







 本文深入解析Linux内核中的CUBIC拥塞控制算法,包括其在内核中的实现细节,如初始化、ssthresh更新、拥塞避免等核心函数。同时,探讨了在长肥管道场景下,CUBIC算法的挑战及解决方案。
本文深入解析Linux内核中的CUBIC拥塞控制算法,包括其在内核中的实现细节,如初始化、ssthresh更新、拥塞避免等核心函数。同时,探讨了在长肥管道场景下,CUBIC算法的挑战及解决方案。
linux内核里面拥塞控制算法比较多,目前大部分用的cubic算法。
在内核里面代码是怎样实现的呢?
static struct tcp_congestion_ops cubictcp __read_mostly = {
.init = bictcp_init, 初始化
.ssthresh = bictcp_recalc_ssthresh, 更新tcp的ssthresh值
.cong_avoid = bictcp_cong_avoid, 重新计算cwnd值
.set_state = bictcp_state, ca状态更新
.undo_cwnd = tcp_reno_undo_cwnd, 丢包时候cwnd更新处理
.cwnd_event = bictcp_cwnd_event, 当cwnd事件发生时调用的
.pkts_acked = bictcp_acked, 数据包ack计数
.owner = THIS_MODULE,
.name = "cubic",
};
看下大概回调怎么实现的
static void bictcp_init(struct sock *sk)
{
struct bictcp *ca = inet_csk_ca(sk);
bictcp_reset(ca);
if (hystart)
bictcp_hystart_reset(sk);
if (!hystart && initial_ssthresh)
tcp_sk(sk)->snd_ssthresh = initial_ssthresh;
}//主要是 ca初始化和ssthresh值初始化
出现拥塞是重新计算ssthresh,就是当前cwnd的一半
static u32 bictcp_recalc_ssthresh(struct sock *sk)
{
const struct tcp_sock *tp = tcp_sk(sk);
struct bictcp *ca = inet_csk_ca(sk);
ca->epoch_start = 0; /* end of epoch */
/* Wmax and fast convergence */
if (tp->snd_cwnd < ca->last_max_cwnd && fast_convergence)
ca->last_max_cwnd = (tp->snd_cwnd * (BICTCP_BETA_SCALE + beta))
/ (2 * BICTCP_BETA_SCALE);
else
ca->last_max_cwnd = tp->snd_cwnd;
return max((tp->snd_cwnd * beta) / BICTCP_BETA_SCALE, 2U);
}
static void bictcp_cong_avoid(struct sock *sk, u32 ack, u32 acked)
{
struct tcp_sock *tp = tcp_sk(sk);
struct bictcp *ca = inet_csk_ca(sk);
if (!tcp_is_cwnd_limited(sk))
return;
if (tcp_in_slow_start(tp)) { //分为正在慢启动过程中的计算
if (hystart && after(ack, ca->end_seq))
bictcp_hystart_reset(sk);
acked = tcp_slow_start(tp, acked);
if (!acked)
return;
}
bictcp_update(ca, tp->snd_cwnd, acked);
tcp_cong_avoid_ai(tp, ca->cnt, acked); //正常窗口值 ++
}
u32 tcp_reno_undo_cwnd(struct sock *sk) //丢包时的处理
{
const struct tcp_sock *tp = tcp_sk(sk);
return max(tp->snd_cwnd, tp->prior_cwnd);
}
cubic算法的整体逻辑
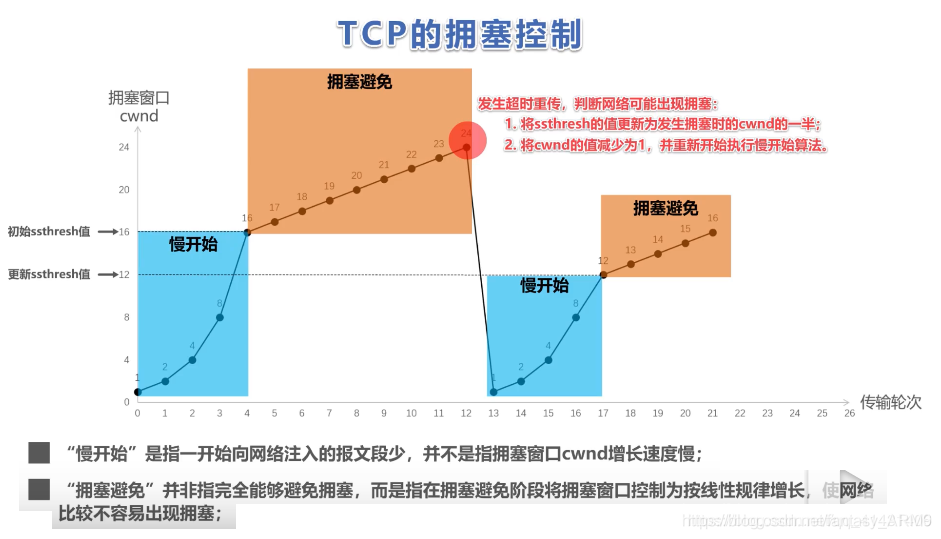
TCP的四种拥塞控制算法
1.慢开始 窗口大小达到ssthresh之后慢开始
2.拥塞控制 判断为拥塞避免的时候,ssthresh马上减半
3.快重传 当出现3个重复的ack的时候,马上重传后面一个分组。如下图
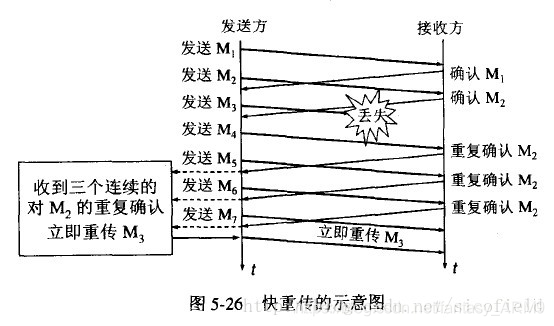
4.快恢复 开始的时候指数级恢复
长肥管道:
有了上面理论基础之后看下面的问题,当网络的RTT非常大,已知光速大概30wkm/s,如果是跨国网络,距离非常远。RTT很大,这样一来。来回的ack时间就很长,如果出现丢包马上就会变成ssthresh减半,慢启动状态。窗口恢复非常困难。
tcp 窗口大小就会是这样的曲线
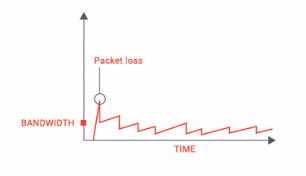
如何解决这种问题。
调大接收端的tcp_rmem 和 发送端tcp_wmem 中间那个缺省值, 让有足够的数据在tcp信道上飘着,就能充分利用信道带宽。
echo "4096 52420000 62910000" > /proc/sys/net/ipv4/tcp_rmem
然后再抓包发现初始化的接收窗口确实变大了,用wireshark看起来没有变大是因为忽略了后面的WS字段,这个是窗口放大倍数,所以长肥管道为了保证有足够的数据在通信信道上跑,就要把接收端的recv buf设置非常大。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









