







集群架构
基本概念
集群:
集群由一个或多个Region组成,Region 由一个或多个Zone组成,Zone由一个或多个OBServer组成,每个OBServer里有若干个partition的Replica。
Region:
对应物理上的一个城市或地域,当OB集群由多个Region组成时, 数据库的数据和服务能力就具备地域级容灾能力,当集群只有一个Region时,如果出现整个城市级别的故障,则会影响数据库的数据和服务能力;
Zone:
一般情况下对应一个有独立网络和供电容灾能力的数据中心,在一个Region内的多个Zone之间OB数据库拥有Zone故障时的容灾能力
OBServer:
运行observer进程的物理机,一台物理机上可以部署一个或多个observer,在ob中,ip+端口唯一
Partition:
ob中以分区为单位组织用户数据,分区在不同机器上的数据拷贝称为副本(replica),同一分区的多个副本使用paxos一致性协议保障副本的强一致性,每个分区和他的副本构成一个独立的paxos组,其中一个分区为主副本(leader),其他分区为从副本(Follower),主副本具备强一致性读写能力,从副本具备弱一致性读能力
部署模式
为保证单一机器故障时同一分区的多数派副本可用,OB数据库会保证同一个分区的多个副本不调度在同一台机器上。由于同一个分区的副本分布在不同的zone/region下,在城市级灾难或者数据中心故障的时保证了数据的可靠性,由保证了数据服务的可用性,达到可靠性与可用性的平衡。OB数据库创新的容灾能力有三地五中心可以无损容忍城市级灾难,以及同城三中心可以无损容忍数据中心级故障。
三地五中心部署

同城三中心部署

RootService
Ob数据库集群会有一个总控服务(Root Service),其运行在某个OBServer上。当Root Service所在的机器故障时,其余的OBServer会选举出新的Root Service,Root Service主要提供资源管理、负载均衡、schema管理等功能,一般情况下,一个zone一个root service
- 资源管理
- 包括Region/Zone/OBServer/Resource Pool/Unit 等元信息管理,比如:上下线OBServer、改变Tenant资源规格等;
- 负载均衡
- 决定Unit/Partition在多个机器间的分布,均衡机器上主分区的个数,在容灾场景下通过自动复制/迁移补充缺失的Replica
- schema管理
- 负责处理DDL请求并生成新的schema
Locality
Locality描述 表或者租户下副本的分布情况。这里的副本分布情况指在Zone上包含的副本的数量以及副本的类型。
- 租户的partition的副本数,增加副本数量:3变5,由
F@z1,F@z2,F@z3变更为F@z1,F@z2,F@z3,F@z4,F@z5可以逆向 - 集群搬迁:从
F@hz1,F@hz2,F@hz3变更为F@hz1,F@sh1,F@sh2,
租户下分区在各个zone上的副本分布和类型称为Locality,我们可以通过建租户指定locality的方式决定租户下分区初始的副本类型和分布。后续可通过改变租户Locality的方式进行修改。
-- 创建租户时指定locality
CREATE TENANT mysql_tenant RESOURCE_POOL_LIST =('resource_pool_1'), primary_zone = "z1;z2;z3", locality ="F@z1, F@z2, F@z3" set ob_tcp_invited_nodes='%',ob_timestamp_service='GTS';
-- 修改租户的locality
ALTER TENANT mysql_tenant set locality = "F@z1, F@z2, L@z3";
-- 表示z1有一个全能型副本,2个只读型副本
locality = "F{1}@z1, R{2}@z1"
-- 表示z1有一个全能型副本,并在同zone其余机器上创建只读型副本
locality = "F{1}@z1, R{ALL_SERVER}@z1
- 一个分区,在一个zone内,最多存在一个paxos副本,可以有若干个非paxos副本;
- RootService会根据用户设置的locality,通过创建/删除/迁移/类型转换的方式,使分区的副本分布和类型满足用户配置的locality;
primary zone
- 通过设置Primary zone来设置Leader副本的位置偏好,实际是一个zone的列表
- 用
;分隔,表示从高到低的优先级; - 用
,分隔,表示相同优先级 ;和,可以混合使用
- 用
- Primary zone具有继承关系,向上继承 Table级-> Table Group级 -> Database级(MySQL)/Schema级(Oracle)-> Tenant级
- Table 优先使用自己,自己没有使用Table Group的
- Table Group 优先使用自己的,自己没有直接使用Tenant的
- Database 优先使用自己的,自己没有,直接使用Tenant的
RootService会根据用户设置的primary zone按照优先级高低顺序,尽可能把分区leader调度到更高优先级的zone内。
多租户架构
- ob数据库通过租户实现资源隔离,每个数据库服务的实例不感知其他实例的存在;
- 通过权限控制确保租户数据的安全性;
- 租户是一个逻辑概念,租户是资源分配的单位。可以理解为一个MySQL实例
有以下特点:
- 不允许跨租户的数据访问,以确保用户的数据资产没有被其他租户窃取的风险
- 租户独占其资源配额

第一章:分布式架构高级技术
聚合资源的物理表示
一个集群由若干个zone组成。zone在oceanbase.__all_zone表
zone是什么?
- zone是可用区 availability zone的简写
- 是一个逻辑概念,是对物理机进行管理的容器
- 一般是同一机房的一组机器的组合;
- 从物理层面讲,一个zone通常等价一个机房、一个数据中心或一个IDC;
- zone可以是一个机架,也可以是一个机房,也可以是一个区域,一般为了性能最起码一个zone要在一个机房里
- 为了交付高级别的Oceanbase,通常会将3个Zone分布在3个机房中,
- 每一个机房对应的是一个IDC,3个机房都在一个Reigon中,表示归属性

zone主要有两种类型
-
读写zone
- 具备读写属性的zone,支持部署全功能型副本、只读副本、普通日志型副本
-
加密zone
- 具备加密属性的zone,仅支持部署加密日志型副本。
zone 操作(只能在sys租户中执行)
-
可以添加:
ALTER SYSTEM ADD ZONE zone_name [zone_option_list];,zone_option_list指定目标zone的属性,有多个用,分隔- region:zone所在region的名称,默认
default_region - idc: 指定机房名称
- Zone_type: 指定zone为读写zone(readwrite)或加密zone(encryption)
- region:zone所在region的名称,默认
-
可以删除:
ALTER SYSTEM DELETE ZONE zone_name ;- 删除之前必须清空zone里的observer
-
可以启动: 每次只能操作一个zone,当前zone操作完以后才可以下一个
ALTER SYSTEM START ZONE zone_name;
-
可以停止,停止的时候都会检查多数派副本均在线,是一个必要条件
- 每条语句每次仅支持启动或停止一个 Zone
- 主动停止zone:
ALTER SYSTEM STOP ZONE zone1;,- 会检查各分区数据副本的日志是否同步
- 多数派副本均在线
- 达到以上两个条件才能执行成功
- 强制停止zone:
ALTER SYSTEM FORCE STOP ZONE Zone1,- 只检查多数派均在线,不管日志是否同步
- ocp上停止zone,包含了停zone和停zone上observer的操作
-
可以隔离:
ALTER SYSTEM ISOLATE ZONE 'zone1' -
可以重启,只支持ocp 白屏操作,重启时融合多了多个命令的集合;
-
可以修改:其实就是给zone设置各种标签,
ALTER SYSTEM ALTER ZONE zone1 SET REGION='HANGZHOU',IDC='HZ1';
OB资源的分配流程
- 集群初始化以后,默认会创建一个系统租户sys,sys租户的配置可以在启动observer的时候指定
可根据用户需求创建业务租户
- 先创建资源规格;
- 根据资源规格创建资源池;
- 根据资源池创建用户;
配置管理☆
配置项,用于运维,控制机器及以上级别的行为,paramters
配置项主要用于运维,常用于控制机器及其以上级别的系统行为;使用paramters
- **生效范围:**集群、租户、zone、机器。
- 生效方式:动态生效、和重启生效;
- 修改方式:
- 通过sql语句修改:
alter system set 参数名=参数值 - 通过启动参数修改:
xxx -o "参数名='参数值'"
- 通过sql语句修改:
- 持久化:持久化到内部表与配置文件中;
- 查询方式:
show paramters- 示例:
show parameters like '参数名'
- 示例:
查看配置项语法:
-- 语法:
SHOW PARAMETERS [LIKE 'pattern' | WHERE expr] [TENANT = tenant_name]
-- 示例:
SHOW PARAMETERS WHERE scope = 'tenant';
SHOW PARAMETERS WHERE svr_ip != 'XXX.XXX.XXX.XXX';
SHOW PARAMETERS WHERE INFO like '%ara%';
SHOW PARAMETERS LIKE 'large_query_threshold';
系统变量和session绑定,控制session级别的行为,通过variables查询
系统变量通常和用户session绑定,用于控制session级别的sql行为;
支持设置Global和session级别的变量。
-
global变量设置以后,当前session上不会生效,新建的session生效;
-
生效范围: 租户的Global级别或session级别;
-
生效方式:设置session级别的,直接生效;全局级别的,新的连接才会生效;
-
修改方式:
- 两种模式都支持的语法:
- session级别:
set 变量名= 变量值 - global级别:
set global 变量名= 变量值
- session级别:
- Oracle模式多了下面的语法:
alter session set 变量名= 变量值alter system set 变量名= 变量值
- 两种模式都支持的语法:
-
持久化:仅global级别会持久化,session级别,session关闭就失效;
-
查询方式:
show variables加上global 查全局- 两种模式都支持的语法
- session级别
SHOW VARIABLES LIKE 'ob_query_timeout'; - global级别:
SHOW GLOBAL VARIABLES LIKE 'ob_query_timeout';
- session级别
- MySQL模式支持的语法:在对应的表中查询系统变量
- session级别
SELECT * FROM INFORMATION_SCHEMA.SESSION_VARIABLES WHERE VARIABLE_NAME = 'ob_query_timeout'; - global级别:
SELECT * FROM INFORMATION_SCHEMA.GLOBAL_VARIABLES WHERE VARIABLE_NAME = 'ob_query_timeout';
- session级别
- Oracle 模式支持的语法,在对应的表里查询系统变量
- session级别:
SELECT * FROM SYS.TENANT_VIRTUAL_GLOBAL_VARIABLE WHERE VARIABLE_NAME = 'ob_query_timeout'; - global级别:
SELECT * FROM SYS.TENANT_VIRTUAL_SESSION_VARIABLE WHERE VARIABLE_NAME = 'ob_query_timeout';
- session级别:
- 两种模式都支持的语法
| 对比项 | 配置项 | 系统变量 |
|---|---|---|
| 作用 | 租户、机器、zone、集群 | 当前租户的会话session |
| 生效方式 | 动态生效、重启 | session级别的,直接生效,全局级别的,新的连接才会生效 |
| 查询方式 | show paramters like ‘’ | session级别的查询:show variables like ‘xxxx’ global级别的查询: show global variables like ‘xxxx’ |
| 设·置方式 | Sql,修改:alter system set 变量名 = 启动加参数`xxx -o "参数名=‘参数值’ | MySQL和Oracle都支持: session级别:set 变量名=变量值 global级别:set global 变量名= 变量值 MySQL存储在information_schema的两张session表中 |
| 持久化 | 会 | global会持久化,session级别关闭就失效 |
资源管理
- 资源单元(Resource Unit )
- 资源单元是一个容器(可以理解为一个虚拟机)。实际上,副本是存储在资源单元之中的,所以资源单元是副本的容器。资源单元包含了计算存储资源(memory、cpu和IO等)同时资源单元也是集群负载均衡的一个基本单位,在集群节点上下线、扩容、缩容时会动态调整资源单元在节点上的分布进而达到资源的使用均衡。
- 资源池(Resource Pool)
- 一个资源池由具有**相同资源配置(创建以后可以修改配置)**的若干个资源单元组成,一个资源池只能属于一个租户
- 一个租户在同一个server上最多有一个资源单元
- 资源配置(Resource Unit Config)
- 资源配置是资源单元的配置信息,用来描述资源池中每个资源单元可用的CPU、内存、存储空间和IOPS等,修改资源配置可以动态调整资源单元的规格。
资源单元(unit)可复用
-- 创建或修改资源单元
CREATE/ALTER RESOURCE UNIT unitname cpu/memory/iops/disk_size/session_num等;
- session_num 最小为64,
- iops:MIN_IOPS最小为128,MAX_IOPS
- memory 最小1G ,需要配置参数,配置以后才可以
- cpu可以0.5个单位
- disk_size 最小512M
-- 删除资源单元
drop resource unit unitname;
-- 查看资源单元配置
select * from __all_unit_config;
示例
# 创建资源单元
create resource unit ut_5c2g max_cpu=2,max_memory='1G',max_iops=10000,max_disk_size='10G',max_session_num=10000;
#修改资源单元
alter resource unit ut_5c2g max_cpu=5,max_memory='2G';
# 查看资源单元配置
select * from __all_unit_config where name ='ut_5c2g';
# 删除资源单元
drop resource unit ut_5c2g;
资源池(pool)
资源池的创建,
- 可以指定在哪些zone创建,
- 一个zone里创建几个(一个zone里创建的unit_num<=observer的数量)
资源池的修改
- 只能由
sys租户的管理员执行 - 修改资源池的命令一次仅支持修改一个参数
-- 创建或修改资源池
create/alter resource pool poolname # 资源池名称
unit='资源规格'
unit_num =(要小于zone中server的数量) #表示在集群的一个zone里面包含的资源单元的个数,该值<=一个zone中的observer的数量
zone_list=(‘z1’,‘z2’) # 表示资源池所在的zone列表,显示该创建的资源使用哪些zone,创建到哪些zone里
-- 查看资源池
select * from __all_resource_pool;
-- 删除资源池
drop resource pool poolname;
-- 合并资源池 把哪些资源池merge到一个资源池中
ALTER RESOURCE POOL MERGE
('pool_name'[, 'pool_name' ...])
INTO ('merge_pool_name')
-- 分裂资源池 ,主要是解决zone上的物理机规格差异较大的时候,可以分裂开以后,给每个资源池单独设规格
ALTER RESOURCE POOL SPLIT INTO ('pool_name' [, 'pool_name' ...]) ON ('zone' [, 'zone' ...])
-- 从租户中移除资源池,主要用于在减少租户副本数的场景中
ALTER TENANT tenant_name RESOURCE_POOL_LIST [=](pool_name [, pool_name...]) ;
-- 查看资源的分配情况
SELECT * FROM oceanbase.gv$unit;
- 资源池可包含不同规格的资源规格
- 资源池创建时只能指定一个资源规格
- 资源池可以合并
- 资源池在不同的ObServer上规格可以不同
示例
-- 创建资源池
create resource pool p1_5c2g unit=ut_2c3g,unit_num=1;
-- 修改资源池
alter resource pool p1_5c2g unit=ut_5c2g;
-- 查看资源池
select * from oceabase.__all_resource_pool where name = 'p1_5c2g'
-- 删除资源池
drop resource pool p1_5c2g;
租户相关操作
租户分为系统租户和普通租户
- 系统租户,即
sys租户,是OB的内置租户,按照兼容模式属于MySQL租户,默认创建 - 普通租户,由
sys创建
注意事项:
- 租户只能由
sys租户的root操作,创建时只能绑定一个资源池; primary_zone中;由高到低,,优先级相同,RANDOM随机,必须大写;ob_compatibility_mode不指定默认是MySQL模式;- 租户的
zone_list不指定,默认使用资源池的zone_list,只能比resource_pool的少
-- 新增租户
create tenant [if not exists] tenantName
[tenant_characteristic_list] [opt_set_sys_var]
-- 说明
- tenant_characteristic_list:
tenant_characteristic [, tenant_characteristic...]
# 租户参数列表
- tenant_characteristic:
COMMENT 'string' # 租户的注释信息
|{CHARACTER SET | CHARSET} [=] charsetname # 指定字符集
|COLLATE [=] collationname # 指定租户的字符序
|ZONE_LIST [=] (zone [, zone…]) # 指定租户的zone列表,默认集群内所有的zone
|PRIMARY_ZONE [=] zone #指定主zone的顺序,为leaber副本的偏好顺序 例如:'zone1;zone2,zone3' zone1>zone2=zone3,不设置,默认均匀分布,也就是以,分隔
|DEFAULT TABLEGROUP [=] {NULL | tablegroup}# 表组信息
|RESOURCE_POOL_LIST [=](poolname [, poolname…]) # 指定资源池,创建时只能指定一个
|LOGONLY_REPLICA_NUM [=] num
|LOCALITY [=] 'locality description' # 指定副本在zone之间的分布情况, 例如:F@z1,F@z2,F@z3,R@z4 表示 z1、z2、z3 为全功能副本,z4 为只读副本
opt_set_sys_var:
{ SET | SET VARIABLES | VARIABLES } system_var_name = expr [,system_var_name = expr]
- ob_compatibility_mode -- 用于指定租户的兼容模式,可选MySQL或ORACLE,默认为MySQL模式
- ob_tcp_invited_nodes -- 指定租户连接时的白名单,%为所有
-- 修改租户(对租户扩容,可以修改资源单元的规格,不能直接替换资源池)
alter tenant tenantName|ALL [SET] [tenant_option_list] [opt_global_sys_vars_set]
- tenant_option_list:
tenant_option [, tenant_option ...]
- tenant_option:
COMMENT [=]'string'
|{CHARACTER SET | CHARSET} [=] charsetname
|COLLATE [=] collationname
|ZONE_LIST [=] (zone [, zone…])
|PRIMARY_ZONE [=] zone
|RESOURCE_POOL_LIST [=](poolname [, poolname…])
|DEFAULT TABLEGROUP [=] {NULL | tablegroupname}
|{READ ONLY | READ WRITE}
|LOGONLY_REPLICA_NUM [=] num
|LOCALITY [=] 'locality description'
|LOCK|UNLOCK;
- opt_global_sys_vars_set:
VARIABLES system_var_name = expr [,system_var_name = expr]
-- 删除租户
drop tenant teantName [force/purge]
-- 删除租户,只有开启回收站的情况下,才会进入回收站
drop tenant tenantName;
- 开启回收站功能:进入回收站
- 关闭回收站:表示延迟删除租户,默认7天后删除(schema_history_expire_time),租户下的表和数据也会被删除
- purge 删除
- drop tenant tenantName purge;
- 延迟删除
- 不进入回收站(无论回收站是否开启)
- force 立即删除租户,无论是否开启回收站
- drop tenant tenantName force;
-- 查看租户
select * from __all_tenant;
注意:绑定到租户上的资源池,不能直接替换掉,可以通过修改资源池的资源规格来调整
示例:
-- 创建租户
create tenant obcp_t1 charset='utf8mb4', zone_list=('zone1,zone2,zone3'), primary_zone='zone1,zone2,zone3', resource_pool_list=('pl_5c2g') set ob_tcp_invited_nodes='%';
-- 修改租户,
ALTER TENANT obcp_t1 primary_zone='zone2';# 修改租户的主zone
-- 删除租户
DROP TENANT obcp_t1 force;
## 其他示例
-- 创建一个3副本的MySQL租户
CREATE TENANT IF NOT EXISTS test_tenant CHARSET='utf8mb4', ZONE_LIST=('zone1','zone2','zone3'), PRIMARY_ZONE='zone1;zone2,zone3', RESOURCE_POOL_LIST=('pool1');
-- 创建一个3副本的Oracle租户
CREATE TENANT IF NOT EXISTS test_tenant CHARSET='utf8mb4', ZONE_LIST=('zone1','zone2','zone3'), PRIMARY_ZONE='zone1;zone2,zone3', RESOURCE_POOL_LIST=('pool1') SET ob_compatibility_mode='oracle';
-- 创建 MySQL 租户,同时指定允许连接的客户端 IP
CREATE TENANT IF NOT EXISTS test_tenant CHARSET='utf8mb4',ZONE_LIST=('zone1','zone2','zone3'), PRIMARY_ZONE='zone1;zone2,zone3', RESOURCE_POOL_LIST=('pool1') SET ob_tcp_invited_nodes='%' ;
-- 确认租户是否创建成功,通过查询oceanbase.gv$tenant视图来确认租户是否创建成功
SELECT * FROM oceanbase.gv$tenant;
-- 管理员登录,默认管理员密码为空(管理员账户:MySQL模式为root,Oracle为sys)
obclient -h10.10.10.1 -P2883 -uusername@tenantname#clustername -p -A
回收站相关操作☆
- 回收站开启的时候,并不是所有的删除都会进回收站,比如 purge,只是延迟删除,并不进入
- 回收的数据库、表恢复的时候,可以重命名
- 回收站的管理主要由
sys租户来完成
-- 查看回收站是否开启,是会话级
obclient> SHOW VARIABLES LIKE 'recyclebin';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| recyclebin | ON |
+---------------+-------+
# 开启回收站
-- 全局级
SET GLOBAL recyclebin = ON/OFF
-- 会话级
SET recyclebin = ON/OFF
-- 查看回收站中的内容
show recyclebin;
-- 清空整个回收站(物理删除)
purege recyclebin;
-- 清空租户(物理删除)
PURGE TENANT tenant_name;
-- 清空数据库(物理删除)
PURGE DATABASE object_name;
PURGE TABLE object_name;
PURGE INDEX object_name;
# 恢复使用FLASHBACK恢复
FLASHBACK TENANT/DATABASE/TABLE object_name TO BEFORE DROP [RENAME to new_object_name];
-- FLASHBACK的执行顺序有从属关系的,要符合从属关系。
-- 从回收站中恢复被删除的表
FLASHBACK TABLE tbl1 TO BEFORE DROP;
-- 从回收站中恢复被删除的表x至y中表名重命名
FLASHBACK TABLE x TO BEFORE DROP RENAME TO user1.y;
- MySQL模式:进入回收站的对象有:索引、表、数据库、租户
- 直接drop索引不会进入回收站,删除表时,表的索引会跟随主表一起进入回收站
- 恢复表的时候会连同索引一起恢复
- 通过
PURGE命令可以单独删除索引 - 表组的表删除以后恢复,如果标准还在,归位,不在,就独立
- Oracle模式:进入回收站的对象有索引和表,不支持数据库和租户
资源分配情况
-
查看集群资源由各个节点的聚合情况
select zone, concat(svr_ip, ':', svr_port) observer, cpu_capacity, cpu_total, cpu_assigned, cpu_assigned_percent, mem_capacity, mem_total, mem_assigned, mem_assigned_percent, unit_Num, round('load', 2) 'load', round('cpu_weight', 2) 'cpu_weight', round('memory_weight', 2) 'mem_weight', leader_count from __all_virtual_server_stat order by zone, svr_ip;
创建租户时的资源分配
通过指定资源池分配资源
# 创建资源规格
create resource unit S2 max_cpu=20,max_mem=40G,…
create resource unit S3 max_cpu=20,max_mem=100G,…
# 创建资源池p_trade和租户tnt_trade,默认全部节点都有
create resource pool p_trade unit=S2,unit_num=1;
create tenant tnt_trade resourcepool=p_trade
# 创建资源池p_pay 和租户tnt_pay
create resource pool p_pay unit=S3,unit_num=2;
create tenant tnt_pay resource pool=p_pay;
资源单元及租户的相关要点
- 资源单元unit是资源分配的最小单元,同一个unit不能跨节点(Obserer)
- 每个租户在一台observer上只能有一个unit
- unit是数据的容器
- 一个租户可以拥有若干个资源池
- 一个资源池只能属于一个租户
- 资源单元是集群负载均衡的一个基本单位
创建分区表时的资源分配
租户有1个unit
- 每个分区有3个副本,默认leader副本提供读写服务,follower副本不提供服务
- 每个分区的三副本内容是一样的

# 创建t1,只有一个分区,会有3个副本,tnt_trade有在集群1-1-1上
create table t1(…);
# 创建t2,只有一个分区,会有3个副本,指定主leader在zone2
create table t2(…) primary_zone=‘zone2’;
# 创建t3,按照指定字段hash分区,分3个,每个分区的主分区会均匀的分开
create table t3(…) partition by hash(<column name>) partitions 3;
租户有多个unit
- 每个分区有三个副本,默认leader副本提供读写服务,在一个zone里只会有一个副本
- 同一个分区不能跨unit,同一个分区表不同分区可以跨unit
- 同号
分区组的分区会聚集在同一个unit内部,不是尽可能

# 创建表组,分为3个分区
create tablegroup tgorder partition by hash partitions 3;
# 创建表t3时,通过hash进行3分区,并指定表组
create table t3(…) partition by hash(…)partitions 3 tablegroup=tgorder;
# 创建表t4时,通过hash进行3分区,并指定和t3一样的表组
create table t4(…) partition by hash(…)partitions 3 tablegroup=tgorder
-- 相同表组的表只能在一个unit中,同号分区组的分区会聚集在同一个unit内部,不是尽可能
- 表组是为了减少sql跨区操作,所以同号分区组的分区会聚集在同一个unit内部
- 发生负载均衡的时候,会将一个分区组的分区放到一个机器中,大概率地保障某些操作涉及的跨表数据在同一分区组中,并不是完全保证**,保障不了我理解就是故障了????**
租户扩容
租户的扩容有两种方式
-
升级规格
alter resource pool pool_mysql unit='S3’; -
增加unit的数量,前提是ob的模式必须是n-n-n,num<=n
alter resource pool pool_mysql unit_num=2;
如图实例:
- 租户资源初始状态为:unit_num = 1
- 分区分布初始状态是t1、t3、t4
- 租户资源扩容:uit_num 由1变为2
- 分区复制时,分区组聚合一起,leader打散
- 切换分区服务
- 删除旧分区
在操作的时候,需要注意
- 分区是数据迁移的最小单元,同一个分区不能跨unit,同一个分区表不同分区可以跨unit
- 同一个
分区组的分区会聚集在同一个unit内部

zone管理及状态 ☆
ps: primary zone 表示leader副本的偏好位置,指定了primary zone实际上是指定了leader更趋向于被调度到哪个zone上。
zone主要有两种类型:
- 读写zone
- 具备读写属性的zone,支持部署全功能型副本、只读型副本、普通日志副本;
- 加密zone
- 仅支持部署加密日志型副本;
zone一共有2个状态active状态和inactive状态,分别对应4个操作
-
新增zone时的inactive状态
ALTER SYSTEM ADD ZONE ’zone’; -
上线zone时的active状态
ALTER SYSTEM START ZONE ’zonename’; -
下线zone时的inavtive状态
ALTER SYSTEM STOP ZONE ’zonename’;- 虽然ocp上observer的状态是停止的,但是还是可以使用;
-
删除zone时的无状态
ALTER SYSTEM DELETE ZONE ’zone’;

server管理及状态 ☆
server的操作,只能是sys租户中进行操作。
查看server的状态,需要通过__all_server 内部表中service_start_time、stop_time 两个字段来确认observer的状态
stop_time- 不为0,表示OBServer被
stop了,此时stop_time的值为OBServer被stop的时间戳
- 不为0,表示OBServer被
status有3个状态,分别是active表示该observer 为正常状态,可能是start了,也可能被stop了- start_service_time >0 并且stop_time=0 表示该server可用
- Start_service_time >0 但是 stop_time >0 表示该server停用了
inactive表示该observer 为下线状态deleting表示该observer 正在被删除,可以被取消
Ps: 需要注意的是,stop server之前,需要确认enable_auto_leader_switch=true,并且分区副本满足多数派;
- stop server的时候,会将该server上的分区Leader切到其他节点,当没有Leader以后,标记为stopped状态,客户端请求不会发送到该server上,该server也不会再对外提供服务。
注意事项:
- 不能跨zone执行stop server的操作,主要是分区可用性的问题,(同一个zone可以同时stop多个server)
- 一个stop操作没有结束之前,不能发起第二个;
- 如果分区数多,observer 上的leader较多,stop server操作时间会比较长,会超时,sql超时默认是10秒,由
ob_query_timeout控制单位为微秒。 - stop server的日志会在
__all_rootservice_event_history记录的是rootservice控制的日志; - stop 以后
__all_server内部表的stop_time由0 变为stop的时间点 - delete server 会迁移资源到其他unit ,uinit的迁移是unit自动均衡的过程,由RootService控制,迁移成功,delete成功。如果其他zone的资源不足,会迁移失败;
- 日志在:/home/admin/oceanbase/log/rootservice.log
- 1-1-1集群是无法stop或delete observer的,因为无法构成多数派;
-- 1,当我们添加一个server的时候,此时start_service_time=0,stop_time=0此时server的状态为inactive,n秒后状态变为active,start_service_time变为对应操作的时间戳
ALTER SYSTEM ADD SERVER 'ip:port' [,'ip:port'…] [ZONE=’zone_name’];
-- 2,当我们删除server的时候,状态为deleting
ALTER SYSTEM DELETE SERVER 'ip:port' [,'ip:port'…] [ZONE=’zone_name’];
-- 需要注意的是:哪种状态删除的observer,取消删除后会回到哪个状态
-- 3,当我们取消删除server的时候,状态被修改为active
ALTER SYSTEM CANCEL DELETE SERVER 'ip:port' [,'ip:port'…] [ZONE=’zone_name’];
-- 4,当我们由stop启动的时候,进行Start Server后start_service_time不变,stop_time归0
ALTER SYSTEM START SERVER 'ip:port' [,'ip:port'...] [ZONE='zone'];
-- 5,当我们停止server的时候,此时stop_time为操作的时间戳,状态仍为active,start_service_time不变
ALTER SYSTEM STOP SERVER 'ip:port' [,'ip:port'...] [ZONE='zone'];

集群扩容
集群扩容在生产上是必不可少的。我们的集群初始状态为2-2-2,每个zone有4个unit,,此时流量高峰来了,我们需要扩容到3-3-3
-- 操作流程:
# 首先集群扩容由2-2-2 扩容到3-3-3;
扩容有三种方案:
-- 方案一: 资源规格够,只是当前observer的流量大
1.1,自动均衡,将原来的一些unit漂移到新的observer上;
-- 方案二:资源规格不够,调整unit的规格
2.1,调整租户的unit规格;
2.2, 自动漂移;
-- 方案三、各方面压力都大,比较适合多分区的表
3.1,调整unit num的数量,最大为3,会在新的zone里创建unit
3.2,自动进行分区复制;
3.3,复制完成后,进行主从切换;
3.4,切换完以后,下线多余的分区及unit;
-- 需要注意以下的两个参数:
enable_rebalance # 是否自动负载均衡
enable_auto_leader_switch #是否自动切换leader
示例:zone2里的unit 10~12 迁移到了zone3里。

增加observer
# 新增zone
#启动observer
/home/admin/oceanbase/bin/observer -i eth0 -P XXXX -p YYYY -z zone1 -d /home/admin/oceanbase/store/obdemo -r 'xxx.xxx.xxx.xxx:xxxx:xxx.xxx.xxx.xxx:xxxx xxx.xxx.xxx.xxx:xxxx:yyyy' -c 20190716 -n obdemo -o "memory_limit_percentage=90,memstore_limit_percentage=60,datafile_disk_percentage=80,config_additional_dir=/data/1/obdemo/etc3;/data/log1/obdemo/etc2"
1, -P 指定RPC端口号
2, -p 指定直连端口号
3,-z 指定待加入的zone名称
4,-d 指定数据的存储目录
5,-r 指定待添加的observer的ip列表
6,-c 指定集群id
7,-n 指定集群名
8,-o 指定启动配置项
# 新增observer
obclient> ALTER SYSTEM ADD SERVER '$IP:$PORT' ZONE 'zone4';
# 重启observer 需要增加一个环境变量,路径为observer安装的目录
echo 'export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/app/observer/lib/' >> ~/.bash_profile
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/app/observer/lib/
OB的资源弹性伸缩与负载均衡相关参数 ☆
- 资源单元的均衡和分区副本均衡开关:enable_rebalance 可选True或False
enable_rebalance是负载均衡的总开关,控制资源单元的均衡和分区副本均衡开关- 资源单元均衡需要参考
resource_soft_limit配置,小于100时,资源单元均衡开启,大于等于100,资源单元均衡关闭 server_balance_cpu_mem_tolerance_percent为触发资源单元均衡的阈值,大于该值,该是调度均衡
- 控制负载均衡时Partition迁移的速度和影响
Migrate_concurrency:迁移并发线程,过大会影响observer- 用于控制内部数据迁移的并发度
data_copy_concurrency: 数据copy并发数量- 用于设置系统中并发执行的数据迁移复制任务的最大并发数
server_data_copy_out_concurrency: 数据copy迁出并发线程数- 用于设置单个节点迁出数据的最大并发数
Server_data_copy_in_concurrency: 数据copy 迁入并发线程数- 用于设置单个节点迁入数据的最大并发数
查看业务租户内部所有leader副本的位置
select t5.tenant_name,t4.database_name,t3.tablegroup_name,t1.table_id,
t1.table_name,t2.partition_id,t2.role,t2.zone,
concat(t2.svr_ip,':',t2.svr_port) observer,
round(t2.data_size / 1024 / 1024) data_size_mb,
t2. row_count
from __all_virtual_table t1 -- 表的基本信息,可查看虚拟表
join gv$partition t2 -- 集群中所有的partition meta信息
on (t1.tenant_id = t2.tenant_id and t1.table_id = t2.table_id)
left join __all_tablegroup t3 -- 表组信息
on (t1.tenant_id = t3.tenant_id and t1.tablegroup_id = t3.tablegroup_id)
join __all_database t4 -- 库信息
on (t1.tenant_Id = t4.tenant_id and t1.database_id = t4.database_id)
join __all_tenant t5 -- 租户信息
on (t1.tenant_id = t5.tenant_id)
where t5.tenant_id = 1001
and t2.role = 1 -- role=1为leader,为2是follower
order by t5.tenant_name,t4.database_name,
t3.tablegroup_name,t2.partition_id;
异地多活会有很多内部请求跨机房
/**
异地多活的情况下,会有很多的内部请求跨机房;
针对多分区的表,如果obproxy能分区裁剪,路由到正确的server上,就是本地查询
如果没有裁剪,就会在一个observer进行请求的分发。
*/

通过primary zone 设置优先级,适配不同业务 ☆
/**
我们在可以通过primary_zone设置优先级,适配不同业务的需求
比如:
*/
-- 我们在跑批处理的时候,希望尽快跑完所有的任务。这个时候,我们是希望主副本(leader)均匀的分散到个observer,综合性能最快;
设置Primary_zone=('z1','z2','z3') 意味着每个zone的的权重都是一样,分区就会均匀分布到z1、z2、z3上;
-- 当我们操作对时延敏感的在线业务,业务量不大,不超过一台机器的处理能力,尽量避免跨服务器访问,从而降低延迟
设置Primary_zone=('z1';'z2';'z3'),意味着z1的优先级最高,只有在z1不可用的时候,才会选举z2, z1>z2>z3;
-- 当我们做容灾方案时,将业务汇聚到比较近的城市,距离较远的城市,只承担从副本的角色;,那同城市内的优先级大于异地
设置primary_zone=('z1','z2';'z3'),意味着z1和z2的优先级一样,z1=z2>z3;

primary zone 有租户、数据库和表不同的级别 ☆
/**租户有primary zone, 数据库也有primary zone 建表的时候也可以指定primary zone;
当我们建库的时候,如果不指定会继承租户的primary zone的设置;
当我们建表的时候,如果不指定primary zone 会继承数据库的primary zone的配置;
但是,当表或库都自己设置了primary zone的时候
表 > 库 > 租户;
*/
租户有primary zone ,数据库也有primary zone ,表也有primary zone ,有相应的优先级
- 表级别的优先级最高,其次数据库,最后租户,可以提供灵活的负载均衡
- 如果不指定,创建库的时候,会继承租户的,创建表的时候会继承数据库的

小结
/**
ob的负载均衡是按partition为单位进行负载均衡的;单表只有一个partition;ob会根据多维度达到均衡;如果设置了表组,均衡的时候,是以表组为单位均衡;
负载均衡有多个维护的
- 分区维度
- 表组维度,同一个表组是为了解决跨分区访问的问题;
- unit 维度
最终的目的是让流量,存储等各方面达到均衡;
ob的迁移是以unit为单位迁移的,
*/
- OB的资源分配流程是:定义资源规格-> 创建资源池-> 分配资源池给租户
- partition自动负载均衡:同一个分区表的不同分区、租户内的所有分区、不同租户建的分区会自动调整,使得分区分布在多个维度上都达到均衡
- 管理员可以通过设置primary_zone,影响租户、数据库、表等对象主副本的分布策略
- 对于关系密切的表,可以通过表组(tablegroup)干预他们的分区分布,使表组内所有的同号分区在同一个unit内部,避免跨节点请求对性能的影响
- unit负载均衡:集群扩容或缩容后,unit自动在不同的observer之间调整,租户的数据自动在unit之间重新均衡;整个过程在线完成,极大的简化运维难度。
第二章、存储引擎
OBServer
安装目录
通常observer安装后有audit、bin、etc、etc2、etc3、log、run、store 这 8 个目录。
- audit目录存放的是审计日志
- bin 存储observer的二进制文件
etc、etc2、etc3都是配置文件目录,内容完全一致,后两个是observer启动后创建,用于备份配置文件- log 目录,存放运行日志的目录,包含observer的运行日志,rs日志和选举日志,单个日志文件大小为256MB
- 通过
enable_syslog_recycle和max_syslog_file_count来控制日志的回收enable_syslog_recycle=true开启日志回收max_syslog_file_count=n设置每种日志的最大日志数量
- 其他参数
enable_syslog_wf单独将warn级别以上的日志复制到wf日志中enable_async_syslog是否启用异步写日志,默认truesyslog_io_bandwidth_limit日志限流量,默认30Msyslog_level日志级别
- 日志类型
- observer.log observer的日志
- observer.log 以及 observer.log.20210901123456
- observer.log.wf 以及 observer.log.wf.20210901123456
rootservice.logRS日志election.log选举日志
- observer.log observer的日志
- 通过
- run
- store是数据文件目录,包含clog、ilog、slog、sstable这4个子目录
- clog、ilog、slog 是事务日志目录
- clog存储动态数据写入的事务日志
- slog存储静态数据写入的事务日志
- ilog存储日志目录
- sstable存储基线数据目录,会有一个block_file,observer启动就会被创建
- 由
datafile_size或datafile_disk_percentage控制 - datafile_size 设置数据文件的大小
- datafile_disk_percentage 表示单用所在磁盘的百分比
- 由
- clog、ilog、slog 是事务日志目录
内存管理
系统架构概念图
OB的存储引擎基于LSM Tree 架构
/**
OB 分为两部分,
一部分数据是动态增量数据放在MemTable中,存储在内存,允许读写
一部分是静态基线数据放在SSTable中,一旦生成不能修改,存储与磁盘;
在Memtable中,有两种组织形式,都是存储的指针
hashtable 优化单值查询场景性能;
b+tree 优化范围查询场景性能;
内存实现了 Block Cache 和 Row cache,避免对基线数据的随机读。
ob最小的读取单位是一个宏快2MB,每个宏块,拆分出来多个可变长的微块。
合并的时候没有更新的宏快不会被重新打开读取。减少了合并期间的写放大。
单个查询,点查,使用多级缓存保证极低的响应时间
内存 布隆过滤器 -> row Cache ->block cache -> 基线数据
由于增量更新的策略,查询每一行数据的时候需要根据版本从新到旧遍历所有的 MemTable 以及 SSTable,将每个 Table 中对应主键的数据融合在一起返回
针对大查询场景,SQL 层会下压过滤条件到存储层,利用存数据特征进行底层的快速过滤,并支持向量化场景的批量计算和结果返回。
Block Cache: 微块缓存,存放从磁盘读取到微块中的信息,类似于Buffer pool,主要用于满足比较大的SQL语句
Block Index Cache : 对应下图中的in-memory b+ tree,微块索引缓存(类似于Block Cache的索引),由于微块数量很多,需要index把block cache中的信息串起来
Row Cache: 基线数据和转储数据的行数据缓存(hash table),对于高频的点查,使用cache可以快速的响应,这里实现MVCC,OB的MVCC是在行级别实现的。
Bloom Filter Cache : 宏块的布隆过滤器缓存,宏块的hash table,用户快速判断行在基线数据或转储数据是否存在
*/

- 静态基线数据(放在SSTable中)
- SSTable是只读的,一旦生成不再被修改,存储于磁盘
Mini SSTableMemTable转储以后直接形成的对象,mini SSTable 有多层Minor SSTable多个mini SSTable会定期合并成Minor SSTableMarjor SSTable每日合并开始后,所有的Mini 和Minor SSTable 都会合并成为Major SSTable- 存储的基本粒度是宏块(Micro Block),单个SSTable实质上是多个宏块的集合,一个宏块大小2MB,启动的时候就进行了切分
- 宏块会切分为多个微块,微块的概念与传统数据库的page/block概念类似,可以通过
block_size指定大小,默认16kb,不同编码格式的微块,数据的存储格式不一样
- 为了加速基线数据的读取(避免对基线数据的随机读)
- Row Cache 行级缓存,
- 加速对单行的查询性能,
- 对于不存在的空行会构建布隆过滤器,并对布隆过滤器进行缓存(有时效),一般是静态数据表
- Block Cache 块级缓存,缓存的是位置信息,ob以2MB为一个宏块,然后继续拆分出多个可变长微块
- 不存在行的空查,构建布隆过滤器
- Row Cache 行级缓存,
- SSTable是只读的,一旦生成不再被修改,存储于磁盘
- 动态增量数据(放在MemTable中)
- 存储于内存,支持读写
- 通过转储变成mini SSTable
TODO
本质上OB是一个基线加增量的的存储引擎,跟关系数据库差别很大,同时也借鉴了部分传统关系型数据库存储引擎的优点
/**
下图展示的是ob 典型的table get示例
点查询:
1,先查询Fuse Row Cache,有数据,直接返回,(fuse 熔合)
2,将以下几个点的数据融合做归并
2.1 查询MemeTable数据,只是更改的数据的字段;
2.2 通过BloomFilter 查询有命中,
2.3 查询 minor sstabe 的row cache(数据从memTable到minor ssTable的时候,是不是已经和原来的数据合并了?)
2.4 查询 major sstable 的 block index cache ,从这里查找到应该去哪个微块里查数据,微块的数据缓存到了Block Cache 中
2.5 将以上的结果做融合归并,然后缓存到Fuse Row Cache中
*/

