







Introduction(介绍)
文件IO作为Linux基础的基础,是非常重要的知识,因此学好文件IO是很重要的。
由于Unix和Linux的相似性,对Unix的讲解对于Linux也是适用的。
大多数的文件I/O在unix系统上仅仅使用了five functions:open(打开文件),read(写入数据),write(读出数据),lseek(定位到文件的特定位置进行文件操作),close(关闭文件)。
本章的IO经常被称为unbuffered I/O,这是相对于Chapter-5的标准IO(基于缓冲区的)。术语unbuffered意味着read和write操作在kernel执行了系统调用。这些unbuffered IO不是ISO C的一部分,也不是POSIX的一部分,而是UNIX特有的。
只要涉及到多进程的资源共享,atomic operation(原子操作)就是很重要的一个概念。会在file IO部分和openfunction涉及到这些知识。
FIle Descriptor
对于内核,所有打开的文件都拥有文件描述符,这是一种非负整数。open和creat可以返回文件描述符,然后将其作为read和write的参数。
Unix系统相应的将0与standard input相联,1与standard ouput相联,2与standard error相联。
在POSIX相关的应用里通常用常量STDIN_FILENO,STDOUT_FILENO,STDERR_FILENO替代magic number(幻数),这些常量定义在头文件<unistd.h>
文件描述符的范围是0~OPEN_MAX,Linux 2.4.22中对于每个进程使用的上限是1,048,576.
Functions
open
链接:http://blog.csdn.net/feather_wch/article/details/50636794
close
打开的文件使用close进行关闭操作。
#include <unistd.h>
int close(int fd);Returns: 0 if OK
-1 on error
关闭一个文件会释放进程在文件上的任何记录锁(record locks)。
进程终止的时候也会自动关闭其打开的所有文件。
lseek
链接:http://blog.csdn.net/feather_wch
read
链接:http://blog.csdn.net/feather_wch
write
读取数据需要writefunction。
#include <unistd.h>
ssize_t write(int fd, const void *buf, size_t count);Return:
number of bytes written if OK
-1 on error
返回值总是等于需求的字节数 count,因为不等则会产生error。通常造成错误的原因是装填满了disk或者超过了文件尺寸的限制。
write操作起始在文件“current offset”,当打开文件使用了flagO_APPEND则会偏移到SEEK_END进行写入。操作成功后,file’s offset增加写入的数目。
I/O Efficiency
我们在回顾第一章节的使用read和write的例子。
#include <stdio.h>
#include <unistd.h>
#define BUFFSIZE 4096
int main(void)
{
int n;
char buf[BUFFSIZE];
while((n = read(STDIN_FILENO, buf, BUFFSIZE))>0)
{
if(write(STDOUT_FILENO, buf, n) != n)
{
fprintf(stderr, "write error");
}
}
if(n < 0)
{
fprintf(stderr, "read error");
}
return 0;
}该实例并没有关闭文件,是因为process结束的时候,kernel会自动关闭文件。这里我们提出一个问题,就是BUFFSIZE的大小是如何决定的?
经过测试系统时间最小的时候是BUFFSIZE为4096的时候,在linux ext2文件系统中。大部分文件系统支持read-head能力,就是当系统预测到连续的数据要被读入的时候,比应用程序需求的多读入一些数据,来假设应用程序很快就会需要这些数据。
File Sharing
UNIX系统支持在不同进程中共享打开的文件。
The Kernel使用了三种数据结构来表示一个打开的文件,这些数据结构之间的关系决定了与其他进程文件共享的进程收到的影响。
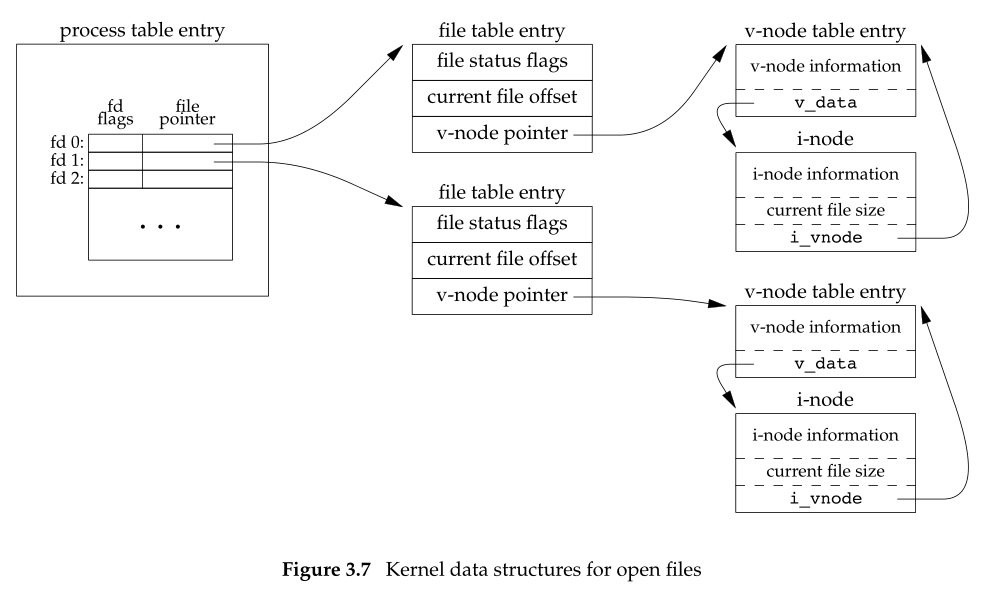
如上图,三种数据结构分别为:
(1)the process table
每个进程在process table里具有an Entry。每个Entry包含两部分:
1. (a).file descriptor
2. (b).指向file table entry的指针
(2)a file table
Each file table entry contains
1. (a).file status flags, 包含了例如,read,write,append,sync,and nonblocking
2. (b).current file offset
3. (c).V-node pointer
(3)v-node table
包含了v-node information如:文件类型和操作文件的函数的指针
另外包含了i-node 信息,inode信息包含了:文件的所有者,文件的尺寸,文件的data blocks来自于disk的哪里。
v-node的数据会在文件被打开的时候从disk读入。
在Linux中没有v-node,只有generic i-node,其是unix中v-node和i-node的综合。
如果两个独立进程打开了同一文件,会如下图所示:
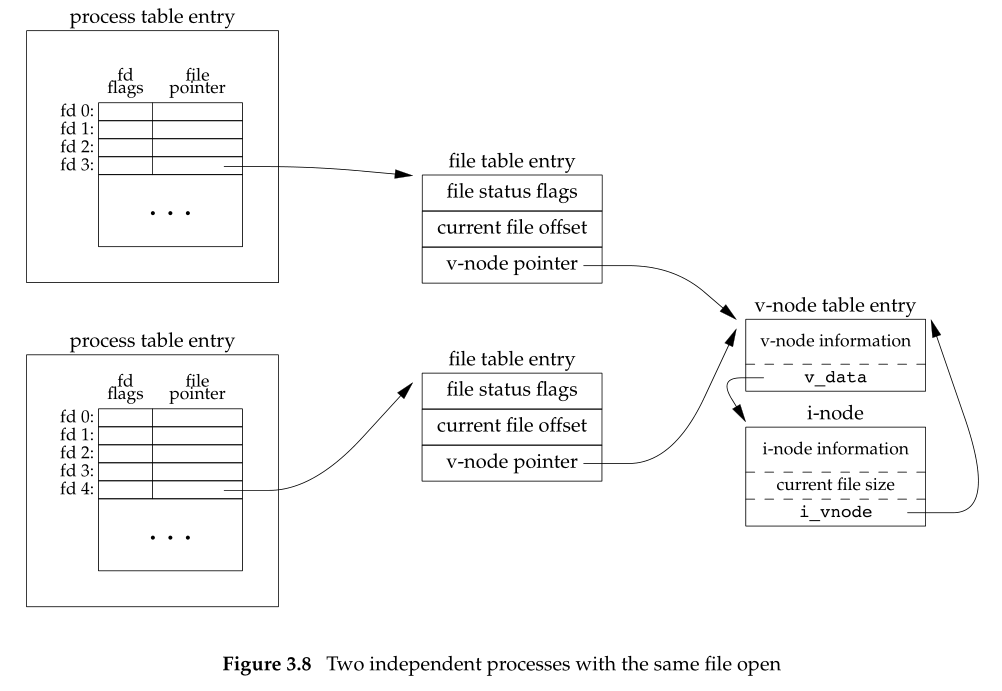
如图可知,两者使用了各自的process table entry和file table,最终使用了同一个v-node table entry。而file table entry的不同仅仅只有current file offset不同。
我们需要知道的是,是有可能多个file descriptor entry指向同一个file table entry,在我们下文讨论函数dup的时候会看到。这也可能发生在我们使用fork(创建多进程)的时候,parent和child对于每个file descriptor分享同一个file table entry。
在后面关于fcntlfunction,我们会知道如何获取和修改file descriptor flagsandfile status flags
Summary
多个进程向同一个文件写入数据的时候,会产生无法预测的结果。如何避免“惊喜”,就需要我们理解atomic operations的概念。
Atomic Operations
原子操作:要么一点也不执行,要么所有操作全部执行完成且不会被打断。
Appeding to A File(向文件追加内容)
我们通过例子来解释非原子操作可能会产生的问题。进程(process) A和进程B同时操作文件。A的作用是在文件末尾新增加内容,B的作用也是如此。首先A将A的file table entry(文件表表项,参考图3.8)中的当前文件偏移设置为1500byte(文件尾)。这时候B进程开始执行,B进程跳转到文件尾1500byte(字节)处,写入了100字节的数据。这时候回到进程A,进程A开始在1500byte偏移处写入数据。这时候你会发现进程B在文件尾写入的数据就会被A给覆盖了。出现这种冲突是因为我们使用了定位到文件尾和写入数据两个分开的系统调用。要知道所有超过1个函数调用的操作都不可能是atomic operation(原子操作)。Unix操作系统解决该问题的方法就是在open函数的时候加上选项O_APPEND,如此一来在每次write操作的时候都是在当前文件尾进行的操作。我们也不需要在write之前调用lseek了。
pread and pwrite
Unix扩展中允许程序原子地(无法打断过程)定位到指定位置并执行IO操作。这些扩展的函数就是pread和pwrite
函数原型如下:
#include <unistd.h>
ssize_t pread(int fd, void *buf, size_t count, off_t offset);
//Returns: number of bytes read,0 if end of file, -1 on error
ssize_t pwrite(int fd, const void *buf, size_t count, off_t offset);
//Returns: number of bytes write, if OK, -1 on error调用pread等于在lseek后调用read,但是有两点特殊的地方:
1. 在pread内部的两个操作之间绝对不会被打断
2. 文件指针不会更新(The file pointer is not updated)
调用pwrite等于在lseek后调用write,特殊之处与pread相同。
Creating a File
