







接下来一段时间打算整理一下Linux内存管理的内容,一是为了梳理、巩固之前的所学,二是为了从全局、从更高层次上来窥探Linux内存管理的精髓。
本文以x86的NUMA模型进行描述,所涉及的内容均基于内核版本Linux-v3.2.40。
1) node_zones : 该node包含的内存域zone
2) node_zonelists :该node的备选节点及内存域列表,后面会详细说明。
3) node_mem_map :linux为每个物理页分配了一个struct page的管理结构体,并形成了一个结构体数组,node_mem_map即为数组的指针;pfn_to_page和page_to_pfn都借助该数组实现。
4) node_start_pfn :该node中内存的起始页帧号
5) node_present_pages :该node中所有的物理page页数
6) node_spanned_pages :该node地址范围内的所有page页数,包括空洞;目前还不清楚什么情况导致与 node_present_pages不同。
7) kswapd:负责回收该node内存的内核线程,每个node对应一个内核线程kswapd。
1.2 全局node数组
在NUMA模型中,必定存在多个node节点, 因此为了快速访问各个节点的内容,内核维护了一个全局的pg_data_t的指针数组 node_data[] ,只要根据node id即可快速找到对应的pg_data_t。
2. 内存域(zone)
由于一些特殊的应用场景,导致只能分配特定地址范围内的内存(比如老式的ISA设备DMA时只能使用前16M内存;比如kmalloc只能分配低端内存,而不能分配高端内存),因此在node中又将内存细分为zone。
2.1 zone的类型
1) ZONE_DMA :定义适合DMA的内存域,该区域的长度依赖于处理器类型。比如ARM所有地址都可以进行DMA,所以该值可以很大,或者干脆不定义DMA类型的内存域。而在IA-32的处理器上,一般定义为16M。
2) ZONE_DMA32 :只在64位系统上有效,为一些32位外设DMA时分配内存。如果物理内存大于4G,该值为4G,否则与实际的物理内存大小相同。
3) ZONE_NORMAL :定义可直接映射到内核空间的普通内存域。在64位系统上,如果物理内存小于4G,该内存域为空。而在32位系统上,该值最大为896M。
4) ZONE_HIGHMEM :只在32位系统上有效,标记超过896M范围的内存。在64位系统上,由于地址空间巨大,超过4G的内存都分布在ZONE_NORMA内存域。
5) ZONE_MOVABLE :伪内存域,为了实现减小内存碎片的机制。
2.2 数据结构
1) wartermark :定义内存回收的水线,有三种水线:WMARK_HIGH、WMARK_LOW、WMARK_MIN。内核线程kswapd检测到不同的水线值会进行不同的处理,当空闲page数大于high时,内存域状态理想,不需要进行内存回收;当空闲page数低于low时,开始进行内存回收,将page换出到硬盘;当空闲page数低于min时,表示内存回收的压力很重,因为内存域中的可用page数已经很少了,必须加快进行内存回收。
2) pageset :per-cpu变量,用于实现每cpu内存的批量申请和释放,减小申请内存时的锁竞争,加快分配内存的速度。
3) free_area :空闲内存链表,按order进行分组,构建伙伴系统模型。同时,如上图所示,为了减少内存碎片,每种order下又根据迁移类型进行了分类,该部分内容后续会进行进一步的解释。free_area数组是停用bootmem分配器、释放bootmem内存时建立起来的。
4) vmstat :用于维护zone中的大量统计信息,在同步和内存回收时非常有用。
2.3 内存“价值”层次结构
内核为内存域定义了一个“价值”的层次结构,按分配的“廉价度”依次为: ZONE_HIGHMEM > ZONE_NORMAL > ZONE_DMA。
高端内存域是最廉价的,因为内核没有任何部分依赖于从该zone中分配内存, 如果高端内存用尽,对内核没有任何副作用,这也是优先分配高端内存的原因。
普通内存域有所不同,因为所有的内核数据都保存在该区域,如果用尽内核将面临紧急情况,甚至崩溃。
DMA内存域是最昂贵的,因为它不但数量少很容易被用尽,而且被用于与外设进行DMA交互,一旦用尽则失去了与外设交互的能力。
因此内核在进行内存分配时,优先从高端内存进行分配,其次是普通内存,最后才是DMA内存。
3. 备选节点及其内存域列表(node_zonelists)
从前面的分析可以知道,zone是进行内存分配的基本容器,如果从某个zone申请内存失败后怎么办呢?这就是node_zonelists将要发挥的作用。