- BloomFilter Cache
- 构建在宏块上,根据实际空查率构建,空查次数超过一定阈值,就会自动构建,并放入缓存中;
- Row Cache
- 针对每个SSTable缓存具体的行数据,在get/multiGet的时候,会将查到的数据放入到Row Cache中,避免下次二分定位
- Block Index Cache
- 缓存微块的索引,以宏为单位,描述宏块中所有的微块范围,访问宏块的时候,需要提前装载微块索引。优先级高
- Block Cache
- 缓存具体的数据微块,每个微块都会解压后装载到Block Cache
- Fuse Row Cache
- 对于增量更新的熔合结果缓存
- Partition Location Cache :缓存Partition的位置信息,用于查询路由
- Schema Cache 缓存数据表的元信息,用于执行计划的生成以及后续的查询
- Clog Cache 缓存 clog 数据,用于加速某些情况下 Paxos 日志的拉取
点查:

范围查:

查询读写
- 插入
- 所有数据表都可以看成索引聚簇表,无主键,会维护一个隐藏主键
- 写入新的数据前,会检查当前数据表是否已经存在相同的主键数据
- 为了加速重复主键查询性能,对于每个sstable都会由后台线程针对不同宏块判重频率来异步调度构建bloomfilter
- 更新
- 更新是在memtable中更新,只包含更新列的新值以及主键列
- 删除
- 和更新列类似,直接以主键写入一行数据,通过行头标记删除动作
- 大量删除对lsm-tree不友好,ob做了优化
- 查询
- 利用cache加速
- 大查询场景,会下压过滤条件到存储层
- 多级缓存
- 对于查询提供针对数据微块的
Block cache - 针对每个SSTable的
Row cache - 针对查询熔合结果的
Fuse Row Cache - 针对插入判空检查的
Bloomfilter cache
- 对于查询提供针对数据微块的
内存分配
/**
OB 是准内存分布式数据库,会占用物理服务器的大部分内存。
物理服务器的总内存,操作系统占一小部分,剩下的大部分由OBserver占用。
设置参数:
- 通过memory_limit_percentage 设置observer占用的百分比,
- 通过 memory_limit设置占用的内存。
当两个参数都存在的时候,memmory_limit 起作用。
*/
- OB是支持多租户架构的准内存分布式数据库,对大容量内存的管理和使用提出了很高要求
- OB会占据物理服务器的大部分内存并进行统一管理,通过以下参数可以限制OB的内存大小
memory_limit_percentage内存占用百分比- 当memory_limit 等于0的时候生效
memory_limit占用内存大小,默认单位为MB也可以设置为40G- 动态修改后,后台reload线程会使其动态生效
- 当设置了memory_limit以后,memory_limit_percentage失效
OB内部内存分配

/**
租户是核心,除了租户,ob自己运行也需要一些数据。不属于任何租户,但所有租户共享的资源,称为系统内部内存
由system_memory 控制ob自己用的内存,安装的时候,注意设置,要不然会占用比较多
ob 3.x 占用30G
刨除system_memory的内存以后,才是租户可用的内存
测试环境一般给system_memory 4~8g就可以了
*/
- 每一个observer都包含多个租户的数据,但observer的内存并不是全部分配给租户
- 通过参数
system_memory设置系统内存上限,3.x默认上限是30G - 租户可用内存为
ob内存上限-系统内部内存
租户内内存划分

/**
租户内部的内存,主要分为两块,
1,不可动态伸缩的内存:memStore ,用来保存DML产生的增量数据
由参数 memstore_limit_percentage决定,默认是50,表示占50%,密集型写入的话,适当的调大该值
当memStore占用超过freeze_trigger_percentage定义的百分比,默认70%,触发冻结以及后续的转储/合并
- 先冻结没毛病(冻结memtable的数据)
- 当没有达到转储的次数的时候,触发的是转储
- 当达到一定次数的时候,触发的是合并;
2,可动态伸缩的内存:KVCache
保存sstable的热数据,提高查询数据
大小可动态伸缩,会被其他cache挤占
除了memstore使用的50内存以外,一部分是租户运行占用的内存,
另一部分是kv cache 、plan cache 、sql area、other area
*/
- 不可动态伸缩的内存:MemStore
- 用于保存DML产生的增量数据,空间不可被占用
- 由
memstore_limit_percentage决定,表示占总租户大小的百分比,默认50,表示占50% - 当MemStore占比较高的时候(超过
freeze_trigger_percentage定义的的百分比,默认70%),触发冻结及后续的转储/合并操作- 当没有到达转储的次数的时候,是触发的转储
- 当达到一定次数的时候,触发的是合并
- 可动态伸缩的内存:KVCache
- 保存来自SSTAble的热数据,提高查询速度
- 大小可动态伸缩,会被其他各种Cache挤占
写入密集型的应用,适当的调大发生转储的内存阈值,通过
memstore_limit_percentage和minor_freeze_times控制,确保业务在高峰运行时,不发生合并,而是把产生的数据暂时转储到此篇中;查询密集型的应用,需要把
memory_limit_percentage调大,让OB占用更多的内存。
数据存储
在存储结构里,最上层是parttion group ,对应一个分区组,简称PG,。
- 一个pg中可能包含多个parttion(不分区只有一个),这些partition的分区键和分区规则要完全相同
- pg是ob数据库的leader选举和迁移复制的最小单位,

MemTable内存结构
OB的内存存储引擎Memtable采用双索引结构,由BTree和Hashtable组成,其中存储的均为指向对应数据的指针。
每次事务执行时,MemTable会自动维护B+树索引与hash索引的一致性;
- HashTable:对应Row Cache的索引
- 针对单行查询的优化
- 校验数据是否已经存在
- 加行锁,放在数据的行头数据结构中,mvcc控制在行
- BTree: 对应Block index cache
- 针对范围查找的优化
- 有序,范围查效果好
- undo 流程
- 需要读取历史快照,顺着内存的反向指针往前回溯即可。

SSTable

用户表每个分区管理数据的基本单元就是SStable,当Memtable 的大小达到某个阈值后,Ob,会将memtable冻结,然后将其中的数据转储与磁盘上。转储后的结构称之为sstable或者minor sstable。
sstable存储于磁盘,存储静态数据并且只读。
当集群发生全局合并的时,每个用户表分区所有的minor sstable 会根据合并快照点,一起参与做marjor 合并,最后生成 major sstable。
宏块(macro block)
ob将磁盘切分为大小为2MB的定长数据块,称之为宏块(macro block)。
- 宏块是数据文件写IO的基本单位
- 每个sstable由若干个宏块构成
- 宏块2MB的大小不可更改
- IO会顺序读写
微块(Micro Block)
宏块内部数据被组织为多个大小为16kb左右的变长数据块,称之为微块(Micro Block).
- 微块中包含若干数据行(Row),数据按照主键排序
- 微块是数据文件读IO的最小单位
- 每个微块在构建时,都会根据用户指定的压缩算法进行压缩,因此宏块上存储的实际上是压缩后的数据
- 读取的时,会解压后放入数据块缓存中
- 微块的大小在创建表时可以指定,也可以通过语句指定
ALTER TABLE mytest SET block_size = 131072;

内存数据落盘策略-合并和转储
LSM 技术简介

LSM Tree ,顾名思义,就是The Log-Structured Merge-Tree 的缩写。从这个名称里面可以看到几个关键的信息:
- 第一: log-structred,通过日志的方式来组织的
- 第二:merge,可以合并的
- 第三:tree,一种树形结构
实际上它并不是一棵树,也不是一种具体的数据结构,它实际上是一种数据保存和更新的思想。简单的说,就是将数据按照key来进行排序(在数据库中就是表的主键),之后形成一棵一棵小的树形结构,或者不是树形结构,是一张小表也可以,这些数据通常被称为基线数据;之后把每次数据的改变(也就是log)都记录下来,也按照主键进行排序,之后定期的把log中对数据的改变合并(merge)到基线数据当中。
核心:利用顺序写来提高写性能。典型的以空间换时间。基于归并排序的数据存储思想
- 将某个对象(partition)中的数据按照“k-v”形式在磁盘有序存储(SSTable)
- 数据插入,先记录在MemStore中的MemTable里,然后再合并(Merge)到底层的sstable里
- SSTable和Memtable之间可以有多级中间数据,同样以kv形式保存在磁盘上,逐级向下合并
合并
- 合并是将动静数据做归并,会比较耗时。
- 是全局级别的操作,产生一个全局快照;
- 全局分区一起做MemTable的冻结操作,要求主备的Partition保持一致;
- 会把当前的大版本的SSTable和MemTable与前一个大版本的全量静态数据进行合并。
OB最简单的LSM Tree只有C0层(MemTable)和C1层(SSTable),其合并过程如下:
合并的时候并不是先转储,而是直接冻结MemTable然后合并到SSTable中
- 将所有observer上的Memtable数据做大版本冻结(Major Freeze),其余内存作为新的Memtable继续使用
- 将冻结后的Memtable数据合并到SSTable中,形成新的SSTable,并覆盖旧的SSTable(已经包含了新旧数据)
- 合并完成后,冻结的MemTable内存才可以被清空并重新使用
这种合并很容易出现问题。

合并按照合并的宏块不同,可以细化为全量合并、增量合并、渐进合并三种方式,ob默认使用增量合并
- 全量合并:合并时间长,耗费IO和CPU,把所有的静态数据都读取出来,和动态数据归并,再写到磁盘中
- 增量合并:只会读取被修改过的宏块数据,和动态数据归并,并写入磁盘,对于未修改过的宏块,则直接重用,ob默认使用
- 渐进合并:每次全量合并一部分,若干轮次后整体数据被重新一遍
执行方式:
-
并行合并 :分区内并行合并,提升分区的合并速度,可以应用到全量、增量、和渐进中
-
轮转合并:以副本为单位合并,将流量切到其他副本
**合并带来的问题:**通过转储来解决
- 集群性的动作
- 高消耗
- 时间长
定时合并
由major_freeze_duty_time 参数控制定时合并的时间
# 设置定时合并时间
alter system set major_freeze_duty_time='02:00';
# 查看定时合并时间,按zone的维度来
show parameters like '%major_freeze_duty_time%'
自动触发合并
当MemStore 达到参数freeze_trigger_percentage配置的值,并且转储的次数达到了minor_freeze_times参数的值,自动触发
# 查看各租户的MemStore使用情况
select * from oceanbase.v$memstore;
# 查询转储次数gv$memstore,__all_virtual_tenant_memstore_info 中的freeze_cnt列
- active_memstore_used 某台服务器上的活动 MemStore 的大小
- total_memstore_used 某台服务器上的总 MemStore 的使用大小
- major_freeze_trigger MemStore 使用量触发转储或合并的阈值
- memstore_limit 在某台服务器上的 Memstore 的上限
- freeze_cnt 触发转储的计数器
手动触发合并
# 在root@sys下执行
alter system major freeze;
# 查看合并状态
select * from __all_zone where name = 'merge_status'
-
转储
为了解决2层LSM Treee合并是引发的问题,OB引入了转储机制(C1层)
引入转储是为了解决合并影响性能的问题,先内存刷入磁盘成minor sstable,刷入成功以后内存空间就释放了
- 将MemTable数据做小版本冻结(Minor Freeze)后写到磁盘上单独的转储文件里,不与SSTable 数据做合并
- 转储文件写完之后,冻结的MemTable内存被清空并重新使用
- 每次转储会将MemTable数据与前一次转储的数据合并,转储文件最终会合并到SSTable中

分层转储(从2.2版本开始)
为了优化转储越来越慢的问题,2.2引入分层转储的机制
- 新增L0层,被冻结的MemTable会直接flush为Mini SSTable,可同时存在多个Mini SSTable(2.2之前只会存在一个转储SSTable)
- L0层 : mini SSTable L0层通过server级配置参数来设置L0内部分层和每层最大SSTable个数;
- 内部分为level-0 到 level-n层,每层最大容纳SSTable的个数相同;
- L0中当低层级的 level-n 的 SSTable 到达一定数目上限或阈值后开始整体 compaction,合并成一个 SSTable 写入到高层级 level-n+1 层中
- 当L0层的Max level内的SSTable个数达到上限后,开始将L0层到L1层的转储,也就是生成一个Minor sstable;
- 这样做的好处是:降低写放大,但是会带来读放大
minor_compact_trigger控制L0层mini sstable总数
- L1层: minor sstable
- 当L0层的sstable合并过来后,会和L1层的minor sstable合并,是有条件的
- L1层的Minor SSTable 仍然维持rowkey有序;
- L2 层: 是基线Major SSTable
- 为了保持多副本间基线数据完全一致,major sstable 保持只读,不发生合并动作
- **
major_compact_trigger控制 memtable dump flush次数达到时触发 合并 **
- ob通过queuing 表来解决小数据量表大批量执行insert和delete带来的读放大;
- 引入 自适应buffer表转储策略(queuing 又称buffer表)
- 在mini sstable 和major sstable之间生成一个 buf minor sstable,生成的时候会消除增量数据里的所有delete标记,避免读放大
- 在查询buf minor sstable的时候,可以避免大量无效扫描动作
- L0层 : mini SSTable L0层通过server级配置参数来设置L0内部分层和每层最大SSTable个数;
- 架构变化:由3层 ------> 4层
- 3层架构:MemTable-> minor SSTable(L1) ->major SSTable(L2)
- 4层架构:MemTable->mini SSTable(L0)->minor SSTable(L1) ->major SSTable(L2)

