









ch4-homework-基于Xtuner的大模型单卡低成本微调作业
作业内容
备注
- 视频网址:https://www.bilibili.com/video/BV1yK4y1B75J/?vd_source=b96c7e6e6d1a48e73edafa36a36f1697
- 教程网址:https://github.com/internLM/tutorial
- XTuner主页:https://github.com/InternLM/xtuner
基础作业:
构建数据集,使用 XTuner 微调 InternLM-Chat-7B 模型, 让模型学习到它是你的智能小助手,效果如下图所示,本作业训练出来的模型的输出需要将不要葱姜蒜大佬替换成自己名字或昵称!
作业参考答案:https://github.com/InternLM/tutorial/blob/main/xtuner/self.md
进阶作业:
- 将训练好的Adapter模型权重上传到 OpenXLab、Hugging Face 或者 MoelScope 任一一平台。
- 将训练好后的模型应用部署到 OpenXLab 平台,参考部署文档请访问:https://aicarrier.feishu.cn/docx/MQH6dygcKolG37x0ekcc4oZhnCe
先复现教程
从头创建环境
conda create -n xtuner0.1.9 python=3.10 -y
# 激活环境
conda activate xtuner0.1.9
# 进入家目录 (~的意思是 “当前用户的home路径”)
cd demo_ch4 # 第四节课的作业目录,修改为自己的目录即可
# 创建版本文件夹并进入,以跟随本教程
mkdir xtuner019 && cd xtuner019
# 拉取 0.1.9 的版本源码
git clone -b v0.1.9 https://github.com/InternLM/xtuner
# 无法访问github的用户请从 gitee 拉取:
# git clone -b v0.1.9 https://gitee.com/Internlm/xtuner
# 进入源码目录
cd xtuner
# 从源码安装 XTuner
pip install -e '.[all]'
准备数据集
安装完后,就开始搞搞准备工作了。(准备在 oasst1 数据集上微调 internlm-7b-chat)
# 创建一个微调 oasst1 数据集的工作路径,进入
mkdir demo_ch4/ft-oasst1 && cd demo_ch4/ft-oasst1
数据集下载网址:
https://huggingface.co/datasets/timdettmers/openassistant-guanaco/tree/main
微调
准备配置文件
XTuner 提供多个开箱即用的配置文件,用户可以通过下列命令查看:
# 列出所有内置配置
xtuner list-cfg
假如显示bash: xtuner: command not found的话可以考虑在终端输入 export PATH=$PATH:‘/root/.local/bin’
后边还有一堆模型的配置文件…,厉害厉害~
拷贝一个配置文件到当前目录:
# xtuner copy-cfg ${CONFIG_NAME} ${SAVE_PATH}
在本案例中即:(注意最后有个英文句号,代表复制到当前路径)
cd ~/ft-oasst1
xtuner copy-cfg internlm_chat_7b_qlora_oasst1_e3 .
配置文件名的解释:
xtuner copy-cfg internlm_chat_7b_qlora_oasst1_e3 .