node_zonelists定义了一个zone搜索列表(每一项代表一个zone),当从某个node的某个zone申请内存失败后,会搜索该列表,查找一个合适的zone继续分配内存。
该列表有两种排列形式,下面以例子进行说明:
假设某NUMA系统有4个内存节点,分别标记为A、B、C、D,每个内存节点有3个内存域, ZONE_DMA、 ZONE_NORMAL、 ZONE_HIGHMEM,分别标记为0、1、2。其模型如下:
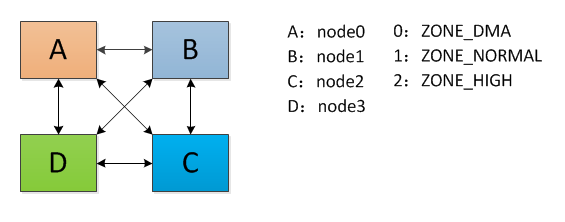
1) 按node进行排序:优先选择距离较近的node,再选择比较廉价的zone
node_zonelists列表如下:
本文以x86的NUMA模型进行描述,所涉及的内容均基于内核版本Linux-v3.2.40。
先上个图,看一下Linux中内存的布局情况,然后对几个术语进行说明:
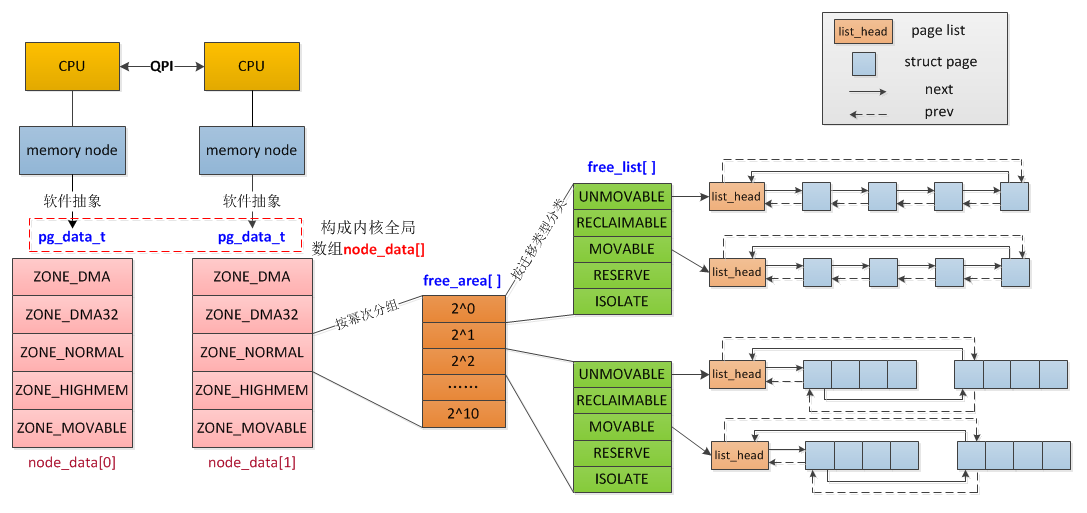
在NUMA模型中,每个CPU都有自己的本地内存节点(memory node),而且还可以通过QPI总线访问其他CPU下挂的内存节点,只是访问本地内存要比访问其他CPU下的内存的速度高许多,一般经过一次QPI要增加30%的访问时延。
Linux中对所有的内存进行统一管理,但由于关联不同的CPU导致访问速度不同,因此又将内存划分为节点(node);在节点内部,又进一步细分为内存域(zone)。
1. 内存节点(node)
由挂在同一个CPU下的一片连续的物理内存组成,在内核中使用pg_data_t进行抽象。
typedef struct pglist_data {
struct zone node_zones[MAX_NR_ZONES]; /* 该node包含的zone */
struct zonelist node_zonelists[MAX_ZONELISTS];
int nr_zones; /* 该node中zone的个数 */
#if 1 //#ifdef CONFIG_FLAT_NODE_MEM_MAP /* means !SPARSEMEM */
struct page *node_mem_map; /* struct page 指针数组,管理该node下的所有物理page */
unsigned long node_start_pfn; /* 该node的开始页帧号 */
unsigned long node_present_pages; /* 该node中物理page的个数 total number of physical pages */
/* 该node空间以页帧为单位计算的个数,可能大于物理page的个数,因为可能存在空洞 */
unsigned long node_spanned_pages; /* total size of physical page
range, including holes */
int node_id; /* 该node的id */
wait_queue_head_t kswapd_wait;
/* 指向负责回收该node中内存的swap内核线程kswapd,一个node对应一个kswapd */
struct task_struct *kswapd; /* Protected by lock_memory_hotplug() */
} pg_data_t;1) node_zones : 该node包含的内存域zone
2) node_zonelists :该node的备选节点及内存域列表,后面会详细说明。
3) node_mem_map :linux为每个物理页分配了一个struct page的管理结构体,并形成了一个结构体数组,node_mem_map即为数组的指针;pfn_to_page和page_to_pfn都借助该数组实现。
4) node_start_pfn :该node中内存的起始页帧号
5) node_present_pages :该node中所有的物理page页数
6) node_spanned_pages :该node地址范围内的所有page页数,包括空洞;目前还不清楚什么情况导致与 node_present_pages不同。
7) kswapd:负责回收该node内存的内核线程,每个node对应一个内核线程kswapd。
1.2 全局node数组
在NUMA模型中,必定存在多个node节点, 因此为了快速访问各个节点的内容,内核维护了一个全局的pg_data_t的指针数组 node_data[] ,只要根据node id即可快速找到对应的pg_data_t。
2. 内存域(zone)
由于一些特殊的应用场景,导致只能分配特定地址范围内的内存(比如老式的ISA设备DMA时只能使用前16M内存;比如kmalloc只能分配低端内存,而不能分配高端内存),因此在node中又将内存细分为zone。
2.1 zone的类型
