







编写配置文件,编写一个服务器软件,按照指定的全限定名,根据路径,让服务器创建这个对象,调用制定方法。
文章目录
1.需求说明
1.1xml文件
给定xml文件
<a1>
<c>hello</c>
<d>com.itheima.HelloServlet</d> <!--全限定名,能根据下面给定的路径,找到这个全限定名并创建对象,调用方法 -->
</a1>
<b1>
<c>hello</c>
<e>/hello</e> <!--给定路径-->
</b1>
1.2分析
- 1.编写xml
- 2.解析xml
- 3.根据全限定名创建对象,调用方法。
2.XML文件
2.1基础
-
可扩展的标签语言
-
标签自定义
-
作用:作为配置文件(本质上是存储数据)
-
书写规范:
- 1.区分大小写
- 2.有根标签
- 3.标签必须关闭:
<xx></xx>,<xx/> - 4.属性必须用引号引起来:
<xx att="value"/> - 5.标签体重的空格或者换行或者制表符都是作为数据内容存在的
<xx>aa</xx><xx> aa </xx>- 二者是不等价的
- 6.特殊字符必须转义:
< > &
-
满足上面规范的文件我们称之为是一个格式良好的xml文件.可以通过浏览器浏览
-
后缀名:
.xml
2.2xml组成部分
2.2.1声明:告诉别人我是一个xml文件
- 格式:
<?xml ..... ?> - 例如:
<?xml version="1.0" encoding="UTF-8"?> <?xml version='1.0' encoding='utf-8' standalone="yes|no"?> - 要求:
- 必须在xml文件的第一行
- 必须顶格写
2.2.2元素(标签)
- 格式:
<xx></xx><xx/>
- 要求:
- 1.必须关闭
- 2.标签名不能以
xml Xml XML开头 - 3.标签名中不能出现
空格 “ ”或者":"等特殊字符
2.2.3属性
- 格式:
<xx 属性名=“属性值”/> - 要求:
属性值必须加引号
2.2.4注释
<!--内容-->
2.2.5CDATA
- xml中的特殊字符必须转义
- CDATA 保证数据保证特殊字符以字符形式输出
- 格式:
<![CDATA[ 原样输出的内容 ]]>
3.xml解析
3.1解析方式
- 1.sax:特点:逐行解析,只能查询.
- 2.dom:特点:一次性将文档加载到内容中,形成一个dom树.可以对dom树curd操作\
3.2解析技术
- JAXP:sun公司提供支持DOM和SAX开发包
- JDom:dom4j兄弟
- jsoup:一种处理HTML特定解析开发包
dom4j:比较常用的解析开发包,hibernate底层采用。
3.3dom4j技术进行查询
-
1.导入jar包:
dom4j-1.6.1.jar -
2.创建核心对象:
new SAXReader() -
3.将xml文档导入内存形成一棵树
<?xml version="1.0" encoding="UTF-8"?> <web-app version="2.5"> <servlet> <servlet-name>HelloMyServlet</servlet-name> <servlet-class>com.itheima.HelloMyServlet</servlet-class> </servlet> <servlet-mapping> <servlet-name>HelloMyServlet</servlet-name> <url-pattern>/hello</url-pattern> </servlet-mapping> </web-app>
-
4.通过根节点获取其他节点(文本,属性,元素)
- 获取所有子元素:
List<Element> list = root.elements(); - 获取元素的指定属性内容:
String value=root.attributeValue("属性名"); - 获取子标签标签体:遍历list获取到每一个元素:
String text=ele.elementText("子标签名称")
public static void main(String[] args) throws Exception { //1.创建核心对象 SAXReader reader = new SAXReader(); //2.获取dom树 Document doc = reader.read("D:\\Users\\xiaopangtou\\OneDrive\\project_web_idea\\xml_tomcat\\xml\\web.xml"); //3.获取根节点 Element root = doc.getRootElement(); //获取其他节点 List<Element> elements = root.elements(); // System.out.println(elements.size()); //遍历集合 for (Element ele:elements) { //获取servlet-name的标签体 String text = ele.elementText("servlet-name"); System.out.println("servlet-name: " + text); //获取url-pattern的标签体 System.out.println("url-pattern: " + ele.elementText("url-pattern")); } //获取root的属性 String value = root.attributeValue("version"); System.out.println(value); }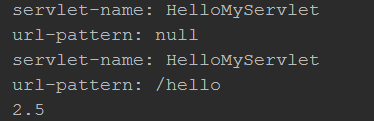
