







前言:
本项目非原创,我也只是作为一名初学者跟着成熟的up主一起敲代码而已。视频来源于:
 https://www.bilibili.com/video/BV1qV4y1d7zY
https://www.bilibili.com/video/BV1qV4y1d7zY在哔哩哔哩闲逛看到这个项目,感觉还不错,于是想要学习一下这个项目怎么写。项目日记也会同步更新。(本人不分享本项目源码,支持项目付费)
本项目大量采用了先前项目中已经写好的代码,而且UP主讲的也很快。因此不适合新手作为自己的第一个项目。
前段时间去赶学校的另外一个项目了,所以这个项目断更了一段时间,接下来的这段时间会主力把这个项目写完。
目录
 今日完结任务:
今日完结任务:
1.创建完文件的表结构:
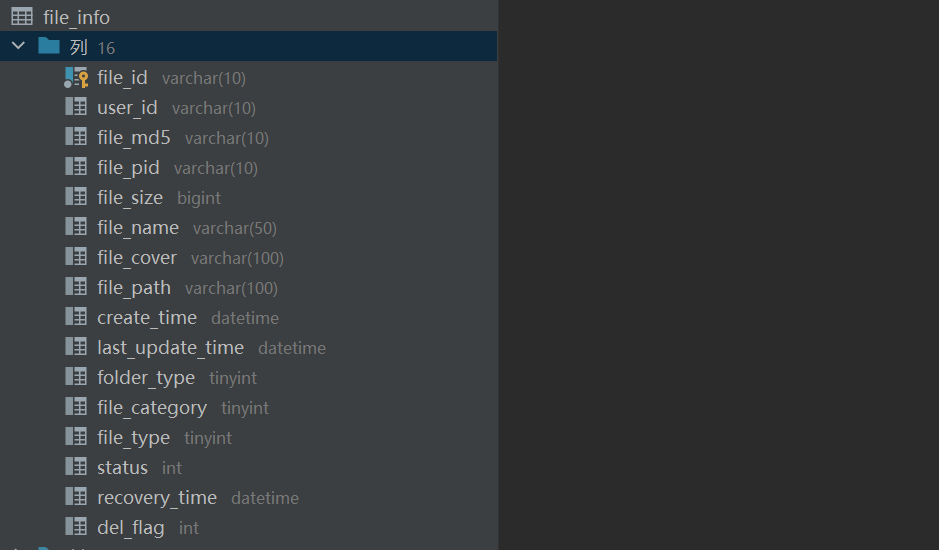
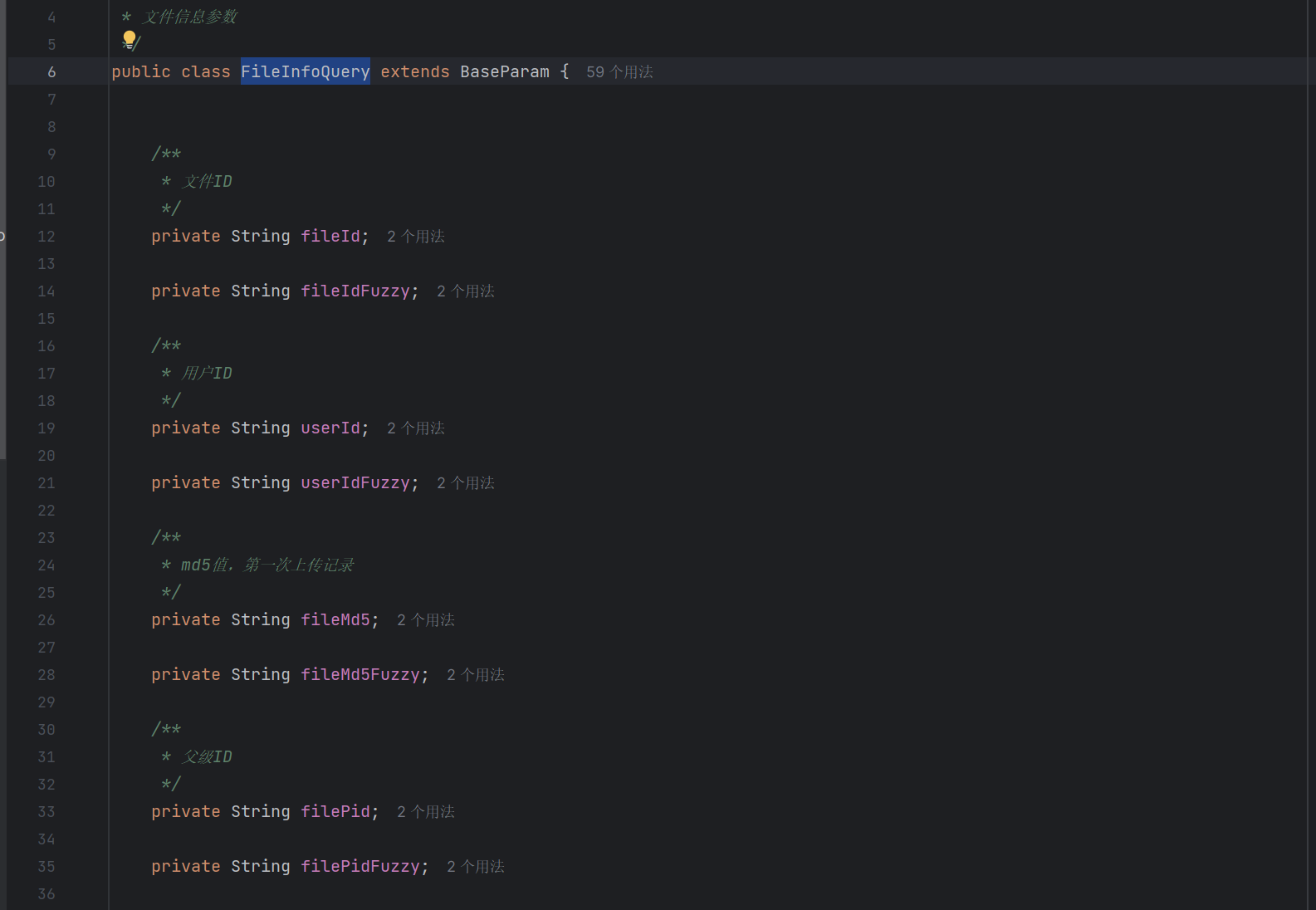
2.完成根据条件分页查询用户文件接口
这个接口比较烦,一句话概括查询条件为:需要查询指定分类的指定用户的指定类型文件。
所以我们先构建一个FileinfoQuery类来统一存储查询条件:
接下来我们看看这个controller层:
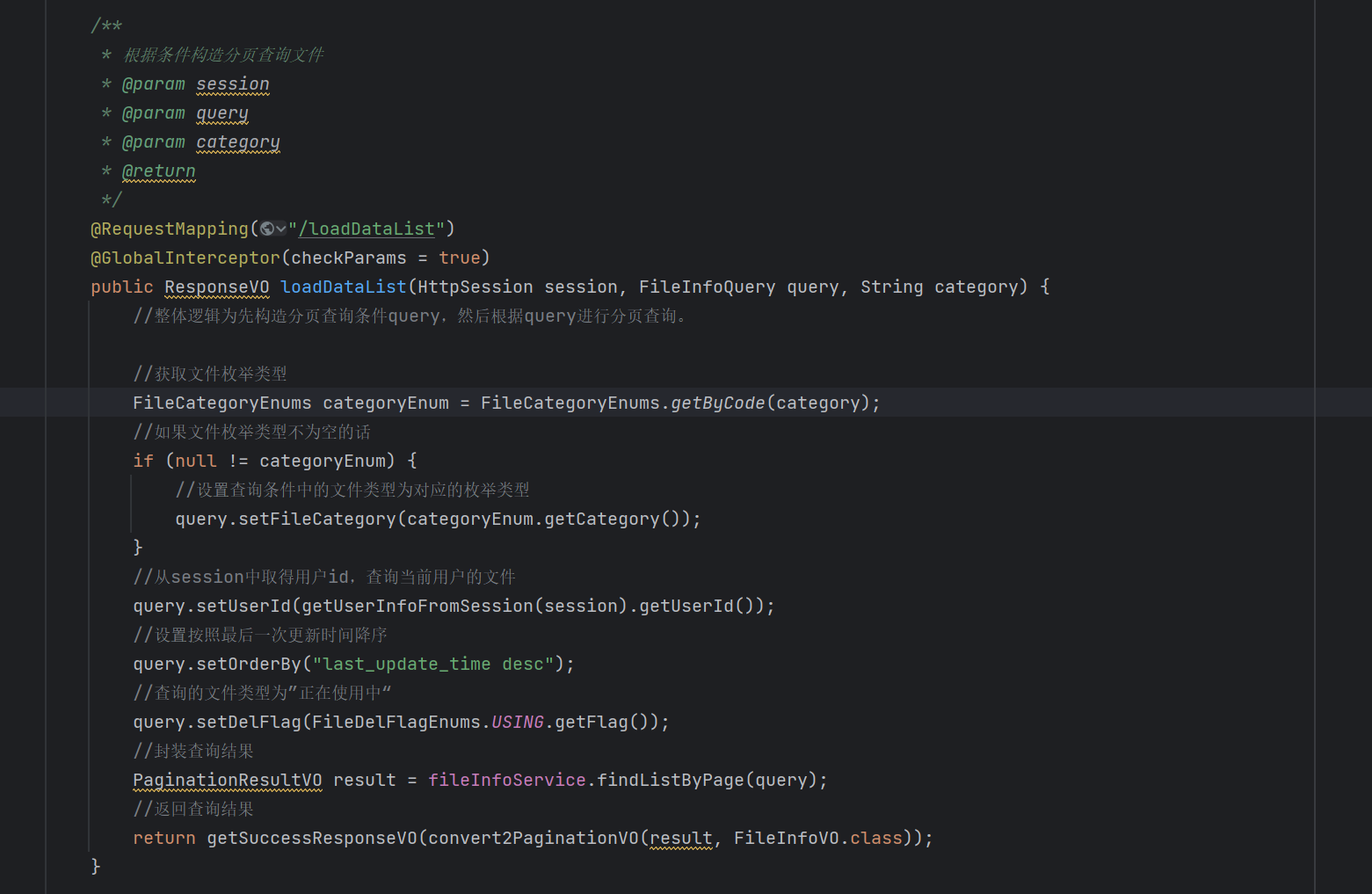
整个controller层的逻辑为:先构造好查询条件类,然后携带查询条件类进入sever层进行查询。
sever层: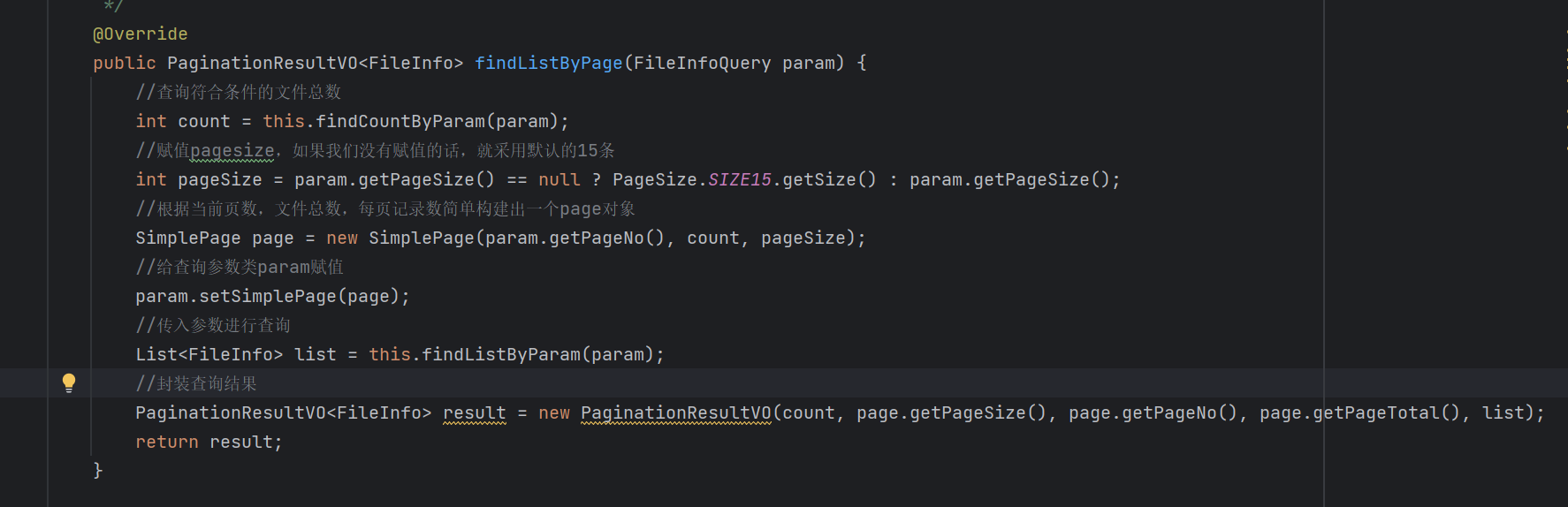
