







基于个人爱好,使用Angular做了一个双语阅读的网站:蜗牛阅读, 用来闲暇时间看看英文的。可惜传了几本书到现在自己都还没看完~
网站后台采用的是Netcore+Mysql,前端页面使用的是Angular8。
既然做了网站就想搜索引擎能搜出来,于是就百度了很多大神的方法。我采用了使用 PhantomJS 抓取页面生成静态HTML的方式满足引擎爬虫的要求。
经过一阵折腾几个搜索引擎终于都能正确收录我的页面了,也有正确的快照。
这篇笔记我会把我整个网站优化过程操作过的一些流程分享给大家,希望能多少帮到大家。
1、优化效果
因为建站之前没有事先百度,貌似我取的名字和网易的蜗牛读书重名了,比较悲催。我的网站定的关键字主要是"蜗牛阅读"和"蜗牛双语阅读"再加上小说的名字。
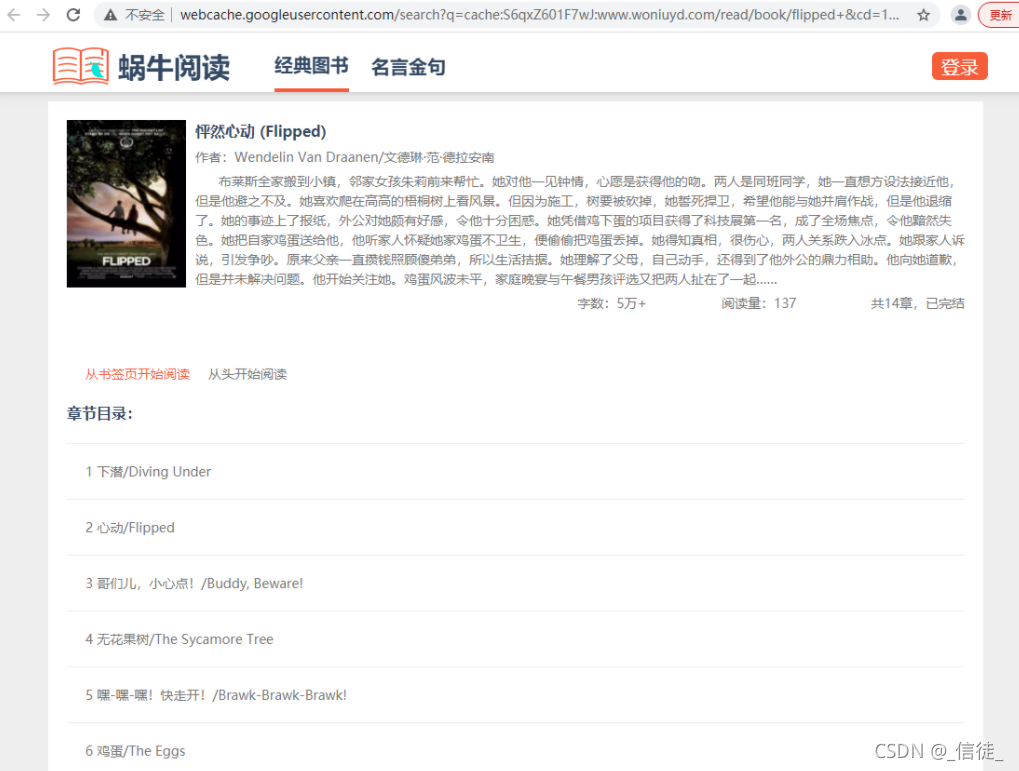
先看百度搜索效果吧, 单独搜蜗牛阅读和蜗牛双语阅读是很难搜出我的网站的。
使用蜗牛双语阅读加小说的名字还勉强能搜出来。
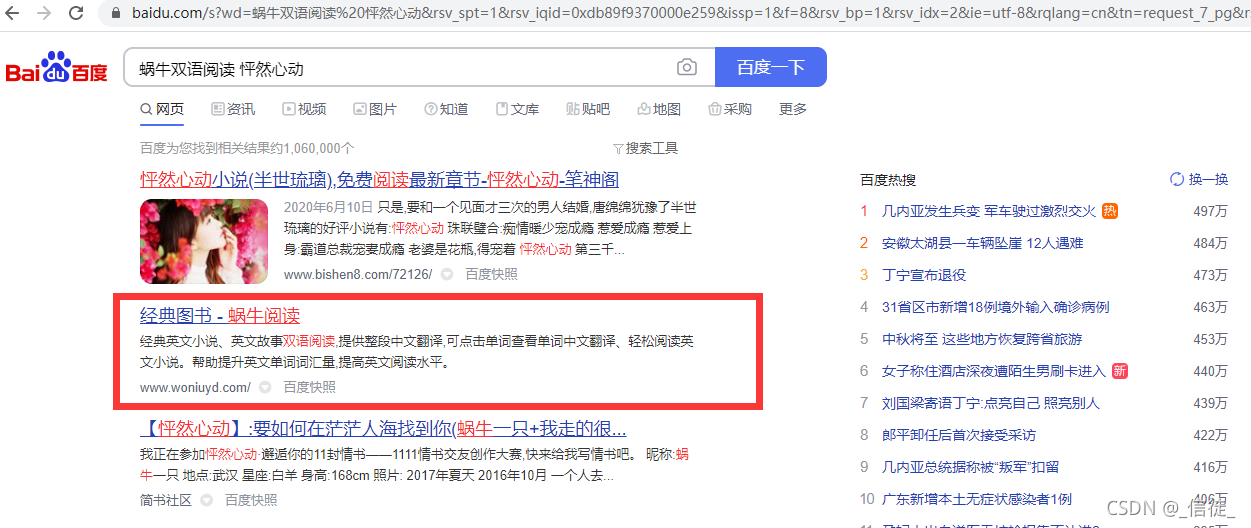
第二个就是我的页面,点击快照也能看到正确的快照页面:
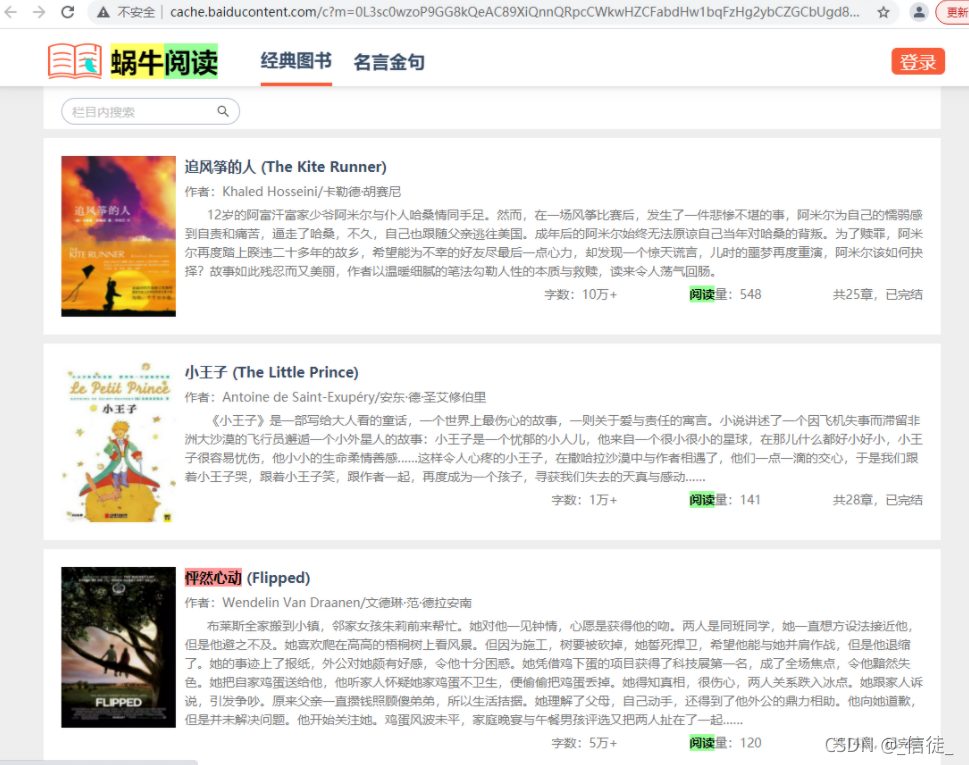
再看看微软的Bing搜索,使用蜗牛双语阅读直接就能搜出来:

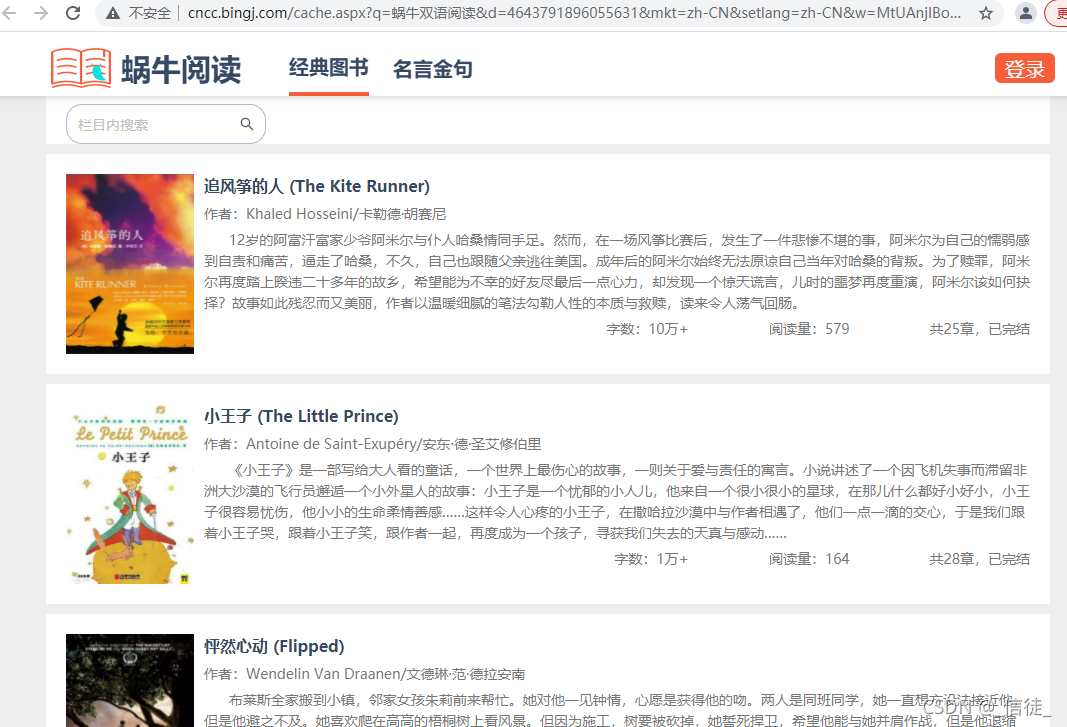
还给我放在了第二个,很给面子。缓存页面也正常:
最后看看谷歌吧, 单独搜蜗牛阅读和蜗牛双语阅读是能搜到我的网站,但是排名很后要翻好多页。使用蜗牛双语阅读加小说的名字就可以比较精准的搜出来:
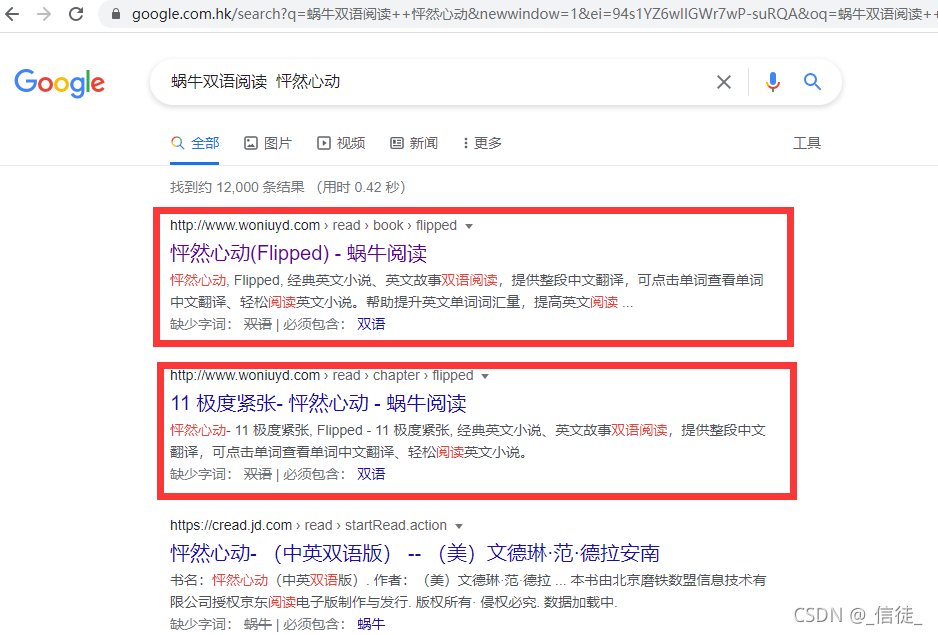
前面两条都是我的页面,而且精准的定位到了单本小说的章节列表页面。缓存页面也正常:
通过对比我发现Bing和谷歌的搜索引擎还是比较客观的,不管你网站访问量多少,按照关键字匹配规则该你排前面就把你的页面排前面。
而且bing和谷歌的蜘蛛也比较勤劳,通过网站后台日志可以看到只要网站的sitemap有更新,他们的蜘蛛就会来抓取你的页面,也不用手动提交收录什么的。
百度的话需要去手动提交收录,还有各种想要收费的操作,手动提交了也很久都不收录,使用完整域名都搜不出来,我这个网站也是过了好久才能在百度上搜出来。
而且百度爬虫也很懒不常抓页面,缓存的页面都是很久之前的版本,属实比较坑。
2、路由地址优化
使用过Angular进行单页应用开发的都知道,常用应用的页面路由地址一般是如下形式:
http://www.aa.com/#/module/page?a=?&b=? //地址中带#号,参数采用问号和&符号连接我们需要将页面地址换成一般网站的地址形式:
http://www.aa.com/module/page/a/b去掉路由地址中的#号,需要关闭路由的哈希模式(有的项目可能并没有开启哈希模式),注释掉AppModule中providers里的 LocationStrategy 即可。

路由的哈希模式关闭后非默认路由页面不能直接刷新,这时候可以通过Nginx按如下配置进行设置使得页面能够自由刷新:
location / {
try_files $uri $uri/ /index.html =404;
//所有路由都先请求index.html再由页面js负责路由跳转
}对于页面参数的优化,可以在路由配置文件中对各个页面的参数进行格式定义。
栗子: http://www.woniuyd.com/read/chapter/flipped/6/2 这个地址表示图书章节的页面,图书的代码是flipped,地址表示第6章的第二页。
其中read是模块的路由地址,chapter是页面的路由地址,flipped,6,2三个都是页面参数。
路由配置如下:
// 最外层模块路由(app-routing.module.ts中):
{ path: 'read', component: FrLayoutComponent, loadChildren: './modules/front/front.module#FrontModule' },
// 模块内部路由(front-routing.module.ts中)
{ path: 'chapter/:code/:chapter/:page', component: FrontChapterComponent },
//:code表示书籍代码 :chapter表示章节序号 :page表示页码序号在页面组件中通过ActivatedRoute获取对应参数值:
constructor(private activeRoute: ActivatedRoute){
this.bookCode = this.activeRoute.snapshot.paramMap.get('code');
this.chapterIndex = parseInt(this.activeRoute.snapshot.paramMap.get('chapter'));
this.pageIndex = parseInt(this.activeRoute.snapshot.paramMap.get('page'));
}3、关键字优化
在Angular单页应用中可以使用框架自带的库动态地对不同的路由页面设置不同的Meta和Title:
import { Title, Meta } from '@angular/platform-browser';
constructor(
private title: Title,
private meta: Meta,
) {
//....
