







目录
一、开场白
1. 自我介绍
2. 项目经历
注意使用STAR法则表述进行表述:背景、过程、方式(你担任的角色)、成果
二、软件测试基础
工作内容
结合项目细聊工作内容
测试方法
- 怎么测试一个接口
- 软件测试方法?
- 黑盒测试和白盒测试
- 1990.01到2020.12等价类划分怎么设计测试用例
- 正则表达式的匹配
匹配一行空格?匹配数字、字母,出现的次数随机? - 异常 常见的异常?
- 目前主要的防御方式,注入型的漏洞具体怎么解决
- SQL注入
- 接口自动化分层设计浅谈
测试文档
自动化测试
测试工具
- 用过哪些测试工具
postman、jmeter、fiddler、java+testNG框架
性能测试
梳理明确压测的目的和步骤:
- 首先我们得知道一个实例在当前线上的硬件条件下的性能表现的极限是多少,即满足99线以及SLA的条件下,能到达的峰值TPS
- 我们的目标值是多少,即在99线为多少的时候,SLA应该在1.0附近,TPS是多少(每秒处理的请求数)(一个实例)
如何定位问题以及优化
游戏测试
三、软件测试实战
排查问题的思路
- 缓存击穿的原因
- 访问一个页面响应慢,是什么原因?
- 怎么判断前端还是后端问题
前端bug:界面显示、字段校验、兼容性【浏览器的解析不一致】
前端bug分为3类:HTML、CSS、Javascript
区别方法:
| 样式问题 | CSS |
|---|---|
| 文本问题 | HTML |
| 交互类问题 | Javascript |
前端bug定位:F12在console中查看报错信息,对于出错的js可以在Sources下查看对应报错的资源文件
后台bug:逻辑【数据相关、排序错误】、性能和安全性有关
页面功能实现-谷歌浏览器F12开发者工具Network一栏
- 请求URL是否正确,错误-前端bug
- 请求参数是否正确,错误-前端bug
- 接口URL和参数都正确,响应内容错误,后台bug
- 一个button, 点击后两种情况 1.没反应 2.跳转报错, 怎么查找是前端还是后端的错误
- 在项目中,A依赖B的模块,但是中间出现问题,你怎么解决?
实战案例
功能/安全/兼容/性能/易用/外观
- 一个产品在1.0版本的基础上进行了一次迭代,现在将它交给你进行测试,如何入手
- a/b
- 加入购物车-购物车-结算
- 支付功能
- 余额宝
- 微信视频
- 电梯
- 饮料售卖机
- 水杯
- app中分享抢红包
- 移动单车扫码
- 有一个带logo的纸杯,怎么对它进行测试。(给提示,比如说杯子的材料,耐热耐冷,杯子的气味,材料;极限的测试,最高最低多少度,装入的液体是否会与纸杯发生化学反应)
- 圆形下水井盖相对于方形的优势是?
在同等用材的情况下他的面积最大
如果是方的、长方的或椭圆的,那无聊之徒拎起来它就可以直接扔进地下道啦!但圆形的盖子嘛,就可以避免这种情况了
四、语言基础
Java
- ArrayList 和 LinkedList 的区别
1、数据结构不同
ArrayList是Array(动态数组)的数据结构,LinkedList是Link(链表)的数据结构。
2、效率不同
当随机访问List(get和set操作)时,ArrayList比LinkedList的效率更高,因为LinkedList是线性的数据存储方式,所以需要移动指针从前往后依次查找。
当对数据进行增加和删除的操作(add和remove操作)时,LinkedList比ArrayList的效率更高,因为ArrayList是数组,所以在其中进行增删操作时,会对操作点之后所有数据的下标索引造成影响,需要进行数据的移动。
3、自由性不同
ArrayList自由性较低,因为它需要手动的设置固定大小的容量,但是它的使用比较方便,只需要创建,然后添加数据,通过调用下标进行使用;而LinkedList自由性较高,能够动态的随数据量的变化而变化,但是它不便于使用。
4、主要控件开销不同
ArrayList主要控件开销在于需要在lList列表预留一定空间;而LinkList主要控件开销在于需要存储结点信息以及结点指针信息。 - List、Set、Map的区别
- 封装 继承 多态 面向对象三要素的理解
- map 与 hashmap 的区别
- hashmap底层
- Jenkins会用吗 容器
- JVM运行时区域
- HashCode怎么计算(考虑哪些东西)
- HashCode的作用(映射)
- 内存泄漏
- 描述一下JAVA的反射机制 为什么JAVA能实现反射C++不能
- 描述一下生产者和消费者的模式 多线程和单线程在代码上的主要的区别
- java八大基础类型
byte short int long floate double char boolean - Java内存分为哪些部分
- static关键字的作用
- final关键字的作用
- 反射的定义
- gc机制 会马上执行嘛?可以手动?
- 垃圾回收机制
- ==和equals的区别
Python
- is和==的区别
| is | 比较的是两个对象的id值是否相等,也就是比较俩对象是否为同一个实例对象,是否指向同一个内存地址 |
|---|---|
| == | 比较的是两个对象的内容是否相等,默认会调用对象的__eq__()方法 |
-
python中的面向对象的特性(封装继承多态)
封装
封装有两个方面的含义:把该隐藏的隐藏起来,把该暴露的暴露出来
只要将 Python 类的成员命名为以双下画线开头的,Python 就会把它们隐藏起来
继承
class 类名(父类1, 父类2, …):按照顺序优先级,同名函数,顺序优先
多态
当同一个变量在调用同一个方法时,完全可能呈现出多种行为(具体呈现出哪种行为由该变量所引用的对象来决定) -
python中的列表常用方法
- list.append(obj) 在列表末尾添加新的对象。一次性只能添加一个元素
>>> name = list("scott")
>>> name
['s', 'c', 'o', 't', 't']
>>> name.append(list(" tiger"))
>>> name
['s', 'c', 'o', 't', 't', [' ', 't', 'i', 'g', 'e', 'r']]
- list.count(obj) 统计某个元素在列表中出现的次数
>>> name = list("scott")
>>> name
['s', 'c', 'o', 't', 't']
>>> name.count('s')
1
>>> name.count("t")
2
>>> name.count("A")
0
>>> name.append(list("Python"))
>>> name
['s', 'c', 'o', 't', 't', ['P', 'y', 't', 'h', 'o', 'n']]
>>> name.count(['P', 'y', 't', 'h', 'o', 'n'])
1
- list.extend(seq) 在列表末尾一次性追加另一个序列中的多个值(用新列表扩展原来的列表)
>>> name = list("scott")
>>> name
['s', 'c', 'o', 't', 't']
>>> name.extend(list(" tiger"))
>>> name
['s', 'c', 'o', 't', 't', ' ', 't', 'i', 'g', 'e', 'r']
- list.index(obj) 从列表中找出某个值第一个匹配项的索引位置
>>> name = list("scott")
>>> name
['s', 'c', 'o', 't', 't']
>>> name.index('t') ##第一个字母t的索引位置是3
3
>>> name.index('a')
Traceback (most recent call last):
File "<stdin>", line 1, in ?
ValueError: list.index(x): x not in list
>>> 'a' in name
False
>>> 'a' not in name
True
- list.insert(index, obj) 将对象插入列表,俩参数,第一个是索引位置,第二个插入的元素对象
>>> name = list("scott")
>>> name
['s', 'c', 'o', 't', 't']
>>> name.insert(2,'tiger') ##在索引为2的地方插入字符串tiger
>>> name
['s', 'c', 'tiger', 'o', 't', 't']
- list.pop([index=-1]) 移除列表的一个元素(默认最后一个),并返回元素值
>>> name = list("scott")
>>> name
['s', 'c', 'o', 't', 't']
>>> name.pop()
't'
>>> name
['s', 'c', 'o', 't']
>>> name.append("t")
>>> name
['s', 'c', 'o', 't', 't']
- list.remove(obj) 移除列表某个值的一个匹配项。如果有俩个相等的元素,就只是移除匹配的一个元素,如果某元素不存在某列表中,便会报错,而且一次性只能移除一个元素
>>> name = list("scott")
>>> name
['s', 'c', 'o', 't', 't']
>>> name.remove("t") #去掉第一个t
>>> name
['s', 'c', 'o', 't']
>>> name.remove("A") #不存在会报错
Traceback (most recent call last):
File "<stdin>", line 1, in ?
