







DeepIntent模型
文献:Zhai S, Chang K H, Zhang R, et al. DeepIntent: Learning Attentions for Online Advertising with Recurrent Neural Networks[C]// KDD 2016:1295-1304.
思想
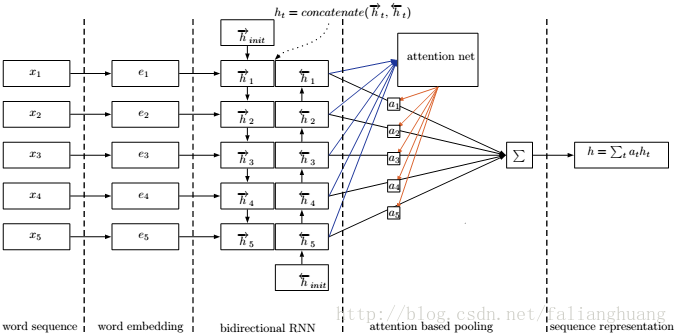
从pooling的角度来解释attention机制,last pooling(选择RNN的最终隐输出作为序列表示向量)存在“远距离信息容易遗忘”的问题;mean pooling(将RNN的各个时刻对应输出进行简单平均)存在“无法区分各个term对用户意图的贡献度的差异”的问题;max pooling(对RNN的所有时刻对应的输出向量的分量取最大值)存在与mean pooling类似的问题. 提出如下的attention pooling:
- h=∑t=1Tatht , 其中 at=exp(s(ht;θ))∑Tt=1exp(s(ht;θ))
s(ht;θ)
为注意网络,主要用来学习权重系数
at
, 网络结构如下:
以查询log文件构造有监督学习的数据集: (q,d+) , (q,d−i) , 分别表示查询序列q,与q诱发的点击 d+ , q查询下并没有点击 (q,d−i) , 有如下目标函数:
- J(θ)=−∑(q,d+)logexp(score(q,d+))exp(score(q,d+))+∑ni=1exp(score(q,d−i)) s.t. score(q,d)=hq(q)Thd(d)
CSE模型(Conceptual Sentence Embedding)
文献:Wang Y, Huang H, Feng C, et al. CSE: Conceptual Sentence Embeddings based on Attention Model[C]// ACL 2016:505-515.
思想
为了解决一词多义问题,将概念与注意机制相结合来实现文本序列的嵌入表示,使得相同的词在不同概念中有不同的向量表示形式。
启发于CBOW与Skip-gram的思想”在预测中心目标词或局部语境词时,需要对词进行向量化”,提出类似思想“在预测中心目标词或局部语境词时,需要对句子进行概念相关向量化”:
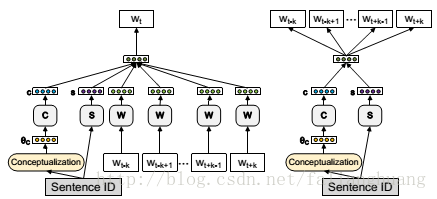
模型: (1) CBOW-CSE ; (2)Skip-Gram-CSE
每个句子有其ID,利用基于知识的文本概念化算法获得句子的概念分布
θC
,
W
与
在对CBOW-CSE的模型参数
Skip-Gram-CSE:忽略输入中的语境词,而从输出中的定长语境随机选取语境词进行预测。预测语境窗口内的一个语境词向量实质上就是给定句子向量
Attention-CSE:CBOW-CSE与Skip-Gram-CSE都需要确定语境窗口大小,这是个难题。太大可能会引入无关词,太小可能会排除相关词。这是由于这些模型是采用同等重要的方式来处理语境窗口内的词语。为此,引入注意机制以区别对待语境窗口内的词语。即将CBOW中的
- ai(w)=edw,i+ri∑−k⩽c⩽k,c≠0edw,c+rc
其中
dw,i∈D|V|×2k
表示词语
w
的
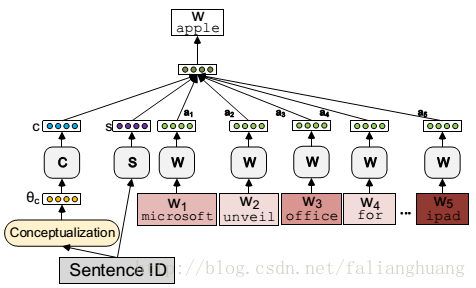
Attention-CSE(参数包括:W,C,S,D,R)















 146
146











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