转储的基本概念:
**转储功能的引入,是为了解决合并操作引发的一系列问题。**转储是租户级的
- 解决合并时资源消耗高,对在线业务性能影响较大
- 解决合并时单个租户MemStore使用率高会触发集群级合并,其他租户成为受害者
- 解决合并耗时长导致MemStore内存释放不及时,容易造成MemStore满二数据写入失败的情况
设计思路:
- 租户级:每个MemStore触发单独的冻结(freeze_trigger_percentage)及数据合并,不影响其他租户
- **粒度可控:**也可以通过命令为指定租户、指定observer、指定分区做转储
- 只和上一次转储的数据做合并,不和SSTable的数据做合并
转储相关参数:
-
freeze_trigger_percentageMemStore达到多少的时候触发转储- 达到
memstore_limit_percentage *freeze_trigger_percentage,先冻结,再根据minor_freeze_times判断是转储还是合并 - 写并发大的业务,减小
freeze_trigger_percentage的值,比如40,使MemStore尽早释放,进一步降低MemStore写满的概率
- 达到
-
minor_merge_concurrency: 转储工作线程数,默认为0,表示10个线程- 并发转储的分区个数,单分区不支持拆分转储,分区表可加速
- 并发过少会影响转储的性能和效果
- 并发过多,消耗过多资源,影响在线业务的性能
-
minor_freeze_times: 控制两次合并之间的转储次数- 达到此数着自动触发合并(major freeze)
- 设置为0 表示关闭转储,则达到冻结阈值(freeze_trigger_percentage)直接触发集群合并
- 增大
minor_freeze_times的值,尽量避免业务峰值时段触发合并,将合并的时机延到低峰期
-
minor_compact_trigger控制mini sstable的个数
转储适用场景:
- 批处理、大量数据导入等场景,写MemStore的速度快,需要MemStore内存尽快释放,MemStore主要保存增量数据
- 业务峰值交易量大,写入MemStore的数据很多,又不想在峰值时段触发合并,希望将合并延后
转储对数据库的影响
优势
- 租户级别,不会影响集群
- 资源消耗少,对在线业务性能影响较低
- 耗时短,MemStore更快释放,降低发生MemStore写满的概率
劣势
- 数据层级增多,查询链路变成,查询性能下降
- 冗余数据增多,占用更多磁盘空间
手动触发
ALTER SYSTEM MINOR FREEZE
[{TENANT[=] (‘tt1' [, 'tt2'...]) | PARTITION_ID [=] 'partidx%partcount@tableid‘}]
[SERVER [=] ('ip:port' [, 'ip:port'...])];
-- 可以指定租户TENANT,可以指定分区PARTITION_ID,可以指定server
# 集群级别转储
ALTER SYSTEM MINOR FREEZE;
# server级别转储
ALTER SYSTEM MINOR FREEZE SERVER='10.10.10.1:2882';
# 租户级别转储
ALTER SYSTEM MINOR FREEZE TENANT=('prod_tenant');
#分区级别转储
ALTER SYSTEM MINOR FREEZE PARTITION_ID = '8%1@1099511627933';
- 可选的控制参数:
tenant: 指定要执行minor freeze的租户Partition_id:指定要执行minor freeze的partitionserver: 指定要执行 minor freeze的observer
- 当什么选项都不指定时,默认对所有的observer上的所有租户执行转储
- 手动触发转储次数,不受参数 minor_freeze_times的限制,手动触发次数过多不会触发合并
自动触发
达到参数freeze_trigger_percentage 配置的值
memstore_limit_percentage *freeze_trigger_percentage,先冻结,再根据minor_freeze_times判断是转储还是合并
查看转储
自动触发的转储在__all_server_event_history表中
select * from __all_server_event_history where (event like '%merge%' or event like '%minor%') order by gmt_create desc limit 10;
+----------------------------+---------------+----------+--------+-------------------------+-----------+--------+-------+--------+-------+--------+-------+--------+-------+--------+-------+--------+------------+
| gmt_create | svr_ip | svr_port | module | event | name1 | value1 | name2 | value2 | name3 | value3 | name4 | value4 | name5 | value5 | name6 | value6 | extra_info |
+----------------------------+---------------+----------+--------+-------------------------+-----------+--------+-------+--------+-------+--------+-------+--------+-------+--------+-------+--------+------------+
| 2023-06-06 20:41:20.768582 | 192.168.80.15 | 2882 | freeze | do minor freeze success | tenant_id | 0 | | NULL | | | | | | | | | |
| 2023-06-06 20:41:20.763871 | 192.168.80.10 | 2882 | freeze | do minor freeze success | tenant_id | 0 | | NULL | | | | | | | | | |
| 2023-06-06 20:41:20.760225 | 192.168.80.13 | 2882 | freeze | do minor freeze success | tenant_id | 0 | | NULL | | | | | | | | | |
| 2023-06-06 20:41:20.642135 | 192.168.80.13 | 2882 | freeze | do minor freeze | tenant_id | 0 | | NULL | | | | | | | | | |
| 2023-06-06 20:41:20.642120 | 192.168.80.15 | 2882 | freeze | do minor freeze | tenant_id | 0 | | NULL | | | | | | | | | |
| 2023-06-06 20:41:20.642010 | 192.168.80.10 | 2882 | freeze | do minor freeze | tenant_id | 0 | | NULL | | | | | | | | | |
| 2023-06-06 20:39:31.851705 | 192.168.80.13 | 2882 | freeze | do minor freeze success | tenant_id | 0 | | NULL | | | | | | | | | |
| 2023-06-06 20:39:31.624214 | 192.168.80.15 | 2882 | freeze | do minor freeze success | tenant_id | 0 | | NULL | | | | | | | | | |
| 2023-06-06 20:39:31.581254 | 192.168.80.10 | 2882 | freeze | do minor freeze success | tenant_id | 0 | | NULL | | | | | | | | | |
| 2023-06-06 20:39:30.796525 | 192.168.80.15 | 2882 | freeze | do minor freeze | tenant_id | 0 | | NULL | | | | | | | | | |
+----------------------------+---------------+----------+--------+-------------------------+-----------+--------+-------+--------+-------+--------+-------+--------+-------+--------+-------+--------+------------+
10 rows in set (0.060 sec)
手动触发的转储__all_rootservice_event_history表中
select * from __all_rootservice_event_history where event like '%minor%'
重点在value2 这个字段中
select * from __all_rootservice_event_history where event like '%minor%' order by gmt_create desc limit 10;
+----------------------------+--------------+-------------------+-------+--------+-------+------------------------------------------------------------------------------------------------------------------------------------------------+-------+--------+-------+--------+-------+--------+-------+--------+------------+---------------+-------------+
| gmt_create | module | event | name1 | value1 | name2 | value2 | name3 | value3 | name4 | value4 | name5 | value5 | name6 | value6 | extra_info | rs_svr_ip | rs_svr_port |
+----------------------------+--------------+-------------------+-------+--------+-------+------------------------------------------------------------------------------------------------------------------------------------------------+-------+--------+-------+--------+-------+--------+-------+--------+------------+---------------+-------------+
| 2023-06-06 20:41:20.768811 | root_service | root_minor_freeze | ret | 0 | arg | {tenant_ids:[], partition_key:{tid:18446744073709551615, partition_id:-1, part_idx:268435455, subpart_idx:268435455}, server_list:[], zone:""} | | | | | | | | | | 192.168.80.10 | 2882 |
| 2023-06-06 20:39:31.851875 | root_service | root_minor_freeze | ret | 0 | arg | {tenant_ids:[], partition_key:{tid:18446744073709551615, partition_id:-1, part_idx:268435455, subpart_idx:268435455}, server_list:[], zone:""} | | | | | | | | | | 192.168.80.10 | 2882 |
| 2023-06-06 19:59:18.528693 | root_service | root_minor_freeze | ret | 0 | arg | {tenant_ids:[], partition_key:{tid:18446744073709551615, partition_id:-1, part_idx:268435455, subpart_idx:268435455}, server_list:[], zone:""} | | | | | | | | | | 192.168.80.10 | 2882 |
| 2023-06-06 02:00:01.530634 | root_service | root_minor_freeze | ret | 0 | arg | {tenant_ids:[], partition_key:{tid:18446744073709551615, partition_id:-1, part_idx:268435455, subpart_idx:268435455}, server_list:[], zone:""} | | | | | | | | | | 192.168.80.10 | 2882 |
| 2023-06-05 02:00:01.766393 | root_service | root_minor_freeze | ret | 0 | arg | {tenant_ids:[], partition_key:{tid:18446744073709551615, partition_id:-1, part_idx:268435455, subpart_idx:268435455}, server_list:[], zone:""} | | | | | | | | | | 192.168.80.10 | 2882 |
| 2023-06-04 02:00:01.794636 | root_service | root_minor_freeze | ret | 0 | arg | {tenant_ids:[], partition_key:{tid:18446744073709551615, partition_id:-1, part_idx:268435455, subpart_idx:268435455}, server_list:[], zone:""} | | | | | | | | | | 192.168.80.10 | 2882 |
| 2023-06-03 02:00:01.845602 | root_service | root_minor_freeze | ret | 0 | arg | {tenant_ids:[], partition_key:{tid:18446744073709551615, partition_id:-1, part_idx:268435455, subpart_idx:268435455}, server_list:[], zone:""} | | | | | | | | | | 192.168.80.10 | 2882 |
| 2023-06-02 02:00:01.319800 | root_service | root_minor_freeze | ret | 0 | arg | {tenant_ids:[], partition_key:{tid:18446744073709551615, partition_id:-1, part_idx:268435455, subpart_idx:268435455}, server_list:[], zone:""} | | | | | | | | | | 192.168.80.10 | 2882 |
| 2023-06-01 02:00:01.891988 | root_service | root_minor_freeze | ret | 0 | arg | {tenant_ids:[], partition_key:{tid:18446744073709551615, partition_id:-1, part_idx:268435455, subpart_idx:268435455}, server_list:[], zone:""} | | | | | | | | | | 192.168.80.10 | 2882 |
| 2023-05-31 02:00:01.036797 | root_service | root_minor_freeze | ret | 0 | arg | {tenant_ids:[], partition_key:{tid:18446744073709551615, partition_id:-1, part_idx:268435455, subpart_idx:268435455}, server_list:[], zone:""} | | | | | | | | | | 192.168.80.10 | 2882 |
+----------------------------+--------------+-------------------+-------+--------+-------+------------------------------------------------------------------------------------------------------------------------------------------------+-------+--------+-------+--------+-------+--------+-------+--------+------------+---------------+-------------+
10 rows in set (0.004 sec)
查看OB集群合并和冻结状态__all_zone
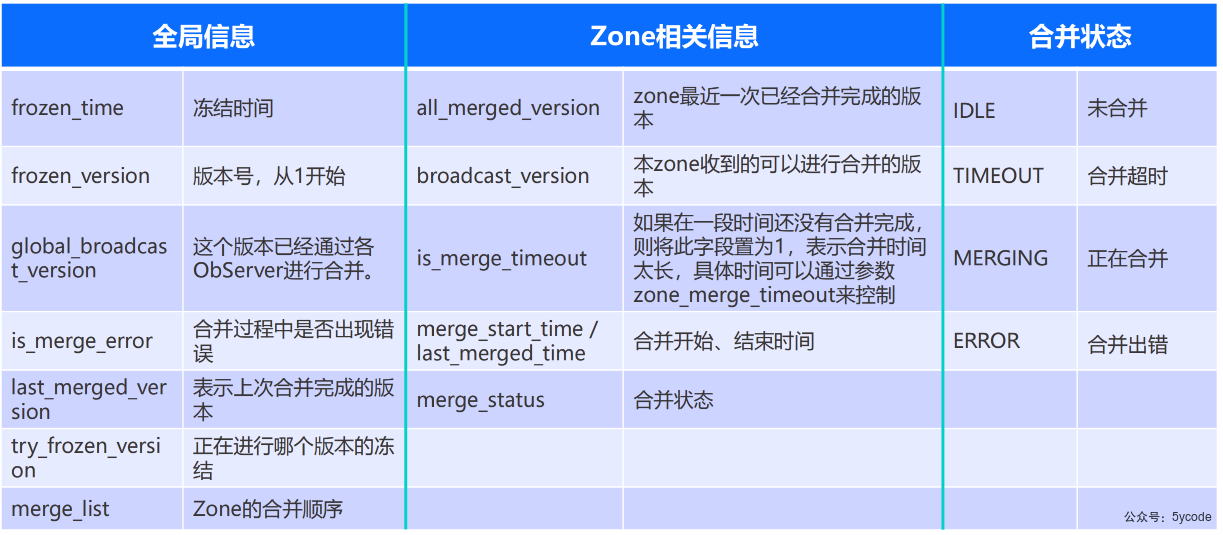
obclient [oceanbase]> select * from __all_zone;
+----------------------------+----------------------------+-------+--------------------------+------------------+------------+
| gmt_create | gmt_modified | zone | name | value | info |
+----------------------------+----------------------------+-------+--------------------------+------------------+------------+
| 2023-05-22 13:44:48.980066 | 2023-05-22 13:44:48.980066 | | cluster | 0 | obcluster |
| 2023-05-22 13:44:48.980585 | 2023-05-23 19:55:14.184675 | | config_version | 1684842914178885 | |
| 2023-05-22 13:44:48.980585 | 2023-06-06 19:59:17.780305 | | frozen_time | 1686052767285953 | |
| 2023-05-22 13:44:48.980585 | 2023-06-06 19:59:17.780305 | | frozen_version | 17 | |
| 2023-05-22 13:44:48.981652 | 2023-05-22 13:44:48.981652 | | gc_schema_version | 0 | |
| 2023-05-22 13:44:48.980585 | 2023-06-06 19:59:37.581624 | | global_broadcast_version | 17 | |
| 2023-05-22 13:44:48.980585 | 2023-05-22 13:44:48.980585 | | is_merge_error | 0 | |
| 2023-05-22 13:44:48.980585 | 2023-06-06 20:05:38.376554 | | last_merged_version | 17 | |
| 2023-05-22 13:44:48.980585 | 2023-06-06 20:05:38.376729 | | lease_info_version | 1686053138375756 | |
| 2023-05-22 13:44:48.980585 | 2023-06-06 20:05:38.376729 | | merge_status | 0 | IDLE |
| 2023-05-22 13:44:48.980585 | 2023-05-22 13:44:48.980585 | | privilege_version | 0 | |
| 2023-05-22 13:44:48.981652 | 2023-05-22 13:44:48.981652 | | proposal_frozen_version | 1 | |
| 2023-05-22 13:44:48.981652 | 2023-05-22 13:44:48.981652 | | snapshot_gc_ts | 0 | |
| 2023-05-22 13:44:48.981652 | 2023-05-22 13:44:48.981652 | | storage_format_version | 4 | |
| 2023-05-22 13:44:48.981652 | 2023-05-22 13:44:48.981652 | | time_zone_info_version | 0 | |
| 2023-05-22 13:44:48.980585 | 2023-05-22 13:44:48.980585 | | try_frozen_version | 1 | |
| 2023-05-22 13:44:48.981652 | 2023-05-22 13:44:48.981652 | | warm_up_start_time | 0 | |
| 2023-05-22 13:44:48.981652 | 2023-06-06 20:05:27.955867 | zone1 | all_merged_version | 17 | |
| 2023-05-22 13:44:48.981652 | 2023-06-06 19:59:37.864609 | zone1 | broadcast_version | 17 | |
| 2023-05-22 13:44:48.982720 | 2023-05-22 19:45:48.340319 | zone1 | idc | 0 | dev |
| 2023-05-22 13:44:48.982720 | 2023-06-06 20:05:27.954791 | zone1 | is_merge_timeout | 0 | |
| 2023-05-22 13:44:48.981652 | 2023-06-06 20:05:27.954791 | zone1 | is_merging | 0 | |
| 2023-05-22 13:44:48.981652 | 2023-06-06 20:05:27.954791 | zone1 | last_merged_time | 1686053127954511 | |
| 2023-05-22 13:44:48.981652 | 2023-06-06 20:05:27.954791 | zone1 | last_merged_version | 17 | |
| 2023-05-22 13:44:48.982720 | 2023-06-06 19:59:37.864609 | zone1 | merge_start_time | 1686052777863600 | |
| 2023-05-22 13:44:48.982720 | 2023-06-06 20:05:27.955867 | zone1 | merge_status | 0 | IDLE |
| 2023-05-22 13:44:48.982720 | 2023-05-22 13:44:48.982720 | zone1 | recovery_status | 0 | NORMAL |
| 2023-05-22 13:44:48.982720 | 2023-05-22 13:44:48.982720 | zone1 | region | 0 | sys_region |
| 2023-05-22 13:44:48.981652 | 2023-06-05 21:05:56.667767 | zone1 | status | 2 | ACTIVE |
| 2023-05-22 13:44:48.982720 | 2023-05-22 13:44:48.982720 | zone1 | storage_type | 0 | LOCAL |
| 2023-05-22 13:44:48.982720 | 2023-05-22 13:44:48.982720 | zone1 | suspend_merging | 0 | |
| 2023-05-22 13:44:48.982720 | 2023-05-22 13:44:48.982720 | zone1 | zone_type | 0 | ReadWrite |
结果字段说明:
- zone为空,表示全局信息,对应name的说明
- zone有具体值,对应的name的说明
轮转合并
借助自身天然具备的多副本分布式架构,OceanBase引入了轮转合并机制
- 适用于多副本机制,可以轮流为每份副本单独做合并
- 合并中的副本,不对外提供服务,流量切到其他副本上;
- 合并完成,流量切回,依次轮转所有的副本
更多说明
- 通过参数
enable_merge_by-turn开启或关闭轮转合并 - 以zone为单位轮转合并,只有一个zone合并完成后才开始下一个zone的合并,合并整体时间变长
- 某一个zone的合并开始之前,会将这个zone上的leader服务切换到其他zone;切换动作对事务有影响
- 由于正在正在合并的zone上没有leader,避免了合并对在线服务带来的性能影响;
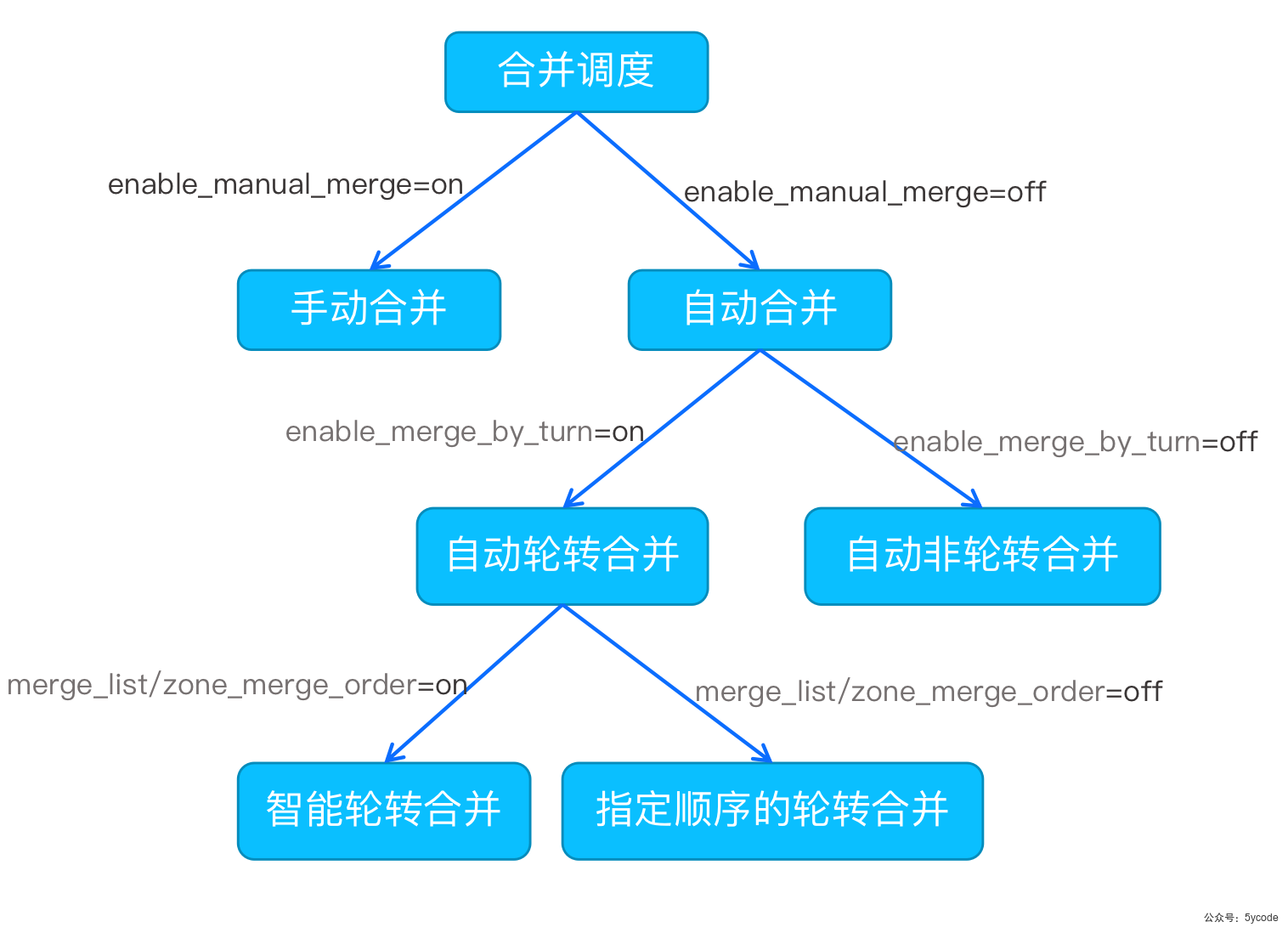
每日合并策略
-
enable_manual_merge: 是否开启手动合并,=on 开启手动合并
-
enable_merge_by_turn 是否开启轮转合并,=on开启轮转合并
-
zone_merge_order指定自动轮转合并的合并顺序,=on智能轮转合并
#假设集群中有三个zone,分别是z1,z2,z3,想设置轮转合并的顺序为"z1 -> z2 -> z3",步骤如下:
alter system set enable_manual_merge = false; -- 关闭手动合并
alter system set enable_merge_by_turn = true; -- 开启轮转合并
alter system set zone_merge_order = 'z1,z2,z3'; -- 设置合并顺序,为大于 ;为等于
# 取消自定义的合并顺序
alter system set zone_merge_order = '' -- 取消自定义合并顺序
/**
当触发了合并调度的时候,先看enable_manual_merge 是手动合并还是自动合并。
如果是自动合并,看下enable_merge_by_turn 有没有设置自动轮转合并
*/
ob轮转合并示例
假设机器中的设置是 zone_merge_order=‘z1,z2,z3,z4,z5’,zone_merge_concurrency=3一次轮转合并的过程如下:
ob的轮转合并一次可以合并多个zone;
生产不建议开启多个zone轮转合并,影响性能,除非在业务低峰期,还有可能资源不够;
| 事件 | 调度 | 并发合并的****ZONE | 合并完成的****ZONE |
|---|---|---|---|
| 1. 开始合并。 | z1,z2,z3发起合并 | z1,z2,z3 | |
| 2. 一段时间后,z2完成合并。 | z4发起合并 | z1,z3,z4 | z2 |
| 3. 一段时间后,z3完成合并。 | z5发起合并 | z1,z4,z5 | z2,z3 |
| 4. 一段时间后,全部ZONE完成合并。 | z1,z2,z3,z4,z5 |
合并策略对比
| 合井策略 | 调度策略 | 如何开启 | 使用场景 | 注释 |
|---|---|---|---|---|
| 手动合并 | 用户通过sql命令指定zone开始合并,需要用户自己控制并发度 | 1.开启手动合并alter system set enable_manual_merge = true; 2.用户自主决定合并顺序和并发度,通过SQL命令调度zone合并,比如调度z1开始合并:alter system start merge zone = ‘z1’; | 纯手工操作,一般在业务每日合并出现问题、需要人工介入的情况下使用 | 一旦开启,每一次合并都需要用户主动调度,除非关掉手动合并,开启自动合并 |
| 自动非轮转合并 | 所有zone一起开始合并,没有并发度控制 | 1.关闭手动合并alter system set enable_manual_merge = false; 2.关闭轮转合并alter system set enable_merge_by_turn = false; | 当业务量比较小的情况下,合并中的zone也能支持业务流量时,则可以开启自动非轮转合并,这样做能够避免用户跨表join请求变成分布式跨机查询 | 每日合并会对业务请求产生一定的性能影响,需要业务进行确认 |
| 自动指定顺序的轮转合并 | 用户直接指定轮转的顺序,RS只负责并发度控制 | 各个版本实现有不同,具体看相关版本介绍 | 一种特殊的轮转合并策略,一般不会使用,只有当智能轮转合并不满足业务需求的情况下,才需要为集群定制特殊的合并调度策略 | 在zone成员发生变更的情况下,自动指定顺序的轮转合并会失效,退化成智能轮转合并 |
| 智能轮转合并 | RS根据一定策略依次调度zone合并,并进行并发度控制 | 1.关闭手动合并alter system set enable_manual_merge = false; 2.开启轮转合并alter system set enable_merge_by_turn = true; | 线上部署最常用的合并调度方案,轮转合并的过程中,RS会保证尽量不影响业务的请求,通过切leader的方式,将用户读写路由到不在合并的zone中; |
合并注意事项
合并超时时间设置
/**
合并超时默认3小时,超过3小时会timeout
- 数据文件最大可以写入90%,超出以后禁止迁入
datafile_size 的优先级大于datafile_disk_percentage用于配置数据盘空间使用阈值,默认90%
*/
- 参数
zone_merge_timeout设置合并超时的阈值,默认值为3h - 如果某个zone的合并执行超过阈值,合并状态被设置为timeout
空间警告水位
- 参数
data_disk_usage_limit_percentage定义数据文件最大可以写入的百分比,超出禁止数据写入,默认90; - 磁盘使用超出阈值,合并打印error,合并失败,需要尽快扩大数据盘物理空间,并调大
data_disk_usage_limit_percentage的值 - 参数
datafile_disk_percentage定义数据盘空间使用阈值(占用 data_dir所在磁盘空间的百分比),默认90 - 参数
dtafile_size用于设置数据文件的大小,该配置项与datafile_disk_percentage同时配置时,以该配置项设置的值为准,默认为0
合并控制
- 合并线程数,由
merge_thread_count控制,控制同时执行合并的分区个数,单分区不能拆分 - 默认为0,表示自适应,实际取值为min(10,cpu_cnt*0.3),对合并速度没有特殊要求,建议默认为0
- 最大不要超过48,会影响性能,还容易触发报警,cpu使用超过90%,触发主机报警
合并版本(保留的数据合并版本个数)
/**
默认合并版本为2 由参数max_kept_major_version_number控制
*/
设置SStable 中保留的数据合并版本个数
- 由参数
max_kept_major_version_number控制,默认值为2 - 调大参数值可以保留更多历史数据,但单用磁盘空间较多
- 在hint中利用frozen_version 指定历史版本
select /*+ frozen_version(16) */ * from tmp1;- 在
__all_virtual_partition_sstable_image_info表中维护了可用的版本号
- 在
查看合并版本
select zone,svr_ip,major_version from __all_virtual_partition_sstable_image_info;
+-------+---------------+---------------+
| zone | svr_ip | major_version |
+-------+---------------+---------------+
| zone1 | 192.168.80.10 | 16 |
| zone1 | 192.168.80.10 | 17 |
| zone2 | 192.168.80.13 | 16 |
| zone2 | 192.168.80.13 | 17 |
| zone3 | 192.168.80.15 | 16 |
| zone3 | 192.168.80.15 | 17 |
+-------+---------------+---------------+
查看合并记录和状态
- 通过
__all_rootservice_event_history表查看合并记录 - 通过
__all_zone查看当前合并状态
转储&合并对比
| 合并(Major freeze) | 转储(Minor freeze) |
|---|---|
| 集群级行为,产生一个全局快照,所有observer上所有租户的MemStore统一冻结。 | 以“租户+observer”为维度,只是MemTable的物化,每个MemStore独立触发冻结;也可以通过手工命令,为特定的分区单独执行。 |
| MemTable数据和转储数据全部合并到SSTable中,完成后数据只剩一层,产生新的全量数据。 | 转储只与相同大版本的Minor SSTable合并,产生新的Minor SSTable,所以只包含增量数据,最终被删除的行需要特殊标记,不涉及SSTable数据,完成后有转储和SSTable两层数据。 |
| 更新的数据量大(全部租户、全部observer、含SSTable),消耗较多的CPU和IO资源,MemStore内存释放较慢。 | 更新的数据量小(单独租户、单独observer、不含SSTable),消耗的资源更少,可加快MemStore内存的释放。 |
| 触发条件:单个租户的MemStore使用率达到freeze_trigger_precentage,并且转储已经达到指定次数;手工触发;定时触发。 | 触发条件: 单个租户的MemStore使用率达到freeze_trigger_precentage; 手工触发。 |
小结
- OB的LSM Tree 可以分为C0层(MemTable)、C1层(Minor SSTable)、C2 层(Major SSTable)
- OB内存通过双索引结构和数据压缩,提高数据的查询性能
- 合并和转储之前,都需要做一次冻结,然后根据参数设置决定冻结之后是转储还是合并
- 合并可以细分为全量合并、渐进合并、增量合并三种方式,同一个数据库,这三种方式对资源的消耗程度递减
- 为了优化转储越来越慢的问题,引入分层转储的机制,为了提高转储速度,加快内存释放速度,被冻结的MemTable会直接flush为Mini SSTable
- 轮转合并可以轮流为每份副本单独做合并,减少业务影响,但同时也存在合并时间变长,切主过程中影响长链接等问题
- 合并和转储特点的比较,两者互补共同组成了OB数据完整的落盘策略
第三章、SQL引擎高级技术
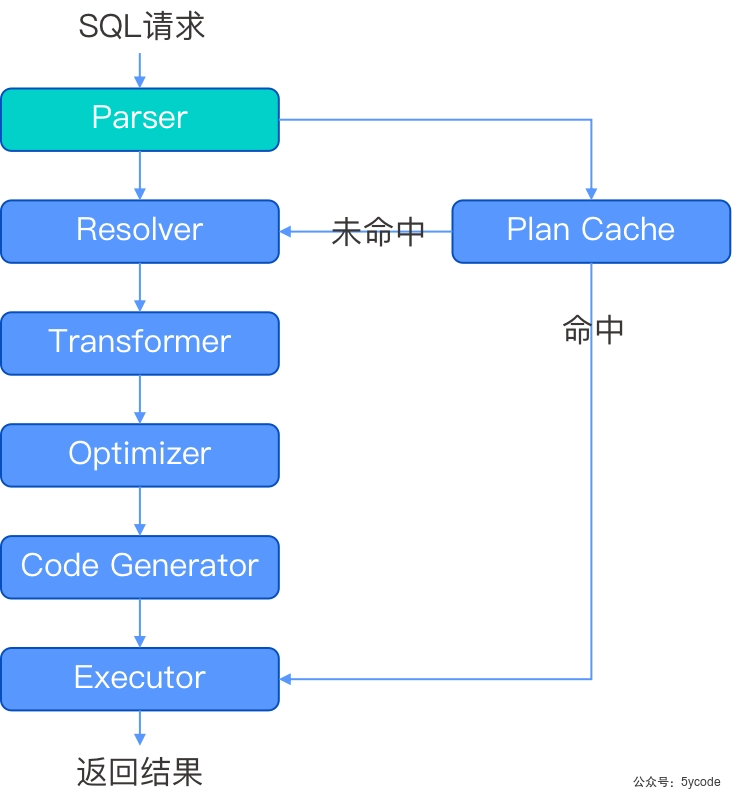
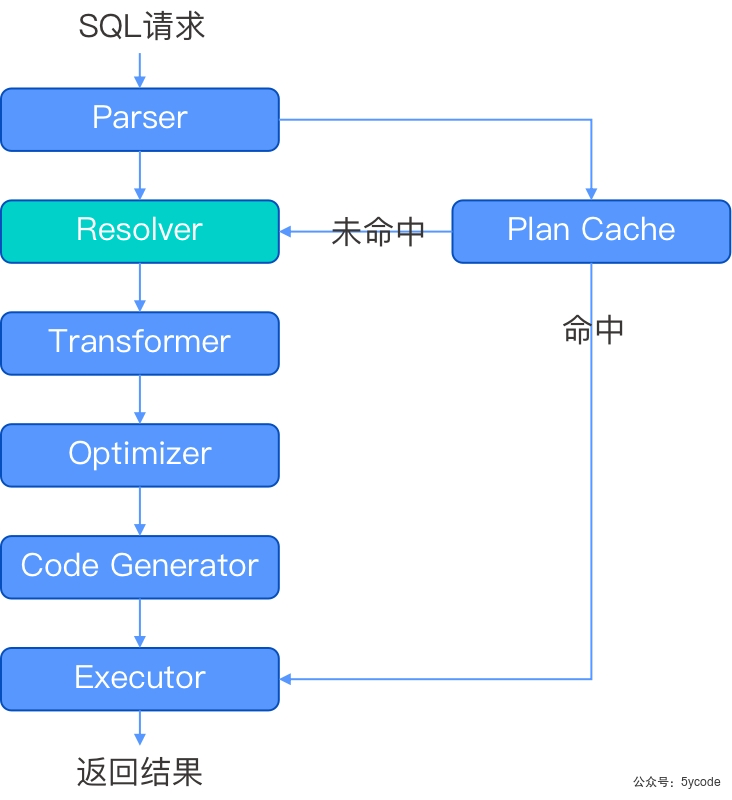
SQL请求执行流程
词法/语法解析- Parser
-- parser 词法/语法解析模块
在收到sql请求后,会将字符串分成一个个的单词,并根据预先设定好的语法规则解析整个请求,将SQL请求字符串转换成带有语法结构信息的内存结构,称之为(语法树)
为了加速sql请求的处理速度,OB对SQL请求采用了快速参数化,以加速查找plan cache的速度;
-- Plan cache 执行计划缓存模块,
将该sql第一次生成的执行计划缓存在内存中,后续的执行可以反复执行这个计划,避免重复查询优化的过程
-- resolver
未命中缓存的会进行resolver解析,resolver会将parser后的语法树转成带有数据库语义的内部数据结构。根据数据库元信息,将sql请求中的token翻译成对应的对象,生成语句树(statment tree)。
- -Transfomer 逻辑改写模块,
分析sql语义,根据内部的规则或代价模型,将用户SQL改写为与之等价的其他形式,并根据提供给后续的优化器进一步优化,主要在 statment tree上做等价变换
-- optimizer 优化器
sql优化核心,为sql请求生成最佳的执行计划,会综合考虑sql的语义、对象数据特征、物理分布等因素,解决访问路径选择、连接顺序选择、联接算法选择,分布式计划生成等核心问题,最终选择一个最佳的sql执行计划。
同时也会自底向上分析,把串行的逻辑执行计划改造成一个可以并行执行的逻辑计划
-- code generator 代码生成器,
将执行计划转换为可执行的代码,缓存到Plan Cache中
-- Executor 执行器,启动SQL的执行
- 本地执行作业:从顶端算子开始调用,根据算子自身的逻辑完成整个执行计划
- 远程或分布式作业:将执行树分成多个可以调度的job,并通过RPC将其发送给相关的节点执行
语义解析- Resolver
Resolver 语义解析模块,将生成的语法树转换成带有数据库语义信息的内部数据结构,
会根据数据库元信息将sql请求中的token翻译成对应的库、表、列、索引等,生成的数据结构叫 statemnet tree (语句树)
逻辑改写-Transformer
在查询优化中,经常利用等价改写的方式,将用户SQL转换为与之等价的另一条SQL,以便于优化器为之生成最佳的执行计划,我们称这一过程为“查询改写”。
改写有两种方式
- 基于规则的改写
- 基于代价的改写
这两种是在一直交替执行的,可能基于规则改写后,又引发了基于代价的改写,直到不能改写为止。
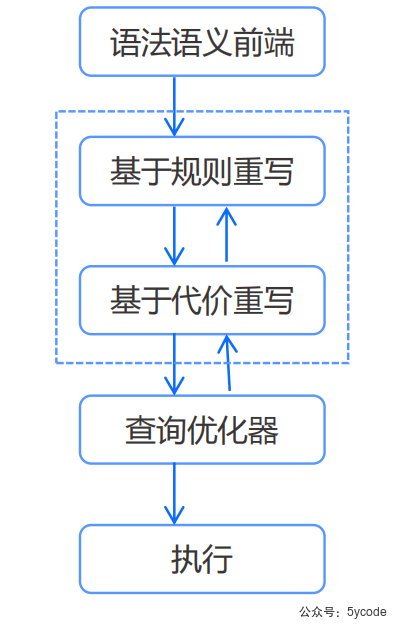
优化器- optimizer
优化器是整个sql请求优化的核心,其作用是为sql请求生成最佳的执行计划。
在优化的过程中,优化器会综合考虑sql请求的语义,对象数据特征、对象物理分布等多方面因素,解决访问路径选择,连接顺序选择、连接算法选择、分布式计划生成等多个核心问题,最终选择一个对应sql的最佳执行计划。
为了利用分布式和多核的优势,ob的查询优化器会对执行计划做并行优化。
代码生成器- code Generator
优化器生成最佳的执行计划,需要通过代码生成器将其转换为可自行的代码。
只是将优化器的结果翻译成可执行代码,并不做任何优化选择。
执行器-executor
本地执行作业
- executor从执行计划顶端算子开始调用
- 由算子自身的逻辑完成整个执行的过程,并返回执行结果。
远程或分布式作业
- executor会根据预选的划分,将执行树分成多个可以调度的job,
- 并通过rpc将其发送给相关节点执行
执行计划缓存- plan cache
为了加速sql请求的处理过程,sql执行引擎会将sql第一次生成的执行计划缓存在内存中,后续对该sql的重复执行可以复用这个计划,避免重复查询优化的过程。
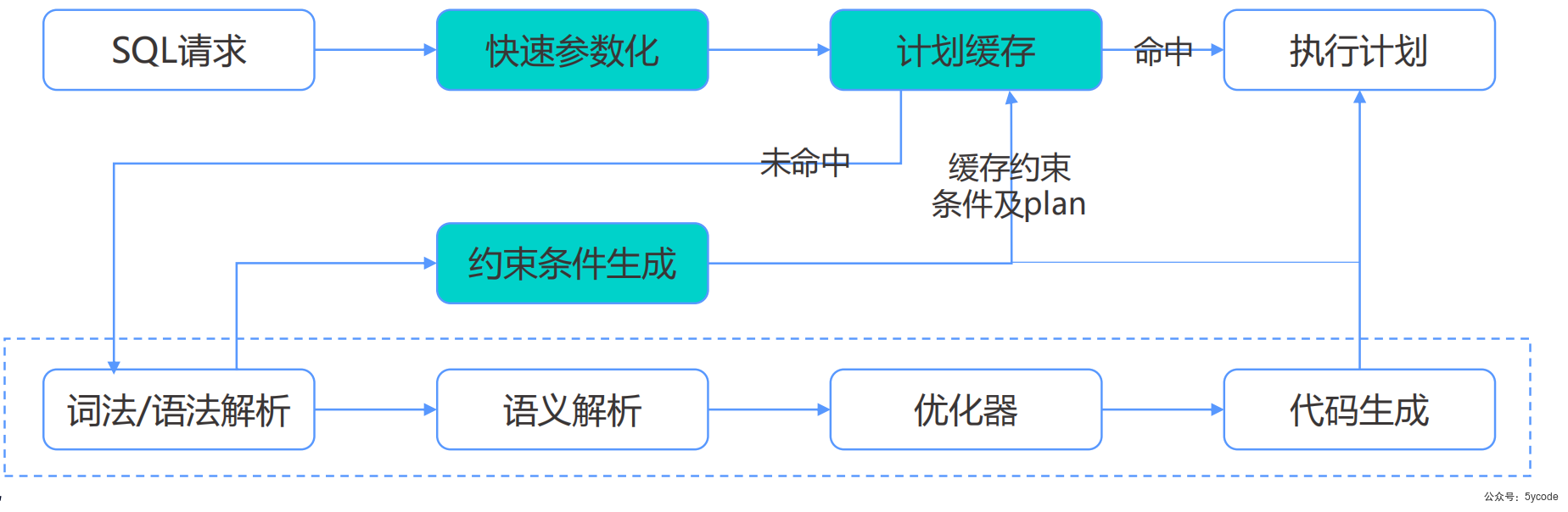
执行计划快速参数化
快速参数化的目的:
- 快速参数化的sql文本可以作为键值在
plan cache中获取执行计划,从而达到仅参数化不同的sql能够共用相同的执行计划。降低sql硬解析的成本,提升查询性能。 - 节省了语法分析过程
- 查找 Hash Map 时,可以将对参数化后语法树的哈希和比较操作,替换为对文本串进行哈希和
MEMCMP操作,以提高执行效率。
什么是参数化?
把sql查询中的常量变成变量的过程。ob使用语法分析对文本串直接参数化后作为 plan cache的键值。
参数化过程举例
无不能参数化的常量
-- 请求sql
select * from t1 where c1 = 5 and c2 = 'oceanbase';
-- 经过词法分析后得到的参数化SQL,
常量5和oceabase被参数化后变成了变量@1和@2
select * from t1 where c1 = @1 and c2 = @2;
-- 参数数组
{5,'oceanbase'}
存在不能参数化的常量
-- sql
select * from t1 where c1 = 5 and c2 = 'oceanbase' order by 1;
-- 经过词法分析后得到的参数化SQL
select * from t1
where c1 = @1 and c2 = @2
order by @3;
-- 参数数组
{5,'oceanbase',1}
-- 约束条件
快速参数化参数数组的第3项必须为数字1
常量不能参数化的场景
只要参数化以后会影响执行计划的,都不能参数化
-
所有order by后面的常量,表示按照
SELECT投影列中第几列进行排序,所以不可以被参数化; -
所有group by 后面的常量,同上
-
limit 后常量,最后返回的条数,如果参数化,执行计划受影响;
-
被物化的参数精度数字(例如"NUMBER(10,2);")
- 比如:
CAST(999.88 as NUMBER(2,1))中的NUMBER(2,1),或者SUBSTR('abcd', 1, 2)中的 1 和 2)
- 比如:
-
select投影列中常量(例如"select 1 as id from tab;")
-
作为格式串的字符串常量(例如"DATE_FORMAT(‘2006-06-00’, ‘%d’); “里面的”%d")
-
函数输入参数中,影响函数结果或带有隐含信息并最终影响执行计划的常量
- (例如"CAST(999.88 as NUMBER(2,1))“中的"NUMBER(2,1)”,
- 或者"SUBSTR(‘abcd’, 1, 2)“中的"1, 2”,
- 或者"SELECT UNIX_TIMESTAMP(‘2015-11-13 10:20:19.012’);" 里面的"2015-11-13 10:20:19.012",指定输入时间戳同时,隐含指定了函数处理的精度值为毫秒)
常量不能参数化举例
-- sql 1及其执行计划
select c1, c2 from t1 order by 1;
explain select c1, c2 from t1 order by 1;
| Query Plan
| ===================================
|ID|OPERATOR |NAME|EST. ROWS|COST|
-----------------------------------
|0 |TABLE SCAN|t1 |22 |40 |
===================================
Outputs & filters:
-------------------------------------
0 - output([t1.c1], [t1.c2]), filter(nil),
access([t1.c1], [t1.c2]), partitions(p0)
1 row in set (0.008 sec)
-- sql2 及其执行计划
select c1, c2 from t1 order by 2;
explain select c1, c2 from t1 order by 2;
| ====================================
|ID|OPERATOR |NAME|EST. ROWS|COST|
------------------------------------
|0 |SORT | |22 |172 |
|1 | TABLE SCAN|t1 |22 |40 |
====================================
Outputs & filters:
-------------------------------------
0 - output([t1.c1], [t1.c2]), filter(nil), sort_keys([t1.c2, ASC])
1 - output([t1.c1], [t1.c2]), filter(nil),
access([t1.c1], [t1.c2]), partitions(p0)
当 order by c1时,c1 为主键,当使用主键的时候,默认就是排序的,不需要再次排序,当order by c2时,需要对c2进行排序,所以不能将order by 后面的常量参数化。
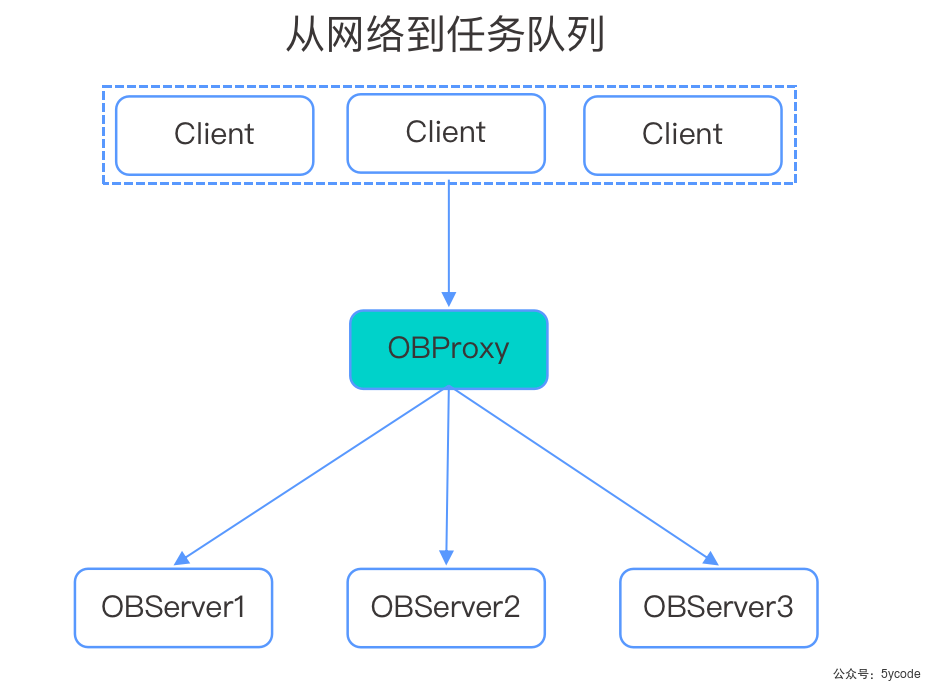
通过OBProxy的sql请求执行流程
- OBProxy包含简单的sql parser功能,
- 从客户端发出的sql语句解析出库名和表名
- 再根据租户名、数据库名、表名,以及分区id等信息,向observer拉取表分区的路由表
- 通过本地缓存的表分区的路由表,路由到合适的observer上。
查看各阶段耗时
obclient [oceanbase]> set ob_enable_trace_log=1;
Query OK, 0 rows affected (0.002 sec)
obclient [oceanbase]> select * from __all_table;
Empty set (0.012 sec)
obclient [oceanbase]> show trace;
+-------------------------------+----------------------------------------------------------------------------+------+
| Title | KeyValue | Time |
+-------------------------------+----------------------------------------------------------------------------+------+
| process begin | in_queue_time:20, receive_ts:1686371489321873, enqueue_ts:1686371489321874 | 0 |
-- parser start
| query begin | trace_id:YB42C0A8500D-0005FC59D439F5E2 | 1 |
| parse begin | stmt:"select * from __all_table", stmt_len:25 | 27 |
-- parser end
| pc get plan begin | | 4 |
| calc partition location begin | | 47 |
| get location cache begin | | 1 |
| get location cache end | | 37 |
| calc partition location end | | 0 |
| pc get plan end | | 13 |
| execution begin | arg1:false, end_trans_cb:false | 3 |
| do open plan begin | plan_id:339064 | 16 |
| sql start stmt begin | | 2 |
| sql start stmt end | | 74 |
| execute plan begin | | 0 |
| execute plan end | | 19 |
| sql start participant begin | | 0 |
| sql start participant end | | 2 |
| do open plan end | | 0 |
| start_close_plan begin | | 1880 |
| start_end_participant begin | | 45 |
| start_end_participant end | | 1 |
| start_close_plan end | | 29 |
| start_auto_end_plan begin | | 1 |
| start_auto_end_plan end | | 21 |
| execution end | | 12 |
| query end | | 36 |
| NULL | PHY_PX_FIFO_COORD | |
| NULL | PHY_PX_REDUCE_TRANSMIT | |
| NULL | PHY_GRANULE_ITERATOR | |
| __all_table | PHY_TABLE_SCAN | |
+-------------------------------+----------------------------------------------------------------------------+------+
obclient [oceanbase]> select * from test.t1 where c1='a1';
obclient [oceanbase]> show trace;
+------------------------------+----------------------------------------------------------------------------+------+
| Title | KeyValue | Time |
+------------------------------+----------------------------------------------------------------------------+------+
| process begin | in_queue_time:24, receive_ts:1686381878258114, enqueue_ts:1686381878258114 | 0 |
-- parser start
| query begin | trace_id:YB42C0A8500A-0005FC59CA16E851 | 0 |
| parse begin | stmt:"select * from test.t1 where c1='a1'", stmt_len:35 | 21 |
-- parser end
| pc get plan begin | | 3 |
| pc get plan end | | 12 |
| transform_with_outline begin | | 0 |
| transform_with_outline end | | 40 |
-- resolve start
| resolve begin | | 38 |
| resolve end | | 174 |
-- resolve end
-- transform start
| transform begin | | 36 |
| transform end | | 186 |
-- transform end
-- optimizer start
| optimizer begin | | 2 |
| get location cache begin | | 123 |
| get location cache end | | 101 |
| optimizer end | | 199 |
-- optimizer end
-- code generator start
| cg begin | | 0 |
| cg end | | 74 |
-- code generator end
-- execution 结束
| execution begin | arg1:false, end_trans_cb:false | 71 |
| do open plan begin | plan_id:211 | 10 |
| sql start stmt begin | | 0 |
| sql start stmt end | | 1 |
| execute plan begin | | 0 |
| execute plan end | | 5 |
| sql start participant begin | | 0 |
| sql start participant end | | 1 |
| do open plan end | | 0 |
| table scan begin | | 8 |
| table scan end | | 21 |
| start_close_plan begin | | 23 |
| start_end_participant begin | | 6 |
| start_end_participant end | | 1 |
| start_close_plan end | | 0 |
| start_auto_end_plan begin | | 1 |
| start_auto_end_plan end | | 1 |
| execution end | |
-- execution 结束
3 |
| query end | | 33 |
| t1 | PHY_TABLE_SCAN | |
+------------------------------+----------------------------------------------------------------------------+------+
37 rows in set (0.010 sec)
-- 执行计划缓存以后,下次再执行,就直接用缓存了
obclient [oceanbase]> select * from test.t1 where c1='a1';
+----+------+
| c1 | c2 |
+----+------+
| a1 | b1 |
+----+------+
1 row in set (0.002 sec)
obclient [oceanbase]> show trace;
+-----------------------------+----------------------------------------------------------------------------+------+
| Title | KeyValue | Time |
+-----------------------------+----------------------------------------------------------------------------+------+
| process begin | in_queue_time:19, receive_ts:1686382022234006, enqueue_ts:1686382022234007 | 0 |
| query begin | trace_id:YB42C0A8500A-0005FC59CA16E853 | 1 |
| parse begin | stmt:"select * from test.t1 where c1='a1'", stmt_len:35 | 30 |
| pc get plan begin | | 4 |
| pc get plan end | | 39 |
| execution begin | arg1:false, end_trans_cb:false | 2 |
| do open plan begin | plan_id:211 | 11 |
| sql start stmt begin | | 1 |
| sql start stmt end | | 0 |
| execute plan begin | | 0 |
| execute plan end | | 6 |
| sql start participant begin | | 0 |
| sql start participant end | | 0 |
| do open plan end | | 0 |
| table scan begin | | 8 |
| table scan end | | 33 |
| start_close_plan begin | | 20 |
| start_end_participant begin | | 4 |
| start_end_participant end | | 1 |
| start_close_plan end | | 0 |
| start_auto_end_plan begin | | 1 |
| start_auto_end_plan end | | 1 |
| execution end | | 3 |
| query end | | 19 |
| t1 | PHY_TABLE_SCAN | |
+-----------------------------+----------------------------------------------------------------------------+------+
25 rows in set (0.003 sec)
-- 执行计划参数化的情况
obclient [oceanbase]> show trace;
+-----------------------------+----------------------------------------------------------------------------+------+
| Title | KeyValue | Time |
+-----------------------------+----------------------------------------------------------------------------+------+
| process begin | in_queue_time:23, receive_ts:1686382175911151, enqueue_ts:1686382175911153 | 0 |
| query begin | trace_id:YB42C0A8500A-0005FC59CA16E855 | 1 |
| parse begin | stmt:"select * from test.t1 where c1='a2'", stmt_len:35 | 49 |
| pc get plan begin | | 7 |
| pc get plan end | | 58 |
| execution begin | arg1:false, end_trans_cb:false | 4 |
| do open plan begin | plan_id:211 | 34 |
| sql start stmt begin | | 1 |
| sql start stmt end | | 1 |
| execute plan begin | | 0 |
| execute plan end | | 10 |
| sql start participant begin | | 0 |
| sql start participant end | | 1 |
| do open plan end | | 1 |
| table scan begin | | 15 |
| table scan end | | 43 |
| start_close_plan begin | | 37 |
| start_end_participant begin | | 9 |
| start_end_participant end | | 1 |
| start_close_plan end | | 0 |
| start_auto_end_plan begin | | 2 |
| start_auto_end_plan end | | 1 |
| execution end | | 7 |
| query end | | 30 |
| t1 | PHY_TABLE_SCAN | |
+-----------------------------+----------------------------------------------------------------------------+------+
25 rows in set (0.003 sec)
DML语句处理
什么是DML?
DML是 data Manipulation language 的缩写,数据操作语言,主要是以insert、update、delete三种指令为核心。另外还包括 replace 、insert into … on duplicated key update ;
insert 执行计划示例
obclient [test]> create table t2(a int primary key, b int, index idx1(b));
Query OK, 0 rows affected (0.142 sec)
obclient [test]> explain insert into t2 values(1, 1), (2, 2);
| Query Plan
| ====================================
|ID|OPERATOR |NAME|EST. ROWS|COST|
------------------------------------
|0 |INSERT | |2 |1 |
|1 | EXPRESSION| |2 |1 |
====================================
-- 只有两个算子EXPRESSION 和INSERT
Outputs & filters:
-------------------------------------
0 - output([column_conv(INT,PS:(11,0),NOT NULL,__values.a)], [column_conv(INT,PS:(11,0),NULL,__values.b)]), filter(nil),
columns([{t2: ({t2: (t2.a, t2.b)})}]), partitions(p0)
1 - output([__values.a], [__values.b]), filter(nil)
values({1, 1}, {2, 2})
update执行计划示例
对于update或delete语句,优化器通过代价模型对where条件进行路径访问的选择,或者order by 数据顺序的选择。
obclient [test]> explain update t2 set b=10 where b=1;
| Query Plan
| ========================================
|ID|OPERATOR |NAME |EST. ROWS|COST|
----------------------------------------
|0 |UPDATE | |990 |1636|
|1 | TABLE SCAN|t2(idx1)|990 |646 |
========================================
-- 根据where条件进行路径访问 根据索引t2(idx1)
Outputs & filters:
-------------------------------------
0 - output(nil), filter(nil), table_columns([{t2: ({t2: (t2.a, t2.b)})}]),
update([t2.b=?])
1 - output([t2.a], [t2.b], [?]), filter(nil),
access([t2.b], [t2.a]), partitions(p0) -- 访问路径
|
1 row in set (0.004 sec)
一致性校验
- DML操作的表对象有一系列约束,在写入数据前会
- 对列的not null、unique key约束检查
- 对写入数据进行类型转换
- 约束性检查失败,回滚该DML语句写入的脏数据
锁管理TODO
- 加锁时机- 通过MVCC和锁结合的机制
- 只有行锁,没有表锁;在线DDL,不中断DML
- 同一行的不同列修改会导致互斥
- 锁存储在行上(内存或磁盘)
- 行锁释放后是顺序唤醒执行(事务与事务的唤醒)
- 尽量避免大量DML语句对同一行进行频繁的并发读写;
- 热点行:可以使用
select ... for update对该行加锁,然后再执行DML操作;- 无法做到读写不互斥,事务提交的时候,为了维护事务的一致性快照,会短暂的读写互斥,称为lock for read
- 只有行锁,没有表锁;在线DDL,不中断DML
- 加锁顺序
- DML会级联的同步更新数据表中的数据和索引表中的数据;
- local index 和单表 global index绑定
- 分区表 global index 完全独立;
死锁解决
- 锁超时机制:通过配置
ob_trx_lock_timeout,默认为语句的超时时间 - 语句超时机制:配置项为
ob_query_timeout默认为10秒 - 事务超时机制: 配置项为
ob_trx_timeout默认为100秒
除了超时,还会有主动解决
DDL语句处理
DDL 流程
OB 的DDL语句不会被优化器处理;
OB的DDL作为command发送到RootServer
RootServer处理
1, 变更信息先持久化
2, 本地schema刷新;
3, 通知其他observer异步刷新
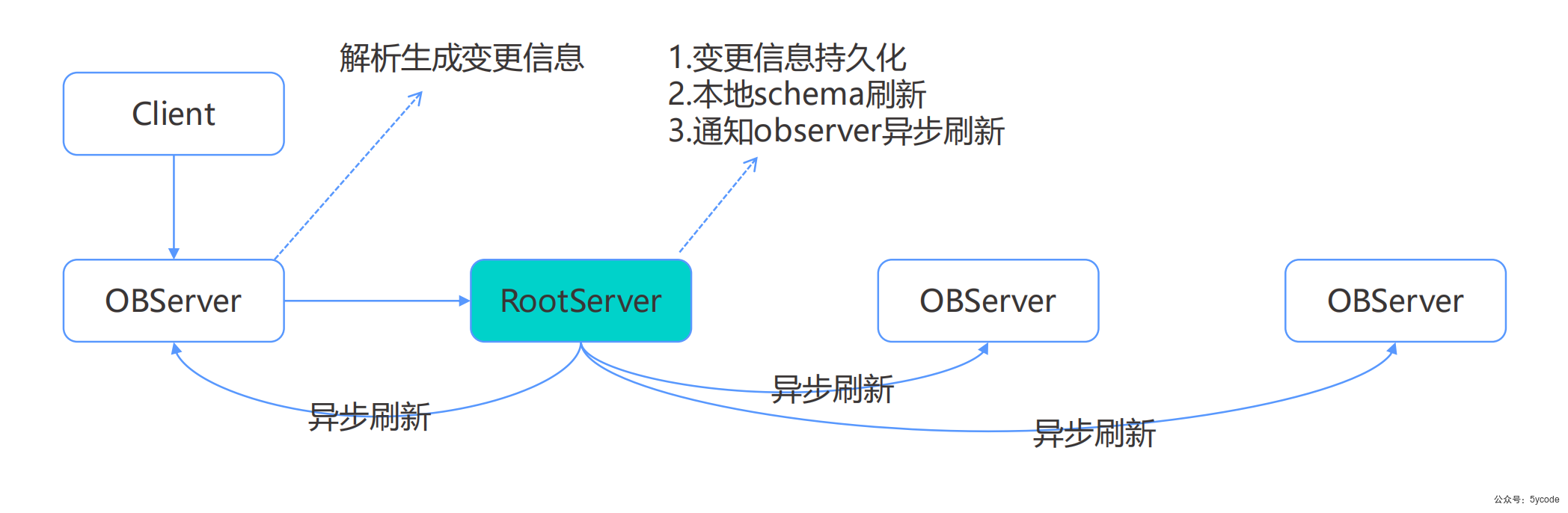
DDL语句处理
- 自动完成全局统一的schema变更,无需用户做一致性检查;
- DDL任务由RootServer 统一调度执行,保证全局范围的一致性;
- 所有DDL都是online的,不会锁表,不会阻塞业务的读写操作;没有锁表的概念
- DML根据schema信息的变更自动记录格式,对业务零影响;
- DML与DDL互不阻塞
查询改写
概念
查询改写是把一个SQL改写成另外一个更加容易优化的sql。
- 基于规则的改写总是会把sql往**“好”**的方向改写,从而增加该SQL的优化空间
- 基于规则的查询改写,并不能总是把SQL往**”好“**的方向改写,需要代价模型来作为判断;比如OR表达式
- 基于代价模型的改写又会触发基于规则的改写,整体采用迭代式的方式进行改写;
需要注意:改写的结果并不一定是好的
基于规则的改写
主要包括
- 子查询相关改写
- 视图合并、子查询展开、any/all 使用 max/min改写;
- 外连接消除
- 简化条件改写
- having 条件消除、等价关系推导、恒真/假消除;
- 非SPJ的改写
- 冗余排序消除、limit下压、distinct 消除、min/max 改写
子查询相关改写 TODO
优化器对于子查询一般使用嵌套执行的方式,也就是父查询每生成一行数据后,都需要执行一次子查询。多次执行子查询、执行效率低。
主要优化点:
- 避免子查询多次执行
- 选择更优的联接顺序和联接方法
- 子查询的联接条件、过滤条件改写为父查询的条件后,优化器进一步优化,比如条件下压等;
视图合并
视图合并是指将代表一个视图的子查询合并到包含该视图的查询中,视图合并后,有助于优化器增加链接顺序的选择,访问路径的选择,以及进一步做其他的改写操作。 增加路径的选择
-- 我们创建三张测试表
CREATE TABLE t1 (c1 INT, c2 INT);
CREATE TABLE t2 (c1 INT PRIMARY KEY, c2 INT);
CREATE TABLE t3 (c1 INT PRIMARY KEY, c2 INT);
-- SQL A 不进行改写
SELECT t1.c1, v.c1
FROM t1, (SELECT t2.c1, t3.c2
FROM t2, t3
WHERE t2.c1 = t3.c1) v
WHERE t1.c2 = v.c2;
-- 可选链接顺序有
•t1, v(t2,t3)
•t1, v(t3,t2)
•v(t2,t3), t1
•v(t3,t2), t1
-- 视图合并改写SQL_B
SELECT t1.c1, t2.c1
FROM t1, t2, t3
WHERE t2.c1 = t3.c1
AND t1.c2 = t3.c2;
-- 可选的链接顺序有
•t1, t2, t3
•t1, t3, t2
•t2, t1, t3
•t2, t3, t1
•t3, t1, t2
•t3, t2, t1
子查询展开为 半连接 semi-join/anti-join
- 改写条件使生成的联接语句能够返回与原始语句相同的行。
子查询展开是将where条件中子查询提升到父查询中,并作为联接条件与父查询并列进行展开。一般涉及的子查询表达式有not in、not exist、exist、any、all。
-- 创建表
CREATE TABLE t1 (c1 INT, c2 INT)
CREATE TABLE t2 (c1 INT PRIMARY KEY, c2 INT)
-- 执行计划
EXPLAIN SELECT * FROM t1 WHERE t1.c1 IN (SELECT t2.c2 FROM t2)\G;
*************************** 1. row ***************************
Query Plan:
=======================================
|ID|OPERATOR |NAME|EST. ROWS|COST|
---------------------------------------
|0 |HASH SEMI JOIN| |495 |3931| -- 展开为了半连接
|1 | TABLE SCAN |t1 |1000 |499 |
|2 | TABLE SCAN |t2 |1000 |433 |
=======================================
Outputs & filters:
-------------------------------------
0 - output([t1.c1], [t1.c2]), filter(nil),
equal_conds([t1.c1 = t2.c2]), other_conds(nil)
1 - output([t1.c1], [t1.c2]), filter(nil),
access([t1.c1], [t1.c2]), partitions(p0)
2 - output([t2.c2]), filter(nil),
access([t2.c2]), partitions(p0)
-- 改写后返回的相同的结果
-- 展开为了半连接
将查询前面的操作符改为 not in 后,可改写为 anti join
子查询展开为内连接
子查询展开是指将 where 条件中子查询提升到父查询中,并作为连接条件与父查询并列进行展开。 一般涉及的子查询表达式有 not in、in、not exist、exist、any、all。
EXPLAIN SELECT * FROM t1 WHERE t1.c1 IN (SELECT t2.c1 FROM t2)\G;
*************************** 1. row ***************************
Query Plan:
====================================
|ID|OPERATOR |NAME|EST. ROWS|COST|
------------------------------------
|0 |HASH JOIN | |1980 |3725| -- t2的c1是主键,具备唯一性,可以转成内连接
|1 | TABLE SCAN|t2 |1000 |411 |
|2 | TABLE SCAN|t1 |1000 |499 |
====================================
Outputs & filters:
-------------------------------------
0 - output([t1.c1], [t1.c2]), filter(nil),
equal_conds([t1.c1 = t2.c1]), other_conds(nil)
1 - output([t2.c1]), filter(nil),
access([t2.c1]), partitions(p0)
2 - output([t1.c1], [t1.c2]), filter(nil),
access([t1.c1], [t1.c2]), partitions(p0)
外连接消除
外联接操作可分为左外联接、右外联接和全外联接。在联接过程中,由于外联接左右顺序不能变换,优化器对联接顺序的选择会受到限制。
外连接消除是指将外连接转换成内连接,从而可以提供更多可选择的连接路径,供优化器考虑。外连接消除需要存在“空值拒绝条件”,即 where 条件中,存在当内表生成的值为 null 时,使得输出为 false 的条件。
-- 这条外连接的sql中,t2.c2可能为null,不会做外链接消除
SELECT t1.c1, t2.c2 FROM t1 LEFT JOIN t2 ON t1.c2 = t2.c2;
-- 加上t2.c2 >5 以后t2.c2不会出现null
SELECT t1.c1, t2.c2 FROM t1 LEFT JOIN t2 ON t1.c2 = t2.c2 WHERE t2.c2 > 5;
-- 直接会优化成
SELECT t1.c1, t2.c2 FROM t1 INNER JOIN t2 ON t1.c2 = t2.c2 WHERE t2.c2 > 5;
基于代价的查询改写
OceanBase 目前只有一种支持基于代价的查询改写 - 或展开(Or-Expansion)
或展开(Or-Expansion):把一个查询改写成若干个用 union all 组成的子查询,这个改写可能会给每个子查询提供更优的优化空间,但是也会导致多个子查询的执行,所以这个改写需要基于代价去判断。
三个作用:
- 允许每个分支使用不同的索引来加速查询
- 允许每个分支使用不同的连接算法来加速查询,避免使用笛卡尔连接
- 允许每个分支分别消除排序,更加快速的获取top-k结果
每个分支使用不同的索引来加速查询
-- 创建表
CREATE TABLE t1(a INT, b INT, c INT, d INT, e INT, INDEX IDX_a(a), INDEX IDX_b(b));
-- 执行sql
SELECT * FROM t1 WHERE t1.a = 1 OR t1.b = 1;
-- 改写后的sql,可以分别使用索引
SELECT * FROM t1
WHERE t1.a = 1
UNION ALL
SELECT * FROM t1
WHERE t1.b = 1 AND LNNVL(t1.a = 1); -- 谓词LNNVL(t1.a=1) 保证两个子查询不会生成重复的结果
-- 如果sql不进行改写,执行计划如下:
EXPLAIN SELECT/*+NO_REWRITE()*/ * FROM t1 WHERE t1.a = 1 OR t1.b = 1;
+--------------------------------------------------------------+
| Query Plan |
+--------------------------------------------------------------+
| ===================================
|ID|OPERATOR |NAME|EST. ROWS|COST|
-----------------------------------
|0 |TABLE SCAN|t1 |4 |649 | -- 没有改写直接全表扫描
===================================
Outputs & filters:
-------------------------------------
0 - output([t1.a], [t1.b], [t1.c], [t1.d], [t1.e]), filter([t1.a = 1 OR t1.b = 1]),
access([t1.a], [t1.b], [t1.c], [t1.d], [t1.e]), partitions(p0)
-- 改写后执行计划如下
EXPLAIN SELECT * FROM t1 WHERE t1.a = 1 OR t1.b = 1;
+------------------------------------------------------------------------+
|ID|OPERATOR |NAME |EST. ROWS|COST|
-----------------------------------------
|0 |UNION ALL | |3 |190 |
|1 | TABLE SCAN|t1(idx_a)|2 |94 | -- 分别使用了索引
|2 | TABLE SCAN|t1(idx_b)|1 |95 |
=========================================
Outputs & filters:
-------------------------------------
0 - output([UNION(t1.a, t1.a)], [UNION(t1.b, t1.b)], [UNION(t1.c, t1.c)],
[UNION(t1.d, t1.d)], [UNION(t1.e, t1.e)]), filter(nil)
1 - output([t1.a], [t1.b], [t1.c], [t1.d], [t1.e]), filter(nil),
access([t1.a], [t1.b], [t1.c], [t1.d], [t1.e]), partitions(p0)
2 - output([t1.a], [t1.b], [t1.c], [t1.d], [t1.e]), filter([lnnvl(t1.a = 1)]),
access([t1.a], [t1.b], [t1.c], [t1.d], [t1.e]), partitions(p02)
每个分支使用不同的联接算法来加速查询
-- 表结构
CREATE TABLE t1(a INT, b INT);
CREATE TABLE t2(a INT, b INT);
-- 原sql,使用笛卡尔
SELECT * FROM t1, t2 WHERE t1.a = t2.a OR t1.b = t2.b;
-- 改写后,每个子查询都可以选择Nested Loop Join、Hash Join 或者Merge Join,这样会有更多的优化空间
SELECT * FROM t1, t2
WHERE t1.a = t2.a
UNION ALL
SELECT * FROM t1, t2
WHERE t1.b = t2.b AND LNNVL(t1.a = t2.a);
-- 原sql未改写前的执行计划
EXPLAIN SELECT/*+NO_REWRITE()*/ * FROM t1, t2 WHERE t1.a = t2.a OR t1.b = t2.b;
+--------------------------------------------------------------------------+
|ID|OPERATOR |NAME|EST. ROWS|COST |
-------------------------------------------
|0 |NESTED-LOOP JOIN| |3957 |585457| -- 使用笛卡尔乘积,性能会比较低
|1 | TABLE SCAN |t1 |1000 |499 |
|2 | TABLE SCAN |t2 |4 |583 |
===========================================
Outputs & filters:
-------------------------------------
0 - output([t1.a], [t1.b], [t2.a], [t2.b]), filter(nil),
conds(nil), nl_params_([t1.a], [t1.b])
1 - output([t1.a], [t1.b]), filter(nil),
access([t1.a], [t1.b]), partitions(p0)
2 - output([t2.a], [t2.b]), filter([? = t2.a OR ? = t2.b]),
access([t2.a], [t2.b]), partitions(p0)
-- 查询优化后的sql的执行计划
EXPLAIN SELECT * FROM t1, t2 WHERE t1.a = t2.a OR t1.b = t2.b;
+--------------------------------------------------------------------------+
|ID|OPERATOR |NAME|EST. ROWS|COST|
-------------------------------------
|0 |UNION ALL | |2970 |9105| 每个子查询分别选择了hash join ,最后进行union all
|1 | HASH JOIN | |1980 |3997|
|2 | TABLE SCAN|t1 |1000 |499 |
|3 | TABLE SCAN|t2 |1000 |499 |
|4 | HASH JOIN | |990 |3659|
|5 | TABLE SCAN|t1 |1000 |499 |
|6 | TABLE SCAN|t2 |1000 |499 |
=====================================
Outputs & filters:
-------------------------------------
0 - output([UNION(t1.a, t1.a)], [UNION(t1.b, t1.b)], [UNION(t2.a, t2.a)], [UNION(t2.b, t2.b)]), filter(nil)
1 - output([t1.a], [t1.b], [t2.a], [t2.b]), filter(nil),equal_conds([t1.a = t2.a]), other_conds(nil)
2 - output([t1.a], [t1.b]), filter(nil),access([t1.a], [t1.b]), partitions(p0)
3 - output([t2.a], [t2.b]), filter(nil),access([t2.a], [t2.b]), partitions(p0)
4 - output([t1.a], [t1.b], [t2.a], [t2.b]), filter(nil),
equal_conds([t1.b = t2.b]), other_conds([lnnvl(t1.a = t2.a)])
5 - output([t1.a], [t1.b]), filter(nil),access([t1.a], [t1.b]), partitions(p0)
6 - output([t2.a], [t2.b]), filter(nil),access([t2.a], [t2.b]), partitions(p0)
每个分支分表消除排序
-- 建表语句
CREATE TABLE t1(a INT, b INT, INDEX IDX_a(a, b));
-- 原sql
SELECT * FROM t1
WHERE t1.a = 1 OR t1.a = 2
ORDER BY b LIMIT 10;
-- 改写后sql,如果存在索引a,b,sql中的子查询都可以用到索引并把排序消除,每个子查询取top-10结果,最终合并再取top10
SELECT * FROM
(SELECT * FROM t1
WHERE t1.a = 1
ORDER BY b LIMIT 10
UNION ALL
SELECT * FROM t1
WHERE t1.a = 2
ORDER BY b LIMIT 10
) AS TEMP
ORDER BY temp.b LIMIT 10;
-- 原sql执行计划
EXPLAIN SELECT/*+NO_REWRITE()*/ * FROM t1 WHERE t1.a = 1 OR t1.a = 2
ORDER BY b LIMIT 10;
+-------------------------------------------------------------------------+
| Query Plan
+-------------------------------------------------------------------------+
|ID|OPERATOR |NAME |EST. ROWS|COST|
------------------------------------------
|0 |LIMIT | |4 |77 |
|1 | TOP-N SORT | |4 |76 | -- 先通过scan找出满足条件的数据,然后再排序,最后返回top 10
|2 | TABLE SCAN|t1(idx_a)|4 |73 |
==========================================
Outputs & filters:
-------------------------------------
0 - output([t1.a], [t1.b]), filter(nil), limit(10), offset(nil)
1 - output([t1.a], [t1.b]), filter(nil), sort_keys([t1.b, ASC]), topn(10) -- 排序
2 - output([t1.a], [t1.b]), filter(nil), access([t1.a], [t1.b]), partitions(p0) -- 取top 10
-- 改写后的sql执行计划
EXPLAIN SELECT * FROM t1 WHERE t1.a = 1 OR t1.a = 2 ORDER BY b LIMIT 10;
+-------------------------------------------------------------------------+
| Query Plan |
+-------------------------------------------------------------------------+
|ID|OPERATOR |NAME |EST. ROWS|COST|
-------------------------------------------
|0 |LIMIT | |3 |76 |
|1 | TOP-N SORT | |3 |76 |
|2 | UNION ALL | |3 |74 |
|3 | TABLE SCAN|t1(idx_a)|2 |37 | -- 两个子查询都利用索引的特性,消除了排序,
|4 | TABLE SCAN|t1(idx_a)|1 |37 |
===========================================
Outputs & filters:
-------------------------------------
0 - output([UNION(t1.a, t1.a)], [UNION(t1.b, t1.b)]), filter(nil), limit(10), offset(nil) -- 分别利用索引找到数据
1 - output([UNION(t1.a, t1.a)], [UNION(t1.b, t1.b)]), filter(nil),
sort_keys([UNION(t1.b, t1.b), ASC]), topn(10) -- 两个结果合并,按b排序,取top 10
2 - output([UNION(t1.a, t1.a)], [UNION(t1.b, t1.b)]), filter(nil)
3 - output([t1.a], [t1.b]), filter(nil),access([t1.a], [t1.b]), partitions(p0),limit(10), offset(nil)
4 - output([t1.a], [t1.b]), filter([lnnvl(t1.a = 1)]),access([t1.a], [t1.b]), partitions(p0),
limit(10), offset(nil)
执行计划
https://www.oceanbase.com/docs/enterprise-oceanbase-database-cn-10000000000946877
- sql是描述型语言,用户在使用的时候,只是描述了要做什么
- Ob接收到的sql,必须生成一个执行计划,本质上是由物理操作符组成的执行树,用来告诉server怎么做
- 执行树可以分为
左深树、右深树、多枝树 - OB优化器主要是考虑
左深树
执行计划展示(explain)
- 通过explain命令查看优化器针对给定sql生成的逻辑执行计划
- explain不会真正执行给定的sql,不用担心带来的性能影响
EXPLAIN [explain_type] dml_statement;
explain_type:
BASIC
| OUTLINE -- 显示outline信息
| EXTENDED -- 将扫描的范围段展示出来
| EXTENDED_NOADDR
| PARTITIONS -- 用于检查设计分区表的查询,如果针对非分区表的查询,partions列的值始终为null
| FORMAT = { TRADITIONAL | JSON } -- 选择输出格式,默认是TRADITIONAL,可以选择JSON
dml_statement:
SELECT statement
| DELETE statement
| INSERT statement
| REPLACE statement
| UPDATE statement
命令格式
执行计划命令有三种模式,分别展现不同粒度的细节信息:
explain basic命令用于最基本的计划展示;explain extended命令用于最详细的计划展示(通常在排查问题时使用这种模式)- 将扫描的范围段展示出来
explain命令所展示的信息可以帮助普通用户了解整个计划的执行方式
展示格式
计划形状与算子信息
- explain输出的第一部分是执行计划的属性结构展示,通过算子可以看到操作层次
- 层次最深的优先执行,层次相同的以特定算子的执行顺序为标准执行
obclient [test]> explain update t2 set b=10 where b=1;
| Query Plan -- 计划形状与算子信息
| ========================================
|ID|OPERATOR |NAME |EST. ROWS|COST|
----------------------------------------
|0 |UPDATE | |990 |1636|
|1 | TABLE SCAN|t2(idx1)|990 |646 | -- 最深入的先执行
========================================
-- 根据where条件进行路径访问
-- 各操作算子的详细信息
-- 表达式、过滤条件、分区信息
Outputs & filters:
-------------------------------------
0 - output(nil), filter(nil), table_columns([{t2: ({t2: (t2.a, t2.b)})}]),
update([t2.b=?])
1 - output([t2.a], [t2.b], [?]), filter(nil),
access([t2.b], [t2.a]), partitions(p0)
|
1 row in set (0.004 sec)
计划形状与算子信息 ☆
-- 各列含义
|ID|OPERATOR |NAME |EST. ROWS|COST|
----------------------------------------
- id 执行树按照前序遍历的方式得到的编号,从0开始
- operator 操作算子的名称
- name 对应表操作的表名或索引名
- EST.ROWS 估算的该操作算子的输出行数
- COST 该操作算子的执行代价(微秒)
-- 常见算子,这个也会考
table lookup 用于表示全局索引的回表逻辑
表访问算子 属于 `table scan` 算子的两个操作 table scan 范围找 table get直接找;
join 连接算子 nested-loop,blk-nested-loop,merge,hash
排序算子 sort top-n sort
聚合算子 merge group by, hash group by ,window function
分布式算子 exchange in/out remote/distribute
集合算子 union,except,intersect,minus
其他算子 limit,material,subplan,expression,count
Table scan 算子
- 是存储层和SQL层的接口,永远忽展示优化器选择哪个索引来访问数据
- 对于普通索引,索引的回表逻辑封装在
table scan算子中 - 对于全局索引,索引的回表逻辑由
table looup算子完成
注意:
table scan算子的operator有两种形式,一种是 table scan 范围扫描,一种是table get 根据主键定位
join 联接算子
join类型有: 内联接(inner join)、外联接(outer join)和半联接(semi/anti join)
join算子主要有
NESTED LOOP JOIN简称NLJ 连接2个子节点MERGE JOIN简称 MJ ,要求左右子节点的数据相对于联接列是有序的HASH JSON简称HJ , 根据连接列计算hash值
排序算子
主要对输入的数据进行排序。
order by 生成 SORT 算子
order by 后面跟 limit 生成 TOP-N SORT 算子
聚合算子
对数据进行分组的算法有HASH算法和MERGE算法 ,根据算法将GROUP BY算子分为
HASH GROUP BYMERGE GROUP BY
对于普通的聚合函数(SUM/MAX/MIN/AVG/COUNT/STDDEV) 也是通过分配GROUP BY算子来完成。分配的是
SCALAR GROUP BY
还有一个比较特殊的用于实现SQL中的分析函数(窗口函数),计算窗口内的相关行的结果。窗口每组可以返回多行。聚合函数一组只能返回一行。
WINDOW FUNCTION
分布式算子
EXCHANGE算子用于线程间进行数据交互的算子,用于分布式场景,一般都是成对出现的。
EXCHANGE IN/ EXCHANGE OUT用于将多个分区上的数据汇聚到一起,发送到查询所在的主节点EXCH-IN/OUT (REMOTE)用于将远程的数据拉回本地EXCH-IN/OUT (PKEY)用于数据重分区- ·
EXCH-IN/OUT (HASH)用于对数据使用一组哈希函数进行重分区 EXCH-IN/OUT(BROADCAST)用于对输入数据使用BROADCAST的方法进行重分区
集合算子
UNION 用于将两个查询的结果集进行并集运算,包括
UNION ALL用于直接对两个查询结果集进行合并输出HASH UNION DISTINCT用于对结果集进行并集、去重后进行输出MERGE UNION DISTINCT用于对结果集进行并集、去重后进行输出
EXCEPT 用于对左右子节点算子输出集合进行差集运算,并进行去重
MERGE EXCEPT DISTINCTHASH EXCEPT DISTINCT
MINUS Oracle 一般使用这个进行差集运算,mysql不区分
INTERSECT 用于对左右子节点算子输出进行交集运算,并进行去重
MERGE INTERSECT DISTINCTHASH INTERSECT DISTINCT
其他算子
LIMIT 算子用于限制数据输出的行数,这与 MySQL 的 LIMIT 算子功能相同。
MATERIAL 算子用于物化下层算子输出的数据。
SUBPLAN FILTER 算子用于驱动表达式中的子查询执行。
SUBPLAN SCAN 算子用于展示优化器从哪个视图访问数据。
COUNT 算子用于兼容 Oracle 的 ROWNUM 功能,实现 ROWNUM 表达式的自增操作。
SELECT INTO 算子用于将查询结果赋值给变量列表,查询仅返回一行数据。
FOR UPDATE 算子用于对表中的数据进行加锁操作。
操作算子详细输出
- explain的第二部分是各操作算子的详细信息,包括输出表达式,过滤条件,分区信息以及个算子的独有信息,包括排序键,连接键,下压条件等
Outputs & filters:
-------------------------------------
0 - output(nil), filter(nil), table_columns([{t2: ({t2: (t2.a, t2.b)})}]),
update([t2.b=?])
1 - output([t2.a], [t2.b], [?]), filter(nil),
access([t2.b], [t2.a]), partitions(p0)
示例TODO
-- 表结构
CREATE TABLE `t3` (
`c1` INT ( 11 ) NOT NULL,
`c2` INT ( 11 ) NOT NULL,
`c3` INT ( 11 ) DEFAULT NULL,
`c4` INT ( 11 ) DEFAULT NULL,
`c5` INT ( 11 ) DEFAULT NULL,
PRIMARY key(c2,c1),
KEY `idx_c3` ( `c3` ) BLOCK_SIZE 16384 LOCAL
) DEFAULT CHARSET = utf8mb4 ROW_FORMAT = COMPACT COMPRESSION = 'zstd_1.3.8' REPLICA_NUM = 3 BLOCK_SIZE = 16384 USE_BLOOM_FILTER = FALSE TABLET_SIZE = 134217728 PCTFREE = 0;
obclient [test]> explain extended select /*+ index(1 idx_c2) */* from t3 where c3 = 5 and c1 = 6 order by c2, c3;
| Query Plan
| =========================================
|ID|OPERATOR |NAME |EST. ROWS|COST|
-----------------------------------------
|0 |TABLE SCAN|t3(idx_c3)|1 |85 |
=========================================
-- 查询t3的索引idx_c3 耗时 85微秒
Outputs & filters:
-------------------------------------
0 - output([t3.c1(0x7f5e55b69520)], [t3.c2(0x7f5e55b697e0)], [t3.c3(0x7f5e55b25970)], [t3.c4(0x7f5e55b69aa0)], [t3.c5(0x7f5e55b69d60)]), filter([t3.c1(0x7f5e55b69520) = 6(0x7f5e55b68e70)]),
access([t3.c3(0x7f5e55b25970)], [t3.c1(0x7f5e55b69520)], [t3.c2(0x7f5e55b697e0)], [t3.c4(0x7f5e55b69aa0)], [t3.c5(0x7f5e55b69d60)]), partitions(p0),
is_index_back=true, filter_before_indexback[true],
range_key([t3.c3(0x7f5e55b25970)], [t3.c2(0x7f5e55b697e0)], [t3.c1(0x7f5e55b69520)]), range(5,MIN,MIN ; 5,MAX,MAX),
range_cond([t3.c3(0x7f5e55b25970) = 5(0x7f5e55b252c0)])
-- 0 表示id=0 的算子
-- output 表示该算子的输出列, 此处select * 所有的字段都会枚举了出来
-- filter 0号算子的过滤谓词 t3.c3=5 t3.c1=6
-- access partitions 扫描的分区中的列
-- is_index_back 是否需要回表,此处使用了idx_c3索引,这个索引中没有select需要的数据,需要回表查询
-- filter_before_indexback 0号算子的filter是否可以直接在索引上计算,还是需要索引回表以后才能计算
-- range_key 索引的rowkey列 此处 是t3.c2 字段,
-- range 索引开始扫描和结束扫描的位置,
-- range_cond 范围条件
Used Hint:
-------------------------------------
/*+
*/
Outline Data:
-------------------------------------
/*+
BEGIN_OUTLINE_DATA
INDEX(@"SEL$1" "test.t3"@"SEL$1" "idx_c3")
END_OUTLINE_DATA
*/
Plan Type:
-------------------------------------
LOCAL
Optimization Info:
-------------------------------------
t3:table_rows:5, physical_range_rows:1, logical_range_rows:1, index_back_rows:0, output_rows:0, est_method:local_storage, optimization_method=cost_based, avaiable_index_name[idx_c3], unstable_index_name[t3], estimation info[table_id:1113805278987097, (table_type:1, version:0-1719597610650934-1719597610650934, logical_rc:0, physical_rc:0), (table_type:0, version:1719597610650934-1719597610650934-9223372036854775807, logical_rc:1, physical_rc:1)]
Parameters
实时执行计划展示
实时执行计划展示可以展示 SQL 的物理执行计划。
使用explain命令,展示出当前优化器所生成的执行计划,执行的时候与explain的结果可能不一样。
为了确定sql在系统中的实际使用的执行计划,可以分析计划缓存中的物理执行计划。
- 每个OBServer的计划缓存都是独立的,可以通过
(g)v$plan_cache_plan_explain这张虚拟表来展示 - 查询
v$plan_cache_plan_explain必须给定tenant_id和plan_id的值,否则返回空集; - 查询
gv$plan_cache_plan_explain必须给定ip,port,tenant_id,plan_id,这四列的值,否则返回空集
obclient [oceanbase]> select * from v$plan_cache_plan_explain where tenant_id=1002 and plan_id='334405'\G
*************************** 1. row ***************************
TENANT_ID: 1013
IP: 192.168.80.10
PORT: 2882
PLAN_ID: 211 -- 执行计划id
PLAN_DEPTH: 0
PLAN_LINE_ID: 0
OPERATOR: PHY_TABLE_SCAN -- 算子名称
NAME: t1 -- 表名称
ROWS: 1 -- 预估的结果行数
COST: 51 -- 预估的代价
PROPERTY: table_rows:22, physical_range_rows:1, logical_range_rows:1, index_back_rows:0, output_rows:1, est_method:local_storage, avaiable_index_name[t1] -- 算子对应的信息
obclient [oceanbase]> select * from gv$plan_cache_plan_explain where ip='192.168.80.10' and port =2882 and tenant_id='1013' and plan_id='211'\G
*************************** 1. row ***************************
TENANT_ID: 1013
IP: 192.168.80.10
PORT: 2882
PLAN_ID: 211
PLAN_DEPTH: 0
PLAN_LINE_ID: 0
OPERATOR: PHY_TABLE_SCAN
NAME: t1
ROWS: 1
COST: 51
PROPERTY: table_rows:22, physical_range_rows:1, logical_range_rows:1, index_back_rows:0, output_rows:1, est_method:local_storage, avaiable_index_name[t1]
1 row in set (0.004 sec)
1) 查询SQL在计划缓存中的plan_id
SELECT * FROM v$plan_cache_plan_stat where tenant_id='1013' and statement like '%from t3%'\G;
2) 使用plan_id 展示应执行计划
select * from v$plan_cache_plan_explain where tenant_id='1013' and plan_id=66329 \G;
*************************** 1. row ***************************
TENANT_ID: 1013
IP: 192.168.80.10
PORT: 2882
PLAN_ID: 66329
PLAN_DEPTH: 0
PLAN_LINE_ID: 0
OPERATOR: PHY_TABLE_SCAN
NAME: t3(idx_c3)
ROWS: 1
COST: 84
PROPERTY: table_rows:5, physical_range_rows:1, logical_range_rows:1, index_back_rows:0, output_rows:0, est_method:local_storage, avaiable_index_name[idx_c3], unstable_index_name[t3], estimation info[table_id:1113805278987097, (table_type:1, version:0-1719597610650934-1719597610650934, logical_rc:0, physical_rc:0), (table_type:0, version:1719597610650934-1719597610650934-9223372036854775807, logical_rc:1, physical_rc:1)]
1 row in set (0.002 sec)
注意:
- 查询
v$plan_cache_plan_explain必须给定tenant_id和plan_id的值,否则返回空集;- 查询
gv$plan_cache_plan_explain必须给定ip,port,tenant_id,plan_id,这四列的值,否则返回空集
查看执行计划的几种方式
-
Explain | describe|desc 方式查看执行计划
{EXPLAIN | DESCRIBE | DESC} [BASIC | OUTLINE | EXTENDED | EXTENDED_NOADDR | PARTITIONS | FORMAT = {TRADITIONAL| JSON}] {SELECT statement | DELETE statement | INSERT statement | REPLACE statement| UPDATE statement} -
通过SQL Trace查看执行过程信息及各阶段的耗时
SET ob_enable_trace_log = 1; SHOW TRACE; -
通过v$sql_audit查看每一次SQL请求的来源、执行状态等统计信息
select * from v$sql_audit;
执行计划缓存
- 一次完整语法解析、语义分析、查询改写、查询优化、代码生成的sql编译流程称为一次
硬解析,硬解析生成执行计划的过程比较耗时(毫秒级); - OB通过计划缓存(plan cache)来避免应解析
1, sql命令进来以后,通过快速参数化解析生成参数化sql
2,查询plan cache中是否有参数化sql的执行计划缓存;
3,有,直接执行sql
如果没有,进行一次硬解析
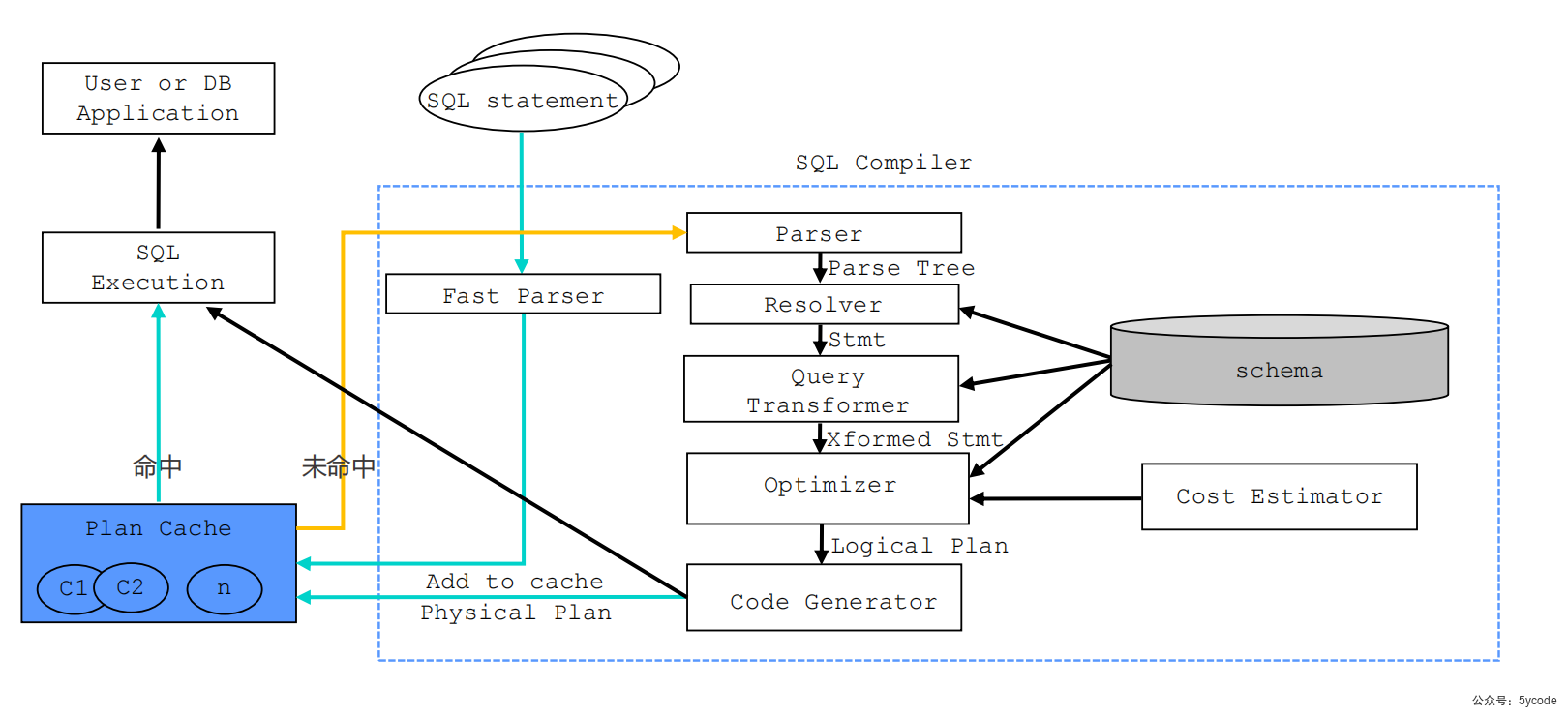
计划缓存例子
obclient [oceanbase]> select * from v$plan_cache_plan_stat limit 1 \G
*************************** 1. row ***************************
tenant_id: 1
svr_ip: 192.168.80.15
svr_port: 2882
plan_id: 412225
sql_id: F96CE9DFB959E383828A9D91575EE97F
type: 2 -- remote 计划
is_bind_sensitive: 0
is_bind_aware: 0
db_id: 1099511627777
statement: SELECT * FROM __all_root_table WHERE tenant_id = ? AND table_id = ? AND partition_id = ? ORDER BY tenant_id, table_id, partition_id, svr_ip, svr_port -- 参数化sql
query_sql: SELECT * FROM __all_root_table WHERE tenant_id = 1011 AND table_id = 1111606255681762 AND partition_id = 0 ORDER BY tenant_id, table_id, partition_id, svr_ip, svr_port
special_params:
param_infos: {1,0,0,0,5},{1,0,0,0,5},{1,0,0,0,5}
sys_vars: 45,4194304,2,4,1,0,0,32,3,1,0,1,1,0,10485760,1,1,0,1,BINARY,BINARY,AL32UTF8,AL32UTF8,BYTE,FALSE,1,100,64,200,0,13,NULL,1,1,1 -- 第一次优化的查询
plan_hash: 12683760849750713488
first_load_time: 2023-06-10 02:07:52.688700
schema_version: 1686017700200792 -- 环境参数
merged_version: 21 -- 合并版本
last_active_time: 2023-06-10 12:21:43.732046
avg_exe_usec: 790
slowest_exe_time: 2023-06-10 10:48:26.679452
slowest_exe_usec: 7416
slow_count: 0
hit_count: 770
plan_size: 81616
executions: 771
disk_reads: 0
direct_writes: 0
buffer_gets: 0
application_wait_time: 0
concurrency_wait_time: 0
user_io_wait_time: 0
rows_processed: 0
elapsed_time: 609656
cpu_time: 146271
large_querys: 0
delayed_large_querys: 0
delayed_px_querys: 0
outline_version: 0
outline_id: -1
outline_data: /*+ BEGIN_OUTLINE_DATA FULL(@"SEL$1" "oceanbase.__all_root_table"@"SEL$1") END_OUTLINE_DATA*/
acs_sel_info:
table_scan: 0
evolution: 0
evo_executions: 0
evo_cpu_time: 0
timeout_count: 0
ps_stmt_id: -1
sessid: 0
temp_tables:
is_use_jit: 0
object_type: SQL_PLAN
hints_info:
hints_all_worked: 1
pl_schema_id: NULL
is_batched_multi_stmt: 0
1 row in set (0.020 sec)
执行计划缓存的淘汰
自动淘汰条件及策略
自动淘汰是指当执行计划缓存占用的内存达到了需要淘汰计划的内存上限时,对计划缓存中的计划执行自动淘汰。
- 触发执行计划淘汰的条件
- 每隔一段时间(由
plan_cache_evict_interval设置,默认1秒)系统会自动检查不同租户在不同服务器上的计划缓存,并判断是否需要执行计划淘汰。如果某个计划缓存占用的内存超过该租户设置的淘汰计划的最高水位线plan_cache_high_watermark,则会触发计划缓存淘汰;
- 每隔一段时间(由
- 执行计划淘汰策略
- 当触发计划缓存淘汰后,优先淘汰最久没有使用的执行计划,直到最低水位线
plan_cache_low_watermark,停止淘汰
- 当触发计划缓存淘汰后,优先淘汰最久没有使用的执行计划,直到最低水位线
自动淘汰相关配置
ps : 系统变量variable 使用
show variables like 'ob_plan_cache%'; 系统参数parameter 使用
show parameters like 'plan_cache%';
plan_cache_evict_intervaparameter :检查执行计划是否需要淘汰的时间间隔;ob_plan_cache_percentagevariable: 计划缓存可使用内存占租户的百分比,默认5%;ob_plan_cache_evict_high_percentagevariable :达到这个百分比的时候,触发缓存淘汰,默认90%;ob_plan_cache_evict_low_percentagevariable :达到这个百分比的时候,停止淘汰;
obclient [oceanbase]> show variables like 'ob_plan_cache%';
+-------------------------------------+-------+
| Variable_name | Value |
+-------------------------------------+-------+
| ob_plan_cache_evict_high_percentage | 90 |
| ob_plan_cache_evict_low_percentage | 50 |
| ob_plan_cache_percentage | 5 |
+-------------------------------------+-------+
3 rows in set (0.003 sec)
自动淘汰示例
-
如果租户内存大小为10G,变量设置如下:
- ob_plan_cache_percentage =10
- ob_plan_cache_evict_high_percentage=90;
- ob_plan_cache_evict_low_percentage=50;
-
则
- 计划缓存内存上限的绝对值= 10G*10%=1G;
- 淘汰计划的高水位线=1G*90% = 0.9G;
- 淘汰计划的低水位线= 1G*50%=0.5G;
需要注意的是:
- 达到0.9以上才会触发淘汰,优先淘汰最久没执行的计划
- 淘汰到0.5的时候,停止淘汰;
- 如果淘汰的速度没有生成的速度快,计划缓存使用内存达到内存上限绝对值1G的时候,将不再往计划缓存中添加新计划,直到淘汰后使用的内存小于1G才会添加新计划到计划缓存中;
手动淘汰
手动淘汰是指强制将计划缓存中计划进行删除,可以指定租户对应的服务器。sql如下:
obclient>ALTER SYSTEM FLUSH PLAN CACHE [tenant_list] [global]
- tenant_list 格式为 tenant = ‘tenant_name,tenant_name…’。如果没有指定这个参数,则清空所有租户缓存;
- 如果没有指定global,则清空本机的计划缓存,添加则清空租户所在的所有的服务器上的计划缓存;
执行计划缓存的刷新
计划缓存中执行可能因为各种原因而失败,这是需要将计划缓存中失效计划进行刷新,即将该执行计划删除后重新优化生成计划再加入缓存;
以下场景会导致计划失败,需要对执行计划进行刷新
- sql中涉及表的schema变更时(比如添加索引,添加或删除列),则该sql在计划缓存中对应的执行计划将被刷新;
- sql中涉及到重新收集表的统计信息时,该sql在计划缓存中所对应的执行计划会被刷新。每次合并后,计划缓存中所有计划将被刷新
- sql进行outline计划绑定变更时,该sql对应的执行计划会被刷新,更新为按绑定的outline生成的执行计划;
执行计缓存的使用控制
计划缓存可以使用系统变量及hit实现使用控制
- 系统变量控制
- 当
ob_enable_plan_cache设置为true时,表示sql请求可以使用计划缓存;设置为false时,表示sql请求不使用计划缓存;默认为true,可以被设置为session级别或者global级别;
- 当
- hint控制
- 使用hint语句 /+use_plan_cache(none)/表示不使用计划缓存
- 使用hint语句/+use+plan_cache(default)/表示使用计划缓存;
执行计划缓存的相关视图及不支持的场景
-
计划缓存相关的视图
-
(g)v$plan_cache_stat记录每个计划缓存的状态,每个计划缓存在该视图中有一条记录 -
(g)v$plan_cache_plan_stat记录计划缓存中所有执行计划的具体信息及每个计划总的执行统计信息; -
(g)v$plan_cahce_plan_explain记录某条sql在计划缓存中的执行计划
-
-
计划缓存暂不支持的场景
- 执行计划所占内存超过20MB时,不会加入计划缓存;
- 如果该计划为分布式执行计划且涉及多个表,不会加入计划缓存;
小结
- 一条sql请求步骤:语法/词法解析生成语法树-> 缓存执行计划得以重用->语义
- 通用hint来指定访问路径或者通过改变连接顺序或连接算法来加速查询
- 通过explain 命令查看优化器针对给定sql生成的逻辑执行计划,通过
v$plan_cache_paln_explain虚表来查看实时的执行计划; - 执行计划缓存可以通过设置淘汰条件及策略达到自动淘汰,也可以使用
alter system flush plan cache来进行手动淘汰;使用use_plan_cache的hit可以指定是否使用执行计划缓存;
第四章、SQL 调优
SQL 调优方法
OB架构与传统数据库的差异
Oceanbase
- 采用Shared-Nothing架构,各个节点之间完全对等,每个节点都有自己的SQL引擎、存储引擎
- 采用LSM-Tree 存储引擎
- 数据分为静态数据(SSTable)和动态数据(MemTable)两部分
- 增量数据写入内存,大量删除会导致读放大
传统分布式数据库架构
- share-disk架构:执行计划并不区分数据所在的物理节点,所有数据访问都可以认为是本地。
- 分布式share-nothing架构,不同的数据被存储在不同的节点上
- 连接两张表时,如果两张表的数据分布在不同的物理节点上,执行计划变为分布式执行计划
- 数据切主,可能由之前本地变为远程执行或分布式执行
SQL 性能问题来源 ☆
- 用户SQL 写法问题- 通过遵循开发规约解决
- 代价模型缺陷 - 绑定执行计划
- 统计信息不准确 - 仅支持本地存储,合并时更新
- 数据库物理设计问题- 决定查询性能
- 系统负载问题- 影响整体吞吐率,影响单sql rt
- 客户端路由问题- 远程执行
SQL调优方法
- 针对单条SQL执行的性能调优
- 单表访问场景
- 索引、排序或聚合、分区、分布式并行
- 多表访问场景
- 连接顺序、连接算法、分布式并行、查询改写
- 单表访问场景
- 针对吞吐量的性能调优
- 优化慢SQL
- 均衡SQL的请求流量资源
- 需要确认
ob_read_consistency、primary_zone、客户端路由策略的设置以及业务热点查询分区的分布是否均衡
- 需要确认
- 均衡子计划的RPC请求流量资源
- observer内部路由策略相关设置、业务热点查询的分区是否均衡
调优基本流程
在SQL调优中,针对慢SQL的分析步骤如下:
- 通过全局SQL审计表
(g)v$sql_audit、sql tarce和计划缓存视图查看sql执行信息,初步查找sql请求的流程中导致耗时或消耗资源的sql - 通过expalin查看优化器给的执行逻辑,确定可能得调优方向
- 常见优化方式如下:
- 对sql做等价改写生成最佳执行计划
- 针对多表访问的sql,还需要关注多表减的连接问题,通过优化访问路径、连接顺序和连接算法等实现优化
分区
OceanBase数据库把普通的表的数据按照一定的规则划分到不同的区块内,同一区块的数据物理上存储在一起,这种划分区块的表叫分区表。每一个区块称作分区。分区技术是非常重要的分布式能力之一
- 解决大表的容量问题和高并发访问时性能问题;
- 普通表只有一个分区
- 每个分区只能存在一个节点内部
分区表目的:在特定的sql操作中减少数据读写的总量以减少响应时间,具备以下特点:
- 可扩展
- 可管理
- 提高性能
分区表特点
- 可多机扩展
- 提高可管理性
- 提高性能
- 自动负载均衡、自动容灾
- 对业务透明,可以取代分库分表方案
- 支持分区间并行
- 单表分区个数最大8192
- 单机partition支持上限:8万(推荐不超过3万)
分区表
- 分为一级分区和二级分区
- 支持的一级分区类型有:Hash、key、list、range、range columns,生成列分区
- 二级分区在一级分区的基础上,又从第二个维度进行了拆分
- MySQL模式
- range分区
- range columns分区
- list分区
- list columns 分区
- hash分区
- key分区
- 组合分区
- Oracle 模式
- range 分区
- list分区
- hash分区
- 组合分区
- MySQL模式
一级分区
hash分区
适用于不能用range分区、list分区方法的场景。通常用于给定分区键的点查询,比如按用户id来分区;
create table t4 (c1 int, c2 int) partition by hash(c1 + 1) partitions 5
-- partition by hash(c1 + 1) 指定分区键为c1, c1+1是表达式
-- partitions 5 表示分5个区
- 通常使用分区键上的hash值来散列记录到不同分区,主要用于点查询;
- 内部hash计算一个hash值,再根据分区数取模,分区键的表达式必须返回int;
- 可以消除热点查询
- MySQL模式hash分区限制和要求
- 分区表达式必须是int类型
- 不能写向量,比如partition by hash(c1,c2)
key分区
-- 指定c1为分区键,不要求是int
create table t1 (c1 varchar(16), c2 int) partition by key(c1) partitions 5
-- key分区不指定键的时候,默认是主键
create table t1 (c1 int primary key, c2 int) partition by key() partitions 5
- 与hash分区类似,但分区键只能是列,但是分布的不均匀
- 系统先对key分区键做一个内部默认的hash再取模(无法自己取模获得在哪个分区)
- key分区键可以是任意类型
- key分区不能写表达式
- key分区支持向量
list分区
-- t通过c1做list分区,不在范围内的最后default兜底
create table t5 (c1 int, c2 int) partition by list(c1)
(partition p0 values in (1,2,3),
partition p1 values in (5, 6),
partition p2 values in (default));
- list分区是根据枚举类型的值来划分分区的,主要用于枚举类型
- 限制和要求
- 分区表达式结果必须是int类型
- 不能写向量,例如 partition by list(c1,c2)
- List columns 和list的区别
- list columns分区不要求是int类型,可以是任意类型
- list columns 不能写表达式
- list columns 支持向量
range分区
-- 按照创建时间分区
CREATE TABLE `info_t`(id INT, gmt_create TIMESTAMP, info VARCHAR(20), PRIMARY KEY (gmt_create))
PARTITION BY RANGE(UNIX_TIMESTAMP(gmt_create))
(PARTITION p0 VALUES LESS THAN (UNIX_TIMESTAMP('2015-01-01 00:00:00')),
PARTITION p1 VALUES LESS THAN (UNIX_TIMESTAMP('2016-01-01 00:00:00')),
PARTITION p2 VALUES LESS THAN (UNIX_TIMESTAMP('2017-01-01 00:00:00')));
- 按用户指定的表达式范围将每一条记录划分到不同分区,通常按时间字段进行分区
- 可以对range分区进行add或drop分区操作
- 存在max value的分区的情况,add分区,只能加在最后,会出现添加失败
- 不存在max value的分区的情况,当插入的数据超出当前分区的最大值,会插入失败(如果定时添加失败,怎么保证数据不丢失)
range columns 分区
- 与range类型相似
- 与range columns的区别
- range columns 分区键可以是任意类型
- range columns 不能写表达式
- range columns 支持向量
生成列分区
生成列: 指这一列是由其他列计算而得,该功能能够满足将某些字段进行一定处理后作为分区键
-- 将t_key进行截取,作为分区字段gc_user_id
CREATE TABLE gc_part_t(t_key varchar(10) PRIMARY KEY, gc_user_id VARCHAR(4) GENERATED
ALWAYS AS (SUBSTRING(t_key, 1, 4)) VIRTUAL, c3 INT)
PARTITION BY KEY(gc_user_id)
PARTITIONS 10;
二级分区
是指按照两个维度来把数据拆分成分区。最常用的地方就是类似用户账单领域,会按照user_id做hash,按照创建时间做range 分区。
CREATE TABLE history_t (user_id INT, gmt_create DATETIME, info VARCHAR(20),
PRIMARY KEY(user_id, gmt_create)) -- 联合主键
PARTITION BY RANGE COLUMNS (gmt_create) -- 一级分区
SUBPARTITION BY HASH(user_id) SUBPARTITIONS 3 -- 二级分区
(PARTITION p0 VALUES LESS THAN ('2014-11-11'),
PARTITION p1 VALUES LESS THAN ('2015-11-11'),
PARTITION p2 VALUES LESS THAN ('2016-11-11'),
PARTITION p3 VALUES LESS THAN ('2017-11-11')
);