- 获取所有子元素:
3.4xpath解析技术
-
依赖于dom4j -
1.导入jar包:
jaxen-1.1-beta-6.jar -
2.加载xml文件到内存
//加载dom树 Document doc = new SAXReader().read("D:\\Users\\xiaopangtou\\OneDrive\\project_web_idea\\xml_tomcat\\xml\\web.xml"); -
3.使用api
selectNodes("表达式")selectSingleNode("表达式")
-
4.表达式的写法
- 从根节点匹配
- 从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置
- 例如一个标签下有一个id属性且有值 id=2;
- 元素名[@属性名=‘属性值’]
- 元素名[@id=‘2’]
public static void main(String[] args) throws Exception { //加载dom树 Document doc = new SAXReader().read("D:\\Users\\xiaopangtou\\OneDrive\\project_web_idea\\xml_tomcat\\xml\\web.xml"); //获取节点 //1.从根节点开始获取节点 List<Element> elements = doc.selectNodes("/web-app/servlet/servlet-name"); Element element = elements.get(0); //获取文本信息 System.out.println(element.getText()); //2.获取某个标签下的单个节点 //这里就不需要从根节点开始写 可以从任意节点开始 Element ele = (Element) doc.selectSingleNode("//servlet/servlet-name"); System.out.println(ele.getText()); }
4.反射
4.1先定义一个测试类,用于实现反射调用
/**
* 20190804
* 创建一个对象 内置三个方法 用于反射概念的讲解
*/
public class HelloMyServlet {
public void add(){
System.out.println("空参的add方法");
}
public void add(int i, int j){
System.out.println("带有两个参数的add方法,其和为:"+(i+j));
}
public int add(int i){
System.out.println("带有一个参数,且返回值为int的add方法");
return i+10;
}
}
4.2实现反射
4.2.1四个步骤
- 1.获取对应的
class对象-
方法1:Class clazz=Class.forName("全限定名");//1.先根据全限定名(包名+类名) 获取class对象 //这里本质上 是将一个类加载到内存中 然后形成的一个字节码对象 Class clazz = Class.forName("core.HelloMyServlet"); -
方法2:Class clazz=类名.class;
// 1.获取class对象 //这里本质上 是将一个类加载到内存中 然后形成的一个字节码对象 //获取class对象的方法2 Class clazz = HelloMyServlet.class; -
方法3:Class clazz==对象.getClass();
// 1.获取class对象 HelloMyServlet hello = new HelloMyServlet(); Class clazz = hello.getClass(); -
2.通过class对象创建一个实例对象,相当于 new 类():
Object clazz.newInstance();//2.通过字节码对象 再创建一个实例对象 相当于空参的调用器 HelloMyServlet hello = (HelloMyServlet) clazz.newInstance(); -
3.通过class对象获取一个方法(
public 修饰的):Method method=clazz.getMethod("方法名",Class .... paramType); paramType为参数的类型//3.根据字节码对象获取方法对象 参数是方法名 Method m = clazz.getMethod("add"); //3.获取含有两个参数的方法对象 方法名 参数1的类型 参数2的类型 ... Method m = clazz.getMethod("add", int.class,int.class); -
4.让方法执行:
method.invoke(Object 实例对象,Object ... 参数);
-
4.2.2实例
@Test
public void f1(){
