






数据类型
- 基本数据类型:Number、String、Boolean、Null、Undefined、Symbol
- 引用数据类型统称为Object,细分有:Object、Array、Function
- 存储方式:基本数据类型的数据直接存储在栈中;引用数据类型的数据存储在堆中,在栈中保存数据的引用地址。栈内存是自动分配内存的,而堆内存是动态分配内存的,不会自动释放,所以每次使用完对象的时候都要把它设置为null,从而减少无用内存的消耗。
isNaN和Number.isNaN函数的区别
- 函数isNaN接收参数后,会将该参数转换为数值,任何不能被转换为数值的都会返回true,因此非数字值传入也会返回true,会影响NaN的判断。
- 函数Number.isNaN会先判断传入参数是否为数字,如果是再继续判断是否为NaN,不会进行数据类型的转换,这种方法对于NaN的判断更为准确。
Object.is()与比较操作符===、==的区别
- 使用双等号==,如果两边的类型不一致,会进行强制类型转换后再进行比较
- 使用三等号===,如果两边的类型不一致,不会做强制类型转换,直接返回false
- 使用Object.is,一般情况下和三等号的判断相同,它处理了一些特殊情况,比如-0和+0不相等,两个NaN是相等的。
判断数据类型
- typeof:返回该类型的字符串形式,包括:number、boolean、string、undefined、object、function、symbol。缺点:typeof null的值是object,无法分辨是null还是object。
- instanceof:用来判断A是否是B的实例,检测的是原型。缺点:只能用来判断对象是否存在于目标对象的原型链上,不能判断一个对象实例具体属于哪种类型。
- constructor:当一个函数F被定义时,JS引擎会为F添加pprototype原型,然后再在prototype上添加一个constructor属性,并让其指向F的引用。当执行var f = new F()时,F原型上的constructor传递到了f上,因此f.constructor == F。
- toString:是object的原型方法,调用该方法,默认返回当前对象的[[class]],格式为[object xxx],其中xxx就是对象的类型。对于Object对象,直接调用toString()就能返回[object Object],而对于其他对象,则需要通过call/apply,如:
Object.prototype.toString().call([]) //[object Array]
Object.prototype.toString().call(true) //[object Boolean]


判断数组
- Object的toString方法
Object.prototype.toString.call(obj).slice(8,-1) === ‘Array’ - 原型链
obj._ _ proto_ _ === Array.prototype - isArray
Array.isArray(obj) - instanceof
obj instanceof Array
0.1+0.2不等于0.3
- 原因:浮点数运算的精度问题。计算机只认识二进制,由于浮点数用二进制表达时是无穷的,IEEE754标准的64位双精度浮点数的小数部分最多支持53位二进制位,所以两者相加后,因浮点数小数位的限制而截断的二进制数字,再转换为十进制,就成了0.30000000000000004
- 解决方法
(1)转为整数运算
function addNumFun(a,b){
const maxLen = Math.max(
a.toString().split('.')[1].length,
b.toString().split('.')[1].length
)
const base = Math.pow(10,maxLen)
return (a*base + b*base) / base
}
null的类型为什么是Object
第一版的JavaScript是用32位比特来存储值的,且是通过值的低1位或低3位来识别类型的。
1:整型(int)
000:引用类型object
010:双精度浮点型double
100:字符串string
110:布尔型boolean
另外还有两个特殊值:undefined用整数-2^30,不在整型的范围内;null机器码空指针,第三位也是000
字面量创建对象和new对象有什么区别?new内部都实现了什么?
