








大家好呀
我是浪前
今天讲解的是网络篇传输层:UDP协议特性
UDP协议的特性如下所示:
- UDP是无连接的
- UDP是不可靠传输
- UDP是全双工的
- UDP是面向数据报的
今天来学习UDP协议的特性,主要就是去通过学习UDP协议的数据报格式,进一步去了解协议的特性
端口号
端口号的使用场景:
写一个服务器,要手动指定一个端口号,通过端口来区分出当前这个主机上的不同应用程序
写一个客户端,在通信的时候,系统会自动分配一个端口号
大小
端口号,固定就是两个字节,表示的数据范围就是0 ~ 65535,一般端口号不会使用0
1~1023称为知名端口号
1024~65535是普通端口号
知名端口号:
22:ssh服务器的端口号,ssh协议是用来登录远程主机的,后面会用到
80: http服务器的端口号
443:https服务器的端口号
这个端口号只是一个建议,可以不去采纳
UDP报文格式
UDP数据报一共包含两个部分:
- 报头
- 载荷
UDP数据报 = UDP报头 + 载荷(应用层数据包)
大概的格式如下所示:
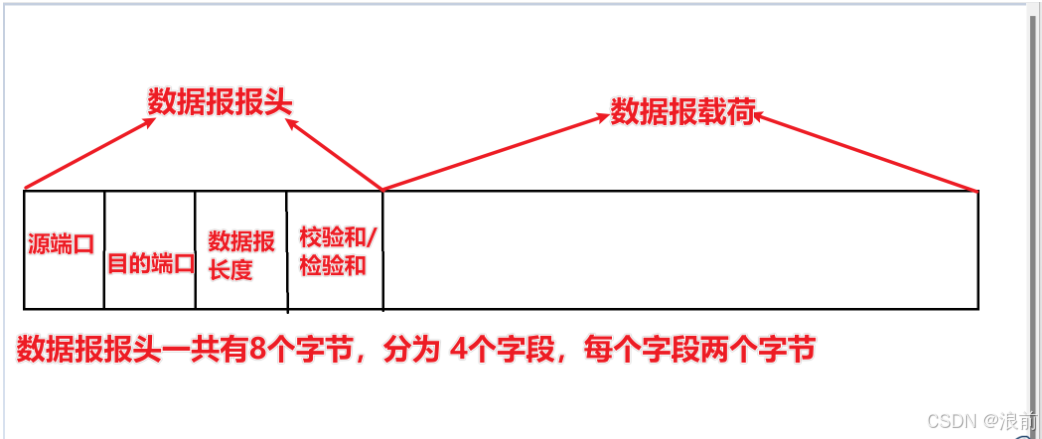
报头和载荷之间可以认为是一个“字符串拼接”,是二进制数据
数据报长度
大小
数据报的长度是两个字节,16位表示的数据,表示的范围是0~65535,
UDP数据报长度最大的就只能是64KB
但是在现在的大数据时代,64KB显然已经是太小了
这样会出问题:
当数据的长度大于64KB的时候,就会发生数据截断:
数据截断:
即本来数据是完整的,但是超过64KB的部分就直接没有了,消失了,被截断了
数据截断的解决方案:
一共有两种解决方案:
- 拆分数据包
- 使用TCP代替UDP
拆分数据包:
在应用层上,把数据包拆分,在拆分之前,是一个数据报表示多个数据
在拆分之后,一个数据报表示一个数据,或者多个数据报表示一个数据
这一种拆分的方式虽然可以解决问题,但是开发成本太高,测试维护成本太高,一般不轻易使用
使用TCP代替UDP:
使用TCP数据报来代替UDP数据报
因为TCP数据报是没有长度限制的,也就不会发生上述的数据截断的问题
校验和
校验和本质上是一个字符串,体积比原始的数据更小,又是通过原始的数据生成的
如果得到的数据和原始的数据相同,那么两者的校验和也相同
反之,校验和相同,那么原始数据也大概率相同
校验和的目的
为了去验证在数据传输过程中数据是否正确
比如,在网上买东西的时候,在快递过程中,这个东西可能会坏掉
而在网络传输过程中的数据也有可能会变成错误的数据
所以需要通过校验和去验证接收方接收到的数据是不是正确的数据
校验和的工作流程:
第一步:发送方把要发送的数据d1通过一定的算法来计算出校验和c1
第二步:发送方将c1和d1一起通过网络发送出去
第三步:接收方收到数据后,收到的数据为d2,(收到的数据可能不是d1),收到的校验和c1
第四步:接收方根据d2按照刚刚相同的算法去计算出一个校验和c2
第五步:对比c1和c2,如果c1和c2相同,则d1和d2是相同的数据,如果不同,则d1和d2不相同
比特翻转
在网络传输过程中,传输的数据本质上就是光信号/电信号/电磁波
而这些光电信号在传输过程是很有可能受到干扰的
受到干扰之后,就会导致原来的高电平/低电平表示0和1
在受到外来磁场干扰之后,会使得原来的低电平转变成高电平,原来的高电平转化为低电平
这个过程就被称为比特翻转
在十几年前,如果出现了太阳黑子/太阳耀斑,就会直接导致地球上的网络通信直接中断
虽然在现在的网络传输体系当中,有了一系列的数据传输过程中的保护机制,可以减少外来的干扰
但是并不代表永远都不会受到干扰了了,还是会受到一些干扰的
所以数据报里面的校验和就是为了去验证网络传输过程中的数据是否正确的,
验证数据有没有发生比特翻转
**如果发现数据已经出现了比特翻转,就已经是错误的数据了,错误的数据报就会丢弃掉,避免继续错下去
数据报当中的检验和并不是以数据的长度/数据的数量来作为检验的标准
检验和是一定要让数据的内容参与到检验标准中的,
而且检验和是拿着原数据中的一部分内容参与计算,如果这一部分数据和原数据刚好对得上,那么就是正确的数据,没有错误
如果这一部分数据和原数据对不上,那么就是错误的数据,就要丢弃掉
校验和是如何计算出来的?
