









第39讲:从双十一看高可用的保障方式
从这一课时开始,专栏内容进入最后一个模块,即分布式高可用系列,这部分的内容,我将以电商大促为背景,讲解系统限流、降级熔断、负载均衡、稳定性指标、系统监控和日志系统等方面的内容。
今天一起来讨论一下,在面对电商大促、秒杀抢购等高并发的业务场景时,都有哪些高可用的保障手段。
从双十一限制退款说起
每年的电商大促活动,规模最大的就是双十一促销,双十一已经从光棍节,演变成了国内最大的电商促销活动。每年的双十一,我都会买一些打折力度比较大的商品,特别是数码产品,比如相机、键盘等,相信你肯定也和我一样,有很多“买买买”的经历。
类似双十一、618 这种促销活动,都会设置整点抢购。不知道你在双十一零点下单的过程中,有没有经历过排队等待,或者系统不可用的情况呢?
另外,细心的你可能已经发现了,历年的双十一活动,当天往往是不支持退款的,几大电商网站都会提前发布公告,对和订单无关的业务进行降级,比如订单退款。
上面这些,都是系统高可用的保障手段。以限制退款为例,一方面从业务角度考虑,由于活动期间流量巨大,订单产生数量过大,需要节省平台和商家的人力资源,节省库存盘点等工作;另一方面,退款处理并不是核心流程,在双十一当天,商家也没有这么多的资源来处理退款请求,在服务治理中,这是典型的业务降级,保护系统,对非核心业务做降级处理。
电商大促的高可用保障
电商大促高可用活动保障的核心是什么呢?当然是稳定性了。
大促是对系统架构的大考,稳定性是技术保障的核心,大公司内部都有严格的故障管理手段,以及故障评级制度,业务团队出现一个大的线上故障,可能一年的绩效都要受影响。
在服务治理中有一个服务可用性的概念,服务可用性是对服务等级协议 SLA 的描述,我们平时说的 4 个 9、5 个 9,就是 SLA。在实际业务中,即使是 4 个 9 的可用性,可能也不足以满足业务需求。我们来做一个简单的计算,假设一个核心链路依赖 10 个服务,这 10 个服务的可用性是 99.99%,那这个核心链路的可用性是 99.99% 的 10 次方,也就是 99.9%,可用性直接下降了一个等级,关联服务再多一些,可用性会更低。
这是一个理想的估算,在生产环境中,还要考虑服务发布、部署等导致的停机情况,可用性还会降低,如果是银行业、金融业等对可用性非常敏感的行业,这个数字是远远不够的。
回到电商大促,我们结合电商的业务场景,讨论一下在电商大促时,如果要保证高可用性,可以从哪些方面入手呢?
第一个特点是海量用户请求,万倍日常流量,大促期间的流量是平时的千百倍甚至万倍,从这一点来讲,要做好容量规划,在平时的演练中需做好调度。目前大部分公司的部署都是应用 Docker 容器化编排,分布式需要快速扩展集群,而容器化编排操作简单,可以快速扩展实例,可以说,容器化和分布式是天生一对,提供了一个很好的解决方案。
第二点是流量突增,是典型的秒杀系统请求曲线,我们都知道秒杀系统的流量是在瞬间达到一个峰值,流量曲线非常陡峭。为了吸引用户下单,电商大促一般都会安排若干场的秒杀抢购,为了应对这个特性,可以通过独立热点集群部署、消息队列削峰、相关活动商品预热缓存等方案来解决。
关于活动商品预热,这里简单展开说一下,秒杀活动都会提前给用户预告商品,为了避免抢购时服务不可用,我们可以提前把相关商品数据都加载到缓存中,通过缓存来支撑海量请求。
在模块六“分布式缓存”中,我花了很多篇幅对缓存的高可用、缓存命中率等知识点做了分享,你可以回顾并思考一下,秒杀活动中如何预热商品数据,可以更好地支撑前端请求?
最后一点是高并发,支撑海量用户请求,对于业务系统来说就是高并发,QPS 会是平时的几百倍甚至更高。开发经验比较多的同学都知道,如果在系统设计时没有考虑过高并发的情况,即使业务系统平时运行得好好的,如果并发量一旦增加,就会经常出现各种诡异的业务问题。比如,在电商业务中,可能会出现用户订单丢失、库存扣减异常、超卖等问题。
应对高并发,需要我们在前期系统设计时,考虑到并发系统容易出现的问题,比如在 Java 语言中,高并发时的 ThreadLocal 数据异常,数据库高并发的锁冲突、死锁等问题点,进行针对性的设计,避免出现业务异常。
可以看到,电商大促面临的问题主要是支撑高并发和高可用,高可用常见的手段有缓存、消息队列,关于这两部分的内容,我们在前面课时中也花了很大的篇幅去介绍,这里就不再赘述了。
另外还有一点在大促时特别重要,那就是避免服务雪崩问题、链路问题、故障传导。
关于服务雪崩我们在模块三“分布式服务”中简单提过,除了对服务可用性的追求,微服务架构一个绕不过去的问题就是服务雪崩。由于微服务调用通常是通过一个链路的形式进行,各个服务之间是一个调用链,牵一发而动全身,某个服务提供者宕机,可能导致整个链路上的连续失败,出现整体超时,最后可能导致业务系统停止服务。
避免服务雪崩问题,可以从限流、降级、熔断、隔离这几个方面入手,我喜欢称它们为高可用的 8 字箴言,在本模块后面的课时中,我将继续深入讨论这几个知识点。
总结
这一课时的内容,以双十一电商大促作为背景,总结了电商大促的业务特点,业务开发中保证稳定性的关键,并且简单介绍了高可用技术保障的几个常见手段,包括我们在前面讲解的消息队列技术、缓存技术,以及后面要展开讲解的限流、降级、熔断、隔离、负载均衡等手段。
在你的工作中,在对系统进行高可用设计时,都做了哪些工作呢?比如如何进行容量评估,超出系统水位如何进行限流和降级,使用了哪些高可用技术中间件呢?欢迎留言分享你的经验。
第40讲:高并发场景下如何实现系统限流?