二级分区支持的分区方式
- 一级hash/key 、二级 range/range_columns分区 或 list/list_columns 分区
- 一级range/range_columns 、二级 hash/key分区 或 list/list_columns 分区
- 一级list/list_columns 、二级 range/range_columns 分区 或hash/key分区
Note :对于range分区的分区操作add/drop,必须是range分区作为一级分区的方式,强烈建议使用range+hash的分区方式
分区管理
-
增加分区
-
伴随数据量增长,range分区需要能够扩展-> add parition
-
语法:alter table … add partition
ALTER TABLE members add partition(partition p3 values less than(2000))
-
-
删除分区
-
对于按时间范围分区的表,有时需要做过期数据清理-> drop partition
-
语法:alter table … drop partition
alter table members drop partition(p3)
-
-
使用限制
- 只有range分区,可以删除任意一个一级的range分区
- 只能以append方式往后添加分区,新添加的分区的range value总是最大的
-
分区查询
SELECT * FROM t1 PARTITION (p0,p1smp1);查询一级分区p0和二级分区p1smp1的数据
分区选择和分区裁剪
-- 表结构
CREATE TABLE `t4` (
`c1` int(11) DEFAULT NULL,
`c2` int(11) DEFAULT NULL
) partition by hash(c1 + 1) partitions 5;
分区选择
-- 直接指定分区查询
obclient [test]> explain select * from t4 partition(p4);
| Query Plan | ===================================
|ID|OPERATOR |NAME|EST. ROWS|COST|
-----------------------------------
|0 |TABLE SCAN|t4 |1 |36 |
===================================
Outputs & filters:
-------------------------------------
0 - output([t4.c1], [t4.c2]), filter(nil),
access([t4.c1], [t4.c2]), partitions(p4)
-- 分区数据
obclient [test]> select * from t4 partition(p4);
+------+------+
| c1 | c2 |
+------+------+
| 3 | 4 |
+------+------+
1 row in set (0.002 sec)
分区裁剪
-- 分区裁剪
obclient [test]> explain select * from t4 where c1 = 5 or c1 = 3;
| Query Plan |ID|OPERATOR |NAME |EST. ROWS|COST|
----------------------------------------------------
|0 |PX COORDINATOR | |2 |37 |
|1 | EXCHANGE OUT DISTR |:EX10000|2 |37 |
|2 | PX PARTITION ITERATOR| |2 |37 |
|3 | TABLE SCAN |t4 |2 |37 |
====================================================
Outputs & filters:
-------------------------------------
0 - output([t4.c1], [t4.c2]), filter(nil)
1 - output([t4.c1], [t4.c2]), filter(nil), dop=1
2 - output([t4.c1], [t4.c2]), filter(nil)
3 - output([t4.c1], [t4.c2]), filter(nil),
access([t4.c1], [t4.c2]), partitions(p1, p4) -- 只查了p1和p4两个分区
1 row in set (0.003 sec)
一级分区裁剪的基本原理
分区裁剪就是根据where子句里面的条件并且计算得到分区列的值,然后通过结果判断需要访问哪些分区。
如果分区函数为表达式,且该表达式作为一个整体出现在等值条件里,也可以做分区裁剪
hash/list 分区
obclient> CREATE TABLE t5 (c1 INT,c2 INT) PARTITION BY HASH(c1 + c2) -- 分区键为c1+c2这个表达式
partitions 5;
obclient [test]> EXPLAIN SELECT * FROM t5 WHERE c1 + c2 = 1 \G
*************************** 1. row ***************************
Query Plan: ====================================
|ID|OPERATOR |NAME|EST. ROWS|COST |
------------------------------------
|0 |TABLE SCAN|t5 |500 |72438|
====================================
Outputs & filters:
-------------------------------------
-- 因为c1+c2=1 作为一个整体条件出现,可以进行分区裁剪
0 - output([t5.c1], [t5.c2]), filter([t5.c1 + t5.c2 = 1]),
access([t5.c1], [t5.c2]), partitions(p1)
1 row in set (0.011 sec)
range分区
通过where子句的分区键的范围跟表定义的分区范围的交集来确定需要访问的分区,对于range分区,因为考虑到函数单调性,如果分区表达式是一个函数并且查询条件是一个范围,则不支持分区裁剪。
CREATE TABLE t1(c1 INT,c2 INT) PARTITION BY RANGE(c1 + 1)
(PARTITION p0 VALUES less than (100),PARTITION p1 VALUES less than (200));
-- 等值条件可以明确在哪个分区,可以可以进行分区裁剪
obclient> EXPLAIN SELECT * FROM t1 WHERE c1 = 150 \G
*************************** 1. row
**********************
Query Plan: ===================================
|ID|OPERATOR |NAME|EST. ROWS|COST|
-----------------------------------
|0 |TABLE SCAN|t1 |1 |1303|
===================================
Outputs & filters:
-------------------------------------
0 - output([t1.c1], [t1.c2]), filter([t1.c1 = 150]),
access([t1.c1], [t1.c2]), partitions(p1)
-- 非等值条件无法进行分区裁剪(如果在明确的范围,做分区裁剪更合适一些)
obclient> EXPLAIN SELECT * FROM t1 WHERE c1 < 150 and
c1 > 110 \G
Query Plan:
============================================
|ID|OPERATOR |NAME|EST. ROWS|COST|
--------------------------------------------
|0 |EXCHANGE IN DISTR | |19 |1410|
|1 | EXCHANGE OUT DISTR| |19 |1303|
|2 | TABLE SCAN |t1 |19 |1303|
============================================
Outputs & filters:
-------------------------------------
0 - output([t1.c1], [t1.c2]), filter(nil)
1 - output([t1.c1], [t1.c2]), filter(nil)
2 - output([t1.c1], [t1.c2]), filter([t1.c1 < 150],
[t1.c1 > 110]),
access([t1.c1], [t1.c2]), partitions(p[0-1])
二级分区裁剪的基本原理
对于二级分区,先按照以及分区键确定一级需要访问的分区,然后通过二级分区键确定二级分区需要访问的分区。然后做一个乘积确定二级分区访问的所有物理分区。
CREATE TABLE t1(c1 INT ,c2 INT) PARTITION BY hash(c1) SUBPARTITION BY RANGE(c2) SUBPARTITION
template (SUBPARTITION sp0 VALUES less than(100),
SUBPARTITION sp1 VALUES less than(200)) partitions 5
obclient> EXPLAIN SELECT * FROM t1 WHERE (c1 = 1 or c1 = 2) -- 一级分区访问2个区的范围
and (c2 > 101 and c2 < 150) \G -- 二级分区访问一个区的范围
Query Plan: ============================================
|ID|OPERATOR |NAME |EST. ROWS|COST|
--------------------------------------------
|0 |EXCHANGE IN DISTR | |1 |1403|
|1 | EXCHANGE OUT DISTR| |1 |1303|
|2 | TABLE SCAN |t1 |1 |1303|
============================================
Outputs & filters:
-------------------------------------
0 - output([t1.c1], [t1.c2]), filter(nil)
1 - output([t1.c1], [t1.c2]), filter(nil)
2 - output([t1.c1], [t1.c2]), filter([t1.c1 = 1 OR t1.c1 = 2], [t1.c2 > 101], [t1.c2 < 150]),
-- 通过一级分区和二级分区组合确定访问所有的物理分区
access([t1.c1], [t1.c2]), partitions(p1sp1, p2sp1)
分区表使用建议
- 业务形态(热点数据打散、历史数据维护便利性、业务sql的条件形态(分区裁剪))
- 了解ob各种分区类型的设置要求
- 分区键必须是主键的子集
- range 分区,最后一个不能是maxvalue
- 考虑分区裁剪、partition wise jion 优化
- leader binding \tablegroup
- 为了避免写入放大问题,选择表的自定义主键时,不要使用随机生成的值,要尽量有序,比如时序递增的
- 分区个数,单机分区上限、单机租户允许创建的最大分区数量上限、单表分区数上限
索引
路径选择(Access path selection)
- 访问路径是指数据库中访问表的方法,即使用哪个索引来访问表
- sql的执行时间一般与扫描的数据量成正比
- 合适的索引查询,可以减少数据的访问量,sql优化,需要分析没有选中索引扫描的原因
何为路径
- 主键
- 二级索引
如何选择
- 规则模型
- 前置规则(正向)
- 剪枝规则(反向)
- 代价模型
考虑因素
- 扫描范围
- 是否回表
- 路径宽度
- 过滤条件
- iteresting order
索引回表
- 一般索引维护的是主键key,索引键和主键key的关系映射
- 当索引里的数据无法覆盖住查询数据的时候,会根据主键key进行再次查询,这个再次查询就是回表。
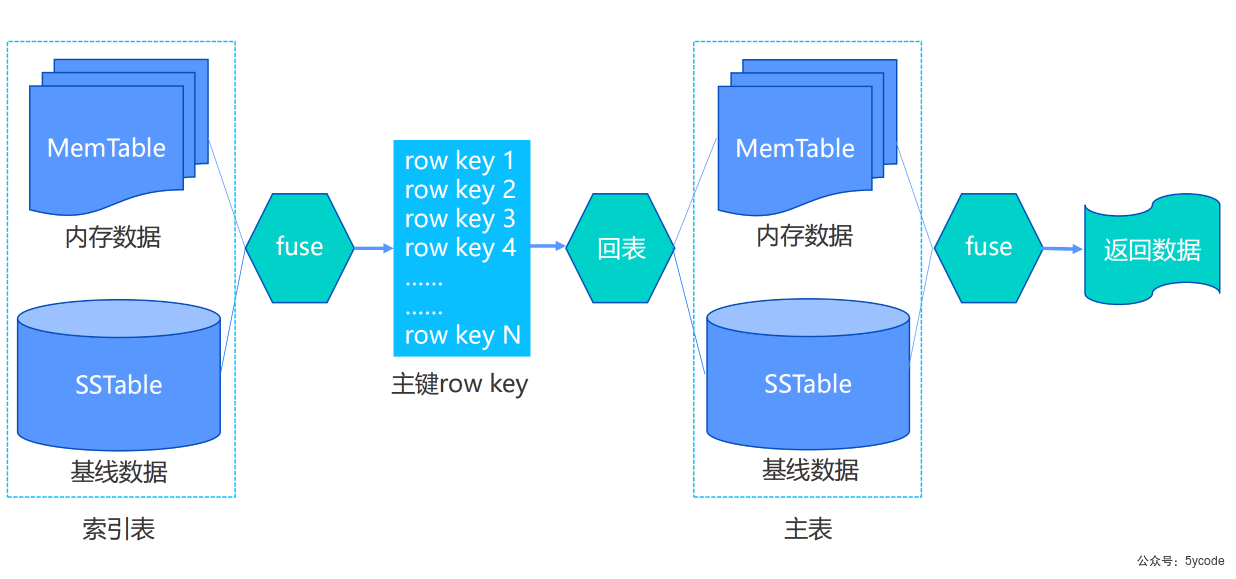
路径选择
- 3.x 只支持B+ tree 索引
- 两种访问
- get: 索引键全部等值覆盖
- scan:返回有序数据
- 字符串条件:‘T%’ (最左匹配可以利用索引)
- 扫描顺序由优化器智能决定
覆盖索引
如果一个访问路径中包含了该查询所需要的所有列,那么该路径就不需要回表,反之,该路径就需要回表。
#创建表索引为c2
create table t2(c1 int primary key, c2 int, c3 int, c4 int, index t2_c2(c2));
# 只查索引c2,不会回表
OceanBase (root@oceanbase)> explain select c2 from t2;
========================================
|ID|OPERATOR |NAME |EST. ROWS|COST|
----------------------------------------
|0 |TABLE SCAN|t2(t2_c2)|1000 |1145|
========================================
Outputs & filters:
-------------------------------------
0 - output([t2.c2]), filter(nil),
access([t2.c2]), partitions(p0)
# 同时查索引c2和主键c1,不会回表(因为c2能把主键c1带出)
OceanBase (root@oceanbase)> explain select c1, c2 from t2;
========================================
|ID|OPERATOR |NAME |EST. ROWS|COST|
----------------------------------------
|0 |TABLE SCAN|t2(t2_c2)|1000 |1180|
========================================
Outputs & filters:
-------------------------------------
0 - output([t2.c1], [t2.c2]), filter(nil),
access([t2.c1], [t2.c2]), partitions(p0)
消除排序 - interesting order
优化器通过interesting order 利用底层的顺序,就不需要对底层扫描的行做排序,还可以消除 order by,进行merge group by ,提高pipeline等
OceanBase (root@oceanbase)> create table t1(c1 int primary key, c2 int, c3 int);
OceanBase (root@oceanbase)> explain select * from t1 order by c1; -- 指定了order by进行排序
| ===================================
|ID|OPERATOR |NAME|EST. ROWS|COST|
-----------------------------------
|0 |TABLE SCAN|t1 |1000 |2327|
-- 实际未进行排序,因为主键本身就是顺序的
===================================
Outputs & filters:
-------------------------------------
0 - output([t1.c1], [t1.c2], [t1.c3]), filter(nil),
access([t1.c1], [t1.c2], [t1.c3]), partitions(p0)
逆序索引扫描
优化器通过排序消除,利用底层的顺序,就不需要对底层扫描的行做排序
OceanBase (root@oceanbase)> create table t1(c1 int primary key, c2 int, c3 int);
OceanBase (root@oceanbase)> explain select * from t1 order by c1 desc; -- 指定了排序
| ==========================================
|ID|OPERATOR |NAME |EST. ROWS|COST|
------------------------------------------
|0 |TABLE SCAN|t1(Reverse)|1000 |2327|
-- Reverse 指定了倒序排序采用了逆序索引扫描
==========================================
Outputs & filters:
-------------------------------------
0 - output([t1.c1], [t1.c2], [t1.c3]), filter(nil),
access([t1.c1], [t1.c2], [t1.c3]), partitions(p0)
OB的索引选择
- OB的索引选择有大量的规则挡在代价模型之前(先规则-> 后代价)
- 正向规则:一旦命中规则直接选择该索引
- 命中唯一索引
- 逆向规则(skyline 剪枝规则)
- 通过比较两个索引,剪掉一些比较“差”的索引
- 剩下的索引通过代价模型选出
- 正向规则:一旦命中规则直接选择该索引
create table t6(a int , b int, c int, unique key idx1(a, b), key idx2(b));
# 命中唯一索引
obclient [test]> explain extended select * from t6 where a = 1 and b = 1\G;
Plan Type:
-------------------------------------
LOCAL
Optimization Info:
-------------------------------------
t6:table_rows:100000, physical_range_rows:1, logical_range_rows:1, index_back_rows:1, output_rows:1, est_method:basic_stat, `optimization_method=rule_based`, `heuristic_rule=unique_index_with_indexback`
-- heuristic_rule=unique_index_with_indexback 命中唯一索引
Parameters
-------------------------------------
1 row in set (0.003 sec)
Optimization Info:
-------------------------------------
t1:optimization_method=rule_based,
heuristic_rule=unique_index_with_indexback
# 保留较好的索引idx1,裁掉交叉的idx2
obclient [test]> explain extended select * from t6 where a = 1 and b = 1\G;
Optimization Info:
-------------------------------------
t6:table_rows:100000, physical_range_rows:989, logical_range_rows:989, index_back_rows:989, output_rows:989, est_method:basic_stat, optimization_method=cost_based, avaiable_index_name[idx1,idx2,t6]
Parameters
连接顺序
- 不同的链接顺序对执行效率影响较大
- 3.x只考虑左深树(某些场景除外)
- 搜索空间
- 对内存占用更友好
- 连接顺序的选择是一个动态规划的过程
- 可通过hint指定连接顺序
- 存在显式连接条件的连接优先于笛卡尔积链接
为什么选择左深树?
- 搜索空间小
- 更利于流水线
- 内存空间小
缺点是没法里用并行执行,可能措施更佳的执行计划
| 左/右深树 | 多枝树 | |
|---|---|---|
| 优势 | 搜索空间小更利于流水线内存空间(foot-print)小 | 充分系统并行能力可能生成更好计划 |
| 劣势 | 无法利用并行执行可能错失更佳的执行计划 | 搜索空间巨大执行消耗资源多 |
创建高效索引原则
- 索引表语普通数据表一样都是实体表,在数据表进行更新的时候会先更新索引表然后再更新数据表,通过事务保证一致性
- 索引要全部包含所查询的列:包含的列全了,就会减少回表
- 等值条件永远放在最前面,(联合索引的时候)
- 过滤和排序数据量大的放前面
- 选择具有高选择性、频繁在where从句中出现,频繁在join关联字段中的字段(索引建的得有意义)
- 不对函数或者表达式中的字段建索引,要么就建函数索引
- 创建一个索引,需要考虑带来的其他insert、update、delete的性能下降,以及索引所占的空间
- 经常被修改的字段建立索引,需要评估性能影响
创建索引
- OB支持在非分区表和分区表上创建索引,
- 可以是局部索引和全局索引,
- 也可以是唯一索引或普通索引。
- 如果是分区表的唯一索引,唯一索引必须包含在表分区的拆分键中
- 创建索引,能够减少对磁盘的读写,特别是单列或多列
- 建表的时候创建,立即生效
- 建表后再创建,是同步生效,表中数据量大时需要等待一段时间
创建索引语法
# MySQL和Oracle模式都支持
CREATE [UNIQUE] INDEX index_name ON table_name ( column_list ) [LOCAL | GLOBAL]
[ PARTITION BY column_list PARTITIONS N ]
# MYSQL模式简介写法
ALTER TABLE table_name ADD INDEX|KEY index_name ( column_list ) ;
等值查询
- 等值查询基于最左匹配原则,只要左侧能匹配上,就能利用,匹配的越多,性能越高
- 索引能效
1(利用了ABC)>2(利用了AB)>3(只用了A)
| 索引中的字段 | 命中索引的SQL | 未命中索引的SQL |
|---|---|---|
| (A,B,C) | 1,where A = ? and B = ? and C = ? 2,where A = ? and B = ? 3,where A = ? and C = ? | where B = ? and C = ? where C = ? |
范围查询
- 范围查询:遇到第一个范围查询的字段后,后续的其他字段不参与索引过滤(不走索引),但是会算子(索引)下推,减少合并的结果,分区表比较有效
- 索引效能:
1(利用了A,然后下推了BC)>2(利用了A,然后下推了B)>3(只利用了A)
| 索引中的字段 | 命中索引的****SQL | 未命中索引的****SQL |
|---|---|---|
| (A,B,C) | 1,where A > ? and B > ? and C < ? 2,where A > ? and B > ? 3,where A > ? and C < ? | where B > ? and C < ? where C in (?,?) |
等值查询与范围查询
| 索引中的字段 | 命中索引的****SQL | 未命中索引的****SQL |
|---|---|---|
| (A,B,C) | 1,where A = ? and B = ? and C > ? 2,where A = ? and B > ? and C = ? 3,where A = ? and B > ? and C > ? | where B > ? and C < ? where C in (?,?) where C = ? |
- 索引效能:
1(利用了ABC)>2(利用AB)=3()利用率AB
局部索引和全局索引
主表的数据按分区键(partitioning key)的值被分成了多个分区,每个分区都是独立的数据结构。这个时候索引引来的单一数据结构不存在。
主键和二级索引
-
主表: 使用create table语句创建的表,也是索引对象依赖的表;
-
主键: 每张表都有主键,内部已主键为序组织数据,如果不指定主键,系统会自动生成隐藏主键,隐藏主键不可被查。
-
索引: 指通过create index 创建的索引对象
OB传统“非分区表”中主表和索引的关系
- 主表的所有数据都保存在一个完整的数据结构中,
- 主表的每一个索引页对应一个完整的数据结构(比如:B+ 树)
- 主表的数据结构和索引的数据结构是一对一的关系
局部索引与全局索引
数据分区以后:
- 数据按照分区键分成了多个区
- 每个分区都是独立的数据结构
- 数据之间没有交集
局部索引:mysql中默认
- 又名分区索引,创建索引的分区关键字是local,分区键等同于表的分区键,分区数等于表的分区数。
- 创建局部唯一索引索引键必须包含主表的分区键,global索引没这个限制;
- 局部索引的分区机制和表的分区机制一样,都是一一对应的关系,也就是每个分区对应一个local的局部索引,不会跨节点访问
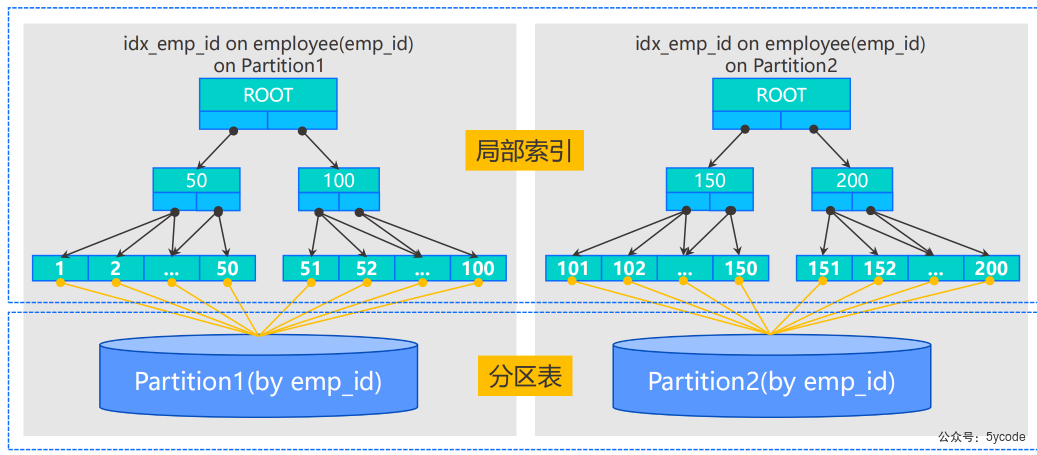
全局索引 oracle 中默认
- 全局索引的创建规则时在索引属性上指定global关键字;
- 只有开启GTS的时候能创建全局索引,(Global timestamp service GTS)维护全局的一致性快照;
- 通过
SHOW GLOBAL VARIABLES LIKE 'ob_timestamp_service';查看,默认是LTS - 通过
SET GLOBAL ob_timestamp_service = GTS;设置为GTS
- 通过
- 全局索引最大的特点是全局索引的分区规则跟分区是相互独立的。全局索引允许指定自己的分区规则和分区个数,不一定需要跟表分区规则保持一致。
全局分区索引,是将所有主表的分区数据合成一个整体来看,然后建立全局索引。
- 索引中的一个键可以映射到多个主表分区中的数据(索引有重复值的时候)。
- 可以自定义独立的数据分布模式可以选择非分区模式(可以分区相同也可以不同),也可以选择非分区模式。
全局索引有两个
- 一个是全局非分区索引(global non-partitioned index)
- 另一个全局分区索引(global partitioned index)
MySQL模式默认创建索引会创建本地索引。
全局索引缺点
- 维护代价大
- 无法保证和主表分区物理位置相同,会跨服务器操作(可以通过表组绑定在一起)
全局非分区索引
- 将所有主表分区的数据合并成一个整体来建立全局索引;
- 索引数据不做分区,保持单一的数据结构
- 某一个索引键会映射到不同的分区表(1对多)
全局非分区索引,可能落在某个分区的observer上,每个索引值,对应的可能是多个分区的数据,索引是只读的,每个节点都有一份数据
比如索引值是5,5在每个observer上都有数据,这个时候,5就会指向多个observer
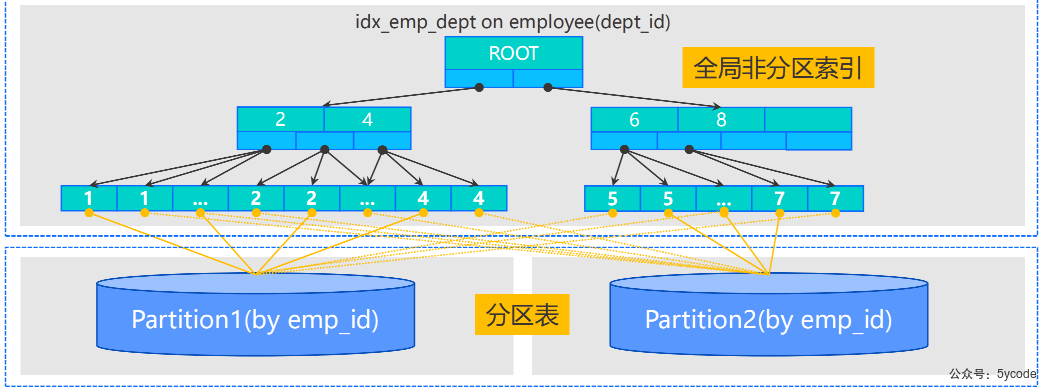
全局分区索引
- 索引数据按指定的方式分区(和主表的分区没有任何关系)
- 索引分区和主表分区是多对多的关系
索引按照自己的方式分区,每个分区的数据又跨了多个分区。这个时候的路由链路变长,稳定性下降
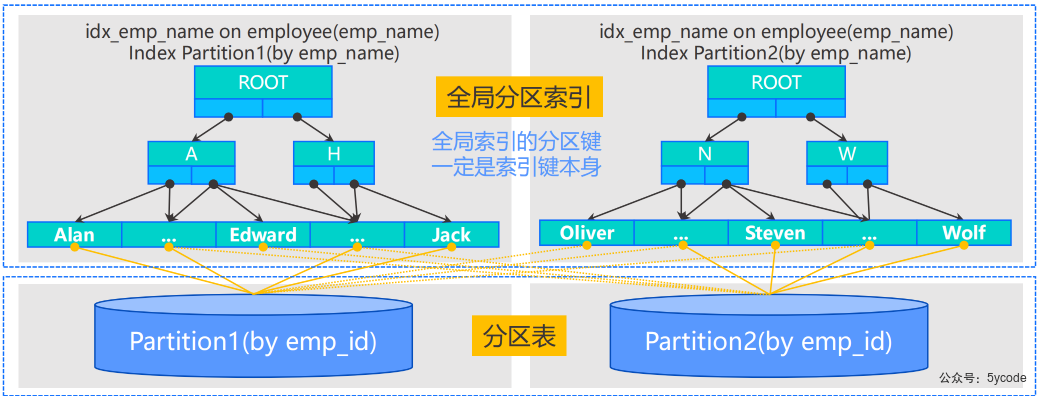
在表的分区键无关的字段上建唯一索引
employee 按照emp_id做了分区,想利用局部索引建立emp_name的唯一约束是无法实现的。
数据在每个分区上都有,而局部索引只和本节点相关。
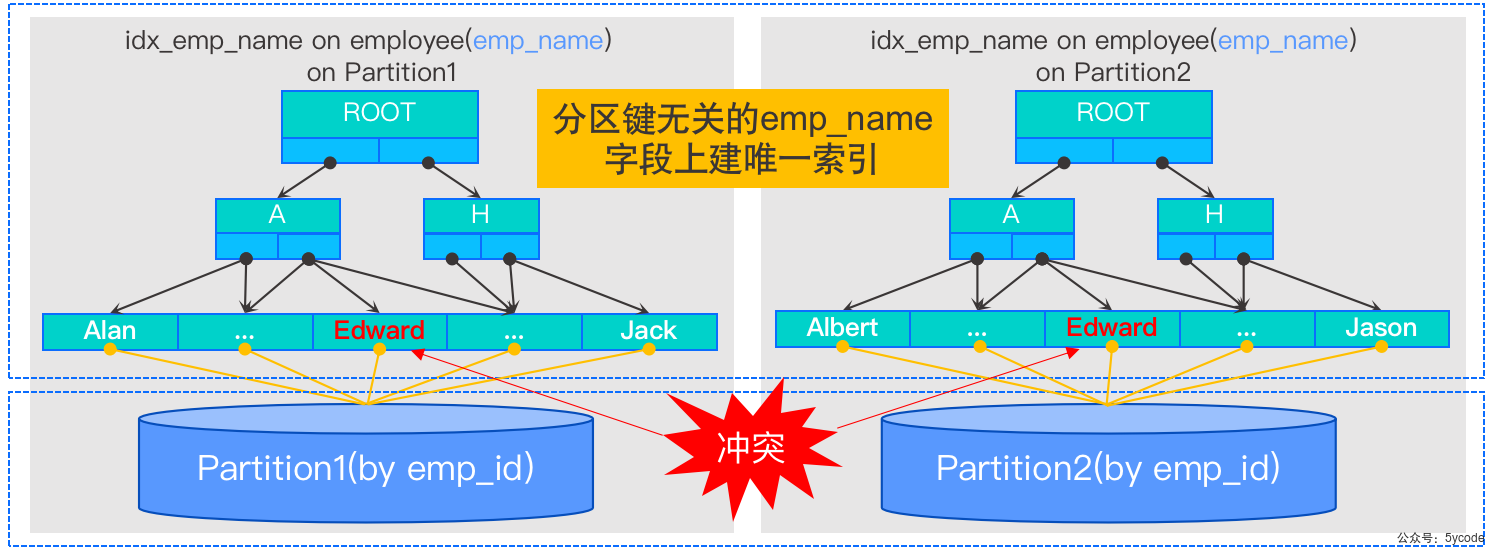
全局非分区索引和全局分区索引的比较
全局索引的分区键一定是索引键的前缀
- 全局非分区索引:
- 只有一个完整的索引树,自然保证唯一性
- 全局分区索引:
- 数据只可能落到一个固定的索引分区中;
- 每个索引分区保证唯一性约束,以达到全局唯一性;
- 通过分区键值定位要扫描的一个或者几个分区(分区裁剪)