//通过实例化一个类 生成对象 然后通过实例化的对象来调用方法
HelloMyServlet hello = new HelloMyServlet();
hello.add();
hello.add(1,2);
}
/**
* 反射的实现方法1
* @throws Exception
*/
@Test
public void f2() throws Exception {
//1.先根据全限定名(包名+类名) 获取class对象
//这里本质上 是将一个类加载到内存中 然后形成的一个字节码对象
Class clazz = Class.forName("core.HelloMyServlet");
//2.通过字节码对象 再创建一个实例对象 相当于空参的调用器
HelloMyServlet hello = (HelloMyServlet) clazz.newInstance();
//3.再通过这个实例对象调用方法
hello.add();
}
/**
* 反射的实现方法1
*/
@Test
public void f3()throws Exception {
//1.先根据全限定名(包名+类名) 获取class对象
//这里本质上 是将一个类加载到内存中 然后形成的一个字节码对象
Class clazz = Class.forName("core.HelloMyServlet");
//2.通过字节码对象 再创建一个实例对象 相当于空参的调用器
HelloMyServlet hello = (HelloMyServlet) clazz.newInstance();
//3.根据字节码对象获取方法对象 参数是方法名
Method m = clazz.getMethod("add");
//4. 让方法对象m 执行
// 其中 第一个参数 obj 是调用这个方法的实例 , arg 是该方法执行时需要的参数 下面没有参数
// 则相当于调用 add()
m.invoke(hello);
}
/**
* 反射的实现方法2
* @throws Exception
*/
@Test
public void f4()throws Exception{
// 1.获取class对象
//这里本质上 是将一个类加载到内存中 然后形成的一个字节码对象
//获取class对象的方法2
Class clazz = HelloMyServlet.class;
//2.通过字节码对象 再创建一个实例对象 相当于空参的调用器
HelloMyServlet hello = (HelloMyServlet) clazz.newInstance();
//3.获取含有两个参数的方法对象 方法名 参数1的类型 参数2的类型 ...
Method m = clazz.getMethod("add", int.class,int.class);
//4.执行方法 传入参数 等价于 add(10,20)
m.invoke(hello, 10,20);
}
/**
* 反射的实现方法3
* @throws Exception
*/
@Test
public void f5()throws Exception{
// 1.获取class对象
HelloMyServlet hello = new HelloMyServlet();
Class clazz = hello.getClass();
//2.通过字节码对象 再创建一个实例对象 相当于空参的调用器
// HelloMyServlet hello = (HelloMyServlet) clazz.newInstance();
//3.获取含有两个参数的方法对象 方法名 参数1的类型 参数2的类型 ...
Method m = clazz.getMethod("add", int.class,int.class);
//4.执行方法 传入参数 等价于 add(10,20)
m.invoke(hello, 10,20);
}
5.结合反射技术实现通过xml文件中的全限定名对应的方法
5.1自定义全限定名来实现这个过程
@Test
public void f1() throws Exception {
//1.定义一个map 实现从 路径(key:/hello) 到 全限定名(value:core.HelloMyServlet)的映射
Map<String,String> map = new HashMap<>();
map.put("/hello", "core.HelloMyServlet");
//2.通过key获取value
String value = map.get("/hello");
//3.通过全限定名 创建实例
Class clazz = Class.forName(value);
HelloMyServlet hello = (HelloMyServlet) clazz.newInstance();
//4.根据clazz获取方法对象
Method m = clazz.getMethod("add");
//5.通过方法对象执行方法
m.invoke(hello);
}
5.2解析xml拿到全限定名
/**
* 20190804
* f1的方法 只是展现了整个过程 但是实际的路径 和 全限定名都应该从xml文件中获取
* 那就很简单了 分别从 xml文件中解析出 servlet-name 和 url-pattern 分别作为 value 和 key 放进一个hashmap里即可