ValueError: list.remove(x): x not in list
>>> "A" not in name
True
>>> name.remove("s","c") #一次只能移除一个元素
Traceback (most recent call last):
File "<stdin>", line 1, in ?
TypeError: remove() takes exactly one argument (2 given)
- list.reverse() 反向列表中元素
>>> name = list("scott")
>>> name
['s', 'c', 'o', 't', 't']
>>> name.reverse()
>>> name
['t', 't', 'o', 'c', 's']
- list.sort( key=None, reverse=False) 对列表进行排序,修改原列表,不会返回一个已排序的列表副本
>>> result = [8,5,5,3,9]
>>> result.sort()
>>> result
[3, 5, 5, 8, 9]
如果我们想要返回一个已排序的列表副本,而不影响原来的列表呢,一种方法,我们可以先复制原来列表(可以用分片赋值复制),然后在复制的列表上做sort操作,另一种方法,就是使用sorted函数,它会返回已排序的列表副本:
>>> result = [8,5,5,3,9]
>>> result2 = sorted(result)
>>> result
[8, 5, 5, 3, 9]
>>> result2
[3, 5, 5, 8, 9]
- list.clear() 清空列表
- list.copy() 复制列表
- python中深拷贝浅拷贝的区别
首先深拷贝和浅拷贝都是对象的拷贝,都会生成一个看起来相同的对象,他们本质的区别是拷贝出来的对象的地址是否和原对象一样,也就是地址的复制还是值的复制的区别
深拷贝就是完全跟以前就没有任何关系了,原来的对象怎么改都不会影响当前对象
浅拷贝,原对象的list元素改变的话会改变当前对象,如果当前对象中list元素改变了,也同样会影响原对象。
python中的深拷贝和浅拷贝
Python 直接赋值、浅拷贝和深度拷贝解析
- 重载
五、数据结构与算法
链表
数组
- 数组和链表的区别?适用?
- 使用链表结构可以克服数组需要预先知道数据大小的缺点
- 链表结构可以充分利用计算机内存空间,实现灵活的内存动态管理
- 但是链表失去了数组随机读取的优点
- 同时链表由于增加了结点的指针域,空间开销比较大
排序
- 对各个排序算法 稳定性、时间复杂度的描述
1、稳定性
选择排序、快速排序、希尔排序、堆排序不是稳定的排序算法,
冒泡排序、插入排序、归并排序和基数排序是稳定的排序算法。
2、时间复杂度 - 冒泡法: 最慢的算法
最好的情况,n-1次比较,移动次数为0,时间复杂度为O(n)
最坏的情况,n(n-1)/2次比较,等数量级的移动,时间复杂度为O(n^2)
复杂度为O(n*n)。当数据为正序,将不会有交换。复杂度为O(0)。 - 选择排序:O(n*n) 不关心表的初始次序
- 直接插入排序:O(n*n)
最好的情况,如果原来本身就是有序的,比较次数为n-1次(分析(while (j >= 0 && temp < R[j]))这条语句),时间复杂度为O(n)
最坏的情况,原来为逆序,比较次数为2+3+…+n=(n+2)(n-1)/2次,而记录的移动次数为i+1(i=1,2…n)=(n+4)(n-1)/2次
如果序列是随机的,根据概率相同的原则,平均比较和移动的次数为n^2/4 - 快速排序:平均时间复杂度log2(n)*n,所有内部排序方法中最高好的,大多数情况下总是最好的。
- 归并排序:log2(n)*n
- 堆排序:log2(n)*n
- 希尔排序:算法的复杂度为n的1.2次幂 初始序列对元素的比较次数有关

3、性能
- 对于一般的随机序列顺序表而言,上述几种排序算法性能从低到高的顺序大致为:冒泡排序、插入排序、选择排序、希尔排序、快速排序
- 对于序列初始状态基本有正序,可选择对有序性较敏感的如插入排序、冒泡排序、选择排序等方法
- 对于序列长度比较大的随机序列,应选择平均时间复杂度较小的快速排序方法
冒泡排序:通过与相邻元素的比较和交换来把小的数交换到最前面
例:5,3,8,6,4
5,3,8,4,6
5,3,4,8,6
3,5,4,8,6
一次冒泡,把最小的数3排到最前面
时间复杂度:O(n^2)
选择排序:一次排序后把最小的元素放到最前面,对整体的选择
- 选5外最小的数和5交换
3,5,8,6,4
3,4,8,6,5
3,4,5,6,8
时间复杂度:O(n^2)
直接插入排序:通过比较找到合适的位置插入元素来达到排序的目的,也叫缩小增量排序
3,5,8,6,4
3,5,6,8,4
3,4,5,6,8
时间复杂度:O(n^2)
待排序列是正序时,时间复杂度是O(n)
** 快速排序**:来自冒泡,比较和交换小数和大数,不仅把小数冒泡到上面同时也把大数沉到下面
右指针找比基准数小的,左指针找比基准数大的,交换之
5,3,8,6,4
1、用5作为比较的基准,最终会把5小的移动到5的左边,比5大的移动到5的右边
2、首先设置i,j两个指针分别指向两端,j指针先扫描(思考一下为什么?)4比5小停止。然后i扫描,8比5大停止。交换i,j位置
5,3,4,6,8
3、然后j指针再扫描,这时j扫描4时两指针相遇。停止。然后交换4和基准数
4,3,5,6,8
一次划分后达到了左边比5小,右边比5大的目的
之后对左右子序列递归排序,最终得到有序序列
- 为什么一定要j指针先动呢?
首先这也不是绝对的,这取决于基准数的位置,因为在最后两个指针相遇的时候,要交换基准数到相遇的位置。一般选取第一个数作为基准数,那么就是在左边,所以最后相遇的数要和基准数交换,那么相遇的数一定要比基准数小。所以j指针先移动才能先找到比基准数小的数
时间复杂度:O(nlgn)
空间复杂度:快速排序在系统内部需要一个栈来实现递归。若每次划分较为均匀,则其递归树的高度为O(lgn),故递归后需栈空间为O(lgn)。最坏情况下,递归树的高度为O(n),所需的栈空间为O(n)
堆排序:思想同简单的选择排序,升序排序就使用大顶堆,反之使用小顶堆。原因是堆顶元素需要交换到序列尾部
实现堆排序需要解决两个问题:
1、如何由一个无序序列建成一个堆?
2、如何在输出堆顶元素之后,调整剩余元素成为一个新的堆?
堆(二叉堆)可以视为一棵完全的二叉树,完全二叉树的一个“优秀”的性质是,除了最底层之外,每一层都是满的,这使得堆可以利用数组来表示(普通的一般的二叉树通常用链表作为基本容器表示),每一个结点对应数组中的一个元素
希尔排序:特点:子序列的构成不是简单的逐段分割,而是将某个相隔某个增量的记录组成一个子序列
如果序列是基本有序的,使用直接插入排序效率就非常高。基本思想是:先将整个待排记录序列分割成为若干子序列分别进行直接插入排序,待整个序列中的记录基本有序时再对全体记录进行一次直接插入排序

归并排序:使用了递归分治的思想,先递归划分子问题,然后合并结果。把待排序列看成由两个有序的子序列,然后合并两个子序列,然后把子序列看成由两个有序序列。。。。。倒着来看,其实就是先两两合并,然后四四合并。。。最终形成有序序列。空间复杂度:O(n)
时间复杂度:O(nlogn)
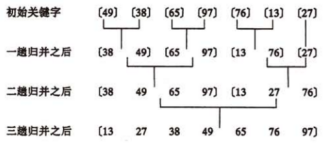
二分法插入排序:在插入第i个元素时,对前面的0~i-1元素进行折半,先跟他们中间的那个元素比,如果小,则对前半再进行折半,否则对后半进行折半,直到left<right,然后再把第i个元素前1位与目标位置之间的所有元素后移,再把第i个元素放在目标位置上
二分插入排序是稳定的与二分查找的复杂度相同;
最好的情况是当插入的位置刚好是二分位置所用时间为O(log₂n);
最坏的情况是当插入的位置不在二分位置所需比较次数为O(n),无限逼近线性查找的复杂度
- 堆排序的实现原理
- 排序算法熟悉吗,快速排序的思想是什么 时间复杂度和空间复杂度
- 100W条数据,找到最小的100条数据,怎么做
树
- 平衡二叉树是什么?