- 字面量:字面量创建对象更简单,方便阅读;不需要作用域解析,速度更快。
- new内部
(1) 创建一个新对象
(2)使新对象的__proto__指向原函数的prototype
(3)改变this指向(指向新的obj)并执行该函数,执行结果保存起来作为result
(4)判断执行函数的结果不是null或者undefined,如果是则返回之前的新对象,否则返回result - js实现一个new方法
function _new(constructer, ...arg) {
// 创建一个空的对象
let resultObj = {};
// 链接该对象到原型,这样新对象就能访问到原型上面的方法
resultObj.__proto__ = constructer.prototype;
// 然后实现步骤3,将新创建的对象作为this的上下文
let result = constructer.call(resultObj, ...arg);
// 实现步骤4:如果该函数没有返回对象(即result不是一个对象),则返回this(即resultObj)
return typeOf result === 'object' ? result : resultobj
}
Object静态方法
静态方法:指部署在Object对象自身的方法。
- Object.keys():参数是一个对象,返回一个数组,数组成员是该对象自身的(不包含继承的)所有属性名。只返回可枚举属性。
- Object.getOwnPropertyNames():与Object.keys()类似,对于一般的对象来说,这两个返回的结果是一样的,只有涉及不可枚举属性时,才会有不一样的结果。Object.getOwnPropertyNames()还返回不可枚举的属性(比如数组的length)。
- 其他静态方法:
Object.defineProperty():通过描述对象,定义某个属性。
Object.freeze():冻结一个对象。
Object.create():该方法可以指定原型对象和属性,返回一个新的对象。
Object.getPrototypeOf():获取对象的prototype对象。
Object实例方法
- Object.prototype.valueOf():返回当前对象对应的值。
- Object.prototype.toString():返回当前对象对应的字符串形式。
- Object.prototype.hasOwnProperty():判断某个属性是否为当前对象自身的属性,还是继承自原型对象的属性。
闭包
- 定义:在一个函数内部有权访问另一个函数内部的变量,本质是在一个函数内部创建另一个函数。
- 闭包特性:
(1)函数嵌套函数
(2)函数内部可以引用函数外部的参数和变量
(3)参数和变量不会被垃圾回收机制回收 - 好处
(1)包含函数内的变量安全,实现封装,避免命名冲突
(2)在内存中维持一个变量,可以做缓存 - 坏处
被引用的变量不能被销毁,增大了内存消耗,造成内存泄漏,解决方法是可以在使用完变量后手动为他赋值为null - 闭包的使用场景
(1)函数防抖、节流:需要一个变量保存计时,考虑维护全局纯净,可以借助闭包。
(2)setTimeout:原生的setTimeout传递的第一个函数不能带参数,通过闭包可以实现传参效果。
function f1(a) {
function f2() {
console.log(a);
}
return f2;
}
var fun = f1(1);
setTimeout(fun,1000);//一秒之后打印出1
- 闭包应用
自由变量的查找,是在函数定义的地方,向上级作用域查找,不是在执行的地方。
(1)函数作为参数被传递
function print(fn){
const a = 200
fn()
}
const a = 100
function fn(){
console.log(a)
}
print(fn) // 100
(2)函数作为返回值被返回
function create(){
const a = 100
return function(){
console.log(a)
}
}
const fn = create()
const a = 200
fn() // 100
- 应用实例:比如缓存工具,隐藏数据,只提供API
function createCache(){
const data = {} //闭包中被隐藏的数据,不被外界访问
return {
set:function(key,val){
data[key]=val
},
get:function(key){
return data[key]
}
}
}
const c = createCache()
c.set('a',100)
console.log(c.get('a')) // 100
JS常见内存泄漏及解决方法
- 意外的全局变量:使用var、let、const声明,或者js使用严格模式 use strict
- 闭包:不要滥用闭包,使用完之后设置为null
- 定时器:使用完之后清除,clearInterval或clearTimeout
- 事件监听:DOM.addEventListener(“click”, callback),手动解除DOM.removeEventListener(“click”,callback)
- 元素引用没有清理:var a = document.getElementById(‘id’);
document.body.removeChild(a);虽然元素被移除了,但因为存在着变量a对它的引用,DOM元素还在内存里,解决方法:a=null - 控制台日志记录console.log()
原型和原型链
- 原型:每个JavaScript对象(null除外)在创建的时候就会与之关联另一个对象,这个对象就是原型。
(1)prototype:函数的prototype属性指向了一个对象,这个对象正是调用该构造函数而创建的实例的原型,prototype带有__proto__和constructor。
(2)proto:每个JavaScript对象(null除外)都具有的一个属性,叫__proto__,这个属性指向了创建该对象的构造函数的原型。 - 原型链:每个实例对象都有一个__proto__私有属性,指向他的构造函数的原型对象prototype,该原型对象也有一个自己的原型对象__proto__,层层向上直到一个对象的原型对象为null。

null和undefined的区别
undefined代表未定义,null代表空对象(主要用于对象初始化)
- null表示没有对象,即该处不应该有值,典型用法:
(1)作为函数的参数,表示该函数的参数不是对象
(2)作为对象原型链的终点 - undefined表示缺少值,此处应该有一个值,但是还没有定义,典型用法:
(1)变量被声明但没有赋值
(2)调用函数时,应该提供的参数没提供
(3)对象没有赋值的属性
(4)函数没有返回值时默认返回undefined
浅拷贝和深拷贝
- 浅拷贝
(1)for in循环赋值
(2)解构赋值 var newObj = { …obj }
(3)var newObj = Object.assign( {},obj )
第一层的没有改变,一层以下就被改变了 - 深拷贝