* @throws Exception
*/
@Test
public void f2() throws Exception {
//1.定义一个map 实现从 路径(key:/hello) 到 全限定名(value:core.HelloMyServlet)的映射
Map<String,String> map = new HashMap<>();
//2.解析xml文件 从中获取 路径(url-pattern) 和 全限定名(core.HelloMyServlet)
//2.1获取dom树
Document doc = new SAXReader().read("D:\\Users\\xiaopangtou\\OneDrive\\project_web_idea\\xml_tomcat\\xml\\web.xml");
//2.2 解析出路径和全限定名
String urlPattern = doc.selectSingleNode("//servlet-mapping/url-pattern").getText();
String servletClass= doc.selectSingleNode("//servlet/servlet-class").getText();
// System.out.println("utl:"+urlPattern);
// System.out.println(" servletClass:" + servletClass);
//3.解析出来的key 和 value push进map
map.put(urlPattern, servletClass);
//4.通过key获取value
String value = map.get(urlPattern);
//5.通过全限定名 创建实例
Class clazz = Class.forName(value);
HelloMyServlet hello = (HelloMyServlet) clazz.newInstance();
//6.根据clazz获取方法对象
Method m = clazz.getMethod("add");
//7.通过方法对象执行方法
m.invoke(hello);
}
到这里有一种恍然大悟的感觉,原来是这样子让具体类里的函数跑起来的,原来是通过前端发来的请求地址中解析出要调用的方法,然后从xml文件中解析出全限定名,然后再通过反射去到具体的业务代码里面执行。
6.xml约束
规定xml中可以出现那些元素及那些属性,以及他们出现的顺序.
- 分类
- DTD约束:struts hiebernate等等
- SCHEMA约束:tomcat spring等等
6.1DTD约束
- 和xml的关联 (一般都会提供好,复制过来即可,有时候连复制都不需要.)
- 方式1:内部关联
- 格式: <!DOCTYPE 根元素名 [dtd语法]>
- 方式2:外部关联-系统关联
- 格式: <!DOCTYPE 根元素名 SYSTEM “约束文件的位置”>
- 例如:<!DOCTYPE web-app SYSTEM “web-app_2_3.dtd”>
- 方式3:外部关联-公共关联(约束文件放在网络位置)
- 格式:<!DOCTYPE 根元素名 PUBLIC “约束文件的名称” “约束文件的位置”>
6.2DTD语法(了解)
-
元素:<!Element 元素名称 数据类型|包含内容>
-
数据类型:#PCDATA:普通文本 使用的时候一般用()引起来
-
包含内容:该元素下可以出现那些元素 用()引起来
-
符号:
- * 出现任意次
- ? 出现1次或者0次
- + 出现至少1次
- | 或者
- () 分组
- , 顺序
-
属性:
- 格式:<!ATTLIST 元素名 属性名 属性类型 属性是否必须出现>
- 属性类型:ID:唯一,CDATA:普通文本
- 属性是否必须出现 REQUIRED:必须出现 IMPLIED:可以不出现
-
一个xml文档中只能添加一个DTD约束
-
xml的学习目标:
- 编写一个简单的xml文件
- 可以根据约束文件写出相应xml文件.
6.3SCHEMA约束
- 一个xml文档中可以添加多个schema约束
- xml和schema的关联.
- 格式:
- <根标签 xmlns="…" …>
- <根标签 xmlns:别名="…" …>
- 名称空间:
- 关联约束文件
- 规定元素是来源于那个约束文件的
- 例如:
- 一个约束文件中规定 table(表格) 表格有属性 row和col
- 还有一个约束文件规定 table(桌子) 桌子有属性 width和height
- 在同一个xml中万一我把两个约束文件都导入了,
- 在xml中我写一个table,这个table有什么属性???
- 我们为了避免这种情况的发生,可以给其中的一个约束起个别名
- 使用的时候若是没有加别名那就代表是来自于没有别名的约束文件
- 例如 table(表格) 给他起个别名 xmlns:a="…"
- 在案例中使用 a:table 代表的是表格
- 若在案例中直接使用 table 代表的是桌子
- 在一个xml文件中只能有一个不起别名;
schema约束本身也是xml文件.
















 187
187











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









