






gem5内存系统
本文档描述了gem5中的内存子系统,重点是CPU在简单内存事务(读取或写入)期间的程序流程。
模型层次
本文档使用的模型包括两个超标量(O3)ARM v7 CPU,每个CPU配有相应的L1数据缓存和简单内存。该模型是通过以下参数运行gem5创建的:
configs/example/fs.py --caches --cpu-type=arm_detailed --num-cpus=2Gem5使用派生自Simulation Objects的对象作为构建内存系统的基本块。这些对象通过端口连接,建立了主/从层次结构。数据流在主端口上启动,而响应消息和监听查询出现在从端口上。
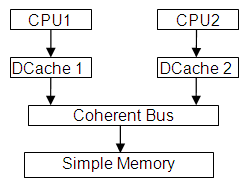
CPU
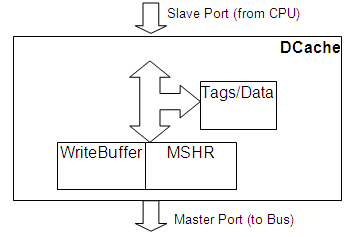
Data Cache 对象实现了标准的缓存结构:
本文件并不详细描述O3 CPU模型,因此仅提供一些关于该模型的相关说明:
读访问 通过向DCache对象的端口发送消息来启动。如果DCache拒绝消息(因为被阻塞或忙碌),CPU将刷新管道,并且访问将在稍后重新尝试。访问在接收到来自DCache的回复消息(ReadRep)时完成。
写访问 通过将请求存储到存储缓冲区中来启动,该缓冲区的上下文在每个时钟周期被清空并发送到DCache。DCache也可能会拒绝请求。写访问在收到来自DCache的写回复(WriteRep)消息时完成。
加载和存储缓冲区(用于读写访问)对活动内存访问的数量没有限制。因此,CPU的最大内存访问请求数量不受CPU仿真对象的限制,而是由底层内存系统模型决定。
分裂内存访问(Split memory access) 已实现。
CPU发送的消息包含所访问区域的内存类型(普通、设备、强序和缓存性)。然而,模型的其余部分并没有使用这些信息,而是对内存类型采取了更简化的方法。
数据缓存对象
数据 Cache 对象实现了标准的缓存结构:
缓存内存读取 如果匹配特定的缓存标签(带有有效和读取标志),将在配置的时间后完成(通过向CPU发送ReadResp)。否则,请求将转发到未命中状态和处理寄存器(MSHR)块。
缓存内存写入 如果匹配特定的缓存标签(带有有效、读取和写入标志),将在相同的配置时间后完成(通过向CPU发送WriteResp)。否则,请求将转发到未命中状态和处理寄存器(MSHR)块。
未缓存内存读取 将转发到 MSHR 块。
未缓存内存写入 将转发到写缓冲区块。
驱逐(且脏)缓存行 将转发到写缓冲区块。
如果以下任何条件为真,则CPU对数据 Cache 的访问将被阻塞:
-
MSHR 块已满。(MSHR缓冲区的大小是可配置的。)
-
写回块已满。(该块缓冲区的大小是可配置的。)
-
针对相同内存缓存行的未完成内存访问数量已达到配置的阈值——有关详细信息,请参见 MSHR 和写缓冲区。
