







今天遇到了一个问题,生存环境有一个表查询耗时超过3s,导致前端超时。大概有三百万条数据,其中用到了order by,当时排查就是排序(filesort)导致查询时间过长,所以想到就是给order by的字段加一个索引,于是我就在测试环境测试(测试环境数据很少100多条的样子),但是发现了一个很奇怪的问题,查询的时候并没有用到索引。
![]()
如图所示,用的还是filesort,百思不得其解。。。反反复复查资料,看到一段很关键的话:innodb引擎对于查询的优化以及索引的使用,引擎根据算法得出如果全表查询比索引更快时,将会忽略索引的使用。但是可以通过 force index(索引名称)强制使用索引
SELECT * FROM XXX_xxx force index(index_name) WHERE。忽然间恍然大悟,我这测试环境就几百条数据还用个屁的索引啊,当然全表查快啊,于是果断从生产环境导了一份数据到测试环境,再次查询发现秒查,explain 后果然已经用上了索引,如下。
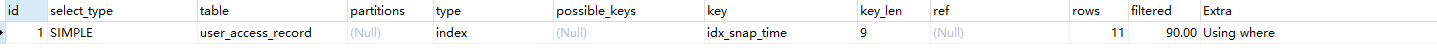
然后我把order by的索引去掉了,发现了查询了7秒。。。所以说这是一个重大的失误,对于有可能暴涨的数据表,order by的字段记得要加索引,时刻谨记!















 427
427











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









