






# 0 简介
今天学长向大家介绍一个机器视觉的毕设项目
毕设分享 目标重识别车辆检测与追踪(源码+论文)
项目获取:
https://gitee.com/assistant-a/project-sharing
跨摄像头车辆检测和跟踪技术的研究与实现
随着计算机视觉技术、通信与半导体技术、网络技术的快速发展,杌器视觉也越米越成熟。硬件和软件的飞速进步,给视频行业也带了巨大变化,视频图像正在走向高清化、网络化、智能化。
目前,中国正处于经济社会的高速发展时期,随着我国城市化进程的快速发展,视频图像也必将获得巨大的发展和应用。由于视频图像其具有形象、直观、生动和连续的特点,能够更加全面的狄取事物的信息,因此它的应用也越来越广泛,在安防,交通,医学,工业生产等方面发挥着越来越重要的作用。比如在智能交通方面的应用,通过对城市交通路线的摄像头信息的提取,经过网络化传输,我们可以获取到交通现场的第一手资料,同时通过对视顿图像数据的智能处理,我们还可以获取到车流统计信息以更好的疏导交通拥堵,可以动态的对重要领导人进行实时跟踪以在不管制交通的情况下保障其安全出行。比如在智能安防方面料的应用,通过视频图像安保人贝能够对于重点区域进行监控,对于特殊入群进行实时观察,同时通过智能应用,可以对危险人物进行人脸检测,对于特殊事件进行预测报警,还有对于重要事件的回放查吞,都给现在的安防带来了巨大的应用前景。通过这两个例子,我们可以看得出来视频图像在各行各业发挥着越来越重要的作用,而当前对视频图像的研究热点之一,就包括视频目标跟踪,它是计算机视觉中的-一个重点。
视频目标跟踪同主要是对于视频图像中我们感兴趣的目标进行实时跟踪。视频跟踪经历了三个阶段的发展:第一个阶段,是传统的视频监控系统,对于目标的跟踪主要依靠人为的切换识别米获取感兴趣日标信息,这样的方式对于操作人员要求高,同时效率低下,错误率高;第二个阶段,是对单个挺像头单目标的跟踪研究,出现了很多经典算法,如 LK 光流法,运动模板检测,mean-shift 跟踪等。通过提取运动目标的单一特征进行跟踪研究,虽然可以在定限制条件下获取好的效果,但是准确性却不高;第三个阶段,是对多个摄像头,多种特征进行机器学习的相互融合处理,以达到理想的效果。
本论文主要解决多摄像头下目标的跟踪检测问题。采用背景差帧法,加图像透视变换技术。论文的研究是基于跨摄像头统一运动车辆的。其次,目前的视频监控系统对于运动车辆的跟踪检测往往是基于单个算法的应用,这样往往顾此失彼的,本论文有效的结合了跟踪算法和检测算法,能够获得比较好的跟踪效果。最后,本论文努力实现在复杂的跟踪环境中对运动车辆的实时监控,提高算法的实用性,为安防行业的发展做出自己的贡献。
第 1 章背景差分法
1.1 背景差分法的原理
背景差分法是采用图像序列中的当前帧和背景参考模型比较来检测运动物体的一种方法,其性能依赖于所使用的背景建模技术。
在基于背景差分方法的运动目标检测中,背景图像的建模和模拟的准确程度,直接影响到检测的效果。不论任何运动目标检测算法,都要尽可能的满足任何图像场景的处理要求,但是由于场景的复杂性、不可预知性、以及各种环境干扰和噪声的存在,如光照的突然变化、实际背景图像中有些物体的波动、摄像机的抖动、运动物体进出场景对原场景的影响等,使得背景的建模和模拟变得比较困难。
背景差分法检测运动目标速度快,检测准确,易于实现,其关键是背景图像的获取。在实际应用中,静止背景是不易直接获得的,同时,由于背景图像的动态变化,需要通过视频序列的帧间信息来估计和恢复背景,即背景重建,所以要选择性的
1.2 常用的背景建模方法
(1)中值法背景建模:顾名思义,就是在一段时间内,取连续 N 帧图像序列,把这 N 帧图像序列中对应位置的像素点灰度值按从小到大排列,然后取中间值作为背景图像中对应像素点的灰度值;
(2)均值法背景建模:均值法建模算法非常简单,就是对一些连续帧取像素平均值。这种算法速度很快,但对环境光照变化和一些动态背景变化比较敏感。其基本思想是,在视频图像中取连续 N 帧,计算这 N 帧图像像素灰度值的平均值来作为背景图像的像素灰度值;
(3)卡尔曼滤波器模型:该算法把背景认为是一种稳态的系统,把前景图像认为是一种噪声,用基于 Kalman 滤波理论的时域递归低通滤波来预测变化缓慢的背景图像,这样既可以不断地用前景图像更新背景,又可以维持背景的稳定性消除噪声的干扰;
(4)单高斯分布模型:其基本思想是,将图像中每一个像素点的灰度值看成是一个随机过程 X,并假设该点的某一像素灰度值出现的概率服从高斯分布,用数学形式表示为:D(x,y)={1,|fk+1(x,y)fk(x,y)|>T0,others
(5)多高斯分布模型:将背景图像的每一个像素点按多个高斯分布的叠加来建模,每种高斯分布可以表示一种背景场景,这样的话,多个高斯模型混合使用就可以模拟出复杂场景中的多模态情形。
(6)高级背景模型:得到每个像素或一组像素的时间序列模型。这种模型能很好的处理时间起伏,缺点是需要消耗大量的内存。
1.3 算法过程
背景差分法是一种对静止场景进行运动分割的通用方法,它将当前获取的图像帧与背景图像做差分运算,得到目标运动区域的灰度图,对灰度图进行阈值化提取运动区域,而且为避免环境光照变化影响,背景图像根据当前获取图像帧进行更新。
根据前景检测,背景维持和后处理方法,存在几种不同的背景差方法。若设 It,BtIt,Bt 分别为当前帧与背景帧图像,T 为前景灰度阈值,则其中一种方法流程如下:

图 1-1 背景差分法流程图
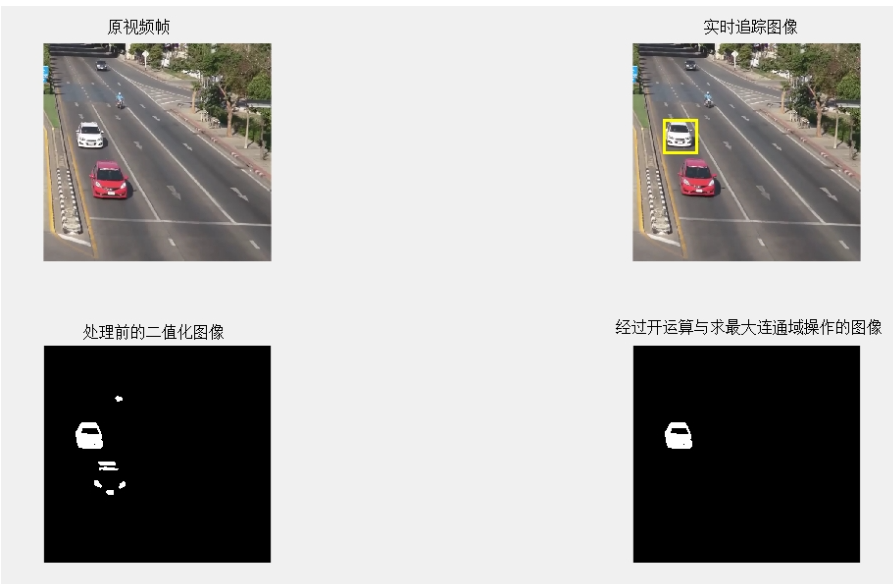
图 1-2 背景差分法效果示意图
第 2 章图像透视变换技术
2.1 图像透视变换原理
透视变换也叫投影变换,仿射变换是透视变换的特例。主要是透视变换能保持“直线性”,即原图像里面的直线,经透视变换后仍为直线。下面给出数学推导:
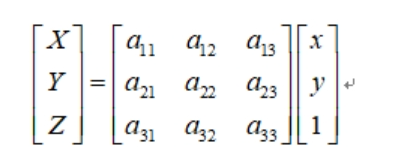
图 2-1 透视变换矩阵变换公式
 ,
,
图 2-2 其中透视变换矩阵
要移动的点,即源目标点为:
另外定点,即移动到的目标点为:

图 2-4 目标点
这是一个从二维空间变换到三维空间的转换,因为图像在二维平面,故除以 Z(X’;Y’;Z’)表示图像上的点:
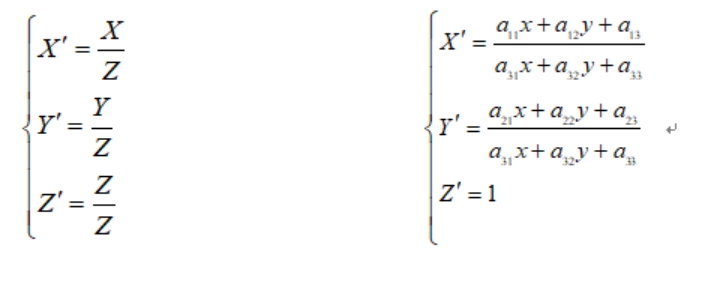
图 2-5 联立方程组
令,展开上面公式,得到一个点的情况:

图 2-6 展开公式
4 个点可以得到 8 个方程,即可解出 A。
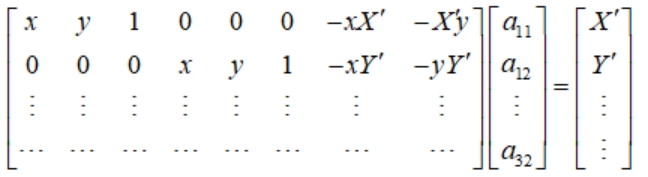
图 2-7 结果示意

图 2-8 透视变换前的图像

图 2-9 透视变换处理后的图像
第 3 章跨摄像头的车辆跟踪算法研发过程
3.1 视频素材的获取
由于基于多摄像头不同视角的监控视频比较罕见,网上多没有渠道获取此类视频。为了得到研究素材,研究小组决定自己动手拍摄。同比例缩小并模拟真实停车场环境,使用车辆模型模拟车辆停车入库操作。
小车模型:孙厝 3 块钱玩具车
拍摄器材:小米 8
摄像头模组:双摄,索尼 IMX363 广角镜头,三星 S5K3M3 长焦镜头万像素
拍摄人员:陈雯雯,刘佳昇

图 3-1 部分视频截图
3.2 背景帧差步骤
3.2.1 背景图像的提取
通过背景帧差法提取提取小车运动轨迹首先要获取视频的背景,本论文使用的背景建模方法为均值法背景建模,其基本思想是,在视频图像中取连续 N 帧,计算这 N 帧图像像素灰度值的平均值来作为背景图像。
3.2.2 前景图像的获取
求出背景图像后,将当前帧图像与背景图像进行差运算,并二值化处理。图像相似部分经过差运算趋于零,目标在经过差运算后受到影响较少。此时对图像进行二值化处理。并进行开运算操作,去除不必要的杂点。最后提取最大连通域,得出仅有目标的二值化图片。求出连通域重心作为车辆位置,返回视频帧标定。实现跟踪的效果。最后将每一帧得到的二值化图像进行叠加操作,可以形成单摄像头下的车辆运动轨迹。
3.3 图像透视变换及空间映射
3.3.1 图像的透视变换
对图像进行透视变化的操作,至少需要取得视频帧中的 4 个点,为视频中某个矩形的 4 个顶点。通过透视变换矩阵得到 4 个点形成的 8 个方程,接触透视变换矩阵。再通过透视变换公式的到原图片对新图片的映射。
3.3.2 图像的空间映射
由于透视变换后会产生图像偏移,所以需要把透视变换得到的结果图中的有效部分提取出来得到结果停车场图像。至此图像透视变换模板完成,通过此模板可以将单摄像图产生的轨迹,变为正视图的轨迹。最后将多个摄像头产生的正视图的轨迹,按照停车场的空间位置进行拼接得到跨摄像的车辆运行轨迹,为了更直观地看到效果,我们手动花了停车场地图,并将其叠加。
第 4 章实验结果与分析
4.1 背景图像的提取

图 4-1 通过均值法获取背景
可以看到由于,视频长度不够。获取的背景图像带有车辆的残影。对系统的影响不大。
4.2 车辆跟踪与轨迹

图 4-2 摄像头 1 跟踪情况
可以看到在提取最大连通域前,二值化图像左上角有干扰。

图 4-3 摄像头 2 跟踪情况
4.3 跨摄像头的路径绘制

图 4-4 与实际地图重合后的轨迹绘制效果
可以看到,结果图记录到了车辆从进入停车场到停到 16 号车位的全过程。精准度较高。
总结与展望
经过一段时间的研究实验和理论技术学习,基于跨摄像头的车辆目标跟踪终于完成了。本文的研究结合了背景差分法,并且图像透视变化算法,针对跨摄像头日标跟踪进行了算法研究和编程实现。
通过研究发现,单个跟踪算法在跟踪过程中存在无法有效克服遮挡、变形、运动速度变化等影响,并且单个银像头自身存在很大的字间局限性。在现实生活中,大部分摄像头都是静态的,如何有效护大监控区域并能够准确跟踪运动目标,跨摄像头的日标跟踪的研究就显得很有必要。
本文研究的研究过程,一共经历了四个部分。第一部分是对视频素材的获取。第二部分,是对算法的大致流程和过程中可能会用到的方法进行讨论,跟踪检测结果综合处理分析,画出跨摄像头跟踪流程图。第三部分,是对跨摄像头算法跟踪检测算法研究与实现,主要是跟踪算法和检测算法。第四部分,对跨摄像头车辆目标的跟踪进行了实验,并且对实验结果进行了分析。
最后实验结果表明,可以做到多摄像头单目标的精准跟踪,但是由于算法限制,我们使用最大连通域的方式只能获取视频中单个目标的跟踪,没办法实现多目标跟踪检测,后续我们融入机器学习的方法对连通域提取特征,实现多目标的检测判断与跟踪。
项目分享
项目获取:














 775
775











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