局部索引与全局索引的执行计划比较
局部索引
-- 根据c2分区
create table t_p_hash (c1 varchar(20),c2 int, c3 varchar(20)) partition by hash(c2) partitions 3;
create index idx_t_p_hash_c1 on t_p_hash (c1) local; -- 给c1创建索引 使用local
create index idx_t_p_hash_c3 on t_p_hash (c3) local; -- 给c2创建索引
-- 查询未指定分区键,局部索引无法进行分区裁剪
obclient [test]> explain extended select c1,c2 from t_p_hash where c3='100'\G;
*************************** 1. row ***************************
Query Plan: ======================================================================
|ID|OPERATOR |NAME |EST. ROWS|COST |
----------------------------------------------------------------------
|0 |PX COORDINATOR | |2970 |19207|
|1 | EXCHANGE OUT DISTR |:EX10000 |2970 |18364|
|2 | PX PARTITION ITERATOR| |2970 |18364|
|3 | TABLE SCAN |t_p_hash(idx_t_p_hash_c3)|2970 |18364|
======================================================================
-- 索引的回表逻辑封装在table scan算子中
Outputs & filters:
-------------------------------------
0 - output([t_p_hash.c1(0x7f5f7a94cea0)], [t_p_hash.c2(0x7f5f7a9256e0)]), filter(nil)
1 - output([t_p_hash.c2(0x7f5f7a9256e0)], [t_p_hash.c1(0x7f5f7a94cea0)]), filter(nil), dop=1
2 - output([t_p_hash.c2(0x7f5f7a9256e0)], [t_p_hash.c1(0x7f5f7a94cea0)]), filter(nil),
force partition granule, asc.
3 - output([t_p_hash.c2(0x7f5f7a9256e0)], [t_p_hash.c1(0x7f5f7a94cea0)]), filter(nil),
access([t_p_hash.c2(0x7f5f7a9256e0)], [t_p_hash.c1(0x7f5f7a94cea0)]), partitions(p[0-2]), -- 查询未指定分区键,局部索引无法进行分区裁剪
is_index_back=true, -- 索引的回表逻辑封装在table scan算子中
range_key([t_p_hash.c3(0x7f5f7a94c920)], [t_p_hash.c2(0x7f5f7a9256e0)], [t_p_hash.__pk_increment(0x7f5f7a9ce0e0)]), range(100,MIN,MIN ; 100,MAX,MAX),
range_cond([t_p_hash.c3(0x7f5f7a94c920) = '100'(0x7f5f7a94c270)])
Used Hint:
-------------------------------------
/*+
*/
Outline Data:
-------------------------------------
/*+
BEGIN_OUTLINE_DATA
INDEX(@"SEL$1" "test.t_p_hash"@"SEL$1" "idx_t_p_hash_c3")
END_OUTLINE_DATA
*/
Plan Type:
-------------------------------------
DISTRIBUTED
Optimization Info:
-------------------------------------
t_p_hash:table_rows:300000, physical_range_rows:2969, logical_range_rows:2969, index_back_rows:2969, output_rows:2969, est_method:basic_stat, optimization_method=cost_based, avaiable_index_name[idx_t_p_hash_c3,t_p_hash], pruned_index_name[idx_t_p_hash_c1]
Parameters
-------------------------------------
1 row in set (0.025 sec)
全局索引
-- 创建表
create table t_p_key (c1 varchar(20),c2 int,c3 varchar(20)) partition by key (c2) partitions 3;
-- 给c3创建global索引,必须开启GTS
create unique index idx_t_p_key_c3_g on t_p_key (c3) global partition by key (c3) partitions 3;
-- 因为c3是全局索引,所以可以使用分区裁剪
explain extended select c1,c2 from t_p_key where c3='66'; -- 可以通过索引裁剪分区
|ID|OPERATOR |NAME |EST. ROWS|COST|
----------------------------------------------------------
|0 |TABLE LOOKUP|t_p_key |1 |91 |
-- 3,利用table lookup 算子对主表进行精确的分区扫描,避免扫描主表的所有分区
|1 | TABLE SCAN |t_p_key(idx_t_p_key_c3_g)|1 |36 |
-- 2,对全局索引进行 table scan 扫描,
==========================================================
Outputs & filters:
-------------------------------------
0 - output([t_p_key.c1(0x7f8b99cb6050)], [t_p_key.c2(0x7f8b99cb3a80)]), filter(nil),
partitions(p[0-2])
1 - output([t_p_key.c2(0x7f8b99cb3a80)], [t_p_key.__pk_increment(0x7f8b99cd9660)]), filter(nil),
access([t_p_key.c2(0x7f8b99cb3a80)], [t_p_key.__pk_increment(0x7f8b99cd9660)]),
partitions(p2), -- 1,通过where条件裁剪出来的分区2
is_index_back=false,-- 未进行回表
range_key([t_p_key.c3(0x7f8b99cb5010)], [t_p_key.shadow_pk_0(0x7f8b99cda660)],
[t_p_key.shadow_pk_1(0x7f8b99cda8f0)]), range(66,MIN,MIN ; 66,MAX,MAX),
range_cond([t_p_key.c3(0x7f8b99cb5010) = '66'(0x7f8b99cb5760)])
局部索引与全局索引的取舍
- 如果查询条件里“包含完整的分区键”,使用本地索引是最高效的;
- 如果需要不包含完整的分区键,的唯一约束
- 用全局索引
- 如果索引列上有带上表的分区键,可以用本地索引
- 全局索引能为高频且精准命中的查询提速并减少IO,范围查询不一定哪种缩影效果更好;
- 不能忽视全局索引在DML中的额外开销:数据更新时带来的跨机分布式事务
- 全局索引如果数据量较大、或容易出现索引热点,可考虑创建全局分区索引
Hint
Hint是一种SQL语句注释,用于将指令传递给Oceanbase数据库优化器,通过Hint可以使优化器生成指定的执行计划。
-
一条语句只能包含一个Hint注释,且必须跟随在
SELECT、UPDATE、INSERT、REPLACE或DELETE之后 -
同一个Hint注释中,可以有多个命令
-
基于代价的优化器,与Oracle的Hint类似
-
MySQL客户端需要执行带Hint的语句,需要使用-c选项登录,否则MySQL客户端会将Hint作为注释给去掉,导致系统无法接收到用户hit
-
server端不认识sql中的hint,直接忽略而不报错
-
hint只影响数据库优化器生成计划的逻辑,而不影响sql语句本身的语义
OB支持hint有以下几个特点
- 不带参数的,如
/*+ func*/,必须有+号,且紧跟注释,不能有空格 - 带参数的,如
/*+ func(param)*/ - 多个hit可以写在同一个注释里,用逗号分隔
/*+ func1,func2(parma)*/ - select语句的hit必须在select字段之后,其他词之前,如:
select /*+func*/ - Update/delete的hit必须紧接着关键字update和delete之后
hint举例
- 强一致/弱一致:
/*+read_consistency(strong)*/,/*+read_consistency(weak)*/ - server端执行语句超时时间:
/*+query_timeout(100000000)*/单位微秒,可以改变当前sql超时的时间 - 采用sort-merge链接:
/*use_merge(表名 表名)*/ - 强制使用索引:
/*+INDEX(表名 索引名) */ - 采用并行:
/*+PARALLEL(N)*/指定语句级别的并发度- 当该hint指定时,会忽略系统变
ob_stmt_parallel_degree的设置
- 当该hint指定时,会忽略系统变
/*+ leading(table_name_list)*/- 指定表的连接顺序
- 如果发现hint指定的table_name不存在,leading hint失效;
- 如果发现hint中存在重复table,leading hint失效
Hit的 行为理念及当前支持的hint
- 为了告诉优化器考虑hint中的方式,数据库的行为更像贪心算法,不会考虑全部可能得路径最优,hint的指定就是为了告诉数据库加入到它的考虑范围
- ob优化器更像是动态规划,已经考虑了所有可能,因此hint告诉数据库加入考虑范围就没有意义。基于此OB的hint更多的是告诉优化器按照指定行为做
| 语句级别Hit | 计划相关HIt |
|---|---|
| MAX_CONCURRENT型 | FULL |
| FROZEN_VERSION | INDEX |
| QUERY_TIMEOUT | LEADING |
| READ_CONSISTENCY | USE_MERGE |
| LOG_LEVEL | USE_HASH |
| QB_NAME | USE_NL |
| ACTIVATE_BURIED_POINT | ORDERED |
查询限流的例子
- hint中使用max_concurrent
- ?表示需要参数化的参数
OceanBase (root@oceanbase)> create table t1(a int primary key, b int, c int);
Query OK, 0 rows affected (0.15 sec)
-- 通过outline创建一个ol_1做执行计划绑定,指定相应的执行计划使用指定的hint
OceanBase (root@oceanbase)> create outline ol_1 on select/*+max_concurrent(0)*/ * from t1 where b =1 and c = 1;
Query OK, 0 rows affected (0.06 sec)
OceanBase (root@oceanbase)> select * from t1 where b =1 and c = 1;
ERROR 5268 (HY000): SQL reach max concurrent num 0
OceanBase (root@oceanbase)> select * from t1 where b =1 and c = 2;
Empty set (0.01 sec)
-- 通过outline创建一个ol_2做执行计划绑定
OceanBase (root@oceanbase)> create outline ol_2 on select/*+max_concurrent(0)*/ * from t1 where b =1 and c = ?;
Query OK, 0 rows affected (0.05 sec)
OceanBase (root@oceanbase)> select * from t1 where b =1 and c = 1;
ERROR 5268 (HY000): SQL reach max concurrent num 0
OceanBase (root@oceanbase)> select * from t1 where b =1 and c = 2;
ERROR 5268 (HY000): SQL reach max concurrent num 0
执行计划绑定
outline创建和删除
如果已上线的业务,如果出现优化器选择的计划不够优化时,则需要在线进行计划绑定(无需对业务进行sql更改),通过DDL操作将一组hint加入到sql中,从而使优化器根据指定的一组hint,对该sql生成更优计划,该组hint称为outline
-
创建outline
-
使用sql_text创建outline
create [or replace] outline <outline_name> on <stmt> [to<target_stmt>] -
使用sql_id创建outline
create outline outline_name on sql_id using hint hint_text
-
-
删除outline
drop outline outline_name- outline 需要在outline_name中指定database名,或者在use database命令执行后执行删除操作。
确定outline创建生效
-
确定outline创建成功
SELECT * FROM oceanbase.gv$outline WHERE OUTLINE_NAME = 'outline_name'; -
确定新的sql是否通过绑定的outline生成了新执行计划
SELECT SQL_ID, PLAN_ID, STATEMENT, OUTLINE_ID, OUTLINE_DATA FROM oceanbase.gv$plan_cache_plan_stat WHERE STATEMENT LIKE '%sql_text%'; -
确定生成的执行计划是否符合预期
SELECT OPERATOR, NAME FROM oceanbase.gv$plan_cache_plan_explain WHERE TENANT_ID = tenant_id AND IP = 'IP_address' AND PORT = port_num AND PLAN_ID = plan_id;
执行计划管理
SQL PLan Management (SPM)是一种稳定执行计划、控制计划演进的机制,确保新生成的计划在经过验证后才能使用,保证计划性能朝好的方向不断更新。SPM基于SQL Plan Baseline 实现,sql plan baseline是执行计划的一个基线,用于持久化存储已经验证过的执行计划信息,每个执行计划科对应一个plan baseline,通过该plan baseline可复现一个执行计划。
SPM机制包含如下过程:
- 计划捕获
- 对于新生成的计划,sql plan baseline为空,则直接加入sql plan baseline,否则通过演进验证新生成的比sql plan baseline中计划性能更优后加入sql plan baseline,并删除旧的plan baseline
- 计划演进
- 通过流量灰度验证新计划的性能是否比以前验证过的计划更优,如果优,则更新;
- 计划选择
- 优化器生成新的计划时,如果有则优先使用已验证计划。新计划需要通过演进验证后再使用;
执行计划管理- DBMS_SPM系统包
DBMS_SPM是操作SPM的命令包,可支持加载、更改以及删除plan baseline信息。
-
LOAD_PLANS_FROM_CURSOR_CACHE,用于将 plan cache中执行计划对应的plan baseline 信息加载到__all_tenant_plan_baseline表中;
DBMS_SPM.LOAD_PLANS_FROM_CURSOR_CACHE ( sql_id IN VARCHAR2, plan_hash_value IN NUMBER := NULL, fixed IN VARCHAR2 := 'NO', enabled IN VARCHAR2 := 'YES') RETURN PLS_INTEGER; -
ALTER_SQL_PLAN_BASELINE 用于修改 plan baseline中某些属性
DBMS_SPM.ALTER_SQL_PLAN_BASELINE ( sql_handle IN VARCHAR2 := NULL, plan_name IN VARCHAR2 := NULL, attribute_name IN VARCHAR2, attribute_value IN VARCHAR2) RETURN PLS_INTEGER; -
Drop_sql_plan_baseline 用于删除某个plan baseline;
DBMS_SPM.DROP_SQL_PLAN_BASELINE ( sql_handle IN VARCHAR2 := NULL, plan_name IN VARCHAR2 := NULL) RETURN PLS_INTEGER;
SQL执行性能监控
(g)v$sql_audit全局sql审计表
- 基于虚拟表
__all_virtual_sql_audit的视图,放在一个可配置的内存空间中 - 容量有限,只保留最新的
- 可以查看每次请求客户端来源,执行server信息,执行状态信息,等待事件及执行各阶段耗时等;
- 按租户拆分的,除了系统租户,其他租户不能跨租户查询
Sql_audit相关设置
-
设置sql_audit使用开关
alter system set enable_sql_audit = true/false -
设置sql_audit内存上限,默认内存上限3g,可以设置范围为[64M,+]
alter system set sql_audit_memory_limit o= '51mb'
(g)v$sql_audit看哪些?
- retry 次数 是否很多(retry_cnt字段),次数多,可能有锁冲突或切主的情况
- queue time的值是否过大(queue_time 字段),很高表明cpu资源不够用
- 获取执行计划时间(get_plan_time) 如果时间很长一般会伴随is_hit_plan=0,表示没有命中plan cache
- 查看execute time 值,如果过大
- 查看是否有很长的等待事件耗时
- 分析逻辑读次数是否异常多
SQL audit 记录的等待事件如下相关信息:
- 记录了 4 大类等待事件分别的耗时(APPLICATION_WAIT_TIME, CONCURRENCY_WAIT_TIME,
, SCHEDULE_TIME), 每类等待事件都涉及很多具体的等待事件
- 记录了耗时最多的等待事件名称(EVENT)及该等待事件耗时(WAIT_TIME_MICRO)
- 记录了所有等待事件发生的次数(TOTAL_WAITS)及所有等待事件总耗时(TOTAL_WAIT_TIME_MICRO)
(g)v$sql_audit淘汰机制
- 后台任务每隔1秒会检测是否需要淘汰
- 达到内存最大可用上限
avail_mem_limit = min(Observer 可用内存*10%,sql_audit_memoery_limit)可用内存的10%或者超过了内存限制; - 淘汰/停止淘汰触发标准
| avail_mem_limit最大可使用上限区间 | 淘汰触发条件 | 停止淘汰触发条件 |
|---|---|---|
| [64M, 100M] | avail_mem_limit - 20M | avail_mem_limit - 40M |
| [100M, 5G] | availmem_limit * 0.8 | availmem_limit * 0.6 |
| [5G, +∞] | availmem_limit - 1G | availmem_limit-2G |
| sql_audidt记录数上限 | 超过900w条记录 | 达到800w条记录 |
/**
当avail_mem_limit 在[64M,100M]范围内时,内存使用值达到avail_mem_limit-20M的时候触发淘汰;
当avail_mem_limit 在[100M,5G]范围内时,内存使用值达到 avail_mem_limit*0.8时触发淘汰;
当avail_mem_limit 在[5G,+∞]范围内时,内存使用值达到 avail_mem_limit-1G时触发淘汰。
当`sql_audidt`记录数超过900万条时,触发淘汰。
*/
SQL trace
SQL Trace 能够交互式的提供上一次执行的sql请求执行过程信息及各阶段的耗时
默认关闭,需要开关开启,可通过session变量控制开关打开或关闭.set ob_enable_trace_log=1开启,为0关闭
show tarce
当开启sql trace的时候,通过show trace查看该sql执行的信息。以下为输出
| 列名 | 说明 |
|---|---|
| Title | 记录执行过程某一个阶段点 |
| KeyValue | 记录某一个阶段点产生的一些执行信息 |
| Time | 记录上一个阶段点到这次阶段点执行耗时 |
示例
oceanbase> set ob_enable_trace_log =1; -- 开启trace
Query OK, 0 rows affected (0.01 sec)
OceanBase (root@oceanbase)> select count(*) from __all_table; +----------+
| count(*) |
+----------+
| 168 |
+----------+
1 row in set (0.03 sec)
OceanBase (root@oceanbase)> show trace;
+-------------------+--------------------------------------------+-------+
| Title | KeyValue | Time |
+-------------------+--------------------------------------------+-------+
| query start | trace_id: "[Y3B6C6451982C-3E9627]"; | 0 |
| parse start | stmt: "select count(*) from __all_table"; | 99 |
-- 词法/语法解析耗时
| pc get plan start | | 16 |
| pc get plan end | | 50 |
-- 执行计划缓存耗时
| resolve start | | 62 |
| resolve end | | 355 |
-- 语义解析耗时
| transform start | | 105 |
| transform end | | 107 |
-- 逻辑改写耗时
| optimizer start | | 3 |
| optimizer end | | 623 |
-- 优化器耗时
| CG start | | 1 |
| CG end | | 156 |
| execution start | | 87 |
| execution end | | 28364 |
执行耗时
| query end | | 166 |
+-------------------+--------------------------------------------+-------+
15 rows in set (0.01 sec)
小结
- 通过索引、分区、并行等方法对单表访问的场景进行优化;通过改变连接顺序、连接算法、查询改写、并行等方法,对多表访问的场景进行优化;针对呑吐量大的场景可以通过均衡请求流量的方法进行优化。
- 分区表是把普通的表的数据按照一定的规则划分到不同的区块内,同一区块的数据物理上存储在一起。是为了在特定的SQL操作中减少数据读写的总量以减少响应时间。OB支持HASH、KEY、LIST、RANGE等多种分区类型,支持一级分区和二级分区。
- 通过创建合适的索引来改变访问路径,从而减小数据的访问量,降低扫描的代价。需要根据不同场景合理来衡量使用局部索引还是全局索引。
- 通过Hint可以影响数据库优化器生成计划的逻辑,但并不影响SQL语句本身的语义。
- 利用(g)v$sql_audit全局审计表可以查看执行过程信息及各阶段的耗时
第五章、分布式事务
全局快照及分布式一致性读
传统数据库的实现原理
快照隔离级别(snapshot isolation)+多版本并发控制(Multi-versionConcurrency controll)
- 数据库的数据维护多个版本(即多个快照),当数据被修改的时候,可以利用不同的版本号区分出正在被修改的内容和修改之前的内容
- 基于上面实现对同一份数据的多个版本做并发访问,避免了锁机制带来的读写冲突问题
我们举个例子:
1,我们先插入一条id为1的记录R1,整个过程没有任何的并发
2,接着我们开始插入id=2的R2记录,开启事务T1以后,来了并发事务T2,查询id<10,此时因为T1事务没有提交,T2事务只能读已提交的
3,接着T1执行事务成功
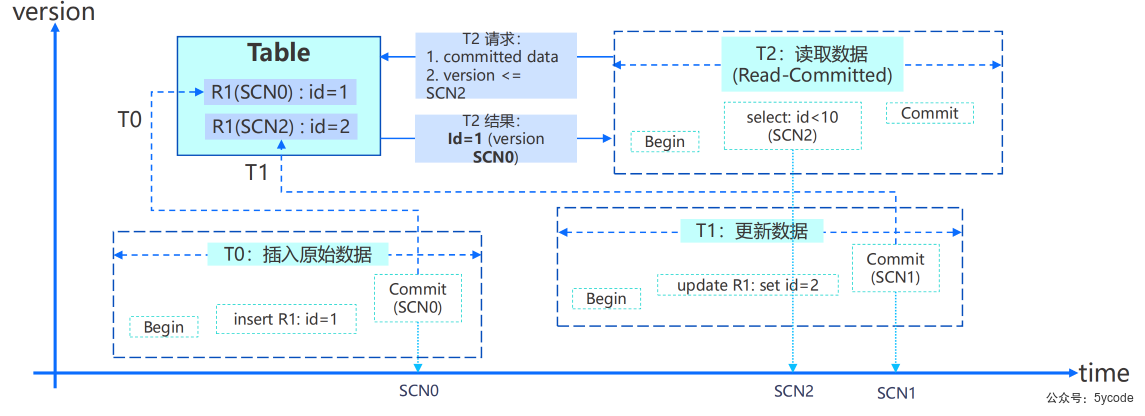
快照隔离级别
| 隔离级别 | 脏读 | 不可重复读 | 幻读 |
|---|---|---|---|
| Read uncommitted | √ | √ | √ |
| Read committed | × | √ | √ |
| Repeatable read | × | × | √ |
| Serializable | × | × | × |
- 没有快照的时候,一个事务里读取的到的数据不一致;
| 时间顺序 | 事务****A | 事务****B |
|---|---|---|
| 1 | 开始事务 | |
| 2 | 第一次查询小明年龄为20岁 | |
| 3 | 开始事务 | |
| 4 | 其它操作 | |
| 5 | 更改小明年龄为30岁 | |
| 6 | 提交事务 | |
| 7 | 第二次查询小明年龄为30岁 | |
| 备注 | 按照正确逻辑,事务A前后两次读取到的数据应该一致 |
| 时间顺序 | 事务****A | 事务****B |
|---|---|---|
| 1 | 开始事务 | |
| 2 | 第一次查询数据总量为100条 | |
| 3 | 开始事务 | |
| 4 | 其它操作 | |
| 5 | 新增100条数据 | |
| 6 | 提交事务 | |
| 7 | 第二次查询数据总量为200条 | |
| 备注 | 按照正确逻辑,事务A前后两次读取到的数据应该一致 |
OB的隔离级别
- MySQL 模式
- 读已提交 (默认)
- 可重复读
- Oracle 模式
- 读已提交(默认)
- 可串行化
设置隔离级别
-
事务级别
set transaction isolation level serializable -
会话级别
alter session set isolation_level=serializable
分布式数据库面临的挑战
和传统单点全共享(shared-everything)架构不同,ob是一个原生的分布式架构,采用了多点无共享(shared-nothing)架构,在在实现跨机器一致的快照隔离级别和多版本并发控制时会面临分布式架构所带来的技术挑战。
t1,在server1插入一条数据R1,已提交
t2,在server1插入一条数据R2,未提交
t3,读取数据的时候只会读取到t1
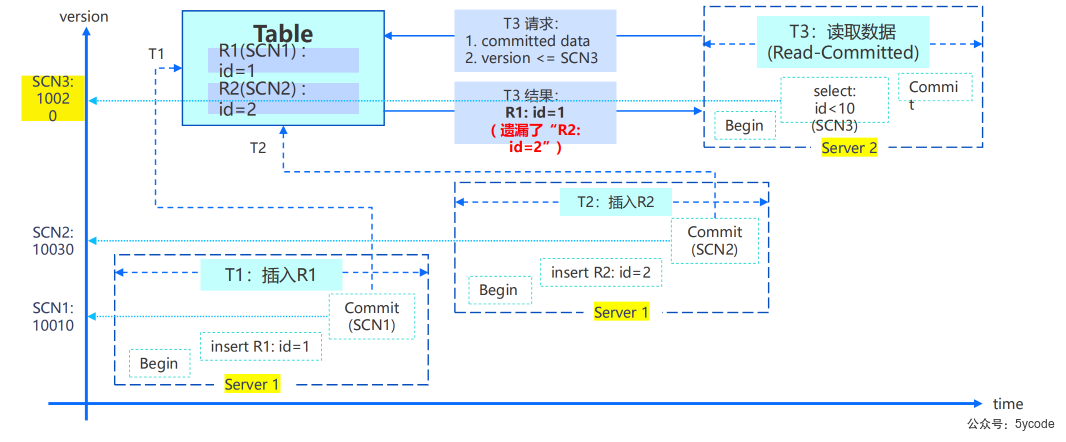
-- 下面的这个图有问题,画图的人有点懒
t1,在server1插入的版本号是 10030
t2,在server2插入版本号10010
t3,在server2查询小于版本号10020的数据
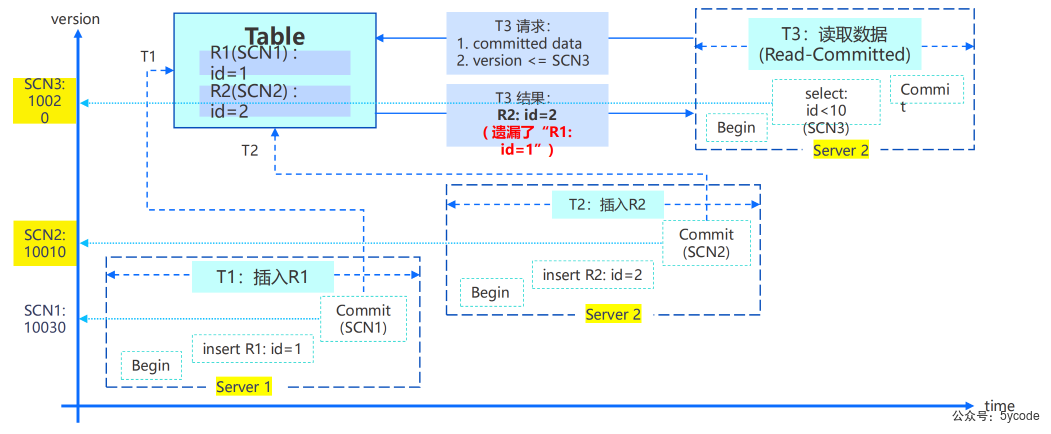
业界常用解决方案
为了解决分布式的问题,保证跨机器的的外部一致性,业内有两种实现方式
- 利用特殊的硬件设备,如gps和原子钟,使多态机器间的系统时钟保持高度一致;
- 软服务,所有的数据库事务通过集中式的服务获取全局一致的事务号,由这个服务来保证版本号的单调向前
OB全局一致快照技术
- OB数据库是利用一个集中式服务来提供全局一致的版本号
- 事务在修改数据或者查询数据的时候,都会从这个集中式的服务处获取版本号,
- ob能保证所有的版本号单调向前
- 全局时间戳服务是按租户划分的
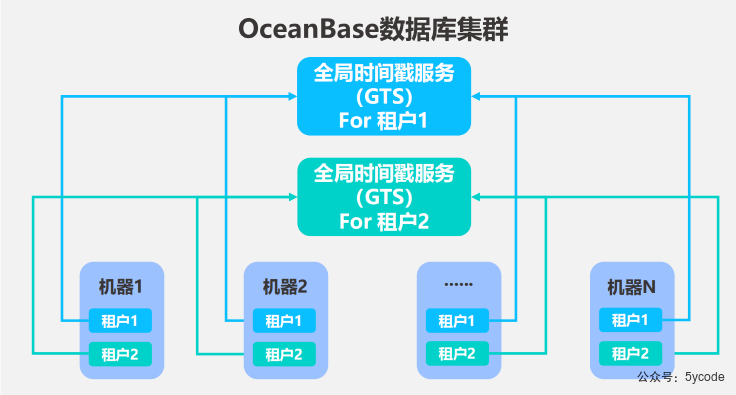
GTS服务高可用
- GTS是集群的核心,根据租户的级别采用不同的实现方式实现高可用
- 用户租户
- Ob数据库使用租户级别内部表
__all_dummy的leader作为GTS的服务提供者,时间来源于该leader的本地时钟。 - GTS默认是三副本,其高可用能力跟普通表一样
- Ob数据库使用租户级别内部表
- 系统租户
- 使用
__all_core_table的leader作为GTS服务的提供者,高可用普通表一样,时间戳正确性保证
- 使用
- 用户租户
- `ob_timestamp_service 用于指向使用何种时间戳服务
- GTS 默认 (事务执行过程中从GTS服务获取全局时间戳作为事务的快照以及事务的提交版本号)
- LTS (事务执行过程中使用服务器本地的时间戳作为事务的快照,不支持跨分区的访问)
- HYG_GTS
OB全局一致性快照如何处理异常
GTS的选举和表的选举一样,其实就是靠表做到了高可用
当leader挂了,以后,rootService会根据paxos协议重新选主;
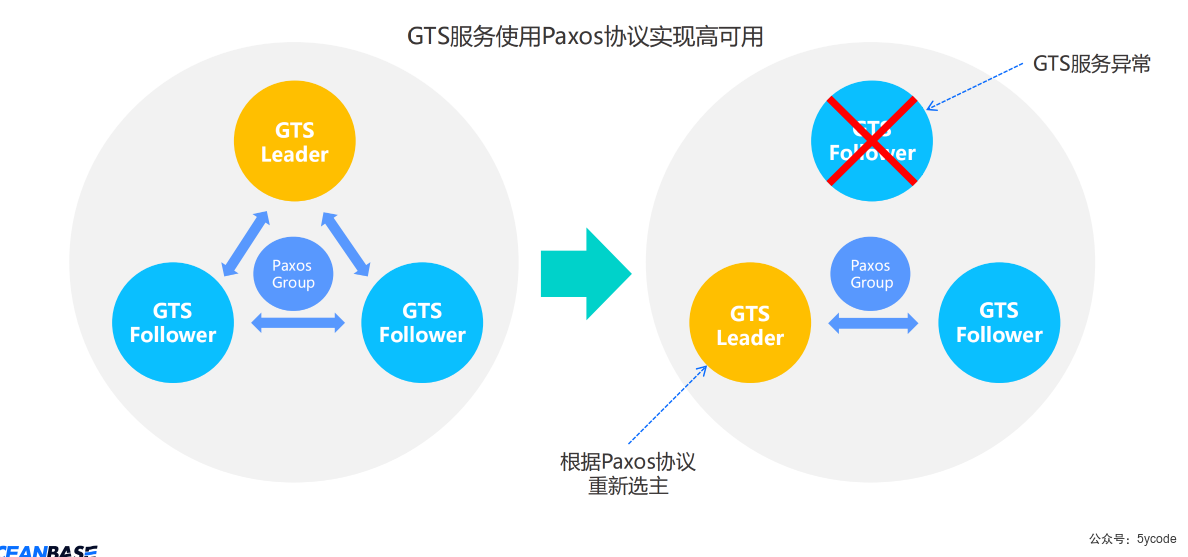
OB通过多种机制保证分布式事务跨机执行的ACID
- 原子性:通过两阶段提交协议保障
- 一致性:事务前后数据的完整性必须保持一致
- 保证主键唯一
- 全局快照:单租户GTS服务,1秒钟内能够响应获取全局时间戳调用次数超200万次
- 隔离性
- 采用MVCC进行并发控制,实现read-committed隔离级别
- 所有修改的行加互斥锁,实现写写互斥
- 读操作读取特定快照版本的数据,读写互不阻塞
- 持久性
- Redo-log使用paxos协议做多副本同步
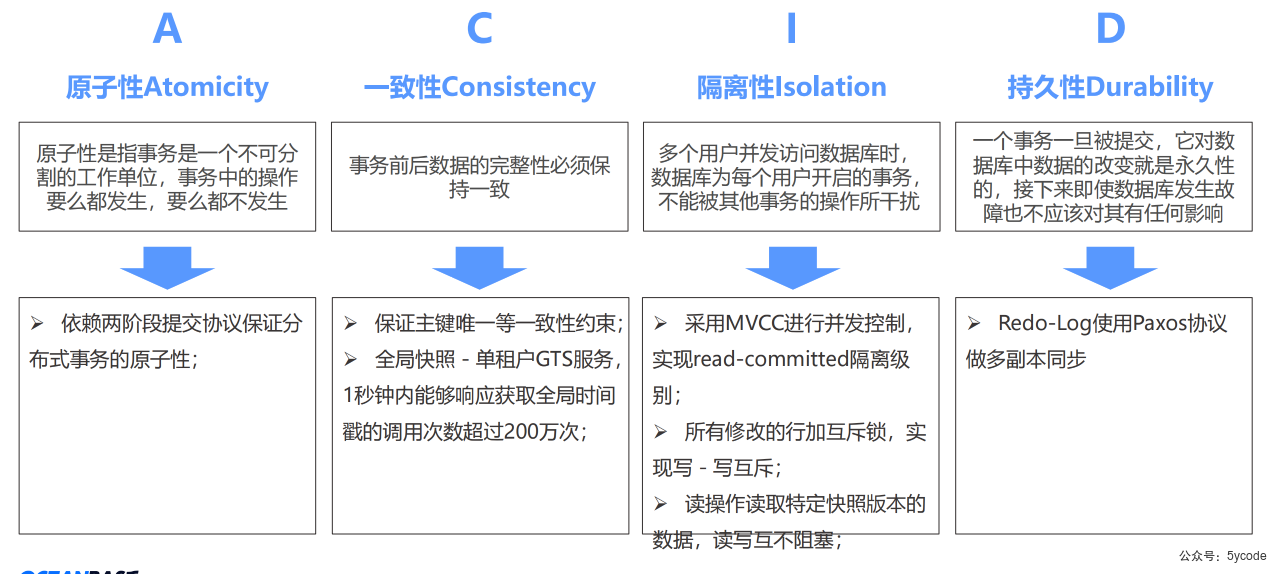
分布式两阶段提交
分布式中可能会出现的问题
场景一
- 交易发生时,负责A账户扣100块钱的A机器死机,没有扣成功,而负责给账户B加100块钱的B机器工作正常,加上了100
- 负责给A账户扣100块钱的A机器正常,已经扣掉100,而负责给账户B加100块钱的B机器死机,100块没加上,那么用户就会损失100
场景一解决方案:
- 使用paxos多副本,比如:账户数据在3台机器上
- 转账时,至少两台机器执行完毕,才算转账完成,一台坏掉了不影响
场景二
- A账户要扣掉100块,但是它的余额只有90块,或者已经达到了今天的转账限额,这种情况下,如果贸然给B账户加了100块,A账户却不够扣,麻烦了
- 如果B账户状态有异常(例如冻结),不能加100块,同样也麻烦了
场景二解决引入裁判员机制
- 裁判员问A账户:你的三台机器都没问题吧?A账户说:没问题。你的账户允许扣100码?A账户说:允许;
- 裁判员问B账户:你的三台机器都没问题吧?B账户说:没问题。你的账户状态能加100码?B账户说:允许;
- 这是裁判员吹哨,A、B同时冻结
- A扣100,B加100,双发昂向裁判汇报“成功”
- 裁判员再吹哨,A、B账户同时解冻
两阶段协议
协调者:负责真个协议的推进,使得多个参与者追踪达到一致
参与者:响应协调者的请求,根据协调者的请求完成prepare 操作及commit/abort操作
2PC是一个非常经典的强一致、中心化的原子提交协议。中心化指的是协调者(coordinator),强一致性指的是需要所有参与者(partcipant)均要执行成功才算成功,否则回滚。
- 第一阶段:协调者(coordinator)发起提议通知所有的参与者(partcipant),参与者收到提议后,本地尝试执行事务,并不commit,之后给协调者反馈,反馈可以是yes或no
- 第二阶段:协调者收到参与者的反馈后,决定commit或者rollback,参与者全部同意这commit,如果有一个参与者不同意则rolback。
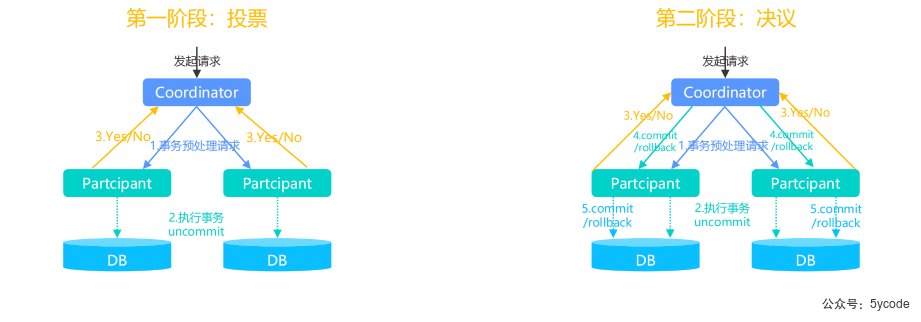
标准两阶段提交协议优缺点
- 优点:状态简单,只依靠协调者状态即可确认和推进整个事务状态;
- 缺点,协调者写日志, commit延时高
OB两阶段提交协议
- 协调者不写日志,变成了一个无持久化状态的状态机
- 事务的状态由参与者的持久化状态决定,只要有一个参与者持久化了,就一定会提交
- 所有参与者都prepare成功即认为事务进入提交状态,立即返回客户端commit prepare成功就返回客户端commit
- 每个参与者都需要持久化参与者列表,方便异常恢复时,构建协调者状态机,推进事务状态
- 参与者增加clear阶段,标记事务状态机是否终止
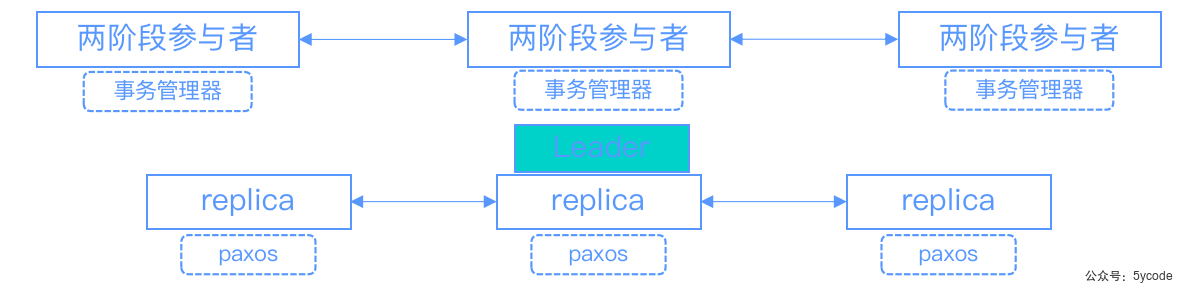
OB的两阶段提交
- 业务不感知是否分布式事务,如果只有一个参与者使用一阶段提交;否则自动使用两阶段提交
- 参与者的实体是partition(px,py,pz) 分区;
- 指定第一个参与者px作为协调者,发送end_trans消息给px并告知参与者列表;px、py、pz
- 第一个参与者即是协调者又是参与者
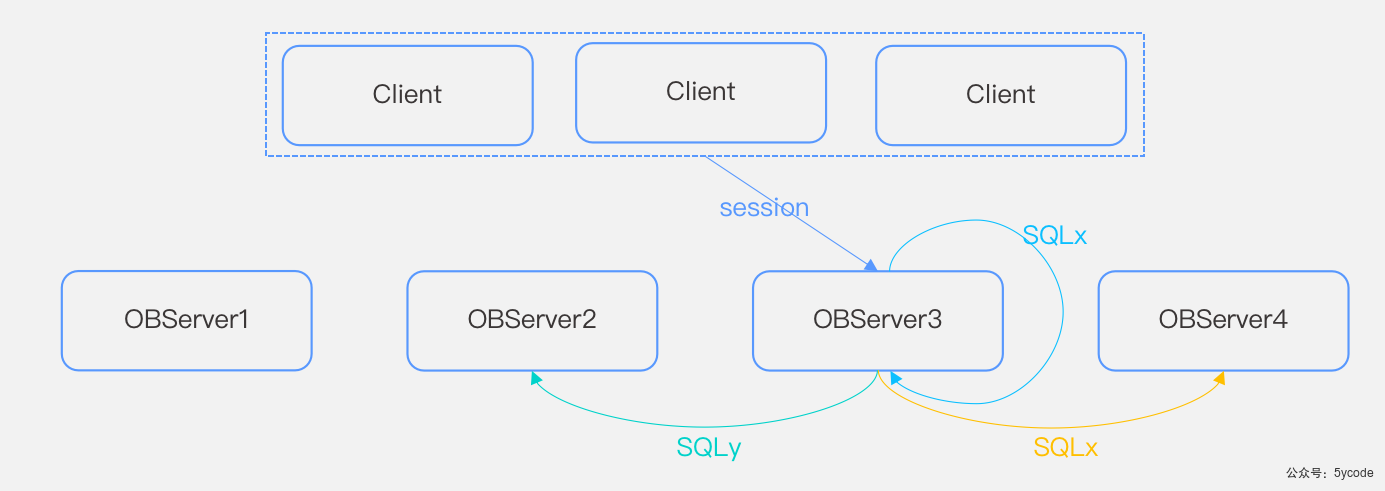
OB两阶段提交延迟分析
用户感知的commit延迟
-
标准:4次日志延迟+2次RPC延迟
1, 协调者写入commit日志(第1次日志延迟),然后发起prepare req给参与者(第1次rpc延迟); 2,参与者写日志,并确认可以提交(第2次日志延迟); 3,协调者写日志(第3次日志延迟),并发起commit req给参与者(第2次rpc延迟); 4,参与者写日commit日志,返回协调者commit ok;(第4次日志延迟) 5,协调者接收到commit ok返给客户端提交成功 -
OB:1次日志延迟+2次RPC延迟
1,协调者发起prepare req 给所有参与者;(第1次rpc延迟) 2,参与者接到prepare req 之后,决定是否可以可以提交,如果可以则持久化 prepare log,并返回给给协调者 prepare ok,否则 prepare 失败;(注意,第一个参与者也是协调者);(第1次日志延迟) 3,协调者收齐所有的参与者的prepare ack之后,进入commit状态,这个时候就可以直接返回事务commit成功,然后想所有的参与者发送commit request;(第2次rpc延迟) 4,参与者接收到commit req 之后释放资源解锁,然后提交commit log,日志持久化完成之后给协调者回复 commit ok消息,然后clear 退出;(第2次日志延迟);(第一张是ppt的图,有问题,第二张是官网的图)
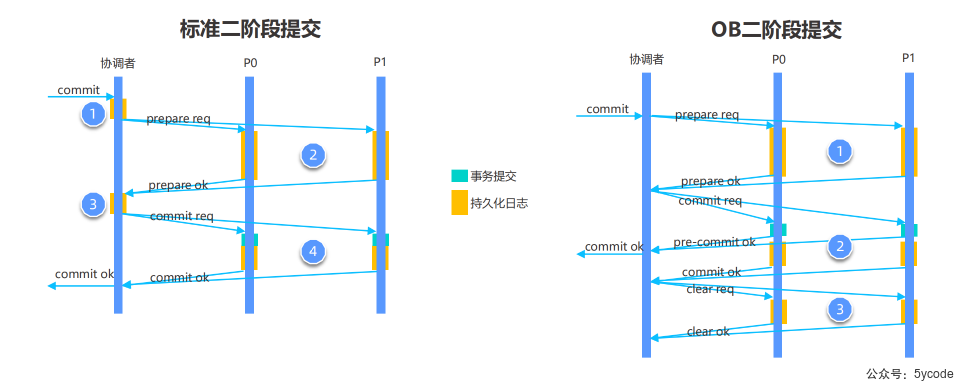
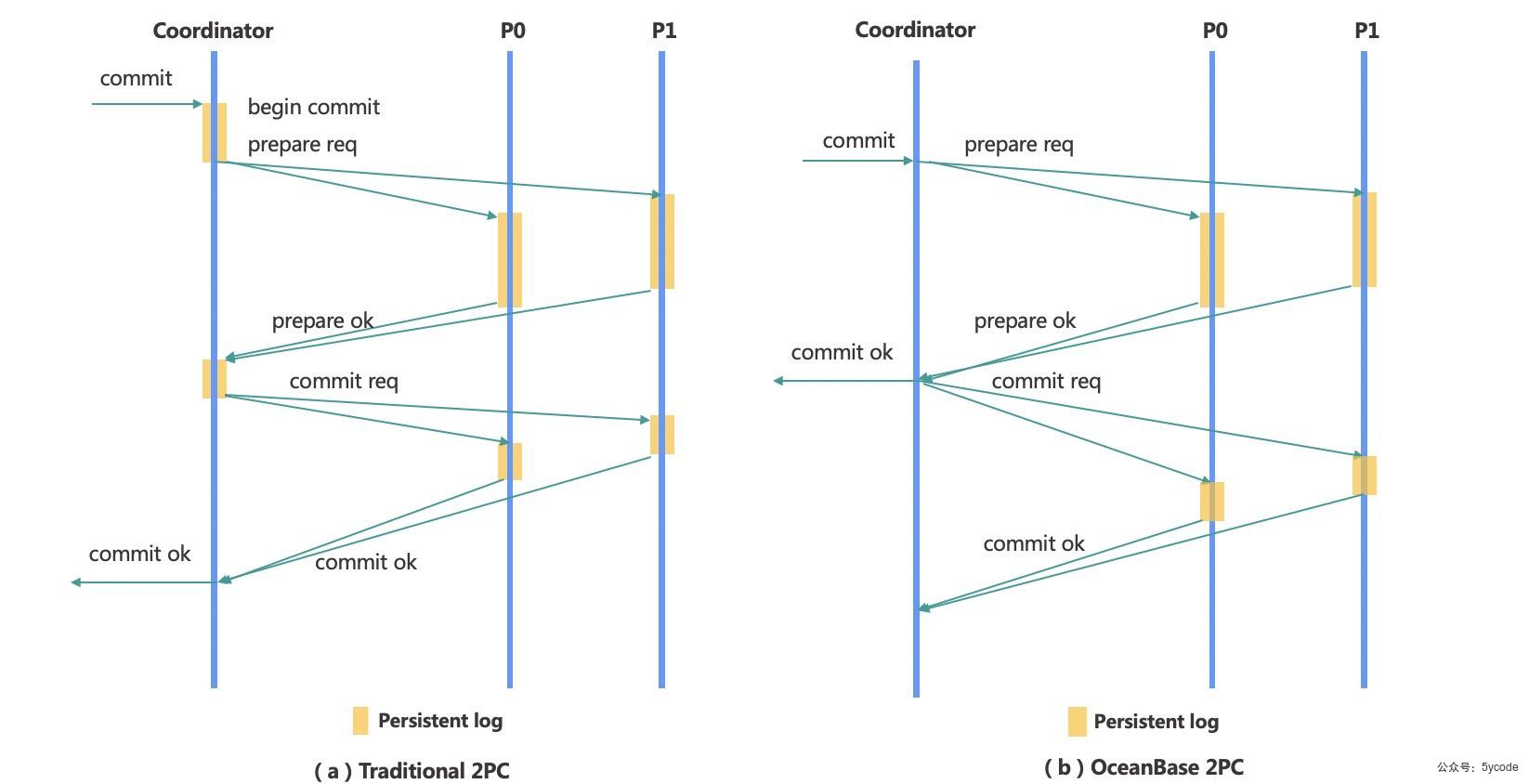
分布式事务的高可用
-
如果事务在prepare状态落盘之前发生宕机,机器恢复后会回滚事务
1, 协调者发起请求,在参与者落盘之前失败了,回滚事务;
-
如果事务处于commit阶段,由于clog已经落盘,即使发生宕机场景,事务都会执行完成,只是业务端可能会收到事务unknown的回复,需要业务confirm事务的状态。
1,协调者发起prepare 2,参与者执行事务,记录clog,不commit,返回成功; 3,这个时候协调者宕机,业务端可能会收到unknown回复;
两阶段提交过程中的参与者宕机
- 还未进入prepared状态
- 参与者所有事务状态丢失
- 参与者会应答协调者prepare unknown消息
- 事务最终会abort
- 已进入prepared状态
- 状态已经paxos同步
- 系统会自动选择一个副本,作为新的leader并恢复出prepare状态,协调者继续推进
两阶段提交过程中协调者宕机
- 协调者与第一个参与者是同一个partition
- 参与者状态机恢复遵从参与者自己的逻辑
- 协调者状态机恢复由参与者回复协调者的消息触发
- 参与者发送prepare ok 后未收到协调者进一步消息(commit/abot)时,认为上一条回复消息丢失,会定时重新发送上一条消息(这个时候认为协调者没有收到,又重新的发了一条)
- 所有参与者都记录全部参与者列表