- 怎么计算二叉树的高度?
- 判断一个树的左右子树是否对称
- 查找二叉树中最近的公共祖先
递归
字符串
堆与栈
- 知道堆吗?
- 小顶堆的空间复杂度,时间复杂度,以及建堆原理,更新过程
动态规划
高级算法
查找
哈希
- hashmap的底层结构?
图
- Map的数据结构
- Map的算法有哪些
六、框架
开发框架
开发框架
Spring
- Spring的设计模型
- Spring框架的AoP的实现原理
测试框架
selenium
Appium
Unittest
Pytest
TestNG
Junit
七、计算机基础
计算机网络



-
OSI七层模型
-
7 - 物理层:比特
主要定义物理设备标准,如网线/光纤的接口类型、各种传输介质的传输速率等。它的主要作用是传输比特流(就是由1、0转化为电流强弱来进行传输,到达目的地后在转化为1、0,也就是我们常说的数模转换与模数转换)。这一层的数据叫做比特。 -
6 - 数据链路层: 帧
定义了如何让格式化数据以进行传输,以及如何让控制对物理介质的访问。这一层通常还提供错误检测和纠正,以确保数据的可靠传输。 -
5 - 网络层:数据报
在位于不同地理位置的网络中的两个主机系统之间提供连接和路径选择。Internet的发展使得从世界各站点访问信息的用户数大大增加,而网络层正是管理这种连接的层。 -
4 - 运输层:报文段/用户数据报
定义了一些传输数据的协议和端口号(WWW端口80等),如: TCP(transmission control protocol –传输控制协议,传输效率低,可靠性强,用于传输可靠性要求高,数据量大的数据) ;UDP(user datagram protocol–用户数据报协议,与TCP特性恰恰相反,用于传输可靠性要求不高,数据量小的数据,如QQ聊天数据就是通过这种方式传输的)。 主要是将从下层接收的数据进行分段和传输,到达目的地址后再进行重组。常常把这一层数据叫做段。 -
3 - 会话层:
通过运输层(端口号:传输端口与接收端口)建立数据传输的通路。主要在你的系统之间发起会话或者接受会话请求(设备之间需要互相认识可以是IP也可以是MAC或者是主机名) -
2 - 表示层:
可确保一个系统的应用层所发送的信息可以被另一个系统的应用层读取。例如,PC程序与另一台计算机进行通信,其中一台计算机使用扩展二一十进制交换码(EBCDIC),而另一台则使用美国信息交换标准码(ASCII)来表示相同的字符。如有必要,表示层会通过使用一种通格式来实现多种数据格式之间的转换。 -
1 - 应用层:报文
-
OSI五层协议
-
第五层——应用层 报文
体系结构中的最高层。直接为用户的应用进程提供服务(例如电子邮件、文件传输和终端仿真)。
在因特网中的应用层协议很多,如支持万维网应用的HTTP协议,支持电子邮件的SMTP协议,支持文件传送的FTP协议,DNS,POP3,SNMP,Telnet等。 -
第四层——运输层(transport layer) 报文段/用户数据报
运输层(transport layer):负责向两个主机中进程之间的通信提供服务。由于一个主机可同时运行多个进程,因此运输层有复用和分用的功能。
复用:就是多个应用层进程可同时使用下面运输层的服务。
分用:就是把收到的信息分别交付给上面应用层中相应的进程。
运输层主要使用以下两种协议:
(1) 传输控制协议TCP(Transmission Control Protocol):面向连接的,数据传输的单位是报文段,能够提供可靠的交付。
(2) 用户数据包协议UDP(User Datagram Protocol):无连接的,数据传输的单位是用户数据报,不保证提供可靠的交付,只能提供“尽最大努力交付”。 -
第三层——网络层(network layer)数据报
网络层(network layer)主要包括以下 两个任务:
(1) 负责为分组交换网上的不同主机提供通信服务。 在发送数据时,网络层把运输层产生的报文段或用户数据报封装成分组或包进行传送。在TCP/IP体系中,由于网络层使用IP协议,因此分组也叫做IP数据报,或简称为数据报。
(2) 选中合适的路由,使源主机运输层所传下来的分组,能够通过网络中的路由器找到目的主机。
协议:IP,ICMP,IGMP,ARP,RARP -
第二层——数据链路层(data link layer) 帧
1.数据链路层(data link layer):常简称为链路层,我们知道,两个主机之间的数据传输,总是在一段一段的链路上传送的,也就是说,在两个相邻结点之间传送数据是直接传送的(点对点),这时就需要使用专门的链路层的协议。
2.在两个相邻结点之间传送数据时,数据链路层将网络层交下来的IP数据报组装成帧(framing),在两个相邻结点之间的链路上“透明”地传送帧中的数据。
3.每一帧包括数据和必要的控制信息(如同步信息、地址信息、差错控制等)。典型的帧长是几百字节到一千多字节。 -
第一层——物理层(physical layer) 比特
物理层(physical layer):在物理层上所传数据的单位是比特。物理层的任务就是透明地传送比特流。 -
tcp 四层协议
-
应用层协议都有什么
-
ARP协议,以及在哪一层
ARP:地址解析协议,通过IP地址找到MAC地址,作用于报文
rarp用于mac找ip
2.5 层,一个“非正式”的层。ARP协议是介于链路层和网络层之间的一个协议,你可以说它属于链路层,也可以说它属于网络层 -
http协议中涉及到的协议在哪几层?
-
IP协议在网络,tcp在运输层
-
tcp三次握手和四次挥手的过程
-
time_wait的作用
-
为什么不能二次握手,为什么要四次挥手
-
TCP三次握手是什么?如果有一次握手失败,发生了哪些事情?
