







rag我简单理解来看就是我先有一段文本,先把它转成向量,保存到向量数据库中,下次我调用llm时将向量数据库中查询的结果给llm作参考并回答。
对rag了解不多,所以开启学习之旅,学完了要应用到实际的需求中,因为最近手里有一个订单就是需要用到这个技术,但是又一知半解。
现在新知识太多了,学不过来,完全学不过来。
看了一个B站关于langchain的rag相关的知识,介绍了langchain官方文档该这么看,感觉有用,贴一下链接:
LangChain实现RAG检索增强_哔哩哔哩_bilibili
因为我是在pgsql中存储和搜索向量,所以推荐这篇文章如何安装pgsql支持向量的操作:https://blog.csdn.net/FrenzyTechAI/article/details/131552053
原生的pgsql不支持或者没有很好的支持向量的操作,所以需要用到扩展的pgsql。
又问了一下同事,大致知道流程了,就是:我需要提供一个接口将文本转成向量存到pgsql数据库。再提供一个查询的接口,这个接口先把传入的文本转成向量,再去pgsql向量数据库查询,最后得出结果,表结构就是文本对应向量,然后查询的时候根据向量文本相似度查询相似度最高的几条记录,这样就可以拿到文本了,再将这个文本丢给AI作参考,然后AI就可以先基于本地内容回答了。
所以本地知识库其实和rag差不多的。
OK!大致思路整理清楚了开始动工:
我这边使用的数据库也是pgsql,但是我本地是windows系统,所以还得看看怎么在windows上安装pgsql的pgvector扩展:
根据:
https://www.cnblogs.com/xiaonanmu/p/17979626