3.文件的分片上传
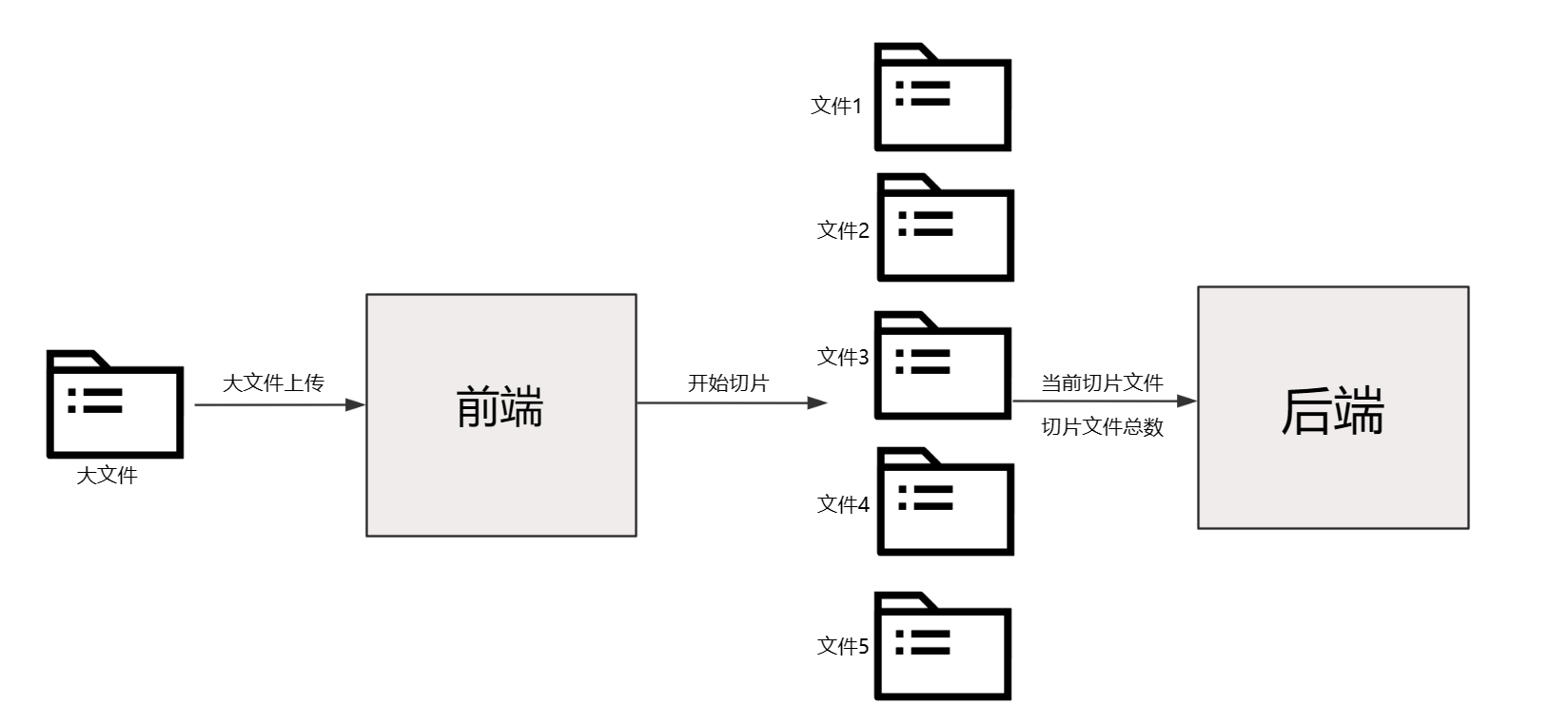
简单的讲一下文件分片上传的思路:当我们前端接收到一个大文件的时候,前端会把这个文件进行切分。告知后端一共切了几个分片以及当前上传的是哪一个分片。
大文件的分片是在前端做的,不是后端!
先看接口层:
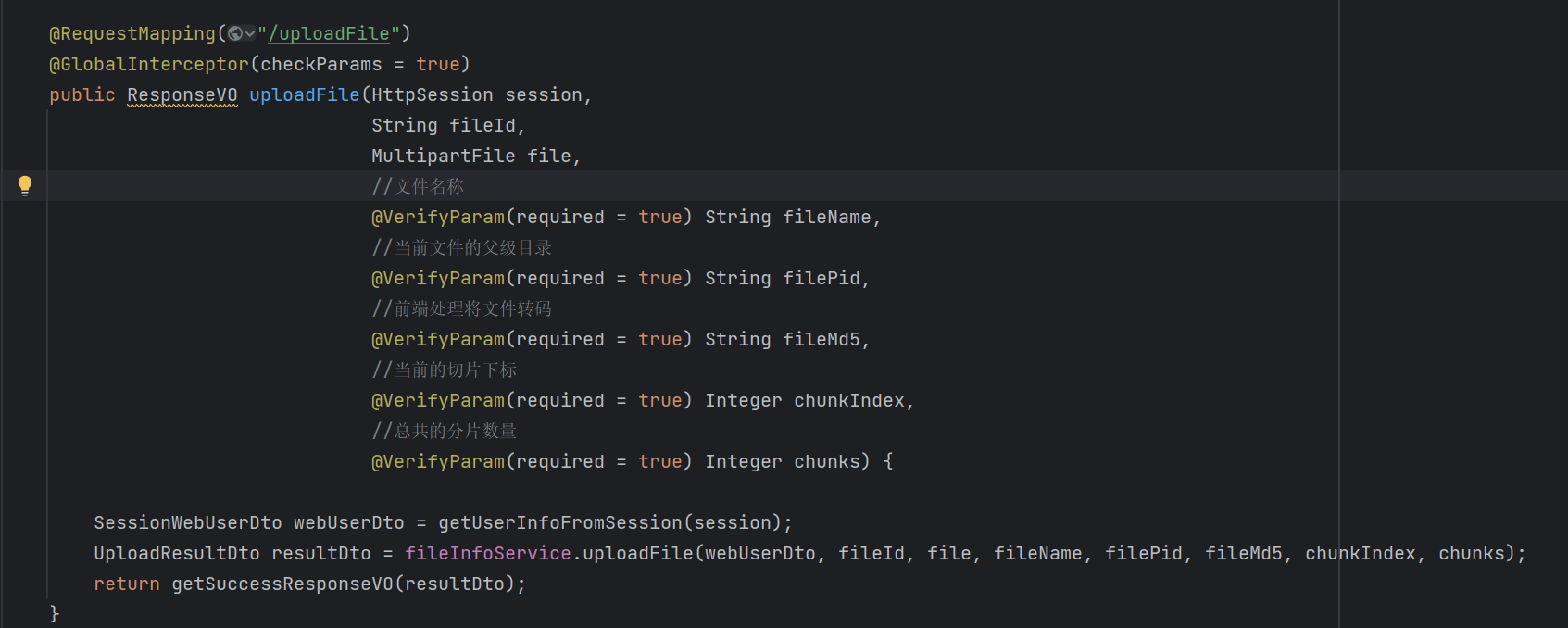
接下来让我们来进入服务层:
服务层的逻辑比较复杂,因此我们先来介绍一下整个服务层对分片上传的处理逻辑的逻辑:
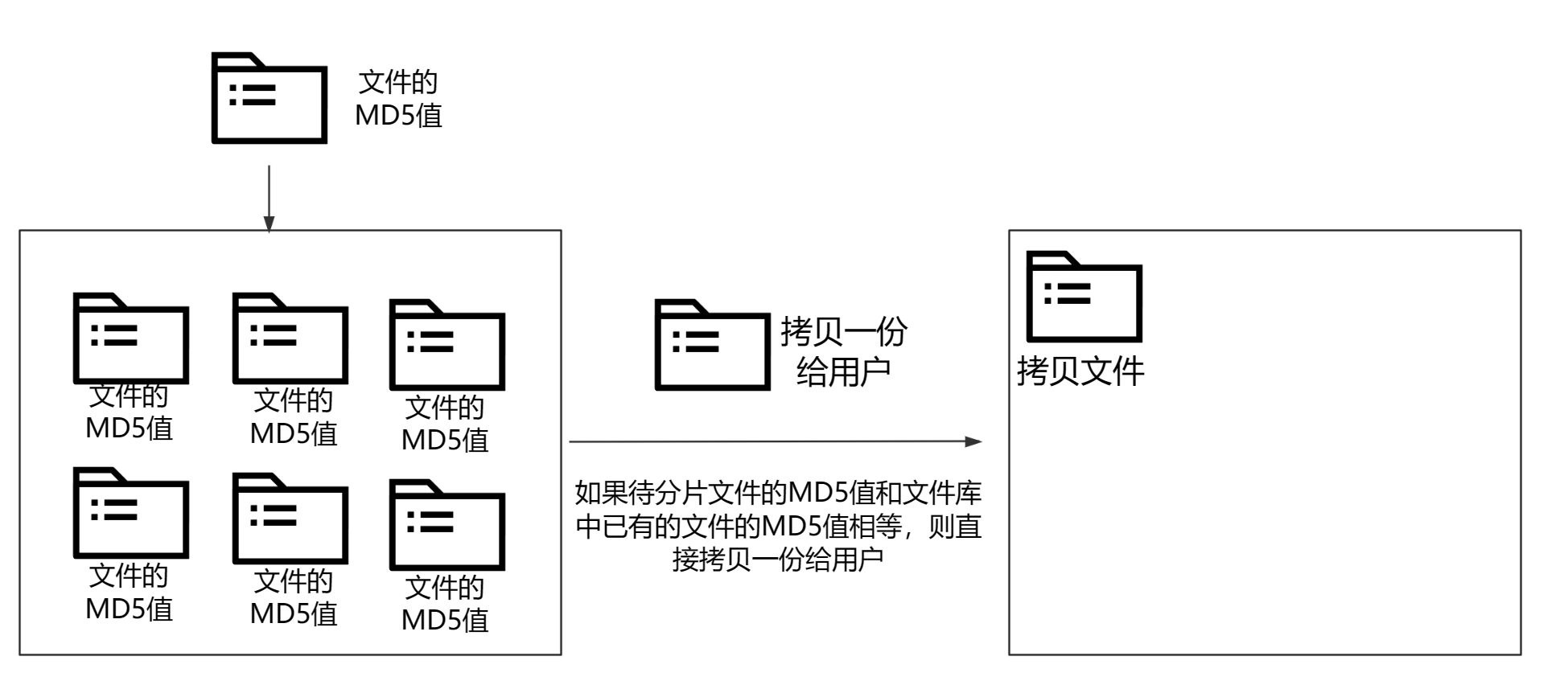