TCP/UDP
-
TCP 和 UDP的区别
1、基于连接与无连接
2、对系统资源的要求(TCP较多,UDP少)
3、UDP程序结构较简单
4、流模式与数据报模式
5、TCP保证数据正确性,UDP可能丢包
6、TCP保证数据顺序,UDP不保证 -
长连接和短连接以及它们各自的适用场景
HTTP/HTTPS
- http和https的区别
HTTP
- 明文传输,数据未加密,安全性较差
- HTTP 页面响应速度比 HTTPS 快,主要是因为 HTTP 使用 TCP 三次握手建立连接,客户端和服务器需要交换 3 个包。而 HTTPS除了 TCP 的三个包,还要加上 SSL 握手需要的 9 个包,所以一共是 12 个包。
- 端口号 80
HTTPS
1 HTTP+SSL加密,安全性较好
2 使用 HTTPS 协议需要到 CA(Certificate Authority,数字证书认证机构) 申请证书,一般免费证书较少,因而需要一定费用。证书颁发机构如:Symantec、Comodo、GoDaddy 和 GlobalSign 等
3 端口号 443
4 更耗服务器资源
-
http为什么是没有加密的
-
http的头部包含什么
| Accept | 允许哪些媒体类型 |
|---|---|
| Accept-Charset | 允许哪些字符集 |
| Accept-Encoding | 允许哪些编码 |
| Accept-Language | 允许哪些语言 |
| Cache-Control | 缓存策略 |
| Connection | 连接选项,是否允许被代理 |
| Host | 请求的主机 |
| If-None-Match | 判断请求实体的Etag是否包含在If-None-Match中,如果包含,则返回304,使用缓存,见Etag |
| If-Modified-Since | 判断修改时间是否一致,如果一致,则使用缓存 |
| If-Match | 与If-None-Match相反 |
| If-Unmodified-Since | 与If-Modified-Since相反 |
| Referer | 表明这个请求发起的源头 |
| User-Agent | 经常用来做浏览器检测的userAgent |
- 响应报文的响应头部有什么字段
| Cache-Control | 缓存策略,如max-age:100 |
|---|---|
| Connection | 连接选项,例如是否允许代理 |
| Content-Encoding | 返回内容的编码,如gzip |
| Content-Language | 返回内容的语言 |
| Content-Length | 返回内容的字节长度 |
| Content-Type | 返回内容的媒体类型,如text/html |
| Data | 返回时间 |
| Etag | entity tag,实体标签,给每个实体生成一个单独的值,用于客户端缓存,与If-None-Match配合使用 |
| Expires | 设置缓存过期时间,Cache-Control也会相应变化 |
| Last-Modified | 最近修改时间,用于客户端缓存,与If-Modified-Since配合使用 |
| Pragma | 似乎和Cache-Control差不多,用于旧的浏览器 |
| Server | 服务器信息 |
| Vary | WEB服务器用该头部的内容告诉 Cache 服务器,在什么条件下才能用本响应所返回的对象响应后续的请求。假如源WEB服务器在接到第一个请求消息时,其响应消息的头部为:Content-Encoding: gzip; Vary: Content-Encoding那么 Cache 服务器会分析后续请求消息的头部,检查其 Accept-Encoding,是否跟先前响应的 Vary 头部值一致,即是否使用相同的内容编码方法,这样就可以防止 Cache 服务器用自己 Cache 里面压缩后的实体响应给不具备解压能力的浏览器。 |
- 浏览器中输入一个网址后,发生了什么
- 详细说一下DNS解析过程
- http状态码
由3个十进制数字组成。第一个数字定义状态码类型,共5种类型
| 分类 | 分类描述 |
|---|---|
| 1** | 服务器收到请求,需要请求者继续操作 |
| 2** | 成功,操作被服成功接收并处理 |
| 3** | 重定向,需要进一步的操作以完成请求 |
| 4** | 客户端错误,请求包含语法错误或无法完成请求 |
| 5** | 服务器错误,服务器在处理请求中发生错误 |
HTTP状态码列表
| 状态码 | 英文名称 | 中文描述 |
|---|---|---|
| 100 | Continue(继续) | 继续 客户端继续请求 |
| 101 | Switching Protocols(切换协议) | 切换协议 服务器根据客户端的请求切换协议。只能切换到更高级的协议,例如,切换到HTTP的新版本协议 |
| 200 | OK | 请求成功 一般用于GET和POST请求 |
| 201 | Created(已创建) | 已创建 成功请求并创建了新的资源 |
| 204 | No Content(没有内容) | Response中包含一些Header和一个状态行, 但不包括实体的主题内容(没有response body) 作用:1. 在不获取资源的情况下了解资源的情况(比如判断其类型) 2. 通过查看Response中的状态码, 看看某个对象是否存在 3. 通过查看Header, 测试资源是否被修改了。 |
| 301 | Moved Permanently(永久移除) | 永久移动 请求的资源已被永久的移动到新URI,返回信息会包括新的URI,浏览器会自动定向到新URI。今后任何新的请求都应使用新的URI代替 |
| 302 | Found(已找到) | 临时移动 客户端应继续使用原有URI HTTP 1.0定义 |
| 304 | Not Modified | 未修改 服务器返回此状态码时,不会返回任何资源 客户端通常会缓存访问过的资源,通过提供一个头信息指出客户端希望只返回在指定日期之后修改的资源 |
| 305 | Use Proxy | 使用代理。 代理的地址在Response 的Location中 |
| 307 | Temporary Redirect | 临时重定向。与302类似。使用GET请求重定向 HTTP1.1 |
| 400 | Bad Request | 客户端请求语法错误,服务器无法理解 |
| 401 | Unauthorized(未授权) | 请求要求用户的身份认证 |
| 402 | Payment Required | 保留,将来使用 |
| 403 | Forbidden(禁止) | 服务器理解请求,但拒绝执行 |
| 404 | Not Found | 服务器无法根据客户端请求找到资源 通过此代码,网站设计人员可设置"您所请求的资源无法找到"的个性页面 |
| 405 | Method Not Allowed | 客户端请求的方法被禁止 |
| 500 | Internal Server Error | 服务器内部错误 |
| 501 | Not Implemented(未实现) | 服务器不支持请求的功能 |
| 502 | Bad Gateway | 作为网关或代理的服务器尝试执行请求时,从远程服务器接收到一个无效的响应 |
| 503 | Service Unavailable | 由于超载或系统维护,服务器暂时无法处理客户端请求 延时的长度可包含在服务器的Retry-After头信息中 |
| 504 | Gateway Time-out | 充当网关或代理的服务器,未及时从远程服务器获取请求 |
| 505 | HTTP Version not supported | 服务器不支持请求的HTTP协议版本 |
- HTTP中的cookie和session区别
| 区别 | Cookie | Session |
|---|---|---|
| 数据存储位置不同 | 客户端浏览器 | 服务器 |
| 存储容量不同 | 单个Cookie保存的数据≤4KB 很多浏览器都限制一个站点最多保存20个Cookie | 对于Session并没有上限 但出于对服务器端的性能考虑,Session内不要存放过多的东西,并设置session删除机制 |
| 存取方式不同 | Cookie中只能保管ASCll字符串,需要通过编码的方式存取Unicode字符或者二进制数据。运用Cookie难以实现存储略微复杂的信息 | |
| 安全程度不同 | Cookie对客户端可见,别人可以分析放在本地的Cookie并进行Cookie欺骗 | 考虑到安全应使用session |
| 有效期不同 | 开发可以通过设置Cookie的属性,达到Cookie长期有效的效果 | 由于Session依赖于名为JSESSIONID的cookie,而Cookie JSESSIONID的过期时间默认为-1,只需关闭窗口该Session就会失效,因而Session不能达到长期有效的效果,就算不依赖Cookie,运用URL地址重写也不能完成,因为假如设置Session的超过时间过长,服务器累计的Session就会越多,越容易导致内存溢出 |
| 服务器压力不同 | 对于并发用户十分多的网站,cookie是很好的选择 | Session一定时间内保存在服务器上,每个用户都会产生一个Session,假如并发访问的用户十分多,会产生十分多的Session,耗费大量的内存。考虑到减轻服务器性能方面,应当使用cookie Cookie保管在客户端,不占用服务器资源 |
| 浏览器支持不同 | 假如客户端浏览器不支持Cookie Cookie是需要客户端浏览器支持的。假如客户端禁用了Cookie,或者不支持Cookie,则会话跟踪会失效。关于WAP上的应用,常规的Cookie就派不上用场了。 |
运用Session需要使用URL地址重写的方式。一切用到Session程序的URL都要进行URL地址重写,否则Session会话跟踪还会失效。关于WAP应用来说,Session+URL地址重写或许是它唯一的选择。
假如客户端支持Cookie。
Cookie 既能够设为本浏览器窗口以及子窗口内有效(把过期时间设为−1),也能够设为一切窗口内有效(把过期时间设为某个大于0的整数)。
Session 只能在本窗口以及其子窗口内有效。假如两个浏览器窗口互不相干,它们将运用两个不同的Session。(IE8下不同窗口Session相干。)
跨域支持上的不同|Cookie 支持跨域名访问
例:将 domain 属性设置为“.a.com”,则以“.a.com”为后缀的一切域名均能够访问该Cookie。跨域名Cookie如今被普遍用在网络中,例如,Google、Baidu、Sina等。
Session则不会支持跨域名访问。Session仅在它所在的域名内有效。
9、会话机制不同
session会话机制:session会话机制是一种服务器端机制,它使用类似于哈希表(可能还有哈希表)的结构来保存信息。
cookies会话机制:cookie是服务器存储在本地计算机上的小块文本,并随每个请求发送到同一服务器。 Web服务器使用HTTP标头将cookie发送到客户端。在客户端终端,浏览器解析cookie并将其保存为本地文件,该文件自动将来自同一服务器的任何请求绑定到这些cookie。
-
HTTP协议常见请求方法
-
从协议的层面来讲,这些方法有什么不同?(面试官提示:比如是否可以放进请求体中?)