在分布式高可用设计中,限流应该是应用最广泛的技术手段之一,今天一起来讨论一下,为什么需要限流,以及常见的限流算法都有哪些。
常见限流算法
限流是服务降级的一种手段,顾名思义,通过限制系统的流量,从而实现保护系统的目的。
合理的限流配置,需要了解系统的吞吐量,所以,限流一般需要结合容量规划和压测来进行。当外部请求接近或者达到系统的最大阈值时,触发限流,采取其他的手段进行降级,保护系统不被压垮。常见的降级策略包括延迟处理、拒绝服务、随机拒绝等。
限流后的策略,其实和 Java 并发编程中的线程池非常类似,我们都知道,线程池在任务满的情况下,可以配置不同的拒绝策略,比如:
-
AbortPolicy,会丢弃任务并抛出异常;
-
DiscardPolicy,丢弃任务,不抛出异常;
-
DiscardOldestPolicy 等,当然也可以自己实现拒绝策略。
Java 的线程池是开发中一个小的功能点,但是见微知著,也可以引申到系统的设计和架构上,将知识进行合理地迁移复用。
限流方案中有一点非常关键,那就是如何判断当前的流量已经达到我们设置的最大值,具体有不同的实现策略,下面进行简单分析。
计数器法
一般来说,我们进行限流时使用的是单位时间内的请求数,也就是平常说的 QPS,统计 QPS 最直接的想法就是实现一个计数器。
计数器法是限流算法里最简单的一种算法,我们假设一个接口限制 100 秒内的访问次数不能超过 10000 次,维护一个计数器,每次有新的请求过来,计数器加 1。这时候判断,如果计数器的值小于限流值,并且与上一次请求的时间间隔还在 100 秒内,允许请求通过,否则拒绝请求;如果超出了时间间隔,要将计数器清零。
下面的代码里使用 AtomicInteger 作为计数器,可以作为参考:
public class CounterLimiter {
//初始时间
private static long startTime = System.currentTimeMillis();
//初始计数值
private static final AtomicInteger ZERO = new AtomicInteger(0);
//时间窗口限制
private static final int interval = 10000;
//限制通过请求
private static int limit = 100;
//请求计数
private AtomicInteger requestCount = ZERO;
//获取限流
public boolean tryAcquire() {
long now = System.currentTimeMillis();
//在时间窗口内
if (now < startTime + interval) {
//判断是否超过最大请求
if (requestCount.get() < limit) {
requestCount.incrementAndGet();
return true;
}
return false;
} else {
//超时重置
requestCount = ZERO;
startTime = now;
return true;
}
}
}
计数器策略进行限流,可以从单点扩展到集群,适合应用在分布式环境中。单点限流使用内存即可,如果扩展到集群限流,可以用一个单独的存储节点,比如 Redis 或者 Memcached 来进行存储,在固定的时间间隔内设置过期时间,就可以统计集群流量,进行整体限流。
计数器策略有一个很大的缺点,是对临界流量不友好,限流不够平滑。假设这样一个场景,我们限制用户一分钟下单不超过 10 万次,现在在两个时间窗口的交汇点,前后一秒钟内,分别发送 10 万次请求。也就是说,窗口切换的这两秒钟内,系统接收了 20 万下单请求,这个峰值可能会超过系统阈值,影响服务稳定性。
对计数器算法的优化,就是避免出现两倍窗口限制的请求,可以使用滑动窗口算法实现,感兴趣的同学可以去了解一下。
漏桶和令牌桶算法
漏桶算法和令牌桶算法,在实际应用中更加广泛,也经常被拿来对比,所以我们放在一起进行分析。
漏桶算法可以用漏桶来对比,假设现在有一个固定容量的桶,底部钻一个小孔可以漏水,我们通过控制漏水的速度,来控制请求的处理,实现限流功能。
漏桶算法的拒绝策略很简单,如果外部请求超出当前阈值,则会在水桶里积蓄,一直到溢出,系统并不关心溢出的流量。漏桶算法是从出口处限制请求速率,并不存在上面计数器法的临界问题,请求曲线始终是平滑的。
漏桶算法的一个核心问题是,对请求的过滤太精准了,我们常说,水至清则无鱼,其实在限流里也是一样的, 我们限制每秒下单 10 万次,那 10 万零 1 次请求呢?是不是必须拒绝掉呢?
大部分业务场景下这个答案是否定的,虽然限流了,但还是希望系统允许一定的突发流量,这时候就需要令牌桶算法。
再来看一下令牌桶算法,在令牌桶算法中,假设我们有一个大小恒定的桶,这个桶的容量和设定的阈值有关,桶里放着很多令牌,通过一个固定的速率,往里边放入令牌,如果桶满了,就把令牌丢掉,最后桶中可以保存的最大令牌数永远不会超过桶的大小。
当有请求进入时,就尝试从桶里取走一个令牌,如果桶里是空的,那么这个请求就会被拒绝。
不知道你有没有应用过 Google 的 Guava 开源工具包,在 Guava 中,就有限流策略的工具类 RateLimiter,RateLimiter 基于令牌桶算法实现流量限制,使用非常方便。
RateLimiter 会按照一定的频率往桶里扔令牌,线程拿到令牌才能执行,RateLimter 的 API 可以直接应用,主要方法是 acquire 和 tryAcquire,acquire 会阻塞,tryAcquire 方法则是非阻塞的。下面是一个简单的示例:
public class LimiterTest {
public static void main(String[] args) throws InterruptedException {
//允许10个,permitsPerSecond
RateLimiter limiter = RateLimiter.create(100);
for(int i=1;i<200;i++){
if (limiter.tryAcquire(1)){
System.out.println("第"+i+"次请求成功");
}else{
System.out.println("第"+i+"次请求拒绝");
}
}
}
}
不同限流算法的比较
计数器算法实现比较简单,特别适合集群情况下使用,但是要考虑临界情况,可以应用滑动窗口策略进行优化,当然也是要看具体的限流场景。
漏桶算法和令牌桶算法,漏桶算法提供了比较严格的限流,令牌桶算法在限流之外,允许一定程度的突发流量。在实际开发中,我们并不需要这么精准地对流量进行控制,所以令牌桶算法的应用更多一些。
如果我们设置的流量峰值是 permitsPerSecond=N,也就是每秒钟的请求量,计数器算法会出现 2N 的流量,漏桶算法会始终限制N的流量,而令牌桶算法允许大于 N,但不会达到 2N 这么高的峰值。
关于这几种限流算法的扩展讨论,我之前在博客中也分析过,可以点击: 96秒破百亿,双11如何抗住高并发流量,作为补充阅读。
总结
这一课时总结了系统限流的常用策略,包括计数器法、漏桶算法、令牌桶算法。
在你的工作中,在对系统进行高可用设计时,都做了哪些工作呢?比如如何进行容量评估,超出系统水位如何进行限流,欢迎留言分享你的经验。
第41讲:降级和熔断:如何增强服务稳定性?