数据 Cache 在块状态下将拒绝来自从端口(来自CPU)的任何请求,无论是否会导致缓存命中或未命中。注意,主端口上的传入消息(响应消息和监听请求)永远不会被拒绝。
在不可缓存的内存区域上发生 Cache 命中(根据ARM ARM的不可预测行为)将使缓存行无效并从内存中提取数据。
标签(Tags)与数据块
Cache 行(在源代码中称为块)被组织成具有可配置关联度和大小的集合。它们具有以下状态标志:
-
有效(Valid)。表示缓存行持有数据,地址标签是有效的。
-
读取(Read)。没有此标志设置的情况下,不会接受读取请求。例如,缓存行在等待写标志完成写入访问时,是有效但不可读的。
-
写入(Write)。可能接受写入。具有写入标志的缓存行表示唯一状态——没有其他缓存内存持有该副本。
-
脏(Dirty)。在驱逐时需要写回。
如果地址标签匹配且有效和读取标志被设置,则读取访问会命中缓存行。如果地址标签匹配且有效、读取和写入标志被设置,则写入访问会命中缓存行。
MSHR和写缓冲队列
未命中状态和处理寄存器(MSHR)队列持有需要访问下一级内存的CPU未完成内存请求列表。这些请求包括:
-
缓存读取未命中。
-
缓存写入未命中。
-
未缓存的读取。
写缓冲区队列持有以下内存请求:
-
未缓存的写入。
-
从驱逐(且脏)缓存行的写回。
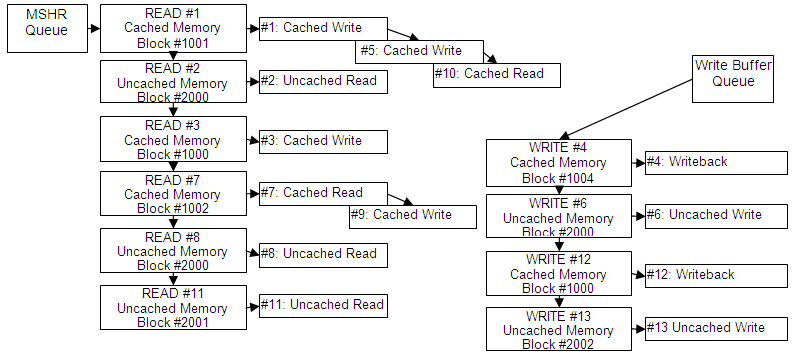
每个内存请求被分配到相应的 MSHR 对象(如图中所示的READ或WRITE),该对象代表必须读取或写入的特定内存块(缓存行),以完成命令。当对同一缓存行进行缓存读取/写入时,它们会共享一个 MSHR 对象,并通过一次内存访问完成。
块的大小(因此读取/写入访问下一级内存的大小)为:
-
对于缓存访问和写回,大小等于缓存行的大小;
-
对于未缓存访问,根据 CPU 指令指定的大小。
通常,数据 Cache 模型区分两种内存类型:
-
普通缓存内存(Normal Cached memory)。总是视为写回、读取和写入分配。
-
普通未缓存内存(Normal uncached)、设备(Device)和强排序(Strongly Ordered)类型被同等对待(视为未缓存内存)。
内存访问顺序
每个CPU读取/写入请求(在从属端口上出现时)会被分配一个唯一的顺序号。 MSHR 对象的顺序号从第一次分配的读取/写入请求中复制。
来自这些两个队列的内存读/写操作按顺序执行(根据分配的顺序号)。当两个队列都不为空时,模型将执行来自 MSHR 块的内存读取,除非写缓冲区已满。然而,模型将始终保持对同一(或重叠)内存缓存行(块)的读/写顺序。
总结:
-
对于缓存内存的访问顺序,除非它们针对同一缓存行,否则不会被保留。例如,访问#1、#5和#10将在同一时钟周期内同时完成(仍然按照顺序)。访问#5将在#3之前完成。
-
所有未缓存内存写入的顺序会被保留。Write#6始终在Write#13之前完成。
-
所有未缓存内存读取的顺序会被保留。Read#2始终在Read#8之前完成。
-