(1)递归循环
(2)JSON.parse(JSON.stringify)function isObject(o){ return Object.prototype.toString.call(o) === '[object Object]' || Object.prototype.toString.call(o) === '[object Array]' } function deepClone(o){ if (isObject(o)) { let obj = Array.isArray(o) ? [] : {} for(let item in o){ if(isObject(o[item])){ obj[item] = deepClone(o[item]) }else{ obj[item] = o[item] } } return obj } else { return o } }
(3)lodash的cloneDeep方法
(4)jQuery的extend方法
JSON.parse(JSON.stringify())的缺点:
(1)obj里有date,拷贝后时间会变成字符串的形式,而不是时间对象;
(2)obj里有RegExp、Error对象,序列化的结果会变成空对象{};
(3)obj里有function、undefined,会丢失;
(4)obj里有NaN、Infinity和-Infinity,会变成null;
(5)JSON.stringify()只能序列化对象的可枚举的自有属性,如果obj中的对象 是由构造函数生成的实例对象,深拷贝后,会丢弃对象的constructor。
常用的lodash方法:
(1)深拷贝:cloneDeep()
(2)对象数组排序:lodash.uniqBy(arr, ‘diagnoseCode’)
(3)比较两个对象是否相同:_.isEqual(this.initTableForm, this.tableForm)
线程和同步
- 单线程
js是单线程的,即js只能在一个线程上运行 - 消息队列(任务队列)
JavaScript运行时,除了一个运行线程,引擎还提供一个消息队列,里面是各种需要当前程序处理的消息。新的消息进入队列的时候,会自动排在队列的尾端。
同步任务:在主线程排队支持的任务,前一个任务执行完毕后,执行后一个任务,形成一个执行栈。
异步任务:异步任务会被主线程挂起,不会进入主线程,而是进入消息队列,而且必须指定回调函数,只有消息队列通知主线程,并且执行栈为空时,该消息对应的任务才会进入执行栈获得执行的机会。 - 宏任务(macrotask)和微任务(microtask):异步任务的两个分类。
宏任务:script、setTimeout、setInterval、setImmediate
微任务:promise.then、process.nextTick、Object.observe、MutationObserve
执行过程:
(1)执行宏任务script
(2)进入script后,所有的同步任务主线程执行
(3)所有宏任务放入宏任务执行队列
(4)所有微任务放入微任务执行队列
(5)先清空所有的微任务队列
(6)再取一个宏任务,执行,再清空微任务队列
(7)依次循环
箭头函数和普通函数的区别
- this指向:箭头函数的this指向它定义时所在的对象,普通函数this指向调用时所在的对象
- 箭头函数不会进行函数提升
- 没有arguments对象,不能使用arguments,如果想要获取参数的话可以使用rest运算符
- 没有yield属性,不能作为生成器Generator使用
- 不能当作构造函数new,原因:
(1)没有自己的this,不能使用call和apply
(2)没有prototype,new关键字内部需要把新对象的__proto__指向函数的prototype
构造函数的arguments:类数组

箭头函数的rest:
var foo = (...args) => {
console.log(args) // [1,2,3]
}
foo(1,2,3)
代理
- 定义:在访问对象前添加一层拦截,可以过滤很多操作。
- 定义方式:
(1)字面量定义,对象里面的get和set
(2)类定义,class里面的get和set
(3)Proxy对象,传两个参数,第一个是目标对象target,第二个对象是放set和get的handler对象。Proxy和上面两个的区别在于Proxy专门对对象的属性进行get和set - 代理的实际应用:
(1)Vue的双向绑定:Vue2用的是Object.defineProperty,Vue3用的是Proxy
(2)校验值
(3)计算属性值
跨域
-
JSONP:JSONP利用了script标签可以任意跨域的特点实现的。img的src、link的href、script的src都没有被同源策略限制到。缺点:只支持get请求。
(1)原生js实现:<script> var script = document.createElement('script'); script.type = 'text/javascript'; // 传参一个回调函数名给后端,方便后端返回时执行这个在前端定义的回调函数 script.src = 'http://www.domain2.com:8080/loginuser=admin&callback=handleCallback'; document.head.appendChild(script); // 回调执行函数 function handleCallback(res) { alert(JSON.stringify(res)); } </script>(2)jQuery Ajax实现
$.ajax({ url:'', type:'GET', dataType:'jsonp', success:function(data){ console.log(data) } })(3)Vue axios实现
this.$http = axios this.$http.jsonp(url,{ params:{}, jsonp:'handleCallback' }).then(res => { console.log(res) }) -
document.domain + iframe:只有在主域相同的时候才使用它
-
location.hash + iframe
-
window.name + iframe
-
CORS:通过自定义请求头来让服务器和浏览器进行沟通
-
nginx代理跨域:nginx模拟一个虚拟服务器,因为服务器与服务器之间是不存在跨域的;发送数据时,客户端 -> nginx -> 服务端;返回数据时,服务端 -> nginx -> 客户端
-
vue 配置proxy代理,原理:在本地运行npm run serve等命令时实际上是用node运行了一个服务器,因此proxy实际上是将请求发给自己的服务器,再由服务器转发给后台服务器,做了一层代理。
回流和重绘
- 回流:当节点树中的部分或全部元素因为需要改变尺寸、布局或隐藏而需要重新构建,这个过程叫作回流。回流必将引起重绘。
- 重绘:节点树中一部分元素改变,而不影响布局的,只影响外观的,比如颜色,该过程叫作重绘。
- 如何减少回流和重绘?
