









如何基于 JVM 分析内存使用对象?
上一讲我带你学习了基于 JVM 的线程分析,相信你已经可以通过热点线程分析出哪些方法在消耗 CPU,拿到这些方法之后你就可以和研发人员讨论后续的优化方案了。那这一讲我们就来重点学习 JVM 内存是如何管理的,有哪些手段可以分析内存对象,并帮助你定位内存的瓶颈。
提到分析 JVM 的内存对象,可能你会问我,之前讲过如何判断服务器内存瓶颈,那 JVM 内存和服务器内存有什么联系呢。我们先来看下这两者的关系,如下图所示:

图 1:内存关系示意图
其实二者的关系很简单,对于服务器系统而言,JVM 只是其中的一部分。当操作系统内存出现瓶颈时,我们便会重点排查哪些应用会占用内存。不过对于更深一步分析内存的使用,并不仅仅是统计使用、空闲等这些数值,我们需要进一步去了解内存结构,以及内存如何分配、如何回收,这样你才能更好地确定内存的问题。
JVM 内存分配
通过第 14 讲的学习你可以知道,Java 文件一般是先编译成 class 结尾的文件,然后通过类加载器到 JVM 内存中。接着我们来看看 JVM 内存结构图,这样能够对它有个全局的了解。
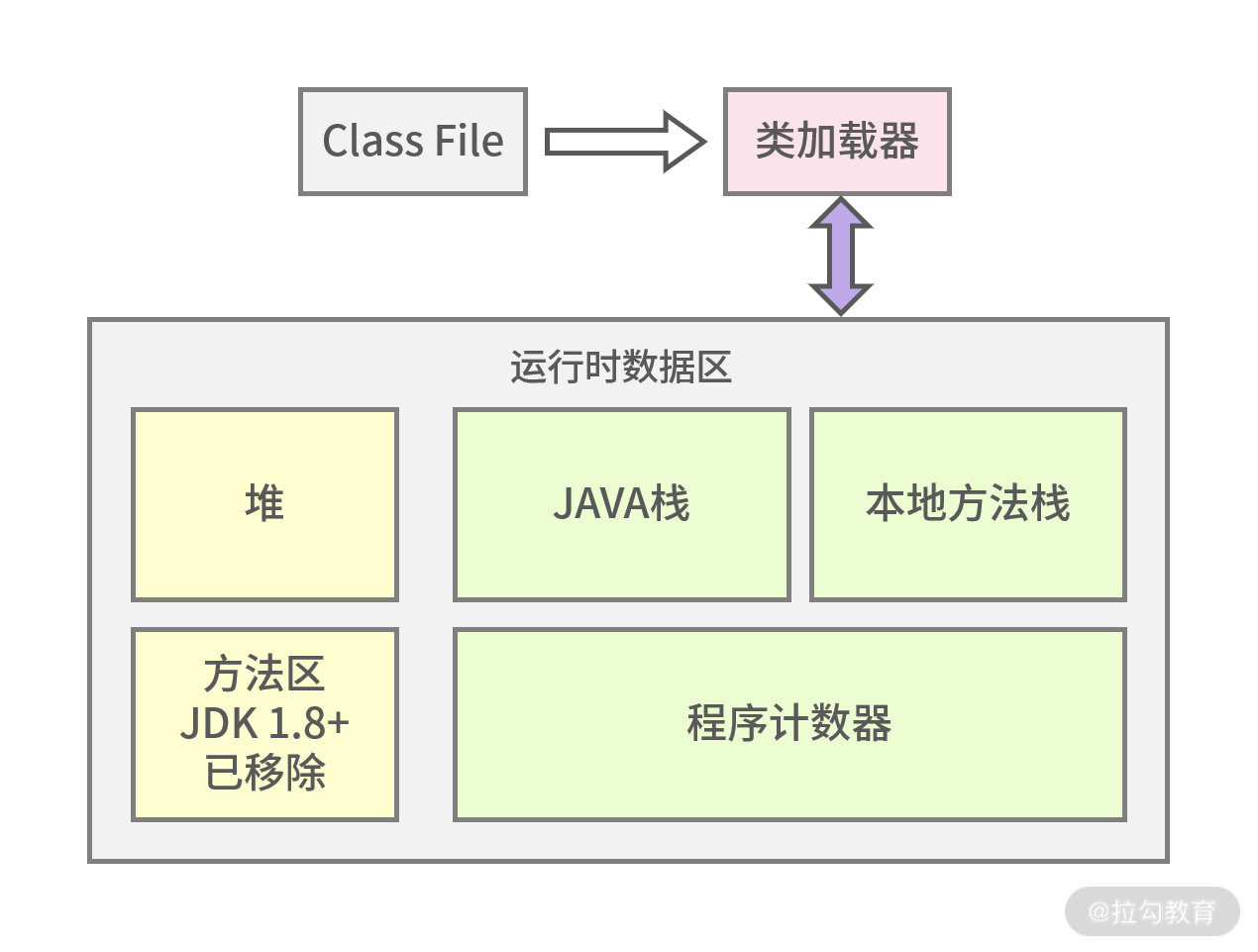
图 2:JVM 内存分配示意图
1.本地方法栈
本地方法栈保存的是 native 方法的信息,native 方法就是 Java 调用非 Java 代码的接口,为什么会有这样的设置呢?简单来说,sun 的解释器是由 C 语言实现的,而 jre 又是基于 Java 语言,所以需要 native 方法来进行跨语言的调用。
2.Java 栈
Java 栈是常用的内存区域之一,它里面存放着基本数据类型和对象的引用,可能你不太清楚什么是对象的引用,拿上一讲中 HelloTester helloTester=new HelloTester() 为例,在 Java 栈中 HelloTester 是个引用,指向在堆空间中开辟的该对象的空间。
3.方法区(JDK 1.8+已经移除)
也叫作永久区,用来存储类信息,如上文描述的 HelloTester。值得注意的是方法区在 JDK 1.8 以上已经被元空间取代,并且元空间不在 JVM 中了,而是在本地内存中独立开辟存储空间。
4.程序计数器
可以认为是线程的信号指示器,它的作用是保存线程当前程序的执行位置,以保证多线程的切换。因为在多线程的情况下,CPU 并不是完成一个线程执行再去执行另外一个线程,而是不停地切换线程执行,这时程序计数器就可以发挥作用了。
5.堆
堆区域是 JVM 调优最重要的区域,堆中存放的数据很多是对象实例,如 HelloTester 的对象存储。堆空间占据着 JVM 中最大的存储区域,存放了很多对象,所以大多数基于 JVM 的内存调优也是对堆空间的调优。
堆空间并非取之不尽,如果一直存放总有用完的时候,所以对于有用的对象应当保存起来,无用的对象应当回收,为了更好地实现这一机制,JVM 将堆空间分成了新生代和老生代,如下图所示:

图 3:GC 示意对比图
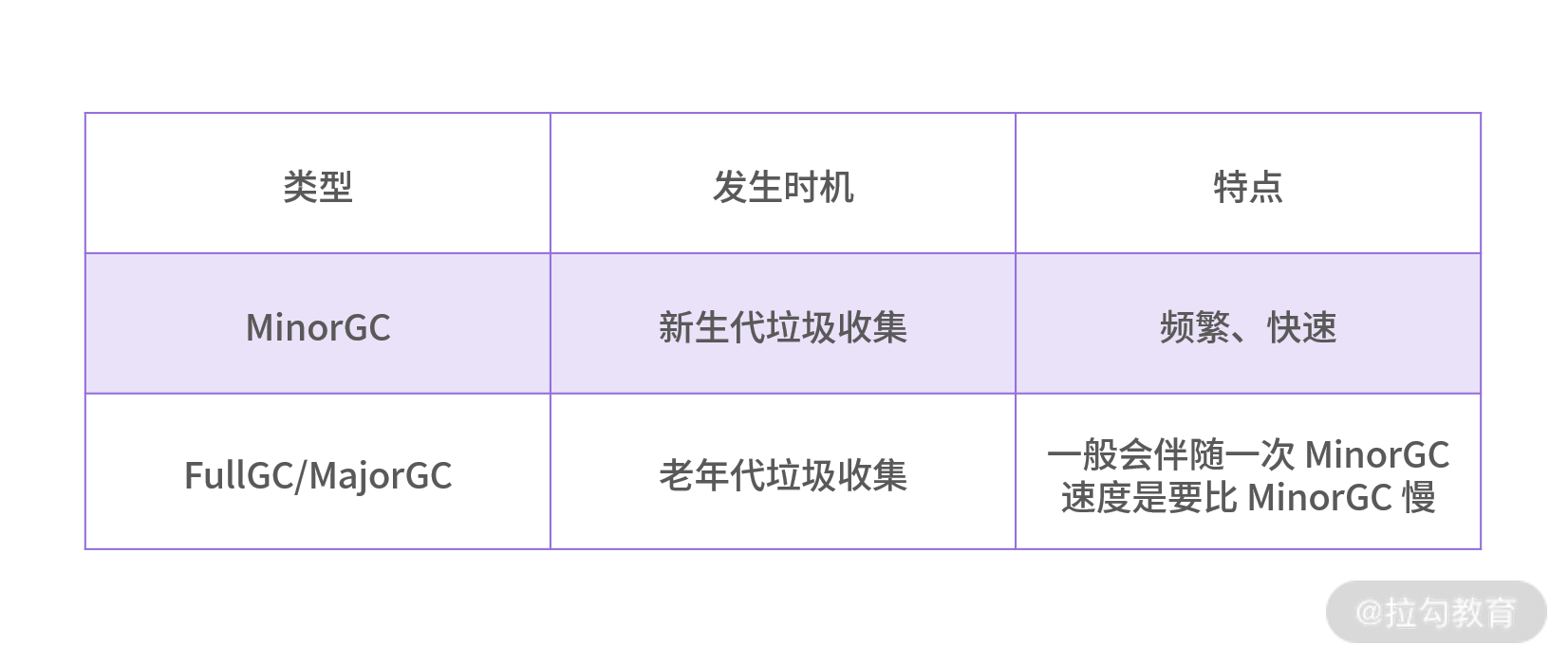
通过图 3 可以看到新生代和老年代的对比,Minor GC 发生在新生代,而 Full GC 发生在老年代。新生代分为三个区,一个 Eden 区和两个 Survivor 区。
先来看下 Eden 区的作用,大部分新生成的对象都是在 Eden 区,Eden 区满了之后便没有内存给新对象使用,Eden 区便会 Minor GC 回收无用内存,剩下的存活对象便会转移到 Survivor 区。
那两个 Survivor 区的作用分别是什么呢?两者其实是对称分布的,一个是 From 区,一个是 To 区。从 Eden 区存活下来的对象首先会被复制到 From 区,当 From 区满时,此时还存活的对象会被转移到 To 区,经历了多次的 Minor GC 后,还存活的对象就会被复制到老年代,老年代的 GC 一般叫作 FullGC 或者 MajorGC。
我们对比下新生代垃圾回收和老年代垃圾回收的区别,如下表所示:
如何定位内存占用问题
回到我们实际工作当中,当你发现 JVM 中使用的内存越来越多或者增长很快的时候,频繁 GC 的时候,应当如何去定位哪些对象导致的这些问题呢?
这其实涉及两个问题:
-
如何去观察 GC 的频次;
-
定位占用内存的对象。
1.如何观察 GC 的频次?
本部分我以 JDK 自带的工具来讲解,我一般使用 jstat 来查看 GC 的频次。首先我们来看下基本用法,如下所示:
[root@JD ~]# jstat -gc 26607 1000 3
S0C S1C S0U S1U EC EU OC OU MC MU CCSC CCSU YGC YGCT FGC FGCT GCT
512.0 512.0 320.0 0.0 86016.0 27828.5 175104.0 157974.6 122840.0 116934.9 16128.0 15060.4 5328 37.311 4 1.042 38.353
512.0 512.0 320.0 0.0 86016.0 27981.9 175104.0 157974.6 122840.0 116934.9 16128.0 15060.4 5328 37.311 4 1.042 38.353
512.0 512.0 320.0 0.0 86016.0 28885.4 175104.0 157974.6 122840.0 116934.9 16128.0 15060.4 5328 37.311 4 1.042 38.353
我们来解析下终端输入的命令:
jstat -gc 26607 1000 3
-
26607 代表查看的 PID 的 Java 进程号;
-
1000 代表每隔 1000ms 也就是 1s 显示一次;
-
3 代表一共显示三次。
接着我们再来看输出选项代表的含义有哪些?这个输出的信息含量比较大,不过信息是有对应关系的,比如 S0C 和 S0U:
-
一般 C 结尾的代表总的容量大小或者计数的次数;
-
U 结尾代表已使用的容量大小。
这是通用的,你可以看到输出项中有很多以 C 或者 U 结尾。S0 则代表第一个 Survivor 区,也就是我上文说的 From 区。通过以上的讲解,我相信很多名词你不用死记硬背也能理解了,比如 S1C 和 S1U 则表示第二个 Survivor 区也就是 To 区的总容量和使用容量。
接下来我罗列下其他的输出选项含义。
-
EC / EU:Eden 区的总容量/已使用空间的大小。
-
OC / OU:老年代总容量/老年代已使用空间大小。
-
MC / MU:方法区总容量/方法区已使用容量大小。
-
CCSC / CCSU:压缩类总容量/压缩类空间使用大小。
-
YGC / YGCT:年轻代垃圾回收的次数/年轻代垃圾回收消耗时间。
-
FGC / FGCT: 老年代垃圾回收次数/老年代垃圾回收消耗时间。
-
GCT:垃圾回收消耗总时间。
这样对比着看会更直观一点,对于上述输出选项的含义我们都需要有一定的印象,从而通过垃圾回收频率和消耗时间初步判断 GC 是否存在可疑问题。
有同学问过这样的问题,堆内存区域划分了这么多代,感觉很复杂,为什么要这么做呢?
我想不分代,内存垃圾肯定也是可以回收的。而让内存区域分代,主要就是优化垃圾回收的性能,也就是 GC 的性能。有点类似于我们日常生活中的垃圾分类,你把干湿垃圾分离,一方面有利于下一步的再利用,再者对于我们后续垃圾的处理效率也会有较大的提升。对于内存回收其实也是这样的,如果不分代那么所有的对象可能都在同一个大的区间里,GC 依次判断则效率必然是很低,如果是分代处理,对不同的区域分以不同的回收策略,这样效率会高很多。
2.如何定位占用内存的对象?
这里我将推荐一个工具 jmap,通过 jmap 可以指定 Java 进程的 PID,查看该进程的对象、数量等等,接下来我做一个演示。
首先我们来查看进程号为 18658 的应用包,如下所示:
[root@JD ~]# ps -ef|grep demo
root 18658 1 0 Dec09 ?后续省略
其中上述输出的第二列 18658 为进程号,然后将进程号通过命令组合可以查看以下信息:
[root@JD ~]# jmap -histo 18658|head -n 20
num #instances #bytes class name
----------------------------------------------
1: 157619 18840672 [C
2: 8326 8324360 [B
3: 146319 3511656 java.lang.String
4: 9224 2825584 [I
5: 65733 2103456 com.example.demo.entity.User
6: 62508 2000256 java.util.HashMap$Node
7: 21868 1618832 [Ljava.lang.Object;
-
num 是编号;
-
instances 是生成的实例个数;
-
bytes 是实例占用的大小;
-
classs name 对象的类名。
其中 [C、[S、[I、[B 对应的类型如下所示:
[C is a char[]
[S is a short[]
[I is a int[]
[B is a byte[]
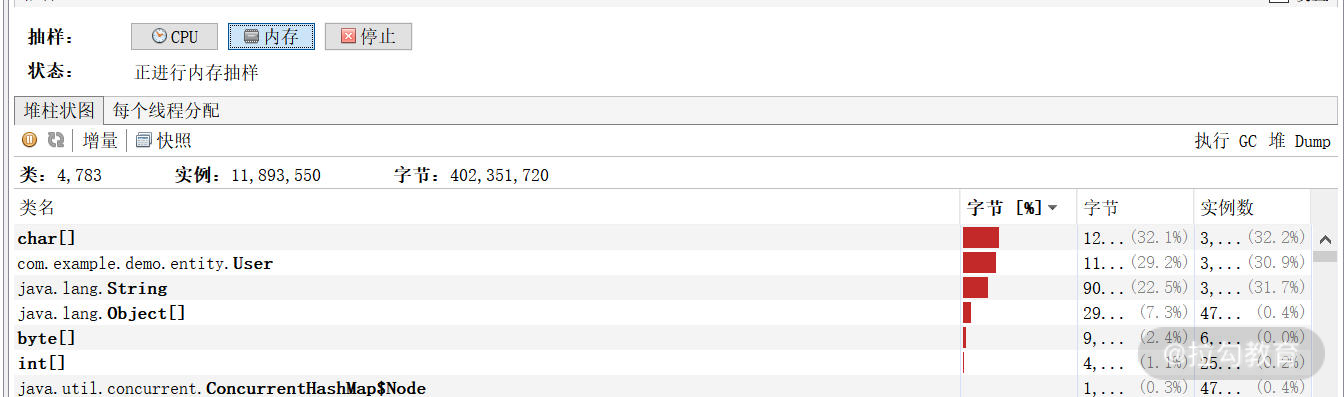
你注意下第五行,这是能够最直接看到的业务类,如果是业务对象尤其需要关注,看是否一直上升。
可视化的 JVM 监控工具
在第三模块中,你可以知道,对于监控定位我一般会采用命令行结合可视化的方案一并讲解,接下来我介绍一个 JDK 自带的 JVM 监控工具:jvisual。
jvisual 能做的事情很多,监控内存泄漏、跟踪垃圾回收、执行时内存分析、CPU 线程分析等,而且通过图形化的界面指引就可以完成,接下来我主要讲述 jvisual 如何使用以及如何看内存对象的占用。
先来看下 jvisual 是如何使用的,一般我们会在启动被测的 jar 服务里进行如下配置:
nohup java -Djava.rmi.server.hostname=实际ip -Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.port=1099 -Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=false -jar demo-0.0.1-SNAPSHOT.jar &
通过这样的方式可以启动暴露 1099 端口,且连接时不需要认证。
然后在本机电脑 jdk 路径 bin 目录下找到 jvisualvm,双击打开,如下图所示:

我们再配置相应的 jmx 连接,如下图所示:

如果出现如下图所示的界面,就证明连接成功了。
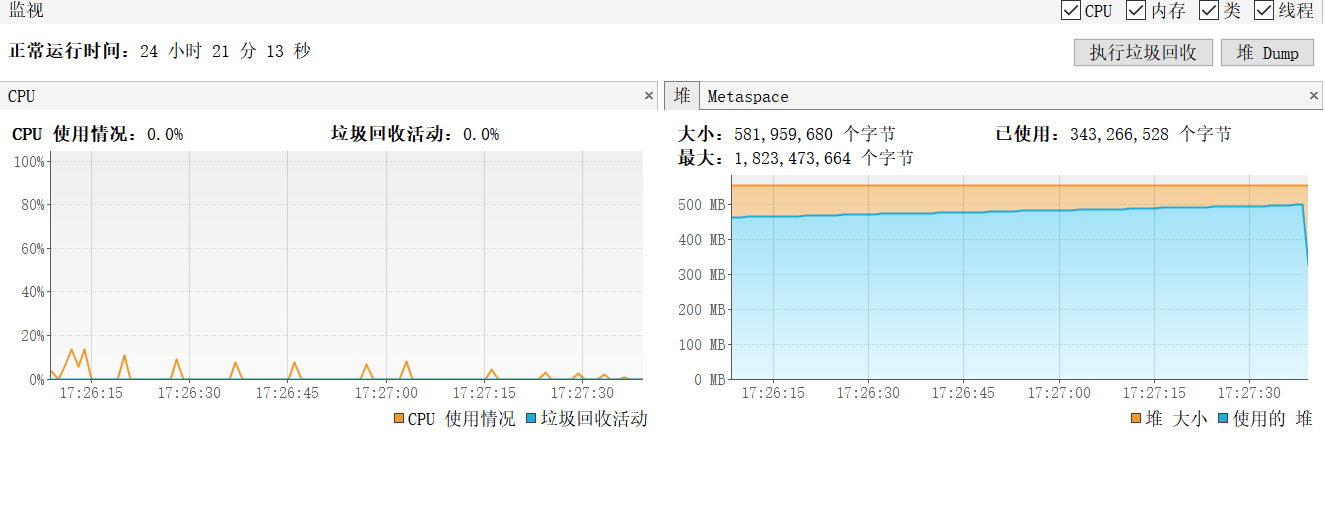
这样我们就能够概览 JVM 的 CPU 和内存的使用情况,如下图所示,通过点击抽样器,你可以分别获得对象在 CPU 和内存的占用。值得注意的是很多初学者把这部分 CPU 监控或者内存监控认为是服务器硬件级别的,这是不对的,这些都是基于 JVM 的监控。
按照内存占用进行排序是非常清晰的,你可以看到随着性能测试的进行,User 类字节占用比例越来越高,如下图所示:
总结
通过本讲的学习,你了解了 JVM 的内存结构,知道了 Java 内存对象经常活动的区域,同时列举了常见的排查手段诊断内存问题。
在本讲中有一个名词叫作 GC 频繁,那在你的实际工作当中,年轻代或者老年代一般多久回收一次算频繁呢?或者什么样的场景让你认为 GC 可能是有问题的呢?欢迎在评论区分享你的观点。
下一讲我将带你一起探讨一款阿里巴巴的监控工具——Arthas,到时见。
如何通过 Artha 定位代码链路问题?
前两讲我分别讲述了 JVM 线程分析和内存分析的实操技巧及注意点,让你可以从表象的硬件瓶颈逐渐深入到定位代码问题。类似于这样的定位方式,有一个共同点是会呈现出硬件层或者表象的一些异常。
然而并不是所有的性能问题都可以通过这样的方式去定位,有时候接口的 TPS 很低,但是各项资源占用也很低,你很难通过资源的异常去找到诊断的切入口。这样的情况也是很常见的,除了可以用《11 | 分布式服务链路监控以及报警方案》中讲到的链路监控工具定位外,这一讲我还会带来一个代码级定位工具——Arthas,Arthas 不仅仅能够让你看到 JVM 的运行状态去定位性能问题,对于很多线上代码异常问题的排查,Arthas 也是手到擒来。
下面的场景你一定很熟悉:
-
如果线上出现了偶发性问题,我们需要花费大量时间一步步排查,日志里的每个细节都不能错过,如果线上不能直接得出结论,还需要线下再去复现,很消耗时间和精力;
-
某行代码没有被执行,也没有出现报错信息,按照传统的方法可能会去加一些判断日志,这就涉及再次上线的问题,很多公司上线流程需要审批,这增加了内耗。
而熟练使用 Arthas 这个工具便可以很好地解决以上问题,接下来我将介绍下 Arthas 以及实战中怎么用 Arthas 定位问题。
Arthas 是什么
Arthas 是阿里提供的一款 Java 开源诊断工具。能够查看应用的线程状态、JVM 信息等;并能够在线对业务问题诊断,比如查看方法调用的出入参、执行过程、抛出的异常、输出方法执行耗时等,大大提升了线上问题的排查效率。
Arthas 的使用方法
首先我们用以下命令下载 Arthas:
wget https://alibaba.github.io/arthas/arthas-boot.jar
Arthas 提供的程序包是以 jar 的形式给出,因此我们可以看出 Arthas 本质也是个 Java 应用。
然后使用 java -jar 命令启动,如下所示:
java -jar arthas-boot.jar
输入启动命令后会跳出选项让你选择要监控的后台 Java 进程,如下代码所示:
[root@JD ~]# java -jar arthas-boot.jar
[INFO] arthas-boot version: 3.3.3
[INFO] Found existing java process, please choose one and input the serial number of the process, eg : 1. Then hit ENTER.
* [1]: 689 cctestplatform.jar
[2]: 31953 unimall.jar
[3]: 14643 sentinel-dashboard-1.7.2.jar
[4]: 20421 org.apache.zookeeper.server.quorum.QuorumPeerMain
[5]: 10694 demo-0.0.1-SNAPSHOT.jar
其中序号表示的就是 Arthas 自动识别的所在服务器的 Java 进程,然后输入要监控的进程的序号并回车,Arthas 便会接着启动,出现 Arthas Logo 之后便可以使用 Arthas 了,如下代码所示:
5
[INFO] arthas home: /root/.arthas/lib/3.4.4/arthas
[INFO] Try to attach process 10694
[INFO] Attach process 10694 success.
[INFO] arthas-client connect 127.0.0.1 3658
wiki https://arthas.aliyun.com/doc
tutorials https://arthas.aliyun.com/doc/arthas-tutorials.html
version 3.4.4
pid 10694
另外如果你想要打印帮助信息可以在启动命令后面加 -h 来完成,如下所示:
java -jar arthas-boot.jar -h
Arthas 实操演示
1.利用 Arthas 线程相关命令定位死锁问题
在排查问题前我们先了解下死锁,死锁是指由于两个或者多个线程互相持有对方所需要的资源,导致这些线程处于等待状态,无法前往执行。如果没有外力的作用,那么死锁涉及的各个线程都将永久处于循环等待状态,导致业务无法预期运行,所以我们的代码要避免死锁的情况。
死锁就好比打游戏排位的时候, A 和 B 不能选相同的英雄,A 选了诸葛亮,但是突然间后悔了,想重新选貂蝉,但是貂蝉已经被 B 选了,但是 B 选择之后也后悔了,想重新选诸葛亮,但是诸葛亮已经被 A 选了。这个时候 A 和 B 都不让步,结果是谁都无法选到想要的英雄。
死锁的代码演示如下:
//线程Lock1代码示意
while(true){
synchronized("obj1"){
Thread.sleep(3000);//获取obj1后先等一会儿,让Lock2有足够的时间锁住obj2
synchronized("obj2"){
System.out.println("Lock1 lock obj2");
}
}
}
//线程Lock2代码示意
while(true){
synchronized(“obj2”){
Thread.sleep(3000); //获取obj2后先等一会儿,让Lock1有足够的时间锁住obj1
synchronized(“obj1”){
System.out.println(“Lock2 lock obj1”);
}
}
}
把以上代码放到服务器中执行,然后我们可以使用 Arthas 的 jvm 命令查看到线程死锁数目为 2,说明程序发生了死锁,如下图所示:

图 1:死锁示意图
接下来我们输入 thread -b 命令查看当前阻塞其他线程的线程,然后我们可以看到 Lock 1 被阻塞了,访问的资源被 Lock 2 占用,如图 2 所示,根据提示的行数我们便能找到死锁位置,对代码进行优化。
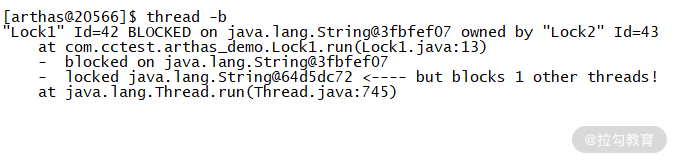
图 2:thread 演示死锁详情图
2.使用 trace 命令查看耗时
我们写几个不同循环次数的方法,分别代表方法耗时不同,代码如下:
//示例代码,timeCost是个接口
public String timeCost(){
cost1();
cost2();
cost3();
.......
}
private void cost3() {
//进行200万次循环......
}
private void cost2() {
//进行10万次循环......
}
private void cost1() {
//进行10次循环......
}
部署之后我们使用 trace 来查找最耗时的方法,在此过程中需要知道包名、类名,以及方法的名字。上述代码方法所在包名为 com.cctest.arthas_demo.controller,类名为 StressSceneController,所以我们需要输入如下 trace 命令:
trace
com.cctest.arthas_demo.controller.StressSceneController timeCost
输完命令后回车,然后 arthas 程序就进入了等待访问状态。这时候访问接口 /timeCost,我们就可以看到被测程序台在疯狂打印日志,等结束之后,arthas 命令窗口便输出了各方法耗时时间,如图 3 所示:

图 3:方法耗时详情
我们可以看到 timeCost 方法总耗时 258391ms:
-
cost 1 调用耗时 9 ms;
-
cost 2 调用耗时 13909 ms;
-
cost 3 调用耗时 244472 ms。
cost 2 和 cost 3 方法耗时都比较长,当你能够定位到方法级别的消耗时长时,基本已经能够找到问题的根因了。
3.使用 watch 命令观察被测方法的参数和返回值
当遇到线上数据问题时,我们一般有两种查找问题的途径:
-
在开发环境中模拟线上数据来复现问题,不过因为环境等各方面的不同,很多情况下模拟数据复现都有难度;
-
在生产日志里查找线索,如果没有相关方法的入参,以及没打印返回值的话,就难以找到有效的信息。
这两种传统查找问题的方式都存在一定的局限性,而使用 Arthas 的 watch 命令可以很方便地根据观察方法入参和出参来判断是否正确定位了代码问题。
为了能够让你更清楚地看到方法名和出参入参,我写了一段示例代码,如下所示:
@GetMapping("/login")
public String login(@RequestParam(value="userName") String userName, @RequestParam(value="pwd")String pwd){
return "OK";
}
然后我们输入 watch 命令,其中 login 后面指定了需要控制台输出的内容,params[0] 代表第一个参数,如果参数有多个,只要 params 加上下标即可,returnObj 代表返回值,示意代码如下:
watch com.cctest.arthas_demo.controller.StressSceneController login "{params[0],params[1],returnObj}"
你可以看到输入上述命令后的返回信息如下:

图 4:watch 返回信息
4.使用 tt 命令定位异常调用
tt 与上面的 watch 的命令有些类似,都可以排查函数的调用情况。但是对于函数调用 n 次中有几次是异常情况,用 watch 就没有那么方便,使用 tt 命令就可以很方便地查看异常的调用及其信息。
使用 tt 命令示意如下:
tt -t com.cctest.arthas_demo.controller.StressSceneController login
然后我们访问接口,每次访问的状态和结果显示如图 5 所示:

图 5:tt 的返回信息
从图中可以看出,tt 显示的信息比 watch 全面。其中 IS-RET 项如果为 false,即为错误的调用。
以上部分介绍了 Arthas 命令在实际例子中的使用,我是通过命令行的方式来演示的,所以你需要登上服务器。之前有提到过,并不是所有的同学都有权限直接进行服务器的操作,那面对这样的情况如何使用 Arthas 呢?其实也是有解决方法的,接下来我们将介绍通过 Web 的方式操作 Arthas。
通过 Web 的方式操作 Arthas
Arthas 提供了客户端访问程序 Arthas Tunnel Server,这样我们便可以操作 Arthas 了,接下来我介绍下 Arthas Tunnel Server 的操作步骤以及操作原理。
1.Arthas Tunnel Server 的操作步骤
(1)下载 arthas-tunnel-server.jar,点击下载地址;
(2)把 Arthas Tunnel Server 部署到能和线上服务器通信的目标服务器;
(3)确保线上服务器启动了 Arthas,线上启动 Arthas 的操作命令,如下所示:
java -jar arthas-boot.jar --tunnel-server 'ws://目标服务器ip:目标服务器port/ws' --target-ip
-
这里说的 target-ip 是指被测程序所在服务器的 IP;
-
目标服务器即 Arthas Tunnel Server 启动的服务器,端口号默认是 8080。
(4)在浏览器中输入 http://目标服务器ip:目标服务器port,就可以访问 WebConsole,如图 6 所示:
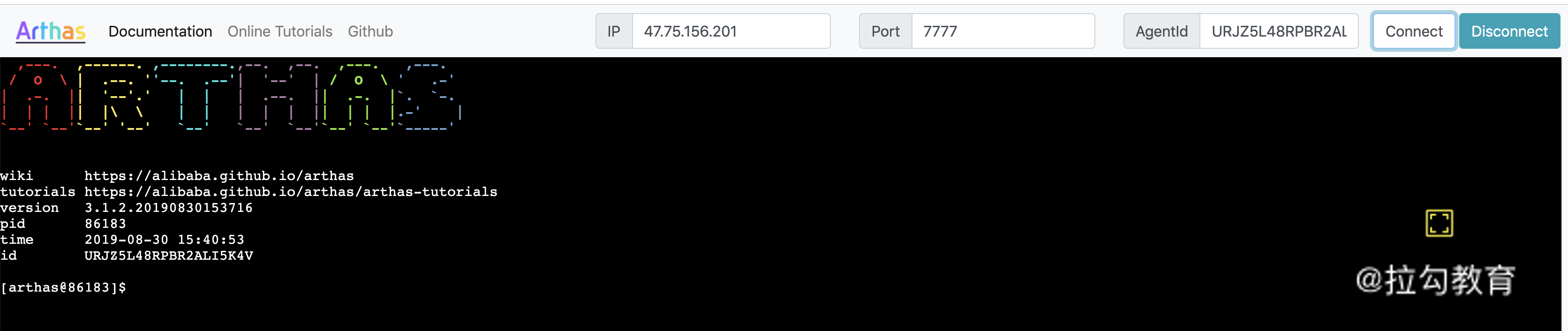
图 6:Web 方式 Arthas 启动
然后我们输入 ip、port 和 agentid 就可以连上被测程序,并且可以开始对被测程序输入 Arthas 命令。接下来的 Arthas 的使用和命令行方式是一样的,不再赘述。
2.Arthas Tunnel Server 的操作原理
通过 Arthas Tunnel Server 的操作步骤,我们可以总结出它实现 Web 访问的原理:所有节点的 Arthas 服务启动都会向注册中心(Arthas Tunnel Server)注册,注册中心维护了一个节点列表,当客户端发起访问某个节点,Arthas Tunnel Server 便会从维护的节点列表找到与请求的 ip 和端口号对应的节点进行访问,然后把访问结果返回给客户端。具体流程如图 7 所示:
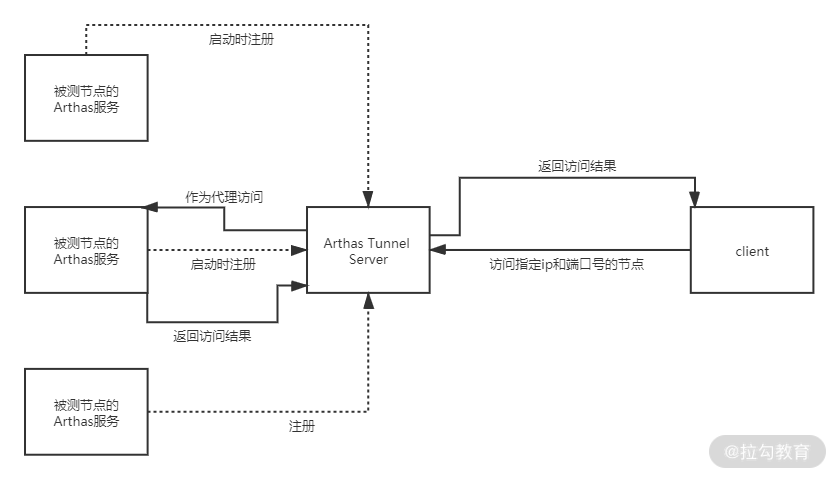
图 7:Arthas Tunnel Server 原理图
通过 Web 方式使用 Arthas 与我们上面所说的非 Web 的方式最大的不同:
-
Web 方式可以授权连接之后通过浏览器输入 Arthas 命令;
-
非 Web 方式则是直接 ssh 连接服务器输入命令。
两者比较起来 Web 方式虽然操作麻烦些,不过在权限管控比较严格的情况下提供了使用 Arthas 的可行性。
总结
这一讲我主要介绍了 Arthas 是什么、为什么使用 Arthas,以及通过实际操作演示 Arthas 是怎么实时定位代码问题的,并且为你介绍了 Arthas Tunnel Server 的操作步骤以及原理。上面第三部分的 4 个操作实例都是比较典型的排查线上问题的方式,通过实例的演示也能看出来 Arthas 的强大和便捷性。
希望这一讲能够对你在实际项目中定位代码问题有所帮助,也能对 Arthas 有一个更深刻的了解。有任何问题,都欢迎在留言区与我交流。
下一讲我带你学习互联网架构中常用的中间件 Redis,从性能的层面来看 Redis 应当如何使用,到时见。
如何应对 Redi 缓存穿透、击穿和雪崩?
上一讲我带你学习了如何应用 Arthas 定位代码以及链路问题。这一讲我将带你来学习一个关键的内存数据库中间件 Redis,希望你可以了解它的作用,以及在使用过程中的常见问题以及解决方案。
为什么使用内存数据库?
首先我们来看看最早期的 Web 架构是什么样的,如图 1 所示:

