









10 React 中的“栈调和”(Stack Reconciler)过程是怎样的?
时下 React 16 乃至 React 17 都是业界公认的“当红炸子鸡”,相比之下 React 15 似乎已经是一副黯淡无光垂垂老矣的囧相了。
在这样的时代背景下,愿意自动自发地了解 React 15 的人越来越少,这是一个令人心碎的现象。毕竟有位伟人曾经说过,“以史为镜,可以知兴替”;还有另一位伟人曾经说过,“学习知识需要建立必要且完整的上下文”——如果我们不清楚 React 15 的运作机制,就无从把握它的局限性;如果我们不能确切地把握 React 15 的局限性,就无法从根本上理解 React 16 大改版背后的设计动机。因此在追逐时代潮流之前,必须学好历史。
在本讲,我们就要迈出“学习历史”的第一步,也是最重要的一步——理解 React 15 的“栈调和”算法。
调和(Reconciliation)过程与 Diff 算法
迫于喜欢钻名词牛角尖的人实在太多,开篇我先来带你做一个概念辨析,显式声明一下专栏中所提及的“调和”和“Diff”两个东西的确切指向。
“调和”又译为“协调”,协调过程的官方定义,藏在 React 官网对虚拟 DOM 这一概念的解释中,原文如下:
Virtual DOM 是一种编程概念。在这个概念里,UI 以一种理想化的,或者说“虚拟的”表现形式被保存于内存中,并通过如 ReactDOM 等类库使之与“真实的” DOM 同步。这一过程叫作协调(调和)。
我来划一下这段话里的重点:通过如 ReactDOM 等类库使虚拟 DOM 与“真实的” DOM 同步,这一过程叫作协调(调和)。
