






一、问题描述
任务:要用工具全自动找出一个网站中的所有带某个特定图标的网页中所有死链。
死链就是失效的链接,错误的链接。对链接发送请求,返回的结果是4XX,5XX,例如404,502等等。如图1-1,这就是一个死链点击之后的页面。

图1-1
现在目标网站是东北师范大学官网。要用自动化程序找出目标网站中所有带有“有奖纠错”标志的网页中的死链,并生成死链信息报告。
“有奖纠错”标志如图1-2。

图1-2
二、工具准备
本次开发需要用到selenium坏境,所以需要安装selenium。
在PyCharm软件Terminal中输入:pip install selenium,即可完成安装。
三、技术路线
3.1 数据结构
用队列queue记录将要访问的链接。
队列queue每一个节点(链接)组成一个树形结构,如图3-1。
对树形结构采用BFS(广度优先遍历)方式遍历。
BFS遍历在此问题中应用如下。
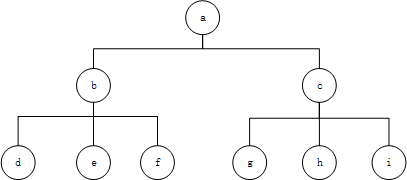
图3-1
如图3-1,图中每一个节点都代表一个链接(链接a,链接b,链接c......)。
访问网站中所有的网页链接具体实现过程如下。
1)首先将链接a加入队列,此时队列queue中有元素a,即queue(a);
2)然后链接a出队(代表将要访问链接a),链接a网页中有链接b,c,所以将b、c加入queue,此时queue中有元素b、c,即queue(b,c);
3)接着链接b出队(访问链接b),链接b中有链接d、e、f,所以将d、e、f,加入queue,此时queue中有元素c、d、e、f,queue(c,d,e,f);
继续出队和进队操作,直到队列queue为空停止。
3.2 避免访问链接进入循环
用哈希表记录访问过的链接。每次访问前做判断。
哈希表以键值对的形式存储元素,并且键具有唯一性,访问哈希表中的元素可以直接根据键(Key)访问对应的值,因此查找速度快。哈希表存储元素的过程是先判断要存储的元素与已有元素的hashcode是不是相同,如果不相同则会直接存储。
函数代码如下。
# 函数功能:判断链接是否访问过
def judge(url):
# 把访问过的节点放在hash表中
if str(url) in hashList:
return True
else:
hashList[str(url)] = True
return False3.3 有奖纠错标志
爬取网页中的图片,并判断是否有目标图片。
用Selenium中的库函数find_elements(),可以获取网页中所有的图片元素,然后判断这些图片中是否含有“有奖纠错”标志图片。
函数代码如下。
# 函数功能:检查网页中是否有“有奖纠错”标志
def check_logo(url):
print(url)
wb = webdriver.Chrome(options=options)
wb.get(url)
imgs = wb.find_elements(By.XPATH, '//img')
flag = '无标志'
for img in imgs:
s = img.get_attribute('src')
if s == func(url) + 'images/yjjc.png':
flag = '有标志'
if flag == '有标志':
return True
else:
return False
wb.close()3.4 status code
判断一个链接是否是死链需要两个步骤。
向链接发送请求。
判断返回的status code(状态码)。
记录死链,记录status code为4XX和5XX的死链,例如404, 502。
代码如下。
request = requests.head(url=u, timeout=1)
if request.status_code >= 400 and request.status_code < 600:
listError.append(rootUrl)
listError.append(url)
listError.append(u)
listError.append(t)
listError.append(request.status_code)
listAllError.append(listError)四、架构图
自动化程序、selenium、浏览器、浏览器驱动、目标网站之间的工作原理如下。
自动化程序调用Selenium客户端的库函数(例如获取页面链接元素)。
然后Selenium客户端库会发送命令,把命令发送给浏览器的驱动程序(WebDriver)。
浏览器驱动程序(WebDriver)接收命令后,驱动浏览器去执行命令。
浏览器执行命令(打开网站网页等),然后再将命令结果返回给浏览器驱动(WebDriver)。
浏览器驱动程序获取命令执行的结果,再将结果返回给自动化程序。
程序再对返回结果做处理。
所以架构图,如图4-1。
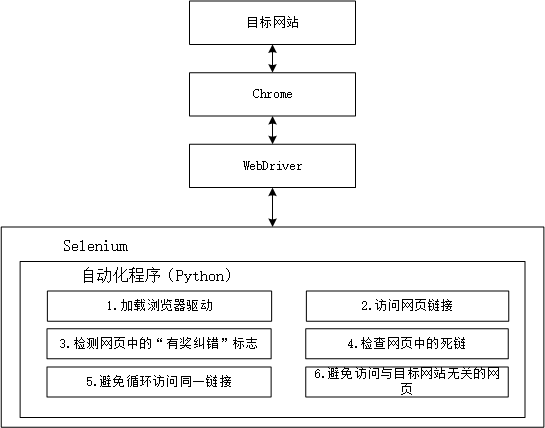
图4-1
五、实验结果
如图5-1,是程序运行输出数结果的部分截图,截图中包括了表头(网站、网页、链接href、文本、错误号),和死链信息。

