



目录
一、情景导入
假设你是一家奶茶店的数据分析师,老板想在下周促销时精准发优惠券,但不想“广撒网”浪费钱。 XGBoost模型可以帮助你把顾客的消费记录,比如最近买过几次、喜欢什么口味、是否加珍珠都喂给模型。XGBoost像经验丰富的店长一样,自动找出规律:“周末下午买过芋圆奶茶的人,80%会回购”。最终,模型锁定了最可能下单的顾客,优惠券使用率直接翻倍。
二、模型介绍
(一)XGBoost:机器学习竞赛的王者算法
XGBoost(极限梯度提升)是一种基于决策树的集成学习算法,通过迭代地构建多棵弱学习器并组合它们的预测结果,实现了远超传统机器学习模型的优异表现。
其核心创新在于:
(1)采用带正则化的目标函数,有效控制模型复杂度防止过拟合;
(2)引入二阶泰勒展开优化损失函数,大幅提升收敛速度;
(3)独创的稀疏感知算法和加权分位数方案,可高效处理大规模稀疏数据;
(4)支持并行化和核外计算,计算效率比传统GBDT提升10倍以上。这些突破性设计使XGBoost在Kaggle等数据科学竞赛中屡创佳绩,成为处理结构化数据的首选算法,广泛应用于金融风控、推荐系统、广告点击率预测等实际业务场景。
(二)XGBoost 凭什么「封神」?
简单来说,XGBoost 是一种基于「梯度提升树(GBDT)」的优化算法,但它在速度、精度和灵活性上做到了极致:
速度快:通过并行计算、缓存优化等技术,训练速度比传统 GBDT 快 10 倍以上,甚至能处理千万级样本。
效果好:自带正则化机制,不易过拟合,在分类、回归、排序等任务中表现稳定。
够灵活:支持自定义损失函数,能处理缺失值、类别特征,还能输出特征重要性。
用一句话总结:它把「简单有效」做到了极致,既不像深度学习那样依赖海量数据和算力,又能在大多数场景下达到接近最优的效果。
三、模型原理
01、三分钟看懂 XGBoost 的核心原理
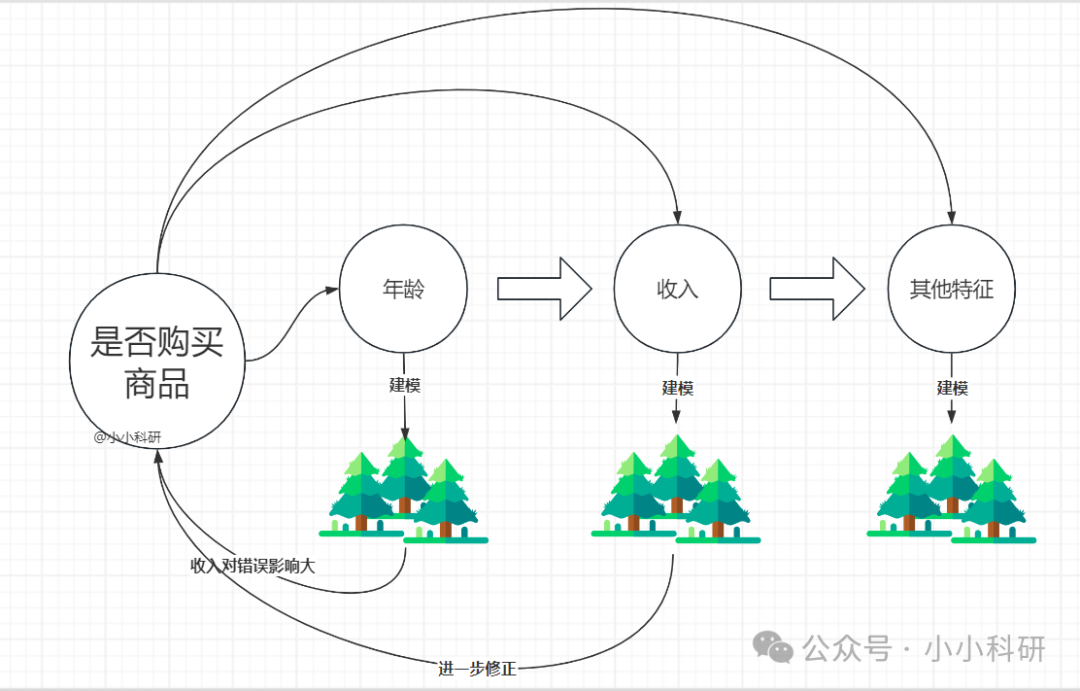
虽然名字里带「极端」,但 XGBoost 的核心逻辑其实很朴素:通过不断叠加「弱分类器」(决策树),最终形成一个「强分类器」。
举个例子:
假设我们要预测一个人是否会购买商品,第一次用「年龄」做了棵简单的决策树(正确率 70%);然后发现「收入」对错误样本影响很大,就基于错误再建一棵以「收入」为核心的树(修正后正确率 80%);继续叠加「是否有车」「浏览时长」等特征的树…… 最后把所有树的结果加权求和,得到高精度预测。
而 XGBoost 的「极端」之处在于:
正则化优化:在树的生长过程中加入惩罚项,防止过拟合(比如限制树的深度、叶子节点数量)。
并行计算:训练时可以同时处理多个特征,大幅提升速度。
缺失值自动处理:无需手动填充缺失值,算法会自动学习缺失值的最优分裂方向。
四、运用场景
1. 金融风控:精准识别欺诈交易、信用违约风险;处理高维稀疏的金融特征,如交易记录、用户画像。
2. 电商推荐:预测用户购买意向,提升转化率;分析点击、加购、收藏等行为数据
3. 医疗诊断:基于患者指标预测疾病风险;处理不均衡的医疗数据集
4. 广告投放:优化CTR(点击率)预估模型;动态调整广告出价策略
5. 工业预测:设备故障预警与剩余寿命预测;生产质量检测与工艺优化
XGBoost凭借出色的特征处理能力和预测精度,成为结构化数据建模的首选工具。
五、实战操作