说人话:调和指的是将虚拟 DOM映射到真实 DOM 的过程。因此严格来说,调和过程并不能和 Diff 画等号。调和是“使一致”的过程,而 Diff 是“找不同”的过程,它只是“使一致”过程中的一个环节。
React 的源码结构佐证了这一点:React 从大的板块上将源码划分为了 Core、Renderer 和 Reconciler 三部分。其中 Reconciler(调和器)的源码位于src/renderers/shared/stack/reconciler这个路径,调和器所做的工作是一系列的,包括组件的挂载、卸载、更新等过程,其中更新过程涉及对 Diff 算法的调用。
所以说调和 !== Diff这个结论,是站得住脚的,如果你持有这个观点,说明你很专业,为你点赞!
但是!在如今大众的认知里,当我们讨论调和的时候,其实就是在讨论 Diff。
这样的认知也有其合理性,因为Diff 确实是调和过程中最具代表性的一环:根据 Diff 实现形式的不同,调和过程被划分为了以 React 15 为代表的“栈调和”以及 React 16 以来的“Fiber 调和”。在实际的面试过程中,当面试官抛出 Reconciliation 相关问题时,也多半是为了了解候选人对 Diff 的掌握程度。因此在本讲中,“栈调和”指的就是 React 15 的 Diff 算法。
Diff 策略的设计思想
在展开讲解 Diff 算法的具体逻辑之前,我们首先从整体上把握一下 Diff 的设计思想。
前面我们已经提到,Diff 算法其实就是“找不同”的过程。在计算机科学领域,要想找出两个树结构之间的不同, 传统的计算方法是通过循环递归进行树节点的一一对比, 这个过程的算法复杂度是 O (n3) 。尽管这个算法本身已经是几代程序员持续优化的结果,但对计算能力有限的浏览器来说,O (n3) 仍然意味着一场性能灾难。