分布式事务优化
- 分布式事务底层优化
- 单分区事务:不走2pc,直接写一条日志即可完成事务提交
- 单机分区事务-> 优化的两阶段提交
- 多机多分区事务-> 完整的两阶段提交-> prepare,commit/abort
- 分布式事务调优优化
- 业务数据模型设计原则:尽量避免跨机分布式事务
- 单sql语句不建议跨机器,通过table group/primary_zone把相关的表的leader放在同一个机器上
- 慎重选择事务中的第一条语句,因为OBProxy的路由规则
redo 日志
ob用于宕机恢复以及维护多副本呢数据一致性的关键组件。
- 物理日志
- 记录全部修改历史
- 最大2mb
- clog_disk_usage_limit_percentage 配置redo日志使用磁盘空间的上限。默认95%,超过不允许任何事物的写入
- clog_disk_utilization_threshold 配置redo日志使用磁盘的下限,默认80%
作用:
- 宕机恢复
- WAL机制
- 回放机制
- 多副本数据的一致性
- 采用multi-paxos协议在多个副本之间同步redo日志
日志文件类型:
- clog commit log
- 文件编号从1号开始并连续递增,文件id不会重复
- 单个文件大小64mb
- ilog index log
- 记录相同分区相同log Id的已经形成多数派日志的commit 位置信息
小结
- 使用全局一致性快照,OB便具备了在全局范围内实现快照隔离级别和多版本并发控制的能力,可以在全局范围内保证外部一致性,并在此基础上实现众多涉及全局数据一致性的功能,比如全局一致性读、全局索引
- 和传统数据库必,ob在保留分布式架构优势的同时,在全局数据一致性上也没有降级,应用开发者就可以像使用单点数据库一样使用ob,不必担心机器之间的底层数据一致性问题;
- ob数据库将paxos分布式一致性协议引入到两阶段提交,使得分布式事务具备自动容错能力。两阶段提交的每个参与者包含多个副本,副本之间通过paxos协议实现高可用。(如果协调者挂了,协调者的高可用,参与者在prepare ok以后没有收到commit消息,会再次给新的协调者发送prepare ok,)
OceanbaseV2.x单个事务的大小为100M,OceanBase3.x 版本支持了大事务,不再受此限制。
语句超时:ob_query_timeout 通常为10秒
事务超时:ob_trx_timeout 默认100秒
OceanBase 数据库采用了分区级别的日志流,每个分区的所有日志要求在逻辑上连续有序。而一台机器上的所有日志流最终会写入到一个日志文件中。
-
clog
- commit log ,用于记录redo 日志的日志内容
- 位于store/clog目录下,文件编号从1开始连续递增
- 单个文件的大小为64MB
- 记录数据库中的数据所做的更改操作
- 以2mb为单位
clog_disk_usage_limit_percentage控制clog或ilog的使用上限,默认95,表示占用磁盘空间的百分比- 超过此值后,observer 不再允许任何新事物的写入,同时不允许接收其他的observer同步的日志
- 对外表现所有访问此observer的读写事务报:
transaction needs rollback
clog_disk_utilization_threshold配置clog或ilog使用下限
-
ilog
- Index log, 用于记录相同分区相同log id 的已经形成多数派日志的commit log的位置信息;
- ilog文件删除不会影响数据的持久性,但会影响系统的恢复时间
第六章OBProxy 路由与使用运维
OBProxy简介
背景
- ob是分布式数据库,每个表甚至每个表的不同分区可能存放在不同的机器上,想要对表进行读写,必须定位到数据所属表或分区的主副本上;
- OBProxy 是OB专用的反向代理软件,目的就是把客户端的sql转发到正确的OBServer上
- 客户端通过负载均衡访问无状态的OBProxy,然后OBProxy 转发到对应的OBServer
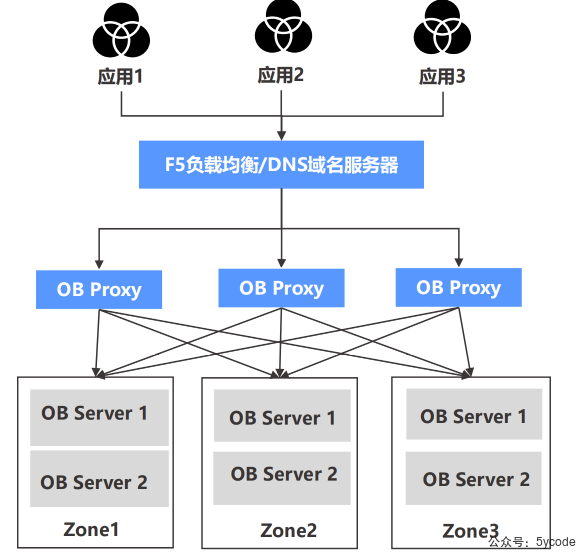
OBProxy核心功能(路由) ☆ FYI
路由
OB核心目标是路由转发
核心功能有:
-
路由
-
链接管理
-
监控&&运维
路由的目的是:将具体的sql转发到最恰当的server上执行,核心过程包括
- 简单的SQL Parser
- LDC路由
- 读写分离
- 备优先读
- 黑名单机制
1, obproxy通过简单的sql解析,解析出数据库名,表名,hint,查询条件
2,根据配置查询出现有的路由规则,具体用哪个;
3,根据具体的路由规则,获取路由表;
4,根据路由表选择目标server;
5,检查路由该服务器是否在黑名单中,在,重新走4,否则直接转发;
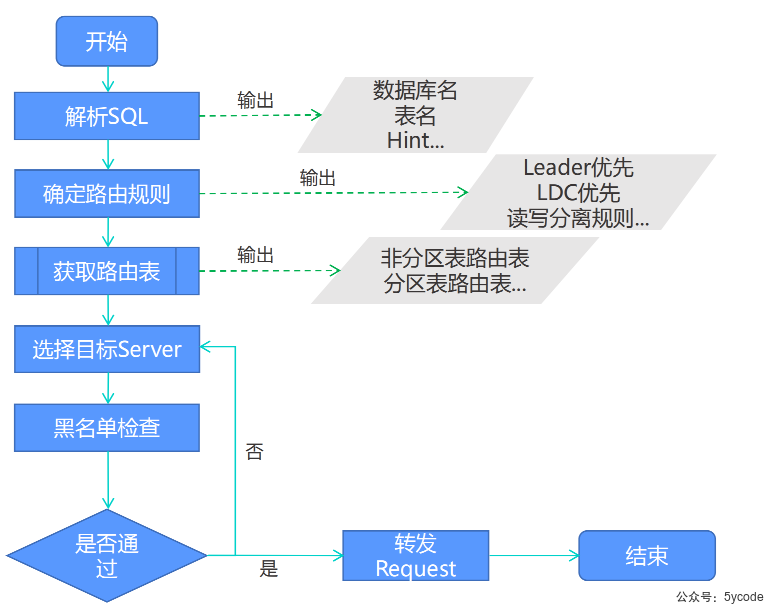
路由功能举例
1, 客户端执行sq1 :Select * from t1 where c1 = 1 and c2 = 2
2,解析并提取出表名 和条件 表名: t1 条件: c1 = 1 and c2 = 2
3,从缓存中获取schema,可以理解为表的一些元数据信息:比如表名对应的分区数据,分区key,分区类型,分区对应的server
4,判断是否分区表
4.1 是分区的情况,提取到分区的表达式,然后计算出分区,进行分区裁剪,定位到对应的分区server上
4.2 不是分区表从缓存中获取location
5, 根据请求类型、LDC、黑白名单最终确定所选择的server
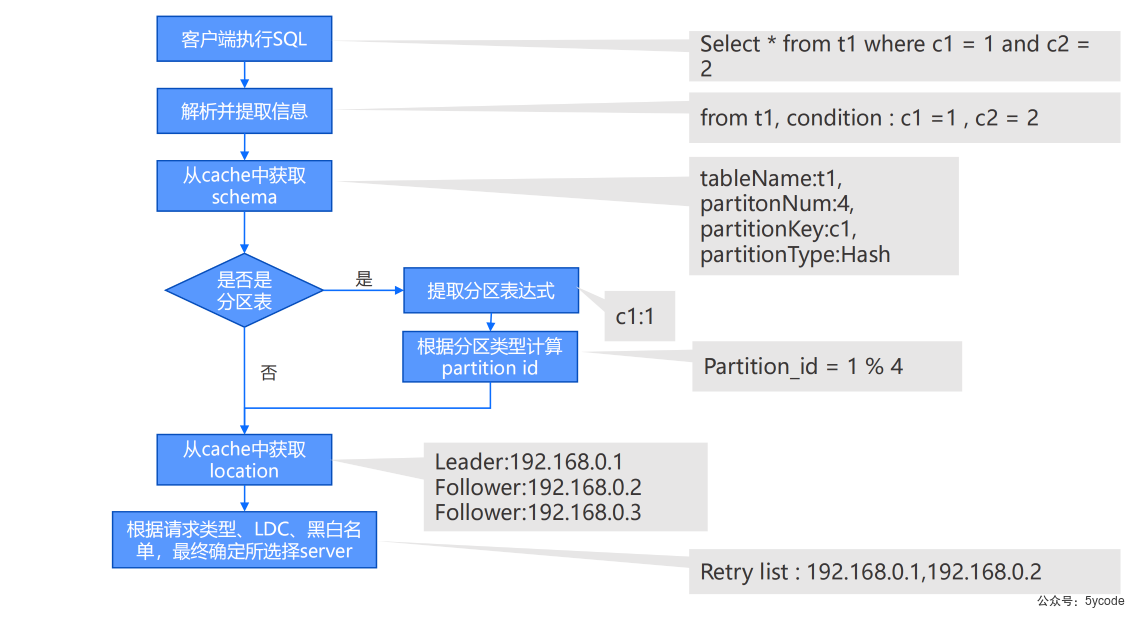
连接管理
- 在Observer宕机/升级/重启的时,客户端与OBProxy的连接不会断开,OBProxy可以迅速切换到正常的server上,对应用透明
- OBProxy支持用户通过同一个OBProxy访问多个OB集群
- server session对于每个client session独占
- 同一个client session对应server session状态保持相同(session变量同步)
/**
1,客户端发送登录请求
2,obproxy 根据cluster_name获取集群机器列表
2.1 如果是rslist启动 odp,直接通过rslist获取对应的机器,此种模式,只能连接一个集群
2.2 如果通过配置obproxy_config_server_url启动的odp,依赖于OCP获取集群
3,obproxy选取一台机器,并查询租户名所在机器列表
4,obproxy拿到以后会缓存起来
*/
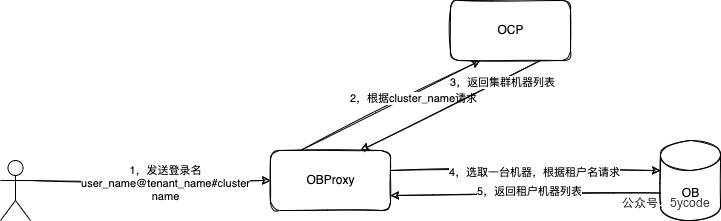
ODP连接方式有4种,常用有两种 ☆
支持四种
-
用户名@租户名#集群名(常用)- 集群名可以是集群名:1 这样
- 单集群的时候,可以不加集群名
-
集群名:租户名:用户名(常用) -
集群名-租户名-用户名 -
集群名.租户名.用户名
监控&&运维
- 周期性汇报统计项到OCP,实现了语句级、事务级别、session级别、obproxy级别的各种统计
- Xflush 日志监控(包括慢查询监控、error包监控等)
- sql audit功能
- 实现了大量内部命令来实现远程监控,查询和运维
OBProxy 部署
- 一般推荐部署到observer上,减少跨网络的访问
- 建议一台机器只部署一个ODP服务,并约定用2883,如果部署多个,需要指定不同的端口和不同的配置文件路径予以区分
部署方式
集中部署
- 集中部署的好处是一套OBProxy可以接管多个
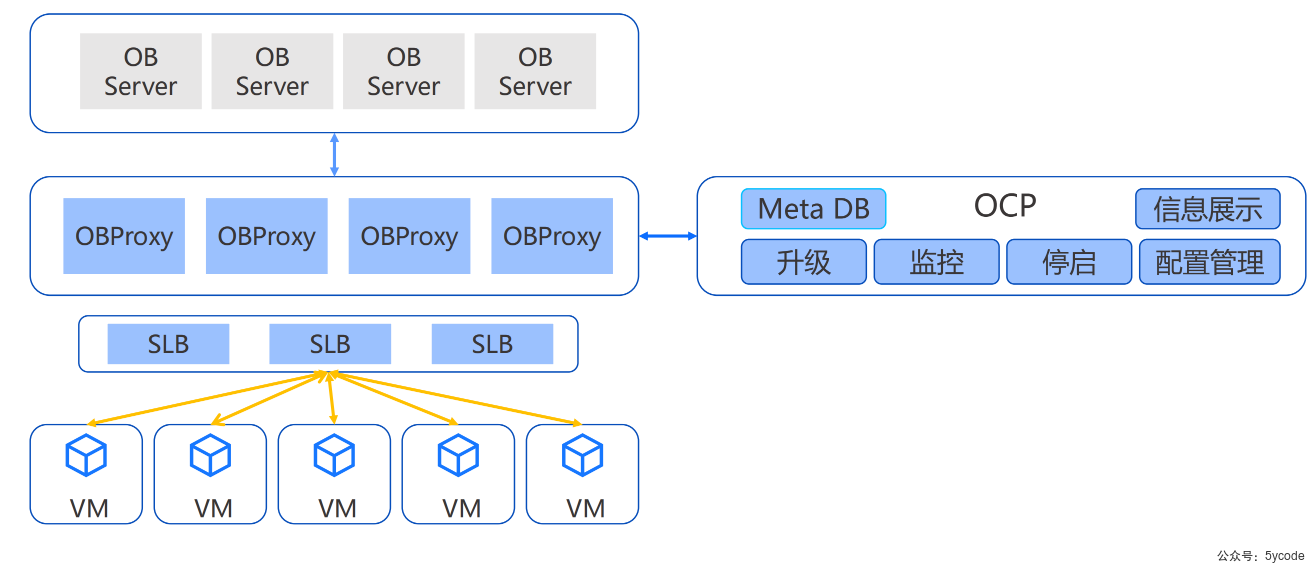
客户端部署
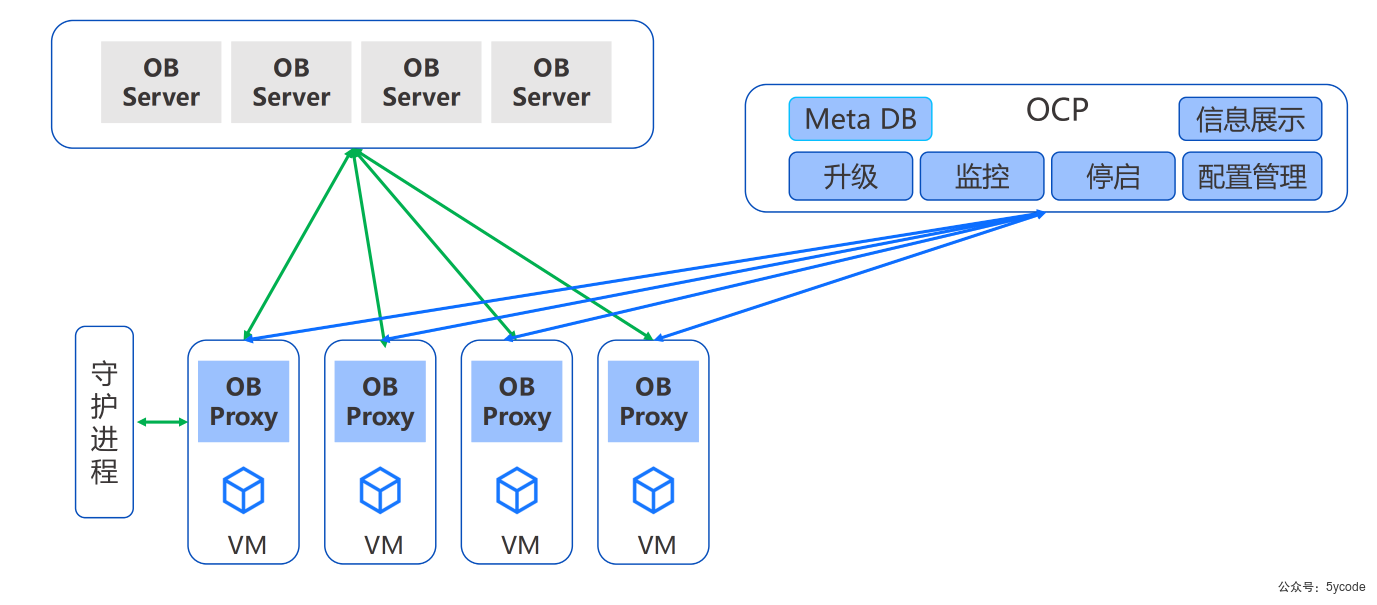
启动模式
ConfigServer是OCP平台提供的OB集群物理入口管理服务,是一个web api 服务
- 测试模式:主要用于现阶段开发调试,无序依赖ConfigServer 测试环境都是用的这种模式,指定一组ip
- 测试模式通过指定集群的RSList(ip列表)来启动 -r,OBProxy集群仅可访问创建OBProxy集群时指定那个OB集群,OBProxy集群创建成功后不可追加可连接的OB集群
- 语法:
./bin/obproxy -p <obproxy_port> -r <'ip:port'> -n <appname> -o -c <cluster_name>
- 生产模式
- OBProxy通过指定Config Server提供的config_url来启动,config server 服务可以获取相关集群的配置信息。同一个config server 可以保存多个ob集群的RSList信息,使obprxoy能为多个OB集群同时提供服务
- 在连接ObProxy时,起用域名类似
root@sys#cluster- root为用户名
- sys为租户
- cluster为集群
- 语法:
./bin/obproxy -p <obproxy_port> -n <appname> -o obproxy_config_server_url='your_config_url' -c <cluster_name>
路由实现
OBProxy 执行流程
- 接到请求后,先解析sql,通过简易解析,解析出表名和库名和条件
- fetch route entry,根据用户的租户名、数据库、表名、分区id,向observer拉取该partition的路由表
- sort route entry,根据各种相关属性对路由表中的ip进行排序(确定路由规则)
- read_consisitency:强一致性读or弱一致性读
- 目标server状态:正在合并or常态
- 路由精准度:PS or TS
- LDC匹配: 本地、同城、异地
- Zone类型
- 读写分离的ob_route_policy取值
- filter byr congestion,从路由表中一次尝试目标ip,通过黑名单进行过滤,命中重新路由
- forward request,将用户请求转发给目标server
和路由相关的一些基础概念
根据以下的配置,OBProxy进行综合的路由排序
- LDC配置:先本地->再同城->最后异地
- 本地: 同城机房(IDC相同)
- 同城:同城不同机房(IDC 不同,region相同)
- 异地:不同的地域(Region不同)
- OBServer状态:常态vs正在合并
- 租户的zone类型:读写型 vs 只读型
- 路由精准度:优先精准度高的
- Obproxy 中有目标partition的路由信息(ps)
- Obproxy中没有partition的路由信息,只有租户的路由信息(TS)
LDC简介
- IDC: 互联网数据中心,可以简单看成一个物理机房
- LDC: logical data center 是对IDC的一种逻辑划分
- Region: 地域信息,同城代表一个城市,包含一个或多个IDC,每个IDC部署一个或多个zone。一个ob集群可以包含若干个Region,每个Region包含若干个IDC,每个IDC部署若干个zone
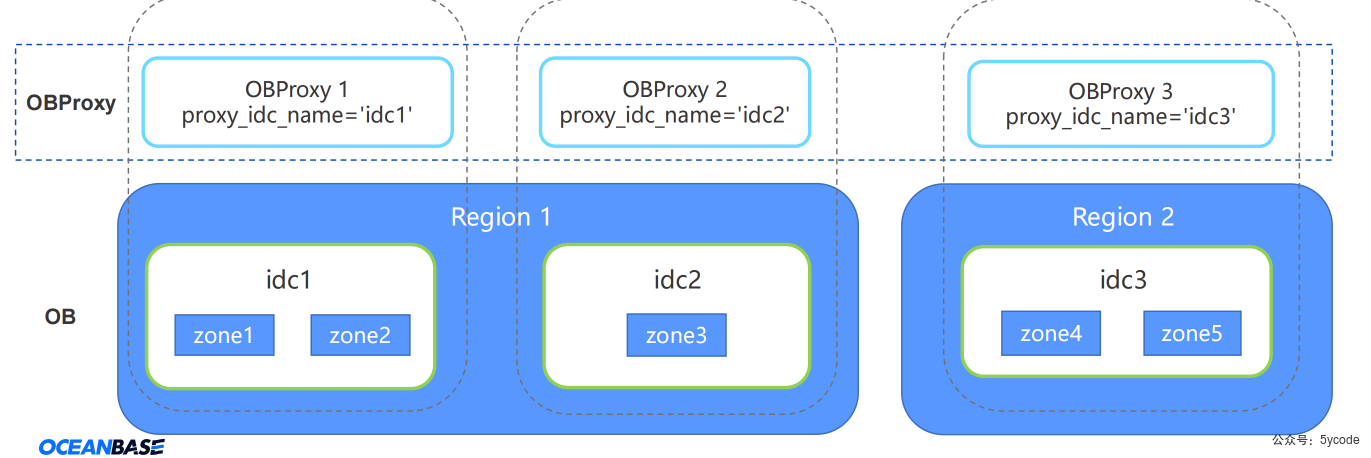
LDC 配置
集群的配置
LDC是指proxy按照根据城市/机房等信息就近路由访问observer,这需要observer设置好自身所处的机房和城市信息,需要proxy提供自身所处的机房信息。
-- 设置机房信息
alter system modify zone "z1" set region = "shanghai";
alter system modify zone "z1" set idc = "zue"
-- 检查observer LDC设置内容是否生效
select * from __all_zone;
obproxy的配置
obproxy 支持客户端和集中式部署,因此proxy 的LDC的支持全局级别和session级别。
- 全局级别: 配置proxy_idc_name用来控制全局级别的当前IDC机房信息、默认为空,配置项的设置可以通过启动参数/登录参数/ocp配置项更新进行,在proxy的启动脚本中使用-i 机房名启动传入,或者通过
alter proxyconfig set proxy_idc_name = '机房名'设置 - session级别: 设置用户变量
set @proxy_idc_name='xx'控制session级别的当前机房信息,默认不指定 - 优先级: session变量> 配置项
IDC配置和LDC匹配情况查询
- 首次启动时通过启动参数:
/bin/obproxy -p2883 -e -o obproxy_config_server_url='ocp_config_server_url',proxy_idc_name='hz001' -n trade - 修改proxy配置项:
alter proxyconfig set proxy_idc_name='hz001' - 通过执行
show proxyinfo idc,可以检查proxy内部识别的LDC部署情况