-
get和post区别
浏览器的GET和POST
GET -
“读取“一个资源:html页面/图片/css/js
-
反复读取不应对访问的数据有副作用,即幂等
-
可以做缓存,浏览器/代理/服务端
-
请求数据有长度限制
-
只读数据
POST
1 用POST来提交一个表单,并得到一个结果的网页
2 不幂等,有副作用。尝试重新执行POST请求,浏览器也会弹一个框提示下这个刷新可能会有副作用,询问要不要继续
3 不能保存为书签
4 写数据 - 增删改
接口中的GET和POST
接口规范REST 【GET】 + 【资源定位符】用于获取资源或资源列表
接口规范REST 【POST】+ 【资源定位符】用于创建一个资源
get和post区别 -
为什么post安全 详细说明
1 HTTP协议中提到GET是安全的方法,因为GET方法只读,不会改变服务器端数据
2 GET请求的参数更倾向于放在url上,因此有更多机会被泄漏
私密数据传输用POST + body就好 -
get和post为什么是不可靠的
因为HTTP是明文协议。每个HTTP请求和返回的每个byte都会在网络上明文传播,不管是url,header还是body
为了避免传输中数据被窃取,必须做从客户端到服务器的端端加密。业界的通行做法就是https——即用SSL协议协商出的密钥加密明文的http数据。这个加密的协议和HTTP协议本身相互独立。如果是利用HTTP开发公网的站点/App,要保证安全,https是最最基本的要求 -
POST和PUT的区别
-
POST所对应的URI并非创建的资源本身,而是资源的接收者
比如:POST http://www.a.com/articles的语义是在http://www.a.com/articles下创建一篇帖子,HTTP响应中应包含帖子的创建状态以及帖子的URI。两次相同的POST请求会在服务器端创建两份资源,它们具有不同的URI;所以,POST方法不具备幂等性。 -
PUT所对应的URI是要创建或更新的资源本身。
比如:PUT http://www.a/articles/1的语义是创建或更新ID为1的帖子。对同一URI进行多次PUT的副作用和一次PUT是相同的;因此,PUT方法具有幂等性。 -
用PUT还是POST创建资源,要看是不是提前可以知道资源所有的数据(尤其是id),以及是不是完整替换。比如对于AWS S3这样的对象存储服务,当想上传一个新资源时,其id就是“ObjectName”可以提前知道;同时这个api也总是完整的replace整个资源。这时的api用PUT的语义更合适;而对于那些id是服务器端自动生成的场景,POST更合适一些
-
为什么post安全 详细说明
因为POST用body传输数据,而GET用url传输,更加容易看到 -
使用post请求传输一个特别大的数据,http是怎么做的
-
HTTP的长连接和短连接?连接是指什么的连接?(TCP)
操作系统
- 死锁的原因,死锁怎么解决
进程/线程
- 怎么理解进程跟线程,二者的区别是什么?
- 进程和线程一个简单解释
进程=火车,线程=车厢 - 进程是资源分配的基本单位;线程是程序执行的基本单位
- 线程在进程下行进(单纯的车厢无法运行)
- 一个进程可以包含多个线程(一辆火车可以有多个车厢)
- 不同进程间数据很难共享(一辆火车上的乘客很难换到另外一辆火车,比如站点换乘)
- 同一进程下不同线程间数据很易共享(A车厢换到B车厢很容易)
- 进程要比线程消耗更多的计算机资源(采用多列火车相比多个车厢更耗资源)
- 进程间不会相互影响,一个线程挂掉将导致整个进程挂掉(一列火车不会影响到另外一列火车,但是如果一列火车上中间的一节车厢着火了,将影响到所有车厢)
- 进程可以拓展到多机,线程最多适合多核(不同火车可以开在多个轨道上,同一火车的车厢不能在行进的不同的轨道上)
- 进程使用的内存地址可以上锁,即一个线程使用某些共享内存时,其他线程必须等它结束,才能使用这一块内存。(比如火车上的洗手间)-"互斥锁"进程使用的内存地址可以限定使用量(比如火车上的餐厅,最多只允许多少人进入,如果满了需要在门口等,等有人出来了才能进去)-“信号量”
假设你经营着一家物业管理公司。最初,业务量很小,事事都需要你亲力亲为。给老张家修完暖气管道,立马再去老李家换电灯泡——这叫单线程,所有的工作都得顺序执行
-
后来业务拓展了,你雇佣了几个工人,这样,你的物业公司就可以同时为多户人家提供服务了——这叫多线程,你是主线程。

-
工人们使用的工具,是物业管理公司提供的,这些工具由大家共享,并不专属于某一个人——这叫多线程资源共享。
-
工人们在工作中都需要管钳,可是管钳只有一把——这叫冲突。解决冲突的办法有很多,比如排队等候、等同事用完后的微信通知等——这叫线程同步。
-
你给工人布置任务——这叫创建线程。之后你还得要告诉他,可以开始了,不然他会一直停在那儿不动——这叫启动线程(start)
-
如果某个工人(线程)的工作非常重要,你(主线程)也许会亲自监工一段时间,如果不指定时间,则表示你会一直监工到该项工作完成——这叫线程参与(join)。
-
业务不忙的时候,你就在办公室喝喝茶。下班时间一到,你群发微信,所有的工人不管手头的工作是否完成,都立马撂下工具,跟你走人。因此如果有必要,你得避免不要在工人正忙着的时候发下班的通知——这叫线程守护属性设置和管理(daemon)。

再后来,你的公司规模扩大了,同时为很多生活社区服务,你在每个生活社区设置了分公司,分公司由分公司经理管理,运营机制和你的总公司几乎一模一样——这叫多进程,总公司叫主进程,分公司叫子进程。
总公司和分公司,以及各个分公司之间,工具都是独立的,不能借用、混用——这叫进程间不能共享资源。各个分公司之间可以通过专线电话联系——这叫管道。各个分公司之间还可以通过公司公告栏交换信息——这叫进程间共享内存。另外,各个分公司之间还有各种协同手段,以便完成更大规模的作业——这叫进程间同步。分公司可以跟着总公司一起下班,也可以把当天的工作全部做完之后再下班——这叫守护进程设置。 -
用过多进程吗,脚本语言有涉及到进程
-
悲观锁和乐观锁,秒杀场景下哪个适用?