(1)减少样式的操作:通过class一次性修改样式,而非一个一个改
(2)避免频繁直接访问计算后的样式,而是先将信息保存下来
事件冒泡和事件捕获有什么区别
DOM2级事件规定事件流包含三个阶段:事件捕获阶段、目标阶段、事件冒泡阶段。
DOM2级事件定义了两个方法:addEventListener()和removeEventListener(),包含三个参数:第一个参数是要处理的事件方式(如click-);第二个是事件处理的函数,可以是匿名函数,也可以是具名函数,但如果需要删除事件,必须是剧名函数;第三个参数是一个布尔值,true表示在捕获阶段调用事件处理程序,false表示在冒泡阶段,默认是false
- 事件冒泡:从下至上执行
- 事件捕获:从上至下执行
防抖和节流
- 防抖:n秒后再执行该事件,如果在n秒内被重复触发,则重新计时。
防抖应用场景:function debounce (fn,delay) { let timer return function () { if(timer) clearTimeout(timer) timer = setTimeout(fn,delay) } }
(1)每次resize/scroll触发统计事件
(2)文本输入的验证(连续输入文字后发送ajax请求进行验证,验证一次就好) - 节流:n秒内只运行一次,如果在n秒内重复触发,只有一次生效。
节流应用场景:function throttle (fn,delay) { let timer return function () { if(!timer){ timer = setTimeout(() => { timer = null fn() },delay) } } }
(1)DOM元素的拖拽功能实现
(2)监听滚动事件判断是否到页面底部自动加载更多
call apply bind
- 都是用来重定义this这个对象的
- bind返回的是一个函数,必须调用它才会执行
- 第一个参数都是this的指向对象,call和bind后面的参数以逗号分隔,apply第二个参数是数组
- call和apply都是改变上下文中的this并立即执行这个函数,bind方法可以让函数想什么时候调用就什么时候调用,并且可以将参数在调用的时候添加。
var a = { user:"追梦子", fn:function(e,d,f){ console.log(this.user); //追梦子 console.log(e,d,f); //10 1 2 } } var b = a.fn; var c = b.bind(a,10); c(1,2);
for in 和 for of 区别
- for in遍历的是数组的索引值(键名);for of遍历的是元素值
- for in的缺陷:索引是字符串类型的数字,不能直接进行几何运算;遍历顺序可能不是实际的内部顺序;for in会遍历数组所有的可枚举类型,包括原型通常配合hasOwnProperty()方法来判断某个属性是否是该对象的实例属性,来将原型对象从循环中剔除(arr.hasOwnProperty(key)或Object.prototype.hasOwnProperty.call(arr,key))
Array.prototype.method=function(){} var myArray=[1,2,4]; myArray.name="数组"; for (var index in myArray) { console.log(myArray[index]); //0,1,2,method,name } for (var value of myArray) { console.log(value); //1,2,4 } - for in更适合遍历对象,for of更适合遍历数组
forEach filter map
- forEach:没有返回值;不支持break、return、continue;删除自身元素index不会被重置;for循环可以控制循环起点(i初始化的数字),forEach只能从0开始;for循环可以修改索引,forEach不能。
forEach不能直接改变数组,直接用item=xxx是不能改变的,但是如果用arr[index]就能改变;如果子元素是对象,可以改变对应属性。 - filter:返回一个符合条件的数组,回调函数中有return返回值,返回true时该元素保存到新数组中,不改变原数组。
- map:返回一个新数组,数组中的元素为原始数组调用函数处理后的值,不改变原数组。
存储
- localStorage:关闭浏览器后数据依然保留,没有过期时间,除非手动清除
localStorage.setItem('key','item') localStorage.getItem('key') localStorage.removeItem('key') localStorage.clear() //全部清除 - sessionStorage:当前会话有效,关闭浏览器或标签后失效
- cookie:保存在客户端,可以设置过期时间;存储大小只有4k;在http下cookie是明文传输的,较不安全。
cookie属性:
(1)expire:设置过期时间,不设置则与会话期相同
(2)http-only:不能被客户端更改访问,防止XSS攻击
(3)Secure:只允许在https下传输
(4)Max-age:cookie生成后失效的秒数document.cookie = "username=jay;expire=Thu, 18 Dec 2043 12:00:00 GMT" //删除时,不需要指定cookie的值 document.cookie = "name=;expire=以前的时间" - session
(1)保存在服务器端
(2)session的运行依赖sessionId,sessionId保存在cookie中,如果禁用cookie,可以把sessionId放在url中
(3)session一般用来跟踪用户的状态
(4)session的安全性更高,一般为使服务端性能更佳,会考虑部分信息保存在cookie中。
从浏览器输入URL都经历了什么
