







 本文深入探讨了Hive中的表创建,包括内部表和外部表的创建,以及各种文件存储格式如textfile、sequencefile、rcfile和orc。重点介绍了分区和分桶的概念,强调了它们在数据存储和查询效率中的作用。此外,还对比了外部表与内部表的区别,特别是在数据删除时对外部文件系统的影响。
本文深入探讨了Hive中的表创建,包括内部表和外部表的创建,以及各种文件存储格式如textfile、sequencefile、rcfile和orc。重点介绍了分区和分桶的概念,强调了它们在数据存储和查询效率中的作用。此外,还对比了外部表与内部表的区别,特别是在数据删除时对外部文件系统的影响。
摘要:本文主要介绍了Hive创建表的一些知识,包含内部表、外部表、分区和分桶等。
一、 表创建基本知识
一般创建sql如下
create table ods_uba.lin_test
(
operate_no string,
dev_no string,
user_id string,
start_time string
)
PARTITIONED BY (start_date string)
CLUSTERED BY (start_time)
INTO 16 BUCKETS
STORED AS ORC tblproperties("parquet.compress"="SNAPPY");partitioned by 是创建分区,其中start_date是分区字段
CLUSTERED BY是分桶字段,这里将数据分成了16个桶,字段是start_time
STORED AS 是数据存储类型
查看表结构如下:
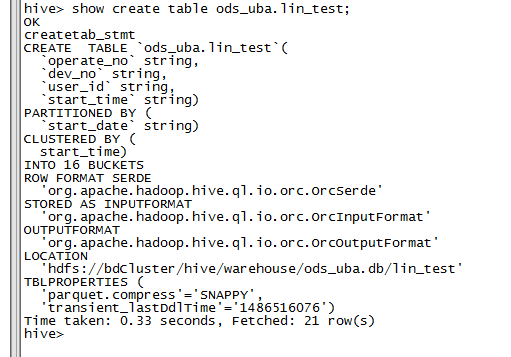
一些相关命令
SHOW TABLES; #查看所有的表
SHOW TABLES '*TMP*'; #支持模糊查询
SHOWPARTITIONS TMP_TABLE; #查看表有哪些分区
DESCRIBE TMP_TABLE; #查看表结构当然,也可以不分区,不分桶。
基本信息:
1、表:一般说的hive表都是指内部表,Hive中的表在HDFS中都有相应的目录用来存储表的数据,目录可以通过${HIVE_HOME}/conf/hive-site.xml配置文件中的 hive.metastore.warehouse.dir属性来配置,一般默认的值是/user/hive/warehouse(这个目录在 HDFS上),。如果我有一个表lin_test,那么在HDFS中会创建/user/hive/warehouse/lin_test目录(这里假定hive.metastore.warehouse.dir配置为/user/hive/warehouse);lin_test表所有的数据都存放在这个目录中。,当然,外部表可以配置其它hdfs来映射文件。可以使用如下命令来查看表对应hdfs的文件:
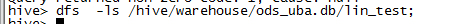
3、分区:在Hive中,表的每一个分区对应表下的相应目录,所有分区的数据都是存储在对应的目录中。比如lin_test表有start_date分区,则对应start_date=20131218,对应表的目录为/user/hive/warehouse /start_date=20131218/,所有属于这个分区的数据都存放在这个目录中。
4、桶:对指定的列计算其hash,根据hash值切分数据,目的是为了并行,每一个桶对应一个文件(注意和分区的区别)。比如将lin_test表start_time列分散至16个桶中,首先对id列的值计算hash,对应hash值为0和16的数据存储的HDFS目录为:/user /hive/warehouse/lin_test/start_date=20131218/part-00000;而hash值为2的数据存储的HDFS 目录为:/user/hive/warehouse/start_date=20131218/part-00002。一般情况下不建议将分桶设置太大,以免小文件过多引起其它更多的问题,用好分桶可以提高计算的效率。
关于文件存储格式还有如下的一些补充:
二、 文件存储格式
1.textfile
默认格式,建表时不指定默认为这个格式
存储方式:行存储
优点:可以直接读取
缺点:磁盘开销大 数据解析开销大。压缩的text文件 hive无法进行合并和拆分
2.sequencefile
二进制文件,以<key,value>的形式序列化到文件中
存储方式:行存储
缺点:存储空间消耗最大
优点:可分割 压缩,全表时查询效率高
一般选择block压缩,文件和Hadoop api中的mapfile是相互兼容的。EQUENCEFILE将数据以<key,value>的形式序列化到文件中。序列化和反序列化使用Hadoop 的标准的Writable 接口实现。key为空,用value 存放实际的值, 这样可以避免map 阶段的排序过程。三种压缩选择:NONE, RECORD, BLOCK。 Record压缩率低,一般建议使用BLOCK压缩。使用时设置参数,
SET hive.exec.compress.output=true;
SET io.seqfile.compression.type=BLOCK; -- NONE/RECORD/BLOCK
create table test2(str STRING) STORED AS SEQUENCEFILE; 3.rcfile