具体来说,若一张页面中有 100 个节点(这样的情况在实际开发中并不少见),1003 算下来就有十万次操作了,这还只是一次 Diff 的开销;若应用规模更大一点,维护 1000 个节点,那么操作次数将会直接攀升到 10 亿的量级。
经常做算法题的人都知道,OJ 中相对理想的时间复杂度一般是 O(1) 或 O(n)。当复杂度攀升至 O(n2) 时,我们就会本能地寻求性能优化的手段,更不必说是人神共愤的 O(n3) 了!我们看不下去,React 自然也看不下去。React 团队结合设计层面的一些推导,总结了以下两个规律, 为将 O (n3) 复杂度转换成 O (n) 复杂度确立了大前提:
-
若两个组件属于同一个类型,那么它们将拥有相同的 DOM 树形结构;
-
处于同一层级的一组子节点,可用通过设置 key 作为唯一标识,从而维持各个节点在不同渲染过程中的稳定性。
除了这两个“板上钉钉”的规律之外,还有一个和实践结合比较紧密的规律,它为 React 实现高效的 Diff 提供了灵感:DOM 节点之间的跨层级操作并不多,同层级操作是主流。
接下来我们就一起看看 React 是如何巧用这 3 个规律,打造高性能 Diff 的。
把握三个“要点”,图解 Diff 逻辑
对于 Diff 逻辑的拆分与解读,社区目前已经有过许多版本,不同版本的解读姿势和角度各有不同。但说到底,真正需要你把握的要点无非下面这 3 个:
-
Diff 算法性能突破的关键点在于“分层对比”;
-
类型一致的节点才有继续 Diff 的必要性;
-
key 属性的设置,可以帮我们尽可能重用同一层级内的节点。
这 3 个要点各自呼应着上文的 3 个规律,我们逐个来看。
1. 改变时间复杂度量级的决定性思路:分层对比