- 浏览器先查看浏览器缓存-系统缓存-路由器缓存,如果缓存中有,会直接在屏幕上显示内容,如果没有,跳至第二步操作
- 在发送http请求前,先进行域名解析(DNS解析),获取相应的ip地址
- 进行http请求,三次握手四次挥手建立断开连接
为什么需要三次握手?两次不行吗?其实这是由TCP的自身特点可靠传输决定的,客户端和服务端要进行可靠传输,那么就需要确认双方的接收和发送能力,第一次握手可以确认客户端的发送能力,第二次握手确认了服务端的接收能力和发送能力,第三次握手才可以确认客户端的接收能力,不然容易出现丢包的情况。 - 服务器处理,将数据返回至浏览器
- 浏览器收到响应,从上而下执行代码
HTML渲染过程
- 解析html,创建DOM树
(1)自上而下解析,遇到任何样式(link、style)和脚本(script)都会阻塞
(2)css加载不会阻塞html的解析,但会阻塞dom的渲染
(3)css加载会阻塞后面js语句的执行
(4)js会阻塞html的解析和渲染
(5)没有defer和async标签的script会立即加载并执行
(6)有async标签的js,js的加载执行和html的解析和渲染并行
(7)有defer标签的js,js的加载和html的解析和渲染并行,但会在html解析完成后执行,在触发DOMContentLoaded事件前执行
(8)DOMContentLoaded和onload的区别:DOMContentLoaded在html解析完毕后执行,onload在页面完全加载完成后执行(包括样式和图片) - 解析css,生成css对象模型
- dom和css合并,构建渲染树
- 布局和绘制
- 解析html,创建DOM树
window.loation对象所包含的属性
- search:搜索内容(从问号开始的URL)
- hash:哈希值(从井号#开始的URL)
- host:主机名和当前URL的端口号
- hostname:主机名
- port:端口号
数组常用方法
改变原数组
- push:数组末尾添加一个或多个元素,返回新的数组长度
- pop:删除并返回数组的最后一个元素,若数组为空,返回undefined
- unshift:数组头部添加一个或多个元素,返回新的数组长度
- shift:删除并返回数组的第一个元素
- sort:对数组元素进行排序
- splice(index,num,str1,str2):删除、添加、替换元素,从index位置开始删除num个元素,并将str1、str2从index位置依次插入。返回删除或被替换的值,没有被删除或替换返回空数组。
不改变原数组
- concat:合并两个或多个数组
- join:按指定字符串分割转换成字符串,默认为逗号。
- reverse:将数组倒序。
- slice(start,end): 截取从开始位置到结束位置(不包含结束位置),参数可以是负值,-1表示最后一个元素,-2表示倒数第二个元素,以此类推。
- forEach:调用数组的每个元素,并将元素传递给回调函数。
- filter:过滤数组,符合条件的元素组成一个新数组返回。
- every:对数组中的每一项进行判断,都符合条件返回true,否则返回false。
- map:原数组的每一项执行函数后,返回一个新的数组。
- some:对数组中的每一项进行判断,有一个符合返回true,都不符合返回false。
- reduce:接收一个函数作为累加器,数组中的每个值(从左到右)开始缩减,最终计算为一个值。第一个参数是初始值或者计算结束后的返回值,第二个参数是当前元素,第三个参数可选,当前元素的索引值,第四个元素可先,当前元素所属的数组对象。
- find:返回符合条件的第一个元素的值。
- indexOf(item,start):返回从指定位置开始符合条件的元素第一次出现的位置。
- findIndex:返回符合条件的第一个元素的索引。
- includes:是否包含指定元素,返回true或false。
字符串常用方法(都不改变原字符串)
- charAt(index):返回指定下标位置的字符,index在0-str.length-1,否则返回空串。不带参数和参数为NaN返回第一个字符。
- charCodeAt(index):返回指定下标的字符的unicode编码,index超出范围返回NaN。
- String.fromCharCode(unicode1,unicode2,…,unicodex):返回unicode编码对应的字符串。
- indexOf(searchStr,startIndex):返回指定的子字符串在字符串中首次出现的位置,匹配不到返回-1。
- lastIndexOf(searchStr,startIndex):返回指定的子字符串在字符串中最后出现的位置。
- includes:是否包含指定子字符串,返回true或false。
- slice(startIndex,endIndex):返回从开始位置到结束位置的字符串,不包括结束位置。如果为负数,-1表示最后一个字符,-2表示倒数第二个,依次类推,第一个参数要小于第二个参数,否则返回空字符串。
- substring(startIndex,endIndex):与slice用法一样,但不接受负数的参数。如果是负数或非法参数,返回原字符串。
- substr(startIndex,length):返回从指定位置开始指定长度的子字符串。如果是负数,同slice处理。
- split:字符串转换为数组。
- search(str/regexp):检索指定字符串或与正则表达式匹配的子字符串,返回匹配的子字符串开始的位置。匹配不到返回-1。
- match:返回匹配到的所有字符串组成的数组,无匹配返回null。
- replace:替换字符或正则表示式。
- toUpperCase、toLowerCase:大小写转换。
js常见的设计模式
- 单例模式:不管创建多少个对象都只有一个实例。