1.后端接收目标文件的MD5值,凭借MD5值在数据库中查找是否已经存在当前文件,如果存在的话,不需要接收分片上传,直接从数据库中拷贝一份即可(秒传)。核心逻辑为:
2.如果当前文件不存在的话,就开始接收分片文件。核心逻辑为:
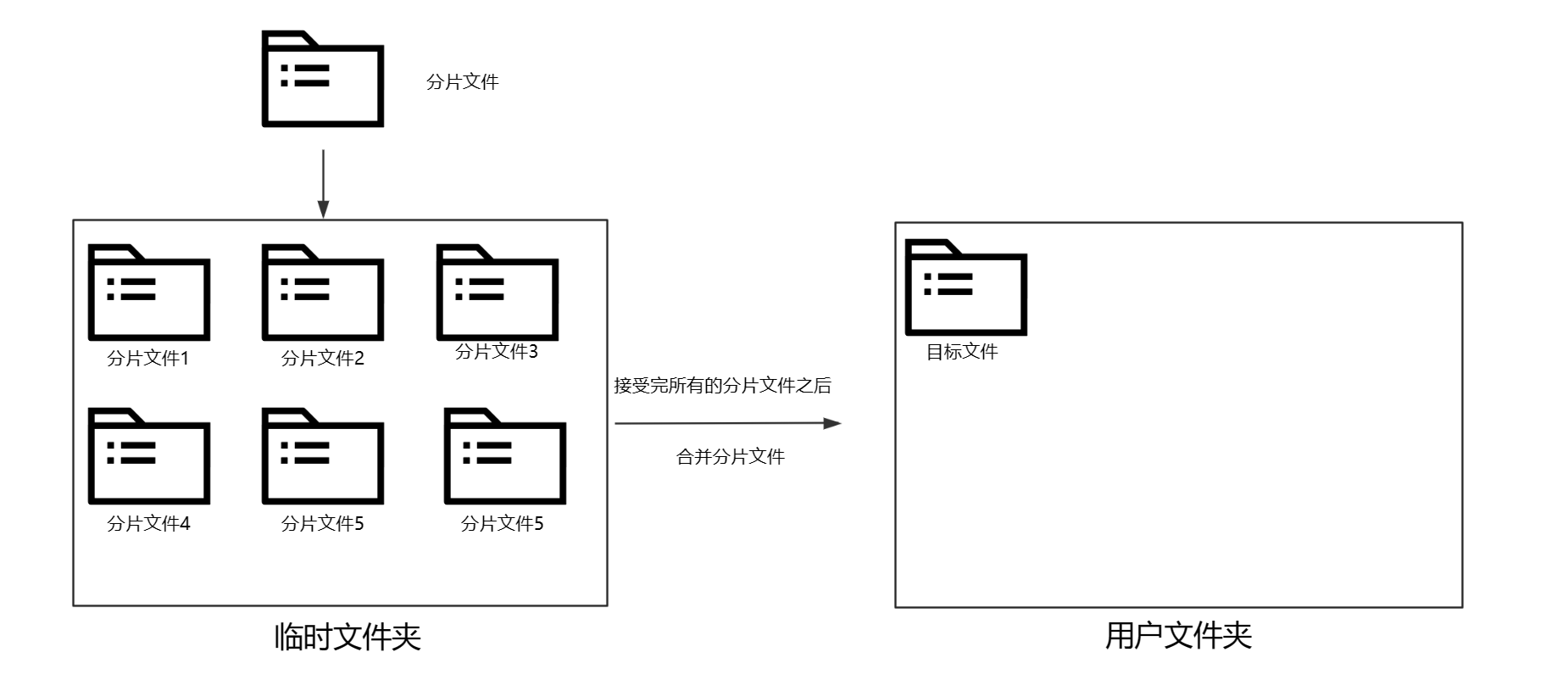
相信图片已经能很清晰的表明我们是如何接收分片文件的了。经过我们的概括,其实分片上传业务层可以分为两个大的板块:秒传业务和分片上传业务。
我们来看一看具体的代码:
1.秒传业务:
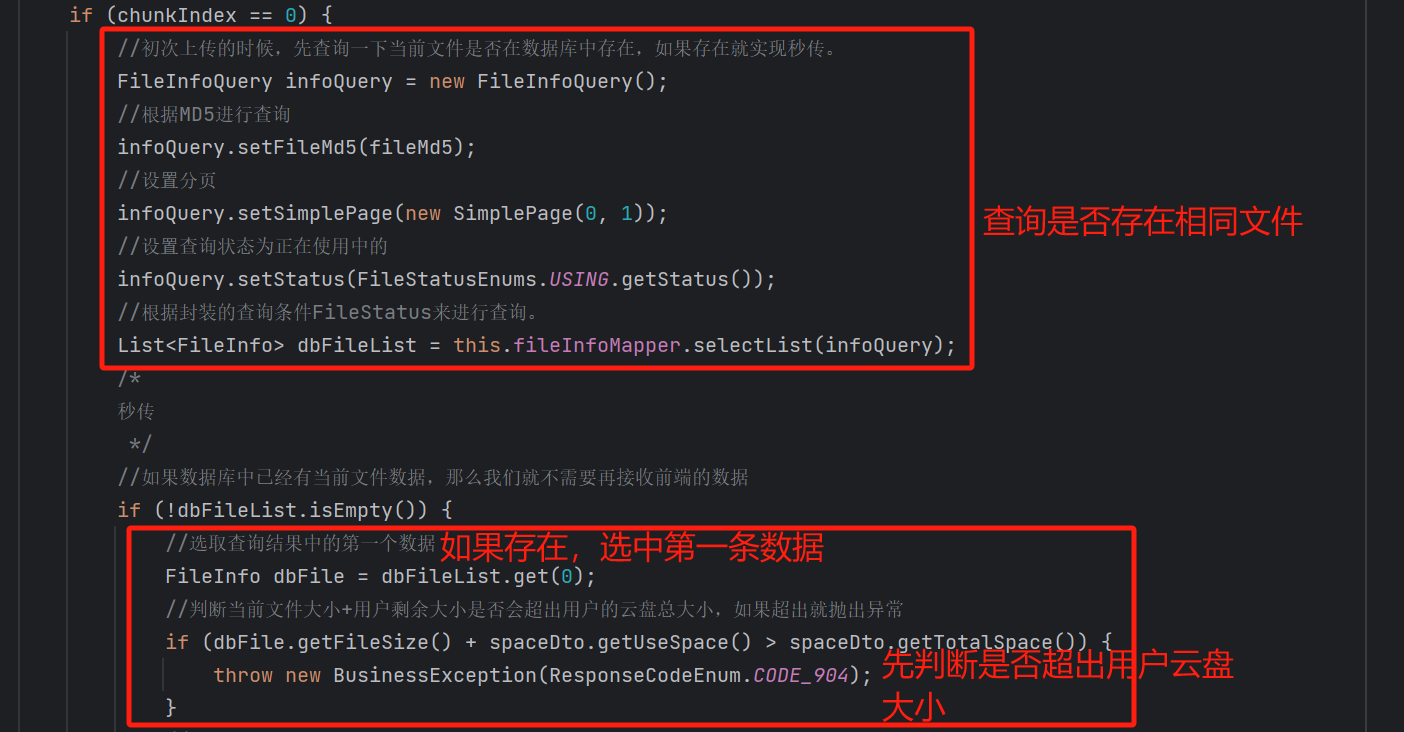
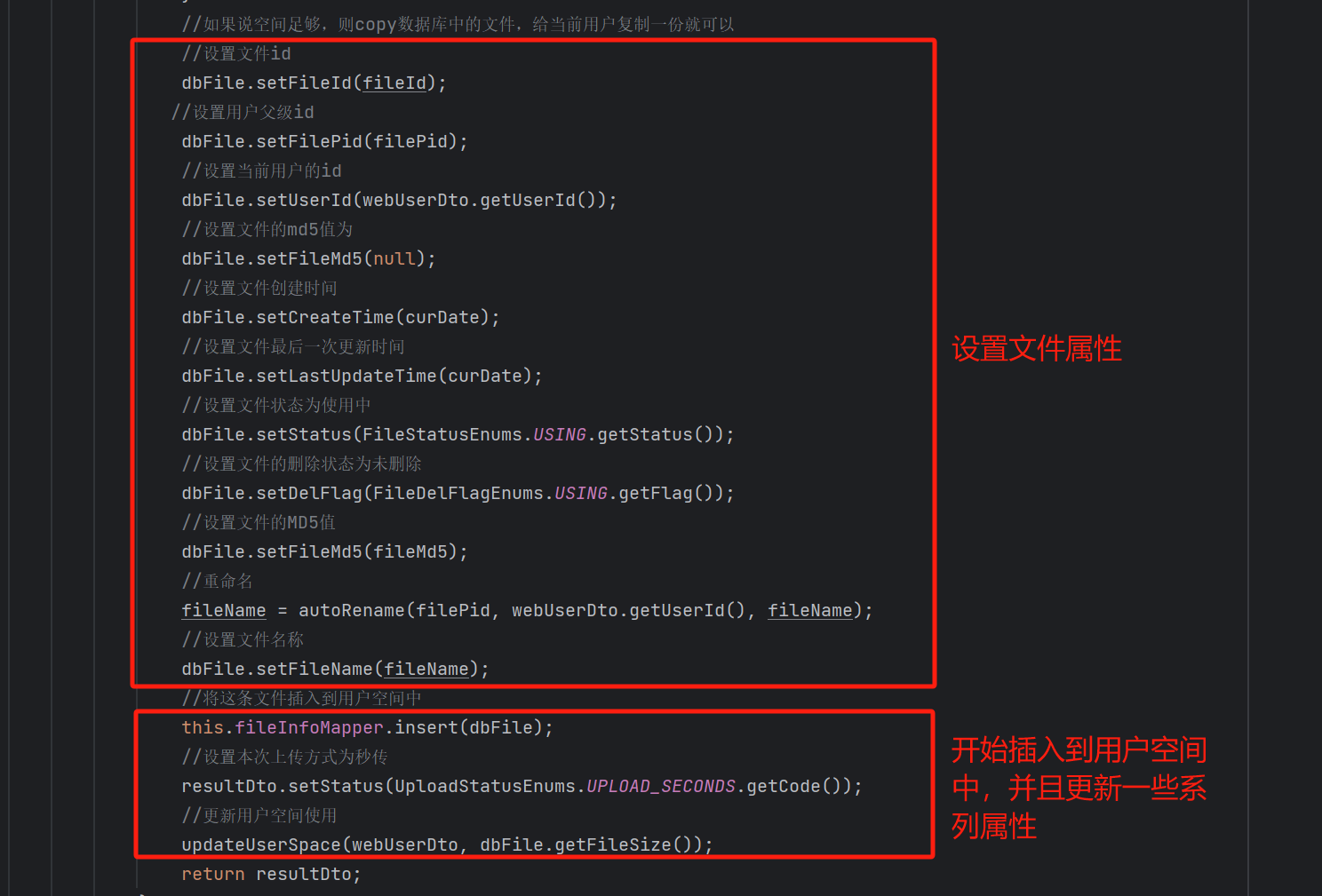
如果【拷贝数据大小 + 用户当前已使用的大小 用户云盘总空间】 则抛出异常,不允许拷贝数据。