上一课时我们分析了限流的常用策略,下面来看一下,高可用的另外两大撒手锏:降级和熔断,关于这两种技术手段如何实施,又有哪些区别呢?
高可用之降级
我们在第 39 课时提过服务降级是电商大促等高并发场景的常见稳定性手段,那你有没有想过,为什么在大促时要开启降级,平时不去应用呢?
在大促场景下,请求量剧增,可我们的系统资源是有限的,服务器资源是企业的固定成本,这个成本不可能无限扩张,所以说,降级是解决系统资源不足和海量业务请求之间的矛盾。
降级的具体实现手段是,在暴增的流量请求下,对一些非核心流程业务、非关键业务,进行有策略的放弃,以此来释放系统资源,保证核心业务的正常运行。我们在第 34 课时中提过二八策略,换一个角度,服务降级就是尽量避免这种系统资源分配的不平衡,打破二八策略,让更多的机器资源,承载主要的业务请求。
就如同我们之前的例子中,电商大促时限制退款,但平时并不会限制,所以服务降级不是一个常态策略,而是应对非正常情况下的应急策略。服务降级的结果,通常是对一些业务请求,返回一个统一的结果,你可以理解为是一种 FailOver 快速失败的策略。
举个例子,我们都有在 12306 网站购票的经历,在早期春运抢票时,会有大量的购票者进入请求,如果火车票服务不能支撑,你想一想,是直接失败好呢,还是返回一个空的信息好呢?一般都会返回一个空的信息,这其实是一种限流后的策略,我们从一个广义的角度去理解,限流也是一种服务降级手段,是针对部分请求的降级。
一般来说,降级针对的目标,一般是业务闭环中的一些次要功能,比如大促时的评论、退款功能,从一致性的角度,因为强一致性的保证需要很多系统资源,降级可能会降低某些业务场景的一致性。
具体在进行服务降级操作时,要注意哪些点呢?首先需要注意梳理核心流程,知道哪些业务是可以被牺牲的,比如双十一大家都忙着抢购,这时候一些订单评论之类的边缘功能,就很少有人去使用。另外,要明确开启时间,在系统水位到达一定程度时开启。还记得我们在第 16 课时提到的分布式配置中心吗?降级一般是通过配置的形式,做成一个开关,在高并发的场景中打开开关,开启降级。
高可用之熔断
不知道你有没有股票投资的经验,在很多证券市场上,在大盘发生非常大幅度的波动时,为了保护投资者的利益,维护正常的市场秩序,会采取自动停盘机制,也就是我们常说的股市熔断。
在高可用设计中,也有熔断的技术手段,熔断模式保护的是业务系统不被外部大流量或者下游系统的异常而拖垮。
通过添加合理的熔断策略,可以防止系统不断地去请求可能超时和失败的下游业务,跳过下游服务的异常场景,防止被拖垮,也就是防止出现服务雪崩的情况。
熔断策略其实是一种熔断器模式,你可以想象一下家里应用的电路过载保护器,不过熔断器的设计要更复杂,一个设计完善的熔断策略,可以在下游服务异常时关闭调用,在下游服务恢复正常时,逐渐恢复流量。
下面我举一个例子,假设你开发了一个电商的订单服务,你的服务要依赖下游很多其他模块的服务,比如评论服务。现在有一个订单查询的场景,QPS 非常高,但是恰好评论服务因为某些原因部分机器宕机,出现大量调用失败的情况。如果没有熔断机制,订单系统可能会在失败后多次重试,最终导致大量请求阻塞,产生级联的失败,并且影响订单系统的上游服务,出现类似服务雪崩的问题,导致整个系统的响应变慢,可用性降低。
如果开启了熔断,订单服务可以在下游调用出现部分异常时,调节流量请求,比如在出现 10% 的失败后,减少 50% 的流量请求,如果继续出现 50% 的异常,则减少 80% 的流量请求;相应的,在检测的下游服务正常后,首先恢复 30% 的流量,然后是 50% 的流量,接下来是全部流量。
对于熔断策略的具体实现,我建议你查看 Alibaba Sentinel 或者 Netflix Hystrix 的设计,熔断器的实现其实是数据结构中有限状态机(Finite-state Machines,FSM)的一种应用,关于 FSM 的具体分析和应用,不是本课时的目标,因为 FSM 不光在算法领域有应用,在复杂系统设计时,为了更好的标识状态流转,用有限状态机来描述会特别清晰。
熔断器的恢复时间,也就是平均故障恢复时间,称为 MTTR,在稳定性设计中是一个常见的指标,在 Hystrix 的断路器设计中,有以下几个状态。
-
Closed:熔断器关闭状态,比如系统检测到下游失败到了 50% 的阈值,会开启熔断。
-
Open:熔断器打开状态,此时对下游的调用在内部直接返回错误,不发出请求,但是在一定的时间周期以后,会进入下一个半熔断状态。
-
Half-Open:半熔断状态,允许少量的服务请求,如果调用都成功(或一定比例)则认为恢复了,关闭熔断器,否则认为还没好,又回到熔断器打开状态。
在系统具体实现中,降级和熔断推荐使用成熟的中间件,包括 Sentinel 和 Hystrix,以及 resilience4j,关于这几种组件的应用细节,这里暂不做展开分析,我一直觉得,授人以鱼不如授人以渔,在解决了原理层面以后,如何实现就变得简单很多。
我在工作中应用 Sentinel 比较多,你可以在Sentinel 官网看到详细的介绍,下面是对这几种组件的对比,来自阿里巴巴 Sentinel 开发团队的分享,作为补充资料:
| Sentinel | Hystrix | resilience4j | |
|---|---|---|---|
| 隔离策略 | 信号量隔离(并发线程数限流) | 线程池隔离/信号量隔离 | 信号量隔离 |
| 熔断降级策略 | 基于响应时间、异常比率、异常数 | 基于异常比率 | 基于异常比率、响应时间 |
| 实时统计实现 | 滑动窗口(LeapArray) | 滑动窗口(基于 RxJava) | Ring Bit Buffer |
| 动态规则配置 | 支持多种数据源 | 支持多种数据源 | 有限支持 |
| 扩展性 | 多个扩展点 | 插件的形式 | 接口的形式 |
| 基于注解的支持 | 支持 | 支持 | 支持 |
| 限流 | 基于 QPS,支持基于调用关系的限流 | 有限的支持 | Rate Limiter |
| 流量整形 | 支持预热模式、匀速器模式、预热排队模式 | 不支持 | 简单的 Rate Limiter 模式 |
| 系统自适应保护 | 支持 | 不支持 | 不支持 |
| 控制台 | 提供开箱即用的控制台,可配置规则、查看秒级监控、机器发现等 | 简单的监控查看 | 不提供控制台,可对接其他监控系统 |
总结
以上就是这一课时的内容,和大家总结了降级和熔断的概念,应用场景和实现手段,通过一些应用实例进行了对比。
不知道你有没有发现,在系统设计中,特别是高可用模块,和生活里的一些博弈策略息息相关,不是一个纯技术领域的工作。比如在中国象棋策略中,有个成语叫作丢车保帅,和服务降级有异曲同工之妙,敌人已经攻打过来了,这时候是保护元帅不被将军,还是丢弃一些军备,下次还能卷土重来呢?而服务降级就是放弃一些非关键功能,保证整体系统的运行。
这一课时中,我也列举了股票熔断、漏电保护器等生活实例,希望大家可以扩展思考一下,高可用设计中的博弈在生活中有哪些体现,也欢迎留言分享你的观点。
第42讲:如何选择适合业务的负载均衡策略?