const SingleMode = (function () { let instance = null function Single (name) { this.name = name } return function (name) { if (!instance) { instance = new Single(name) } return instance } })() const oA = new SingleMode('jay') const oB = new SingleMode('hll') console.log(oA) // {name:'jay'} console.log(oB) // {name:'jay'} console.log(oA === oB) // true - 工厂模式:工厂模式定义一个用于创建对象的接口,这个接口由子类决定实例化哪一个类。该模式使一个类的实例化延迟到了子类。子类可以重写接口方法以便创建的时候指定自己的对象类型。
function factoryMode (o) { const instance = {} instance.name = o.name instance.age = o.age instance.getInstance = function () { return 'name:' + instance.name + ',age:' + instance.age } return instance } const obj1 = factoryMode({ name: 'jay', age: '18' }) const obj2 = factoryMode({ name: 'hll', age: '5' }) console.log(obj1) // {name:'jay',age:18,getInstance:f()} console.log(obj2) // {name:'hll',age:5,getInstance:f()} - 发布者-订阅者模式:多个订阅者同时监听同一个数据对象,当这个数据对象发生变化的时候会执行一个发布事件,通知所有的订阅者。
- 代理模式:为其他对象提供一种代理以控制对这个对象的访问。
- 迭代器模式:提供一种方法顺序访问一个聚合对象中的各个元素,而又不需要暴露该对象的内部表示。
const each = function (arr, callback) { for (let i = 0; i < arr.length; i++) { // 将值、索引返回给回调函数处理 if (callback(i, arr[i]) === false) { break// 中止迭代器,跳出循环 } } } // 外部调用 each([1, 2, 3, 4, 5], (index, value) => { if (value > 3) { return false // 返回false中止each } console.log([index, value]) // [0,1] [1,2] [2,3] })
js实现继承的几种方式
- 原型继承:将父类的实例作为子类的原型
缺点:来自原型对象的所有属性被所有实例共享;无法向父类构造函数传参。function Parent (name) { this.name = name } function Son () { } Son.prototype = new Parent() Son.prototype.name = 'jay' const son = new Son() console.log(son.name) // jay console.log(son instanceof Parent) // true console.log(son instanceof Son) // true - 构造函数继承:在子类的构造函数中,通过 apply ( ) 或 call ( )的形式,调用父类构造函数,以实现继承。缺点:子类实例不能继承父类的构造属性和方法。
- 组合继承(结合原型和构造函数继承):通过调用父类,继承父类的属性并保留传参的优点(利用call改变this),再通过将父类实例作为子类原型,使父类原型中的方法也能继承,最后改变子类原型中的constructor。缺点:调用了两次父类的构造函数,造成了不必要的消耗。
function Parent (name) { this.name = name } function Son (name, age) { Parent.call(this, name) this.age = age } Son.prototype = new Parent() Son.prototype.constructor = Son const son = new Son('jay', 18) console.log(son) // {name:'jay',age:18} console.log(son instanceof Parent) // true console.log(son instanceof Son) // true - 寄生组合继承:借用构造函数+相当于浅拷贝父类的原型对象。
function Parent (name) { this.name = name } function Son (name, age) { Parent.call(this, name) this.age = age } Son.prototype = Object.create(Parent.prototype) Son.prototype.constructor = Son const son = new Son('jay', 18) console.log(son) // {name:'jay',age:18} console.log(son instanceof Parent) // true console.log(son instanceof Son) // true - class extends继承:寄生组合继承的语法糖
网络原理
- 三次握手和四次挥手
(1)三次握手:第一次握手:客户端像服务端发送一个SYN包,客户端进入SYN_SENT状态,等待服务端确认;第二次握手:服务端收到SYN后,给客户端返回一个SYN+ACK包,表示已收到SYN,并进入SYN_RECEIVE状态;第三次握手:客户端向服务端发送一个ACK包表示确认,双方进入establish状态,连接已建立。
为什么是三次握手?