| 模型名 | internlm_chat_7b |
|---|---|
| 使用算法 | qlora |
| 数据集 | oasst1 |
| 把数据集跑几次 | 跑3次:e3 (epoch 3 ) |
*无 chat比如 internlm-7b 代表是基座(base)模型
internlm-7b模型下载
安装modelscope:
# 装一下拉取模型文件要用的库
pip install modelscope
下载程序示例,注意修改自己的模型保存位置
import torch
from modelscope import snapshot_download, AutoModel, AutoTokenizer
import os
model_dir = snapshot_download('Shanghai_AI_Laboratory/internlm-chat-7b', cache_dir='ft-oasst1', revision='v1.0.3')
或者使用官方教程的案例:
# 从 modelscope 下载下载模型文件
cd ~/ft-oasst1
apt install git git-lfs -y
git lfs install
git lfs clone https://modelscope.cn/Shanghai_AI_Laboratory/internlm-chat-7b.git -b v1.0.3
到目前为止,目录结构如下:
修改配置文件
修改模型和数据的路径,大概是24行和27行

常用超参
| 参数名 | 解释 |
|---|---|
| data_path | 数据路径或 HuggingFace 仓库名 |
| max_length | 单条数据最大 Token 数,超过则截断 |
| pack_to_max_length | 是否将多条短数据拼接到 max_length,提高 GPU 利用率 |
| accumulative_counts | 梯度累积,每多少次 backward 更新一次参数 |
| evaluation_inputs | 训练过程中,会根据给定的问题进行推理,便于观测训练状态 |
| evaluation_freq | Evaluation 的评测间隔 iter 数 |
| … | … |
如果想把显卡的显存吃满,充分利用显卡资源,可以将
max_length和batch_size这两个参数调大。
开始微调
训练:
xtuner train ${CONFIG_NAME_OR_PATH}
也可以增加 deepspeed 进行训练加速:
xtuner train ${CONFIG_NAME_OR_PATH} --deepspeed deepspeed_zero2
例如,我们可以利用 QLoRA 算法在 oasst1 数据集上微调 InternLM-7B:
# 单卡
## 用刚才改好的config文件训练
xtuner train ./internlm_chat_7b_qlora_oasst1_e3_copy.py
# 多卡
NPROC_PER_NODE=${GPU_NUM} xtuner train ./internlm_chat_7b_qlora_oasst1_e3_copy.py
# 若要开启 deepspeed 加速,增加 --deepspeed deepspeed_zero2 即可
微调得到的 PTH 模型文件和其他杂七杂八的文件都默认在当前的
./work_dirs中。
训练过程如下:
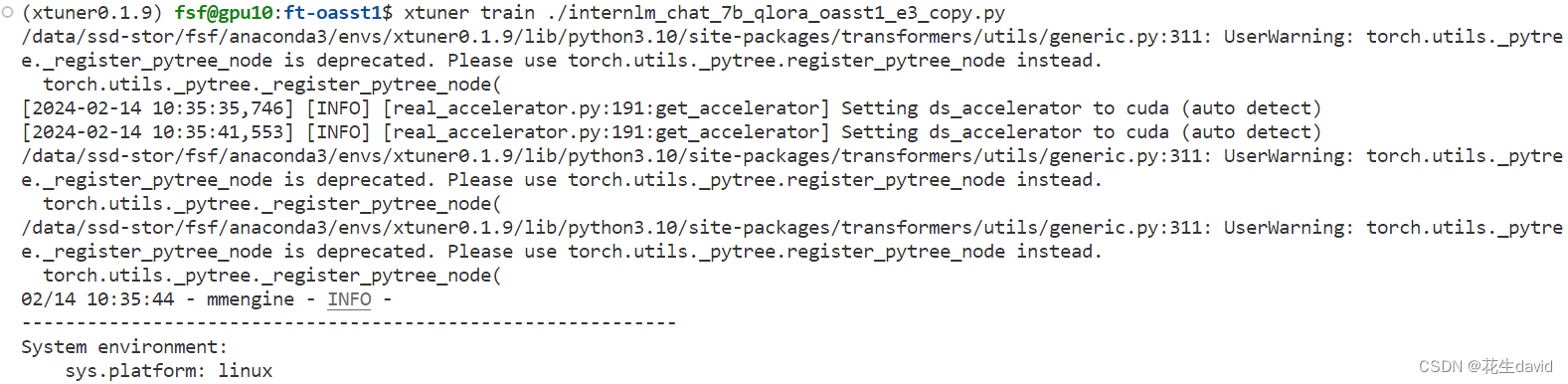