在分布式系统的高可用设计中,负载均衡非常关键,我们知道,分布式系统的特性之一就是支持快速扩展,那么集群扩展之后,服务请求如何从服务器列表中选择合适的一台呢?这就需要依赖负载均衡策略。
负载均衡在处理高并发,缓解网络压力,以及支持扩容等方面非常关键,在不同的应用场景下,可以选择不同的负载均衡,下面一起来看一下负载均衡相关的知识。
负载均衡的应用
负载均衡是指如何将网络请求派发到集群中的一个或多个节点上处理,一般来说,传统的负载均衡可以分为硬件负载均衡和软件负载均衡。
-
硬件负载均衡,就是通过专门的硬件来实现负载均衡,比如常见的 F5 设备。
-
软件负载均衡则是通过负载均衡软件实现,常见的就是 Nginx。
无论是硬件负载均衡还是软件负载均衡,实现原理都是一样的,在负载均衡中会记录一个可用的服务列表,负载均衡服务器会通过心跳机制来确认服务可用性,在网络请求到达后,F5 或者 Nginx 等负载均衡设备,会按照不同的策略,进行服务器的路由,这就是负载均衡的流程。
负载均衡的应用非常广,这一课时我们主要关注在分布式系统的请求调用,服务分发中的负载均衡。
常见的复杂均衡策略
一般而言,有以下几种常见的负载均衡策略。
轮询策略
轮询策略是最容易想到也是应用最广泛的负载均衡策略。轮询策略会顺序地从服务器列表中选择一个节点,请求会均匀地落在各个服务器上。轮询适合各个节点性能接近,并且没有状态的情况,但是在实际开发中,不同节点之间性能往往很难相同,这时候就可以应用另一种加权轮询策略。
加权轮询
加权轮询是对轮询策略的优化,给每个节点添加不同的权重。举个简单的例子,在实际开发中通常使用数组的数据结构来实现轮询,比如现在我有 A、B、C 三个节点,就可以在数组中添加 1、2、3 的数据,分别对应三个节点。现在我进行一个加权调整,让 1、2、3 对应 A,4、5 对应 B、C,这时候继续进行轮询,不同节点的权重就有变化了。
随机策略
随机策略和轮询相似,从列表中随机的取一个。我们都学过概率论的课程,真正的随机是很难实现的,所以如果访问量不是很大,最好不要应用随机策略,可能会导致请求不均匀。
最小响应时间
这个主要是在一些对请求延时敏感的场景中,在进行路由时,会优先发送给响应时间最小的节点。
最小并发数策略
你可以对比最小响应时间,最小并发策略会记录当前时刻每个节点正在处理的事务数,在路由时选择并发最小的节点。最小并发策略可以比较好地反应服务器运行情况,适用于对系统负载较为敏感的场景。
除了这些,还有哈希策略等,另外,在第 35 课时中我们提到过一致性哈希,其实一致性哈希也是一种负载均衡策略,一致性哈希经常应用在数据服务的路由中。
负载均衡如何实现
在分布式服务调用中,根据负载均衡实现的位置不同,可以分为服务端负载均衡和客户端负载均衡。
-
在服务器端负载均衡中,请求先发送到负载均衡服务器,然后通过负载均衡算法,在众多可用的服务器之中选择一个来处理请求。
-
在客户端负载均衡中,不需要额外的负载均衡软件,客户端自己维护服务器地址列表,自己选择请求的地址,通过负载均衡算法将请求发送至该服务器。
相信你已经看到了,这两种负载均衡,最大的区别就是服务器列表维护的位置。
下面我们来看一下,服务端负载均衡和客户端负载均衡如何实现呢?