当使用open操作的时候,使用了O_CREAT和O_EXCL如果文件存在则出错,如果不存在则创建新文件。该先进行文件是否存在的判断,然后创建文件的操作也是原子操作,因为如果在判断文件不存在后,其他进程创建了文件并且写入了数据,此时回到原进程执行了创建操作就会清除原有的数据。这种情况是不允许发生的。
dup and dup2 Functions
在你需要复制文件描述符的时候,可以使用这两个函数。具体内容介绍请进入下面的链接。
链接:http://blog.csdn.net/feather_wch/article/details/50647093
sync,fsync, and fdatasync Functions
为了确保disk上的文件系统和buffer cache内容的一致性。系统提供了sync,fsync,fdatasync这些函数。
链接如下:http://blog.csdn.net/feather_wch/article/details/50647096
fcntl Function
fcntl用于改变已经打开的文件属性
链接:http://blog.csdn.net/feather_wch/article/details/50646906
/dev/fd
系统提供了目录/dev/fd,打开文件/dev/fd/n等同于复制描述符n, 意味着文件n已经被打开。
函数调用
fd = open("/dev/fd/0", mode);大部分系统会忽视参数mode,一些系统会将其作为打开的文件mode的子集。这也等效于
fd = dup(0);描述符0和fd共享file table entry(see Figure 3.8). 例如fd = open("/dev/fd/0", O_RDWR);虽然使用了O_RDWR但是这并不能改变文件只读的属性。
一些系统提供了路径名/dev/stdin ,/dev/stdout ,/dev/stderr,这和/dev/fd/0 or 1 or 2是等效的。
/dev/fd主要用途是在shell中,例如filter file2 | cat file1 - file3,就是先cat file1,然后file2的输出,然后是file3。“|” 管道的作用就是前者的输出作为后者的输入。cat使用“-”代指标准输入。
该命令可以替换为filter file2 | cat file1 /dev/fd/0 file3,用该方法替代“-”可以避免用户将“-”误认为命令行选项。
Summary
This chapter has described the basic I/O functions provided by the UNIX System.These are often called the unbuffered I/O functions because each read or write invokes a system call into the kernel. Using only read and write, we looked at the effect of various I/O sizes on the amount of time required to read a file. We also looked at several ways to flush written data to disk and their effect on application performance.
Atomic operations were introduced when multiple processes append to the same file and when multiple processes create the same file. We also looked at the data structures used by the kernel to share information about open files. We’ll return to these data structures later in the text.
We also described the ioctl and fcntl functions. We return to both of these functions later in the book. In Chapter 14, we’ll use fcntl for record locking. In Chapter 18 and Chapter 19, we’ll use ioctl when we deal with terminal devices.
















 2130
2130

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