对未缓存内存的读取和写入访问的顺序不一定会被保留,除非它们的访问区域重叠。因此,Write#6 始终在 Read#8 之前完成(它们针对同一内存块)。然而,Write#13可能会在Read#8之前完成。
一致性总线对象
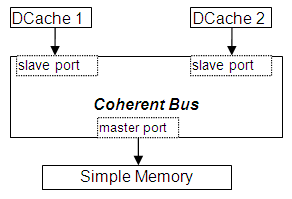
一致性总线对象
一致性总线对象提供了对snoop协议的基本支持:
-
所有在从属端口的请求都被转发到相应的主端口。对于缓存内存区域的请求,还会将其转发到其他从属端口(作为snoop请求)。
-
主端口的回复被转发到相应的从属端口。
-
主端口的snoop请求会被转发到所有从属端口。
-
从属端口的snoop回复被转发到请求来源的端口。(注意,snoop请求的来源可以是从属端口或主端口。)
总线在以下事件发生后会在可配置的时间内进入阻塞状态:
-
将数据包发送(或尝试发送)到从属端口。
-
向主端口发送回复消息。
-
从一个从属端口发送到另一个从属端口的snoop响应。
总线处于阻塞状态时,会拒绝以下传入消息:
-
从属端口的请求。
-
主端口的回复。
-
主端口的snoop请求。
简单内存对象
简单内存对象不会阻塞从属端口的访问。
内存的读取/写入会立即生效。(在接收到请求时会执行读取或写入操作。)
回复消息会在可配置的时间后发送。
消息流
内存读访问顺序
以下图示显示了命中的Data Cache行的读取访问,其中包含有效(Valid)和读取(Read)标志:

缓存未命中的读访问将生成以下消息序列:
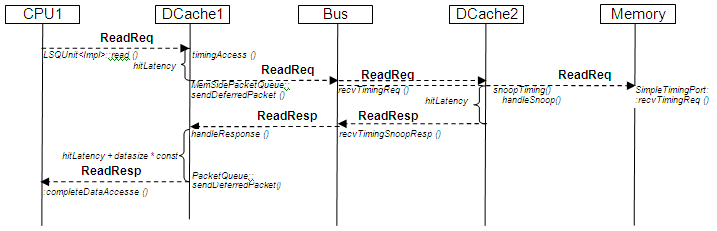
请注意,总线对象不会从DCache2和内存对象处获得回复。它将相同的ReadReq数据包(消息)发送给内存和数据缓存。当数据缓存要回复snoop请求时,它会将消息标记为MEM_INHIBIT标志,告知内存对象不要处理该消息。
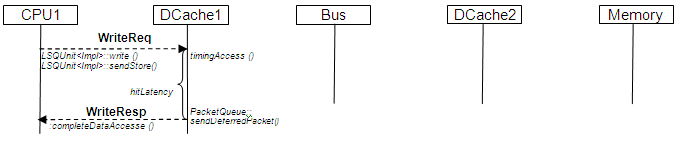
内存写访问顺序
以下图示展示了写访问命中DCache1缓存行的情况,该缓存行具有有效(Valid)和写入(Write)标志:
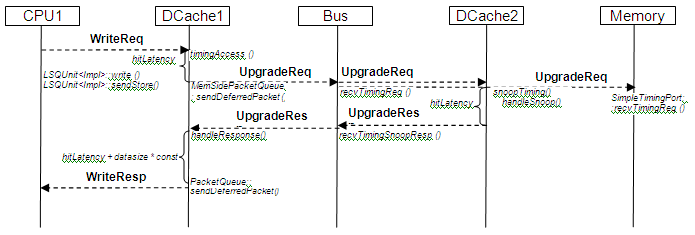
下一个图示展示了写访问命中DCache1缓存行的情况,该缓存行具有有效(Valid)标志但没有写入(Write)标志——这被视为写未命中。DCache1会发出UpgradeReq请求以获取写权限。DCache2::snoopTiming将使已命中的缓存行失效。请注意,UpgradeResp消息不携带数据。
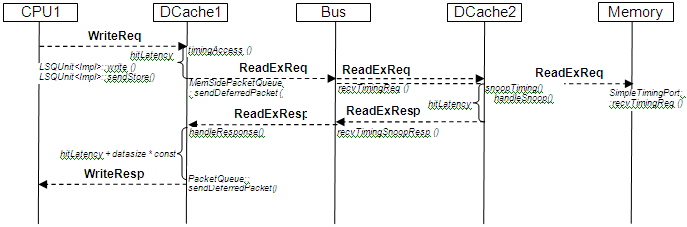
下一个图示展示了DCache中的写未命中。ReadExReq会使DCache2中的缓存行失效。ReadExResp携带了内存缓存行的内容。















 1171
1171

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









