







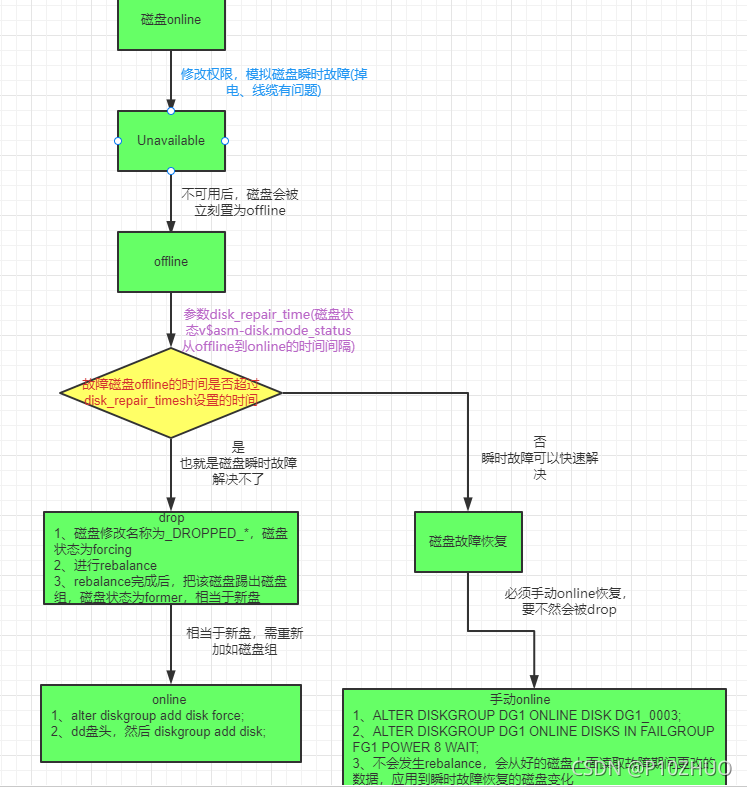
ASM磁盘超过disk_repair_time导致磁盘状态为forcing
oracle asm磁盘在实际工作中,由于一些原因,可能会不可访问,有时造成磁盘组直接dismount,数据库重启,有时磁盘组状态没影响,还是mount。那么到底磁盘出现什么状况?会造成磁盘组dismount?在什么情况下磁盘组状态无影响?下面就做一些简单的验证。
fast mirror resync
说到上面这些,那不得不说asm的特性fast mirror resync。因为它和asm磁盘的状态息息相关。
当一个ASM磁盘不可用时,ASM会把它从磁盘组里移除吗?要看情况,通常取决于ASM版本和磁盘组的冗余级别。因为一个external冗余的磁盘组会直接被dismount,所以主要关注normal和high冗余磁盘组的情况。 ASM 10g版本,磁盘会被直接drop。从11gR1,一个磁盘不可用时会先被offline,此时disk repair计时器开始介入,如果计时器达到磁盘组DISK_REPAIR_TIME 属性值时,这个磁盘会从所属的磁盘组中drop掉。如果这个磁盘在计时器过期前恢复可用,那么它的状态会变回online,不会被drop。但是ASM是如何发现磁盘恢复可用又有什么机制将它恢复online呢?
啥叫 fast mirror resync
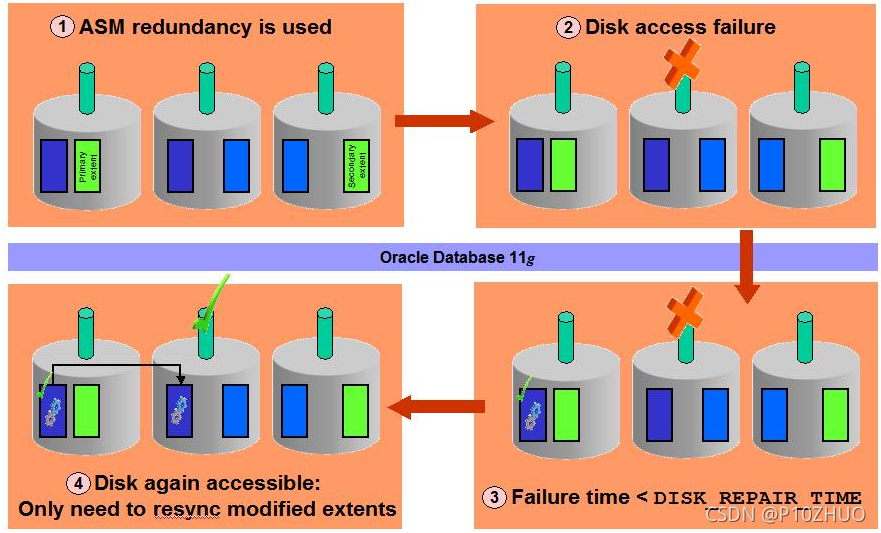
11g introduces new Scalability and Performance improvements for ASM, this is the case of ASM Fast Disk Resync Feature which quickly resynchronizes ASM disks within a disk group after transient disk path failures as long as the disk drive media is not corrupted. Any failures that render a failure group temporarily unavailable are considered transient failures. Disk path malfunctions, such as cable disconnections, host bus adapter or controller failures, or disk power supply interruptions, can cause transient failures. The duration of a fast mirror resync depends on the duration of the outage. The duration of a resynchronization is typically much shorter than the amount of time required to completely rebuild an entire ASM disk group.
