






Debezium迁移和同步Oracle数据
概览
Debezium是RedHat开源的一个将多种数据源实时变更数据捕获,形成数据流输出的开源工具。当前支持MySQL、PostgreSQL、SQL Server、Oracle、Db2等常用数据库。Debezium Oracle connector是基于kafka conect的一种实现,用于捕获并记录Oracle数据库中发生的行级更改,包括在connector运行期间新增的表。可以将connector配置为仅捕获schema和表的特定子集的变化,或者忽略、屏蔽或截断特定列中的值。
虽然当前官方仅测试了Oracle EE 12 和 19两个版本,但是从原理上connector适用于所有Oracle 版本。Debezium支持LogMiner和XStream API两种方式从Oracle获取更改事件,但XStream API需要GoldenGate license,而LogMiner完全是免费的,所以一般情况推荐使用LogMiner,这也是默认的设置。
特点
- 支持全量快照,在第一次启动时抽取监视表的全量数据;
- 支持增量快照,分块抽取全量数据,并与数据变化事件交错传递到下游,适合表中有海量数据的场景;
- 支持即席快照,即手动触发全量快照或增量快照,可用数据补录等;
- 全量迁移和数据同步无缝衔接,完成全量快照迁移后,自动启动增量同步,即使迁移过程中发数据变化也不会丢失数据;
- 高可用部署,依靠kafka connect集群特性,如若遇到故障自动重启;
- 正好一次语义,所有状态数据记录在特定的kafka topic中,即使重启也不会导致数据丢失或重复;
- 支持事务边界事件,支持在事件流中添加事务开始和结束事件,以及在每个事件中标识事务ID,从而在下游应用可以以事务为单位处理事件流;
- 支持捕获DDL事件;
部署
先决条件
- 已部署:Apache Zookeeper、Apache Kafka和Kafka connect;
- 已安装Oracle,并进行必要的配置,详见;
- Oracle的JDBC驱动和XStream API驱动(仅在XStream模式需要);
部署流程
Debezium connector可以理解为自定义的一个kafka connector组件,遵循添加通用的kafka connector流程。具体流程如下:
- 下载 Debezium connector插件压缩包;
- 解压到Kafka Connect所在的服务器上任意路径;
- 将该路径添加到Kafka Connect的插件路径列表中;
- 配置connector将其加入到Kafka Connect集群,其中比较重要的配置是指定期望监听的表;
- 重启Kafka Connect集群;
详细配部署步骤参见。
Debezium connector启动后,首先生成监视表的快照数据,将全量的数据转换成事件,推送到下游。完成快照后,将持续监视oracle中的变化,以流式事件的方式推送到kafka的多个topic中,后续的应用程序可以根据需要处理。
快照
通常,Oracle 服务器上的redo日志配置为不保留数据库的完整历史记录。因此,Debezium Oracle connector无法从redo日志中检索数据库的整个历史记录。为了使connector能够为数据库的当前状态建立基线,connector第一次启动时,它会获取数据库的初始一致快照。
可以通过设置snapshot.mode配置属性的值来自定义connector创建快照的方式。默认情况下,连接器的快照模式设置为initial。
connector默认流程–创建初始快照
当快照模式设置为默认时,connnector完成以下任务来创建快照:
- 确定需要捕获的表;
- 获取监视表的
ROW SHARE LOCK,以防止在创建快照期间表结构发生变化。Debezium持有锁的时间很短; - 从服务器上的redo日志获取当前系统改变号(SCN)的位置;
- 获取所有相关表的结构信息;
- 释放步骤2获取的锁;
- 依据步骤3读取的SCN位置,全表扫描所有相关数据库表和schema(例如
(SELECT * FROM … AS OF SCN 123),为每行生成一个READ事件,并且将事件写入kafka中与表相关联的topic; - 在connector的
offset在记录已成功完成快照,这里的offset是kafka的一个connector使用的一个特定kafka topic;
快照处理流程开始后,如果由于connector失败、rebalancing等原因导致流程中断,connector重启后处理流程会重新启动。connector完成初始快照后,它会从它在步骤3中读取的SCN位置开始处理redo日志,不会错过任何更新。如果connector因某种原因再次停止,则在重新启动后,它会从先前停止的位置继续流式处理redo日志。
