






代码:
import urllib.request
# (1) 定义一个url 想要访问的地址
url = 'https://www.baidu.com'
# (2) 把UA那行粘贴过来并变成字典(前后变字符串)
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Safari/537.36 Edg/115.0.0.0"
}
# (3) 请求对象的定制 字典类型变为Request类型,因参数顺序问题所以这里必须使用关键字传参
'''
urlopen源码解释:
Open the URL url, which can be either a string or !!!a Request object.!!!
'''
# print(type(request)) <class 'urllib.request.Request'>
request = urllib.request.Request(url=url, headers=headers)
# (4) 模拟浏览器向服务器发送请求 记得连网!
response = urllib.request.urlopen(request)
# (5) 获取响应中的页面的源码
content = response.read().decode('utf-8')
# (6) 打印数据
print(content)
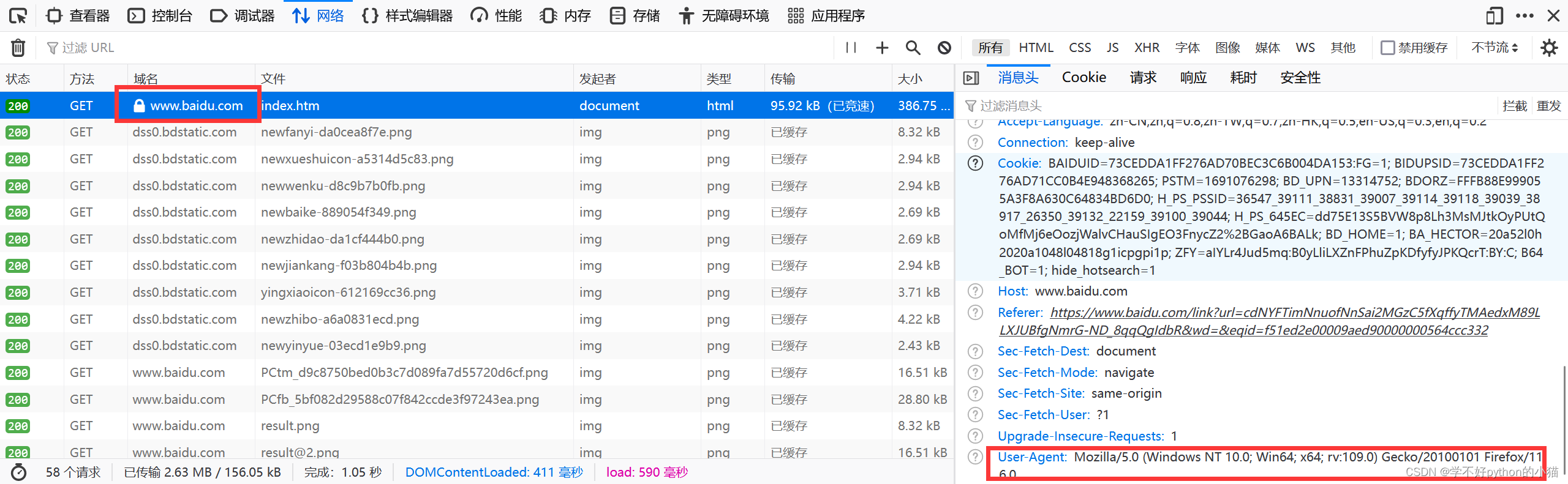
百度一下UA获取如下图:
(1)百度一下右键检查

(2)点击网络然后刷新

(3)找到www.baidu.com点击,右边页面拖至最下面,找到User-Agent行并复制
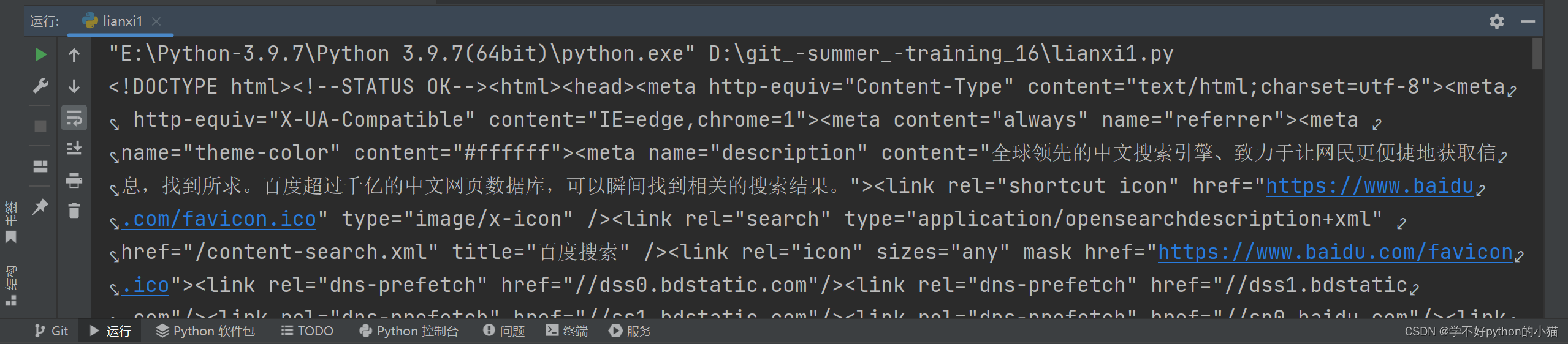
成功爬取截图:



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