–11g 为 ASM 引入了新的可扩展性和性能改进,这就是 ASM 快速磁盘重新同步功能的情况,只要磁盘驱动器介质没有损坏,它就会在瞬时磁盘路径故障后快速重新同步磁盘组中的 ASM 磁盘。任何导致故障组暂时不可用的故障都被视为暂时故障。磁盘路径故障,例如电缆断开、主机总线适配器或控制器故障,或者磁盘电源中断,都可能导致瞬时故障。快速镜像重新同步的持续时间取决于中断的持续时间。重新同步的持续时间通常比完全重建整个 ASM 磁盘组所需的时间短得多。当一个磁盘离线时,oracle 引擎不会平衡其他磁盘,而是跟踪在中断期间修改的分配单元。故障磁盘中存在的内容由其他磁盘跟踪,对故障磁盘内容所做的任何修改实际上都是在其他可用磁盘中进行的。一旦磁盘恢复并且online,属于该磁盘并在此期间被修改的数据将再次重新同步。这避免了繁重的rebalance。
为什么出现 fast mirror resync
在ASM 10G时,ASM会立即Drop变成不可用的磁盘。这会触发一个尝试恢复数据冗余的重平衡操作。一旦重平衡过程完成,数据冗余度会恢复,同时磁盘会被移除出磁盘组。一旦磁盘不可用的故障被解决,可以通过alter diskgroup命令将磁盘重新添加回磁盘组。 例如:alter diskgroup DATA add disk ‘name’; 这又会再次触发一个重平衡操作,一旦重平衡过程完成,磁盘会恢复成为磁盘组成员。
在oracle 10g ASM 中,如果发生磁盘故障(光纤故障,控制器故障,HBA卡故障或其它故障造成ASM磁盘无法访问)时,ASM实例自动将该故障磁盘drop掉。
磁盘组冗余模式为Normal或High的环境,当ASM磁盘被drop后,触发ASM磁盘组的重平衡动作,保证被drop的磁盘上涉及的extent的再次冗余。在ASM重平衡非常消耗时间和磁盘IO操作。在某些场景需要短暂offline某些磁盘时,触操drop操作,那么会触发重平衡,添加回来的时候再次触发重平衡,这种情形非常不友好。而且在重平衡的因此,在11g版本,提供了ASM快速磁盘同步特性(ASM Fast Mirror Resync)。
ASM fast disk resync significantly reduces the time required to resynchronize a transient failure of a disk. When a disk goes offline following a transient failure, ASM tracks the extents that are modified during the outage. When the transient failure is repaired, ASM can quickly resynchronize only the ASM disk extents that have been affected during the outage
–ASM 快速磁盘重新同步显着减少了重新同步磁盘瞬时故障所需的时间。当磁盘因暂时性故障而脱机时,ASM 会跟踪在中断期间修改的区。当暂时性故障修复后,ASM 可以快速重新同步仅在中断期间受到影响的 ASM 磁盘区。.
1)短暂磁盘故障,避免rebalance耗时和耗资源的过程
2)省时省资源
fast mirror resync使用场景
磁盘临时短暂故障,例如电缆断开、主机总线适配器或控制器故障,或者磁盘电源中断,都可能导致瞬时故障。
磁盘短暂故障恢复后,磁盘online,不用rebalance,直接从其他正常盘读取故障时的修改,应用到故障盘上面。
disk repair time是给计划性offline磁盘使用的,不是给磁盘损坏用的
fast mirror resync必须条件
- This feature requires that the redundancy level for the disk should be set to NORMAL or HIGH.
- compatible.asm & compatible.rdbms = 11.1.0.0.0 or higher --磁盘组COMPATIBLE参数影响到磁盘组的格式,元数据,AU等
- You need to set DISK_REPAIR_TIME parameter, which gives the time it takes for the disk to get repaired. The default time for this is set to 3.6 hours.
不可用场景
the disk drive media is not corrupted
如果是磁盘自身故障(DG冗余模式为Norma/High),这个磁盘必须drop,添加磁盘后,oracle会自动rebalance。如果冗余模式为external,磁盘出故障时,磁盘组会离线,要通过备份来恢复数据库。Exadata冗余度至少为Normal,是通过在ASM级别中mirror,所以等cell节点任何一个节点down机,不影响数据库的正常使用。
测试场景
构建测试环境:
创建磁盘组
SQL> create diskgroup testdg normal redundancy disk '/dev/asm_arch01','/dev/asm_arch02','/dev/asm_arch03' ATTRIBUTE 'compatible.asm'='11.2';
Diskgroup created.