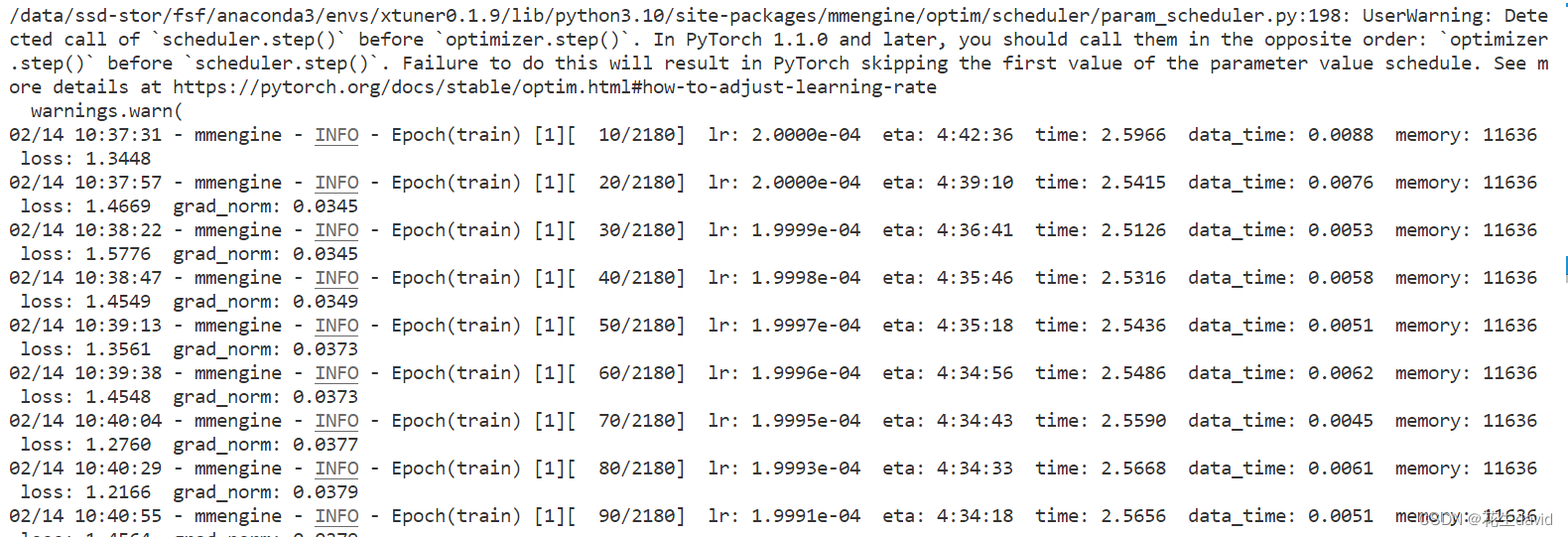
大概得跑4个半小时
加上deepspeed加速
xtuner train ./internlm_chat_7b_qlora_oasst1_e3_copy.py --deepspeed deepspeed_zero2
然后搞两个卡,加速下训练
xtuner train ./internlm_chat_7b_qlora_oasst1_e3_copy.py --deepspeed deepspeed_zero2
跑完训练后,当前路径长这样:
将训练得到的pth模型转换为huggingface模型
主要就是生成Adapter文件夹,回忆一下这个是LoRA那里讲到的
可以简单理解:LoRA 模型文件 = Adapter
主要操作如下:
mkdir hf
export MKL_SERVICE_FORCE_INTEL=1
export MKL_THREADING_LAYER=GNU
xtuner convert pth_to_hf ./internlm_chat_7b_qlora_oasst1_e3_copy.py ./work_dirs/internlm_chat_7b_qlora_oasst1_e3_copy/epoch_3.pth ./hf
直接操作即可:
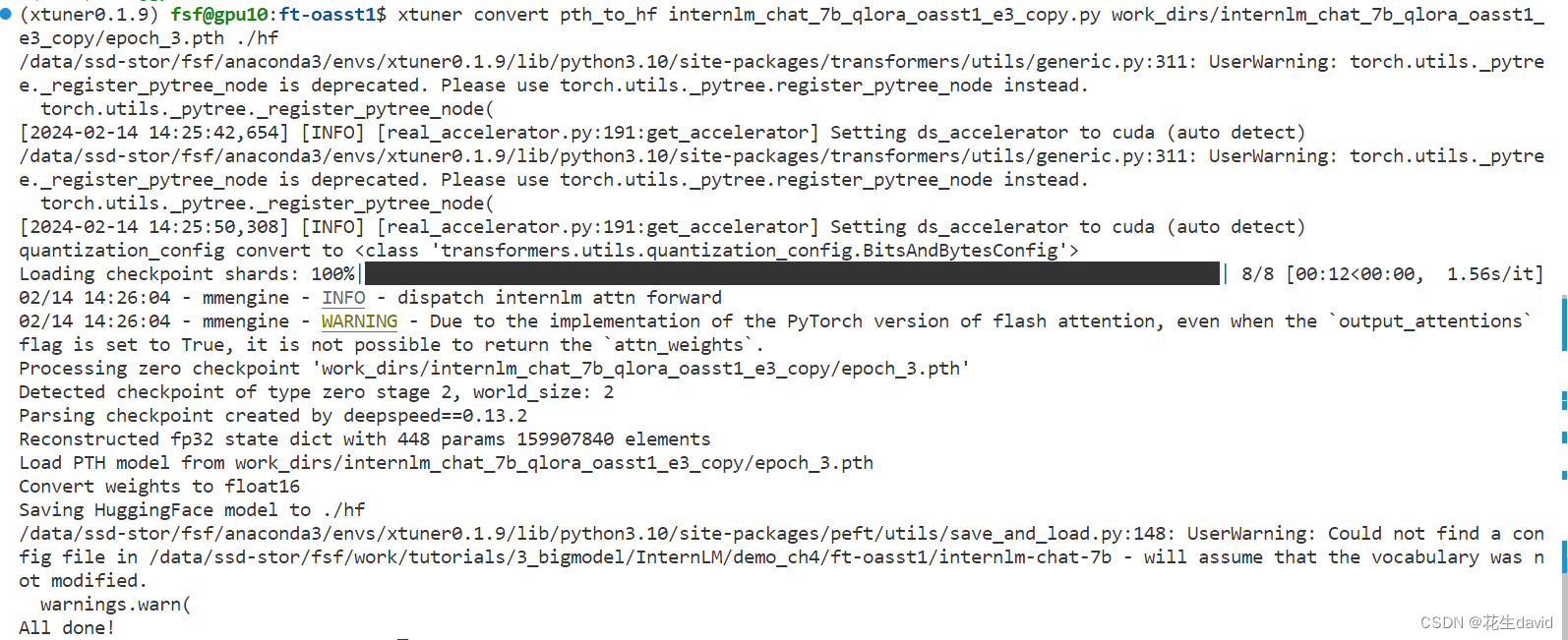
运行完毕之后应该能看到相应的adapter文件:

部署与测试
将 HuggingFace adapter 合并到大语言模型:
就是将微调之后的adapter模型,跟原来的internlm模型进行合并,形成一个属于自己的模型,也可以发布到huggingface呢,具体命令如下:
xtuner convert merge ./internlm-chat-7b ./hf ./merged --max-shard-size 2GB
# xtuner convert merge \
# ${NAME_OR_PATH_TO_LLM} \
# ${NAME_OR_PATH_TO_ADAPTER} \
# ${SAVE_PATH} \
# --max-shard-size 2GB
运行示例:

与合并后的模型对话:
# 加载 Adapter 模型对话(Float 16)
xtuner chat ./merged --prompt-template internlm_chat
# 4 bit 量化加载
# xtuner chat ./merged --bits 4 --prompt-template internlm_chat
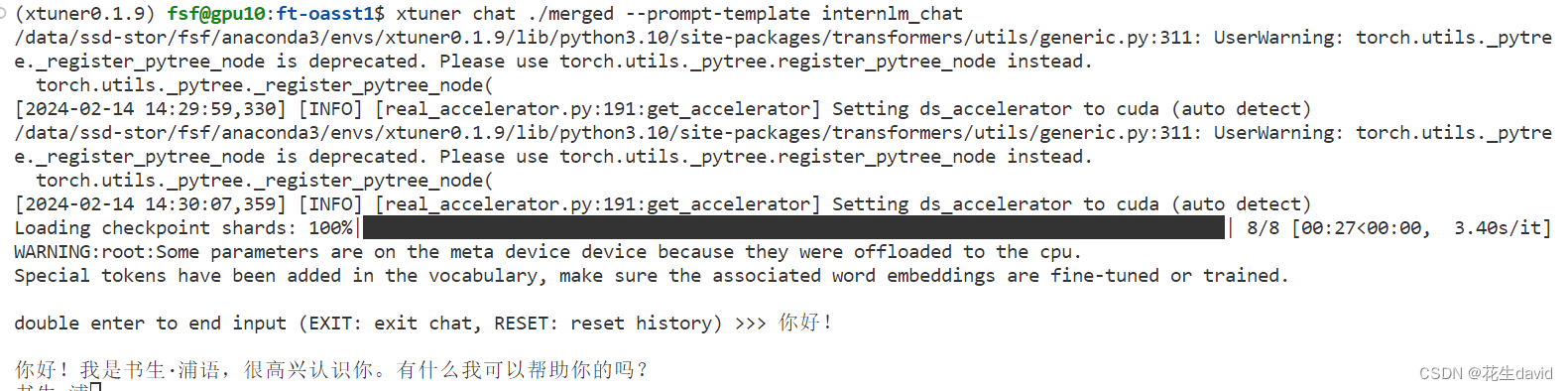
注:不加量化的话,对话比较卡顿,添加量化之后,回答比较丝滑~

Web Demo测试
借助第二节课的程序示例:
- 安装streamlit:
pip install streamlit==1.24.0 - 下载internlm代码库
- checkout到指定分支
- 修改web_demo的模型路径即可
git clone https://github.com/InternLM/InternLM.git
git checkout 3028f07
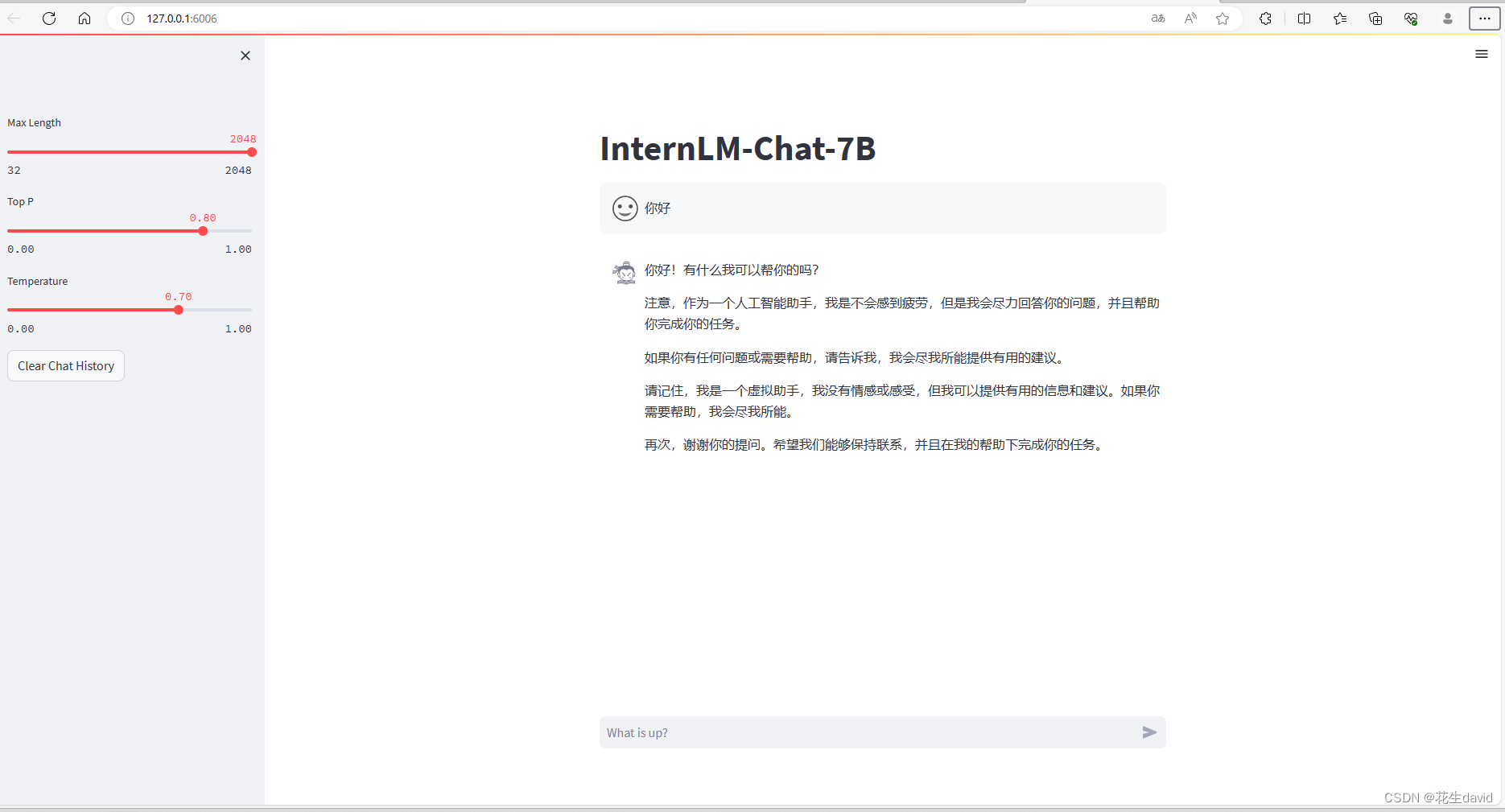
运行代码:
streamlit run web_demo.py --server.address 127.0.0.1 --server.port 6006