PostgreSQL安装扩展vector_pgvector安装-CSDN博客
这两篇文章的参考,我需要在本地安装C++然后手动make,先安装C++
:
下载 Visual Studio Tools - 免费安装 Windows、Mac、Linux
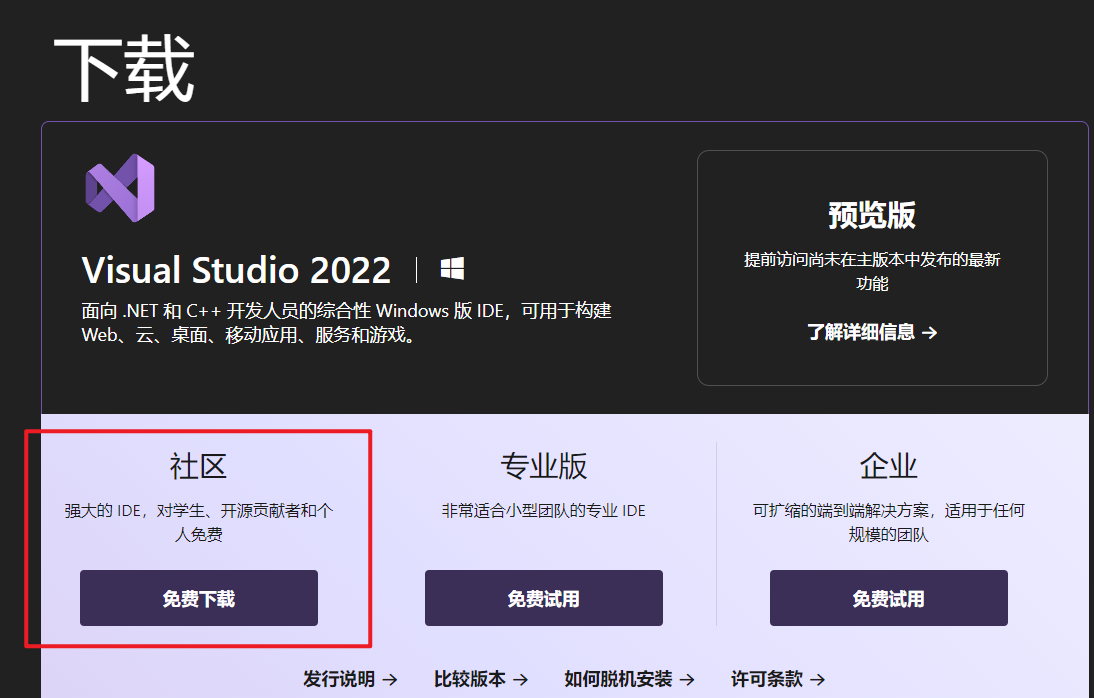
我们下载社区版就行
然后我们只装这一个:
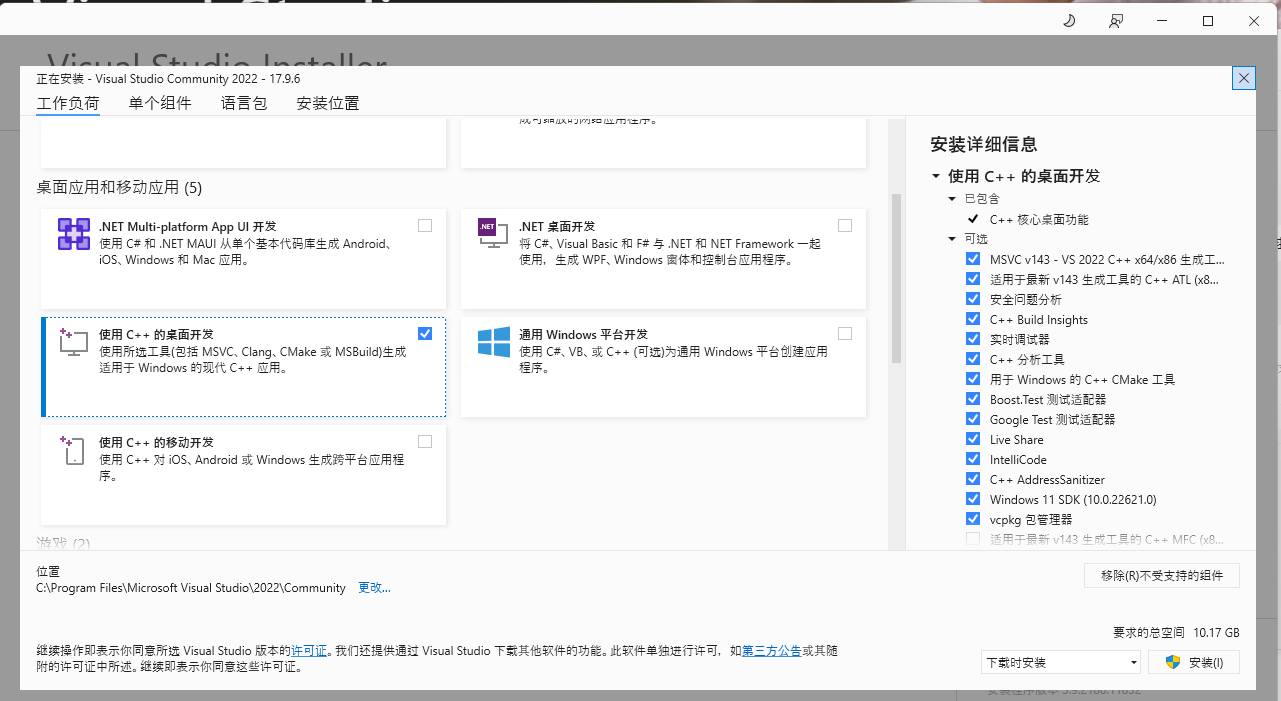
等下载完成:
安装好后打开:C:\Program Files\Microsoft Visual Studio\2022\Community\VC\Auxiliary\Build
就能看到有这个文件
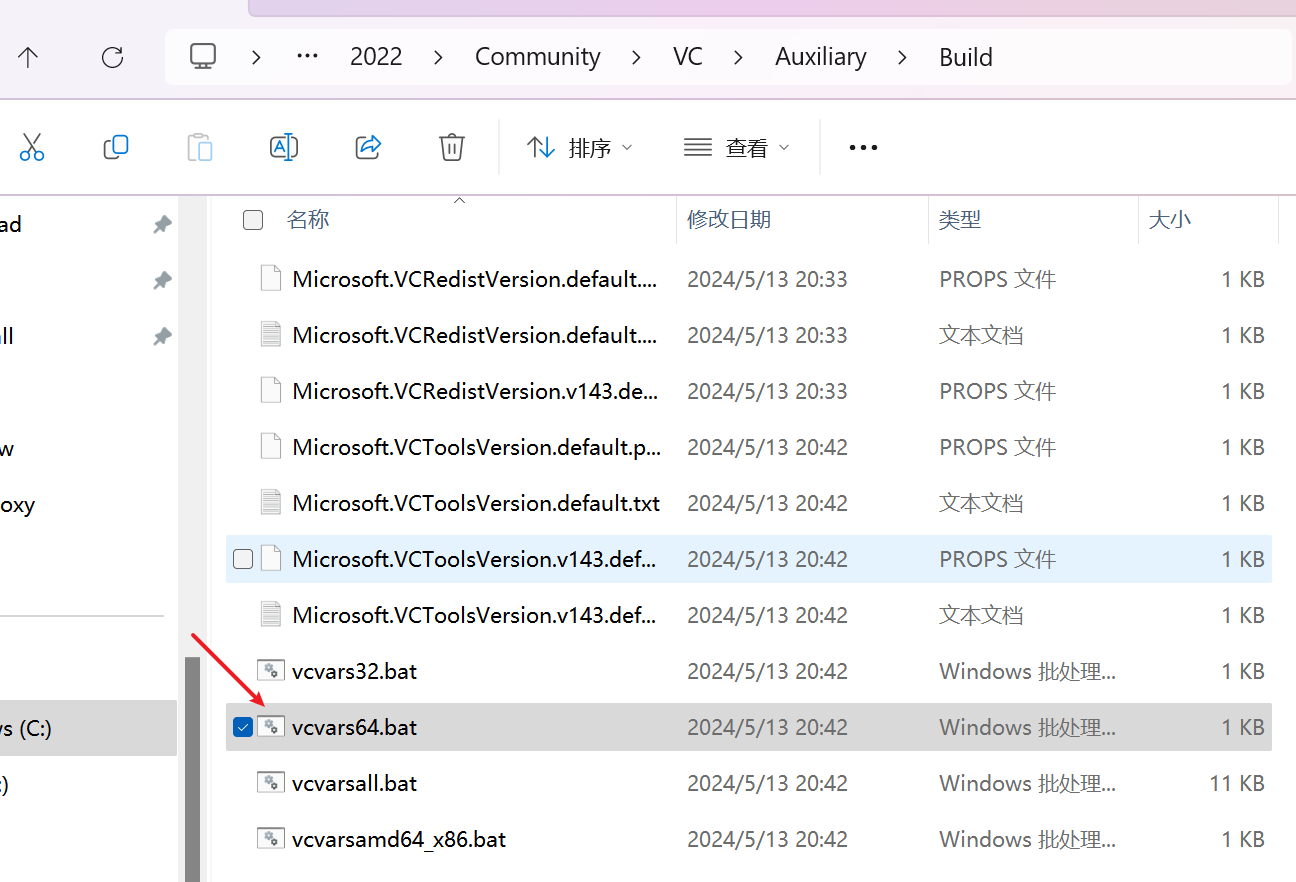
我们命令行执行:
call "C:\Program Files\Microsoft Visual Studio\2022\Community\VC\Auxiliary\Build\vcvars64.bat"

再去官网下载pgsql的pgvector扩展:
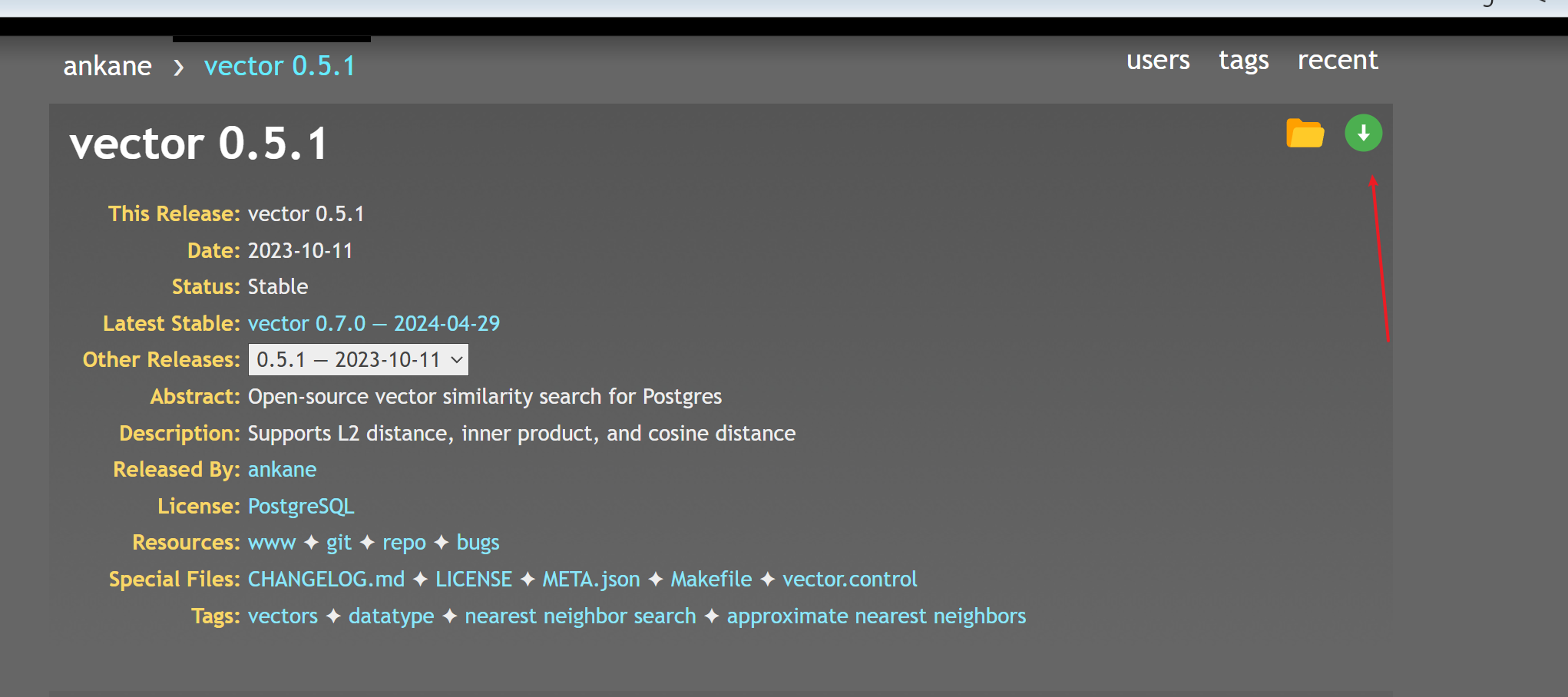
vector 0.5.1: Open-source vector similarity search for Postgres / PostgreSQL Extension Network
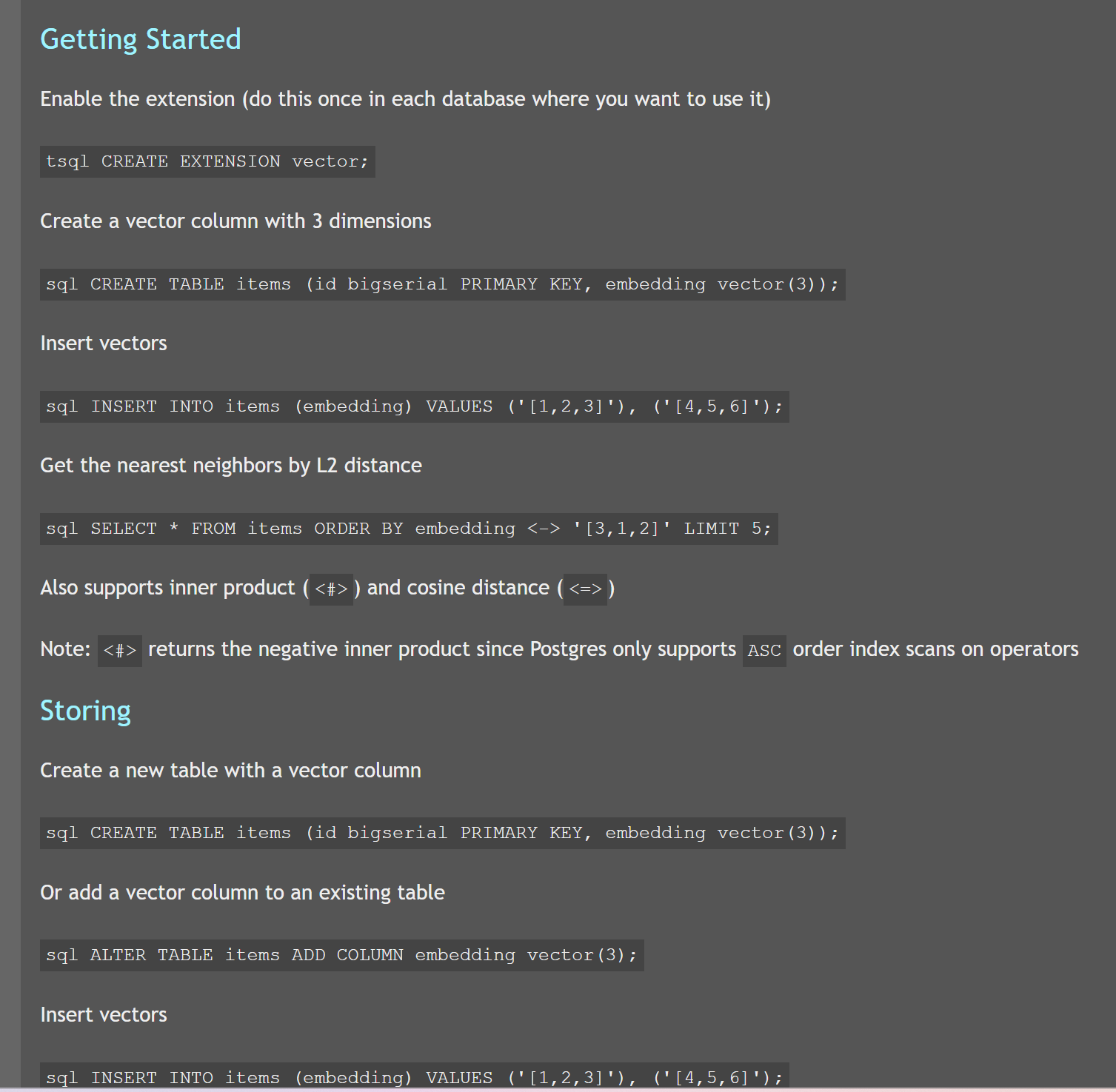
这个官网下面还有使用教程:
我们这里下载0.5.1版本的:

下载之后解压:
然后打开命令行输入nmake看看有没有效:

输出内容了,说明nmake安装成功!