在分布式服务调用中,服务端负载均衡常用的组件是 Spring Cloud Eureka,如果你选择了 Dubbo 作为中间件,那么可以应用 Dubbo 内置的路由策略。
在 Spring Cloud 中开启负载均衡的方法很简单,有一个专门的注解 @LoadBalanced 注解,配置这个注解之后,客户端在发起请求的时候会选择一个服务端,向该服务端发起请求,实现负载均衡。另外一种客户端负载均衡,也有对应的实现,典型的是 Spring Cloud Ribbon。
Ribbon 实际上是一个实现了 HTTP 的网络客户端,内置负载均衡工具、支持多种容错等。
我们上面提到的几种策略,在 Ribbon 中都有提供,包括 RoundRobinRule 轮询策略、RandomRule 随机策略、BestAvailableRule 最大可用策略、WeightedResponseTimeRule 带有加权的轮询策略等。
如果你的应用需要比较复杂的负载均衡场景,推荐应用 Ribbon,本课时的目的是讲解负载均衡被实现的原理,你可以到 Ribbon 的官方仓库,去了解相关的应用。
总结
以上就是本课时的内容了,我和大家一起讨论了负载均衡的应用场景、常见负载均衡策略,以及服务端和客户端负载均衡实现组件。
现在我们来思考一个问题,为什么说分布式高可用设计中,负载均衡很关键呢?我们都知道,在分布式场景下,特别是微服务拆分后,不同业务系统之间是解耦的,负载均衡策略,也就是描述了各个应用之间如何联系。
我们用订单场景来举例子,下单时依赖商品服务,假设我们选择的是轮询策略,当某台商品服务器出现网络故障、服务超时,此时下单就会受影响,如果改为最小可用时间策略,订单服务就会自动进行故障转移,不去请求超时的节点,实现高可用。
在你的工作中,应用过哪些负载均衡策略呢,又是如何进行配置的,欢迎留言进行分享~
第43讲:线上服务有哪些稳定性指标?
在分布式高可用设计中,系统监控非常重要,系统监控做好了,可以提前对异常情况进行报警,避免很多线上故障的产生。系统监控做得好不好,也是评价一家互联网公司基础建设水平的重要标准,今天一起来讨论一下,线上服务都有哪些监控指标,又应该如何展开呢?
系统监控的重要性
我的一个朋友是做底层开发工作的,包括内部数据库和微服务的中间件,前不久入职了一家互联网创业公司,这家公司虽然成立不久,但是业务发展很快。最近这几天他和我吐槽,公司的系统监控做得很差,线上经常有各种故障,不得不经常救火,工作非常疲惫。
听了这位朋友的感受,不知道你是否也有过类似的经历,系统监控等稳定性工作,看似离业务开发有点远,但其实是非常重要的,系统监控做得不好,开发人员需要花很多的时间去定位问题,而且很容易出现比较大的系统故障,所以越是在大公司里,对监控的重视程度就越高。
各种监控指标可以帮助我们了解服务运行水平,提前发现线上问题,避免小故障因为处理不及时,变成大故障,从而解放工程师的人力,我在之前的工作中,曾经专门做过一段时间的稳定性工作,现在把自己的一些经验分享给你。
在实际操作中,系统监控可以分为三个方面,分别是监控组件、监控指标、监控处理,在这一课时呢,我先和大家一起梳理下监控指标相关的知识,在接下来的第 44 课时,我将分享常用的监控组件,以及监控报警处理制度。

稳定性指标有哪些
稳定性指标,这里我按照自己的习惯,把它分为服务器指标、系统运行指标、基础组件指标和业务运行时指标。
每个分类下面我选择了部分比较有代表性的监控项,如果你还希望了解更多的监控指标,可以参考 Open-Falcon 的监控采集,地址为 Linux 运维基础采集项。
服务器监控指标
服务器指标主要关注的是虚拟机或者 Docker 环境的运行时状态,包括 CPU 繁忙程度、磁盘挂载、内存利用率等指标。
服务器是服务运行的宿主环境,如果宿主环境出问题,我们的服务很难保持稳定性,所以服务器监控是非常重要的。常见的服务器报警包括 CPU 利用率飙升、磁盘空间容量不足、内存打满等。
| 监控项 | 指标描述 |
|---|---|
| CPU 空闲时间 | 除硬盘 IO 等待时间以外其他等待时间,这个值越大,表示 CPU 越空闲 |
| CPU 繁忙程度 | 和 CPU 空闲时间相反 |
| CPU 负载 | CPU 负载(如果是 Docker,此指标收集物理机的 load)和 CPU 利用率监控 |
| CPU 的 iowait | 在一个采样周期内有百分之几的时间属于以下情况:CPU 空闲且有仍未完成的 I/O 请求 |
| CPU 的 system | CPU 用于运行内核态进程的时间比例 |
| CPU 的 user | CPU 用于运行用户态进程的时间比例 |
| load1 | 表示最近 1 分钟内运行队列中的平均进程数量 |
| load3 | 表示最近 5 分钟内运行队列中的平均进程数量 |
| load15 | 表示最近 15 分钟内运行队列中的平均进程数量(在 falcon 系统里) |
| 磁盘使用情况 | 磁盘使用情况,磁盘已用,未使用容量 |
服务器的指标,在实际配置中,需要根据服务器核心数不同,以及不同的业务特点配置不同的指标策略。比如,如果是一个日志型应用,需要大量的磁盘资源,就要把磁盘报警的阈值调低。
系统运行指标
系统指标主要监控服务运行时状态、JVM 指标等,这些监控项都可以在 Open-Falcon 等组件中找到,比如 JVM 的 block 线程数,具体在 Falcon 中指标是 jvm.thread.blocked.count。下面我只是列举了部分监控指标,具体的你可以根据自己工作中应用的监控组件来进行取舍。
| 监控项 | 指标描述 | 说明 |
|---|---|---|
| JVM 线程数 | 线程总数量 | 关注整体线程运行情况 |
| JVM 阶段线程增长 | 累计启动线程数量 | 线程应该尽量复用,因此不宜持续创建新线程 |
| JVM 死锁 | 死锁个数 | 线程死锁,一般都不能忍受 |
| JVM 的 block 线程数 | blocked 状态的线程数 | blocked 状态的线程过多,说明程序遭遇剧烈的锁竞争 |
| GC 的次数 | GC 的次数 | 垃圾回收的这几个指标,通常会综合来看,在进行调优时非常重要 |
| GC 时间 | GC 的时间 | |
| 年轻代 GC | 年轻代 GC 的次数 | |
| 老年代 GC 次数 | 年老代 GC 的次数 | |
| 老年代 GC 时间 | 年老代 GC 的时间 |
基础组件指标
在基础组件这里,主要包括对数据库、缓存、消息队列的监控,下面我以数据库为例进行描述,虽然各个中间件对数据库监控的侧重点不同,但是基本都会包括以下的监控项。如果你对这部分指标感兴趣,我建议你咨询一下公司里的 DBA 了解更多的细节。
| 监控项 | 指标描述 |
|---|---|
| 写入 QPS | 数据库写入 QPS |
| 数据库查询 QPS | 查询 QPS |
| 数据库的死锁 | 死锁处理不及时可能导致业务大量超时 |
| 数据库慢查询 QPS | 慢查询 QPS |
| 数据库的活跃连接数 | 数据库的活跃连接数 |
| 数据库的总连接数 | 数据库的总连接数 |
| 数据库 Buffer Pool 命中率 | 可能引起数据库服务抖动,业务系统不稳定 |
在进行数据库优化时要综合这部分指标,根据具体业务进行配置。
业务运行时指标
业务运行时指标和上面其他分类的指标是不同的,需要根据不同的业务场景来配置。
举个例子,你现在开发的是一个用户评论系统,那么就需要关注每天用户评论的请求数量、成功率、评论耗时等。业务指标的配置,需要结合各类监控组件,在指标的选择上,通常需要结合上下游各个链路,和产品设计、运营同学一起对齐,明确哪些是核心链路,并且进行指标的分级。
总结
这一课时讨论了系统监控的重要性,以及系统监控指标的分类,常见的监控指标及其含义。
对稳定性指标的了解,看起来是系统运维负责的工作,但实际上对开发同学也同样重要,打个比方,系统监控指标好像就是医院里体检时的各项化验数据,只有全面了解这些数据,才能更好地明确身体健康情况。
在你的工作中,是如何对稳定性监控指标进行配置的,在配置告警阈值时考虑了哪些因素,应用了哪些监控组件呢?欢迎留言进行分享。
第44讲:分布式下有哪些好用的监控组件?
