









1. 前言:
再查询英雄联盟战绩的时候,我们有时候会筛选战绩,比如按照对局的不同,按照单双排、灵活、甚至是通过英雄去筛选对局,如果获取这些数据接口的对局并没有数据,这种获取分页数据这种在sql中貌似很简单就能做到的事情,这里便成为相对麻烦做到的事情了。
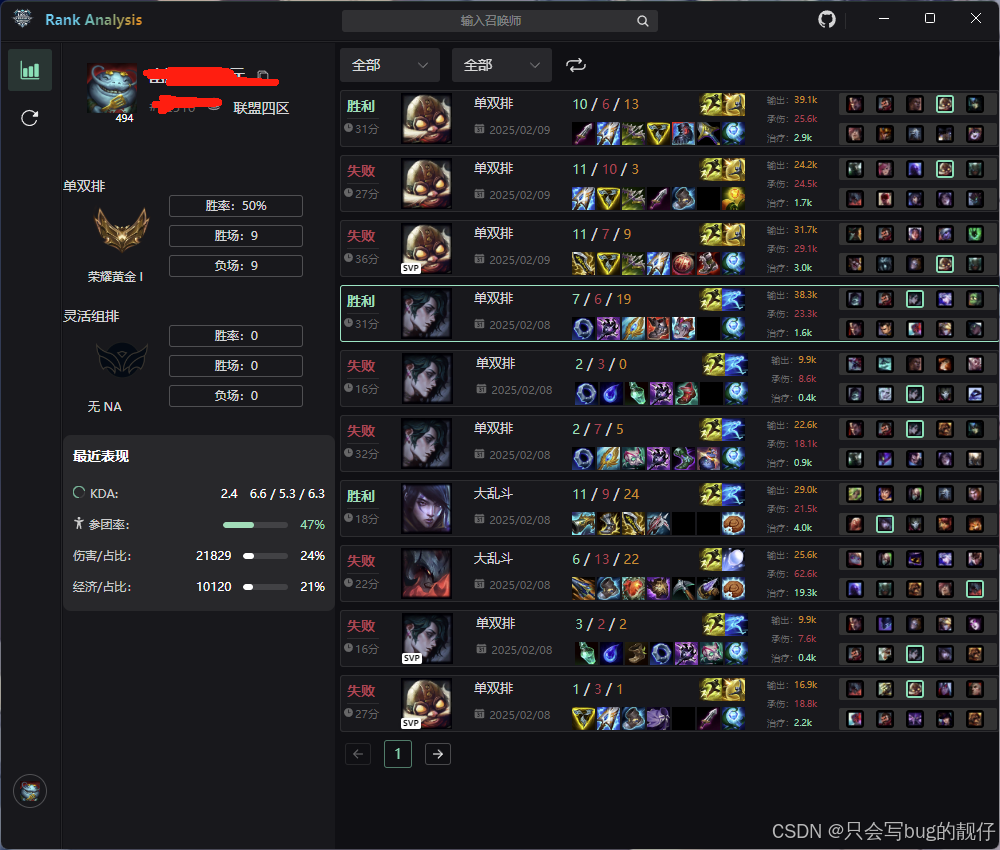
2. 实现过程
我们很容易想到的思路便是从所有对局中去找了,但是每次遍历所有数据是很麻烦的,rank-analysis 只是起到 http 服务的作用,数据并不在本地,网络 io 是很花费时间的操作,所以,这里去了下巧
- 可以通过限制起搜的 index 去缩小搜索的范围
- 可以只设置上下页,而不可以跳页,让数据的筛选有前后记忆性。
- 增加每次 io 的数量去减少 io 的次数
后端并没有做很多的处理,主要是通过前端去限制范围
func getFilterMatchHistory(params MatchHistoryParams) (client.MatchHistory, int, int, error) {
index := params.BegIndex
filterQueueId := params.filterQueueId
filterChampId := params.filterChampId
matchHistory := client.MatchHistory{}
maxGames := 10 // 设定最大筛选结果数,防止无限循环
for i := index; i < params.EndIndex; i += 100 {
tempMatchHistory, err := client.GetMatchHistoryByPuuid(params.Puuid, i, i+100)
if err != nil {
return matchHistory, index, i, err // 发生错误时立即返回当前已收集的比赛
}
for j, game := range tempMatchHistory.Games.Games {
// 进行筛选:如果 filterChampId 和 filterQueueId 都匹配,才添加
if (filterChampId == 0 || game.Participants[0].ChampionId == filterChampId) &&
(filterQueueId == 0 || game.QueueId == filterQueueId) {
matchHistory.Games.Games = append(matchHistory.Games.Games, game)
}
// 如果筛选的比赛数量超出 maxGames,则提前返回
if len(matchHistory.Games.Games) >= maxGames {
return matchHistory, index, i + j, err
}
}
}
return matchHistory, index, index, nil
}
前端实现,前端主要是通过一个栈去记录已经翻过页的起止索引,每次进行筛选的时候都需要至少指定起搜的 index,除了第一页不用,下一页的beginIndex 是上一页 endIndex 的索引 +1.