接下来开始编译pgvector扩展,我们的目标文件:
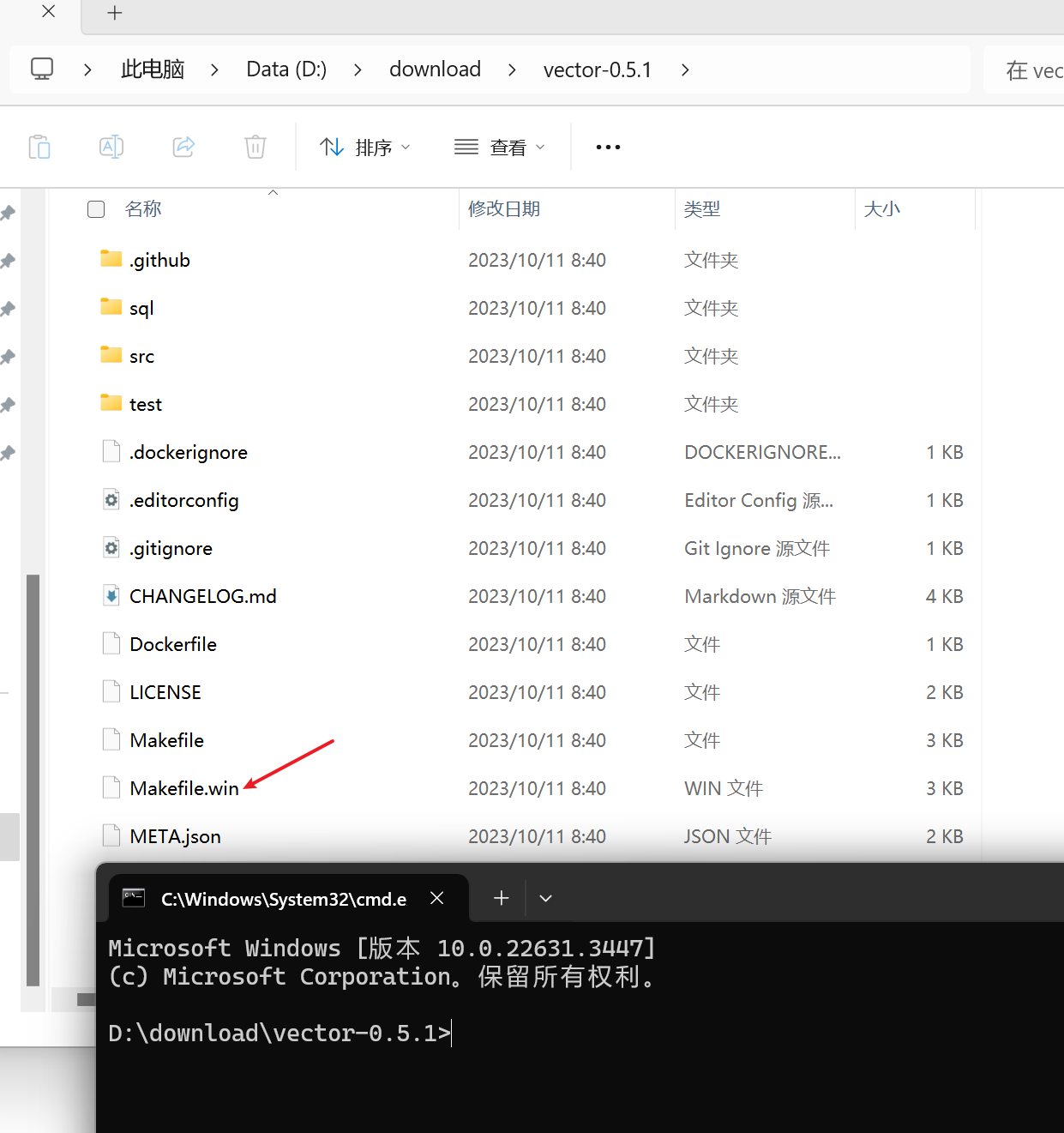
我们先设置一下pgsql的安装目录,这里要改成自己真实的安装目录,再以管理员身份运行命令行输入,不然可能会失败:
set "PGROOT=D:\soft_install\pgsql-16"
不设置的话会报错:

我们设置一下:

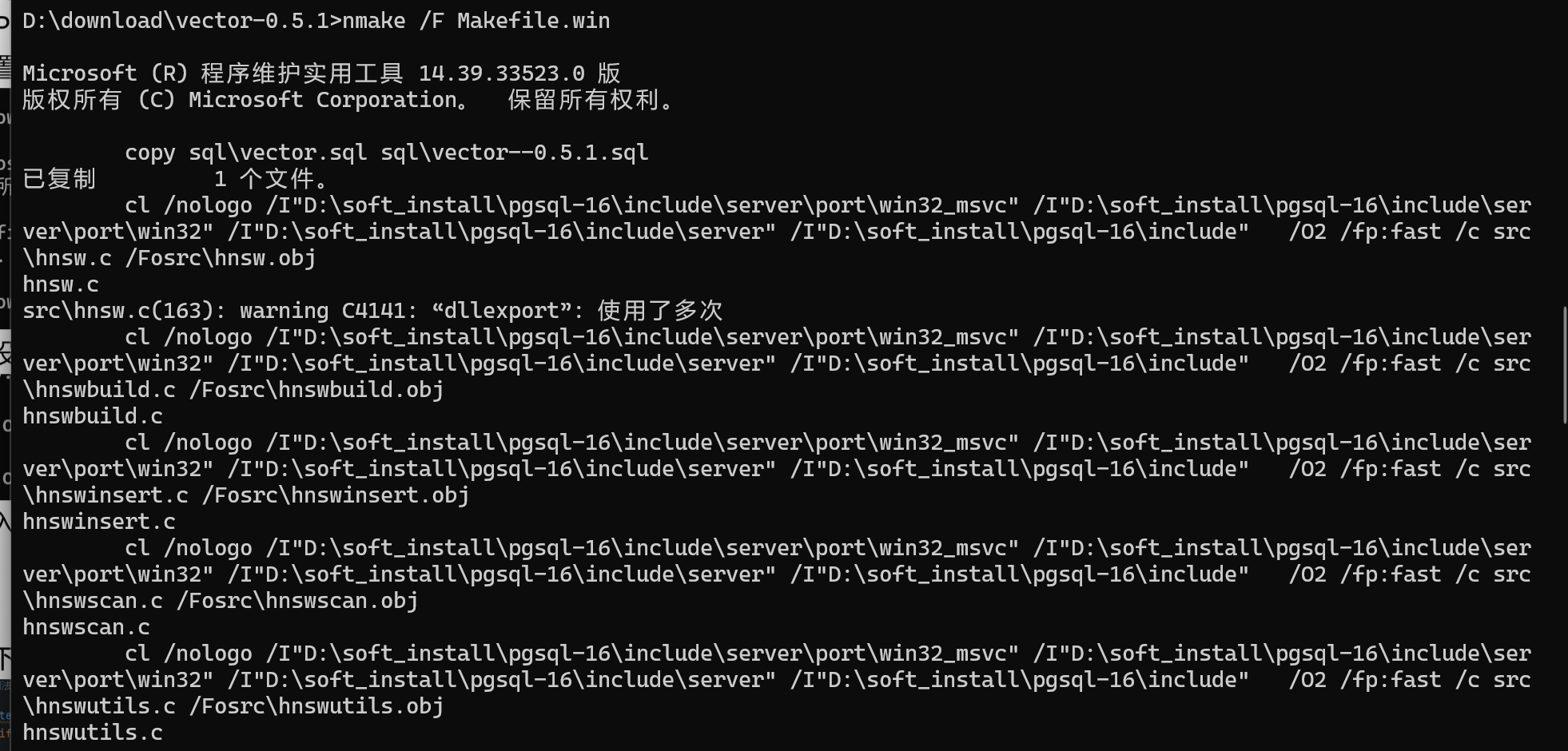
再输入nmake /F Makefile.win,执行结果时这样的:

再输入nmake /F Makefile.win install:
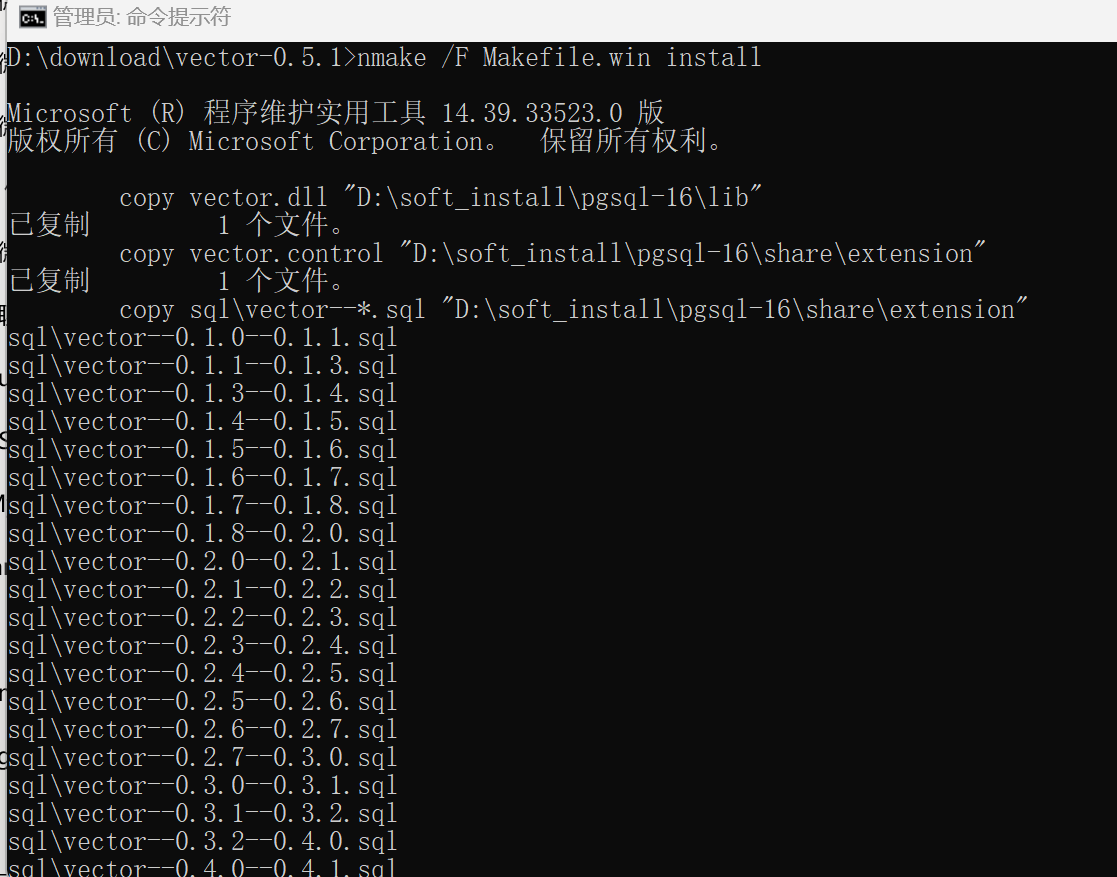
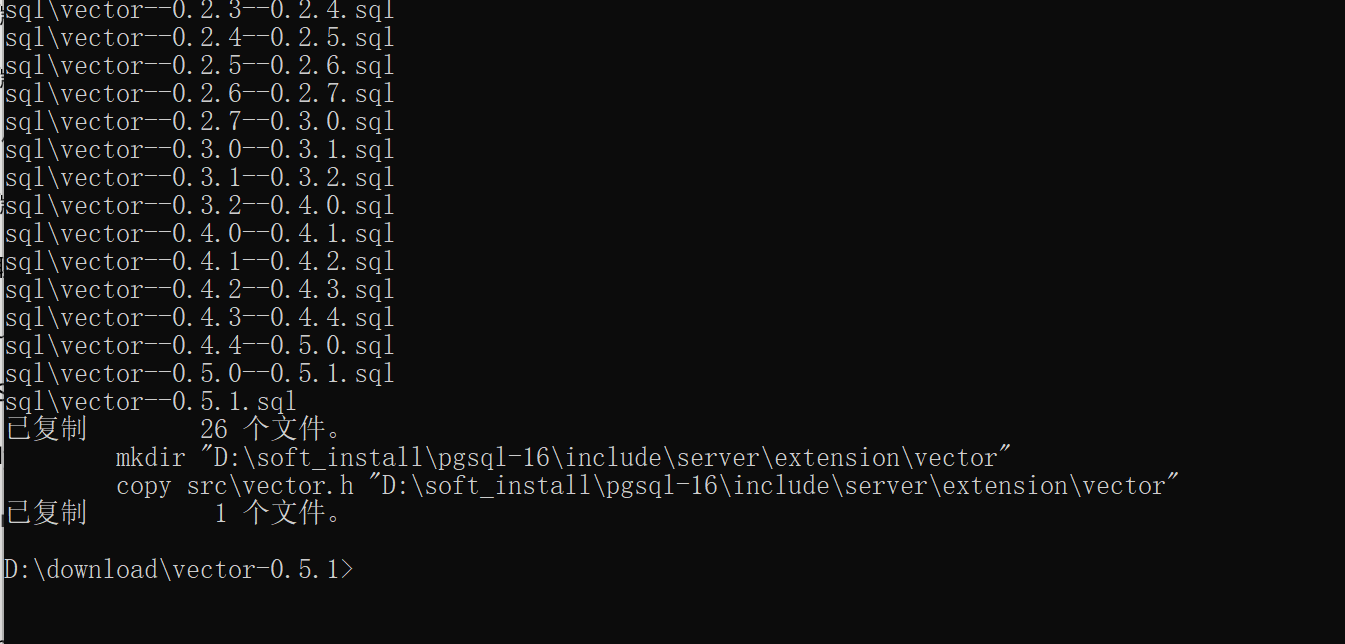
应该是安装完成了。
安装完成后还得启用,我们是windows的话,打开pgadmin4:
运行此命令以启用扩展:CREATE EXTENSION vector;;
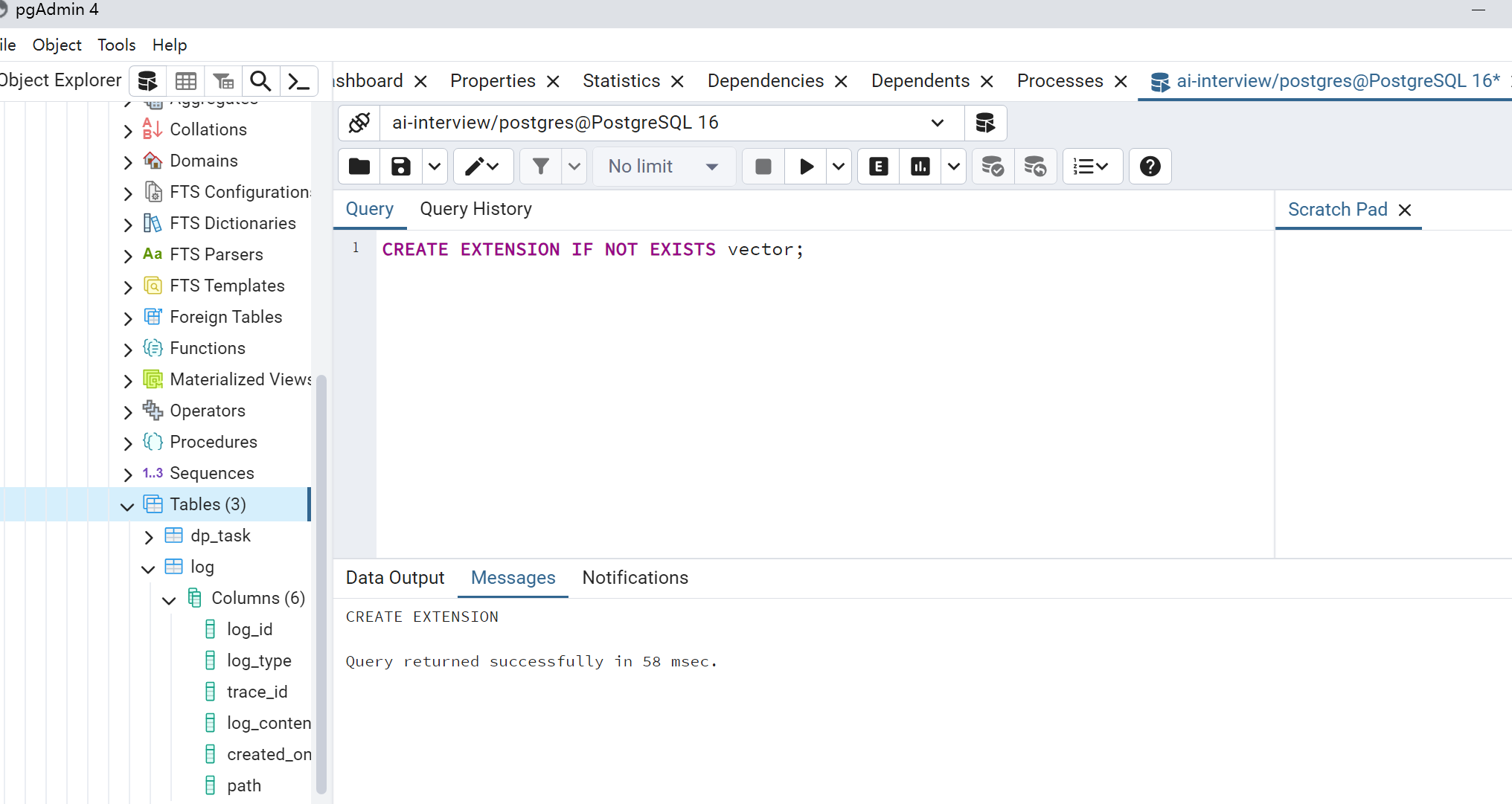
验证是否安装成功:
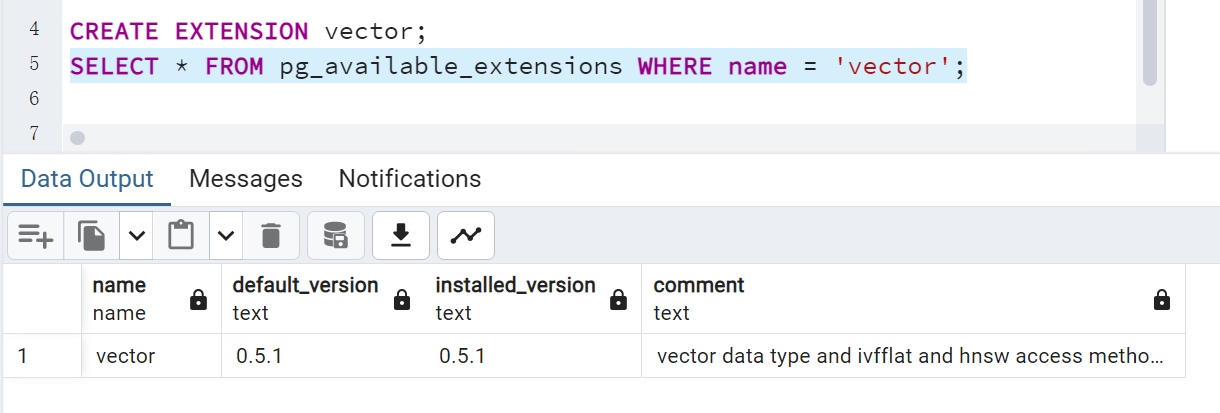
说明我们成功安装了vector0.5.1版本的了。
在这里也能看到:
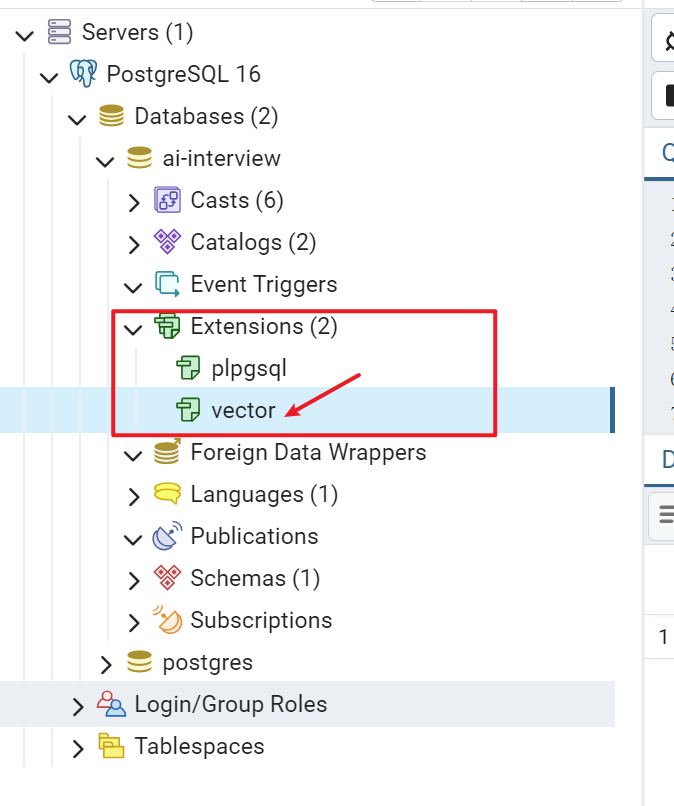
我再创建一个符合我的项目需求的表,用来存储文本和向量结构:
CREATE TABLE IF NOT EXISTS public.job_info_vector
(
id character varying(36) COLLATE pg_catalog."default" NOT NULL,
city_id character varying(36) COLLATE pg_catalog."default" NOT NULL,
city_name character varying(36) COLLATE pg_catalog."default" NOT NULL,