OBProxy 主要路由策略
- 写请求: 写请求路由到 readWrite zone的主副本
- 读请求有两种
- 强一致性读
- 默认的路由策略就是强一致性读(也就是路由到主副本)
- 需要读取partition的leader副本的数据,即SQL必须转发到涉及partition的leader server上执行,以保证获取到实时最新的数据
- 强一致性读适用于对读写一致性要求高的场景
- 弱一致性读
- 主备均衡路由策略(默认)
- 备优先读策略
- 读写分离策略
- 强一致性读
弱一致性读
配置弱一致性读
ob可以通过设置ob_read_consistency参数进行一致性读配置
- Global级别
- 用户通过
set global ob_read_consistency='weak'对当前租户所有会话生效(当前会话不生效)
- 用户通过
- session级别
- 通过设置
set ob_read_consistency='weak'只对当前正在连接的sesion生效 - sql hint,用户在select中加
/*+ read_consistency(weak)*/的Hit,仅限本语句
- 通过设置
整个的优先级为sql hint > session > global
主备均衡路由策略(默认)
Obproxy默认的路由方式为主备均衡路由
- 首先考虑Region,相同region的observer 优先于不同Region的observer
- 其次考虑合并状态,处于常态的observer 优先于 合并状态observer
- 考虑IDC关系,相同IDC的OBserver优先于不同IDC的observer
详细的路由顺序
-
相同 Region,相同 IDC 并且不处于合并状态的 OBServer
- 同一个region中,相同idc 中有不合并状态的observer优先路由
-
相同 Region,不同 IDC 并且不处于合并状态的 OBServer
- 如果相同idc中都处于合并状态,那就寻找不同IDC中不处于合并状态的observer
-
相同 Region,相同 IDC 并且处于合并状态的 OBServer
- 如果到了这一步是否意味着集群已经挂了?
-
相同 Region,不同 IDC 并且处于合并状态的 OBServer
-
不同 Region 并且不处于合并状态的 OBServer
-
不同 Region 并且处于合并状态的 OBServer
备优先读策略
-
备优先读仅在弱一致性时生效
-
优先读follower
-
通过用户级别的系统变量
proxy_route_policy控制 -
设置命令:
set @proxy_route_policy='[policy]';- 设置follower_first ,优先发给备
- 设置 unmerge_follower_first,优先发给不在集群合并状态的备机
-
验证命令:
select @proxy_route_policy;或者 show proxysession variables;
取值为follower_first时,路由逻辑是优先发备(即使集群在合并状态)
同机房不合并的备> 同城不同机房不合并的备-> 同机房在合并的备->同城不同机房在合并的备->同城机房不合并的主->同城不同机房不合并的主->不同城不合并的备->不同城合并的备->不同城不合并的主->不同城合并的主
取值为unmerge_follower_first时,路由逻辑是优先发不在集群合并状态的备机
同机房不合并的备->同城不同机房不合并的备->同机房不合并的主->同城不同机房不合并的主->同机房在合并的备->同城不同机房合并的备->不同城不合并的备->不同城不合并的主->不同城合并的备->不同城合并的主
读写分离策略
要求客户端将写请求路由到主副本,将弱一致性读请求到follower节点。
设置命令:set @@global.ob_route_policy=readonly_zone_first;
- Obproxy 中有目标partition的路由信息(ps)
- Obproxy中没有partition的路由信息,只有租户的路由信息(TS)
| 值 | 路由策略 | 说明 |
|---|---|---|
| readonly_zone_first | 1.本地常态读库PS -> 2.同城常态读库PS -> 3.本地合并读库PS -> 4.同城合并读库PS ->…. | 默认值, 读库优先访问: 优先级: zone类型 > 合并状态 > idc状态 |
| only_readonly_zone | 1.本地常态读库PS -> 2.同城常态读库PS -> 3.本地合并读库PS -> 4.同城合并读库PS -> 5.本地常态读库TS ->…. | 只访问读库 优先级:合并状态 > idc状态 |
| unmerge_zone_first | 1.本地常态读库PS -> 2.同城常态读库PS -> 3.本地常态写库PS -> 4.同城常态写库PS->……. | 优先访问不在合并的zone: 优先级:合并状态 > zone类型 > idc状态 |
OBProxy使用限制
- proxy parser在根据sql选择server时,有以下几点特殊的逻辑:
- 只解析
Begin/START/transacton/set和其他DML如果遇到其他单词开头的语句,会直接跳过,认为该语句不包含表名 - 会按照第一条包含实体表名的stmtement进行路由,如果整个stmtement都不包含表名,则将请求发送至上一条sql发送的server
- 只解析
- observer会根据执行计划类型,来告诉proxy是否将请求路由至正确的server,如果路由失败,proxy会更新location
- server返回第一条DML的命中情况
obproxy比较推荐的用法
- 以下情况,select可以等价替换成 update/delete/replace/inset,proxy能够将请求发送至正确的server,并且server能够按照proxy的命中情况进行反馈
begin; select * from t1;commit;- 开启事务走leader副本
set @@autocommit=1;insert into t1 values(); set@@autocommit=0;- 事务相关,走leader副本
select * from t1; insert into t2 values;- 第一条不确定走哪个,第二条走leader副本
set @@ob_trx_timeout=1000000;begin;select * from t1;commit- 开启事务,走leader
- 以下情况,proxy会将请求发送至上一个sql使用的server
create table t1(id int primary key); create table t2(id int primary key);
不建议使用的语句
- 以下几种情况(第一个DML是非实体表),proxy能够将请求发送至正确的server,但server反馈的信息不准,不建议使用
select '1'; select 8 from t1;select 1不能定位到具体的serverselect '1' from dual;select 8 from t1;
- 以下情况,proxy可能能够将请求路由至正确的server,但server反馈信息不准,不建议使用
create table t1(id int primary key); insert into t1 values();(如果是分区表)
- 以下集中情况,proxy会强制将请求路由至上一次使用的server,server反馈的信息可能不准,不建议使用
show warnings;select * from t1;show count(\*) errors;select * from t1;
使用和运维
守护进程
- OBproxy 无状态,重启不影响数据一致性,所以obproxy在部署时带一个守护进程,周期性检查obproxy的健康程度,一旦发现宕机就立即重启OBProxy
- 手动启动和检查过程如下:
- 启动守护进程,守护进程会拉起obproxy
obproxyd.sh -c start -e private -n <obproxy名称>- 这里可以动态指定名称,可以理解能起多个
- 检查进程状态 :
ps -ef|grep obproxy|grep '^admin' - 登录验证:
obclient -uroot@sys#[集群名称] -P2883 -h127.0.0.1 -p[密码] -Doceanbase -c
- 启动守护进程,守护进程会拉起obproxy
OBProxy 配置项
- 以系统租户通过OBProxy连接OB集群
- 查看和修改obproxy配置(2883 obproxy,2881 observer)
show proxyconfig;展示proxy内部各项配置项属性以及config server的配置信息alter proxyconfig set key=value更新指定配置项
config server配置只能通过config server来更新- 部分配置需要重启proxy才生效
配置项可以分三种类型
- proxy写入到本地etc文件夹中配置文件的配置项,用户可以根据使用场景更新
- proxy 内部使用,对一般用户不可见的配置项,不会注册到内部表中
- proxy从
config server中获取到的配置信息,只用来展示config server的配置,不会注册到内部表或dump到本地配置文件中,以“json_config”开头
常用配置项
xflush_log_level监控用的xflush的日志级别syslog_levelobproxy自己的应用日志级别observer_query_timeout_delta关系到网络断开连接,到认为observer不可用的delta时间默认20秒log_cleanup_interval清理obproxy自身应用日志的间隔时间log_dir_size_threshold: proxy 日志大小阈值,超过阈值即可进行日志清理internal_cmd_mem_limited: 会话较多,导致buffer内存不足时需要调大
常见问题
启动失败
- 机器是否存在hostname: 输入
hostname -i确认host ip是否存在 - 目录是否存在,权限是否正确:确保当前目录下有读、写、执行的权限
- 端口是否被占用: 使用obproxyd.sh 启动OBProxy,使用的端口为2883
- 启动环境是否指定正确,如果通过obproxyd.sh启动,需要使用-e 参数指定OBProxy运行环境
成功启动,无法建立连接
| 常见问题 | 报错 | 解决思路 |
|---|---|---|
| IP PORT错误 | ERROR 2003 (HY000): Can’t connect to MySQL server on ‘127.1’ (111) | 检查所需建立连接的obproxy, obproxy是否存在 |
| 权限错误 | ERROR 1045 (42000): Access denied for user ‘XXXXXXXXX’ | 直接连接observer确认该信息是否正确 |
| 租户名错误 | ERROR 5160 (HY000): invalid tenant name specified in connection string | 本机mysql版本是否过低,MySQL 5.7.8之前版本, 用户名长度超过16字节会被截断。5.7.8版本之后版本用户长度超过32字节会被截 |
| 认证错误 | ERROR 2013 (HY000): Lost connection to MySQL server at ‘reading authorization packet’, system error: 0 | 本地json配置集群是否和远程json文件一致,该配置文件主要用于确认你需要连接的OB集群是否存在 |
慢查询配置项及其修改方式
obproxy有自己的慢查询日志打印功能,通过一下配置可控制打印到日志中的sql或事务的时间阈值
| 配置项 | 说明 |
|---|---|
| slow_transaction_time_threshold | 指慢查询或事务的整个生命周期的时间阈值,超过了该时间,就会打印相关日志。默认2ms |
| slow_proxy_process_time_threshold | 在发往 Server 前 Proxy 本身的处理时间,包括获取集群信息、路由信息、黑名单信息等。 |
| slow_query_time_threshold | 指从 OBProxy 获取 SQL 直到返回给客户端之前的这段时间的阈值,超过了该时间,也会打印相关日志。 |
操作示例,一般修改配置项slow_transaction_time_threshold即可
alter proxyconfig set slow_transaction_time_threshold = '100ms';
alber proxyconfig set slow proxy_process_time_threshold='5ms'; -- 默认2ms,适用于大多场景
慢查询举例
[2016-05-24 22:39:00.824392] WARN [PROXY.SM] update_cmd_stats (ob_mysql_sm.cpp:4357) [28044][Y0-7F70BE3853F0] [14]
Slow query:
client_ip=127.0.0.1:17403 -- 执行SQL client IP
server_ip=100.81.152.109:45785 -- SQL被路由到的observer
conn_id=2147549270
cs_id=1
sm_id=8
cmd_size_stats=
client_request_bytes:26 -- 客户端请求 SQL大小
server_request_bytes:26 -- 路由到observer SQL大小
server_response_bytes:1998889110 -- observer转发给obproxy数据大小
client_response_bytes:1998889110 -- obproxy转发给client数据大小
cmd_time_stats=
client_transaction_idle_time_us=0 -- 在事务中该条SQL与上一条SQL执行结束之间的间隔时间, 即客户端事务中SQL间隔时间
client_request_read_time_us=0 -- obproxy读取客户端SQL耗时
server_request_write_time_us=0 -- obproxy将客户端SQL转发给observer耗时
client_request_analyze_time_us=15 -- obproxy 解析本条SQL消耗时间
cluster_resource_create_time_us=0 -- 如果执行该条SQL, 需要收集OB cluster相关信息(一般发生在第一次连接到该集群的时候), 建立集群相关信息耗时
pl_lookup_time_us=3158 -- 查询partition location耗时
prepare_send_request_to_server_time_us=3196 -- 从obproxy接受到客户端请求,到转发到observer执行前总计时间,正常应该是前面所有时间之和
server_process_request_time_us=955 -- observer处理请求的时间,对于流式请求就是从observer处理数据,到第一次转发数据的时间
server_response_read_time_us=26067801 -- observer转发数据到obproxy耗时,对于流式请求observer是一边处理请求,一边转发数据(包含网络上的等待时间)
client_response_write_time_us=716825 -- obproxy将数据写到客户端耗时
request_total_time_us=26788969 -- 处理该请求总时间
sql=select * from sbtest1 -- 请求SQL
SQL相关timeout设置
默认设置
-
查询超时:
ob_query_timeout默认10sset @@ob_query_timeout = 200*1000*1000
-
事务未提交超时:
ob_trx_timeout默认100sset @@ob_trx_timeout = 200*1000*1000
-
事务空闲超时:
ob_trx_idle_timeout默认120s
-- 示例
create table test (id int);
-- 设置查询超时时间为200秒
set @@ob_query_timeout = 200*1000*1000
-- 设置事务超时时间为200秒
set @@ob_trx_timeout = 200*1000*1000
begin;-- 开启事务
insert into test values(1);
-- 间隔200秒
insert into test values(2);
select * from test; -- 结果为空,说明事务已回滚
rollback;
常见超时原因:
- 连接闲置时间超时,通过
ping 保持链接 - 客户单sql执行耗时长 ,通过调优sql或调整timeout 的值来解决;
小结
- obproxy 是ob高性能且易于运维的反向代理服务器,具有防连接闪断、observer宕机或升级不影响客户端正常请求,兼容所有mysql客户端,支持热升级和多集群功能
- proxy核心功能包括:路由、连接管理、运维&监控
- proxy 的部署方式可以分为集中部署和客户端部署
- proxy可以通过RSList启动,也可以通过config_url启动,前者只能管理特定的ob集群,后者可以管理多个集群
- proxy弱一致性读策略可以分为主备均衡的路由策略(默认),备优先读策略、读写分离策略
- proxy 慢查询日志除了sql本身执行的时间,还包括发送和接收数据消耗的网络延时
第七章、OB迁移(OMS)、备份与恢复
OB迁移服务
OB迁移服务OMS
OMS: Oceanbase Migration service 是OB提供的一种支持同构或异构RDBMS与OB之间进行数据交互的服务,具备在线迁移存量数据和实时同步增量数据的能力。
- 支持多种数据源
- 支持MySQL/kafka等多种类型的数据终端与OB进行实时数据传输
- 在线迁移无感知:双向同步,不停服
- 安全可靠高性能:实时复制异构的IT基础结构之间大量数据的毫秒级延迟,可用于数据迁移、跨城异地数据灾备,应急系统、实时数据同步、容灾、数据库升级和迁移等多场景
- 实时同步助解耦:支持OB两种租户与自建kafka、rocketmq之间的额数据实时同步,可用于实时数仓搭建,数据查询和报表分流等业务场景
架构概览
- OMS 作为中间层,连接源数据库和目标数据库;
OMS分层功能体系
- 服务接入层
- 主要包括客户端迁移服务的交互、各种类型数据源的管理、迁移任务的录入、oms各个组件模块的运维和监控、以及告警设置等;
- 流程编排层
- 主要负责实现上层表结构同步、启动全量数据同步、增量数据同步,数据校验和数据订正,以及链路切换等任务的执行细节;
- 组件链路层:包括以下模块
- 负责全量数据的迁移和校验、并整堆校验不一致的数据生成订正sql脚本的light-dataflow模块
- 负责数据库增量日志的读取,解析和存储的store模块
- 负责想目标端数据库并发写入的JDBCWrite模块
- 负责想目标的消息队列增量写入的Connector模块
- 负责组建状态监控的Supervisor模块