1) ZONE_DMA :定义适合DMA的内存域,该区域的长度依赖于处理器类型。比如ARM所有地址都可以进行DMA,所以该值可以很大,或者干脆不定义DMA类型的内存域。而在IA-32的处理器上,一般定义为16M。
2) ZONE_DMA32 :只在64位系统上有效,为一些32位外设DMA时分配内存。如果物理内存大于4G,该值为4G,否则与实际的物理内存大小相同。
3) ZONE_NORMAL :定义可直接映射到内核空间的普通内存域。在64位系统上,如果物理内存小于4G,该内存域为空。而在32位系统上,该值最大为896M。
4) ZONE_HIGHMEM :只在32位系统上有效,标记超过896M范围的内存。在64位系统上,由于地址空间巨大,超过4G的内存都分布在ZONE_NORMA内存域。
5) ZONE_MOVABLE :伪内存域,为了实现减小内存碎片的机制。
2.2 数据结构
struct zone {
/* zone watermarks, access with *_wmark_pages(zone) macros */
unsigned long watermark[NR_WMARK]; /* 内存回收的水线 */
/*
* We don't know if the memory that we're going to allocate will be freeable
* or/and it will be released eventually, so to avoid totally wasting several
* GB of ram we must reserve some of the lower zone memory (otherwise we risk
* to run OOM on the lower zones despite there's tons of freeable ram
* on the higher zones). This array is recalculated at runtime if the
* sysctl_lowmem_reserve_ratio sysctl changes.
*/
/* 为各个内存域指定的保留内存,用于分配不能失败的关键性内存分配 */
unsigned long lowmem_reserve[MAX_NR_ZONES];
#ifdef CONFIG_NUMA
int node; /* 该zone所属的node的node id */
/*
* zone reclaim becomes active if more unmapped pages exist.
*/
/* 对应的page个数大于这两个值时,开始进行回收 */
unsigned long min_unmapped_pages;
unsigned long min_slab_pages;
#endif
/* 为什么是per-cpu?
* 因为每个cpu都可从当前zone中分配内存,而pageset本身实现的一个功能就是批量申请和释放
* 修改为per-cpu可减小多个cpu在申请内存时的所竞争
*/
struct per_cpu_pageset __percpu *pageset;
/*
* free areas of different sizes
*/
spinlock_t lock;
struct free_area free_area[MAX_ORDER]; /* 空闲内存链表,按幂次分组,用于实现伙伴系统 */
/* Fields commonly accessed by the page reclaim scanner */
spinlock_t lru_lock;
struct zone_lru lru[NR_LRU_LISTS]; /* 用于链接各种类型的page */
struct zone_reclaim_stat reclaim_stat;
unsigned long pages_scanned; /* 上一次回收扫描过的page数 since last reclaim */
unsigned long flags; /* zone flags, see below */
/* Zone statistics */
atomic_long_t vm_stat[NR_VM_ZONE_STAT_ITEMS]; /* 内存状态统计 */
/*
* The target ratio of ACTIVE_ANON to INACTIVE_ANON pages on
* this zone's LRU. Maintained by the pageout code.
*/
unsigned int inactive_ratio;
/*
* Discontig memory support fields.
*/
struct pglist_data *zone_pgdat;