SQL> select GROUP_NUMBER,DISK_NUMBER,name,path,STATE,HEADER_STATUS,MODE_STATUS,FREE_MB,TOTAL_MB,FAILGROUP from v$asm_disk where GROUP_NUMBER !=1;
GROUP_NUMBER DISK_NUMBER NAME PATH STATE HEADER_STATU MODE_ST FREE_MB TOTAL_MB FAILGROUP
------------ ----------- ------------------------------ -------------------- -------- ------------ ------- ---------- ---------- ------------------------------
2 0 TESTDG_0000 /dev/asm_arch01 NORMAL MEMBER ONLINE 3019 3072 TESTDG_0000
2 2 TESTDG_0002 /dev/asm_arch03 NORMAL MEMBER ONLINE 1995 2048 TESTDG_0002
2 1 TESTDG_0001 /dev/asm_arch02 NORMAL MEMBER ONLINE 1995 2048 TESTDG_0001
创建表空间,灌入数据:
SQL> create tablespace test datafile '+testdg' size 500m;
Tablespace created.
SQL> create table test tablespace test as select * from dba_objects;
Table created.
SQL> insert into test select * from test;
18334 rows created.
SQL> /
36668 rows created.
SQL> /
73336 rows created.
SQL> insert into test select * from test;
146672 rows created.
SQL> /
293344 rows created.
SQL> /
586688 rows created.
SQL> commit;
Commit complete.
SQL> select sum(bytes)/1024/1024 from dba_segments where segment_name='TEST';
SUM(BYTES)/1024/1024
--------------------
128
开启fast mirror resync
1)开启该功能需要针对磁盘组设置disk_repair_time的值。默认是3.6h
为了测试,设置disk_repair_time为5分钟,m代表分钟,h代表小时,如果不输单位,默认是小时
2)compatible.asm & compatible.rdbms = 11.1.0.0.0 or higher
[grid@11gasm ~]$ asmcmd lsattr -G testdg -ml
Group_Name Name Value RO Sys
TESTDG access_control.enabled FALSE N Y
TESTDG access_control.umask 066 N Y
TESTDG au_size 1048576 Y Y
TESTDG cell.smart_scan_capable FALSE N N
TESTDG compatible.asm 11.2.0.0.0 N Y
TESTDG compatible.rdbms 10.1.0.0.0 N Y
TESTDG disk_repair_time 3.6h N Y
TESTDG sector_size 512 Y Y
[grid@11gasm ~]$ asmcmd setattr -G testdg disk_repair_time '5m'
ORA-15032: not all alterations performed
ORA-15242: could not set attribute disk_repair_time
ORA-15283: ASM operation requires compatible.rdbms of 11.1.0.0.0 or higher (DBD ERROR: OCIStmtExecute)
[grid@11gasm ~]$ asmcmd setattr -G testdg compatible.rdbms '11.2.0.0.0'
[grid@11gasm ~]$ asmcmd setattr -G testdg disk_repair_time '5m'
[grid@11gasm ~]$ asmcmd lsattr -G testdg -ml
Group_Name Name Value RO Sys
TESTDG access_control.enabled FALSE N Y
TESTDG access_control.umask 066 N Y
TESTDG au_size 1048576 Y Y
TESTDG cell.smart_scan_capable FALSE N N
TESTDG compatible.asm 11.2.0.0.0 N Y
TESTDG compatible.rdbms 11.2.0.0.0 N Y
TESTDG disk_repair_time 5m N Y
TESTDG sector_size 512 Y Y
模拟磁盘不可用(Unavailable)
当数据库正常运行,磁盘组正常mount的时候,更改/dev/sdf的权限以模拟磁盘损坏(由于udev会实时修改磁盘的权限,所以在udev规则里面直接修改sdf磁盘):
[root@11gasm ~]# ls -ltr /dev/asm_arch03
lrwxrwxrwx 1 root root 3 Sep 27 19:07 /dev/asm_arch03 -> sdf
[root@11gasm ~]# ls -ltr /dev/sdf
brw-rw---- 1 grid oinstall 8, 80 Sep 27 19:22 /dev/sdf
[root@11gasm ~]# vi /etc/udev/rules.d/99-oracle-asmdevices.rules