post_id character varying(36) COLLATE pg_catalog."default" NOT NULL,
post_name character varying(36) COLLATE pg_catalog."default" NOT NULL,
description character varying(1024) COLLATE pg_catalog."default" NOT NULL,
created_on character varying(35) COLLATE pg_catalog."default" NOT NULL,
description_vector vector NOT NULL,
CONSTRAINT job_info_vector_pkey PRIMARY KEY (id)
)
TABLESPACE pg_default;
ALTER TABLE IF EXISTS public.job_info_vector
OWNER to postgres;
COMMENT ON COLUMN public.job_info_vector.city_id
IS '城市id';
COMMENT ON COLUMN public.job_info_vector.city_name
IS '城市名';
COMMENT ON COLUMN public.job_info_vector.post_id
IS '岗位id';
COMMENT ON COLUMN public.job_info_vector.post_name
IS '岗位名称';
COMMENT ON COLUMN public.job_info_vector.description
IS '岗位对应的招聘信息';
COMMENT ON COLUMN public.job_info_vector.created_on
IS '创建时间';
COMMENT ON COLUMN public.job_info_vector.description_vector
IS '向量的表示';大致的流程:
1、我需要提供一个接口供将传入的内容分块并向量化存储
2、提供查询接口(将查询的内容向量化再查询)
一个一个来实现。
网上找了下,暂时没找到加载一段文本的,而是只有加载文件的,就那几行代码。
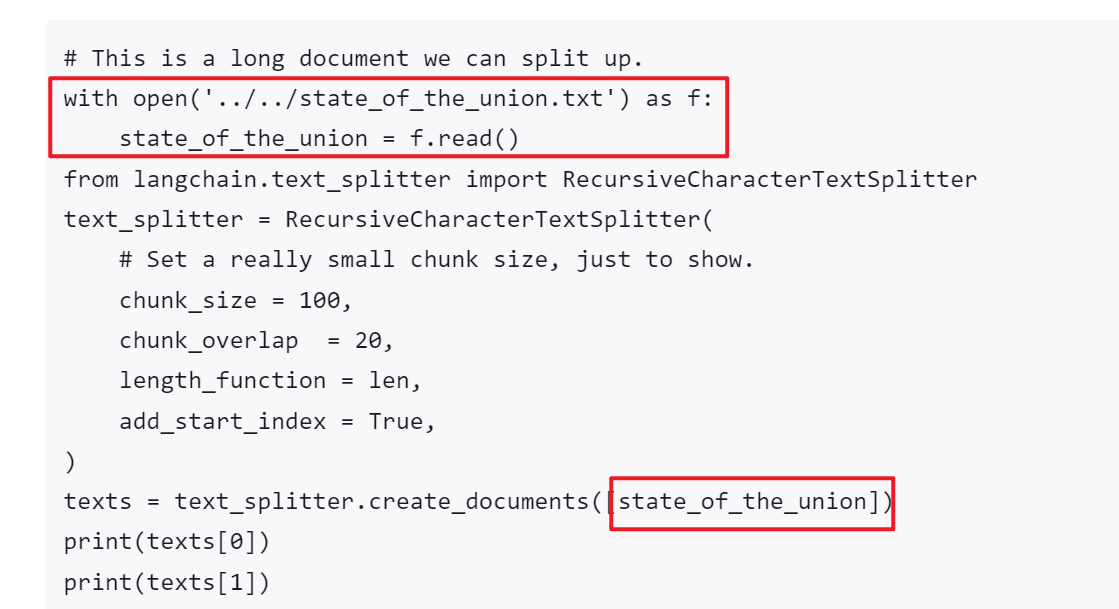
所以我这里封装一个方法,可以把一段文本封装为一个文本流:
import io
def read_from_text(text):
with io.StringIO(text) as f:
return f.read()拆分的代码:
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=200,
chunk_overlap=30,
length_function=len,
)
texts = text_splitter.create_documents([read_from_text(r.text)])效果:

下一段的开头会有一段内容和上一段结尾的内容重合的:
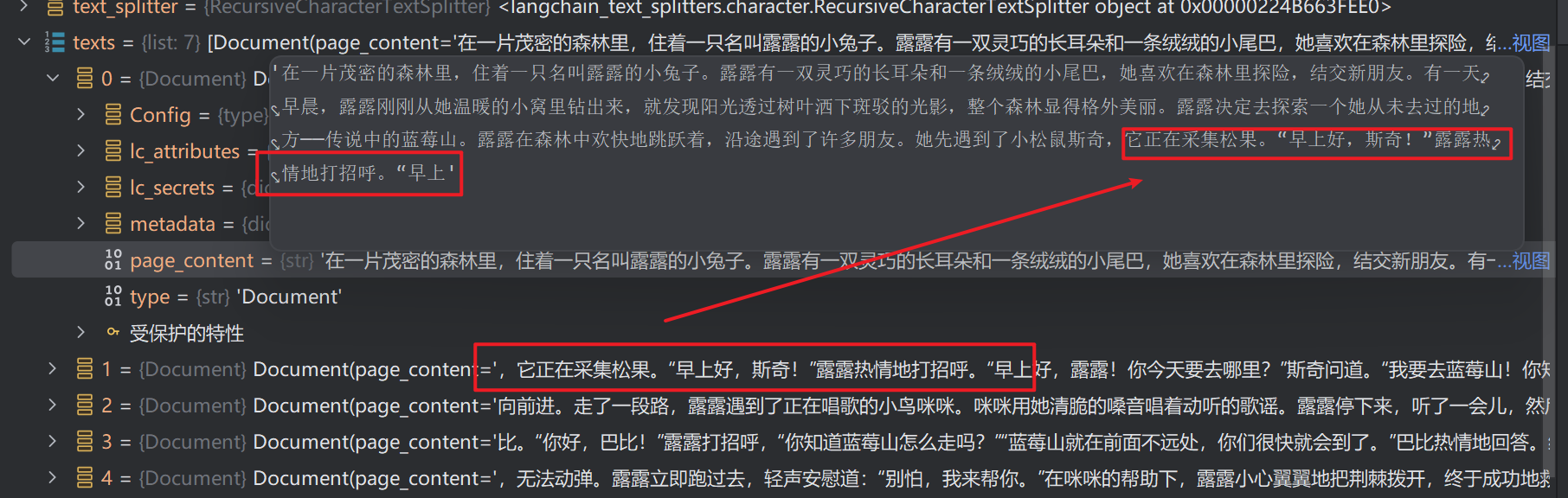
ok,拆分这一步完成了,接下来就是有多少段就向量化几次并入库:
texts = text_splitter.create_documents([read_from_text(r.description)])
job_dao = JobInfoVectorDao()
for text in texts:
vector = self.text_to_vector(app, text.page_content)
if not vector:
continue
# 数据入库
job_dao.add(JobInfoVectorModel(
id=str(uuid.uuid4()),
city_id=r.city_id,
city_name=r.city_name,
post_id=r.post_id,