(一)参数调优:新手也能玩转的「黄金法则」
XGBoost 的参数虽多,但无需死记硬背。记住「先调结构,再调正则,最后精调学习率」的顺序,就能快速找到最优解。
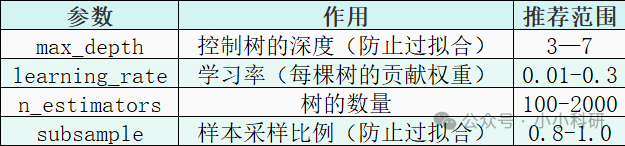
01、必调的核心参数
max_depth:数据维度高时调小(如 3),样本多可适当调大(如 5)。
学习率:初期用 0.1 快速试错,最终模型用 0.01 提升精度。
n_estimators:与学习率成反比:学习率 0.1 时设 100,0.01 时设 1000。
subsample:数据量大时用 0.8 采样,小样本建议 1.0。
02、防过拟合「三板斧」
如果模型出现「训练效果好,测试效果差」的过拟合现象,试试这三个参数:
gamma:分裂节点的「门槛」,值越大越保守(推荐 0-1)。
reg_alpha:L1 正则化,惩罚叶子节点权重(适合高维数据,推荐 0-5)。
reg_lambda:L2 正则化,默认值 1,可增大到 5-10 增强惩罚。
03、不平衡数据怎么办?
在风控、医疗等场景中,正负样本比例可能高达 1:100,这时一定要加上这个参数:
scale_pos_weight = 负样本数量 / 正样本数量(二)实战:用 XGBoost 快速搭建一个分类模型
# 1. 导入工具库
import xgboost as xgb
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score#
2. 加载数据(乳腺癌数据集,预测肿瘤是否良性)
data = load_breast_cancer()
X = data.data # 特征(如肿瘤大小、质地等)
y = data.target # 标签(0=恶性,1=良性)
# 3. 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42 # 80%训练,20%测试)
# 4. 定义模型(基础参数配置)
model = xgb.XGBClassifier(
objective="binary:logistic", # 二分类任务
max_depth=3, # 树深度,控制过拟合
learning_rate=0.1, # 学习率
n_estimators=100, # 树的数量
scale_pos_weight=1, # 样本平衡(这里正负样本较均衡)
random_state=42 # 随机种子)
# 5. 训练模型
model.fit(X_train, y_train)
# 6. 预测与评估
y_pred = model.predict(X_test)
print(f"测试集准确率:{accuracy_score(y_test, y_pred):.4f}") # 通常能达到95%以上六、总结
XGBoost 的强大,在于它把复杂的算法细节封装成了「傻瓜式接口」,但真正用好它,需要理解每个参数背后的逻辑。记住:没有万能的参数,只有适合数据的参数。
下次面对分类、回归问题时,不妨先用 XGBoost 搭个 baseline(基准模型),你会惊讶于它的表现!
关注【小小科研】公众号,了解更多模型哦,感谢支持!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