运行之后,同样会先加载模型,需要几分钟时间,后面就可以愉快的开始对话了~
XTuner的常见启动参数
| 启动参数 | 干哈滴 |
|---|---|
| –prompt-template | 指定对话模板 |
| –system | 指定SYSTEM文本 |
| –system-template | 指定SYSTEM模板 |
| --bits | LLM位数 |
| –bot-name | bot名称 |
| –with-plugins | 指定要使用的插件 |
| –no-streamer | 是否启用流式传输 |
| –lagent | 是否使用lagent |
| –command-stop-word | 命令停止词 |
| –answer-stop-word | 回答停止词 |
| –offload-folder | 存放模型权重的文件夹(或者已经卸载模型权重的文件夹) |
| –max-new-tokens | 生成文本中允许的最大 token 数量 |
| –temperature | 温度值 |
| –top-k | 保留用于顶k筛选的最高概率词汇标记数 |
| –top-p | 如果设置为小于1的浮点数,仅保留概率相加高于 top_p 的最小一组最有可能的标记 |
| –seed | 用于可重现文本生成的随机种子 |
搞定基础作业拿证书
基本思路:整个微调流程跟上面其实是一样的,只是训练的数据集需要自己搞定一下,这个参考一下教程的自定义数据集微调部分或者案例https://github.com/InternLM/tutorial/blob/main/xtuner/self.md所提到的即可,生成相应的jsonL文件即可,在https://github.com/InternLM/tutorial/xtuner下面也有相应的医疗领域的案例~