KERNEL=="sd?", SUBSYSTEM=="block", PROGRAM=="/sbin/scsi_id -g -u -d /dev/$name", RESULT=="36000c29b297a11de28d314dec925e638", SYMLINK+="asm_data01", OWNER="grid", GROUP="oinstall", MODE=
"0660"
KERNEL=="sd?", SUBSYSTEM=="block", PROGRAM=="/sbin/scsi_id -g -u -d /dev/$name", RESULT=="36000c298847bde752dd8a04309efe9d7", SYMLINK+="asm_data02", OWNER="grid", GROUP="oinstall", MODE=
"0660"
KERNEL=="sd?", SUBSYSTEM=="block", PROGRAM=="/sbin/scsi_id -g -u -d /dev/$name", RESULT=="36000c2906fa88bc78ecc2ef935bcf7af", SYMLINK+="asm_arch01", OWNER="grid", GROUP="oinstall", MODE=
"0660"
KERNEL=="sd?", SUBSYSTEM=="block", PROGRAM=="/sbin/scsi_id -g -u -d /dev/$name", RESULT=="36000c2971d09dcb90cfd95ad8a19d3cf", SYMLINK+="asm_arch02", OWNER="grid", GROUP="oinstall", MODE=
"0660"
#KERNEL=="sd?", SUBSYSTEM=="block", PROGRAM=="/sbin/scsi_id -g -u -d /dev/$name", RESULT=="36000c2973496bbad9aedcb9c56ff31bb", SYMLINK+="asm_arch03", OWNER="grid", GROUP="oinstall", MODE
="0660"
[root@11gasm ~]# start_udev
Starting udev: [ OK ]
[root@11gasm ~]# ls -ltr /dev/sd*
brw-rw---- 1 root disk 8, 0 Sep 28 14:13 /dev/sda
brw-rw---- 1 root disk 8, 2 Sep 28 14:13 /dev/sda2
brw-rw---- 1 root disk 8, 1 Sep 28 14:13 /dev/sda1
brw-rw---- 1 grid oinstall 8, 32 Sep 28 14:13 /dev/sdc
brw-rw---- 1 root disk 8, 96 Sep 28 14:13 /dev/sdg
brw-rw---- 1 root disk 8, 97 Sep 28 14:13 /dev/sdg1
brw-rw---- 1 root disk 8, 80 Sep 28 14:14 /dev/sdf
brw-rw---- 1 grid oinstall 8, 64 Sep 28 14:14 /dev/sde
brw-rw---- 1 grid oinstall 8, 48 Sep 28 14:14 /dev/sdd
brw-rw---- 1 grid oinstall 8, 16 Sep 28 14:14 /dev/sdb
接下来创建一个数据文件,以此来构造变化
SQL> alter tablespace test add datafile '+testdg' size 100m;
Tablespace altered.
当一个磁盘不能被ASM或者ASM客户端读或写时,会被认为不可用。数据库是一种典型的ASM客户端,但ASM客户端并不只限于是数据库。磁盘会因为各种原因变成不可用,本地硬盘的SCSI线缆受损,存储的SAN交换机或者网络故障,NFS空间的服务器故障,双活场景的站点故障,又或是磁盘本身故障等各种场景。无论是哪种情况,ASM或者是ASM客户端会报IO错误,然后ASM会进行相应的处理。
磁盘状态由Unavailable变为offline
asm alert日志:
Tue Sep 28 15:08:41 2021
Errors in file /u01/app/grid/diag/asm/+asm/+ASM/trace/+ASM_ora_5001.trc:
ORA-15025: could not open disk “/dev/asm_arch03”
ORA-27041: unable to open file
Linux-x86_64 Error: 2: No such file or directory
Additional information: 3
NOTE: process user5001+asm (5001) initiating offline of disk 2.3915950068 (TESTDG_0002) with mask 0x7e in group 2
NOTE: checking PST: grp = 2
Tue Sep 28 15:08:41 2021
GMON checking disk modes for group 2 at 14 for pid 18, osid 5001
NOTE: checking PST for grp 2 done.
NOTE: sending set offline flag message 127771928 to 1 disk(s) in group 2
WARNING: Disk TESTDG_0002 in mode 0x7f is now being offlined
NOTE: initiating PST update: grp = 2, dsk = 2/0xe968a7f4, mask = 0x6a, op = clear
GMON updating disk modes for group 2 at 15 for pid 18, osid 5001
WARNING: GMON has insufficient disks to maintain consensus. Minimum required is 2: updating 2 PST copies from a total of 3.