如果满足条件的话,就开始拷贝数据:
2.分片上传业务
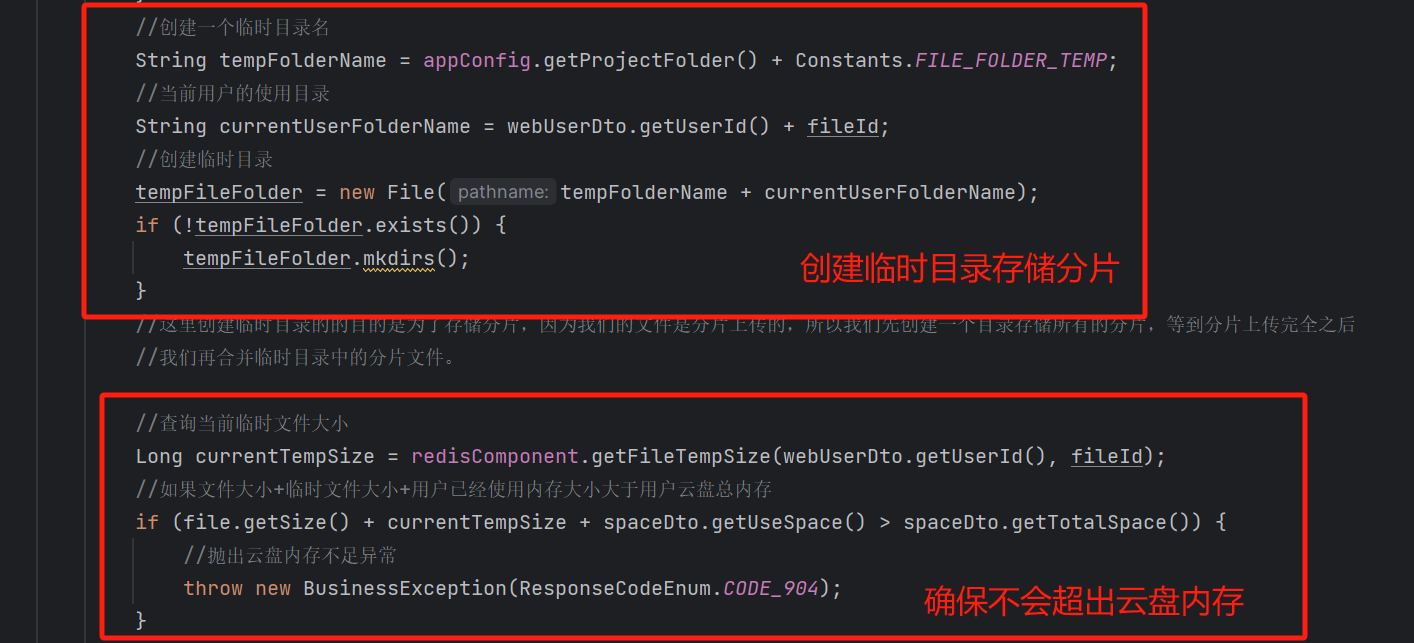
接下来开始保存分片文件

当我们接收到最后一个分片文件的时候,需要异步合并所有的分片文件。
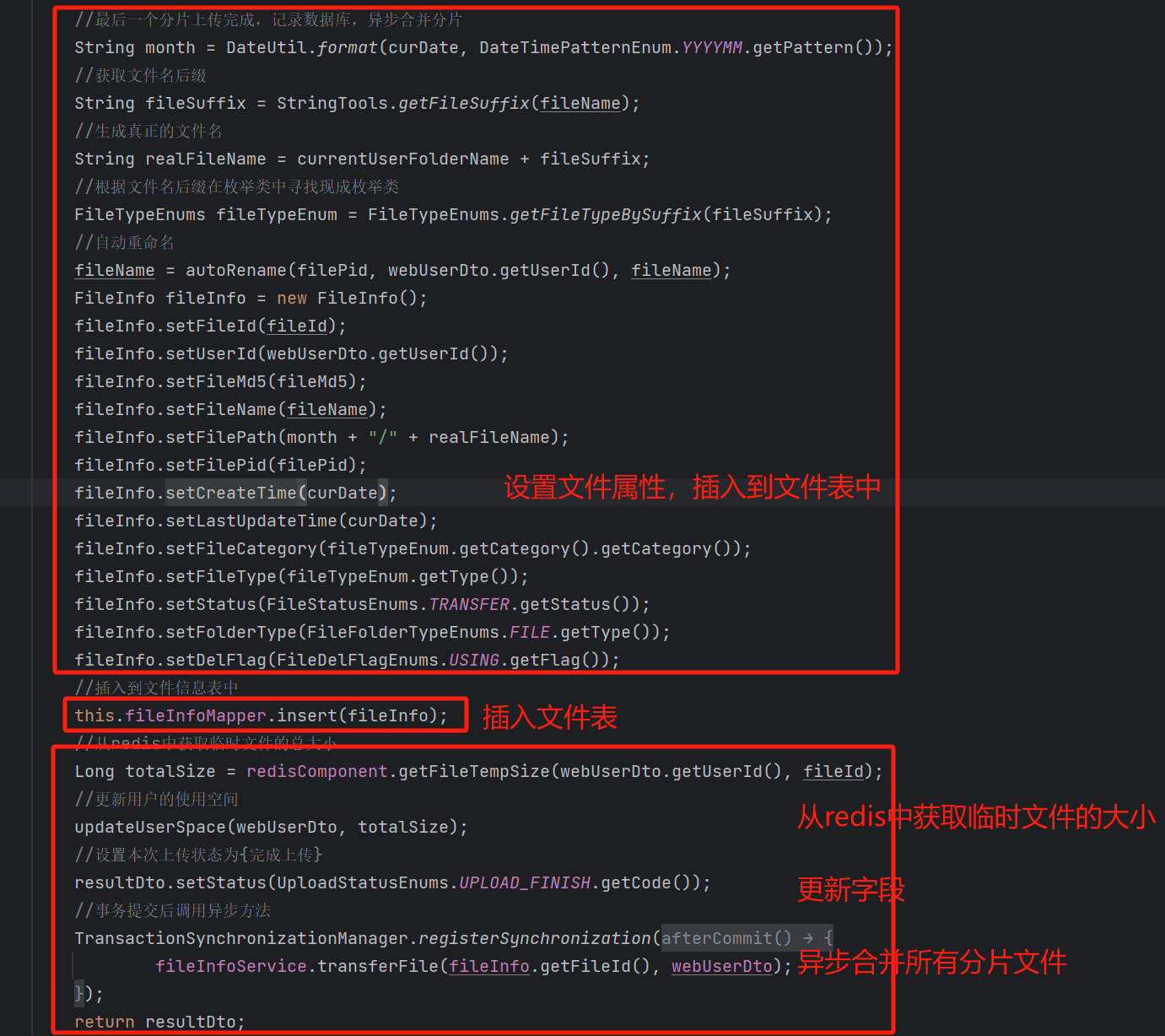
这里还有一个需要注意的地方,因为这个方法涉及到了修改大量的数据库字段,所以我们添加了给这个方法添加了事务。

而我们又使用了这个方法,注册了一个同步器,表示在当前事务提交之后,异步执行合并文件的方法(transferFile) ,但是如果我们直接使用这个transferFile方法的话,异步是不会生效的,因为他没有交给Spring 管理。