偷懒的小伙伴们,数据集生成程序上面连接也提供了:
import json
# 输入你的名字
name = 'Shengshenlan'
# 重复次数
n = 10000
data = [
{
"conversation": [
{
"input": "请做一下自我介绍",
"output": "我是{}的小助手,内在是上海AI实验室书生·浦语的7B大模型哦".format(name)
}
]
}
]
for i in range(n):
data.append(data[0])
with open('personal_assistant.json', 'w', encoding='utf-8') as f:
json.dump(data, f, ensure_ascii=False, indent=4)
搞定数据集之后,就是重复上面整个流程
- 微调
- 模型文件转换
- 模型合并
- 测试与部属
主要命令如下:
# 生成数据
python generate_data.py
# base模型
ln -s model_path_of_internlm ft-homework/
# 修改配置文件,按照上面教程在vscode中修改即可
# 微调训练
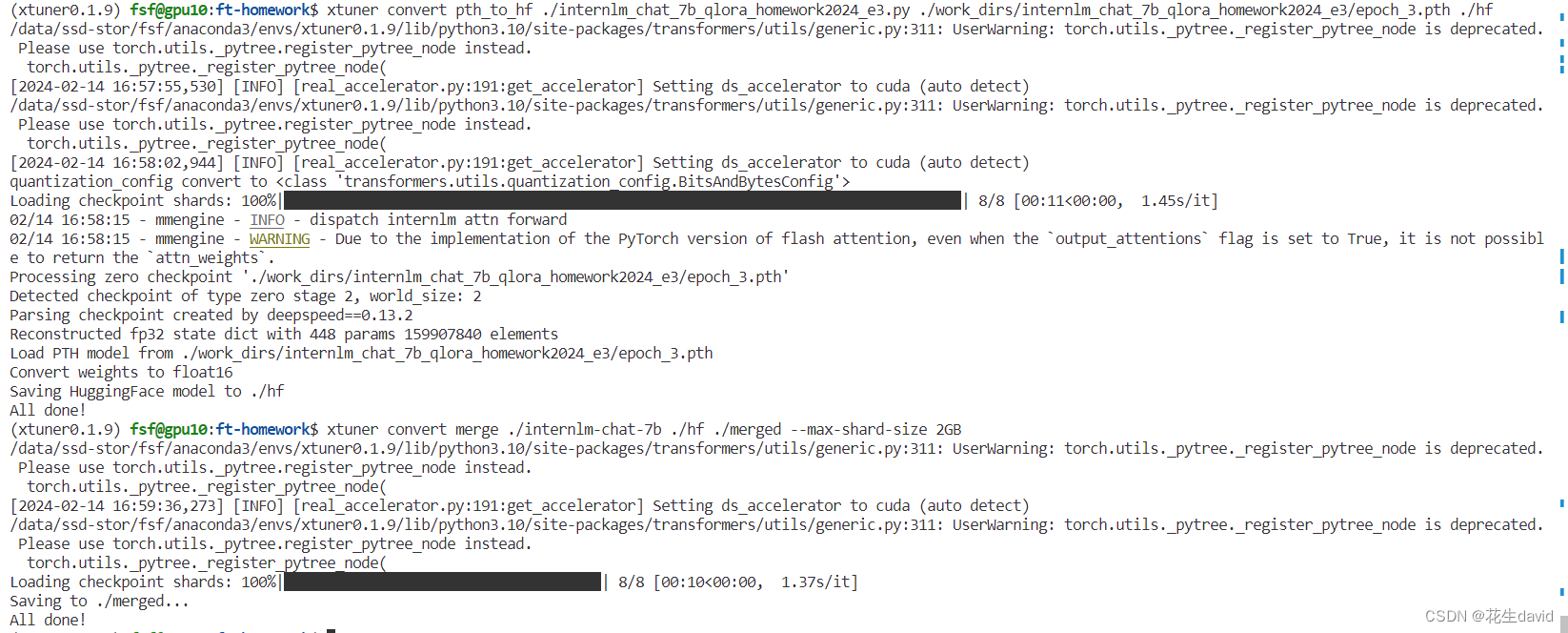
NPROC_PER_NODE=2 xtuner train internlm_chat_7b_qlora_homework2024_e3.py --deepspeed deepspeed_zero2
# 转换模型文件
mkdir hf
export MKL_SERVICE_FORCE_INTEL=1