图 1:早期架构
这是互联网早期的常用架构,不过这样的架构一般只满足于基本的业务运转,一旦业务量迅速增高,就会出现各种请求延迟,甚至超时响应或者直接请求拒绝的情况 ,也就是在高访问量下会发生性能问题,而且这样的框架性能问题又集中在数据库层面。
那么问题来了,为什么会产生这种情况呢?由于数据库的数据是存在硬盘上,硬盘的 I/O 读写瓶颈会直接影响并发量。既然磁盘 I/O 读写时瓶颈,我们是不是可以采用速度更快的内存来存储常用但数据量不算大的数据呢?答案是肯定的。
为了解决上面的问题,目前通用的做法是引入基于内存的数据库,这样的数据库一般是把数据先放到内存里,引入缓存中间件之后的项目 Web 服务架构图如下所示:
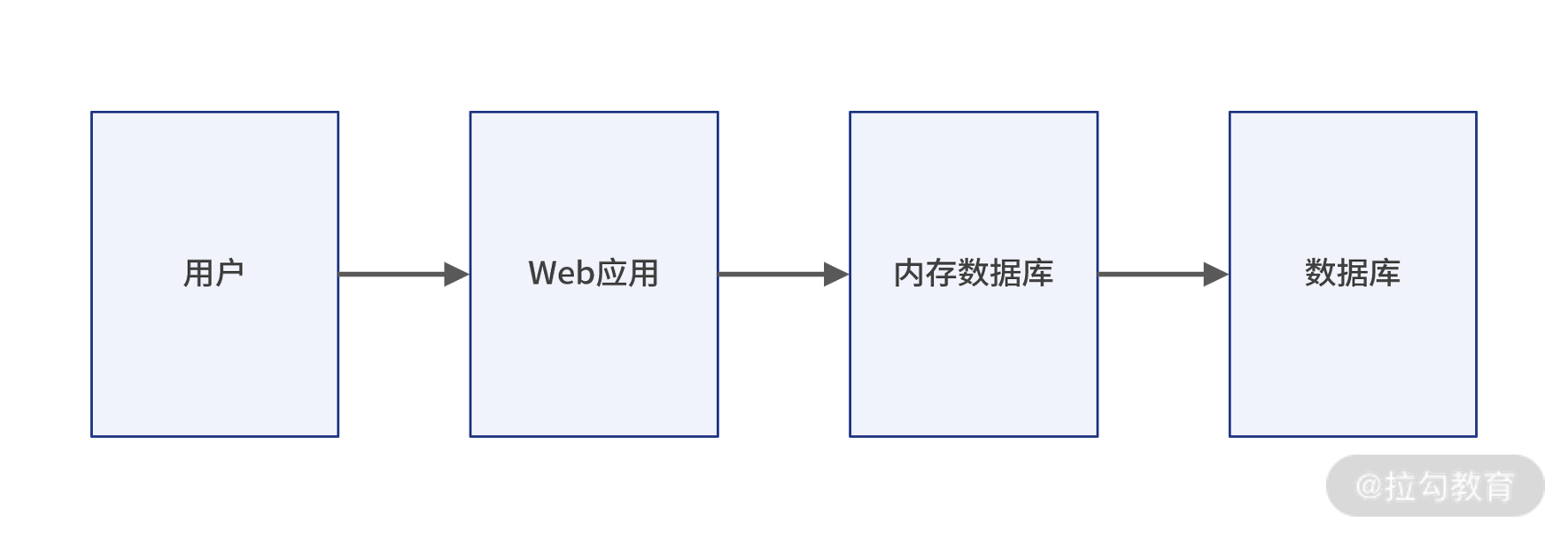
图 2:演变架构
这样便可以较大程度缓解传统数据库带来的磁盘 I/O 读写瓶颈,而我们最常使用的基于内存的数据库就是 Redis 和 MemCached。
Redis 和 Memcached 对比
1.存储方式
-
MemCached 目前只支持单一的数据结构 Key-Value 形式;
-
Redis 支持多种数据结构,有字符串、列表、集合、散列表、有序集合等。
2.持久化
持久化就是把数据从内存永久存储到磁盘里,可以防止断电等异常情况下数据丢失等问题。目前 Redis 支持持久化,而 MemCached 不支持。遇到灾难,MemCached 无法恢复数据,Redis 可以恢复数据,保证了数据的安全性。
从以上特点可以看出 Redis 在数据多样性和安全性上远高于 MemCached。以我的从业经历讲,MemCachded 使用频率越来越低,绝大多数的业务场景使用 Redis 居多。
Redis 带来的性能影响
我们列举一个案例来看 Redis 带来的性能影响。
我们使用 Spring Boot 开发连接 Redis 的 demo,分如下三步。
(1)在 Maven 中引入 Spring Boot 使用的 Redis 类库,如下代码所示:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
<version>2.4.2</version>
</dependency>
(2)通过注解方式获取 RedisTemplate,如下代码所示:
@Autowired
private RedisTemplate<String, String> redisTemplate;
(3)使用 Redis 提供的 API 实现业务代码的缓存读写,如下代码所示:
@GetMapping("/getRedisTestData")
public Result getRedisTestData(){
String redisTestListData = null;
try {
redisTestListData = redisTemplate.boundValueOps("redisTest.findAll").get();
//如果redis中没有数据的话
if(null == redisTestListData){
//查询数据库获得数据
List<RedisTest> redisTestList = simulateSceneRepository.findAll();
//转换成json格式字符串
ObjectMapper om = new ObjectMapper();
redisTestListData = om.writeValueAsString(redisTestList);
//将数据存储到redis中,下次在查询直接从redis中获得数据,不用再查询数据库
redisTemplate.boundValueOps("redisTest.findAll").set(redisTestListData);
log.info("从Mysql数据库获得数据");
}else{
log.info("从redis缓存中获得数据");
}
} catch (Exception e){
log.error("e:{}",e);
}
return Result.resultSuccess(null,redisTestListData,"数据读取成功");
}
通过如上三步就可以完成 Java 使用 Redis 的 demo,我大概总结下代码流程,第一次先判断 Redis 中是否存在查询的数据,如果没有就需要从数据库中读取数据了,读取成功之后把数据回写到 Redis 中,后面的请求就能直接从 Redis 中直接读取了,较大地减少了对数据库的查询压力。我们可以通过运行上面写好的代码来看下实际效果。
首先我们向数据表 redis_test 插入 10w 条数据,然后分两次访问该接口,对比下两次访问的响应时间。
第一次直接从 MySQL 数据库读取,一共花了 39.43s,如下图所示:
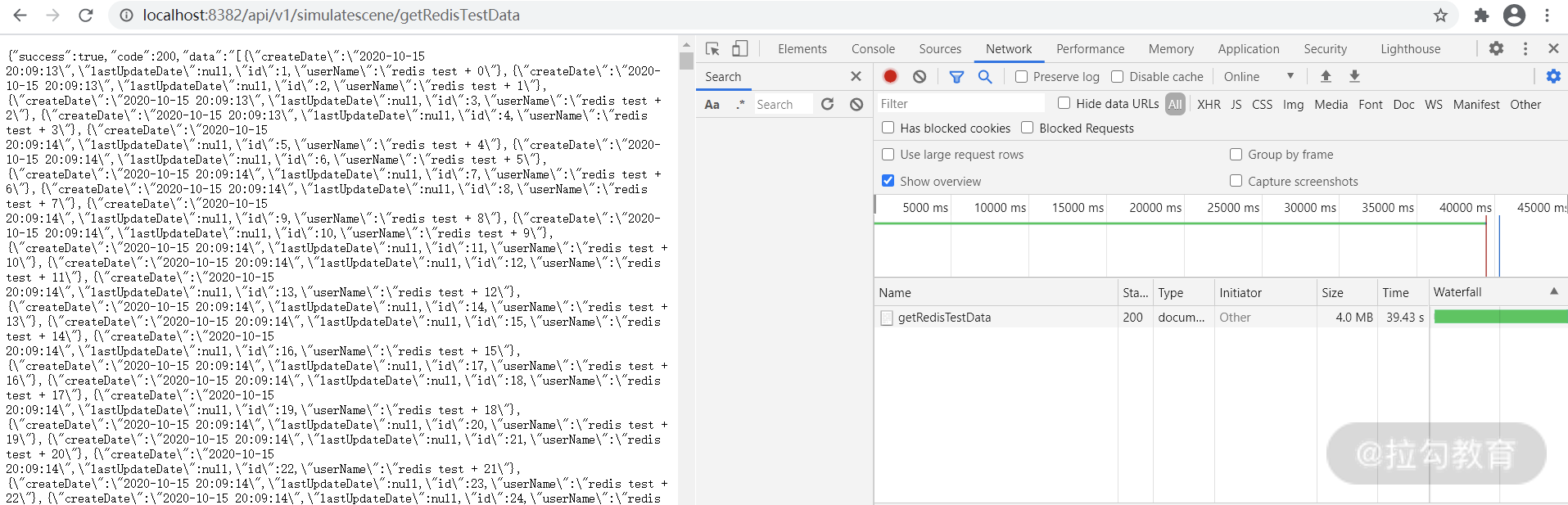
图 3:MySQL 取数据耗时
而第二次数据已经进入 Redis,请求只需要 2.62s,节省了很长时间。值得注意的是为了演示效果,取出的数据条数达到 10w+,所以响应时间也达到了秒级别。在正常的互联网业务当中,Redis 读写操作均在毫秒级别。