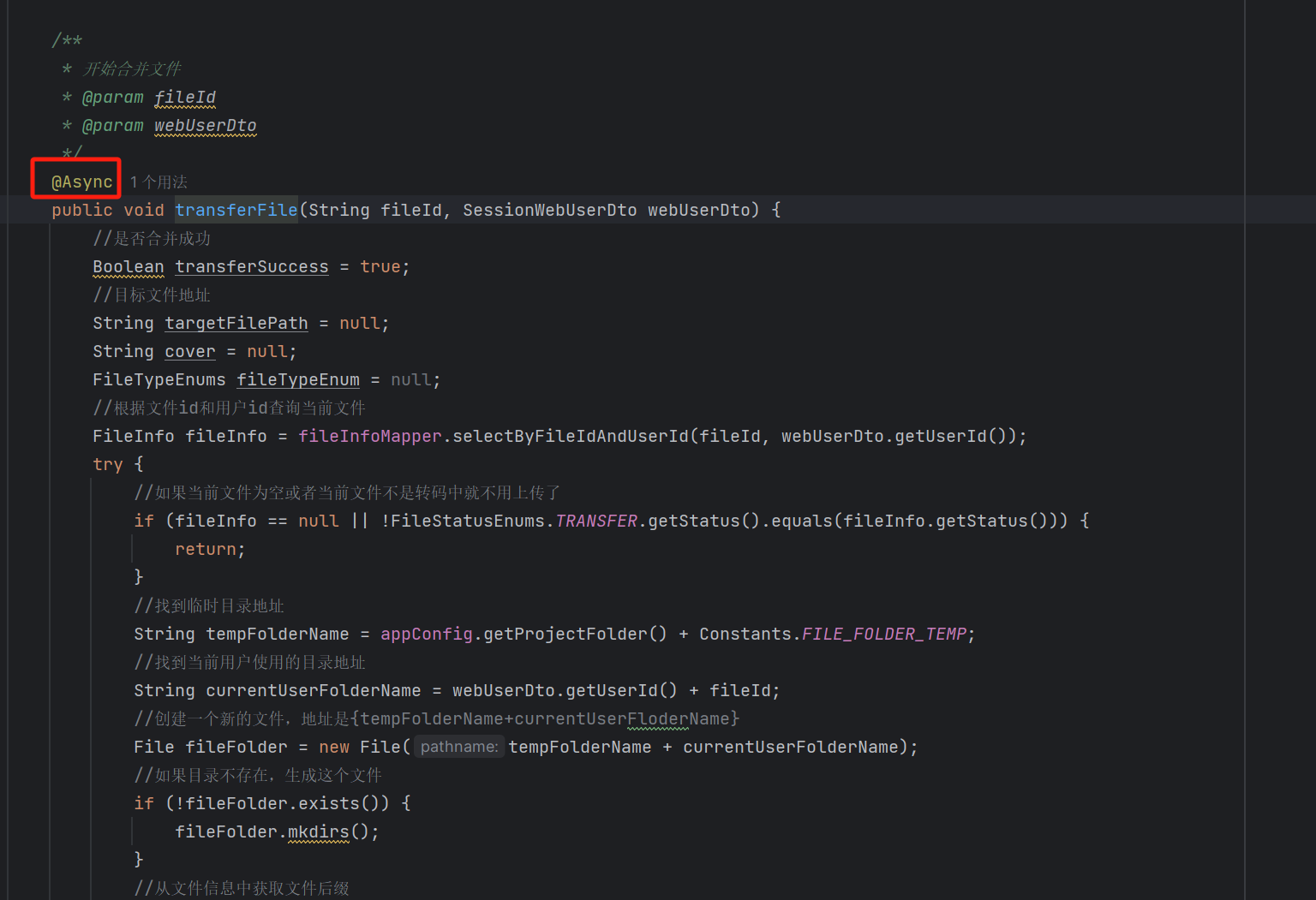
所以我们需要在FileInfoService中去依赖注入一个FileInfoService,将他交给Spring 容器进行管理。

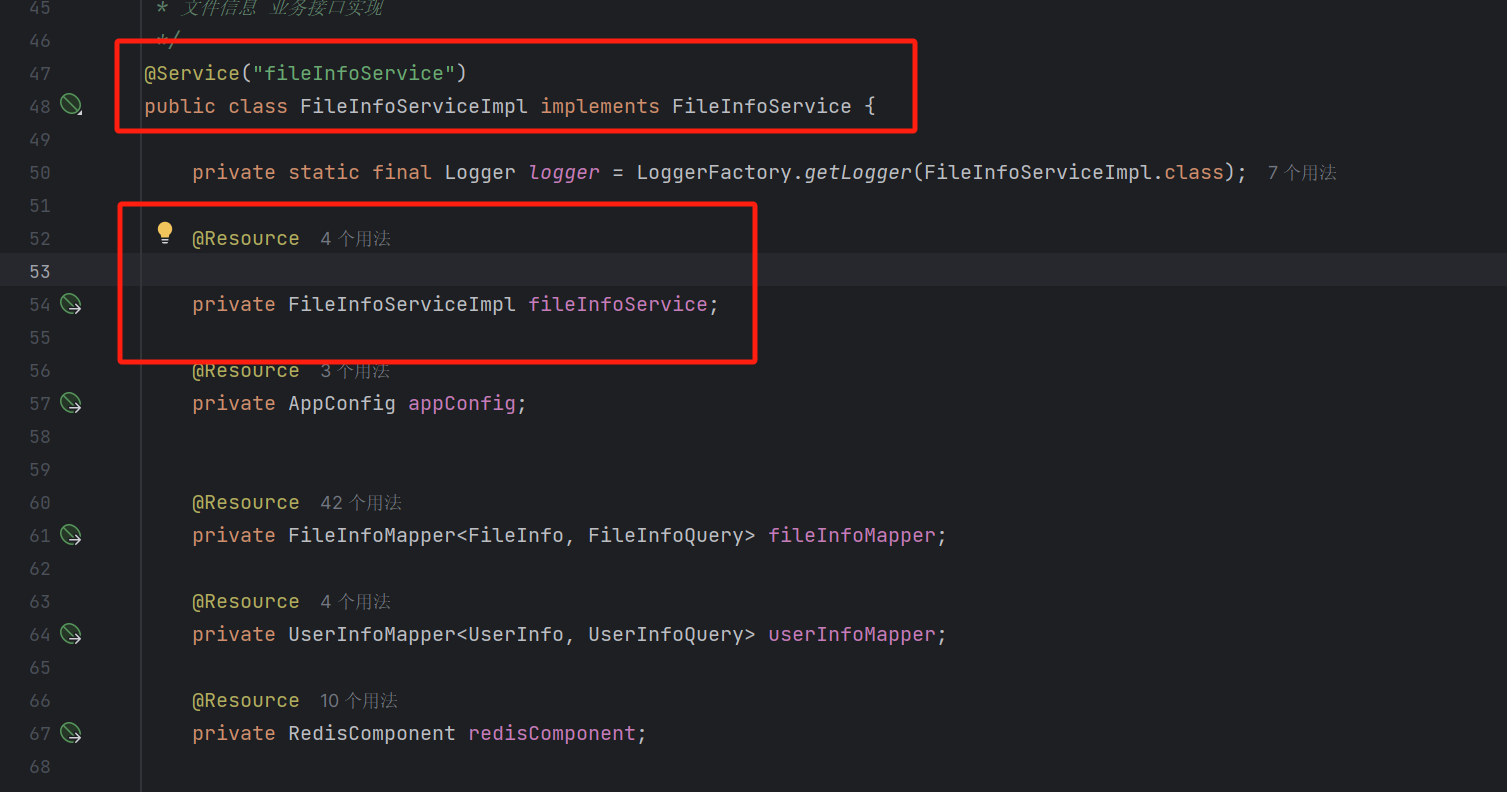
但如果只是这样简单写的话,就会造成循环依赖了:
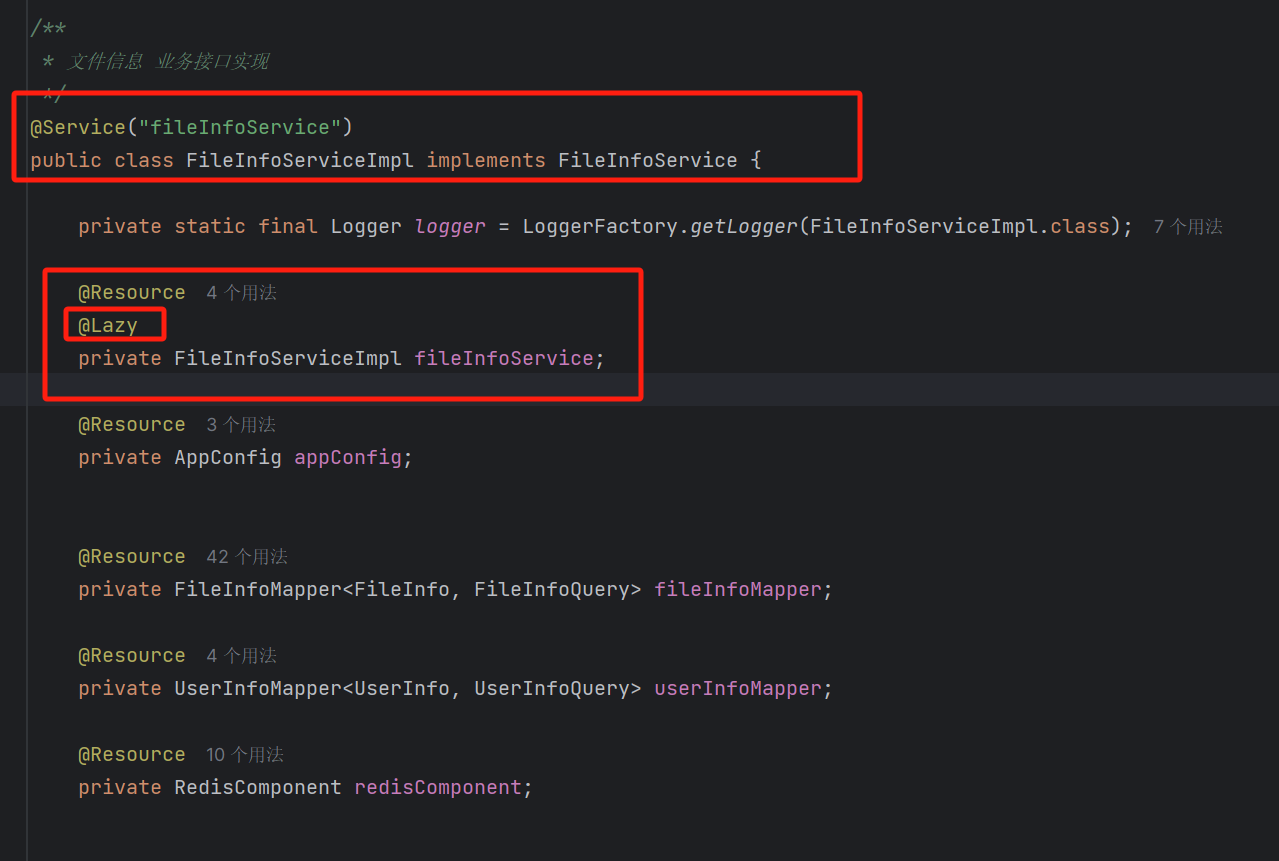
所以我们要给我们这个注解手动添加一个@Lazy注解,形成懒加载。
 那么这样的话,我们的分片上传业务就写完了。后面我会更新一下合并文件的transferFile方法