乐观锁:乐观锁在操作数据时非常乐观,认为别人不会同时修改数据。
因此乐观锁不会上锁,只是在执行更新的时候判断一下在此期间别人是否修改了数据:如果别人修改了数据则放弃操作,否则执行操作。
悲观锁:悲观锁在操作数据时比较悲观,认为别人会同时修改数据。
因此操作数据时直接把数据锁住,直到操作完成后才会释放锁;上锁期间其他人不能修改数据。
乐观锁的实现方式主要有两种:CAS机制和版本号机制
乐观锁和悲观锁优缺点和适用场景
乐观锁和悲观锁并没有优劣之分,它们有各自适合的场景;下面从两个方面进行说明。
功能限制
与悲观锁相比,乐观锁适用的场景受到了更多的限制,无论是CAS还是版本号机制。
例如,CAS只能保证单个变量操作的原子性,当涉及到多个变量时,CAS是无能为力的,而synchronized则可以通过对整个代码块加锁来处理。
再比如版本号机制,如果query的时候是针对表1,而update的时候是针对表2,也很难通过简单的版本号来实现乐观锁。
竞争激烈程度
如果悲观锁和乐观锁都可以使用,那么选择就要考虑竞争的激烈程度:
- 当竞争不激烈 (出现并发冲突的概率小)时,乐观锁更有优势,因为悲观锁会锁住代码块或数据,其他线程无法同时访问,影响并发,而且加锁和释放锁都需要消耗额外的资源。
- 当竞争激烈(出现并发冲突的概率大)时,悲观锁更有优势,因为乐观锁在执行更新时频繁失败,需要不断重试,浪费CPU资源。
CAS缺点 - ABA问题
- 高竞争下的开销问题:在并发冲突概率大的高竞争环境下,如果CAS一直失败,会一直重试,CPU开销较大
- 功能限制。CAS的功能是比较受限的,例如CAS只能保证单个变量(或者说单个内存值)操作的原子性
Linux
- 查看 当前目录及各子目录下的文件名含关键字 ‘test’ 的文件名
- 查看 当前目录及各子目录下的文件内容含关键字的文件名;
- 用命令修改文件中的内容
- 查看日志
- 实时查看日志文件最后几行:tail -n 50 wx.log
- 查进程:ps -aux | less -N
- tar:压缩和解压文件
- 处理日志的命令、find命令
- 统计日志文件中包含某个字符串的行数
find access_log.20160423.txt | xargs cat | grep .POST\s\/upload\/zyb-prd.|wc -l - 查看端口的命令
- lsof:查找占用端口的进程 lsof -i:port 或 netstat -nap | grep port
- top:经常用来监控linux的系统状况,是常用的性能分析工具,能够实时显示系统中各个进程的资源占用情况
- 根据进程号查端口号: lsof -i | grep pid 或 netstat -nap | grep pid
- 查找文件的第16、17行: sed -n ‘16,17p’ date.log
- 查找文件里关键词最多的
- 查找进程名为live的进程:pgrep live | xargs ps -u --pid
- 说一说你知道的其他的命令
- 问一个深入点的:一个日志文件包含日期、订单编号和订单信息,我想知道订单数最多的订单编号
数据库
关系型数据库
数据库基本理论
- 数据库的事务有什么用?什么时候应该使用事务,什么时候不该使用事务?
事务即用户定义的一个数据库操作序列,这些操作要么全做要全不做,是一个不可分割的工作单位
- 事务ACID特性
原子性,一致性,隔离性,持续性
- 事务的隔离级别
事务的隔离性:同一时间只允许一个事务请求同一数据,不同事物之间彼此没有任何干扰 - -未提交读READ UNCOMMITTED:一个事务在提交之前,对其他事务是可见的,即事务可以读取未提交的数据。存在“脏读”(读到了脏数据)问题;
- 提交读READ COMMITTED:事务在提交之前,对其它事务是不可见的。存在“不可重复读”(两次查询的得到的结果可能不同,即可能在查询的间隙,有事务提交了修改)问题。解决了“脏读”问题。
- 可重复读REPEATABLE READ:在同一事务中多次读取的数据是一致的。解决了脏读和不可重复读问题,存在“幻读”(在事务两次查询间隙,有其他事务又插入或删除了新的记录)。— MySQL默认隔离级别。
- 可串行化SERIALIZABLE:强制事务串行化执行。即一个事物一个事物挨个来执行,可以解决上述所有问题。
事务隔离级别如下:
| 事务隔离级别 | 脏读 | 不可重复读 | 幻读 |
|---|---|---|---|
| 未提交读(read-uncommitted) | 是 | 是 | 是 |
| 提交读(read-committed) | 否 | 是 | 是 |
| 可重复读(repeatable-read) | 否 | 否 | 是 |
| 串行化(serializable) | 否 | 否 | 否 |
- 左连接 右连接区别
- 使用什么提高查询效率:索引;
- 索引
- 索引的数据结构:B+树;为什么不用B树/其他结构?
- 联合索引和唯一索引的区别
- 索引 多列联合索引 怎么查询
- 查询语句时怎么知道我是否使用到索引?explain
- 如果插入或删除数据,索引会变吗?会变
- order by和group by区别?
order by 是对结果集排序 group by是分组(聚合)
group by优先级高于order by - Redis 和 MySQL 的关系和使用场景,什么是击穿?
- 数据库范式
- Redis有哪些数据结构
- mysql的引擎
- 数据库怎么优化
- 数据库缓存技术
- mysql中删除命令有几种,各有什么区别
SQL
- 怎么给table增加一个column
ALTERTABLE table_name ADD column_name datatype
- 怎么插入一行数据
"INSERT INTO UserID(UserID, name, ) VALUES ('123456','阿瑟大')
- 怎么更新一行数据
UPDATE SET 字段 1=值 1 [,字段 2=值 2… ] [WHERE 子句 ] [ORDER BY 子句] [LIMIT 子句]
- drop和delete的区别
- 查询成绩大于80分的学生的姓名
select a.姓名, avg(b.成绩) as 平均成绩
from student as a left join score as b
on a.学号 = b.学号
group by a.学号
having avg(b.成绩)>85;
- 查询每个年级总分最高的学生信息
- sql语句(连接查询,distinct)
- 学生表和班级表:左连接;平均分>80的班级
select a.学号,a.姓名, avg(b.成绩) as 平均成绩
from student as a left join score as b
on a.学号 = b.学号
group by a.学号
having avg(b.成绩)>85;
- 两个数据库查询:一个多表查询、一个用到group by和having
- 员工表employee(staffid,time) 查找最晚入职的员工信息
select * from employee where time IN (select max(time) from employee);
- 查找stu表内名字为lily,住址包含北京的信息,按年龄降序排序;我开始是select *然后要求只查住址列怎么办?
Select * from stu where name=’lily’ and province like ‘北京%’ ORDER BY age DESC;
修改包含北京的列里北京两个字为上海
UPDATE stu SET province '北京'='上海' where province = '北京';
- 有一张表存储用户访问信息,表名accessLog,字段:uid(用户id),url(用户访问的url)、ip(用户来源ip)、time(访问日志,格式YYYYMMDD)。统计2019年7月28日,用户访问次数,访问url个数
group by uid
select count(*) from accessLog where time ='2019-7-28'
八、编程题
- 空格替换,将空格替换为其他字符
- 1-10000个无序数中随机取出两个数,用最小的时间复杂度和空间复杂度
- 输入hew HisL LL,要求输出ll hISl HEW
- 针对自己写的代码怎么设计测试用例。(提示:单测case有没有覆盖到,考虑其他的异常)
- 查找单链表倒数第K个节点
- java实现查找最长子串
- 统计一个字符串每个字符出现的次数?