一种行列存储相结合的存储方式。首先,其将数据按行分块,保证同一个record在一个块上,避免读一个记录需要读取多个block。其次,块数据列式存储,有利于数据压缩和快速的列存取。 理论上具有高查询效率(但hive官方说效果不明显,只有存储上能省10%的空间,所以不好用,可以不用)。
RCFile结合行存储查询的快速和列存储节省空间的特点
1)同一行的数据位于同一节点,因此元组重构的开销很低;
2) 块内列存储,可以进行列维度的数据压缩,跳过不必要的列读取。
查询过程中,在IO上跳过不关心的列。实际过程是,在map阶段从远端拷贝仍然拷贝整个数据块到本地目录,也并不是真正直接跳过列,而是通过扫描每一个row group的头部定义来实现的。但是在整个HDFS Block 级别的头部并没有定义每个列从哪个row group起始到哪个row group结束。所以在读取所有列的情况下,RCFile的性能反而没有SequenceFile高。
优点:压缩快, 快速列存取, 读记录尽量涉及到的block最少 ,读取需要的列只需要读取每个row group 的头部定义。
缺点:读取全量数据的操作 性能可能比sequencefile没有明显的优势。但是如果指定一列的话,效率最高
4.orc
存储方式:数据按行分块 每块按照列存储
压缩快 快速列存取
效率比rcfile高,是rcfile的改良版本
5.自定义格式
用户可以通过实现inputformat和 outputformat来自定义输入输出格式。
总结:
textfile 存储空间消耗比较大,并且压缩的text 无法分割和合并 查询的效率最低,可以直接存储,加载数据的速度最高
sequencefile 存储空间消耗最大,压缩的文件可以分割和合并 查询效率高,需要通过text文件转化来加载
rcfile 存储空间最小,查询的效率最高 ,需要通过text文件转化来加载,加载的速度最低
三、 外部表
一般可用建表如下:
CREATE EXTERNAL TABLE IF NOT EXISTS ods_xxx.kafka_web_source_log
(
source_log string,
muid string,
chnl_code string,
opt_type string,
vt_time string,
st_time string
)
PARTITIONED BY (opdt string)
CLUSTERED BY (vt_time)
INTO 16 BUCKETS
row format delimited
fields terminated by '^' lines terminated by '\n'
stored as textfilefields terminated指明分隔的字符
lines terminated 指明分行的字符
1.关联HDFS文件
hive并不会自动关联hdfs中指定目录的partitions目录,需要手工操作。通过给已经创建的表增加分区数据的方式,与HDFS上的文件相互关联起来。有以下几种语法格式:
(1)alter table 表名称 add partition (分区名1=分区值1,...) location 'HDFS上的文件的路径';
(2)LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE xxx [PARTITION (yyy = zzz)]
如
load data inpath '/hive/warehouse/ods_uba.db/kafka_web_source_log/opdt=2017-01-06' into table ods_uba.kafka_web_source_log_temp partition (opdt='2017-01-06')
当然,也可以在创建外部表的时候就指明hdfs文件的位置
如下:
CREATE EXTERNAL TABLE IF NOT EXISTS ods_uba.kafka_web_source_log
(
source_log string,
muid string,
chnl_code string,
opt_type string,
vt_time string,
st_time string
)
PARTITIONED BY (opdt string)
CLUSTERED BY (vt_time)
INTO 16 BUCKETS
row format delimited
fields terminated by '^' lines terminated by '\n'
stored as textfile
LOCATION '/hive/warehouse/ods_uba.db/kafka_web_source_log';alter table kafka_web_source_log add if not exists partition(opdt='2017-01-09')
查看表结构如下:
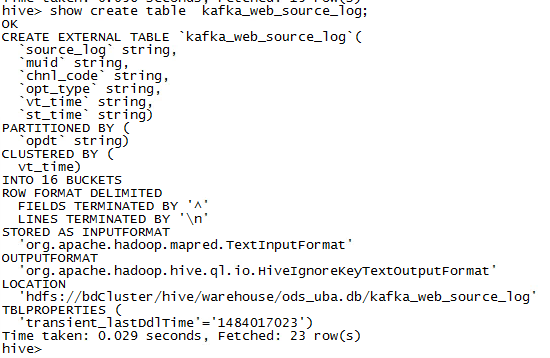
也可以使用命令
DESCRIBE EXTENDED 来显示更加详细的信息,如下:
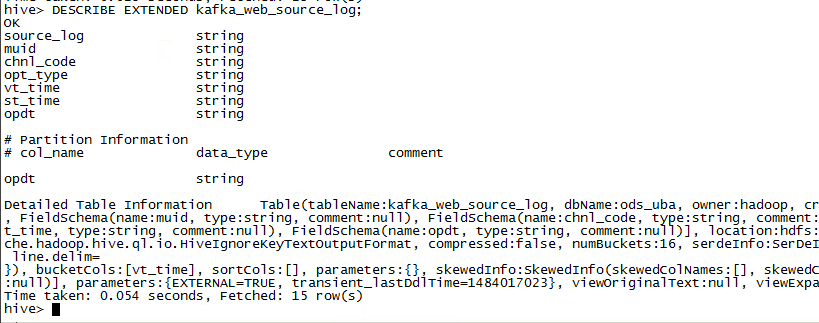
2、外部表与内部表的区别
(1)、外部表创建时要添加EXTERNAL,外部表查询是只是去关联hdfs文件,并按照分割符号转成对应的字段
(2)、外部表删除表后,hdfs文件不会被删除。同理,外部表删除分区后,hdfs文件也不会被删除

















 1366
1366

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