Table 1. connector配置属性snapshot.mode:
| 取值 | 描述 |
|---|---|
| initial | connector按照默认快照流程的方式处理数据库快照,当快照完成后,connector开始流式处理数据库后续的改变事件 |
| schema_only | connector获取所有相关表的结构信息,执行默认快照流程的除步骤6以外的所有步骤,即connector启动阶段不会生成表示数据集的READ事件 |
即席快照
当初始快照完成以后,它不会再次执行。这是因为一般情况下,数据库的后续变化数据,将通过流式读取redo日志实现。
但有时,重新执行快照(全部或部分表)非常有用,此类情况包括:
- 一个新表被添加到捕获表的列表中;
- 部分kafka topic被删除,其内容需要重建;
- 由于配置错误,导致数据损坏;
Debezium提供了一种信号表的方式,实现再次执行快照流程。原理是在connector的配置文件中设置signal.data.collection,其取值是数据库中的一个表的名字,例如some_schema.debezium_signals。该表有三列,其建表语句的示例如下:
CREATE TABLE debezium_signals (id VARCHAR(42) PRIMARY KEY, type VARCHAR(32) NOT NULL, data VARCHAR(2048) NULL);
当需要重新执行快照时,在该表中插入如下一条记录。其中id字段可以是任意字符串,type字段必须是"execute-snapshot",data字段是一个json,内容是需要产生快照表的集合。
insert some_schema.debezium_signals values("d139b9b7-7777-4547-917d-e1775ea61d41","execute-snapshot","{data-collections: [public.MyFirstTable, public.MySecondTable]}")
增量快照
初始快照是获取预先存储在数据库中的所有数据的好方法。但是,这种方法也有一些缺点:
- 对于较大的数据集,可能需要很长时间才能完成;数小时甚至数天;
- 必须是快照完成之后,才能开始redo日志的流式处理;
- 快照不可恢复,如果在快照完成之前connector停止或重新启动了,则必须从头开始重新启动快照;
- 在开始流式处理redo日志之后加入的新表,不会快照;
为了缓解这些问题,引入了一种称为增量快照的新机制。该机制是参考Netflix发布的DBLog而设计,详见Debezium增量快照设计文档、DBLog_A-Watermark-Based-Change-Data-Capture-Framework和Netflix发布DBLog:一款通用的变化数据捕获框架。
算法
这里的快照与数据库通常意义的snapshot的语义并不相同,而是通过执行类似select * from table where start_key <= primary_key and primary_key <end_key的语句获取的数据分片,每次处理一个分片,直至处理完全表存量数据。这些数据分片产生的事件和redo日志产生的事件交错在一起,传递到下游应用。该算法的核心是处理数据分片和redo日志冲突的问题,即在处理数据分片过程中本分片又被其他应用修改了的问题,其算法可以简单用下图描述:
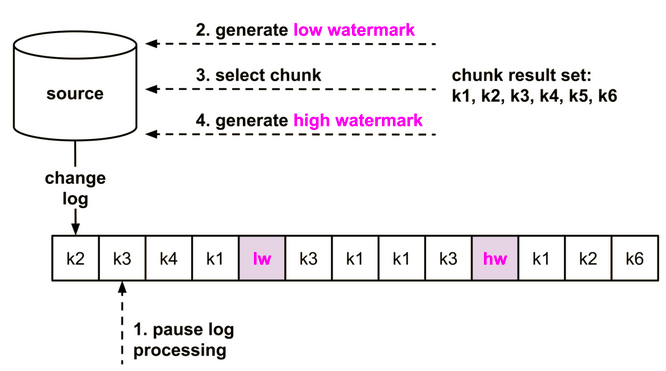
首先,在开始读数据分片之前将low watermark插入redo日志,开始读取数据分片并缓存在内存中,完成之后将high watermark插入redo日志。
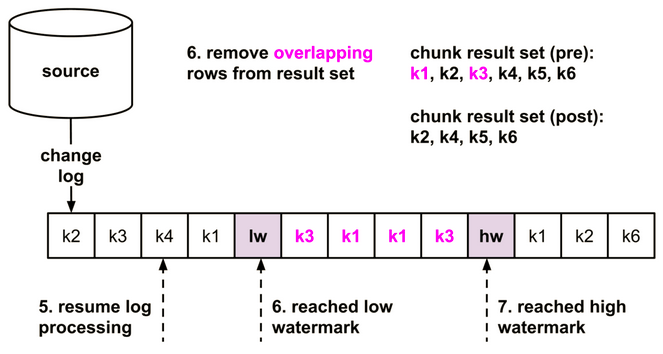
接着开始处理redo日志,在这过程中必然会遇到low watermark和high watermark两条特殊的日志。这两条特殊日志组成了一个日志窗口,如果该窗口内的redo日志和前面的数据分片重叠(即有相同的primary_key),则删除数据分片中对应的数据。处理完窗口内的redo日志后将剩余的数据分片输出到下游。
实现
为实现将水印low watermark和high watermark插入到redo日志,需要在源库中增加两个表snapshot-window-open和snapshot-window-close,并且将其加入到debezium监视的白名单。当需要在redo日志中插入水印时,在表中插入数据即可。
需要启用信号表,以触发增量快照执行,信号表的使用方法参见‘即席快照’。
生成的增量快照事件和普通的redo日志事件交错在一起,格式如下:
{
"before":null,
"after": {
"pk":"1",
"value":"New data"
},
"source": {
...