图 4:Redis 取数据耗时
从上面实例可以看出使用 Redis 和不使用 Redis 性能差距明显,所以从目前的互联网项目来讲,使用 Redis 是一个非常普遍的情况,接下来我们来了解下 Redis 其他特性和优缺点。
Redis 其他特性以及优缺点
1.Redis 的特性
主从复制功能
虽然数据在内存中读写速度比较快,但是在高并发情况下也会产生读写压力特别大的情况,Redis 针对这一情况提供了主从复制功能。
主从复制的好处有如下两点:
-
提供了 Redis 扩展性,当一台 Redis 不够用时,可以增加多台 Redis 作为从服务器向外提供服务;
-
提供了数据备份和冗余服务器,当 Redis 主服务器意外宕机,从服务器可以顶替主服务器向外提供服务,增加了系统的高可用性。
脚本操作
Redis 提供了 lua 脚本操作,你可以将 Redis 存取操作写到 lua 脚本里,然后通过 Redis 提供的 API 来执行 lua 脚本,这样就可以实现 Redis 相关操作。
我们同样可以用 Redis 提供的 API 直接实现 Redis 相关操作,那么为什么有时候又要绕一圈去操作 lua 脚本呢?因为 lua 脚本能够保证操作的原子性,即所有的操作当作一个操作,要么全部失败要么全部成功。而直接使用 API 不一定能保证一连串操作的原子性,所以当需要保证原子性的时候需要使用 lua 脚本。
发布与订阅
该特性可以将 Redis 作为消息中间件,在服务端产生消息,然后在客户端消费消息队列里的消息,但是作为消息队列不是 Redis 的强项,所以不推荐使用。比如 Redis 作为消息队列消息并非完全可靠,会产生消息丢失的问题,并且也不支持消息分组。在性能上,如果入队和出队操作频繁,那 Redis 性能比起 RabbitMq 等常用消息队列来说还是有差距的。
了解了 Redis 的一些特性,那使用过程中有没有一些注意点呢?其实我们也会踩到坑,比较常见的问题是缓存穿透、缓存击穿以及缓存雪崩,接下来就来讲讲这些问题出现的现象以及如何解决。
2.Redis 的缺点
缓存穿透
缓存穿透的情况是 Redis 和 MySQL 数据库都没有这条数据,但是用户不断并发发起请求,请求压力会同时落到数据库和缓存上,这样的情况相对于设计初衷来说,对系统的压力就会大很多了,而且这也是黑客发起攻击的手段之一,找寻你的系统是否存在漏洞。
那在项目中如果遇到缓存穿透我们该如何解决呢?
遇到缓存穿透,我们可以在请求访问缓存和数据库都没查到数据时,给一个默认值或者 Null 值,即 Key-Null。然后该缓存值的有效时间可以设置得短点,比如 30s。在业务代码中判断如果是 Null 值就取消查询数据库,或者间隔 30s 之后重试,这样的方式可以大幅度减轻数据库的查询压力。
缓存击穿
单个数据在缓存中不存在,而在数据库中存在。一般这种情况都是缓存失效导致的,在缓存失效的时间段有大量并发用户访问,首先访问缓存,因为 Key 已经过期了,所以查不到数据,然后所有查询压力都会落到数据库上,造成数据库的压力过大。并且还有可能因为并发问题导致重复更新缓存而过多占用缓存资源。
在项目中如果遇到缓存击穿问题,该如何解决呢?
-
对于一些经常被访问的热点数据,可以根据业务特性主动检查使其 Redis 数据永不过期,当然这样的设置并不代表说这条数据一直不更新而处在 Redis 中,而是根据数据字段中的失效时间和系统时间的对比主动检查更新数据,使 Redis 数据不会过期;
-
通过后台定时刷新,根据缓存失效时间节点去批量刷新缓存数据,这个适合 Key 失效时间相对固定的场景。
缓存雪崩
大量数据在同一时间失效,会造成数据库查询压力过大导致宕机。缓存雪崩与缓存击穿的区别在于缓存击穿是单个数据失效,缓存雪崩是多个数据同一时间失效。
在项目中如果遇到缓存雪崩的问题,我们该如何解决呢?以下 3 种方法可以帮我们解决。
-
如果程序设置的缓存过期时间统一为一个固定的值,比如 5s、10s、15s 等等,那么很有可能出现大量数据在同一时间失效。这个时候我们可以设置不同的过期时间,比如统一时间加上一个随机时间,这样可以让缓存的时间尽量均匀分布一点。
-
不设置过期时间,让程序的定时任务自动定时更新或者清除缓存
-
使用集群化的方式,保证高可用。
总结
通过本讲的学习你了解了 Redis 的作用,Redis 使用过程中遇到的缓存穿透、缓存击穿以及缓存雪崩现象,及如何解决此类问题,相信你已经有了一个更深刻的认识。
我想 Redis 带来的好处是很多的,通过这一讲的学习,你也应该知道 Redis 使用不当也会带来不少问题,其实无论什么技术,都不是万能的。我也想听一听你们在使用 Redis 时遇到过哪些问题并且是如何解决的,欢迎在评论区与我交流。
同时这讲也多次提到了 MySQL,其实 MySQL 的性能优化也会有很多方案,下一讲我将带你学习如何才能优化 MySQL 性能。
如何才能优化 MySQL 性能?
上一讲带你学习了 Redis,知道了它带来的好处,不过 Redis 虽然高效迅速,但如果不能合理使用依然会存在不少性能问题。
这一讲我会带你学习以 MySQL 为例的持久化的数据库,说到数据库优化这块,很多同学并不陌生,比如添加索引、读写分离之类。那如何第一时间发现索引有没有缺失、索引有没有生效、扫描了多少行、读写分离用的什么策略,很多同学又不知道如何回答,本讲我就围绕 MySQL 优化的点来一起聊聊。
为什么要对 MySQL 进行优化?
有一句俗话叫作“Web 项目即增删改查”,虽然这句话未必精确,但足以体现 Web 项目对数据的依赖程度,MySQL 数据库作为数据的重要载体,自然围绕着 MySQL 的优化也是必不可少的。而且对于一些发展中公司来说,往往项目初期数据量比较少,并没有把数据库优化列入日常的活动当中。当业务累积到足够的数据量时,会发现系统越来越慢,这时候数据库优化才引起重视,并投入大量的人力物力,当然不仅仅消耗的是企业成本,还会牺牲用户体验。
一次 SQL 的查询过程是怎样的?
简单来说,我们可以将这个过程概括为以下 5 步。
-
客户端发送一个查询 SQL 给数据库服务器。
-
服务器先检查查询缓存,如果命中,也就是查询缓存中有这条记录,那么便直接返回缓存中的结果。如果没有命中,则进入下一阶段(解析器)。
-
服务器由解析器检查 SQL 语法是否正确,然后由预处理器检查 SQL 中的表和字段是否存在,最后由查询器生成执行计划,也就是 SQL 的执行方式或者步骤。
-
MySQL 根据优化器生成的执行计划,调用存储引擎的 API 来执行查询。
-
将结果返回给客户端。
然后我们将上述步骤使用流程图展示,如下所示:

图 1:MySQL 查询过程
对于 MySQL 来说,影响性能的关键点有哪些?
关于这个问题,我想大家都应该可以回答一些,比如硬件层面、系统层面等等。但在性能领域中,一个不能忽略的问题是你需要考虑影响的面有多少,以及如何优化才是最具有性价比的。以我的经验来看,如何做优化更具性价比也存在漏斗模型,如图 2 所示。
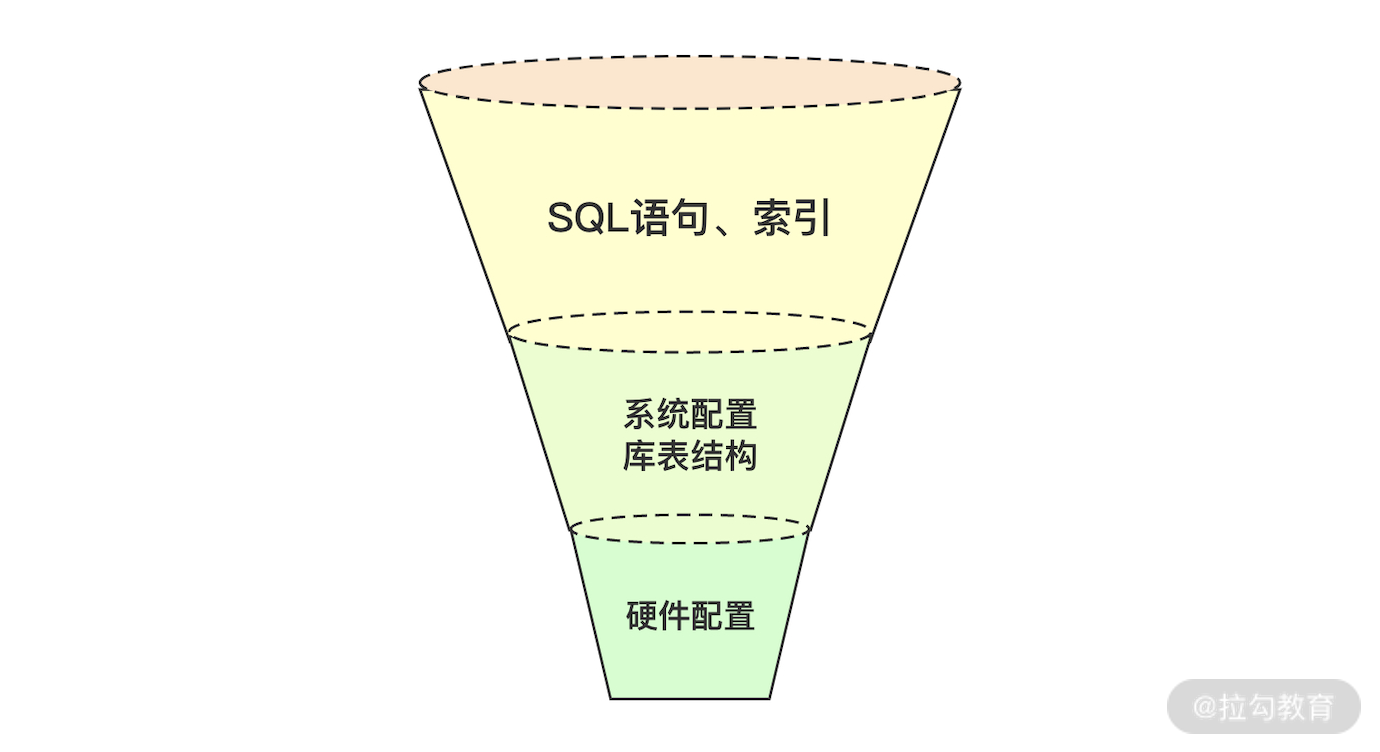
图 2:漏斗模型
从上往下看:
-
SQL 语句和索引相关问题是最常见的,带来的价值也是最明显的;
-
系统配置库表结构带来的价值次之;
-
而硬件层次的优化优先级是不高的。
1.硬件配置
现在我们基本上都是使用云服务器,就会涉及服务器配置选型,对于数据库处理复杂 SQL 而言,尽量选择高频 CPU,而且数据库一般都会开辟缓存池来存放数据,所以在服务器选型的时候内存大小也需要考虑。一般来说数据库服务器的硬件配置的重要性高于应用服务器配置,这方面了解下即可,测试工作基本上不会涉及数据库服务器的选型,而且一旦选型固定之后不会轻易改变数据库的硬件配置。
2.MySQL 系统配置选项
(1)max_connections
这个参数表示 MySQL 可以接收到的最大连接数,可以直接通过如下命令查看:
mysql> show variables like '%max_connections%';
+-----------------+-------+
| Variable_name | Value |
+-----------------+-------+
| max_connections | 151 |
+-----------------+-------+
那如何查看 MySQL 的实际连接数呢?我们可以用如下命令进行查看:
mysql> show status like 'Threads%';
+-------------------+-------+
| Variable_name | Value |
+-------------------+-------+
| Threads_cached | 7 |
| Threads_connected | 64 |
| Threads_created | 1705 |
| Threads_running | 1 |
+-------------------+-------+
其中 Threads_connected 是你实际的连接数。如果 max_connections 的值设置较小,在高并发的情况下易出现 “too many connections” 这样的报错,我们可以通过如下命令调节配置从而减少此问题的发生,你可以根据所在公司的实际情况进行配置。
mysql> set global max_connections=500;
(2)innodb_buffer_pool_size
这个参数实际定义了 InnoDB 存储引擎下 MySQL 的内存缓冲区大小。
来解释下这句话什么意思,首先 InnoDB 存储引擎是 MySQL 的默认存储引擎,使用也很广泛。缓冲池是什么呢?其实就和缓存类似,通过上一讲学习你可以知道,从磁盘读取数据效率是很低的,为了避免这个问题,MySQL 开辟了基于内存的缓冲池,核心做法就是把经常请求的热数据放入池中,如果请求交互的数据都在缓冲池中则会很高效,所以一般数据库缓冲池设置得会比较大,占到操作系统内存值的 70%~80%。
那如何评估缓冲池大小是否合理?
我们可以通过计算缓存命中率来判断,公式为:
(1-innodb_buffer_pool_reads/innodb_buffer_pool_read_request) * 100
一般来说,当缓存命中率低于 90% 就说明需要加大缓冲池了。
关于公式中的两个变量的查看方式,通过如下命令你就可以获得:
show status like 'Innodb_buffer_pool_read_%';
+---------------------------------------+----------+
| Variable_name | Value |
+---------------------------------------+----------+
| Innodb_buffer_pool_read_ahead_rnd | 0 |
| Innodb_buffer_pool_read_ahead | 51 |
| Innodb_buffer_pool_read_ahead_evicted | 0 |
| Innodb_buffer_pool_read_requests | 25688179 |
| Innodb_buffer_pool_reads | 2171 |
+---------------------------------------+----------+
3.SQL 优化