OMS功能
数据迁移
- 迁移任务
- 迁移任务是OMS数据迁移功能的基本单元。OMS在创建迁移任务时,可以指定的最大迁移范围是数据库级别,最小迁移范围是表级别。迁移任务的生命周期包括结构迁移、全量数据迁移、增量迁移同步链路的全部流程管理
- 迁移类型
- oms支持schema结构迁移,全量数据迁移及增量数据迁移,同时支持数据校验功能
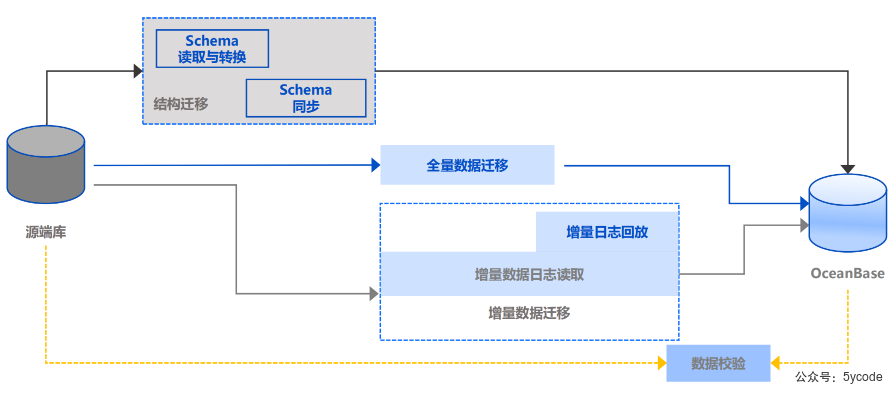
利用OMS实现平滑去O迁移方案
数据实时同步+快速切换+回滚预案
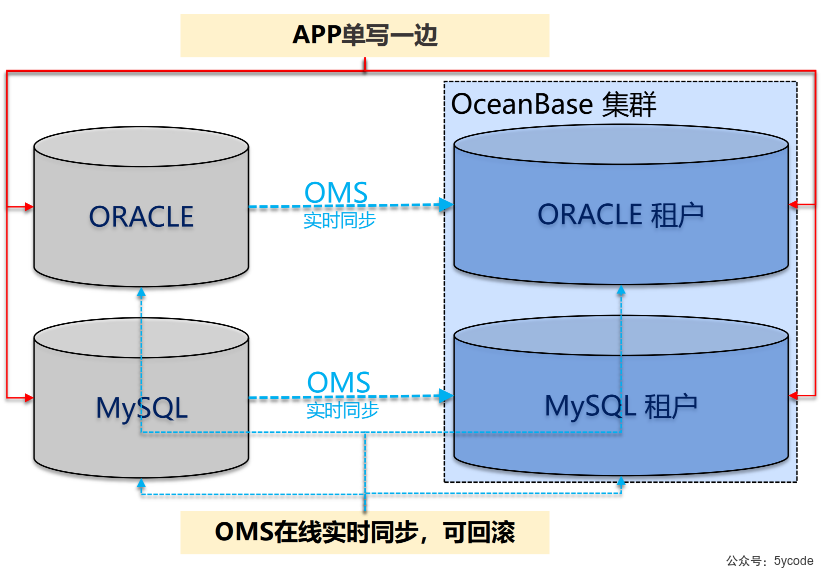
1, 应用读写Oracle/MySQL
2, OMS实时同步:Oracle/MySQL ->OB
3,应用停写Oracle/MySQL (暂停业务几分钟,或者开启异步写)
4,OMS全量校验: OB vs Oracle/MySQL (时效性)
5,OMS实时同步: OB -> Oracle/MySQL (校验完成后,切换同步路径)
6,应用切换读写OB
-- 回滚预案
1, 应用停写OB (业务暂停,或者开启异步写)
2,OMS 全量校验:Oracle/MySQL vs OB
3,OMS 实时同步:Oracle/MySQL -> OB
应用切换读写Oracle/MySQL
数据同步
OMS可以作为数据同步工具使用,不依赖于OB,OMS提供的多种实时数据同步功能广泛应用于实时数据仓库搭建、数据查询和报表分流等业务。
- 支持OB两种租户(Oracle/MySQL)与自建Kafka、RocketMQ自建的实时数据同步
- 支持Sybase ASE和自建RocketMQ之间的实时数据同步
- 支持OB_MYSQL/Oracle/MySQL 和datahub之间的实时数据同步
- 支持库、表和列三级对象名映射,
- 同步对象的选择粒度为表、列,可以根据需要选择的同步的对象,可以实现对源端实例和目标实例的库名、表名或列名不同的两个对象之间进行数据同步
- 支持消息队列处理工具作为数据同步的目标端
- 支持数据过滤
- 支持根据DML类型过滤投递消息,过滤需要同步的数据
- 完善的性能查询体系
- 数据同步提供同步延迟、当前同步位点等数据,便于查看同步链路的性能
- 动态管理数据同步任务
- 支持在数据同步过程中动态增加同步数据表,并支持回拉位点重新投递增量数据
OMS功能总结
- 数据库不停服迁移
- 传统数据库停机迁移的方式对业务影响较大;
- OMS不停服数据数据迁移功能不影响迁移过程中源数据库对外提供服务,将数据迁移对业务的影响降到最小;
- 完成迁移后,源库的数据都实时同步到目标库中以后,通过校验,业务可以切换;
- 实时数据同步
- 支持实时同步OB、Sybase等数据库增量数据到自建的kafka、rocketMq等消息队列;
- oms支持OB物理表和自建的kafka等数据源自建的数据实时同步,可以用于BI、实时数仓、数据查询和报表分流等业务;
备份恢复技术架构及操作方法
为什么要备份?
- 满足监管要求
- 防止管理员误操作后,错误数据同步所有副本,导致数据无法恢复
- 防止数据库因各种故障而造成数据丢失,降低灾难性能数据丢失的风险,从而达到灾难恢复的目的,比如:
- 硬盘驱动器损坏
- 黑客攻击、病毒
- 自然灾害、电源浪涌、磁干扰
物理备份/恢复方案的系统架构
- OB支持:OSS/NFS/COS三种备份介质,文档上是OSS/NFS
- OB从V2.2.52版本开始支持集群级别的物理备份
- 物理备份由基线数据、日志归档数据两种数据组成
- 日志归档是指日志数据的自动归档功能,observer会定期将日志数据归档到指定的备份路径,全自动
- 数据备份指的是备份基线数据的功能,全量备份和增量备份两种
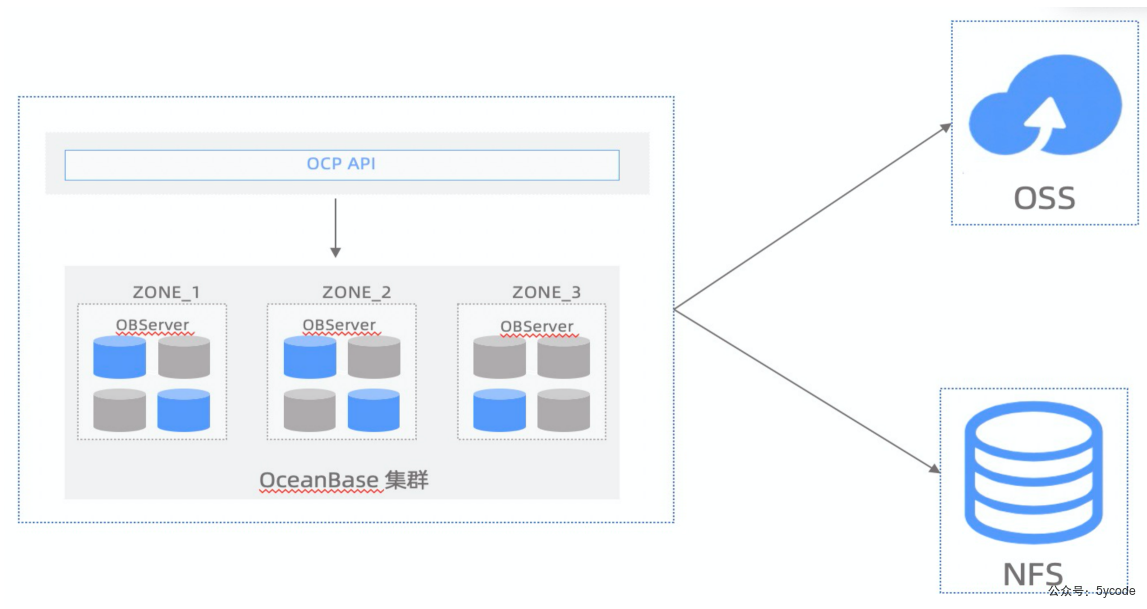
/**
备份服务由Root Service发起调度
将备份请求发动到各observer上,
备份线程将所有基线数据的宏块备份到目的地
*/
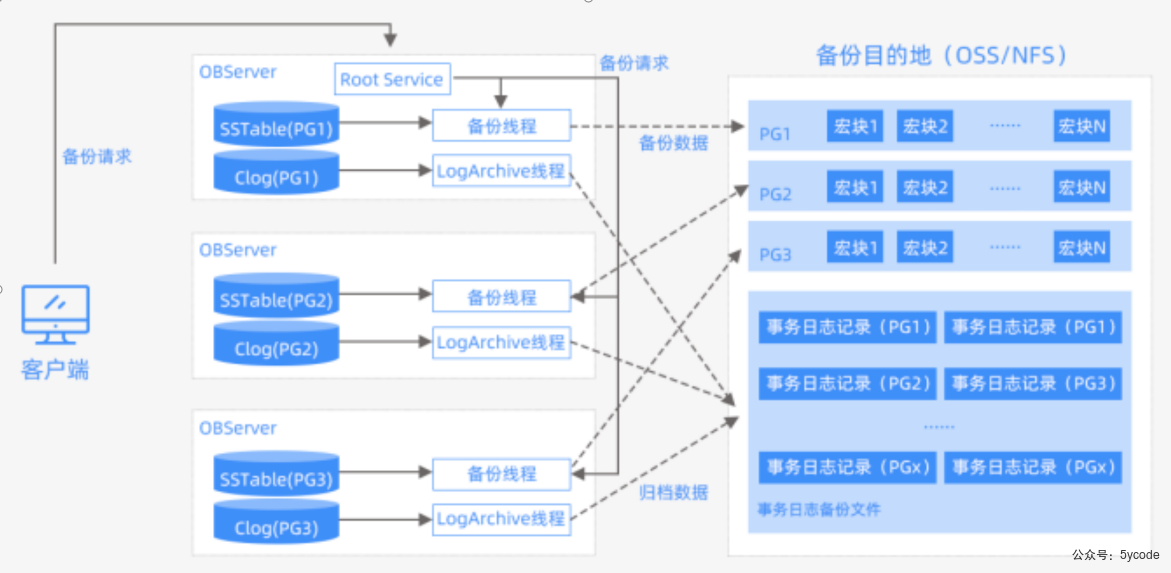
备份恢复数据
- 支持基线数据和增量数据备份
- 基线数据:最后一次合并落盘的数据之和
- 增量数据:是当前合并时间点以后得所有更新数据,一般会存储转发MemTable的内存表中,同时也会实例化commit log文件的形式存放在硬盘上;
- 支持数据库上的任何操作
- OB的备份 恢复支持数据库上的任何操作
- 包括用户权限、表定义、租户定义、系统变量、用户信息、视图等逻辑数据以及所有的物理数据
- 支持集群级和租户级备份
- OB 的备份恢复目前支持的最小粒度是租户
- 可以按需只备份某个租户,从而增加了备份的灵活性,节省了空间
物理备份介绍
- 数据备份支持的是备份基线数据的功能,分为全量和增量备份两种
- 全量备份是备份所有的基线的宏块;
- 增量备份是指上一次备份以后新增和修改过后的宏块;
- 日志归档是定期备份到备份目的端的,只需要用户发起一次
alter system archivelog日志备份就会在后台持续进行(必须触发执行)
物理备份操作方法
-
部署NFS,所有的observer需要连接到NFS服务器,或采取OSS服务器,
-
执行备份
2.1 配置备份目的地,执行alter system语句配置
alter system set backup_dest = 'file://data/nfs/backup'; alter system set backup_dest = 'oss://xxxxxx';2.2 启动ob的数据日志归档功能
alert system archivelogs;2.3 执行全量备份或增量备份
- 先合并一次
- 可以对备份数据设置密码
- 增量备份的前提是已经全量备份过了
alter system major freeze; -- 执行全量备份前,对集群进行一次合并 set encryption on identified by 'password' only; -- 设置备份密码(可选) alter system backup database; -- 执行全量备份 alter system backup incremental database; -- 执行增量备份,(必须已经全量备份过) -
查看任务状态
select * from cdb_ob_backup_progress; -- 查看备份任务 select * from cdb_ob_backup_set_details; -- 查看备份任务历史
物理恢复介绍
- 在目标集群上建立恢复租户需要的unit与资源池
- 通过 alter system restore teanant 命令调度租户恢复任务,内部流程如下:(先系统后用户)
- 创建恢复用的租户
- 恢复租户的系统表数据
- 恢复租户的系统表日志
- 调整恢复租户的元信息
- 恢复租户的用户表数据
- 恢复租户的额用户表这日子
- 恢复扫尾工作
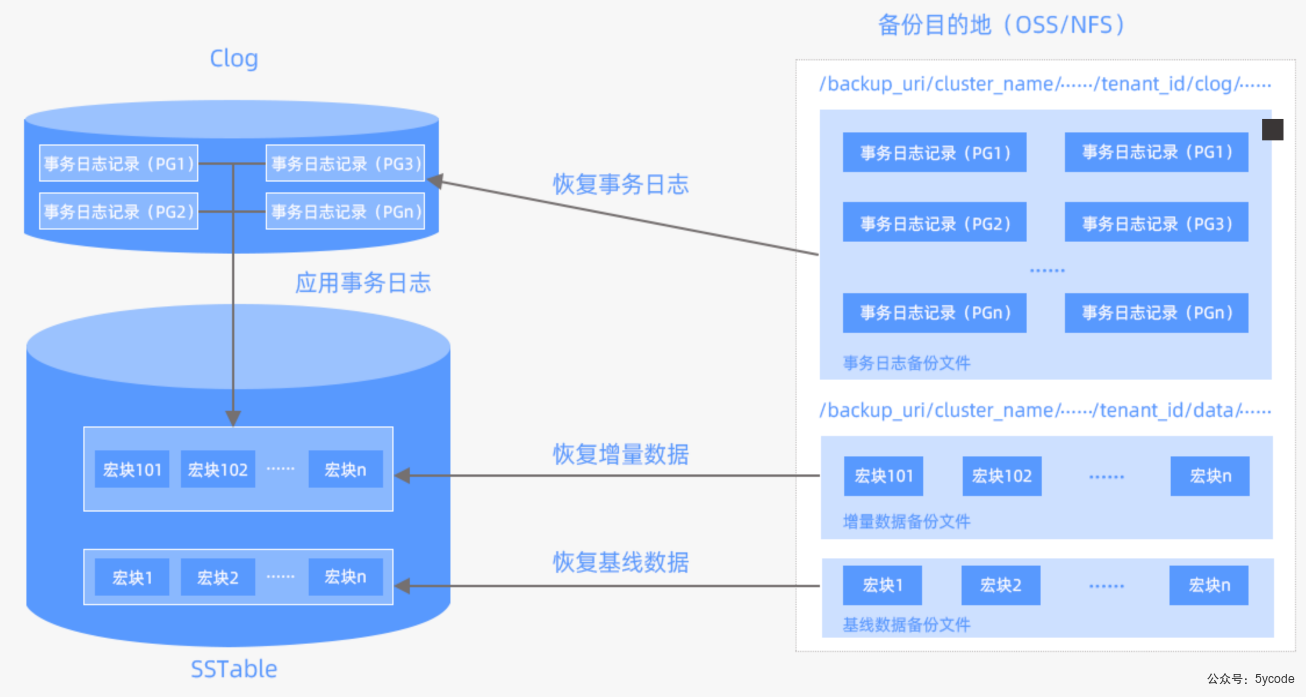
物理恢复操作方法(黑屏)
-
停止日志备份:
alter system noarchivelog -
执行恢复
2.1 创建要恢复目标租户需要的unit、resource pool
create resource unit 各种规则; create resource pool xxx;2.2 设置加密信息、以及恢复密码(如果未加密,或者恢复时可以访问原来的kms,跳过本步骤);恢复密码是备份时添加的密码
set @kms_encrypy_info = '加密string' -- SET DECRYPTION IDENTIFIED BY 'password1','password2'; <----备份时设置的“全量备份”,“增量备份”的密码,未设置可跳过次步骤2.3 打开恢复配置执行恢复任务
-- 设置恢复线程,需要根据cpu设置 alter system set restore_concurrency = 50 -- 检查 restore_concurrency 是否为0,为0 的话需要执行这条语句 alter system resore 目标租户名 from 源租户名 at 'uri' UNTIL 'timestamp' WITH 'restore_option’; -
查看任务状态
SELECT svr_ip,role, is_restore, COUNT(*) FROM __all_virtual_meta_table AS a, (SELECT value FROM __all_restore_info WHERE name='tenant_id') AS b WHERE a.tenant_id=b.value GROUP BY role, is_restore, svr_ip ORDER BY svr_ip, is_restore; SELECT * FROM __all_restore_info;
小结
- ob提供迁移服务、支持同构或异构RDBMS与OB之间进行数据交互的服务
- OMS的功能体系可以分为服务接入层、流程编排层、组件链路层
- oms主要应用场景包括数据不停服迁移和数据实时同步
- ob数据库支持oss和nfs两种备份介质
- ob支持基线数据和增量数据备份,支持数据库上的任何操作的备份,支持集群级备份和租户级备份
- ob物理备份恢复需要再目的集群上建立恢复租户需要的unit和resource pool
第八章、OB 运维、监控与异常处理
用户权限管理
黑屏操作
用户管理
- 用户管理包括:创建用户、删除用户、修改密码、修改用户名、锁定用户、用户授权和撤销授权等;
- 用户分为两类:系统租户下的用户,一般租户下的用户;
- 创建用户时
- 当前会话为系统租户,创建的用户是系统租户
- 一般租户用户,创建的是一般租户的用户
| 用户操作 | MySQL****模式 | Oracle****模式 |
|---|---|---|
| 创建用户 | CREATE USER [IF NOT EXISTS] user_name [IDENTIFIED BY ‘password’]; | CREATE USER user_name IDENTIFIED BY password [PROFILE user_profile] [DEFAULT TABLESPACE table_space]; |
| 删除用户 | DROP USER user_name; | DROP USER user_name cascade; |
| 修改用户密码 | ALTER USER user_name IDENTIFIED BY ‘password’; | ALTER USER user_name IDENTIFIED BY ‘password’; |
| 锁定和解锁用户 | ALTER USER user_name ACCOUNT {LOCK | UNLOCK}; | ALTER USER user_name ACCOUNT {LOCK | UNLOCK}; |
权限与权限等级管理
-
MySQL模式的权限主要有以下三类:
-
用户级权限:用户级权限是全局的权限,不是针对某个指定的数据库;
grant process,select on *.* to user_name; -- 授权所有权限 -
数据库级权限:数据库级权限适用于数据库及其中的所有对象
grant select on db_name.* to user_name; -- 授予指定库select权限 -
对象权限:数据库指定类型的对象,可以是指定库、指定类型、或全局所有数据库对象的权限;
grant select on db_name.table_name to user_name -- 指定库,指定表对象的select权限
-
-
Oracle模式的权限主要有以下两类:
-
系统权限:允许用户在数据库执行标准的管理员任务,如果需要对Schema对象执行操作,就必须对其授予适当的系统权限
grant select any table to user_name; -
对象权限:允许用户对指定对象执行特定的操作;
grant select on db_name.table_name to user_name;
-
白屏 OCP
用户管理
ocp用户有几个关键概念:
- 角色:角色是一组权限的集合,是权限的载体
- 用户:每个用户都必须扮演一个或多个角色,具备这些橘色说包含的权限;
只是讲了ocp的用户操作,没有讲怎么通过ocp进行对用户的添加删除
OCP中,进入租户的用户管理,在用户管理里可以操作用户。
日志查询
日志概述
除了observer.log、election.log、rootservice.log
还有对应warning以上级别的日志,后缀为.wf的日志文件
| 日志名称 | 日志路径 | 说明 |
|---|---|---|
| 启动和运行日志(observer.log)还有wf后缀 | OBServer 服务器的 ~/appname/log 目录下 | OceanBase 数据库所有的启动过程和启动后的运行过程中的日志 |
| 选举模块日志(election.log) | OBServer 服务器的 ~/appname/log 目录下 | 选举模块记录的日志 |
| RootService日志(rootservice.log) | OBServer 服务器的 ~/appname/log 目录下 | RootService 模块记录的日志 |
事务/存储日志
clog commit log 记录提事务相关的日志,不止commit log,乱序
ilog index log 是clog的分区索引文件,单分区有序
slog storage log sstable的操作日志信息
| 日志名称 | 日志路径 | 说明 |
|---|---|---|
| Clog | OBServer服务器的 “~/datadir/clog”目录下 | Commit Log,所有 Partition 共用,日志可能是乱序的,记录事务、Partition Service 提供的原始日志内容。此目录下的日志基于 Paxos 协议在多个副本之间同步(该Clog指代广义的 Commit Log,代表整个事务的所有日志信息) |
| Ilog | OBServer服务器的 “~/datadir/ilog”目 录下 | Index Log,所有 Partition 共用,单 Partition 内部日志有序,记录 Partition 内部log_id->clog(file_id, offset) 的索引信息;每个副本自行记录 |
| Slog | OBServer服务器的 “~/datadir/slog”目 录下 | 记录 Storage Log,指 SSTable 操作日志信息 |
事务日志
事务日志包括:redo log,prepare log,commit log,abort log,clear log等;
- redo log 记录了事务的具体操作,比如某一行数据的某个字段从A修改为B;
- Prepare log 记录了事务的prepare 状态
- commit log 表示这个事务成功commit,并记录commit信息,比如事务的全局版本号;
- clear log 用于通知事务清理事务上下文;
- Abort log 表示这个事务被回滚;
observer 日志级别
需要注意的是:
user_err -> 用户输入导致的错误
| 日志级别 | 含义 |
|---|---|
| ERROR | 严重错误。用于记录系统的故障信息,且必须进行故障排除,否则系统不可用 |
| USER_ERR | 用户输入导致的错误 |
| WARN | 警告。用于记录可能会出现的潜在错误 |
| INFO(default) | 提示。用于记录系统运行的当前状态,该信息为正常信息 |
| TRACE | 与 INFO 相比更细致化地记录事件消息 |
| DEBUG | 调试信息。用于调试时更详细地了解系统运行状态,包括当前调用的函数名、参数、变量、函数调用返回值等 |
observer 日志格式
主要组成:记录时间、日志级别、[模块名]、文件名:行号、线程ID和日志内容
[time] log_level [module_name] function_name (file_name:file_no) [thread_id][Ytrace_id0-trace_id1] [log=last_log_print_time]log_data
| 参数 | 说明 |
|---|---|
| module_name | 打印该条日志的语句所在模块 |
| function_name | 打印该条日志的语句所在的函数 |
| file_no | 打印该条日志的语句所在文件的具体行数 |
| thread_id | 打印该条日志的线程的线程号 |
| trace_id0-trace_id1 | 该条日志的 traceid,由 traceid0 和 traceid1 组成,该 traceid 可通过 RPC 在各个 OBServer 间传递,从而可以根据 traceid 号来获取相互之间有关联关系的日志数据 |
| last_log_print_time | 写上一条日志所用的数据,单位为 us |
| log_data | 具体的日志数据 |
observer 日志注意事项
- 日志写满256MB时,会做日志文件切换,原日志文件名加上
.%Y%m%d%H%M%S格式的时间 - OB默认不会自动清理日志,OB可按日志个数回收日志,通过
enable_syslog_recycle和 max_syslog_file_count两个参数控制; - 日志限流控制参数
syslog_io_bandwidth_limit - Warning 及以上信息生成单独日志文件控制参数:
enable_syslog_wf,开启后每类文件自动生成一个带有.wf后缀的warning日志文件(observer.log.wf、election.log.wf、rootservice.log.wf)
| 参数 | 说明 | 默认值 |
|---|---|---|
| enable_syslog_recycle | 是否开启回收系统日志的功能 | False |
| max_syslog_file_count | 设置在回收日志文件之前可以容纳的日志文件数量 | 0(无限制) |
| syslog_io_bandwidth_limit | 设置系统日志所能占用的磁盘 IO 带宽上限,超过带宽上限容量的系统日志将被丢弃 | 30MB |
| enable_syslog_wf | 设置是否把 WARN 以上级别的系统日志打印到一个单独的日志文件中 | True |
Observer 错误码
- ob高度兼容MySQL,不仅功能和协议,对MySQL原生错误也兼容,在MySQL租户中并和MySQL保持一致
- 在Oracle中,错误信息会以前缀+数字码的形式返回。数据库错误以ORA开头返回,存储过程错误以PLS开头返回
| 模式 | 错误格式 | 说明 |
|---|---|---|
| MySQL模式 | ERROR <err_num> (<sql_stat>) : err_msg | err_num表示错误码,sql_stat表示SQL STATE,err_msg表示错误信息 |
| Oracle模式 | ORA-<err_num>:<err_msg> | err_num表示兼容Oracle数据库的错误码,err_msg表示错误信息 |
observer MySQL错误信息范围
| 错误码范围 | 说明 |
|---|---|
| 0001 ~ 3999 | 兼容MySQL的错误信息有关MySQL服务端及客户端错误码请参见: https://dev.mysql.com/doc/mysql-errors/8.0/en/server-error-reference.html https://dev.mysql.com/doc/mysql-errors/8.0/en/client-error-reference.html |
| 4000 ~ 4499 | 通用错误码 |
| 4500 ~ 4999 | RootService 错误码 |
| 5000 ~ 5999 | SQL、WITH 子句及 Factoring 错误码 |
| 6000 ~ 6999 | 事务、MVCC 与 clog 错误码 |
| 7000 ~ 7999 | 选举模块错误码 |
| 8000 ~ 8999 | 致命错误。当客户端收到该范围内的错误时,需要关闭 SQL 连接 |
| 9000 ~ 9499 | 备份恢复及 STORAGE 3.0 错误码 |
日常运维操作
白屏OCp操作
常用运维操作
| 运维场景 | 步骤 |
|---|---|
| 时钟同步 | OceanBase从Partition的多个副本中选出主对外提供服务。为避免Paxos的活锁问题,OceanBase采用一种基于时钟的选举算法选主 检查 NTP 状态:运行 ntpstat 检查 NTP 服务器状态。如果结果为 synchronised to NTP server,则可以认定 NTP 的配置处于同步状态检查 NTP 的偏移量:多次执行 `ntpq -p |
| 内存不足 | OB是准内存数据库,任何写操作都需要消耗内存资源,只有合并和转储操作能够释放内存资源,所以当合并和转储速度长时间低于内存消耗速度时,内存最终将被耗尽,服务能力跌零 调大租户内存 转储 / 合并 |
| 外存(磁盘)不足 | 运行日志盘满:可清空较老的日志 clog盘满:查询表 __all_virtual_server_clog_stat,清除较老的日志,再合并数据文件满:扩容,或将较老的数据迁移到历史库,再合并 |
黑屏运维
集群运维管理
在集群中启动或停止zone的操作,通常用于允许或禁止zone内的所有物理服务器对外提供服务的需求场景
-
启动或停止zone
alter system {start|stop|force stop} zone [zone_name] -- 启动zone alter system start zone zone1; -- 停止zone alter system stop zone zone1; -
修改zone信息
alter system {alter|change|modify} zone [zone_name] set [zone_option_list]; zone_option_list: region,idc,zone_type(readonly,readwrite) -
查看zone的状态
select * from __all_zone;
observer 运维管理
-
查看observer的信息;
select * from __all_server; select * from __all_server_event_history limit 100; -- server 的系统事件,包括转储、表操作等 -- 查询转储情况 select * from __all_server_event_history where module IN ('freeze', 'minor_merge') ORDER BY gmt_create DESC limit 100; +----------------------------+---------------+----------+--------+-------------------------+-----------+--------+-------+--------+-------+--------+-------+--------+-------+--------+-------+--------+------------+ | gmt_create | svr_ip | svr_port | module | event | name1 | value1 | name2 | value2 | name3 | value3 | name4 | value4 | name5 | value5 | name6 | value6 | extra_info | +----------------------------+---------------+----------+--------+-------------------------+-----------+--------+-------+--------+-------+--------+-------+--------+-------+--------+-------+--------+------------+ | 2024-07-03 02:00:03.043679 | 192.168.80.13 | 2882 | freeze | do minor freeze success | tenant_id | 0 | | NULL | | | | | | | | | | | 2024-07-03 02:00:02.924622 | 192.168.80.15 | 2882 | freeze | do minor freeze success | tenant_id | 0 | | NULL | | | | | | | | | | | 2024-07-03 02:00:02.848593 | 192.168.80.10 | 2882 | freeze | do minor freeze success | tenant_id | 0 | | NULL | | | | | | | | | | | 2024-07-03 02:00:02.069874 | 192.168.80.13 | 2882 | freeze | do minor freeze | tenant_id | 0 | | NULL | | | | | | | | | | | 2024-07-03 02:00:02.069482 | 192.168.80.15 | 2882 | freeze | do minor freeze | tenant_id | 0 | | NULL | | | | | | | | | | | 2024-07-03 02:00:02.069330 | 192.168.80.10 | 2882 | freeze | do minor freeze | tenant_id | 0 | | NULL | | | | | | | | | | | 2024-07-02 19:33:21.284922 | 192.168.80.13 | 2882 | freeze | do minor freeze success | tenant_id | 1001 | | NULL | | | | | | | | | | | 2024-07-02 19:33:21.167959 | 192.168.80.13 | 2882 | freeze | do minor freeze | tenant_id | 1001 | | NULL | | | | | | | | | | | 2024-07-02 19:30:23.712914 | 192.168.80.15 | 2882 | freeze | do minor freeze success | tenant_id | 1001 | | NULL | | | | | | | | | | | 2024-07-02 19:30:23.609304 | 192.168.80.15 | 2882 | freeze | do minor freeze | tenant_id | 1001 | | NULL | | | | | | | | | | | 2024-07-02 18:16:52.198031 | 192.168.80.10 | 2882 | freeze | do minor freeze success | tenant_id | 1001 | | NULL | | | | | | | | | | | 2024-07-02 18:16:52.107622 | 192.168.80.10 | 2882 | freeze | do minor freeze | tenant_id | 1001 | | NULL | | | | | | | | | | -
管理observer的状态:
-
Start server 操作
alter system start server 'ip:port' [,'ip:port'...] [zone='zone_name'] alter system start server '192.168.100.1:2282'; -
Stop server 操作
alter system stop server 'ip:port' [,'ip:port'...] [zone='zone_name'] alter system stop server '192.168.100.1:2282' zone = 'z1';
-
stopped并非等价于进程退出,进程可能仍然在运行,仅仅是集群认为该节点为stopped状态。系统会把流量切走
observer 服务管理(进程)
管理observer服务,需要登录ob server所在的宿主机
-
查看observer进程:
ps -ef|grep observer -
启动observer进程:
# 进入ob的目录 cd /home/admin/oceanbase/ ./bin/observer [启动参数] ./bin/observer --help 查看observer参数的详细信息 -
停止observer进程:
kill -15 `pgrep observer` kill -9 `pgrep observer`
observer 服务启动恢复
由于增删改数据在内存中,进程启动后
- 需要与其他的副本同步,将clog或者ssd 基线数据进行同步(补齐)
- 需要将上一次合并之后的内存数据恢复出来(clog回放),才能提供服务;
注意事项:
- 停机时间短(分钟或小时级),一般只追齐clog
- 停机时间戳(天级别),clog落后太多,会直接追齐ssd基线数据,然后补齐合并版本后的clog
- 查询
__all_server表的start service time字段来判断observer是否对外提供服务 - 可以在停止observer服务前执行转储
alter system minor freeze;以加快observer服务恢复过程;- 合并会影响集群性能,转储落地
服务停止(停机运维)☆
需要注意的是:stop observer只是集群认为节点不存在,进程还在,停服,是需要重启机器的;
-
根据运维时长,设置永久下线时间,向上取大值;
alter system set server_permanent_offline_time='86400s'; -
将服务从当前observer切走,保证停服时,对于业务没有影响;
alter system stop server '192.168.80.15:2882'; -
检查副本全部切走
select count(*) from __all_virtual_table t,__all_virtual_meta_table m where t.table_id=m.table_id and role=1 and m.svr_ip='ip地址'select m.svr_ip,count(*) from __all_virtual_table t,__all_virtual_meta_table m where t.table_id=m.table_id and role=1 group by m.svr_ip; +---------------+----------+ | svr_ip | count(*) | +---------------+----------+ | 192.168.80.10 | 268 | | 192.168.80.13 | 2369 | +---------------+----------+ -
停止进程
kill -15 observer pid
select zone,with_rootserver,status,stop_time,start_service_time from __all_server;
+-------+-----------------+--------+------------------+--------------------+
| zone | with_rootserver | status | stop_time | start_service_time |
+-------+-----------------+--------+------------------+--------------------+
| zone1 | 1 | active | 0 | 1684836691733547 |
| zone2 | 0 | active | 0 | 1684836681083988 |
| zone3 | 0 | active | 1686908454628137 | 1684836680796171 |
+-------+-----------------+--------+------------------+--------------------+
3 rows in set (0.003 sec)
服务恢复
运维操作完机器以后,需要恢复ob服务进程;
-
机器上电;
-
检查该机器的ntp同步状态和服务运行情况;
-
admin用户启动observer进程;
-
系统租户登录,启动server
alter system start server '192.168.80.15:2882'; -
检查
__all_server表select zone,with_rootserver,status,stop_time,start_service_time from __all_server; +-------+-----------------+--------+-----------+--------------------+ | zone | with_rootserver | status | stop_time | start_service_time | +-------+-----------------+--------+-----------+--------------------+ | zone1 | 1 | active | 0 | 1684836691733547 | | zone2 | 0 | active | 0 | 1684836681083988 | | zone3 | 0 | active | 0 | 1684836680796171 | +-------+-----------------+--------+-----------+--------------------+ -
改回永久下线时间,默认下线时间是3600秒
alter system set server_permanent_offline_time='3600s';
故障节点替换
需要确保集群中有足够的冗余observer,可以代替故障节点进行工作;
-
系统租户登录,stop server,确保主副本都切走;
-
为目标zone添加新的server
alter system add server 'ip:2882' zone 'zone1'; -
将故障server下线,下线以后ob会自动将被下线的observer的unit迁移至新添加的observer上;
alter system delete server 'ip:2882' zone 'zone1' -
检查
__all_server表中的server状态,旧observer的信息已经消失;
数据库监控
系统监控视图:系统视图
OB数据库系统表都存储在sys租户,主键中存储租户号,区分每个租户的内容。每个租户内部创建一个该租户数据的只读视图
- 所有
__all开头的表格包含所有租户的数据 - 所有以
__tenant开头的表格仅包含单个租户内部的数据
| 租户类型 | 包含系统表类别 |
|---|---|
| SYS租户 | 核心表 分表位置信息表 模式及用户权限表 DDL 操作相关的表 系统配置相关的表 系统变量及系统状态相关的表 Zone 和服务器等部署相关的系统表 租户、Resource Pool、Unit 相关的系统表 |
| 普通租户 | 以 __tenant 作为表名前缀的只读视图,表示租户内信息 其它系统表的视图 |
状态查询sql
- 查看zone状态:
select * from __all_zone;is_merge_error对应的value是否是0- status是否全为active
- 查看observer状态:
select * from __all_server;- ob通过status、stop_time来标识observer的状态
- stop_time为0,标识observer为started状态,不为0时,表示observer处于stopped状态
- status为active时,表示observer处于正常状态,为inactive时,表示observer处于下线状态,为deleting时表示observer正在被删除
磁盘空间查询sql
-
查询OB集群中,各OBServer的磁盘容量和已使用量
- 单位为字节
select total_size/1024/1024/1024,used_size/1024/1024/1024,free_size/1024/1024/1024, svr_ip from __all_virtual_disk_stat; +---------------------------+--------------------------+--------------------------+---------------+ | total_size/1024/1024/1024 | used_size/1024/1024/1024 | free_size/1024/1024/1024 | svr_ip | +---------------------------+--------------------------+--------------------------+---------------+ | 320.000000000000 | 3.894531250000 | 316.105468750000 | 192.168.80.10 | | 320.000000000000 | 3.992187500000 | 316.007812500000 | 192.168.80.13 | | 320.000000000000 | 3.824218750000 | 316.175781250000 | 192.168.80.15 | +---------------------------+--------------------------+--------------------------+---------------+ -
按租户、表统计磁盘空间使用;
- 如果租户某unit磁盘空间占用过大,考虑增加租户unit;
- 如果单表磁盘空间占用过大(>200G),考虑分区;
- 该查询只包含sstable磁盘,不含memTable内存中数据;
select tenant_id, svr_ip, unit_id, table_id, sum(data_size) /1024/1024/1024 size_G from __all_virtual_meta_table group by 1, 2, 3, 4 limit 10; +-----------+---------------+---------+---------------+----------------+ | tenant_id | svr_ip | unit_id | table_id | size_G | +-----------+---------------+---------+---------------+----------------+ | 1 | 192.168.80.10 | 1 | 1099511677777 | 0.000000440515 | | 1 | 192.168.80.13 | 2 | 1099511677777 | 0.000000440515 | | 1 | 192.168.80.15 | 3 | 1099511677777 | 0.000000440515 | | 1 | 192.168.80.10 | 1 | 1099511677778 | 0.000000000000 | | 1 | 192.168.80.13 | 2 | 1099511677778 | 0.000000000000 | | 1 | 192.168.80.15 | 3 | 1099511677778 | 0.000000000000 | | 1 | 192.168.80.10 | 1 | 1099511677782 | 0.000000000000 | | 1 | 192.168.80.13 | 2 | 1099511677782 | 0.000000000000 | | 1 | 192.168.80.15 | 3 | 1099511677782 | 0.000000000000 | | 1 | 192.168.80.10 | 1 | 1099511677784 | 0.000002182088 | +-----------+---------------+---------+---------------+----------------+
历史事件查询SQL
-
__all_rootservice_event_history记录集群级别的历史事件,比如:- 合并
major freeze - server上下线;
- 修改primary_zone 引发的切主操作、负载均衡任务执行等;
- 保留7天内的数据;
select * from __all_rootservice_event_history where event like '%minor%' order by gmt_create desc limit 10\G; *************************** 1. row *************************** gmt_create: 2023-06-16 02:00:01.121762 module: root_service event: root_minor_freeze name1: ret value1: 0 name2: arg value2: {tenant_ids:[], partition_key:{tid:18446744073709551615, partition_id:-1, part_idx:268435455, subpart_idx:268435455}, server_list:[], zone:""} name3: value3: name4: value4: name5: value5: name6: value6: extra_info: rs_svr_ip: 192.168.80.10 rs_svr_port: 2882 - 合并
-
__all_server_event_history记录observer级别的事件,比如- 转储
- 用户发起的系统命令
- 保留7天内的数据
-- 查询超时了,设置超时时间为100秒 obclient [oceanbase]> set @@ob_query_timeout=100*1000*1000; Query OK, 0 rows affected (0.002 sec) select * from __all_server_event_history where svr_ip='192.168.80.10' and module in('freeze','minor_merge') order by gmt_create desc limit 10\G; *************************** 1. row *************************** gmt_create: 2023-06-16 14:26:24.504847 svr_ip: 192.168.80.10 svr_port: 2882 module: freeze event: do minor freeze success name1: tenant_id value1: 1001 name2: value2: NULL name3: value3: name4: value4: name5: value5: name6: value6: extra_info: *************************** 2. row *************************** gmt_create: 2023-06-16 14:26:24.406889 svr_ip: 192.168.80.10 svr_port: 2882 module: freeze event: do minor freeze name1: tenant_id value1: 1001 name2: value2: NULL name3: value3: name4: value4: name5: value5: name6: value6: extra_info:
机器剩余资源查询sql
obclient [oceanbase]> select b.zone, a.svr_ip, a.cpu_total, a.cpu_assigned cpu_ass, a.cpu_assigned_percent cpu_ass_percent,round(a.mem_total/1024/1024/1024, 2) as mem_total, round(a.mem_assigned/1024/1024/1024, 2) mem_ass,round((a.mem_total-a.mem_assigned)/1024/1024/1024, 2) as mem_free,a.mem_assigned_percent mem_ass_percent from __all_virtual_server_stat a,__all_server b where a.svr_ip = b.svr_ip order by zone,cpu_assigned_percent desc;
-- __all_virtual_server_stat 资源占用监控
-- __all_server observer监控
+-------+---------------+-----------+---------+-----------------+-----------+---------+----------+-----------------+
| zone | svr_ip | cpu_total | cpu_ass | cpu_ass_percent | mem_total | mem_ass | mem_free | mem_ass_percent |
+-------+---------------+-----------+---------+-----------------+-----------+---------+----------+-----------------+
| zone1 | 192.168.80.10 | 16 | 7 | 43 | 22.00 | 9.00 | 13.00 | 40 |
| zone2 | 192.168.80.13 | 16 | 6 | 37 | 22.00 | 7.00 | 15.00 | 31 |
| zone3 | 192.168.80.15 | 16 | 5 | 31 | 22.00 | 6.00 | 16.00 | 27 |
+-------+---------------+-----------+---------+-----------------+-----------+---------+----------+-----------------+
- 关键指标
cpu_ass_percent和mem_ass_percentcpu和内存占比较高,再加租户或扩容租户可能会因资源不够失败,可以考虑扩容集群了;
系统性能视图
gv$memory
主要是展示各个租户在所有observer上各模块的内存使用情况,基于__all_virtual_memory_info创建
select * from gv$memory where used>0 limit 10;
+-----------+---------------+------+-----------------+-------+---------+-------------+------------+
| TENANT_ID | IP | PORT | CONTEXT | COUNT | USED | ALLOC_COUNT | FREE_COUNT |
+-----------+---------------+------+-----------------+-------+---------+-------------+------------+
| 1 | 192.168.80.10 | 2882 | CharsetUtil | 256 | 256 | 0 | 0 |
| 1 | 192.168.80.10 | 2882 | ClogGe | 3 | 24576 | 0 | 0 |
| 1 | 192.168.80.10 | 2882 | Election | 3 | 6288384 | 0 | 0 |
| 1 | 192.168.80.10 | 2882 | ElectionGroup | 2 | 4192256 | 0 | 0 |
| 1 | 192.168.80.10 | 2882 | GtsTaskQueue | 1 | 149120 | 0 | 0 |
| 1 | 192.168.80.10 | 2882 | HashBuckPlanCac | 1 | 786512 | 0 | 0 |
| 1 | 192.168.80.10 | 2882 | HashBuckPlanSta | 2 | 1573024 | 0 | 0 |
| 1 | 192.168.80.10 | 2882 | HashNodePlanCac | 15 | 119400 | 0 | 0 |
| 1 | 192.168.80.10 | 2882 | HashNodePlanSta | 22 | 176352 | 0 | 0 |
| 1 | 192.168.80.10 | 2882 | LogEventTask | 3 | 24576 | 0 | 0 |
+-----------+---------------+------+-----------------+-------+---------+-------------+------------+
10 rows in set (0.051 sec)
- CONTEXT 内存所属模块(mod)名称
- count 内存分配与释放的差值,即当前该 Mod 使用中的内存单元个数
- Used 该 Mod 当前使用的内存数值,单位:Byte
- Alloc_count 该 Mod 申请的内存总个数
- free_count 该mood释放的内存总个数;
gv$memstore
记录所有服务器所有租户的memtable的内存使用状态,以__all_virtual_tenant_memstore_info创建
select * from gv$memstore limit 10;
+-----------+---------------+------+-----------+-----------+---------------------+---------------------+------------+
| TENANT_ID | IP | PORT | ACTIVE | TOTAL | FREEZE_TRIGGER | MEM_LIMIT | FREEZE_CNT |
+-----------+---------------+------+-----------+-----------+---------------------+---------------------+------------+
| 1 | 192.168.80.10 | 2882 | 482344960 | 484442112 | 1073741800 | 2147483600 | 0 |
| 500 | 192.168.80.10 | 2882 | 0 | 0 | 2305843009213693950 | 4611686018427387900 | 0 |
| 1001 | 192.168.80.10 | 2882 | 272629760 | 274726912 | 536870900 | 1073741800 | 1 |
| 1002 | 192.168.80.10 | 2882 | 419430400 | 421527552 | 536870900 | 1073741800 | 0 |
| 1013 | 192.168.80.10 | 2882 | 178257920 | 180355072 | 536870900 | 1073741800 | 0 |
| 1 | 192.168.80.13 | 2882 | 455081984 | 457179136 | 1073741800 | 2147483600 | 0 |
| 500 | 192.168.80.13 | 2882 | 0 | 0 | 2305843009213693950 | 4611686018427387900 | 0 |
| 1001 | 192.168.80.13 | 2882 | 203423744 | 205520896 | 536870900 | 1073741800 | 1 |
| 1002 | 192.168.80.13 | 2882 | 171966464 | 174063616 | 536870900 | 1073741800 | 1 |
| 1013 | 192.168.80.13 | 2882 | 161480704 | 163577856 | 536870900 | 1073741800 | 0 |
+-----------+---------------+------+-----------+-----------+---------------------+---------------------+------------+
10 rows in set (0.061 sec)
- active 当前活跃的 MemTable 的内存占用大小,单位为字节。
- total 当前所有 MemTable 的内存占用大小,单位为字节。
- Freeze_trigger 触发 MemTable 冻结的内存大小,单位为字节。
- mem_limit MemTable 的内存大小限制,单位:字节。
- freeze_cnt MemTable 的冻结次数
gv$sql_audit
- 存储所有server上每一次sql请求的来源,执行状态等统计信息,按照租户拆分,(除了系统租户,其他租户不能跨租户查询)
-- 检查特定租户下top 10的sql执行时间
select sql_id, query_sql,count(*), avg(elapsed_time), avg(execute_time), avg(queue_time), avg(user_io_wait_time) from gv$sql_audit where tenant_id=1001 group by sql_id having count(*)>1 order by 5 desc limit 10\G
*************************** 1. row ***************************
sql_id: 1D0BA376E273B9D622641124D8C59264
query_sql: COMMIT
count(*): 2
avg(elapsed_time): 131.0000
avg(execute_time): 52.0000
avg(queue_time): 23.0000
avg(user_io_wait_time): 0.0000
*************************** 2. row ***************************
sql_id: CE24605B761C41943C6BA08A35ADE81F
query_sql: set autocommit = 1
count(*): 2
avg(elapsed_time): 107.0000
avg(execute_time): 27.0000
avg(queue_time): 21.0000
avg(user_io_wait_time): 0.0000
*************************** 3. row ***************************
sql_id: 59CD8AC8C338B5FFC0584EE4BEBB5A0D
query_sql: SET @@autocommit = 0;
count(*): 2
avg(elapsed_time): 92.5000
avg(execute_time): 20.5000
avg(queue_time): 22.5000
avg(user_io_wait_time): 0.0000
3 rows in set (0.041 sec)
-- 检查特定租户下消耗cpu最多的top sql
select sql_id, avg(execute_time) avg_exec_time, count(*) cnt,
-> avg(execute_time-TOTAL_WAIT_TIME_MICRO) cpu_time
-> from gv$sql_audit where tenant_id=1001
-> group by 1 order by avg_exec_time * cnt desc limit 5;
+----------------------------------+---------------+------+-----------+
| sql_id | avg_exec_time | cnt | cpu_time |
+----------------------------------+---------------+------+-----------+
| 96F6ACF4C648E78A9B49634B9EC60359 | 27773.0000 | 2 | 2400.0000 |
| 23F89A4B19B99E0A22B56E3E89E5BBD3 | 32981.0000 | 1 | 4498.0000 |
| 420BD8E0D672A432EA226B6D34DB7119 | 15776.0000 | 1 | 1631.0000 |
| 58A0629A503BE94DCF21D4F7DBB1A03E | 6675.0000 | 1 | 3863.0000 |
| 4AD8B0D222F2DA4196291BBBDB6C3B41 | 1221.2500 | 4 | 728.7500 |
+----------------------------------+---------------+------+-----------+
gv$sql
记录所有热更新的sql的相关统计信息,记录每个plan上的统计信息,汇总单个plan多次执行的统计信息,每个plan都会在表中有一行。
select * from gv$sql limit 10\G;
*************************** 1. row ***************************
CON_ID: 1 -- 租户id
SVR_IP: 192.168.80.10
SVR_PORT: 2882
PLAN_ID: 12641379 -- 执行计划的id
SQL_ID: 5A1C61645F1275647B24D4E894ED0B5F -- sql的标识符
TYPE: 1 -- sql类型,local remote distribute
-- SQL_TEXT sql语句文本
SQL_TEXT: select /*+ MONITOR_AGENT READ_CONSISTENCY(WEAK) */ status, (case when stop_time=? then ? else (time_to_usec(now()) - stop_time)/? end) as stopped_duration_seconds from __all_server where svr_ip = ? and svr_port = ?
PLAN_HASH_VALUE: 1566845618910964684 -- 执行计划的hash值
FIRST_LOAD_TIME: 2024-07-03 02:10:23.131710 -- 第一次执行时间
LAST_ACTIVE_TIME: 2024-07-03 16:05:12.130509 -- 上一次执行时间
AVG_EXE_USEC: 345 -- 平均执行耗时
SLOWEST_EXE_TIME: 2024-07-03 07:56:09.136316 -- 最慢执行开始时间点
SLOWEST_EXE_USEC: 6164 -- 最慢执行消耗时间
SLOW_COUNT: 0 -- 慢查询次数统计
HIT_COUNT: 50089 -- 命中plan cache的统计
PLAN_SIZE: 57040 -- 物理计划占用的内存
EXECUTIONS: 50090 -- 执行次数
DISK_READS: 0 -- 读磁盘次数
DIRECT_WRITES: 0 -- 写磁盘次数
BUFFER_GETS: 100180 -- 逻辑读次数
APPLICATION_WAIT_TIME: 0
CONCURRENCY_WAIT_TIME: 0
USER_IO_WAIT_TIME: 0 -- 所有 IO 类事件等待时间
ROWS_PROCESSED: 50090 -- 所有 Schedule 类事件等待事件
ELAPSED_TIME: 17292724 -- 完成总消耗时间
CPU_TIME: 14955872 -- 消耗的cpu时间
gv$plan_cache_plan_stat
- 记录当前租户在所有server上的计划缓存中缓存的每个缓存对象的状态。
select * from gv$plan_cache_plan_stat limit 1\G
*************************** 1. row ***************************
tenant_id: 1
svr_ip: 192.168.80.10
svr_port: 2882
plan_id: 12641379 -- 缓存对象的 ID
sql_id: 5A1C61645F1275647B24D4E894ED0B5F -- 缓存对象对应的 SQL ID
type: 1 -- 1:表示本地计划 Local Plan 2:表示远程计划 Remote Plan 3:表示分配计划 Distribute Plan
is_bind_sensitive: 0
is_bind_aware: 0
db_id: 1099511627777 -- 数据库 ID
-- statement 参数化sql
statement: select /*+ MONITOR_AGENT READ_CONSISTENCY(WEAK) */ status, (case when stop_time=? then ? else (time_to_usec(now()) - stop_time)/? end) as stopped_duration_seconds from __all_server where svr_ip = ? and svr_port = ?
-- query_sql 第一次加载计划时查询的原始 SQL 语句
query_sql: select /*+ MONITOR_AGENT READ_CONSISTENCY(WEAK) */ status, (case when stop_time=0 then 0 else (time_to_usec(now()) - stop_time)/1000000 end) as stopped_duration_seconds from __all_server where svr_ip = '192.168.80.10' and svr_port = 2882
special_params:
param_infos: {1,0,0,0,5},{1,0,0,0,5},{1,0,0,0,5},{1,0,0,-1,22},{1,0,0,0,5},{1,0,0,0,15},{1,0,0,0,5},{1,0,0,0,15}
sys_vars: 45,4194304,2,4,1,0,0,32,3,1,0,1,1,0,10485760,1,1,0,1,BINARY,BINARY,AL32UTF8,AL32UTF8,BYTE,FALSE,1,100,64,200,0,13,NULL,1,1,1
plan_hash: 1566845618910964684
first_load_time: 2024-07-03 02:10:23.131710
schema_version: 1694432260176200
merged_version: 410
last_active_time: 2024-07-03 16:10:06.130881
avg_exe_usec: 345
slowest_exe_time: 2024-07-03 07:56:09.136316
slowest_exe_usec: 6164
slow_count: 0
hit_count: 50383 -- 被命中次数
plan_size: 57040 -- 缓存对象占用的内存大小
executions: 50384 -- 执行次数
disk_reads: 0 -- 所有执行物理读的次数
direct_writes: 0
buffer_gets: 100768 -- 所有执行逻辑读的次数
application_wait_time: 0
concurrency_wait_time: 0
user_io_wait_time: 0
rows_processed: 50384 -- 所有执行选择的结果行数或执行更改表中的行数
elapsed_time: 17392801 -- 接收到请求到执行结束所消耗的时间。
cpu_time: 15044304 -- 所有执行消耗的 CPU 时间。
large_querys: 0 -- 被判断为大查询的次数
delayed_large_querys: 0 -- 被判断为大查询且被丢入大查询队列的次数
delayed_px_querys: 0 -- 并行查询被丢回队列重试的次数
outline_version: 0
outline_id: -1 -- Outline 的 ID,为 -1 表示不是通过绑定 Outline 生成的计划
outline_data: /*+ BEGIN_OUTLINE_DATA FULL(@"SEL$1" "oceanbase.__all_server"@"SEL$1") READ_CONSISTENCY("WEAK") END_OUTLINE_DATA*/
acs_sel_info:
table_scan: 0 -- 表示该查询是否为主键扫描
evolution: 0
evo_executions: 0
evo_cpu_time: 0
timeout_count: 0 -- 超时次数
ps_stmt_id: -1
sessid: 0
temp_tables:
is_use_jit: 0
object_type: SQL_PLAN
hints_info: READ_CONSISTENCY("WEAK") -- SQL 计划的 Hint 信息
hints_all_worked: 1
pl_schema_id: NULL
is_batched_multi_stmt: 0
gv$plan_cache_plan_explain(物理执行计划)
- 存储缓存在全部server中的计划缓存中的物理执行计划
- 仅支持get操作,查询时需要指定ip、port、tenant_id、plan_id字段
select * from gv$plan_cache_plan_explain where ip='192.168.80.10' and port=2882 and tenant_id=1 and plan_id=12641379\G;
*************************** 1. row ***************************
TENANT_ID: 1
IP: 192.168.80.10
PORT: 2882
PLAN_ID: 12641379
PLAN_DEPTH: 0
PLAN_LINE_ID: 0
OPERATOR: PHY_TABLE_SCAN -- Operator 的名称
NAME: __all_server
ROWS: 1
COST: 52
-- PROPERTY 对应 Operator 的信息
PROPERTY: table_rows:3, physical_range_rows:1, logical_range_rows:1, index_back_rows:0, output_rows:1, est_method:local_storage, avaiable_index_name[__all_server]
ERROR:
No query specified
性能监控
常规监控
- ocp数据趋势里看
捞取慢sql
-
ob中执行时间超过
trace_log_slow_query_watermark(默认值100毫秒)的sql,在observer日志中都会打出slow query消息; -
在observer日志中查找慢sql
-- 查看日志中所有的slow query fgrep '[slow query]' observer.log |sed -e 's/|/\n/g' | more -- 根据trace_id查询某个slow query grep '<trace_id>' observer.log |sed -e 's/|/\n/g' | more -
OB提供了两张虚拟表
v$sql_audit,gv$sql_audit记录最近一段时间sql执行历史; -
v$sql_audit存储本机的sql执行历史,gv$sql_audit存储真个机器的sql执行历史;-- 查询某租户执行时间大于1s(1000000微秒)的sql select * from v$sql_audit where tenant_id =1 and elapsed_time > 1000000 limit 10; -- 查询sql执行时间按秒分布的直方图 select round(elapsed_time/1000000), count(*) from v$sql_audit where tenant_id = 1 group by 1; +-----------------------------+----------+ | round(elapsed_time/1000000) | count(*) | +-----------------------------+----------+ | 0 | 7658 | +-----------------------------+----------+
obproxy 慢sql打印
-- 指慢查询或事务的整个生命周期的时间阈值,超过了该时间,就会打印相关日志,默认5秒
ALTER PROXYCONFIG SET slow_transaction_time_threshold='100ms';
-- 指从 OBProxy 获取 SQL 直到返回给客户端之前的这段时间的阈值,超过了该时间,也会打印相关日志,默认500毫秒
ALTER PROXYCONFIG SET slow_proxy_process_time_threshold='5ms';
修复慢sql
- 创建索引
- outline绑定,可以通过sql_text 创建,也可以通过sql_id 创建
常见异常处理



















 7806
7806

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