const page = ref(1)
var curBegIndex = 0;
var curEndIndex = 0;
const pageHistory = ref<{ begIndex: number, endIndex: number }[]>([]);
const nextPage = () => {
if (filterQueueId.value != 0 || filterChampionId.value != 0) {
getHistoryMatch(name, curEndIndex + 1, 1500).then(() => {
page.value++
});
} else {
getHistoryMatch(name, (page.value) * 10, (page.value) * 10 + 9).then(() => {
page.value++
});
}
pageHistory.value.push({ begIndex: curBegIndex, endIndex: curEndIndex });
}
const prevPage = () => {
if (filterQueueId.value != 0 || filterChampionId.value != 0) {
const lastPage = pageHistory.value.pop();
if (!lastPage || lastPage.begIndex == null || lastPage.endIndex == null) {
throw new Error("Last page's begIndex or endIndex is null or undefined");
}
getHistoryMatch(name, lastPage.begIndex, lastPage.endIndex).then(() => {
page.value--
});
} else {
getHistoryMatch(name, (page.value - 2) * 10, (page.value - 2) * 10 + 9).then(() => {
page.value--
})
};
}
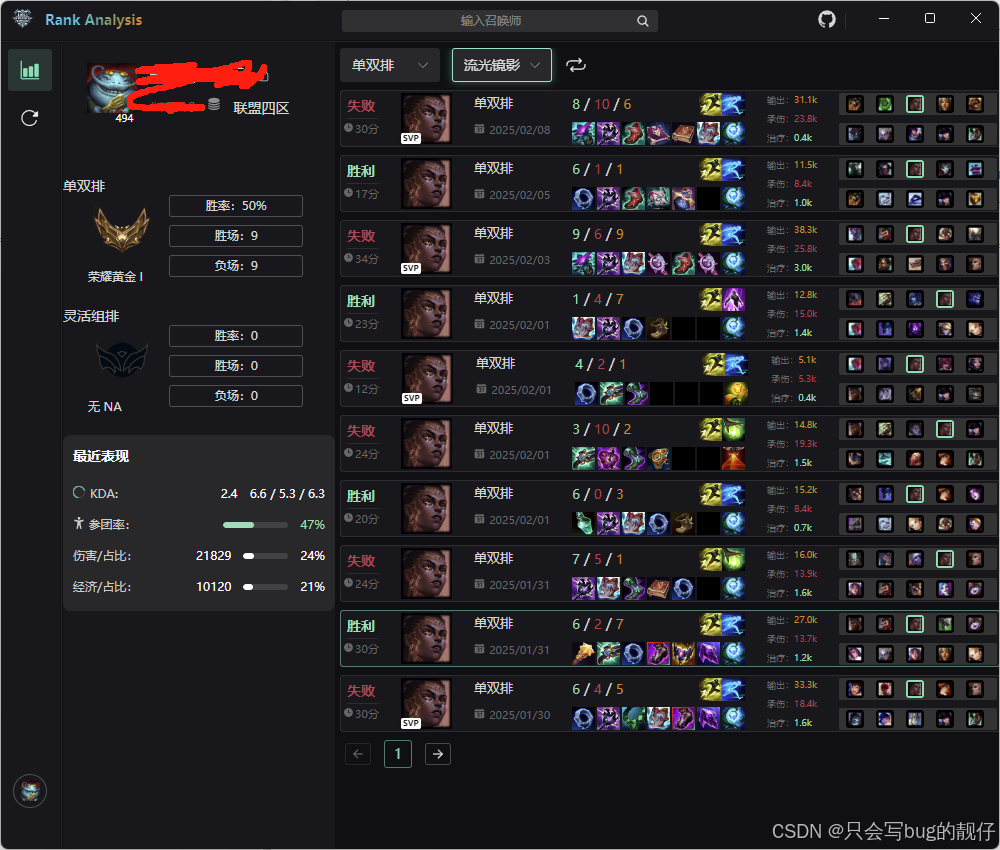
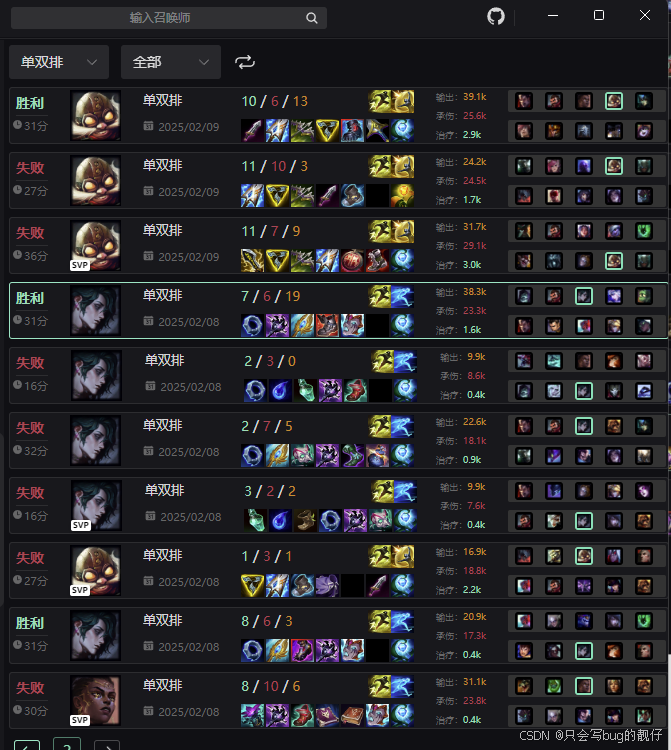
最后达成的效果就是即能筛选又可以翻页,就是就目前来看,性能有点着急,如果,一直凑不够十个可能会遍历到最后,即便吧最大索引设置成1500,也非常慢



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