NOTE: group TESTDG: updated PST location: disk 0000 (PST copy 0)
NOTE: group TESTDG: updated PST location: disk 0001 (PST copy 1)
NOTE: PST update grp = 2 completed successfully
NOTE: initiating PST update: grp = 2, dsk = 2/0xe968a7f4, mask = 0x7e, op = clear
GMON updating disk modes for group 2 at 16 for pid 18, osid 5001
NOTE: group TESTDG: updated PST location: disk 0000 (PST copy 0)
NOTE: group TESTDG: updated PST location: disk 0001 (PST copy 1)
NOTE: cache closing disk 2 of grp 2: TESTDG_0002
NOTE: PST update grp = 2 completed successfully
Tue Sep 28 15:09:02 2021
WARNING: Disk 2 (TESTDG_0002) in group 2 will be dropped in: (300) secs on ASM inst 1
由上面日志可以看出:
1、NOTE: process _user5001_+asm (5001) initiating offline of disk 2.3915950068 (TESTDG_0002) with mask 0x7e in group 2 磁盘会先被置为offline状态。
2、WARNING: Disk 2 (TESTDG_0002) in group 2 will be dropped in: (**300**) secs on ASM inst 1 这个300s就是我们设置的disk_repair_time为5分钟。此处显示,5min后,磁盘将被drop掉。
此时磁盘状态:
GROUP_NUMBER DISK_NUMBER NAME PATH STATE HEADER_STATU MODE_ST FREE_MB TOTAL_MB FAILGROUP
------------ ----------- ------------------------------ -------------------- -------- ------------ ------- ---------- ---------- ------------------------------
2 2 TESTDG_0002 NORMAL UNKNOWN OFFLINE 1614 2048 TESTDG_0002
2 0 TESTDG_0000 /dev/asm_arch01 NORMAL MEMBER ONLINE 2544 3072 TESTDG_0000
2 1 TESTDG_0001 /dev/asm_arch02 NORMAL MEMBER ONLINE 1614 2048 TESTDG_0001
SQL> select * from v$asm_operation;
no rows selected
数据库alert日志:
Tue Sep 28 15:08:41 2021
alter tablespace test add datafile ‘+testdg’ size 100m
Tue Sep 28 15:08:41 2021
NOTE: disk 2 (TESTDG_0002) in group 2 (TESTDG) is offline for reads
NOTE: disk 2 (TESTDG_0002) in group 2 (TESTDG) is offline for writes
Completed: alter tablespace test add datafile ‘+testdg’ size 100m
以下分为两种情况:
1)offline时间超过了disk_repair_time
2)offline时间没有超过disk_repair_time
第一种情况
磁盘状态由offline被drop
asm alert日志:
Tue Sep 28 15:12:05 2021
WARNING: Disk 2 (TESTDG_0002) in group 2 will be dropped in: (117) secs on ASM inst 1
Tue Sep 28 15:15:09 2021
WARNING: PST-initiated drop of 1 disk(s) in group 2(.505960219))
SQL> alter diskgroup TESTDG drop disk TESTDG_0002 force / ASM SERVER /
NOTE: requesting all-instance membership refresh for group=2
Tue Sep 28 15:15:11 2021
GMON updating for reconfiguration, group 2 at 17 for pid 24, osid 5079
NOTE: cache closing disk 2 of grp 2: (not open) TESTDG_0002
NOTE: group TESTDG: updated PST location: disk 0000 (PST copy 0)
NOTE: group TESTDG: updated PST location: disk 0001 (PST copy 1)
NOTE: group 2 PST updated.
Tue Sep 28 15:15:11 2021
NOTE: membership refresh pending for group 2/0x1e28571b (TESTDG)
GMON querying group 2 at 18 for pid 13, osid 2398
NOTE: cache closing disk 2 of grp 2: (not open) _DROPPED_0002_TESTDG
SUCCESS: refreshed membership for 2/0x1e28571b (TESTDG)
NOTE: starting rebalance of group 2/0x1e28571b (TESTDG) at power 1
SUCCESS: alter diskgroup TESTDG drop disk TESTDG_0002 force / ASM SERVER /
SUCCESS: PST-initiated drop disk in group 2(505960219))
Starting background process ARB0
Tue Sep 28 15:15:13 2021
ARB0 started with pid=23, OS id=5359
NOTE: assigning ARB0 to group 2/0x1e28571b (TESTDG) with 1 parallel I/O
cellip.ora not found.
NOTE: F1X0 copy 3 relocating from 2:2 to 65534:4294967294 for diskgroup 2 (TESTDG)
NOTE: Attempting voting file refresh on diskgroup TESTDG
Tue Sep 28 15:15:22 2021
NOTE: Rebalance has restored redundancy for any existing control file or redo log in disk group TESTDG
NOTE: stopping process ARB0
SUCCESS: rebalance completed for group 2/0x1e28571b (TESTDG)
Tue Sep 28 15:15:23 2021
NOTE: requesting all-instance membership refresh for group=2
Tue Sep 28 15:15:26 2021
GMON updating for reconfiguration, group 2 at 19 for pid 23, osid 5385
NOTE: cache closing disk 2 of grp 2: (not open) _DROPPED_0002_TESTDG
NOTE: group TESTDG: updated PST location: disk 0000 (PST copy 0)
NOTE: group TESTDG: updated PST location: disk 0001 (PST copy 1)
NOTE: group 2 PST updated.
SUCCESS: grp 2 disk _DROPPED_0002_TESTDG going offline
GMON updating for reconfiguration, group 2 at 20 for pid 23, osid 5385
NOTE: cache closing disk 2 of grp 2: (not open) _DROPPED_0002_TESTDG
NOTE: group TESTDG: updated PST location: disk 0000 (PST copy 0)
NOTE: group TESTDG: updated PST location: disk 0001 (PST copy 1)
NOTE: group 2 PST updated.