那么这样的话,我们的分片上传业务就写完了。后面我会更新一下合并文件的transferFile方法
小知识点:
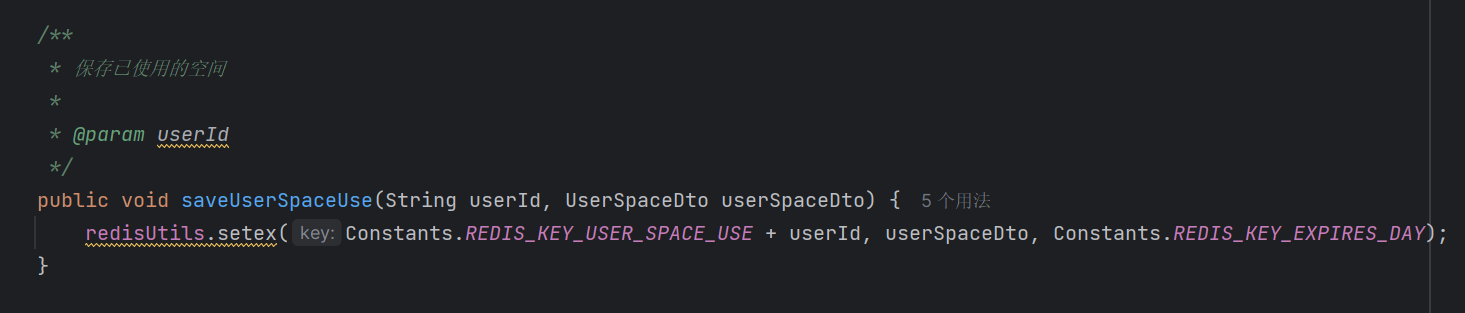
1.因为文件的分片会很多,所以我们是把文件的大小,用户空间大小,用户已使用的空间大小放到Redis中去存储的。这样可以避免频繁的查询数据库字段。
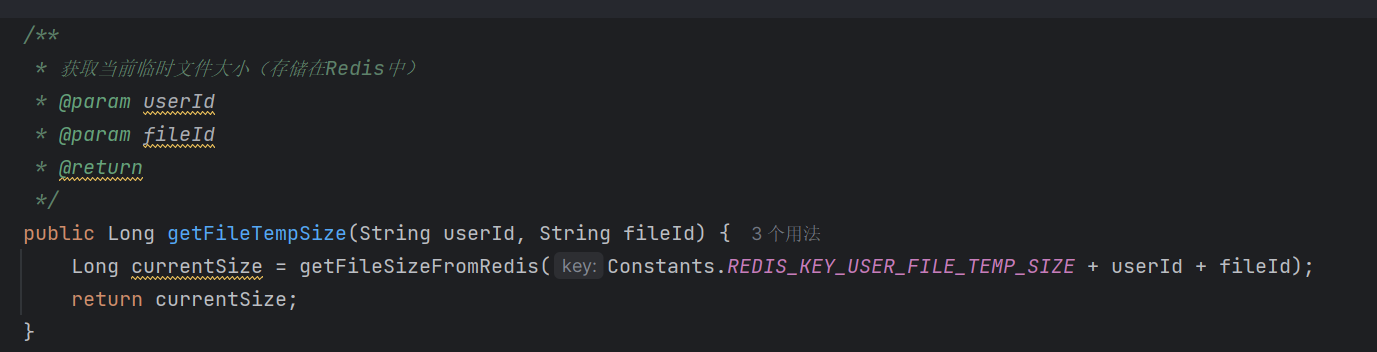
2.Nginx和Spring boot自身就对上传和接收的文件大小限制有限制,因此如果我们的分片文件大小大于Nginx和Spring boot的本身限制,我们就要修改这两个的接收文件大小限制或者修改分片大小,否则就会报错
Nginx:
在service下添加参数:client_max_body_sizeSpring boot:
spring.http.multipart.maxFileSize=xxMb
spring.http.multipart.maxRequestSize=xxMb总结:
这篇文章是分两天写完的,分片上传的业务逻辑很复杂,调用的方法也很多,写的我心力憔悴。不过确实学习到了很多的东西。因此我一定要把这块逻辑搞清搞懂。
如果我的内容对你有帮助,请点赞,评论,收藏。创作不易,大家的支持就是我坚持下去的动力!



















 7193
7193

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