图5-1
附录A
完整代码。
import time, os, re
import requests
import pandas as pd
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
options = webdriver.ChromeOptions()
wd = webdriver.Chrome(options=options)
url = '目标网站'
listAllError = [] # 记录所有的错误信息
listError = [] # 记录一条错误信息 网站 网页 链接href 文本 错误号
hashList = {} #hash表,记录访问过的链接
queue = [] # 队列,记录即将访问的网页链接
queue.append(url)
columns = ["网站", "网页", "链接href", "文本", "错误号"] # 表头,死链信息
strNenu = 'nenu.edu'
# 函数功能:获取网页所在网站
def func(url):
x = re.split('/+', str(url))
y = x[0] + '//' + x[1] + '/'
return str(y)
# 函数功能:检查带有“有奖纠错”标志的网站中异常链接
def check_bug(url):
global listError
global listAllError
rootUrl = func(url) # 获取url所在网站
try:
wb = webdriver.Chrome(options=options)
wb.get(url)
# 获取所有的链接
links = wb.find_elements(By.XPATH, "//a")
for link in links:
u = link.get_attribute('href')
t = link.get_attribute('innerText')
if t == '':
continue
try:
request = requests.head(url=u, timeout=1)
if request.status_code >= 400 and request.status_code < 600:
listError.append(rootUrl)
listError.append(url)
listError.append(u)
listError.append(t)
listError.append(request.status_code)
listAllError.append(listError)
listError = []
dt = pd.DataFrame(listAllError, columns=columns)
dt.to_excel("Bug.xlsx", index=0) # 将数据写入文件
except:
print()
wb.close()
except:
print()
wb.close()
# 函数功能:检查网页中是否有“有奖纠错”标志
def check_logo(url):
print(url)
wb = webdriver.Chrome(options=options)
wb.get(url)
imgs = wb.find_elements(By.XPATH, '//img')
flag = '无标志'
for img in imgs:
s = img.get_attribute('src')
if s == func(url) + 'images/yjjc.png':
flag = '有标志'
if flag == '有标志':
return True
else:
return False
wb.close()
# 函数功能:判断链接是否访问过
def judge(url):
# 把访问过的节点放在hash表中
if str(url) in hashList:
return True
else:
hashList[str(url)] = True
return False
def check_link(link):
# 如果访问过,退出函数
if judge(link):
return
if strNenu not in str(link):
return
# 不用了,已将把访问过的链接放在哈希表中了
# listPass.append(link) # 这里存放已经遍历过的链接
try:
if check_logo(link):
# 有标志,检查该网页中的死链接
x = re.split('/+', str(link))
# 是网站中的一个网页
if x[2] != '':
check_bug(link)
except:
print()
wd.get(link)
addresses = wd.find_elements(By.XPATH , '//a')
for address in addresses:
a = address.get_attribute('href')
queue.append(a)
# 启动开始
while True:
check_link(queue.pop(0)) # 弹出队列中的第一个链接,,并访问
if len(queue) == 0: # 队列为空,退出循环,结束程序
break














 987
987











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