NOTE: membership refresh pending for group 2/0x1e28571b (TESTDG)
GMON querying group 2 at 21 for pid 13, osid 2398
GMON querying group 2 at 22 for pid 13, osid 2398
NOTE: Disk _DROPPED_0002_TESTDG in mode 0x0 marked for de-assignment
SUCCESS: refreshed membership for 2/0x1e28571b (TESTDG)
Tue Sep 28 15:15:32 2021
NOTE: Attempting voting file refresh on diskgroup TESTDG
1、15:15:09的时候,asm开始主动drop force操作。然后是刷新PST。
2、drop的时候,asm会发生rebalance。rebalance 的时候,磁盘被命名为_DROPPED_0002_TESTDG
3、rebalance完成后,2号磁盘被彻底删除,剔出testdg磁盘组。
4、15:09:02-15:15:09,差不多6min,我们设置是5min。不知道为什么多了1min。
GROUP_NUMBER DISK_NUMBER NAME PATH STATE HEADER_STATU MODE_ST FREE_MB TOTAL_MB FAILGROUP
------------ ----------- ------------------------------ -------------------- -------- ------------ ------- ---------- ---------- ------------------------------
2 2 _DROPPED_0002_TESTDG FORCING UNKNOWN OFFLINE 2046 2048 TESTDG_0002
2 0 TESTDG_0000 /dev/asm_arch01 NORMAL MEMBER ONLINE 2304 3072 TESTDG_0000
2 1 TESTDG_0001 /dev/asm_arch02 NORMAL MEMBER ONLINE 1280 2048 TESTDG_0001
上面的查询说明,name变为了_DROPPED开头的,state 变为了forcing。官方文档对forcing 的定义:–FORCING - Disk is being removed from the disk group without attempting to offload its data. The data will be recovered from redundant copies, where possible.
说明磁盘正在被从磁盘组中剔除,此时肯定还在rebalance,因为剔除过程肯定要rebalance完后,才会剔除成功。
SQL> select * from v$asm_operation;
GROUP_NUMBER OPERA STAT POWER ACTUAL SOFAR EST_WORK EST_RATE EST_MINUTES ERROR_CODE
------------ ----- ---- ---------- ---------- ---------- ---------- ---------- ----------- --------------------------------------------
2 REBAL RUN 1 1 2 555 118 4
数据库alert日志:
Tue Sep 28 15:15:11 2021
SUCCESS: disk TESTDG_0002 (2.3915950068) renamed to _DROPPED_0002_TESTDG in diskgroup TESTDG
Tue Sep 28 15:15:26 2021
SUCCESS: disk _DROPPED_0002_TESTDG (2.3915950068) dropped from diskgroup TESTDG
从数据库的alert日志的时间节点可以看出,drop的时候,会先重命名,把TESTDG_0002 (v$asm_disk.name) renamed to _DROPPED_0002_TESTDG。然后等待rebalance。rebalance完成后,15:15:26,会把这个磁盘从磁盘组中直接删除。 _DROPPED_0002_TESTDG (2.3915950068) dropped from diskgroup TESTDG**
在ASM 10G时,ASM会立即Drop变成不可用的磁盘。这会触发一个尝试恢复数据冗余的重平衡操作。一旦重平衡过程完成,数据冗余度会恢复,同时磁盘会被移除出磁盘组。一旦磁盘不可用的故障被解决,可以通过alter diskgroup命令将磁盘重新添加回磁盘组。 例如:alter diskgroup DATA add disk ‘ORCL: DISK077’; 这又会再次触发一个重平衡操作,一旦重平衡过程完成,磁盘会恢复成为磁盘组成员。 但是如果多个磁盘同时发生故障,又或者一个磁盘故障在重平衡过程中又有磁盘故障会导致什么结果?这取决于多个因素,磁盘组的冗余度、磁盘是否来自于相同或不同的failgroup和故障磁盘是否是partner关系。 在一个normal冗余级别的磁盘组,ASM能容忍来自于一个failgroup中的一块或者多块,甚至是全部的磁盘故障。如果来自于不同的failgroup的磁盘变成不可用,仅当它们之间不存在partner关系时,ASM才能容忍。 这里提到的“容忍"的具体含义是指磁盘组能继续online同时ASM客户端访问不受影响。 在一个high冗余级别的磁盘组,ASM能容忍仅来自于两个failgroup中的一块或者多块,甚至是全部的磁盘故障。如果来自于两个以上failgroup的磁盘变成不可用,partner关系规则仍然有效。基本上,ASM能容忍任意数量的磁盘变成不可用,只要它们之间不存在partner关系时。
磁盘状态由drop变为online
当故障磁盘offline的时间超过disk_repair_time 设置的时间,那么磁盘将会被从 磁盘组中删除。磁盘组中已经没有故障的盘了。
GROUP_NUMBER DISK_NUMBER NAME PATH STATE HEADER_STATU MODE_ST FREE_MB TOTAL_MB FAILGROUP
------------ ----------- ------------------------------ -------------------- -------- ------------ ------- ---------- ---------- ------------------------------
2 0 TESTDG_0000 /dev/asm_arch01 NORMAL MEMBER ONLINE 2406 3072 TESTDG_0000
1 1 DATADG_0001 /dev/asm_data02 NORMAL MEMBER ONLINE 1552 5120 DATADG_0001
1 0 DATADG_0000 /dev/asm_data01 NORMAL MEMBER ONLINE 1568 5120 DATADG_0000
2 1 TESTDG_0001 /dev/asm_arch02 NORMAL MEMBER ONLINE 1382 2048 TESTDG_0001
此时,如果需要把这块盘重新加进去,需要使用alter diskgroup add disk语句重新添加。加force或者dd磁盘&重新添加。
SQL> alter diskgroup testdg add disk '/dev/asm_arch03' force;
Diskgroup altered.