post_name=r.post_name,
description=text.page_content,
description_vector=json.dumps(vector),
))数据库效果如下:
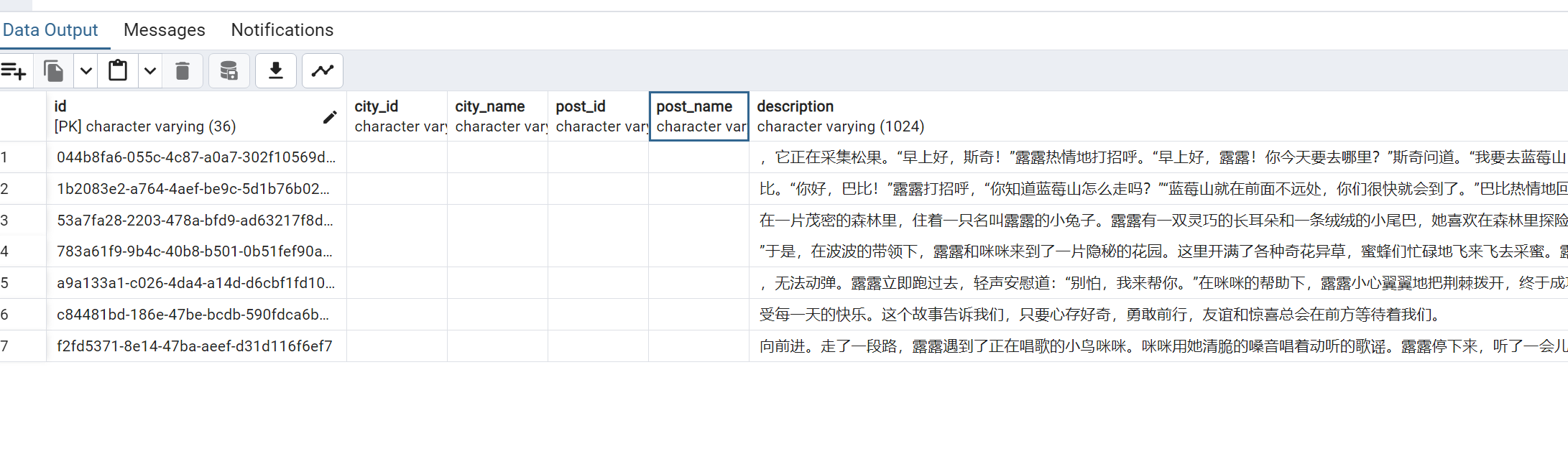
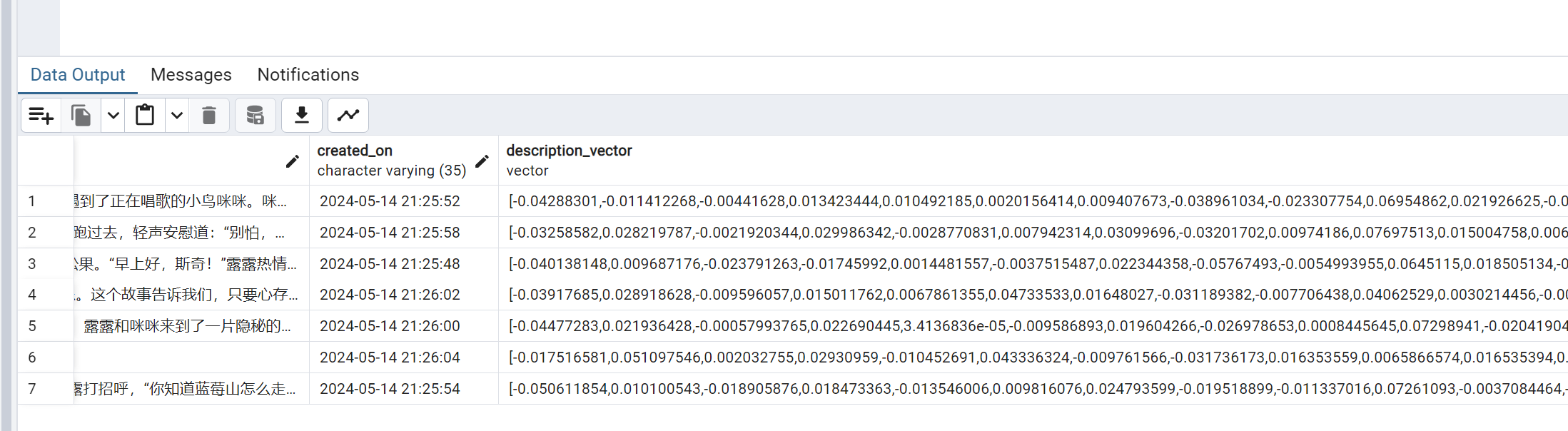
OK!向量的拆分和入库完成。
这里文本转向量的方法用的是智谱的。
接下来就是搜索了:
pgvector官网就有搜索的sql,直接拿过来再结合自己的项目就行,我这里也直接用原生sql了。
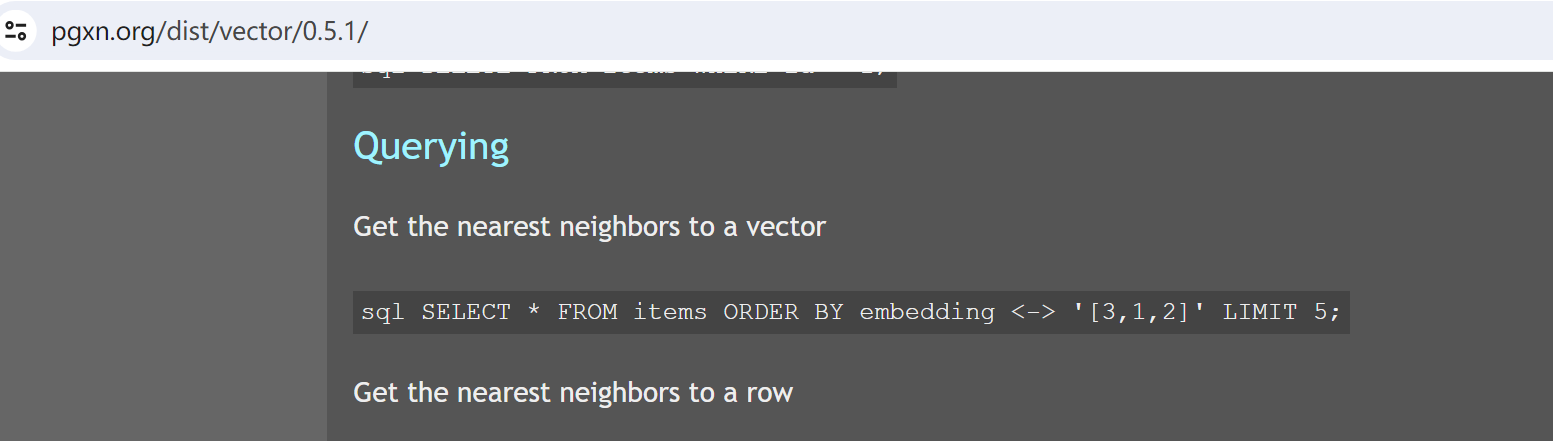
调一下智谱的embedding接口看看效果,首先我们得先有向量数据:
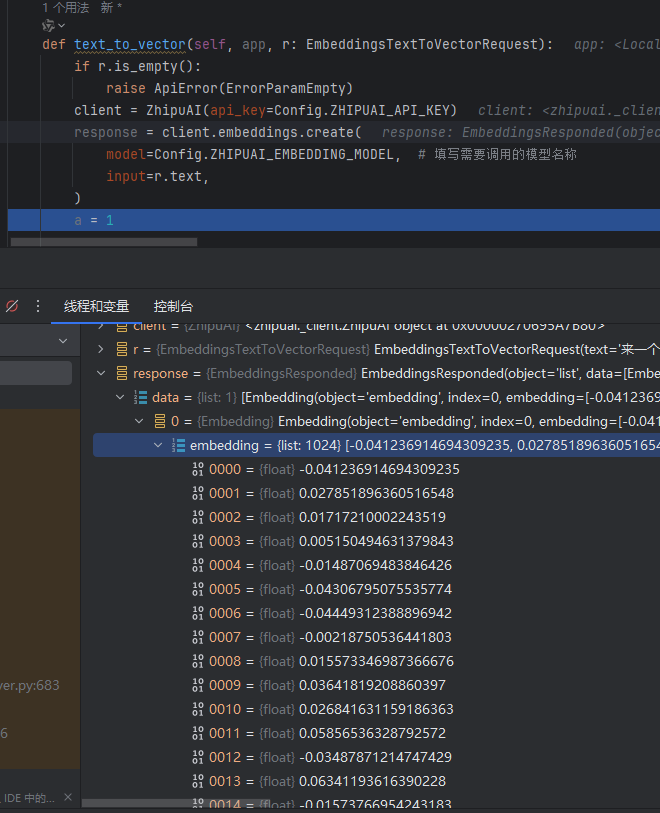
text_embedding接口文档:https://open.bigmodel.cn/dev/api#text_embedding
拿到结果后就需要入库了,我这边的代码:
# 先拆分
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=Config.ZHIPUAI_EMBEDDING_CHUNK_SIZE,
chunk_overlap=Config.ZHIPUAI_EMBEDDING_CHUNK_OVERLAP,
length_function=len,
)
texts = text_splitter.create_documents([read_from_text(r.description)])
job_dao = JobInfoVectorDao()
for text in texts:
vector = self.text_to_vector(app, text.page_content)
if not vector:
continue
# 数据入库
job_dao.add(JobInfoVectorModel(