- 有100亿个URL,从里面找出重复的URL
字符串
- 统计一个字符串每个字符出现的次数
- collections.Counter()
from collections import Counter
s = 'ababcc'
print(Counter(s))
- 字典推导式和str自带的统计方法str.count
s = 'ab cacb'
print({a:s.count(a) for a in set(s.replace(' ',''))})
- 自己写逻辑实现
s='a bcac'
r = {}
for x in s.replace(' ',''):
r[x] = r.get(x, 0) + 1
print(r)
from functools import reduce
def count_char(string):
z = {}
for i in string:
if i not in z:
z[i]=1
else:
z[i]+=1
return z
i=count_char(input("请输入一个字符串:"))
print('你输入的字符串每个字符出现次数为:',str(i))
print(reduce(lambda x, y: y + x, i))
- 统计一个字符串中第一个出现次数最多的字符
from collections import Counter
s='a b c ca'
c = Counter(s.replace(' ',''))
print(c.most_common(1)[0][0])
- 统计字符串中出现次数最多的三个字符
# 在字符串中统计每个字符的数量,并输出靠前的几个字符及数量
str1 = "fadsgsgaerawrdewgrefdsafaerzfe"
dict1 = {}
dict2 = {}
for i in range(0, len(str1)):
list1 = dict1.keys()
if str1[i] in list1:
dict1[str1[i]] = dict1[str1[i]]+1
else:
dict1[str1[i]] = 1
print('按照键值对的形式,展示每个字符的数量:', '\n', dict1)
for i in range(0, 3):
key1 = max(dict1, key=dict1.get)
dict2[key1] = dict1[key1]
del dict1[key1]
print('只展示最靠前的3个字符和对应的数量:', '\n', dict2)
from collections import Counter
s='a b cd acaee'
c = Counter(s.replace(' ',''))
print(c.most_common())
print(c.most_common(1)[0][0])
print(c.most_common(2)[1][0])
print(c.most_common(3)[2][0])
- 判断回文
def is_palindrome(string):
for index in range(len(string)//2):
if string[index] != string[len(string)-index-1]:
return False
return True
print(is_palindrome('abcddcba'))
print(is_palindrome('pythonohtyp'))
print(is_palindrome('bookkob'))
- 返回频率最高的k个单词
import re
def findtop(string,k):
dic = {word:string.count(word) for word in re.findall(r'[\w]+',string)}
# 如果各个迭代器的元素个数不一致,则返回列表长度与最短的对象相同,利用 * 号操作符,可以将元组解压为列表
# 与zip 相反,zip(*) 可理解为解压,返回二维矩阵式
words, cnts = zip(*sorted(dic.items(),key=lambda x : x[1],reverse=True)[:k])
return words
string = "i am so happy and i am so sad , i"
print(findtop(string,5))
# 输出
# ('i', 'am', 'so', 'and', 'happy')
# 以string列表形式返回string中pattern的所有非重叠匹配项。从左到右扫描该字符串,并以找到的顺序返回匹配项。如果该模式中存在一个或多个组,则返回一个组列表;否则,返回一个列表。如果模式包含多个组,则这将是一个元组列表。空匹配项包含在结果中。
# 语法
re.findall(pattern, string, flags = 0)
# 示例
re.findall('a', 'This is a beautiful place!')
# 输出 ['a','a','a']
Python3 zip() 函数
Python3 sorted() 函数
Python lambda:定义匿名函数
-
有100亿个URL,从里面找出重复的URL
#
# 二分查找
# @param n int整型 数组长度
# @param v int整型 查找值
# @param a int整型一维数组 有序数组
# @return int整型
#
class Solution:
def upper_bound_(self , n , v , a ):
# write code here
if a[n-1] < v:
return n + 1
left=0
right=n-1
while left<right: # 当left=right时停止,题目要寻找第一个
mid = int((left+right)/2)
if a[mid]>=v:
# mid大于并且等于value时(这里等于很关键),在左区间[left,mid]继续寻找
right=mid # 注意上面有等于号,所以这里mid不能减一
else: # 当mid小于vlue时,在右区间[mid+1,right]中继续寻找
left=mid+1
return left+1
- 开辟一个和str长度大小相同的一个字符串ans,把传入的str倒序赋值到ans字符串上, 时间复杂度O(N),额外空间复杂度O(N)
class Solution:
def solve(self , str ):
ans=""
Len = len(str)
for i in range(0,Len):
ans+=str[Len-1-i]
return ans
- 直接调用库函数
class Solution:
def solve(self , str ):
return str[::-1]
- 使用双指针
class Solution:
def solve(self , str ):
l,r = 0,len(str) - 1# 定义一个双指针
s = list(str) #将str变为list,然后可以进行字符的交换
while l < r:#进行字符串的翻转
c = s[l]
s[l] = s[r]
s[r] = c
l += 1
r -= 1
return ''.join(s)
树
- 二叉树的中序遍历
递归
# Definition for a binary tree node.
# class TreeNode:
# def __init__(self, x):
# self.val = x
# self.left = None
# self.right = None
class Solution:
def inorderTraversal(self, root: TreeNode) -> List[int]:
if root == None:
return []
left = self.inorderTraversal(root.left)
right = self.inorderTraversal(root.right)
return left + [root.val] + right
非递归
# Definition for a binary tree node.
# class TreeNode:
# def __init__(self, x):
# self.val = x
# self.left = None
# self.right = None
class Solution:
def inorderTraversal(self, root: TreeNode) -> List[int]:
if root == None:
return []
stack = []
res = []
temp = root
while temp or stack:
if temp != None:
stack.append(temp)
temp = temp.left
else:
temp = stack.pop()
res.append(temp.val)
temp = temp.right
return res
其他
# -*- coding:utf-8 -*-
class Solution:
def jumpFloor(self, number):
# write code here
#此题与菲波那切数列的本质一致
if number == 1:
return 1
if number == 2:
return 2
fOne = 1
fTwo = 2
for i in range(3,number+1):
fN = fTwo + fOne
fOne = fTwo
fTwo = fN
return fN
- 全是数字的字符串相加,且位数很多
- 一个文件中出现的单词数量最多的前5个单词,单词之间由空格隔开
import re
from collections import Counter
c = Counter(re.findall( '\w+' ,open('test.txt').read()))
print(c.most_common(1)[0][0])
print(c.most_common(2)[1][0])
print(c.most_common(3)[2][0])
print(c.most_common(4)[3][0])
print(c.most_common(5)[4][0])
- 数组中最大子数组和
遍历数组,记录从第一个元素加到当前元素的和,并更新最大和。如果该值小于0,说明会对后续和产出负面影响(负数会让后面的加和变小),则把该值置为0(相当于舍弃前面的序列,重新开始计算)。
class Solution:
"""
@param nums: A list of integers
@return: An integer denote the sum of maximum subarray
"""
def maxSubArray(self, nums):
# write your code here
if nums is None or len(nums) == 0:
return 0
sum = -2**31 - 1
ans = 0
for i in nums:
ans += i
sum = max(ans, sum)
if ans < 0:
ans = 0
return sum
- 统计数组中,连续子数组和的最大值
动态规划
# -*- coding:utf-8 -*-
def function(lists):
max_sum = lists[0]
pre_sum = 0
for i in lists:
# 因为最大子列表一定是从一个非0的数开始的(假定列表中有正数有负数)
# 所以就可以暂时筛选掉小于0的数,即便列表全是负数,那么最大的子列表肯定是负数最大的一个
if pre_sum < 0:
pre_sum = i
else:
pre_sum += i
if pre_sum > max_sum:
max_sum = pre_sum
return max_sum
lists = [0, 1, 2, 3, -4, 5, -6]
print(function(lists))
- 给一个数字(比如12476)写代码实现还是这些数字组合起来找到比这个数字小的最大的组合
lists = [5, 4, 3, 2, 1]
for i in range(len(lists)-1, -1, -1):
print(lists[i])
if(lists[i]<lists[i-1]):
t=lists[i]
lists[i]=lists[i-1]
lists[i-1]=t
break
print(lists)
# 输出[5, 4, 3, 1, 2]
- 谁是窃贼问题
警察局抓了a,b,c,d四名偷窃嫌疑犯,其中只有一人是小偷。审问中
a说:“我不是小偷。”
b说:“c是小偷。”
c说:“小偷肯定是d。”
d说:“c在冤枉人。”
已知四个人中三人说的是真话,一人说的是假话,问到底谁是小偷?