因为如果只有两次,在服务端收到SYN后,向客户端返回一个ASK就进入establis状态,如果请求中遇到网络问题而没有传给客户端,客户端一直是等待状态,后面服务端发送的信息也接收不了了。
(2)四次挥手:客户端向服务端发送一个FIN包,进入FIN_WAIT1状态;服务端收到后,向客户端发送ACK包确认,进入CLOSE_WAIT状态,客户端接收到ACK包后进入FIN_WAIT2状态;服务端再把剩余没传完的数据发送给客户端,发送完毕后再发送一个FIN+ACK包,进入LAST_ACK(最后确认)状态;客户端收到后,再向服务器发送ACK包,再等待两个周期后关闭连接。
为什么等待两个周期?
因为最后服务端发送的ACK包可能丢失,如果不等待两个周期的话,服务端在没收到ACK包之前,会不停的重复发送FIN包而不关闭。
为什么是四次握手?
服务端在收到客户端的FIN报文后,可能还有一些数据要传输,所以不能马上关闭,但是会做出应答,返回ACK报文段,再发送完数据后,再向客户端发送FIN报文,表示数据已经发送完毕,请求关闭连接。 - http状态码
(1)2 开头的表示成功 一般是200
(2)3 开头的表示重定向
301永久重定向
302临时重定向
304资源未被修改,可以在缓存中取数据
(3)4 开头表示客户端错误
403跨域,没权限
404请求资源不存在
(4)5 开头表示服务端错误
500服务器错误
504网关超时 - http1.0、http1.1、http2有什么区别?
(1)http0.9只能进行get请求
(2)http1.0增加了post、head、option、put、delete等
(3)http1.1增加了长连接keep-alive,增加了host域,并且节约宽带
(4)http2多路复用,头部压缩,服务器推送 - http和https有什么区别?https的实现原理?
(1)http无状态连接,而且是明文传输,不安全
(2)https传输内容加密,身份验证,保证数据完整性

正则表达式
- 语法:/正则表达式主体/修饰符
- test方法检测一个字符串是否匹配某个模式,返回true或false
- exec方法检索字符串中的正则表达式的匹配,返回数组,其中存放匹配的结果,匹配不到返回null
- 元字符
\d 查找数字
\s 查找空白字符
\b 匹配单词边界
\uxxxx 查找以十六进制数规定的unicode字符 - 方括号
[abc] 查找方括号之间的任意字符
[0-9] 查找任何从0到9的数字
(x|y) 查找任何以|分隔的字符 - 量词
n+ 至少含有一个
n* 0个多多个
n? 0个或1个
js末尾必须加分号的情况
如果下一行的第一个字元是下面5个字符之一,JavaScript将不对上一行句尾添加分号:“(”、“[”、“/”、“+”、“-”
js获取地址栏参数
const str = 'http://baidu.com?name=jay&age=18&sex=0'
const arr = str.slice(str.indexOf('?') + 1).split('&')
const obj = {}
arr.forEach(item => {