id=str(uuid.uuid4()),
city_id=r.city_id,
city_name=r.city_name,
post_id=r.post_id,
post_name=r.post_name,
description=text.page_content,
description_vector=json.dumps(vector),
))
return self.return_dataclass(EmbeddingsTextToVectorResponse(
success=True,
chunk_count=len(texts),
chunk_size=Config.ZHIPUAI_EMBEDDING_CHUNK_SIZE,
chunk_overlap=Config.ZHIPUAI_EMBEDDING_CHUNK_OVERLAP,
))我让ChatGPT给了我们一批内容用来训练:
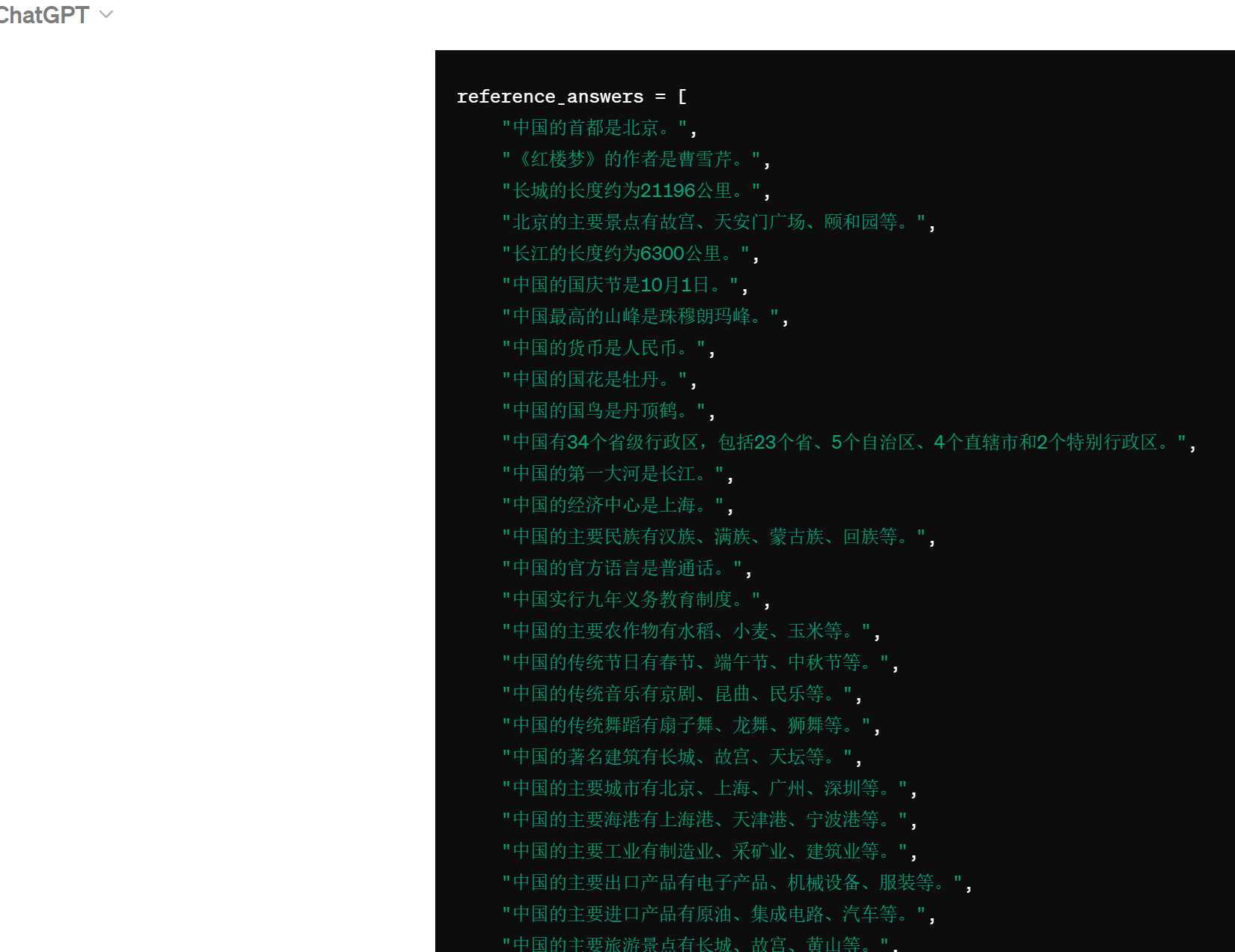
然后我逐个调用智谱的embedding入库,结果如下:
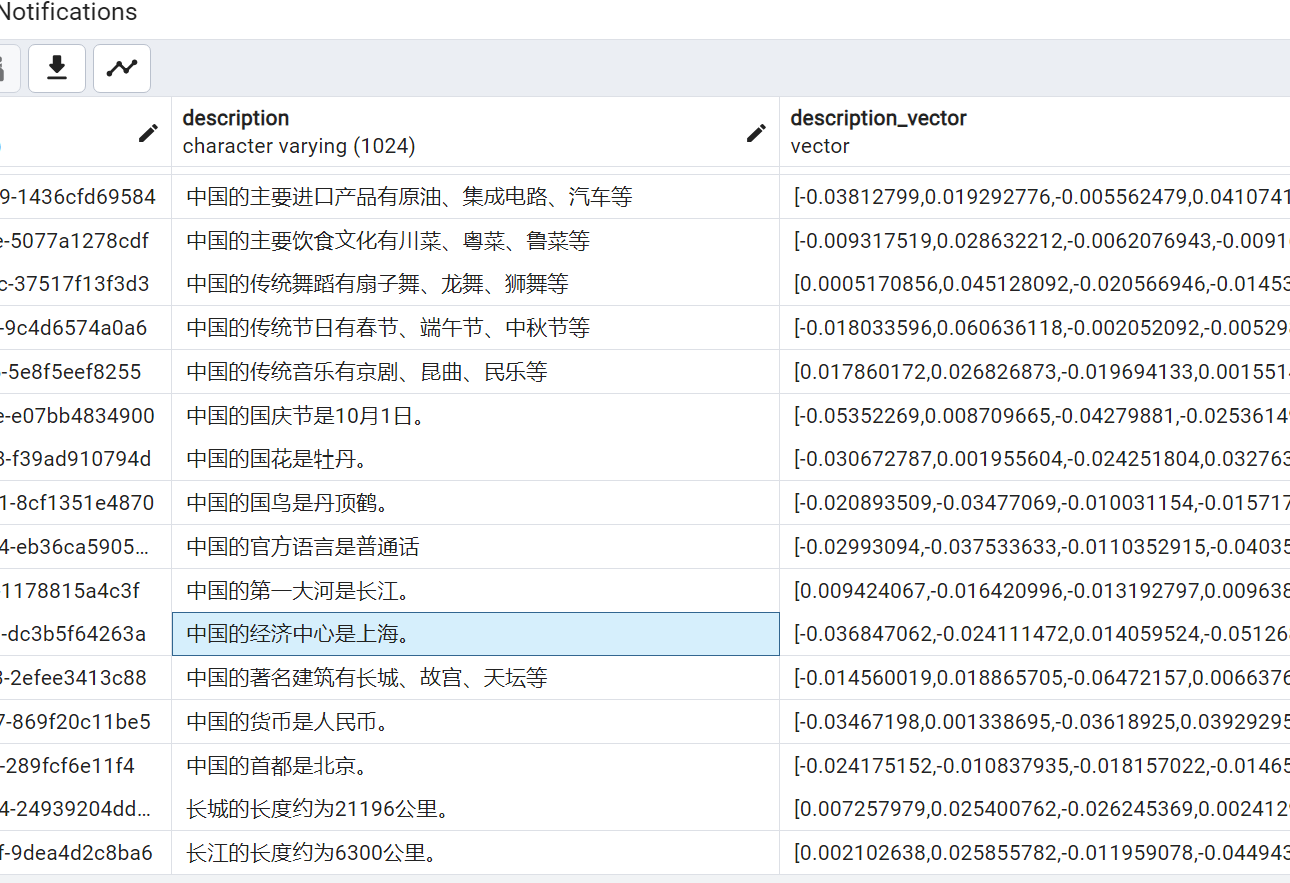
然后我的查找的代码:
from sqlalchemy import text
def get_list(self, model: JobInfoVectorModel, r: EmbeddingsTextToVectorSearchRequest):
where_sql = "where 1 = 1"
if not is_empty(r.city_id):
where_sql += " and city_id = :city_id "
if not is_empty(r.city_name):
where_sql += " and city_name = :city_name "
if not is_empty(r.post_id):
where_sql += " and post_id = :post_id "