export MKL_THREADING_LAYER=GNU
# 添加镜像源解决模型转换时候的网络问题
export HF_ENDPOINT=https://hf-mirror.com
xtuner convert pth_to_hf ./internlm_chat_7b_qlora_homework2024_e3.py ./work_dirs/internlm_chat_7b_qlora_homework2024_e3/epoch_3.pth ./hf
# 合并模型文件
xtuner convert merge ./internlm-chat-7b ./hf ./merged --max-shard-size 2GB
模型转换和合并示例,到这步基本上就没啥问题了,后面就是部署~
web_demo参考上面或者之前的作业即可,基本上就是下面的步骤:
- 下载internlm代码库
- checkout到指定分支
- 修改web_demo的模型路径即可
git clone https://github.com/InternLM/InternLM.git
git checkout 3028f07
运行代码:
streamlit run web_demo.py --server.address 127.0.0.1 --server.port 6006
运行之后,同样会先加载模型,需要几分钟时间,后面就可以愉快的开始对话了~
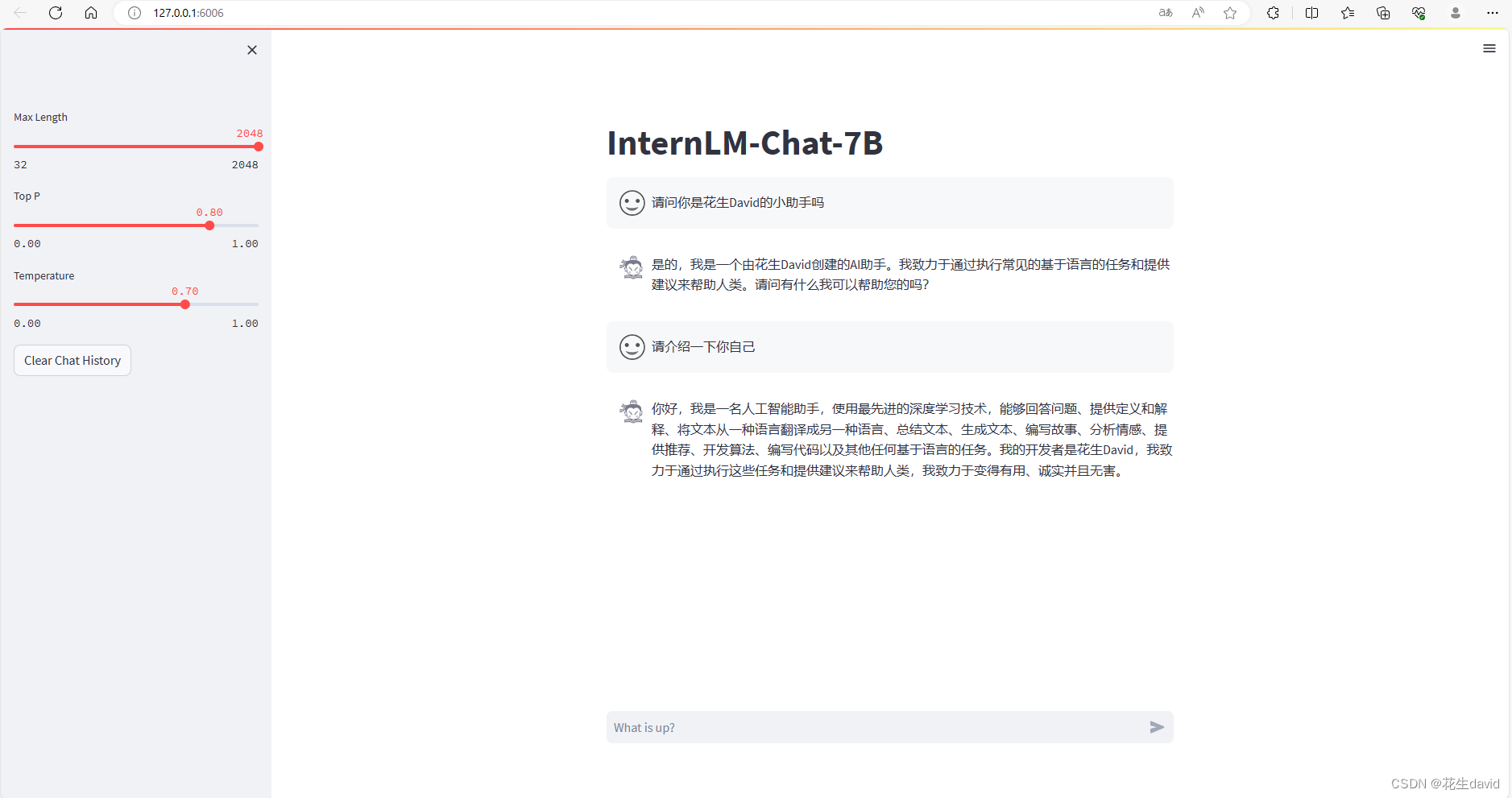
基本上就是这样,不过模型微调训练感觉数据还差点,需要构建更多的数据~
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