const tempArr = item.split('=')
obj[tempArr[0]] = tempArr[1]
})
console.log(obj)
关于跨域请求
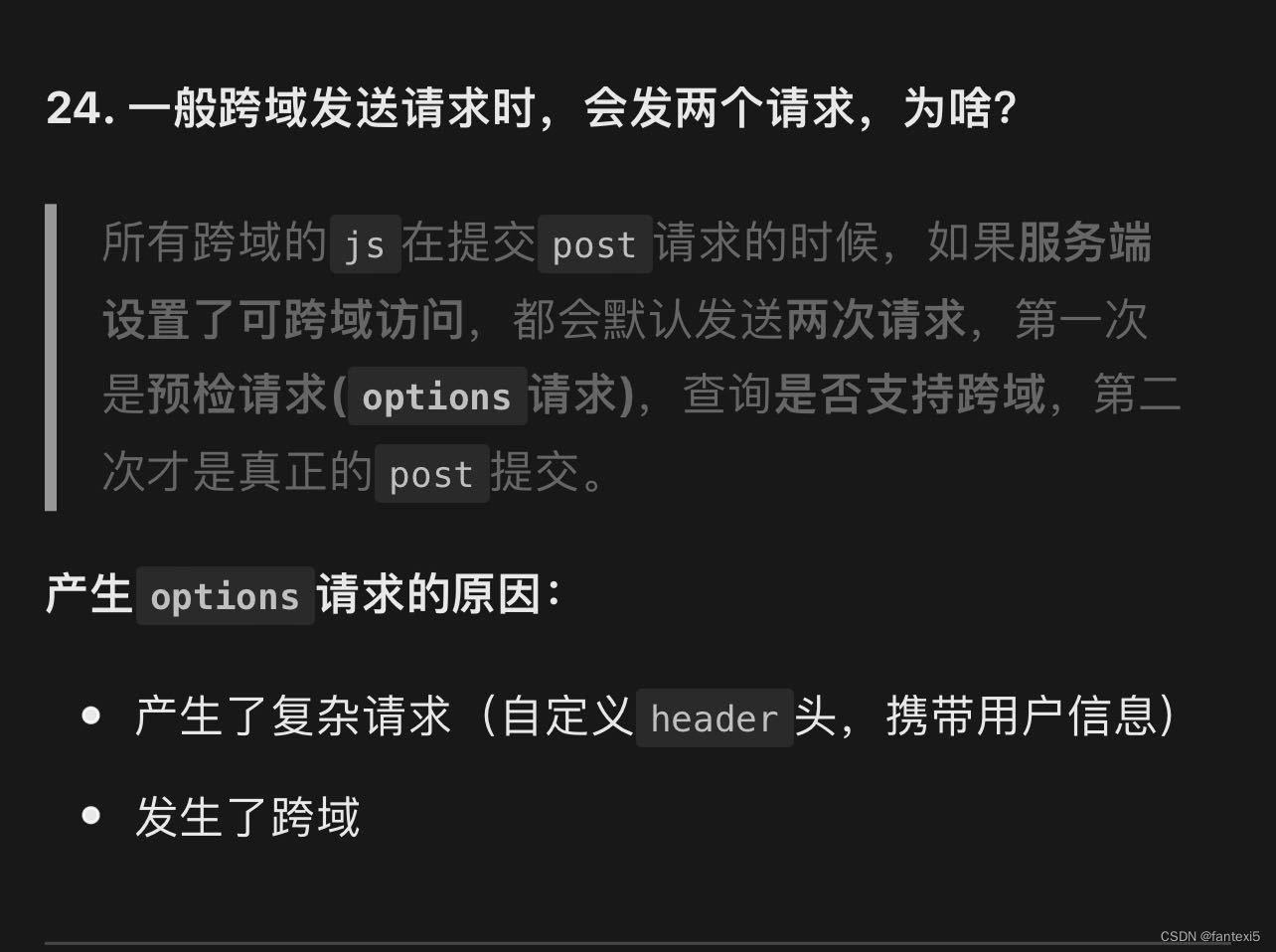
http和webSocket
http无法让服务端主动去发送信息,为了解决这个问题,我们有三种常见的解决方案:短轮询、长轮询、webSocket
- 短轮询:就是不断的间隔一段时间发一个http请求,直到拿到需要的信息才结束。
- 长轮询:向客户端发送一个http请求,服务端长时间将连接挂起,长时间不返回数据,直到拿到需要的信息才返回。
- webSocket:和http一样都是基于TCP的应用层协议,可以让服务器将数据主动推送给客户端。默认端口是80和443;协议标识符是ws,如果加密是wss;没有同源限制,客户端可以与任意服务器通信。
webSocket用法:
// 创建一个webSocket对象
var ws = new webSocket('wss://webchat-bj-test5.clink.cn')
// 实例化对象的onopen属性,用于指定连接成功后的回调函数
ws.onopen = function(evt){
ws.send('hello')
}
// 实例化对象的onmessage属性,用于指定收到服务器数据后的回调函数
ws.onmessage = function(evt){
console.log(evt.data)
ws.close()
}
// 实例化对象的onclose属性,用于指定连接关闭后的回调函数
ws.onclose = function(evt){
}
- 比较:短轮询实现简单,但浪费带宽和服务器资源;
长轮询可以减少请求数量和带宽,但要考虑意外关闭的情况,实现复杂。
给一个ul下面插入100个li应该怎么插入?如何优化dom操作?
var ul = document.getElementById('ul')
for(var i=0;i<100;i++){
var li = document.createElement('li')
li.innerHTML = 'index:' + i
ul.appendChild(li)
}
优化dom操作:使用DocumentFragment,它是没有父节点的最小的文档对象,用于存储HTML和XML片段。
var ul = document.getElementById('ul')
var fragment = document.createDocumentFragment()
for(var i=0;i<100;i++){
var li = document.createElement('li')
li.innerHTML = 'index:' + i
fragment .appendChild(li)
}
ul.appendChild(fragment)















 767
767











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