对于成熟的互联网公司来说,不管是硬件还是配置层面的数值都已经优化且形成了一定的经验值,其实不太可能频繁地改动。而对于业务的 SQL 来说,每天都会更新,一旦 SQL 本身执行很慢,无论从配置或者是硬件进行优化都无法根本解决问题。SQL 的问题也是你做数据库调优接触最多的,也是多样化的,所以接下来我们就继续学习慢 SQL 相关的知识点。
(1)什么是慢 SQL?
从默认定义上来讲,执行超过 10s 的 SQL 都被定义为慢 SQL。不过对于互联网应用来讲,10s 的时间标准过于宽松,如果是比较热门的应用 10s 都不能返回结果,基本可以定义为事故了,所以很多企业都会修改这个配置。先来看下怎么查看慢查询配置的时间,如下命令示意,你可以看到默认的配置是 10s。
mysql> show variables like 'long_query_time';
+-----------------+-----------+
| Variable_name | Value |
+-----------------+-----------+
| long_query_time | 10.000000 |
如果需要修改该配置为 1s,可以在 my.cnf 中添加,这样的方式需要重启 MySQL 服务。
long_query_time=1
(2)如何获取慢 SQL?
你在分析慢 SQL 之前首先需要获取慢 SQL,如何获取慢 SQL 呢,其中的一种方式是在 my.cnf 中配置,如下示意:
slow_query_log=1
slow_query_log_file=/data/mysql-slow.log
你就可以将慢 SQL 写入相应的日志文件内。除了这个方法,在测试过程中,我也会使用 show full processlist 这个命令实时获取交互的 SQL,通过观察 state 状态以及 SQL 出现的频率也能判断出来是不是慢 SQL。
(3)如何分析慢 SQL?
关于慢 SQL,绝大多数原因都是 SQL 本身的问题,比如写的业务 SQL 不合理,返回了大量数据;表设计不合理需要多表的连接查询;索引的问题等。在我的经验当中,众多 SQL 问题中索引相关的问题也是最突出的,在我看来索引的相关问题有以下几种。
索引缺失
首先来看看什么是索引,索引是一种单独地、物理地对数据库表中一列或者多列进行排序的数据库结构。索引的作用相当于图书的目录,可以根据目录的页码快速找到所需要的内容。当数据库存在大量数据做查询操作,你就需要 check 是否存在索引,如果没有索引,会非常影响查询速度。
在 InnoDB 中,我们可以简单地把索引分成两种:聚簇索引(主键)和普通索引。按照我的理解来看,聚簇索引是叶子节点保存了数据,而普通索引的叶子节点保存的是数据地址。
通常推荐在区分度较高的字段上创建索引,这样效果比较好,比如,一个会员系统中,给用户名建索引,查询时候可以快速定位到要找的数据,而给性别字段建索引则没有意义。
索引失效
添加索引只是其中的一个必要步骤,并不是添加完成后就万事大吉了。在一些情况下索引其实是不生效的,比如索引列中存在 Null 值、重复数据较多的列、前导模糊查询不能利用索引(like '%XX' 或者 like '%XX%')等。在一般情况下你可以使用执行计划查看索引是否真正生效,在下一讲中,我也会用更多的实例带你看这个问题。
联合索引不满足最左前缀原则
又来新概念了,有两个问题:
-
什么是联合索引;
-
什么又是最左前缀。
首先来解释下联合索引,用大白话解释就是一个索引会同时对应多个列,比如 c1、c2、c3 为三个字段,则可以通过 index_name(c1,c2,c3) 的方式建立联合索引,这样做的好处是什么呢?通过这样的方式建立索引,等于为 c1、(c1,c2)、(c1,c2,c3) 都建立了索引。因为每增加一个索引,也会增加写操作的磁盘开销,所以说联合索引是一种性价比比较高的建立索引的方式。
那么什么是最左前缀原则呢?你刚刚在 c1、c2、c3 上建立了联合索引,索引中的数据也是按 c1、c2、c3 进行排序,最左前缀顾名思义就是最左边的优先,比如如下 SQL 命令:
SELECT * FROM table WHERE c1="1" AND c2="2" AND c3="3"
这条 SQL 就会按照从左到右的匹配规则,如果打破最左前缀规则联合索引是不生效的,如下写法所示:
SELECT * FROM table WHERE c1="1" AND c3="3"
那如何判断 SQL 有没有走索引或者索引有没有生效呢?接下来我们要了解一个新概念叫作执行计划,什么是执行计划呢?
执行计划通常是开发者拿到慢 SQL 之后,优化 SQL 语句的第一步。MySQL 在解析 SQL 语句时,会生成多套执行方案,然后内部会进行一个成本的计算,通过优化器选择一个最优的方案执行,然后根据这个方案会生成一个执行计划。开发者通过查看 SQL 语句的执行计划,可以直观地了解到 MySQL 是如何解析执行这条 SQL 语句的,然后再针对性地进行优化。
(4)如何查看 SQL 语句的执行计划?
我们可以在执行 SQL 的前面添加 desc,如下所示:
desc select * from user
或者添加 explain,如下所示:
mysql> explain select * from user;
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------+
| 1 | SIMPLE | user | NULL | ALL | NULL | NULL | NULL | NULL | 9984 | 100.00 | NULL |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------+
1 row in set, 1 warning (0.01 sec)
对于 explain 返回的内容我选择一些重点解释一下,尤其是对性能产生不利的表现内容。
table
table 显示的是这一行的数据是关于哪张表的,上述内容中显示的表名就是 user。
type
这是重要的列,显示连接使用了何种类型,类型还是蛮多的,我选择最不理想的 ALL 类型和你解释一下,这个连接类型对于查询的表进行全表数据扫描,这种情况比较糟糕,应该尽量避免,上面的示例就进行了全表扫描。
key
key 表示实际使用的索引。如果为 Null,则没有使用索引,这种情况也是尤其需要注意的。
rows
rows 表明 SQL 返回请求数据的行数,这一行非常重要,返回的内容中 SQL 遍历了 9984 行,其实也证明了这条 SQL 遍历了一张表。
extra
关于 extra,我列举两个你需要注意的状态,因为这样的状态是会对性能产生不良的影响,意味着查询需要优化了。
**Using filesort:**表示****SQL 需要进行额外的步骤来发现如何对返回的行排序。它会根据连接类型、存储排序键值和匹配条件的全部行进行排序。
**Using temporary:**表示****MySQL 需要创建一个临时表来存储结果,非常消耗性能。
总结
本讲相对系统地讲述了常见的 MySQL 数据库性能影响点,你可以从一个全局的角度去思考诊断 MySQL 性能问题的步骤,同时我也讲了执行计划,通过执行计划可以发现 SQL 性能问题产生的原因,这是一个非常实用的手段。
你所在的公司有没有遇到过数据库的性能问题,是怎么发现和解决的?欢迎在留言区与我分享。
下一讲我会带你继续使用执行计划带你学习导致慢 SQL 最频发的索引问题,进一步用实例来帮助你分析 SQL 索引使用常见的误区,到时见。
如何根治慢 SQL?
上节课带你学习了 MySQL 优化的整体思路,我们将优化策略逐渐进到了索引层面,性能优化其实也是这样,一般大处着眼,小处着手。这节课我将从更多的实例出发诊断 SQL 相关的问题,你可以认为是第 18 讲的补充和进阶。
show full processlist
上一讲已经提到过在你诊断 SQL 之前,首先要知道的是如何获取这些有问题的 SQL,一般有两种方式可以获取:
-
从慢日志文件中获取,上一讲也描述过配置方法;
-
通过 show full processlist 实时获取交互的 SQL。
有同学留言说不知道具体应该如何使用 show full processlist,所以这里我演示下该命令的具体用法。show full processlist 可以显示哪些 SQL 线程正在运行,也可以在 MySQL 交互行下直接运行,来看下这个命令会给你展现哪些信息。
mysql> show full processlist;
+--------+---------+---------------------+----------------+---------+------+----------+-----------------------+
| Id | User | Host | db | Command | Time | State | Info |
+--------+---------+---------------------+----------------+---------+------+----------+-----------------------+
| 121553 | root | localhost | mall | Sleep | 48 | | NULL |
| 139421 | netdata | localhost | NULL | Sleep | 1 | | NULL |
| 140236 | root | localhost | cctester | Sleep | 1778 | | NULL
我们来解释下信息中每列的含义。
-
ID:作为一个标识 ID,如果你打算 kill 一个 SQL,可以根据 ID 来进行。
-
User:当前正在执行 SQL 的用户,只显示你登录账号权限范围内能够看到的用户。
-
Host:显示这个语句是从哪个 ID 和端口上发出的。
-
db:当前线程使用的库名。
-
Command:连接执行的命令状态,一般是 Sleep、Query、Connect 等。
-
Time:状态持续的时间(单位是秒)。
-
State:显示当前 SQL 语句的状态,这是一个非常重要的判断标识,比如多次刷新命令时,发现 SQL 常处于 Sending data,那么这条 SQL 大概率是存在问题的。
-
Info:显示正在执行的 SQL 语句,这也是你能直接拿到慢 SQL 的方式。
实例对比:索引对性能的影响
关于索引的基本作用通过《18 | 如何才能优化 MySQL 性能?》的内容相信你已经了解,而在性能层面更直观的影响,我想通过对比实验结果也许会更清晰一点。
我们新建了一个 user 表,表结构如下:
mysql> desc user;
+-------------+--------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------------+--------------+------+-----+---------+-------+
| id | int(11) | NO | | NULL | |
| Name | varchar(18) | YES | | NULL | |
| password | varchar(20) | YES | | NULL | |
| description | varchar(100) | YES | | NULL | |
+-------------+--------------+------+-----+---------+-------+
通过查看表信息,你可以发现我并没有添加索引,接着我使用 10 个线程测试一条SQL,其中SQL内容是通过 ID 号来查看数据,性能结果表现如下:

在 ID 列添加索引后继续基于同一条 SQL ,进行 10 线程压测,结果数据如下:

从测试结果来看,在未添加索引的情况下,TPS 是 109.4,而添加逐渐索引后,同等压力下 TPS 达到了 240.2。
CPU 资源占用如下所示:
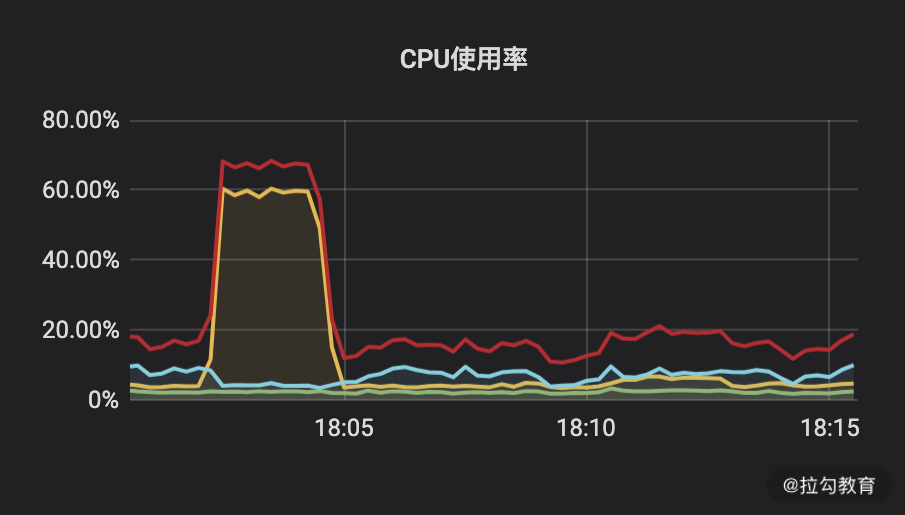
CPU 使用率图
红线:Total
黄线:User
蓝色:Iowait
绿线:System
在未添加索引的情况下,在 18:05 之前有 CPU 使用飙高,在添加索引后我在 18:10 基于同一场景测试,你会发现服务端资源使用率较低,而且 TPS 还翻了一倍以上。
通过这样一段对比,相信你能非常直观地感觉到索引带来的性能差别。
那我们是不是添加了索引就万事大吉呢,其实不是这样的,索引也有效率之分,也会存在索引失效等情况,接下来我就结合上一节课讲的执行计划来判断索引使用是否合理。有了执行计划我认为绝大多数 SQL 的问题你都可以找到优化的方向,而且对于我来说执行计划带来的直接好处是并不需要进行专门的性能测试就可以提前发现慢 SQL。
继续通过执行计划来看索引的使用技巧
1.索引覆盖
什么是索引覆盖?
走索引查询数据时,如果该索引已经包含需要的数据,则称之为索引覆盖。若索引中不能拿到想要的数据,则需要通过主键拿一整行数据,这个过程叫回表,需要一次 IO 操作,所以我们写 SQL 时尽量使用索引覆盖,降低 IO 开销。
如何判断是否是索引覆盖?
通过 extra 判断是否显示 Using index,如下示例所示:
mysql> show create table cctester \G;
*************************** 1. row ***************************
Table: cctester
Create Table: CREATE TABLE `cctester` (
`id` int(11) NOT NULL,
`name` varchar(11) DEFAULT NULL,
`mobile` bigint(20) DEFAULT NULL,
`score` int(11) DEFAULT NULL,
`subject` varchar(20) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `idx_name` (`name`),
KEY `idx_subject` (`subject`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4
1 row in set (0.21 sec)
//上述这是表结构
mysql> desc select name from cctester where name ="cc";
+----+-------------+----------+------------+------+---------------+----------+---------+-------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+----------+------------+------+---------------+----------+---------+-------+------+----------+-------------+
| 1 | SIMPLE | cctester | NULL | ref | idx_name | idx_name | 47 | const | 1 | 100.00 | Using index |
+----+-------------+----------+------------+------+---------------+----------+---------+-------+------+----------+-------------+
1 row in set, 1 warning (0.01 sec)
//上述是第一段执行计划
mysql> desc select name,score from cctester where name ="cc";
+----+-------------+----------+------------+------+---------------+----------+---------+-------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+----------+------------+------+---------------+----------+---------+-------+------+----------+-------+
| 1 | SIMPLE | cctester | NULL | ref | idx_name | idx_name | 47 | const | 1 | 100.00 | NULL |
+----+-------------+----------+------------+------+---------------+----------+---------+-------+------+----------+-------+
1 row in set, 1 warning (0.00 sec)
//上述是第二段执行计划
首先看下 cctester 表的结构,再观察下面两个 SQL 的执行计划对比,第一个 SQL 走 name 字段,只拿 name 字段内容,第一段执行计划显示了 Using index,说明索引覆盖了;而第二个 SQL 需要额外取 mobile 字段,所以需要回表,你也可以发现第二段执行计划 Extra 列返回的 NULL,所以没有用到索引覆盖,这些细小的差别都可以通过执行计划捕捉到。
2.联合索引
联合索引就是多个字段组成联合索引,在上一讲我们也讲过基本的作用和最左前缀规则。不过我发现一个误区,同样还是这样的一个示例 SQL,索引规则同样是 index_name(c1,c2,c3),下面这样的示例一定是符合最左前缀规则的:
SELECT * FROM table WHERE c1="1" AND c2="2" AND c3="3"
那么,我改变下 SQL 的查询顺序,如下所示:
SELECT * FROM table WHERE c2="2" AND c3="3" AND c1="1"
请问这样还满足最左前缀规则吗?对于 AND 这样的情况,可能很多同学觉得这个顺序和索引列不一致,应该是不满足最左前缀了,事实上不是这样的。
不管你是使用 (c1,c2,c3) 或者是 (c2,c3,c1),都是使用了联合索引,虽然表面上 (c2,c3,c1) 不符合最左前缀规则,但是 MySQL 本身是有查询优化器,它会确定这条 SQL 根据联合索引的字段顺序,最后再确定执行计划。所以说在查询字段满足条件的情况下字段顺序查询优化器是可以帮助你“纠正”的,在你项目实操过程中,对最左前缀的理解不要只局限于字面,如果你不确定可以通过执行计划来判断。
上面我举的例子是 SQL 中查询条件进行 AND 连接,看上去比较简单,我再讲一个联合索引的常用场景,看下面这样一个案例:
mysql> desc select name,subject,score from cctester where subject = 'english' order by score;
+----+-------------+----------+------------+------+---------------+------+---------+------+------+----------+-----------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+----------+------------+------+---------------+------+---------+------+------+----------+-----------------------------+
| 1 | SIMPLE | cctester | NULL | ALL | idx_subject | NULL | NULL | NULL | 6 | 50.00 | Using where; Using filesort |
+----+-------------+----------+------------+------+---------------+------+---------+------+------+----------+-----------------------------+
1 row in set, 1 warning (0.02 sec)
//以上是第一段执行计划
mysql> alter table cctester add index idx_subject_score_name(subject,score,name);
Query OK, 0 rows affected (0.15 sec)
//以上添加联合索引
mysql> desc select name,subject,score from cctester where subject = 'english' order by score;
+----+-------------+----------+------------+------+------------------------------------+------------------------+---------+-------+------+----------+--------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+----------+------------+------+------------------------------------+------------------------+---------+-------+------+----------+--------------------------+
| 1 | SIMPLE | cctester | NULL | ref | idx_subject,idx_subject_score_name | idx_subject_score_name | 83 | const | 3 | 100.00 | Using where; Using index |
+----+-------------+----------+------------+------+------------------------------------+------------------------+---------+-------+------+----------+--------------------------+
//以上是第二段执行计划
这里还是基于 cctester 的表结构,根据 where 条件 subject 查询之后再根据 score 排序,第一段执行计划可以看到 SQL 没有用到索引且需要额外的排序,而第二段执行计划中 SQL 使用了联合索引且不用再排序。在原理上解释就是,(subject,score,name) 索引中根据 subject 定位到的数据已经根据 score 排好顺序了,不需要再排序,这种 order by 的场景是联合索引使用最经典的案例。
3.索引失效的场景
索引虽好,但不代表你建了这条索引就一定会被使用,下面我列举了常用的索引失效的情况,也是日常工作中常见的一些情况。
隐式类型转换
表结构中类型是 varchar,SQL 中用的 int,这是开发最常忽略的问题,如下示例所示:
(root@localhost) [t]> show create table t\G
*************************** 1. row ***************************
Table: t
Create Table: CREATE TABLE `t` (
`id` int(11) NOT NULL,
`name` varchar(11) DEFAULT NULL,
`score` varchar(11) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `idx_name` (`name`),
KEY `idx_score` (`score`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4
1 row in set (0.00 sec)
//以上是建表语句
(root@localhost) [t]> desc select * from t where socre = '99';
+----+-------------+-------+------------+------+---------------+------------+---------+-------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------------+---------+-------+------+----------+-------+
| 1 | SIMPLE | t | NULL | ref | idx_score | idx_score | 47 | const | 2 | 100.00 | NULL |
+----+-------------+-------+------------+------+---------------+------------+---------+-------+------+----------+-------+
1 row in set, 1 warning (0.00 sec)
(root@localhost) [t]> desc select * from t where socre = 99;
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+
