:
1、[0-3],表示找到一个位置上的字符只能是0到3折四个数字,与(abc|bcd|cde)的作用比较类似,但圆括号可以匹配多个连续的字符
而一对方括号只能匹配单个字符
2、[^0-3] 表示找到这个位置上字符只能是除了0到3之外的所有字符
3、[:digit:] 0-9 [:alnum] A-Za-z0-9
()和[]有本质的区别
()内的内容表示的是一个表达式,()本身不匹配任何东西,也不惜那是匹配任何东西,只是把括号内的内容作为
同一个表达式来处理,例如(ab){1,3},就表示ab一起连续出现最少1次,最多三次。如果没有括号的话,ab{1,3},
就表示a 后面紧跟的b出现的最少一次,最多三次。另外,括号在匹配模式中也跟重要。这个就不延伸了。
[]表示匹配字符在[]中,兵出现一次,并且reshuffle字符写在[]会被当成普通字符来匹配,例如[(a)],会匹配(、a、)、这三个字符。
所以()[] 无论是作用还是表示的含义。都有天壤之别,没有什么联系。
四 字符类
1 [[:xxx:]],预定义的一些命名字符类
1、[[:alnum:]]:英文大小写字母和数字;
2、[[:alpha:]]:英文大小写字母;[:lower:]:小写;[:upper:]:大写;
3、[[:digit:]]:数字;
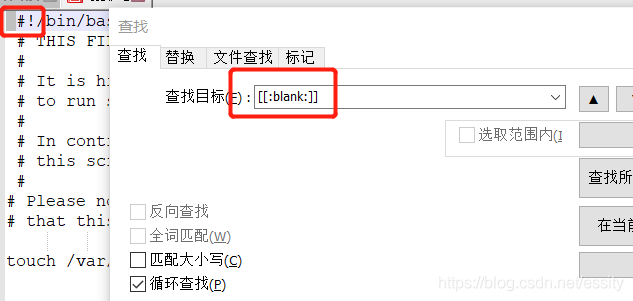
4、[[:blank:]]:空格,tab;[:space:]:任何会产生空白的字符:空格,tab,CR;
5、[[:graph:]]:除了空格和tab意外的任何字符,等同于^[:blank:];
6、[[:print:]]:任何可以打印的字符;
2 字符
| 字符 | 含义 | 举例 |
|---|---|---|
| . | 匹配除换行符\n之外的任意一个字符 | abc.可以匹配abcd或abc6等 |
| [] | 匹配括号中的任意一个字符 | [abc]可以匹配ad,bd,cd |
| - | 在[]内表示字符范围 | [0-9a-fA-F]可以匹配一位16进制数字 |
| [^] | 匹配除[]中的字符中的任意一个字符 | [^xy]1,可以匹配a1,b1,但是无法匹配x1,y1 |
| * | 代表0个或者多个重复字符 | 例如o*,代表0到n个o都可以匹配 |
| |转义字符 | \.表示.这个字符 | |
| .* | 表示任意多个任何字符,可以相当于shell中的通配符* | |
| [ | 标记一个中括号表达式的开始。 | |
| { | 标记限定表达式的开始。 | |
| 例如: | ||
 | ||
| 注意:1、grep采用的贪心匹配,它会匹配当前行中的所有匹配内容;2、echo $?表示是否匹配成功(如果成功返回值为0,不成功返回值为1)。 | ||
 | ||
 |
3 非打印字符
| 字符 | 含义 | 举例 |
|---|---|---|
| \cx | 匹配由x指明的控制字符。例如,\cM匹配一个Control-M或回车符。x的值必须为A-Z或a-z之一。否则,将c视为一个原意的‘c’字符。 | |
| \f | 匹配一个换页符。等价于\x0c和\cL。 | |
| \n | 匹配一个换行符。等价于\x0a和\cJ。 | |
| \r | 匹配一个回车符。等价于\x0d和\cM。 | |
| \s | 匹配任何空白字符,包括空格,制表符,换页符等等。等价于[\f\n\r\t\v] | |
| \S | 匹配任何非空白字符,等价于[^\f\n\r\t\v] | |
| \t | 匹配一个制表符,等价于\x09和\cl | |
| \v | 匹配一个垂直制表符,等价于\x0b和\cK |
4 数量限定符
| 字符 | 含义 | 举例 |
|---|---|---|
| ? | 匹配前面的子表达式零次或一次,或指明一个非贪婪限定式。 | [0-9]?\.[0-9]匹配0.0、1.7、.6等。 |
| + | 匹配前面的子表达式一次或多次。 | [a-zA-Z0-9.-]+@[a-zA-Z0-9.-]+\.[a-zA-Z0-9.-]+匹配email地址 |
| * | 紧跟在他前面的单元应匹配零次或多次 | [0-9][0-9]*匹配至少一位数字,等价与[0-9]+,[a-zA-Z_]+[a-zA-Z_0-9]*匹配C语音的标识符 |
| {N} | 紧跟在它前面的单元应精确匹配N次 | [0-9][0-9]{2}匹配100到999的整数 |
| {N,} | 紧跟在它前面的单元应匹配至少N次 | [0-9][0-9]{2,}匹配大于等于三位数的整数 |
| {,M} | 紧跟在它前面的单元应匹配最多M次 | [0-9]{,1}指最多匹配0-9之间的一个整数,相当于[0-9]? |
| {N,M} | 紧跟在它前面的单元应匹配至少N次,最多M次 | [0-9]{1, 3}\.[0-9]{1, 3}\.[0-9]{1, 3}\.[0-9]{1, 3}匹配IP地址 |
 | ||
 |
5 位置限定符
| 字符 | 含义 | 举例 |
|---|---|---|
| ^ | 表示行首的位置 | ^content匹配一行开头的content |
| $ | 表示行尾,如果设置了 | ;$匹配一行结尾的;,;$匹配空行 |
| < | 匹配单词开头的位置 | |
| > | 匹配单词结尾的位置 | |
| \b | 匹配一个字边界,即字与空格间的位置。 | |
| \B | 非字边界匹配 | |
 | ||
 |
6 特殊符号
| 字符 | 含义 | 举例 |
|---|---|---|
| () | 将正则表达式的一部分括起来组成一个单元,可以对整个单元使用数量限定符 | ([0-9]{1,3}\.){3}[0-9]{1, 3}匹配IP地址 |
| | | 连接两个子表达式,表示或的关系 | `n(o |
 |
7 其他普通字符及其替换
| 符号 | 替换正则 | 匹配 |
|---|---|---|
| \d | [0-9] | 数字字符 |
| \D | [^0-9] | 非数字字符 |
| \w | a-zA-Z0-9 | 数字字母下划线 |
| \W | [^\w] | 非数字字母下划线 |
| \s | [\r\n\t\f] | 表格,换行等空白区域 |
| \S | [^\s] | 非空白区域 |
| 假如我们去掉-E选项,会有什么现象呢? | ||
 | ||
| 此时,不难发现,去掉-E选项之后没有进行正常的正则匹配,这种现象需要我们引入如下的两个概念! |
五 使用示例
匹配文本:"fontname": b"OKFYIZ+\xcb\xce\xcc\xe5", ;
对应正则表达式:"fontname": b"(?<=").*?(?=")", 。
六 基本正则表达式&扩展正则表达式
区别:正则表达式的扩展正则(Extended规范)和基本正则(Basic规范)下,有些字符? + {} | ()应该解释为普通字符,要表示上述特殊含义则需要加“\”转义字符。反之,在扩展规范下,? + {} | ()应被理解为特殊含义,要取其字面值,也要对其进行“\”转义。
因此,grep工具带上-E选项,表示使用扩展正则来进行匹配,若没有该选项,则表示使用基准正则来进行匹配。
对于上述的问题,我们举例如下:

当目标字符串当中本身就包含了? + {} | ()字符,要想进行正则匹配,应该这样做:



综上,正则表达式有以下三个分类:1、基本正则表达式:Basic即BPEs;2、扩展正则表达式:tended即EREs;3、Perl的正则表达式:PREs。
因此,当grep指令不跟任何参数时,表示要使用BREs;“-E”表示使用EREs;“-P”参数,表示使用PREs。
七 贪婪模式与非贪婪模式
1、贪婪模式:正则表达式匹配时,会尽量多的匹配符合条件的内容。

注意:grep默认采用贪婪匹配,可能会对我们的测试结果造成干扰,大家可以上网使用“正则在线转换工具”进行测试。
2、非贪婪模式:正则表达式匹配时,会尽量少的匹配符合条件的内容,也就是说,一旦发现匹配符合要求,立马就匹配成功,而不会继续匹配下去(除非有g,开启下一组匹配)。

八 零宽断言
1、所谓断言,是用来声明一个应该为真的事实。在正则表达式中,只有当断言为真时才会继续进行匹配。
2、零宽断言:像用于查找某些内容之前或者之后的东西,其中一些特殊字符如“\b、^、$”等用于指定一个位置,这个位置应满足一定的条件。
3、分类:
(1)零宽度正预测先行断言(?=exp)
它断言自身出现的位置之后能匹配的表达式exp。如:\b\w+(?=ing\b),表示匹配以ing结尾的单词的前面的部分(除ing以外的部分)。当我们要查找“I’m singing while you’re dancing.”时,它会匹配sing和danc。

(2)零宽度正回顾后发断言(?>=exp)
它断言自身出现的位置的前面能匹配的表达式exp。如:(?<=\bre)\w+\b会匹配以re开头的单词的后半部分(除er以外的部分),例如:在查找“reading a book”时,它匹配ading。


















 1614
1614

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









