







首先,放出基础源代码(未修改的存在bug版本)
代码片1:
transform = trans.Compose(
[
trans.ToTensor(),
trans.Normalize((0.5,0.5,0.5),(0.5,0.5,0.5))
]#将0-1的范围转化成-1,1
)
trainset = torchvision.datasets.CIFAR10(download=False,root='./data',train=True,transform = transform)
#包装
trainloader = torch.utils.data.DataLoader(trainset,batch_size=4,shuffle=True,num_workers=2)
testset = torchvision.datasets.CIFAR10(download=False,root='./data',train=False,transform = transform)
testloader = torch.utils.data.DataLoader(testset,batch_size=4,shuffle=False,num_workers=2)代码片2:
import matplotlib.pyplot as plt
import numpy as np
def imshow(img):
img = img/2+0.5
npimg = img.numpy()
plt.imshow(np.transpose(npimg,(1,2,0)))
plt.show()
dataiter = iter(trainloader)
#images,labels = dataiter.next()
imshow(torchvision.utils.make_grid(images))
print(''.join('%5s'%classes[labels[i]] for i in range(4) ))1.首先,如果直接跑这两个代码片的话,会出现第一个问题:
出现如下报错(方便搜索者搜索笔者在这里不用截图而直接复制错误)
'_SingleProcessDataLoaderIter' object has no attribute 'next'
这个问题其实是不同的pytorch版本所支持的语法不同,笔者自身的pytorch版本为2.0.1,所以其支持的语法为
images, labels = next(dataiter),此问题即可解决
2.其次,在解决完这个问题后,再次跑程序不会出现语法错误,而是在jupyter nootbook中出现此类情况:
【内核挂掉了,正在重启】
导致这个问题的其实是有两种情况的
(1)对于第一个代码片,在Windows系统中,由于其线程问题,我们要将trainloader和testloader中的num_workers设置为0
(2)对于第二的代码片,添加
import os
os.environ["KMP_DUPLICATE_LIB_OK"]="TRUE"笔者猜测应该是通过os包内函数来对系统环境进行约束,但是具体的函数作用在查找资料后仍未得到良好解释,如果有大佬指导欢迎评论留言
更改之后代码片如下(我连起来写了):
transform = trans.Compose(
[
trans.ToTensor(),
trans.Normalize((0.5,0.5,0.5),(0.5,0.5,0.5))
]#将0-1的范围转化成-1,1
)
trainset = torchvision.datasets.CIFAR10(download=False,root='./data',train=True,transform = transform)
#包装
trainloader = torch.utils.data.DataLoader(trainset,batch_size=4,shuffle=True,num_workers=0)
testset = torchvision.datasets.CIFAR10(download=False,root='./data',train=False,transform = transform)
testloader = torch.utils.data.DataLoader(testset,batch_size=4,shuffle=False,num_workers=0)
#分隔符
import matplotlib.pyplot as plt
import numpy as np
import os
os.environ["KMP_DUPLICATE_LIB_OK"]="TRUE"
def imshow(img):
img = img/2+0.5
npimg = img.numpy()
plt.imshow(np.transpose(npimg,(1,2,0)))
plt.show()
dataiter = iter(trainloader)
#images,labels = dataiter.next()
images, labels = next(dataiter)
imshow(torchvision.utils.make_grid(images))
print(''.join('%5s'%classes[labels[i]] for i in range(4) ))调整后执行情况如下:
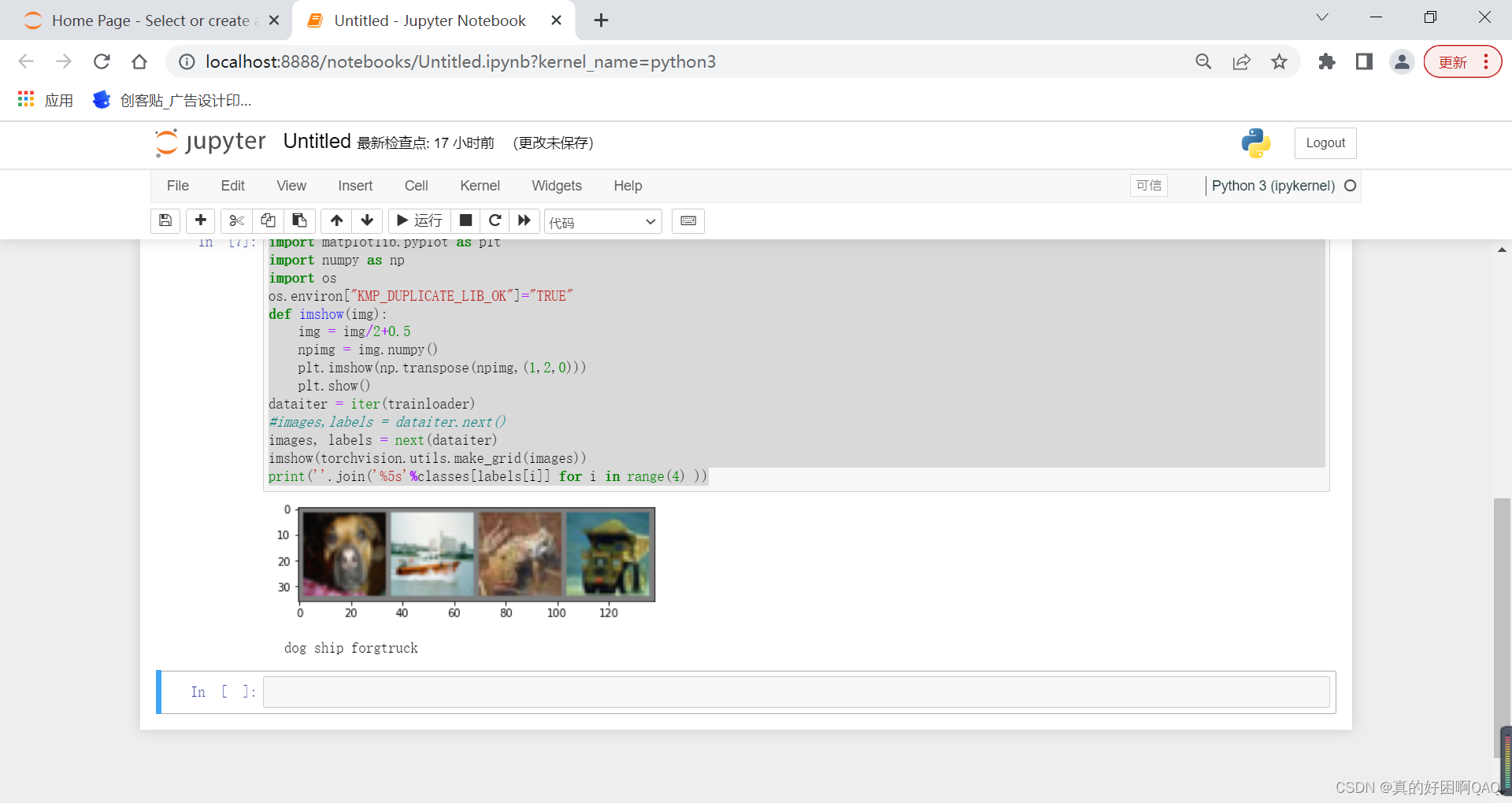














 3058
3058











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