if not is_empty(r.post_name):
where_sql += " and post_name = :post_name "
order_sql = f"ORDER BY description_vector <-> '{json.dumps(r.description_vector)}' ASC"
limit_sql = f" LIMIT 5 "
query_sql = text(f"select id, city_id, city_name, post_id, post_name, description, "
f"created_on from {model.__tablename__} {where_sql} {order_sql} {limit_sql}")
result = db.session.execute(query_sql, {
'city_id': r.city_id,
'city_name': r.city_name,
'post_id': r.post_id,
'post_name': r.post_name
}).fetchall()结果还是很不错的,见下图:
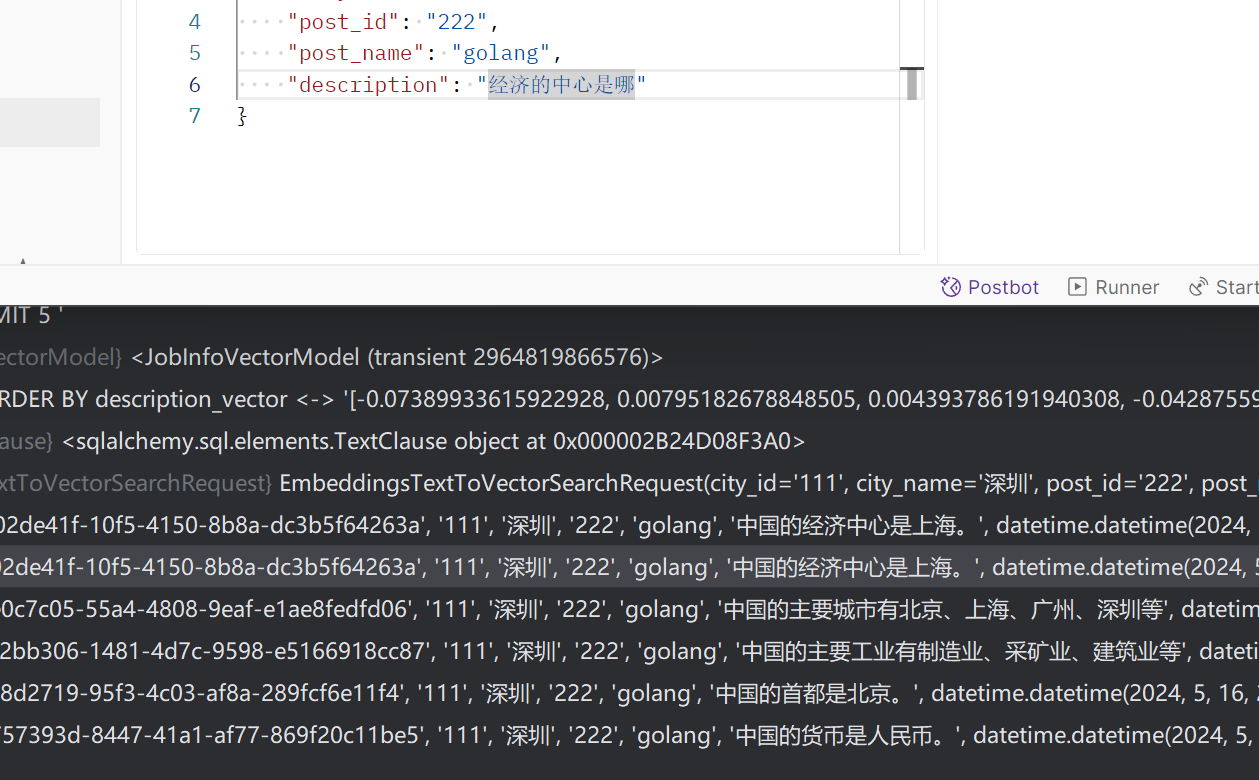

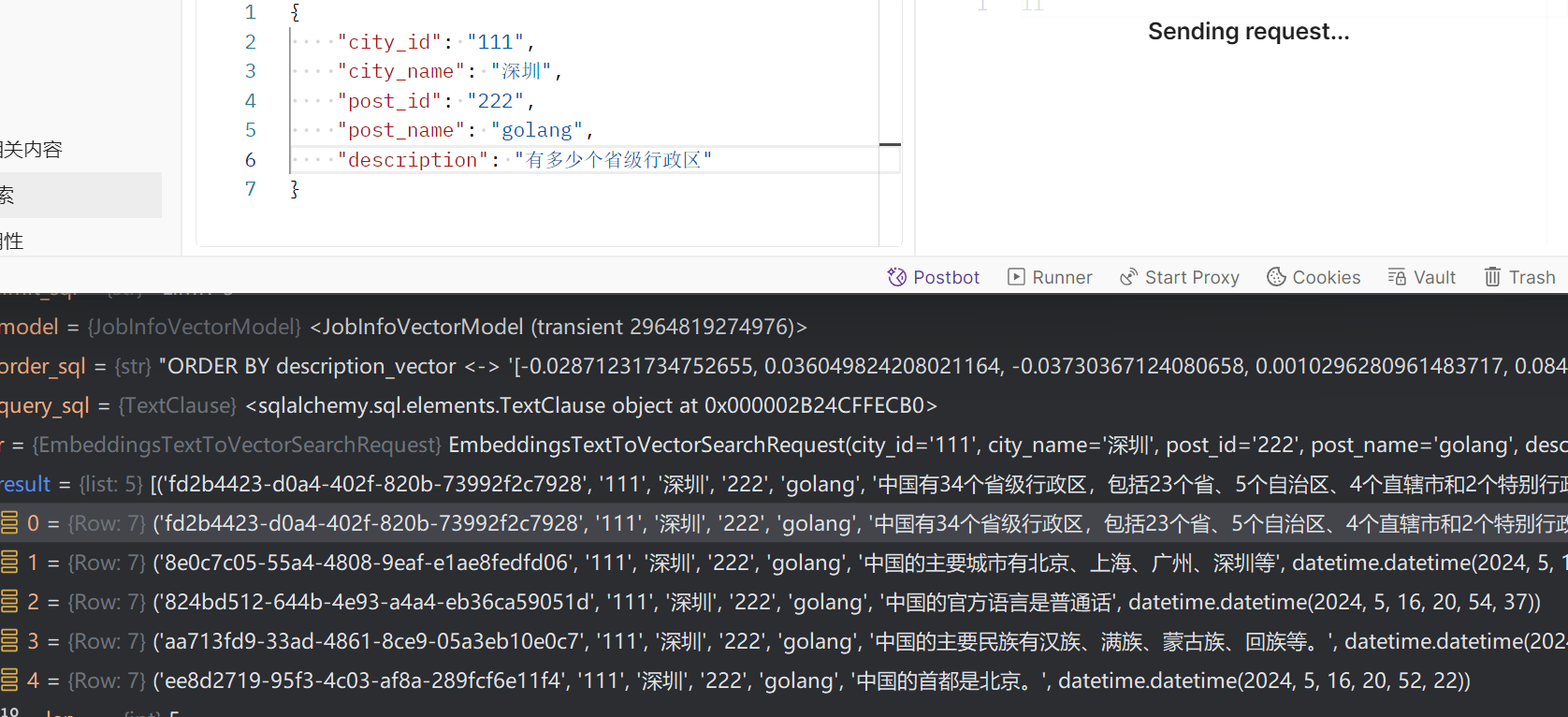
又学到一个新知识!满足。
这篇文章就到这里啦!如果你对文章内容有疑问或想要深入讨论,欢迎在评论区留言,我会尽力回答。同时,如果你觉得这篇文章对你有帮助,不妨点个赞并分享给其他同学,让更多人受益。
想要了解更多相关知识,可以查看我以往的文章,其中有许多精彩内容。记得关注我,获取及时更新,我们可以一起学习、讨论技术,共同进步。
感谢你的阅读与支持,期待在未来的文章中与你再次相遇!
我的微信公众号:【xdub】,欢迎大家订阅,我会同步文章到公众号上。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