问题分析:
ABCD编号1234,枚举尝试
算法设计:
用变量x存放小偷的编号,则x的取值范围从1取到4,就假设了他们中的某人是小偷的所有情况。四个人所说的话就可以分别写成:
a说的话:x!=1
b说的话:x == 3
c说的话:x==4
d说的话:x != 4或not(x ==4)
注意:在x的枚举过程中,当这四个逻辑式的值相加等于3时,即表示“四个人中三人说的是真话,一人说的是假话”。
算法如下:
for x in range(1,5):
if((x!=1)+(x==3)+(x==4)+(x!=4)==3):
print(chr(64+x),"is a thief .");
range函数
range(start, stop[, step])
# start: 计数从 start 开始。默认是从 0 开始。例如range(5)等价于range(0, 5);
# stop: 计数到 stop 结束,但不包括 stop。例如:range(0, 5) 是[0, 1, 2, 3, 4]没有5
# step:步长,默认为1。例如:range(0, 5) 等价于 range(0, 5, 1)
-
数组长度都为n的A B两数组,都为单调递增,找出这两个数组的中位数(不合并两个数组)
-
不用第三个变量,交换两个变量的值
"容器"法:栈 / 队列
int a = 1,b = 2;
Stack<Integer> stack = new Stack<Integer>();
stack.push(a);
stack.push(b);
a = stack.pop();
b = stack.pop();
坐标法:把a、b看作数轴上的两个点,而a、b的值则为a、b点到原点的距离
int a = 1,b = 2;
//把a,b放在数轴上,围绕着a,b两点间的距离来计算问题
a = b - a;//a,b两点间的距离
b = b - a;//b到原点距离减去b到a的距离,则为a到原点的距离,赋值给b
a = b + a;//a到原点的距离加上a,b两点的距离,则为b到原点距离,赋值给a
//交换完毕
位运算法
int a = 1,b = 2;
//异或运算:相同位上的二进制数,相同为0,不同为1
a = a ^ b; //0001^0010=0011
b = a ^ b; //0011^0010=0001
a = a ^ b; //0011^0001=0010
储存地址法
int a = 1,b = 2;
if(a<b)
{
a = b - a;
b = b - a & 0x0000ffff;
a = b + a & 0x0000ffff;
}
else
{
b = a - b;
a = a - b & 0x0000ffff;
b = a + b & 0x0000ffff;
}
- 存储 1-100有序自然数的数组,其中一个数被替换为-1,现打乱这个数组,找出被替换为-1的数字
- 创建一个HashMap,以1到100为键,值都是0 。然后遍历整个数组,每读到一个数,就找到HashMap当中对应的键,让其值加一。由于数组中缺少一个整数,最终一定有99个键对应的值等于1, 剩下一个键对应的值等于0。遍历修改后的HashMap,找到这个值为0的键。
假设数组长度是N,那么该解法的时间复杂度是O(1),空间复杂度是O(N)。 - 先算出1+2+3…+100的和,然后依次减去数组里的元素,最后得到的差+(-1),就是被替换的数字。
假设数组长度是N,那么该解法的时间复杂度是O(N),空间复杂度是O(1)。
- 求两个有序数组的中位数
1 由于两个数组都是排好序的,因此首先可以想到的思路就是利用归并排序把两个数组合并成一个有序的长数组,然后直接取出中位数即可
def median_1(A, B):
# 思路一: 先组合成一个有序数列,再取中位数
# 时间复杂度O(m+n)
len_A = len(A)
len_B = len(B)
C = []
if len_A == len_B == 0:
raise ValueError
i = j = 0
for k in range(0, len_A + len_B):
if j == len_B or (i < len_A and A[i] <= B[j]):
C.append(A[i])
i += 1
else:
C.append(B[j])
j += 1
half = (len_A + len_B) // 2
if (len_A + len_B) % 2 == 0:
return (C[half - 1] + C[half]) / 2
else:
return C[half]
排序
- 快排 ,时间复杂度和空间复杂度 怎么测试
平均时间复杂度:O(nlogn)
#!usr/bin/env python
# encoding:utf-8
# 快排
# 1. 挑选基准值:从数列中挑出一个元素,称为"基准"(pivot)
# 2. 分割:重新排序数列,所有比基准值小的元素摆放在基准前面,所有比基准值大的元素摆在基准后面(与基准值相等的数可以到任何一边)。
# 在这个分割结束之后,对基准值的排序就已经完成
# 3. 递归排序子序列:递归地将小于基准值元素的子序列和大于基准值元素的子序列排序。
# 分割
def partition(arr, low, high):
i = (low - 1) # 最小元素索引
pivot = arr[high] # 基准值
for j in range(low, high):
# 当前元素小于或等于 pivot
if arr[j] <= pivot:
i = i + 1
arr[i], arr[j] = arr[j], arr[i]
arr[i + 1], arr[high] = arr[high], arr[i + 1]
return (i + 1)
# arr[] --> 排序数组
# low --> 起始索引
# high --> 结束索引
# 快速排序函数
def quickSort(arr, low, high):
if low < high:
pi = partition(arr, low, high)
quickSort(arr, low, pi - 1)
quickSort(arr, pi + 1, high)
arr = [5, 3, 8, 6, 4]
n = len(arr)
quickSort(arr, 0, n - 1)
print("排序后的数组:")
for i in range(n):
print("%d" % arr[i])
链表
- 判断两个单链表是否会相交
class LNode:
def __init__(self):
self.data = None
self.next = None
def IsIntersect(head1, head2):
if head1 == None or head1.next == None or head2 == None or head2.next == None or head1 == head2:
return None
tmp1 = head1.next
tmp2 = head2.next
n1, n2 = 1, 1
while tmp1.next != None:
tmp1 = tmp1.next
n1 += 1
while tmp2.next != None:
tmp2 = tmp2.next
n2 += 1
if tmp1 == tmp2:
if n1 > n2 :
while n1 - n2 > 0:
head1 = head1.next
n1 -= 1
if n2 >n1 :
while n2 - n1 >0:
head2 = head2.next
n2 -= 1
while head1 != head2:
head1 = head1.next
head2 = head2.next
return head1
else:
return None
if __name__ == '__main__':
head1 = LNode()
head2 = LNode()
cur = head1
i= 1
while i<8 :
tmp = LNode()
tmp.data = i
cur.next = tmp
cur = tmp
if i==5 :
p = tmp
i += 1
cur = head2
i= 1
while i<5 :
tmp = LNode()
tmp.data = i
cur.next = tmp
cur = tmp
i += 1
cur.next = p
interNode = IsIntersect(head1,head2)
if interNode is not None:
print('两个链表相交点为:'+str(interNode.data))
else:
print('不相交')
- 链表成环,找出环的入口
- 查找单链表倒数第K个节点
class Node: # 结点类
def __init__(self, data):
self.data = data
self.next = None
class SingleLinkList: # 单链表类
def __init__(self):
self.head = None
self.tail = None
def append(self, x): # 单链表尾部追加方法
if self.head is None:
self.head = self.tail = Node(x)
else:
self.tail.next = Node(x)
self.tail = self.tail.next
# 创建链表
test_link = SingleLinkList()
for i in range(1, 8):
test_link.append(i)
# 打印链表看一下
p = test_link.head
print("链表:", end="\t")
while p is not None:
print(p.data, end="\t")
p = p.next
print()
# 方法一 顺序遍历法
def find_it(link: SingleLinkList, k):
# 第一步获取长度
i = 0
p = link.head
while p is not None: # 循环完成后 i就是链表的长度
i += 1
p = p.next
if i < k:
return None
j = 0
p = link.head
while i - j > k: # 循环完成后 p就是倒数第三个结点
p = p.next
j += 1
return p.data
# 测试方法一
t = test_link
k = 5
print(f"倒数第{k}个元素是:", find_it(t, k), "(顺序遍历法)")
# 方法二 快慢指针法
def find_it(link: SingleLinkList, k):
slow = link.head # slow指向第一个元素
j = 1
p = link.head
while p is not None: # 如果链表的元素个数少于k, return None
p = p.next
j += 1
if j >= k:
break
else:
return None
fast = p # fast指向第k个元素
while fast.next is not None: # 循环结束之后fast指向最后一个元素,slow指向倒数第k个元素
slow = slow.next
fast = fast.next
return slow.data
# 测试方法二
t = test_link
k = 5
print(f"倒数第{k}个元素是:", find_it(t, k), "(快慢指针法)")
- 找出两个有序单链表中重复的数字集合
-
- 链表存储1->2->3->4…要求变成2->1->4->3
- 反转链表 时间&空间复杂度
利用python赋值的特性,时间复杂度O(n)
class Solution:
# 返回ListNode
def ReverseList(self, pHead):
if not pHead:
return None
root = None
while pHead:
pHead.next,root,pHead = root,pHead,pHead.next
return root
九、智力题
十、HR常问
十一、反问
- 入职后主要负责的工作内容















 148
148











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