| 1 | SIMPLE | t | NULL | ALL | idx_score | NULL | NULL | NULL | 4 | 25.00 | Using where |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+
1 row in set, 3 warnings (0.00 sec)
观察上面例子可以发现,score 字段是 varchar 类型,当 SQL 中忘写单引号则走不到索引,接下来我继续讲解实例,我举的例子你不用过多考虑业务特性,单纯看索引问题即可。
模糊匹配开头
由于 MySQL 最左匹配原则,所以查询条件模糊开头无法命中索引,如下所示:
(root@localhost) [t]> desc select * from t where score like '%9';
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+
| 1 | SIMPLE | t | NULL | ALL | NULL | NULL | NULL | NULL | 4 | 25.00 | Using where |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+
1 row in set, 1 warning (0.00 sec)
通过执行计划你会发现上面的情况并没有命中索引。
or 不同条件
从上面建表结构中我们可以看到 name 字段和 score 字段都有索引,但直接写 or 查询两个字段无法使用索引,这种场景,我们可以将 or 改写成 union 即可。通过如下实例的第一段和第二段执行计划中涉及的索引项就可以看出。
(root@localhost) [t]> desc select * from t where name = 'allen' or score = '456';
+----+-------------+-------+------------+------+---------------------+------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------------+------+---------+------+------+----------+-------------+
| 1 | SIMPLE | t | NULL | ALL | idx_name,idx_score | NULL | NULL | NULL | 4 | 43.75 | Using where |
+----+-------------+-------+------------+------+---------------------+------+---------+------+------+----------+-------------+
1 row in set, 1 warning (0.00 sec)
//第一段执行计划
(root@localhost) [t]> desc select * from t where name = 'allen' union all select * from t where score = '456';
+----+-------------+-------+------------+------+---------------+------------+---------+-------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------------+---------+-------+------+----------+-------+
| 1 | PRIMARY | t | NULL | ref | idx_name | idx_name | 47 | const | 1 | 100.00 | NULL |
| 2 | UNION | t | NULL | ref | idx_score | idx_score | 47 | const | 1 | 100.00 | NULL |
+----+-------------+-------+------------+------+---------------+------------+---------+-------+------+----------+-------+
2 rows in set, 1 warning (0.00 sec)
//第二段执行计划
总结
本讲从实际工作出发,以慢 SQL 中问题的重灾区索引为切入点,以执行计划为手段诊断了索引的常见问题,这些都是 SQL 优化中最常见的知识点,通过实例可以让你明白这些优化带来的好处。
你还见过哪些索引未生效的情况?欢迎在评论区给出你的思考。
下一节课我将带来结束篇:线上全链路性能实践总结,虽是作为最终的 ending,还是想给你带来更多的干货,到时见。
结束语 线上全链路性能测试实践总结
作为专栏的最后一篇,我想和你聊聊线上全链路性能测试。全链路性能测试是一个非常热门的话题,不少公司也在摸索实践,这篇就以我的经验来谈谈对线上全链路性能测试的认知和实践的总结。
线上全链路性能测试提出的背景
按照我的认知,线上全链路性能测试是由阿里巴巴在 2012 年双 11 之后首次提出来的,因为当年的双 11 用户访问高峰时期系统成功率只有 50%,对于阿里同学来说,那应该是心情很沉重的双 11,复盘后发现其中的一块网卡被打满,在线下的性能测试环境中并没有发现这个问题。
为什么呢,说白了线下的压测理论上都是“缩容”测试,什么是缩容呢,就是服务器数量或者硬件配置是远低于线上的,规模容量是缩小了很多的。这导致了一些问题并不能充分被发现,实际访问量也不能很好被预估。在这样的问题背景下,线上的全链路性能测试就被提出来了。其实这和我开篇的一个观点是一致的,性能测试体系能够发展迅速,往往是公司各种大促的血泪史催化出来的,风险控制往往也能够带来最直接的生产力。
什么是线上全链路性能测试?
线上全链路性能测试就是基于真实的业务场景,实际线上环境,模拟多线程对各个业务链路进行压力测试的过程。
很多人提出了一个问题,有了线上全链路测试还需要线下性能测试吗?关于这个问题我也回答过,线上线下的性能测试理论上应当是互补的关系,线下往往权限充足而且不会对生产环境产生影响,可以发现更多的基本性能问题以及各类异常性能场景的测试,而线上是最真实的环境,对于性能验收的准确性至关重要。
什么样的情况适合全链路性能测试?
我并不认为所有的公司都适合直接进行线上性能测试,罗马不是一天建成,性能测试成熟的公司基本都经历了一段血泪史,是以一定的代价换的,对于线上全链路的开展我觉得需要几个前提:
1.已经在性能环境下进行过性能测试,但线上依然存在性能事故;
2.有频繁的促销需求,每次大促业务规则变化多;
3.对硬件成本较为敏感,需要进行容量测试,验证扩容缩容后的系统处理能力。
线上全链路性能测试聚焦的目的
相信你已经在线下进行过多轮的测试验证,线上的性能测试绝不是让你再去一遍遍执行发现基础的性能问题,线上性能测试的核心目的是验证系统的容量、部署结构的优化空间、整体线上的稳定性。
线上全链路性能测试实施重要前提
1.评估线上全链路压测的可行性
最核心要思考的点是能不能做到压测数据的隔离,所谓数据隔离你应该能够想到的就是数据库中压测数据不能跟真实的数据混在一起,从而无法区分,比如用户数据、下单商品数据等。通用的做法是先对数据进行打标,打标的意思就是做标记,比如压测数据都会有一个能够区别于真实业务的标识,比如加 header,比如用户名基于相同的 test 开头的标记,一般对于数据隔离的方案有两种。
(1)标记清理
第一种做法就是把标记的数据进行删除,一般在压测完成之后根据标识统一清理数据,所以做标记是一个重要前提,还有个前提是你需要整理清楚涉及哪些库表,有没有依赖关系,并且做到和开发以及 DBA 确认,这样删除数据更安全。
(2)影子库表
什么是影子库表呢?简单来说就是做一个和生产一样的库表,然后把压测数据加入影子库表,这样的做法相对于清理数据的方式,后期的事情会少一点,并不需要每次都一定要清理数据。这样的做法也有一些注意点,影子库表并不是仅仅建一个空的库表,它也需要你将生产数据迁移,还有这样的做法前期工作量会大一点,需要进行中间件改造自动识别压测流量才能进入影子库表。
这两种方式各有千秋,可以根据公司的业务特性做具体的方案落地。
2.对业务场景梳理
理清核心链路流程,线上有很多的接口,所谓线上的全链路性能测试也不会把所有的接口纳入测试范围当中。我的做法是先理清楚核心的业务模块,你必须要对你的业务模块有最基本的感知,哪些是核心模块,哪些是非核心,下面我罗列一个电商基本的业务模块图。
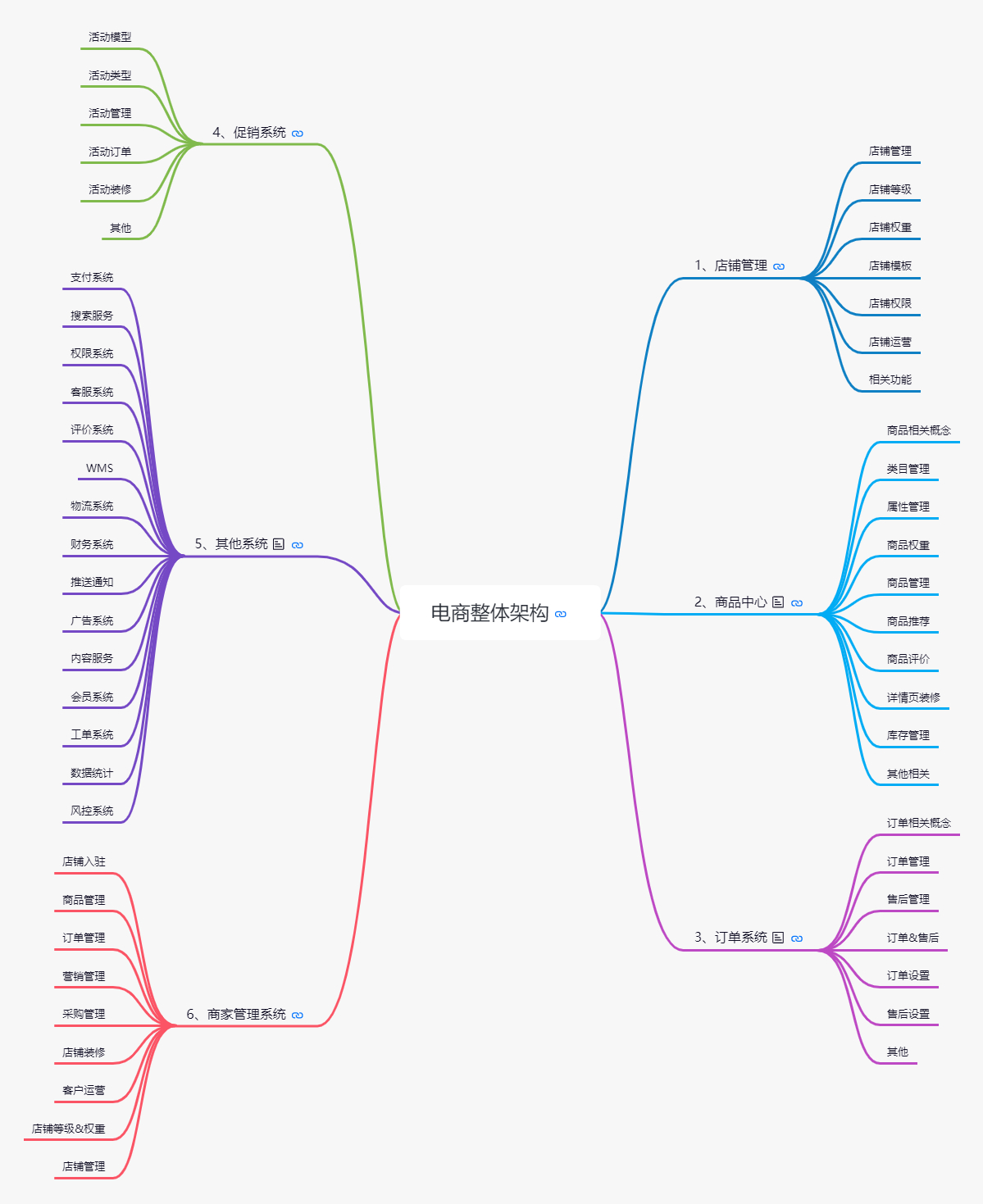
你可以看到仅文字描述的功能就已经非常多了,如果再去细分接口,可能一张图表都放不下。你首先要考虑的就是在这些模块中,哪些是不用进行全链路性能测试的,比如类似于商家管理系统,这本身是后台系统,并不直接面向用户。同样在你确定需要测试的性能模块中进一步确定哪些接口需要进行性能测试,关于细分到接口的选择我一般将大促时的访问数据进行参考,具体的方法《07 | 你真的知道如何制定性能测试的目标吗?》也有所提及。
3.理清数据传输链路
什么是数据传输链路呢?可以想象一下你在线下压测的场景,是不是内网环境从你的压测机就直接到服务暴露出的访问接口。而线上的链路可能远比这个复杂得多,比如数据是不是首先经过防火墙、硬件层的负载均衡等,你需要把这些链路也理清楚,说白了就是要理清线上的部署架构。这也是性能测试需求分析的步骤,防火墙之类的底层结构是不会轻易变动的,但对于线上实际的应用部署节点可能变动就很多了,我们会针对不同的应用节点部署结构和数量经常调整,所以在压测之前需要前置好这些条件并记录清楚。
线上全链路性能测试实施要点
首先需要表明一些观点,很多测试人员在实际测试过程中要么是自己造数据构造场景,如果遇到一些需要开发配合的可能会被直接打回,在线上的全链路性能测试过程中可以说系统改造是必需的,线上全链路性能测试也是多团队协作完成的,并不是测试人员的“独角戏”。
很多测试同学在进行线下性能测试时,几乎是一个人完成所有的活动,包括编写脚本、压测、监控、分析等等。在开展线上全链路的时候,可能会把这一套也继续沿用,这其实是一个误区,我认为线上的性能测试相对于线下至少有三个特性。
1.时间敏感
怎么理解时间敏感呢?线上的性能测试一般都需要申请窗口期,并不是你个人决定压测就可以直接进行了,一般来说,绝大部分公司都是选择在凌晨进行,这样对实际用户的影响最小。就以测试同学来举例,线上的性能测试也有很多准备工作,测试之前会有很多试验性的工作,比如商品数据是否有效、用户 token 是否过期。一旦进行正式的压测环节,一般需要按照时间去分解任务,遇到问题讲究快速解决,需要最正确的人去做相关的任务协同,比如哪些服务集群、哪些中间件需要哪些人去监控,在有效的时间内以达到最高效率。
2.权限敏感
权限敏感很好理解,说白了你作为测试不可能像在性能测试环境一样具备充足的权限,比如可以在性能测试环境随时重启服务,增删改查数据等。作为测试在线上你不可能有这些权限,所以线上的性能测试并不是你可以自由发挥的。
3.高风险
说到高风险,通过其他两个特性也能看出来,如果风险不大,时间和权限自然也就没这么敏感了,所以基于风险较高,我们在线上全链路性能测试执行的时候,更希望有一个“项目经理”的角色,进行人员安排、任务同步、风险预警等,这样的角色需要深入了解性能流程以及系统的风险控制。
测试人员可以扮演的角色?
1.全链路性能测试执行者
作为一名测试执行者,你需要更关注测试本身的内容,那测试本身的内容有哪些呢?我以电商网站为例来说明,根据每家公司的业务或者体量的不同,具体的事物会有差别,但一些思路是可以借鉴的:
-
压测机环境准备,压测机分布式节点检查;
-
压测数据准备和检查,如会员数据、商品下单数据;
-
参数化文件切割;
-
脚本以及参数化文件分发;
-
测试场景执行以及指标收集和记载。
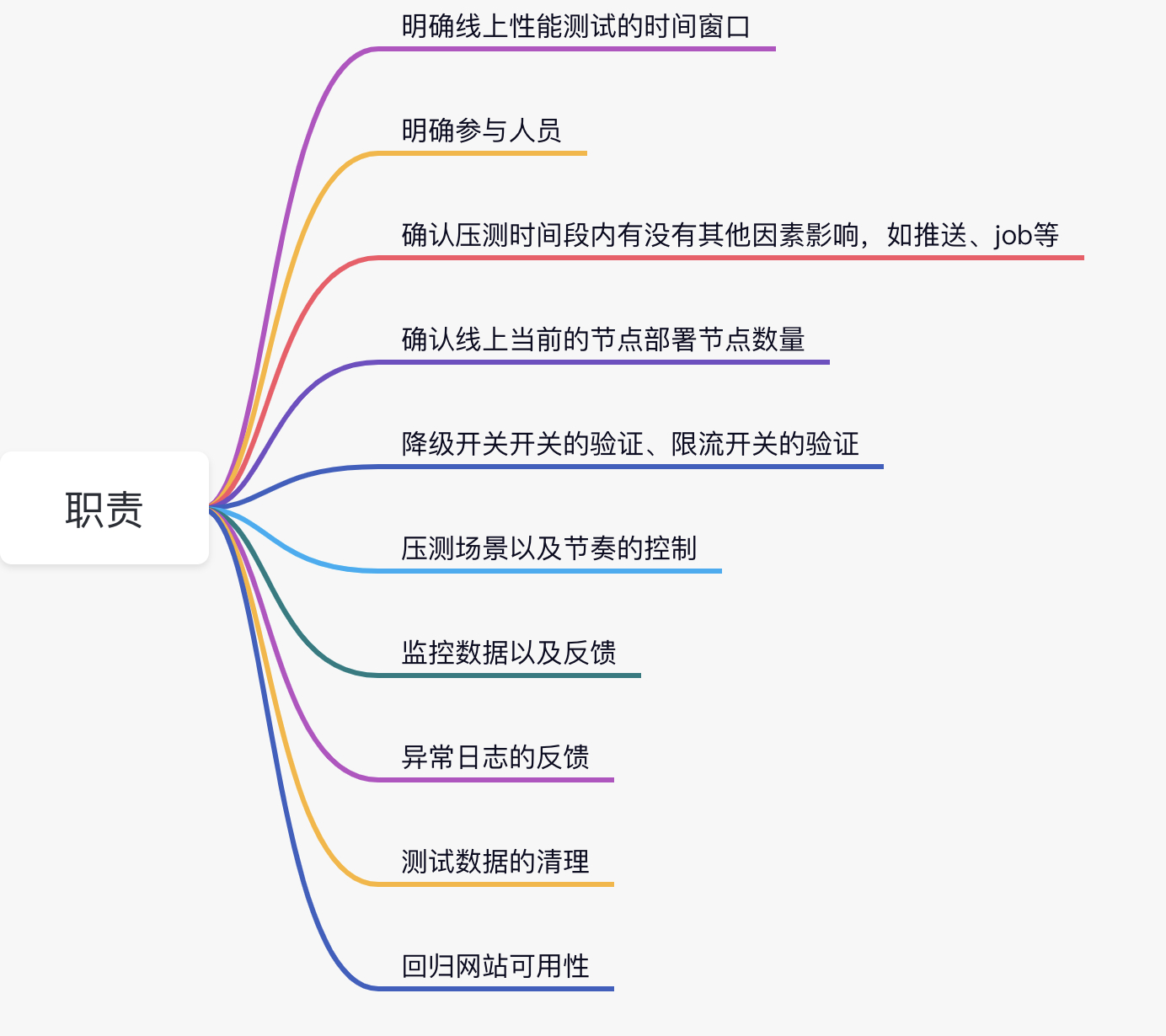
2.线上全链路测试的“项目经理”
我刚刚也说了线上的性能测试需要一名“项目经理”,很多人思维定式认为这位项目经理需要一定级别的 leader 来担任,其实并不完全是这样。以我的思路来看,性能测试一线经验丰富的同学来承担更适合,当然这位同学不仅仅需要性能经验丰富,也需要对架构以及业务有基本盘的认知,至少做到心中有底。
如果作为一个线上全链路压测实施的“项目经理”,你需要组织什么事情呢?我用一个思维导图罗列下。
线上全链路测试的风险
对于很多公司还是很忌惮在线上直接开始性能测试,因为觉得这样做风险太大了。这个担心是有道理的,阿里巴巴在刚刚提出这个议题时,内部也有很多不同的声音,一旦性能测试导致线上系统出现故障,轻则影响用户体验,重则系统不可用、真金白银的损失,任何人都不想为这个测试风险而买单。
虽然文章中列举了很多事项和注意点,但真正实施起来还是可能会遇到问题,所以线上性能测试的手段也是需要被测试的,比如先基于单条数据的打标、隔离、清理等,而且更需要的是发散性思维去思考,能不能把相关问题都考虑全面了,比如我之前的举例,对数据库进行数据隔离,那你有没有考虑到如 ES 数据、日志数据是否也需要做到有效的隔离呢?
监控预警
在线上全链路压测过程中,报警是非常重要的,出现意外情况可以及时终止压测,防止造成额外损失。报警的规则也是需要严格制定的,硬件的、系统的、业务的,包括响应延时等都应当设置相关的阈值等,第三模块有非常详细的描述,相信你应该对监控已经比较熟悉了。
总结
线上的全链路性能测试并不是高不可攀的技术,虽然有一定的技术门槛,但真正运作起来其实考验的是组织能力,线上全链路性能测试我认为是在线下专项性能测试上做的升级。这篇也是本专栏最终的收尾了,希望你能有所收获。
虽然本专栏已经结束了,但是后续我仍然会在微信公众号(软件测试架构师俱乐部)发表更多的知识,欢迎你来关注。
最后,我将邀请你为本专栏进行结课评价,你的每一个反馈,我和拉勾教育都会关注且认真对待。希望你能为自己的学习之旅画上一个完整的句号,点击链接,参与课程评价,编辑同学会随机抽 5 位同学送精美礼品。















 798
798











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