}
this.title.setTitle('我的标题');
this.meta.updateTag({ name: 'description', content: '我的页面描述' });
this.meta.updateTag({ name: 'keywords', content: '我的页面关键字' });4、内部跳转优化
这个是指应用内部页面跳转尽量使用a标签,而不是使用别的标签加(click)事件进行跳转。
比如从图书列表页面点击图书跳到单本图书章节页面:
<a *ngFor="let book of bookList" href="{{domain + '/read/book/' + book.code }}">
//a标签链接跳转 推荐写法
<div *ngFor="let book of bookList" (click)="showBook(book)">
//showBook(book) js代码进行跳转 不推荐5、使用PhantomJS 抓取页面生成静态HTML
因为搜索引擎只识别静态的html文件进行收录,所以我们需要针对想要收录的路由地址生成对应的静态html文件供爬虫抓取。
我这里使用的是 phantomjs。 官网可以下载绿色压缩包: Download PhantomJS
以下脚本是我抓取页面作为网站首页的静态html的脚本:
console.log('render static file start ... ');
var fs = require('fs');
var page = require('webpage').create();
var baseUrl = "http://www.woniuyd.com/";
var savePath = "E:\\Work\\StaticFiles\\";
phantom.outputEncoding = "utf-8";
//获取网站主页
getIndex(fs, page, "read/list/1", function () {
console.log("task finished .");
phantom.exit(0);
});
//获取首页
function getIndex(fs, page, indexUrl, callback) {
console.log("render " + baseUrl + indexUrl + " ... ");
page.open(baseUrl + indexUrl, function (status) {
if (status === "success") {
setTimeout(function () {
fs.write(saveDirPath + "index.html", page.content, 'w');
console.log("render " + baseUrl + indexUrl + " finish. ");
if (callback) {
callback();
}
}, 1000); //延时保存页面,确保所有资源都已加载完成
} else {
console.log(baseUrl + indexUrl + " !!!!page load fail");
}
});
}使用命令行工具进入到解压的phantomjs目录 执行 phantomjs script.js 命令运行脚本就可以抓取保存html文件。
需要注意的是phantomjs对JS版本的支持并不如浏览器那么强大,尽量按照ES6以前的语法写脚本。我试过的箭头函数就不支持。
针对网站不同的模块,按照对应的目录结构调整脚本,就可以将想要爬虫抓取的html全部保存下来。
6、样式文件打包,静态文件部署
另外一个需要注意的地方是,如果网站的样式很多很复杂,那么网站发布的时候angular.json中extractCss需要设置为true,即单独打包一个独立的样式文件,而不是将样式全部包含在发布后的index.html中。
全部包含在index.html中会造成抓取保存的静态html文件过大,百度不能正确保存快照(百度限制了缓存文件大小,好像是100k)。
extractCss节点位置:
{
"$schema": "./node_modules/@angular/cli/lib/config/schema.json",
...,
"projects": {
"woniuyuedu": {
"projectType": "application",
...,
"architect": {
"build": {
"builder": "@angular-devkit/build-angular:browser",
...,
"configurations": {
"production": {
...,
"extractCss": true,
...,
}
}
}
}
}
}静态html文件准备好后,复制到网站服务器目录中,建议的目录是 /assets/static/
即如果你的网站实际index.html的路径是: rootfolder/index.html
那么其对应的静态文件应该复制的路径是: rootfolder/assets/static/index.html
另外独立打包发布的样式文件也要复制一份到/assets/static/目录,即:rootfolder/assets/static/styles.abcd63526***.css
静态文件放置好后,再进行Nginx配置,针对爬虫进行请求重定向就可以了。
7、Nginx设置爬虫重定向
可以针对想要的路由及目录进行配置。
我的配置如下:
map $http_user_agent $is_bot {
default 0;
~[a-z]bot[^a-z] 1;
~*'Baiduspider' 1;
~[sS]pider[^a-z] 1;
'Yahoo! Slurp China' 1;
'Mediapartners-Google' 1;
'YisouSpider' 1;
}
server{
listen 80;
...
if ($is_bot){
rewrite ^/index.html$ /assets/static/index.html break;
rewrite ^/read/(.*) /assets/static/read/$1.html break;
}
...
}到此,各搜索引擎就可以正确抓取网站的静态页面了。
自己测试可以使用curl指令:
curl -A "Mozilla/5.0 (compatible; Baiduspider/2.0; +http://www.baidu.com/search/spider.html)" http://www.woniuyd.com/read/1.html> e:\curl.html也可以使用baidu自己的抓取诊断:https://ziyuan.baidu.com/crawltools/index?site=http://www.woniuyd.com/
8、最后
其他前端单页框架开发的网站也可以采用本文phantomjs+nginx的模式满足SEO需求。
我也是第一次搭建网站,对SEO也是一知半解,欢迎大家提供意见,欢迎参观 蜗牛阅读 也可以加友情链接哦。私信联系。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