第二种情况:
磁盘故障恢复online
为了测试fast mirror功能,我们可以模拟一些数据库的变化:
SQL> alter tablespace test add datafile '+testdg' size 50m;
Tablespace altered.
SQL> /
Tablespace altered.
模拟磁盘瞬时故障恢复:
[root@11gasm ~]# start_udev
Starting udev: [ OK ]
[root@11gasm ~]# ls -ltr /dev/sdf
brw-rw---- 1 grid oinstall 8, 80 Sep 28 19:15 /dev/sdf
磁盘状态改变为:
SQL> /
GROUP_NUMBER DISK_NUMBER NAME PATH STATE HEADER_STATU MODE_ST FREE_MB TOTAL_MB FAILGROUP
------------ ----------- ------------------------------ -------------------- -------- ------------ ------- ---------- ---------- ------------------------------
0 0 /dev/asm_arch03 NORMAL MEMBER ONLINE 0 0
2 2 TESTDG_0002 NORMAL UNKNOWN OFFLINE 1428 2048 TESTDG_0002
2 0 TESTDG_0000 /dev/asm_arch01 NORMAL MEMBER ONLINE 2300 3072 TESTDG_0000
2 1 TESTDG_0001 /dev/asm_arch02 NORMAL MEMBER ONLINE 1424 2048 TESTDG_0001
瞬时故障的磁盘已经显示出来了,/dev/asm_arch03,状态都是合适的。他映射在asm实例中的name TESTDG_0002状态异常,所以必须手工online处理。
手动online磁盘
SQL> alter diskgroup testdg online disk TESTDG_0002;
Diskgroup altered.
asm实例日志:
Tue Sep 28 19:25:26 2021
WARNING: Disk 2 (TESTDG_0002) in group 2 will be dropped in: (300) secs on ASM inst 1
Tue Sep 28 19:26:38 2021
SQL> alter diskgroup testdg online disk TESTDG_0002
Tue Sep 28 19:26:38 2021
NOTE: initiating online disk group 2 disks
TESTDG_0002 (2)
NOTE: process s000+asm (19969) initiating offline of disk 2.3915950082 (TESTDG_0002) with mask 0x7e in group 2
NOTE: sending set offline flag message 2870376454 to 1 disk(s) in group 2
Tue Sep 28 19:26:38 2021
WARNING: Disk TESTDG_0002 in mode 0x1 is now being offlined
NOTE: initiating PST update: grp = 2, dsk = 2/0xe968a802, mask = 0x6a, op = clear
GMON updating disk modes for group 2 at 89 for pid 25, osid 19969
NOTE: cache closing disk 2 of grp 2: (not open) TESTDG_0002
NOTE: PST update grp = 2 completed successfully
NOTE: initiating PST update: grp = 2, dsk = 2/0xe968a802, mask = 0x7e, op = clear
GMON updating disk modes for group 2 at 90 for pid 25, osid 19969
NOTE: cache closing disk 2 of grp 2: (not open) TESTDG_0002
NOTE: PST update grp = 2 completed successfully
NOTE: requesting all-instance membership refresh for group=2
NOTE: F1X0 copy 3 relocating from 2:2 to 2:4294967294 for diskgroup 2 (TESTDG)
NOTE: initiating PST update: grp = 2, dsk = 2/0x0, mask = 0x11, op = assign
GMON updating disk modes for group 2 at 91 for pid 25, osid 19969
NOTE: cache closing disk 2 of grp 2: (not open) TESTDG_0002
NOTE: group TESTDG: updated PST location: disk 0000 (PST copy 0)
NOTE: group TESTDG: updated PST location: disk 0001 (PST copy 1)
NOTE: PST update grp = 2 completed successfully
NOTE: requesting all-instance disk validation for group=2
Tue Sep 28 19:26:39 2021
NOTE: disk validation pending for group 2/0x1e28571b (TESTDG)
NOTE: Found /dev/asm_arch03 for disk TESTDG_0002
WARNING: ignoring disk in deep discovery
SUCCESS: validated disks for 2/0x1e28571b (TESTDG)
GMON querying group 2 at 92 for pid 25, osid 19969
NOTE: initiating PST update: grp = 2, dsk = 2/0x0, mask = 0x19, op = assign
GMON updating disk modes for group 2 at 93 for pid 25, osid 19969