"snapshot":"incremental"
},
"op":"r",
"ts_ms":"1620393591654",
"transaction":null
}
kafka topic
Debezium最终将发生在数据库上的INSERT、UPDATE和DELETE事件发送到kafka的topic上,每个表都对应的一个topic,其命名规则为:
serverName.schemaName.tableName。
例如,如果服务名为fulfillment,schema名为inventory,该数据库包含的表:orders、customers和products,则发送事件到以下的3个topic中,每个表对应一个topic:
fulfillment.inventory.orders
fulfillment.inventory.customers
fulfillment.inventory.products
除了上面的topic以外,还有一个名字为服务名的topic,用于存放schema变化事件,如上例中该topic名称为fulfillment。当任意的一个表结构发送变化,在该topic中将产生一条新的事件,消息格式参见
对事务的支持
上面描述的变化事件都是基于数据库在行的变化,但是有时我们希望能够感知事务的边界,比如那些事件是属于同一个事务,以便能在下游重做该事务。Debezium针对这种情景,提供事务边界事件机制。当启用该功能后,将增加一个新的topic,名字为<database.server.name>.transaction,当事务的BEGIN和END时,将在topic中分别收到两个标识事务边界个事件,其格式为:
| 名称 | 取值 | 说明 |
|---|---|---|
| status | BEGIN 或 END | |
| id | 任意字符串 | 事务的标识符 |
| event_count | 整型 | 表示该事务产生的事件总数量 |
| data_collections | json数组 | 事件集合 |
例子:
{
"status": "BEGIN",
"id": "5.6.641",
"event_count": null,
"data_collections": null
}
{
"status": "END",
"id": "5.6.641",
"event_count": 2,
"data_collections": [
{
"data_collection": "ORCLPDB1.DEBEZIUM.CUSTOMER",
"event_count": 1
},
{
"data_collection": "ORCLPDB1.DEBEZIUM.ORDER",
"event_count": 1
}
]
}
在启用了事务记录后,在数据变化事件中也增加了于事务相关字段,如下例所示:
{
"before": null,
"after": {
"pk": "2",
"aa": "1"
},
"source": {
...
},
"op": "c",
"ts_ms": "1580390884335",
"transaction": {
"id": "5.6.641",
"total_order": "1",
"data_collection_order": "1"
}
}
数据变化事件
事件包含key和value两部分
key
key又包含schema和payload两部分,其中schema是对内容类型的描述,payload是真正的内容;
例如,有一个表的定义如下:
CREATE TABLE customers (
id NUMBER(9) GENERATED BY DEFAULT ON NULL AS IDENTITY (START WITH 1001) NOT NULL PRIMARY KEY,
first_name VARCHAR2(255) NOT NULL,
last_name VARCHAR2(255) NOT NULL,
email VARCHAR2(255) NOT NULL UNIQUE
);
该表共用4个列,其中id是其主键。当该表发送数据变化后,由Debezium connector生成的事件的key如下:
{
"schema": {
"type": "struct",
"fields": [
{
"type": "int32",
"optional": false,
"field": "ID"
}
],
"optional": false,
"name": "server1.INVENTORY.CUSTOMERS.Key"
},
"payload": {
"ID": 1004
}
}
value
同样是上述的表,当该表发送数据变化后,由Debezium connector生成的事件的value如下:
{
"schema": { ... },
"payload": {
"before": {
"ID": 1004,
"FIRST_NAME": "Anne",
"LAST_NAME": "Kretchmar",
"EMAIL": "annek@noanswer.org"
},
"after": {
"ID": 1004,
"FIRST_NAME": "Anne",
"LAST_NAME": "Kretchmar",
"EMAIL": "anne@example.com"
},
"source": {
"version": "1.7.0.Final",
"name": "server1",
"ts_ms": 1520085811000,
"txId": "6.9.809",
"scn": "2125544",
"commit_scn": "2125544",
"snapshot": false
},
"op": "u",
"ts_ms": 1532592713485
}
}
schema是payload的元数据,描述了payload部分的数据结构。payload分为:before、after、source、op和ts_ms几部分。
- op :表示当前事件的类型,取值为:c表示insert、u表示update、d表示delete、r表示快照read;
- ts_ms: connector处理该事件的本地时间戳,可以省略;
- before:变化事件发生之前的值;
- after:变化事件发生之后的值;
- source:事件源的结构信息,包括connector版本、事务ID等;















 439
439











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