在上一课时的内容中,分析了分布式系统下的线上服务监控的常用指标,那么在实际开发中,如何收集各个监控指标呢?线上出现告警之后,又如何快速处理呢?这一课时我们就来看下这两个问题。
常用监控组件
目前分布式系统常用的监控组件主要有 OpenFalcon、Nagios、Zabbix、CAT 等,下面一起来看看这几款组件的应用及相关特性。好钢要用在刀刃上,由于各类监控组件的应用和配置更偏向基础运维,所以本课时的目的是希望你对几种组件有个基本了解,不建议投入太多时间学习组件的配置细节。
OpenFalcon
Open-Falcon 是小米开源的一款企业级应用监控组件,在很多一线互联网公司都有应用,已经成为国内最流行的监控系统之一。
我们在上一课时中介绍的监控指标,Open-Falcon 都有支持,我个人觉得,Open-Falcon 是监控指标最完善的监控组件之一。Falcon有一个特点,它是第一个国内开发的大型开源监控系统,所以更适合国内互联网公司的应用场景,在使用上,Open-Falcon 也要比其他的监控组件更加灵活,关于Open-Falcon 的监控指标,你可以在官网上了解更多的信息:Open-Falcon 官网。
Zabbix
Zabbix 基于 Server-Client 架构,和 Nagios 一样,可以实现各种网络设备、服务器等状态的监控。Zabbix 的应用比较灵活,数据存储可以根据业务情况,使用不同的实现,比如 MySQL、Oracle 或 SQLite 等,Zabbix 的 Server 使用 C 语言实现,可视化界面基于 PHP 实现。
Zabbix 整体可以分为 Zabbix Server 和 Zabbix Client,即 Zabbix Agent,Zabbix对分布式支持友好,可以对各类监控指标进行集中展示和管理,并且有很好的扩展性,采用了微内核结构,可以根据需要,自己开发完善各类监控。
如果希望了解更多具体的应用,还可以去 Zabbix 官网了解相关的内容:ZABBIX 产品手册。
Nagios
Nagios(Nagios Ain’t Goona Insist on Saintood)是一款开源监控组件,和 Zabbix 等相比,Nagios 支持更丰富的监控设备,包括各类网络设备和服务器,并且对不同的操作系统都可以进行良好的兼容,支持 Windows 、Linux、VMware 和 Unix 的主机,另外对各类交换机、路由器等都有很好的支持。
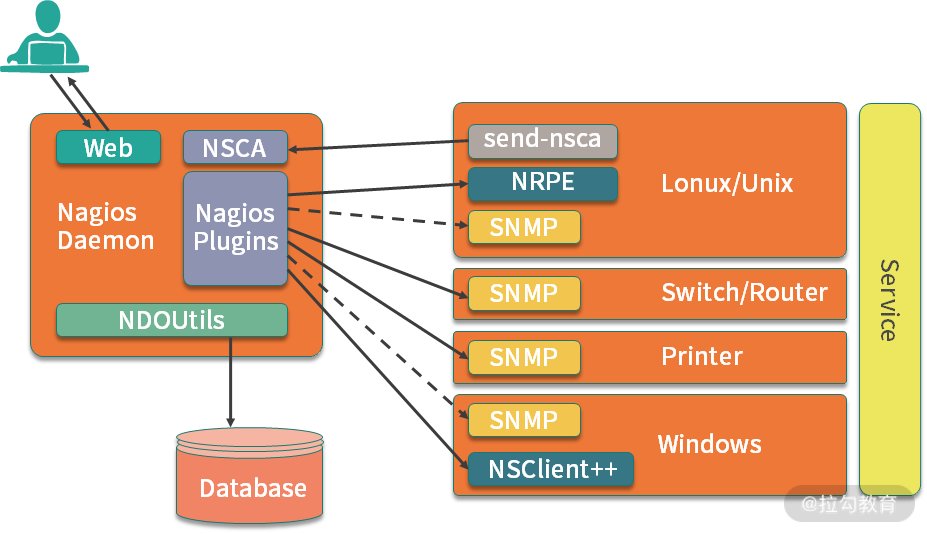
Nagios 对各类网络协议下的监控支持非常好,我们在第 42 课时提过硬件负载均衡的 F5 设备,就可以应用 Nagios 进行监控。
Nagios 虽然监控报警能力强大,但是配置比较复杂,各种功能都要依靠插件来实现,图形展示效果很差。从这个角度来看,Nagios 的应用更加偏向运维,大部分业务开发同学在工作中简单了解就可以。
Nagios 还可以监控网络服务,包括 SMTP、POP3、HTTP、NNTP、PING 等,支持主机运行状态、自定义服务检查,可以进行系统状态和故障历史的查看,另外,使用 Nagios 可以自定义各种插件实现定制化的功能。感兴趣的同学可点击这里查看官网了解一下。
CAT
CAT(Central Application Tracking)早期是大众点评内部的监控组件,2014 年开源,并且在携程、陆金所、猎聘网等大型互联网公司内部广泛应用。
CAT 基于 Java 开发,特别适合 Java 技术栈的公司,对分布式系统支持非常好。在社区开源以后,CAT 又加入了很多特性功能,已经成为一个大而全的应用层统一监控组件,对各类分布式服务中间件、数据库代理层、缓存和消息队列都有很好的支持,可以为业务开发提供各个系统的性能指标、健康状况,并且还可以进行实时告警。
相比其他偏向运维的监控组件,比如 Nagios、Cat 更加关注应用层面的监控指标,支持性能埋点和优化,对开发工程师更加友好。我在工作中和 CAT 打交道比较多,比较推荐这款监控组件,大家有机会可以在自己的公司里推广使用。
点击这里查看 CAT 项目的开源地址,由于篇幅所限,这里只做简单介绍,另外附上点评技术团队发表的技术文章:
监控处理制度
大型互联网公司都非常重视服务稳定性工作,因为服务稳定性直接影响用户体验,影响公司产品在用户心中的口碑,线上服务稳定性是开发者需要重点关注的,那么如何处理线上告警,出现报警如何第一时间处理呢?
