







前段时间周末快11点了,收到前下属小明的QQ消息和电话
说遇到个很急的问题,公司在做个活动,但服务器经常挂,就算重启服务器, 15分钟后,rds数据库cpu就会到 100%
把连接情况发了个图过来
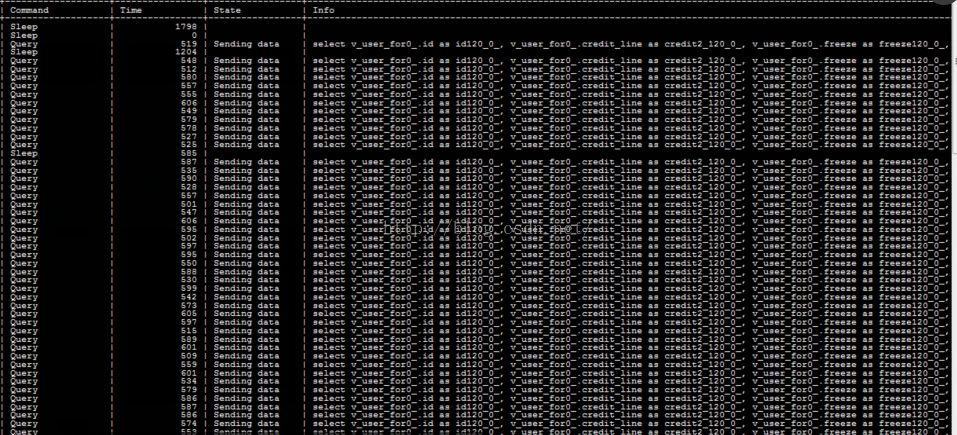
通过以上截图,给他分析了下:
在连接数 500 以下的情况,同一查询居然占满了CPU所有资源,第一感觉是此 sql 肯定没使用到索引或此sql过于繁杂,当然还有个疑问就是为什么此 查询量会这么多?
由于是新活动,服务器又挂了这么久了,老板一直在催,他实在搞不定,迫于压力向我求助,但远程还是不方便支持,就邀请现场支撑下。
于是打个的士狂奔过去。
到了现场后,仔细分析了连接情况,从 sql 来看,是生成的,而小明找的确是自己写的类似的 sql,很遗憾 方向错了。
得冷静下,想了些方案来进行处理:
1.要找根源则需要首先得找到此条 sql 的生成地点,然后重新手工写,不自动生成,建立索引,加快数据获取速度
2.采用缓存减少此sql 的执行次数
经过一段时间排查后,终于找到了此 sql 生成地点,并单独在数据库中进行执行(应用服务器已关闭),explan 分析了下,发现本身执行并不慢。
但仔细看代码后,发现一个很严重的代码问题,导致此 sql 的查询量非常巨大,然后数据库崩了。
以下为大概写法:
class A {
public B b;
public B getB(){ // 查询数据库,获取此对象}
}
//重点的是下面的代码
A a=new A();
a.b.属性1
a.b.属性2
a.b.属性3 .......
实际上每次在访问 b 的任意属性时,都会重新从数据库获取最新数据,数据库怎么可能不被搞死,新活动用户量本来就大,并发量多一点点,用户点着点着,数据库直接崩了。
找到原因后,采用方案2处理,问题解决(后面几天也有沟通,同样或更多连接数,数据库CPU占用率低于10%)。
解决后,顺便给他推荐了能提高效率的工具, play 局部编译工具,他用着评价不错
总结:
sql 多采用 explan 分析下,索引很重要
写代码真不能图快,图快往往是在挖坑,要注重性能及基本原则。
一旦后续用户数爆增的情况下,就得多采用缓存及数据库读写分离 或分布式应用来解决,sql 性能瓶颈也需要非常关注。















 1339
1339

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