NOTE: group TESTDG: updated PST location: disk 0000 (PST copy 0)
NOTE: group TESTDG: updated PST location: disk 0001 (PST copy 1)
NOTE: group TESTDG: updated PST location: disk 0002 (PST copy 2)
NOTE: PST update grp = 2 completed successfully
NOTE: membership refresh pending for group 2/0x1e28571b (TESTDG)
GMON querying group 2 at 94 for pid 13, osid 2398
NOTE: cache opening disk 2 of grp 2: TESTDG_0002 path:/dev/asm_arch03
SUCCESS: refreshed membership for 2/0x1e28571b (TESTDG)
NOTE: initiating PST update: grp = 2, dsk = 2/0x0, mask = 0x5d, op = assign
SUCCESS: alter diskgroup testdg online disk TESTDG_0002
GMON updating disk modes for group 2 at 95 for pid 25, osid 19969
NOTE: PST update grp = 2 completed successfully
NOTE: initiating PST update: grp = 2, dsk = 2/0x0, mask = 0x7d, op = assign
GMON updating disk modes for group 2 at 96 for pid 25, osid 19969
NOTE: PST update grp = 2 completed successfully
NOTE: Voting File refresh pending for group 2/0x1e28571b (TESTDG)
NOTE: F1X0 copy 3 relocating from 2:4294967294 to 2:2 for diskgroup 2 (TESTDG)
NOTE: initiating PST update: grp = 2, dsk = 2/0x0, mask = 0x7f, op = assign
GMON updating disk modes for group 2 at 97 for pid 25, osid 19969
NOTE: PST update grp = 2 completed successfully
NOTE: reset timers for disk: 2
NOTE: completed online of disk group 2 disks
TESTDG_0002 (2)
NOTE: Attempting voting file refresh on diskgroup TESTDG
数据库alert日志:
Tue Sep 28 19:26:42 2021
NOTE: Found /dev/asm_arch03 for disk TESTDG_0002
SUCCESS: disk TESTDG_0002 (2.3915950082) replaced in diskgroup TESTDG
NOTE: disk 2 (TESTDG_0002) in group 2 (TESTDG) is online for writes
NOTE: disk 2 (TESTDG_0002) in group 2 (TESTDG) is online for reads
此时asm磁盘状态已经恢复正常
SQL> select * from v$asm_operation;
select GROUP_NUMBER,DISK_NUMBER,name,path,STATE,HEADER_STATUS,MODE_STATUS,FREE_MB,TOTAL_MB,FAILGROUP from v$asm_disk where GROUP_NUMBER !=1;
no rows selected
SQL>
GROUP_NUMBER DISK_NUMBER NAME PATH STATE HEADER_STATU MODE_ST FREE_MB TOTAL_MB FAILGROUP
------------ ----------- ------------------------------ -------------------- -------- ------------ ------- ---------- ---------- ------------------------------
2 2 TESTDG_0002 /dev/asm_arch03 NORMAL MEMBER ONLINE 1428 2048 TESTDG_0002
2 0 TESTDG_0000 /dev/asm_arch01 NORMAL MEMBER ONLINE 2300 3072 TESTDG_0000
2 1 TESTDG_0001 /dev/asm_arch02 NORMAL MEMBER ONLINE 1424 2048 TESTDG_0001
当一个系统管理员或者ASM管理员修复了导致磁盘不可用的故障后(例如更换了某条故障的线缆),接下来该怎么做能让磁盘恢复online状态?这个过程能否能自动呢? 答案同样也是看情况。如果是Exadata或者是Oracle Database Appliance,磁盘会被自动online。其他情况是ASM管理员需要通过alter diskgroup命令将磁盘恢复为online状态。 例如: alter diskgroup DATA online disk ‘ORCL: DISK077’; 或者 alter diskgroup DATA online all;
总结
ASM磁盘状态为forcing
参考
ASM 11g New Featur
es - How ASM Disk Resync Wo
rks. (Doc ID 466326.1)
http://blog.itpub.net/31397003/viewspace-2143361
https://www.tidba.com/2019/06/24/asm-fast-mirror-resync/
https://blog.csdn.net/a4221722/article/details/53465490














 287
287











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