一般来说,线上故障处理有下面几个原则:
-
发现故障,第一时间同步到相关业务负责人,上下游链路;
-
第一时间快速恢复业务,快速进行故障止血;
-
及时协调资源,避免故障升级;
-
事后进行故障复盘和总结,避免再次出现类似问题。
线上告警和故障,相信大部分开发同学都会遇到,故障处理经验的提高是研发工程师进阶和成长当中必须经历的。如何处理各类故障,是否有一个体系化的稳定性知识,也是衡量架构师的重要标准,从故障中我们可以吸取到很多教训,提升服务的稳定性,更好的支持业务。
总结
这一课时的内容分享了常见的分布式监控组件应用,以及线上故障处理制度的相关内容,介绍了 Open-Falcon、Zabbix、Nagios 及 Cat 的应用,一起讨论了线上告警的 SOP 如何制定。
在稳定性建设中,监控指标和监控组件都是我们的工具,是术的层面;故障告警如何处理,如何做好事前监控和事后复盘,是道的层面,术业专攻,再结合合理的制度,才可以把稳定性工作做好。
在你负责的项目中,应用了哪些监控组件呢?又是如何进行配置的呢?欢迎留言分享你的经验。
第45讲:分布式下如何实现统一日志系统?
在业务系统开发中,日志的收集和分析很重要,特别是在进行故障分析时,日志记录得好,可以帮我们快速定位问题原因。在互联网分布式系统下,日志变得越来越分散,数据规模也越来越大,如何更好地收集和分析日志,就变成了一个特别重要的问题。
传统的日志查看
查看日志对工程师来说最简单不过了,虽然有了各类日志分析工具,但还是要熟悉命令行语句的操作,特别是在很多大型公司的面试中,都会考察求职者对 Linux 基本指令的应用和熟悉程度。下面我们一起来回顾一下。
Linux 查看日志的命令有多种:tail、cat、head、more 等,这里介绍几种常用的方法。
-
tail 和 head 命令
tail 是我最常用的一种查看方式,典型的应用是查看日志尾部最后几行的日志,一般会结合 grep 进行搜索应用:
tail -n 10 test.log
tail -fn 1000 test.log | grep 'test'
head 和 tail 相反,是查看日志文件的前几行日志,其他应用和 tail 类似:
head -n 10 test.log
-
more 和 less
more 命令可以按照分页的方式现实日志内容,并且可以进行快速地翻页操作,除了 more 命令以外,常用的还有 less 命令,和 more 的应用类似。
-
cat
cat 命令用于查看全部文件,是由第一行到最后一行连续显示在屏幕上,一次显示整个文件,一般也会结合 grep 等管道进行搜索。
除了基本的指令以外,还有 AWK 和 SED 命令,用于比较复杂的日志分析,例如,sed 命令可以指定对日志文件的一部分进行查找,根据时间范围,或者根据行号等搜索。关于 AWK 和 SED 详细的应用说明,你可以结合 help 指令查看命令示例。不过呢,我的建议是只要了解基本操作就可以,一些比较复杂的语法可以通过查看手册或者搜索类似的命令行应用来实现:
为什么需要统一日志系统
使用上面的 Linux 指令进行日志查看与分析,在单机单节点下是可以应用的,但是如果扩展到分布式环境下,当你需要查看几十上百台机器的日志时,需要不停地切换机器进行查看,就会变得力不从心了。
你可以思考一下,在分布式场景下,除了不方便查看集群日志以外,传统日志收集都存在哪些问题?