/* zone_start_pfn == zone_start_paddr >> PAGE_SHIFT */
unsigned long zone_start_pfn; /* 该zone的起始页帧号 */
/*
* zone_start_pfn, spanned_pages and present_pages are all
* protected by span_seqlock. It is a seqlock because it has
* to be read outside of zone->lock, and it is done in the main
* allocator path. But, it is written quite infrequently.
*
* The lock is declared along with zone->lock because it is
* frequently read in proximity to zone->lock. It's good to
* give them a chance of being in the same cacheline.
*/
unsigned long spanned_pages; /* total size, including holes */
unsigned long present_pages; /* amount of memory (excluding holes) */
} ____cacheline_internodealigned_in_smp;1) wartermark :定义内存回收的水线,有三种水线:WMARK_HIGH、WMARK_LOW、WMARK_MIN。内核线程kswapd检测到不同的水线值会进行不同的处理,当空闲page数大于high时,内存域状态理想,不需要进行内存回收;当空闲page数低于low时,开始进行内存回收,将page换出到硬盘;当空闲page数低于min时,表示内存回收的压力很重,因为内存域中的可用page数已经很少了,必须加快进行内存回收。
2) pageset :per-cpu变量,用于实现每cpu内存的批量申请和释放,减小申请内存时的锁竞争,加快分配内存的速度。
3) free_area :空闲内存链表,按order进行分组,构建伙伴系统模型。同时,如上图所示,为了减少内存碎片,每种order下又根据迁移类型进行了分类,该部分内容后续会进行进一步的解释。free_area数组是停用bootmem分配器、释放bootmem内存时建立起来的。
4) vmstat :用于维护zone中的大量统计信息,在同步和内存回收时非常有用。
2.3 内存“价值”层次结构
内核为内存域定义了一个“价值”的层次结构,按分配的“廉价度”依次为: ZONE_HIGHMEM > ZONE_NORMAL > ZONE_DMA。
高端内存域是最廉价的,因为内核没有任何部分依赖于从该zone中分配内存, 如果高端内存用尽,对内核没有任何副作用,这也是优先分配高端内存的原因。
普通内存域有所不同,因为所有的内核数据都保存在该区域,如果用尽内核将面临紧急情况,甚至崩溃。
DMA内存域是最昂贵的,因为它不但数量少很容易被用尽,而且被用于与外设进行DMA交互,一旦用尽则失去了与外设交互的能力。
因此内核在进行内存分配时,优先从高端内存进行分配,其次是普通内存,最后才是DMA内存。
3. 备选节点及其内存域列表(node_zonelists)
从前面的分析可以知道,zone是进行内存分配的基本容器,如果从某个zone申请内存失败后怎么办呢?这就是node_zonelists将要发挥的作用。
node_zonelists定义了一个zone搜索列表(每一项代表一个zone),当从某个node的某个zone申请内存失败后,会搜索该列表,查找一个合适的zone继续分配内存。
该列表有两种排列形式,下面以例子进行说明:
假设某NUMA系统有4个内存节点,分别标记为A、B、C、D,每个内存节点有3个内存域, ZONE_DMA、 ZONE_NORMAL、 ZONE_HIGHMEM,分别标记为0、1、2。其模型如下:
1) 按node进行排序:优先选择距离较近的node,再选择比较廉价的zone
node_zonelists列表如下:

或者

可能存在两种列表是因为A到B和A到D的距离是一样的。
2) 按zone进行排序:优先选择比较廉价的zone,再选择距离较近的node
node_zonelists列表如下:

或者

可能存在两种列表是因为A到B和A到D的距离是一样的。
还有一个关键的数据结构struct page由于太复杂也太重要,后面单独进行介绍。















 1997
1997











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