在UDP中的检验和是如何进行检验的呢?
使用了一个简单的方式:
CRC算法来进行检验的,CRC算法是一种循环冗余校验
CRC算法是如何计算的:
如下代码所示:
我们要计算一个两个字节的校验和:
short checksum = 0;
for(遍历数据报中的每一个数据){
chectsum += 当前遍历的数据;
}
如上就是一个2字节的校验和的计算方式:
在这个过程中,由于是校验和只有两个字节的大小,所以在计算过程中,chectsum会发生数据溢出,但是没关系,溢出了也没有事
以上 就是校验和使用CRC算法计算出来的校验值
校验值的具体工作流程
1: UDP数据报的发送端在发送数据之前,会先根据CRC算法计算出一个校验和的具体的值,放在UDP数据报中,我们将这个校验值设置为c1
2: UDP数据报的接收方: 在接收到这个数据之后,会根据传输过来的数据使用同样的CRC算法计算出一个校验和,我们设这个校验和的值为c2
3: 然后让c1和c2这两个值进行比较,如果c1和c2的值相同,则传输的数据就是正确的数据
如果c1和c2的值不同,则传输的数据存在了比特翻转的问题,是错误的数据
在网络传输过程中,如果真的发生了比特翻转,一般也是很少的数据发生了比特翻转,
不会出现大规模的数据都出现了比特翻转,如果真的出现的概率也很低的
但是在这个过程中,如果发生比特翻转的数据真的太多了,就会恰好使得c1和c2的值都相同,校验和是对的,但是数据却发生了比特翻转…
出现了这一种情况出现,就需要我们使用更加精确地算法去计算校验值了,不能再使用CRC算法了
这一种更加精确的计算校验值的算法就是mb5算法:
md5算法:
md5算法是业界最高精度的计算校验值的算法,是通过一系列的公式计算出来的
计算的大概过程我们忽略不计,我们可以去研究一下这个md5算法的具体特性:
md5算法有三个特性:
- 定长
- 分散
- 不可逆
定长:
不管这个传输的原数据有多长,最终计算出来的md5的值都是一个确定的长度
这个md5值的确定长度一共有三种版本:
- 16位的版本,定长就是2字节
- 32位的版本,定长就是4字节
- 64位的版本,定长就是8字节
分散:
只要原数据变化一点点,计算出来的md5的值的差异就很大
在网络传输中,会发生比特翻转的数据都很少,但是在计算md5值的过程中,即使原数据只是发生了很少的比特翻转,最终计算出来的md5的值差异都很大,所以很容易就可以发现数据是否发生了比特翻转,大大提高了查询数据是否是错误数据的效率
由此,这个分散的特性也决定了md5算法也可以称为“字符串hash算法”
什么是hash算法?
将整数中的key转化为数组的下标的过程,就是hash算法
而字符串hash算法: 就是将字符串转化为md5值,之后将md5值这个整数转化为数组的下标
这个分散的特性决定了经过这个md5算法计算出来的哈希表,会很少发生哈希冲突
因为哈希冲突就是在多个key映射到了同一个数组下标,导致链表/树的长度很长,导致哈希表性能下降
而这个分散特性决定了md5算法是字符串hash算法,也决定了产生的哈希表的每一个链表的长度都不是很长
不可逆:
将原数据转换为md5值是比较简单的
但是不可以直接根据一个计算好的md5值去反推出原数据
md5算法是不可以直接反推的,因为计算量非常大。
下一篇博客我们将会去讲解传输层的TCP协议~



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