-
无法实现日志的快速搜索
传统的查找是基于文件的,搜索效率比较低,并且很难对日志文件之间的关系进行聚合,无法从全局上梳理日志,也很难进行调用链路的分析。
-
日志的集中收集和存储困难
当有上千个节点的时候,日志是分布在许多机器上的,如果要获取这些日志的文件,不可能一台一台地去查看,所以这就是很明显的一个问题。
-
日志分析聚合及可视化
由于日志文件分布在不同的服务器上,因此进行相关的分析和聚合非常困难,也不利于展开整体的数据分析工作。
除了这些,还有日志安全问题,以电商场景为例,很多业务日志都是敏感数据,比如用户下单数据、账户信息等,如何管理这些数据的安全性,也是一个很关键的问题。
ELK 统一日志系统
我在之前的工作中,曾经负责搭建了业务系统的 ELK 日志系统,在第 25 课时我们介绍 ElasticSearch 技术栈时中曾经提到过 ELK Stack,就是下面要说的 ELK(ElasticSearch Logstash Kibana)日志收集系统。
ElasticSearch 内核使用 Lucene 实现,实现了一套用于搜索的 API,可以实现各种定制化的检索功能,和大多数搜索系统一样,ElasticSearch 使用了倒排索引实现,我们在第 25 课时中有过介绍,你可以温习一下。
Logstash 同样是 ElasticSearch 公司的产品,用来做数据源的收集,是 ELK 中日志收集的组件。
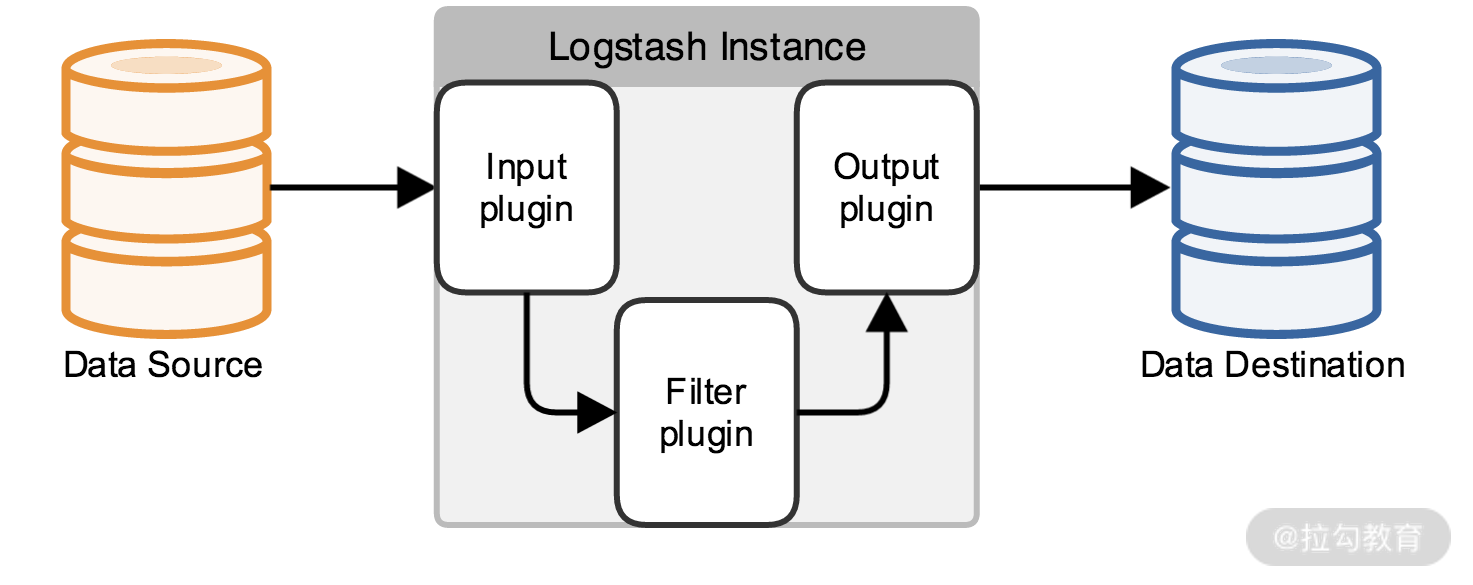
Logstash 的数据流图如上图所示,你可以把 Logstash 想象成一个通用的输入和输出接口,定义了多种输入和输出源,可以把日志收集到多种文件存储中,输出源除了 ElasticSearch,还可以是 MySQL、Redis、Kakfa、HDFS、Lucene 等。
Kibana 其实就是一个在 ElasticSearch 之上封装了一个可视化的界面,但是 Kibana 实现的不只是可视化的查询,还针对实际业务场景,提供了多种数据分析功能,支持各种日志数据聚合的操作。
ELK 系统进行日志收集的过程可以分为三个环节,如下图所示:
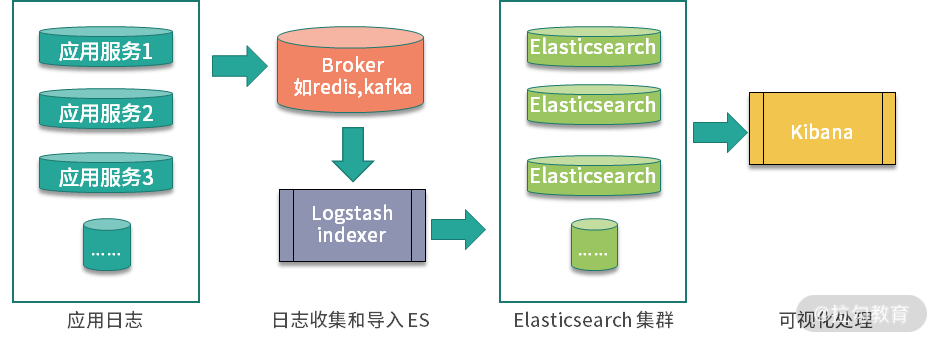
-
使用 Logstash 日志收集,导入 ElasticSearch
Logstash 的应用非常简单,核心配置就是一个包含 input{}、filter{}、output{} 的文件,分别用来配置输入源、过滤规则和配置输出。下面的配置是一个典型的实例:
input {
file {
path => "/Users/test/log"
start_position => beginning
}
}
filter {
grok {
match => { "message" => "%{COMBINE}"}
}
}
output {
ElasticSearch {}
stdout {}
}
-
在 ElasticSearch 中实现索引处理
日志数据导入到 ElasticSearch 中以后,实现索引,在这一步中,可以针对不同日志的索引字段进行定制。
-
通过 Kibana 进行可视化操作、查询等
作为一个商业化产品,Kibana 已经支持了非常丰富的日志分析功能,并且可以选择应用一些机器学习的插件,可以在 Kibana 的官方文档中了解更多。
在我之前的系统设计中,是使用 Flume 进行容器内的日志收集,并且将日志消息通过 Kakfa 传送给 Logstash,最后在 Kibana 中展示。这里分享我之前的一篇关于 ELK 的技术文章,作为补充阅读:ELK 统一日志系统的应用。
总结
今天分享了业务开发中关于日志收集的一些知识,包括常用的日志分析命令、传统日志收集方式在分布式系统下的问题,以及应用 ELK 技术栈进行日志收集的流程。
日志作为系统稳定性的重要抓手,除了今天介绍的日志分析和统一日志系统,在业务开发中进行日志收集时,还有很多细节需要注意。比如 Java 开发中,在使用 Log4j 等框架在高并发的场景下写日志可能会出现的日志丢失,以及线程阻塞问题,还有日志产生过快,导致的磁盘空间不足报警处理等。
你在开发中有哪些日志收集和应用的心得体会,欢迎留言进行分享。
如果你觉得课程不错,从中有所收获的话,不要忘了推荐给身边的朋友哦。前路漫漫,一起加油~



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