结合“DOM 节点之间的跨层级操作并不多,同层级操作是主流”这一规律,React 的 Diff 过程直接放弃了跨层级的节点比较,它只针对相同层级的节点作对比,如下图所示。这样一来,只需要从上到下的一次遍历,就可以完成对整棵树的对比,这是降低复杂度量级方面的一个最重要的设计。
需要注意的是:虽然栈调和将传统的树对比算法优化为了分层对比,但整个算法仍然是以递归的形式运转的,分层递归也是递归。
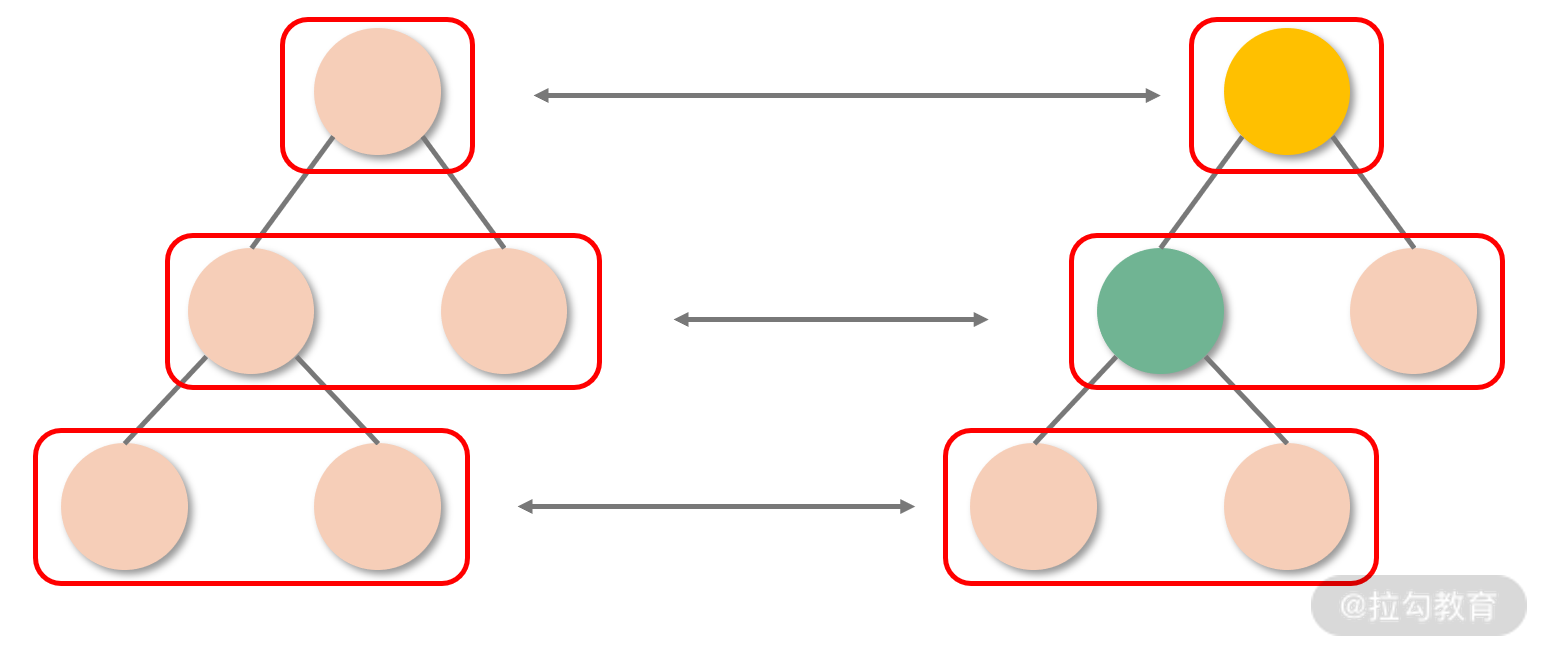
那么如果真的发生了跨层级的节点操作(比如将以 B 节点为根节点的子树从 A 节点下面移动到 C 节点下面,如下图所示)会怎样呢?很遗憾,作为“次要矛盾”,在这种情况下 React 并不能够判断出“移动”这个行为,它只能机械地认为移出子树那一层的组件消失了,对应子树需要被销毁;而移入子树的那一层新增了一个组件,需要重新为其创建一棵子树。
销毁 + 重建的代价是昂贵的,因此 React 官方也建议开发者不要做跨层级的操作,尽量保持 DOM 结构的稳定性。
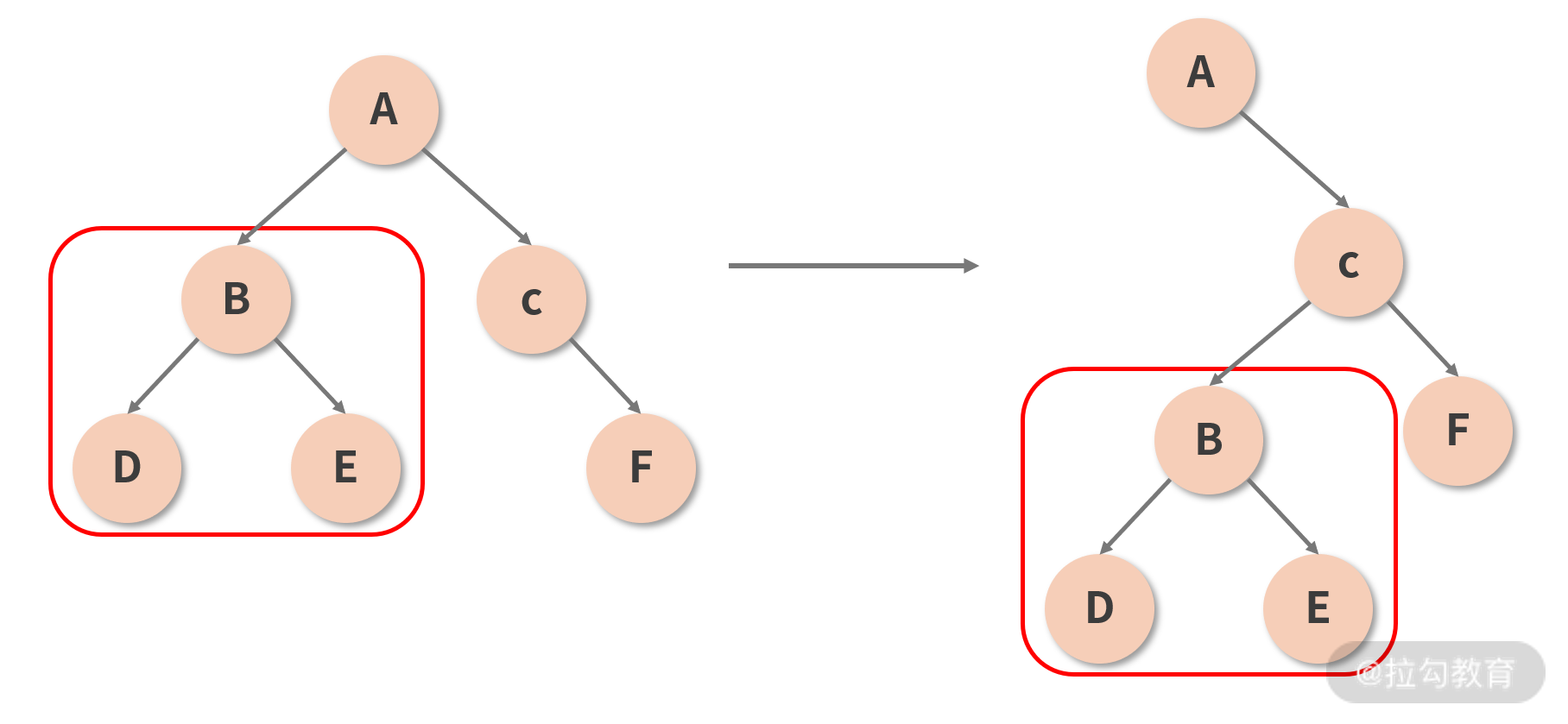
2. 减少递归的“一刀切”策略:类型的一致性决定递归的必要性
结合“若两个组件属于同一个类型,那么它们将拥有相同的 DOM 树形结构”这一规律,我们虽不能直接反推出“不同类型的组件 DOM 结构不同”,但在大部分的情况下,这个结论都是成立的。毕竟,实际开发中遇到两个 DOM 结构完全一致、而类型不一致的组件的概率确实太低了。
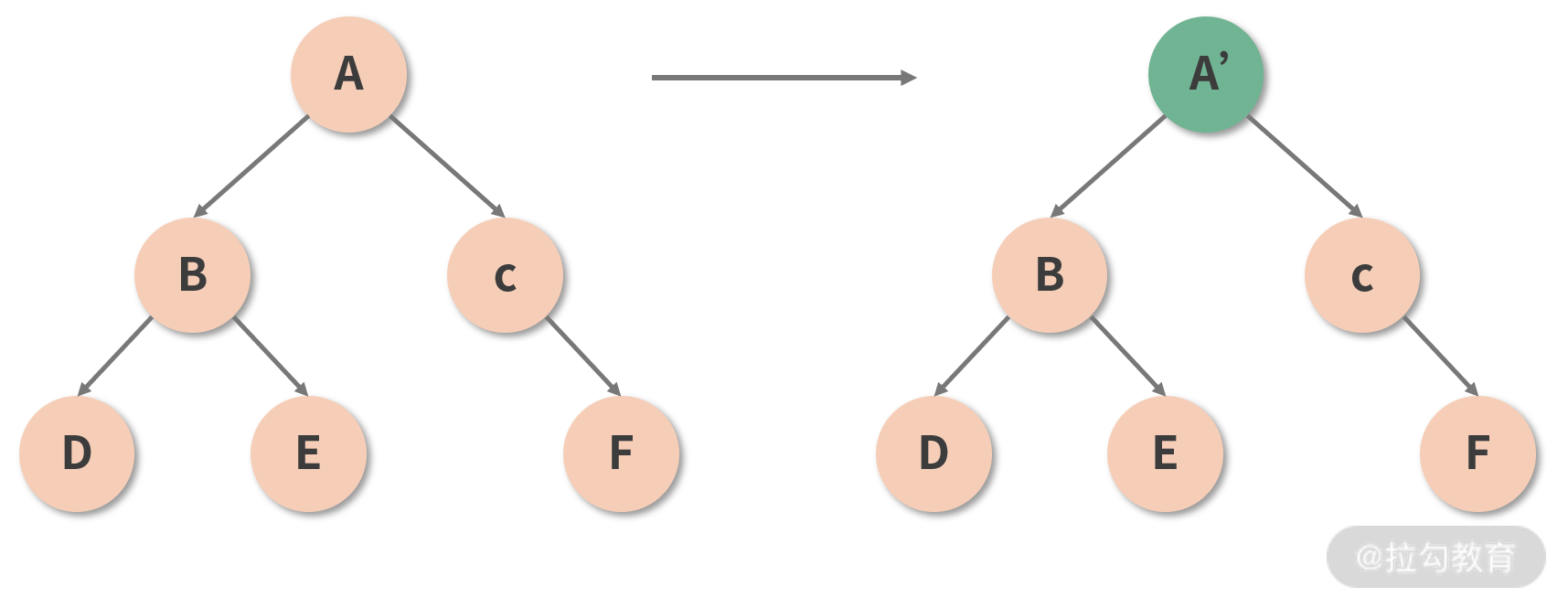
本着抓“主要矛盾”的基本原则,React 认为,只有同类型的组件,才有进一步对比的必要性;若参与 Diff 的两个组件类型不同,那么直接放弃比较,原地替换掉旧的节点,如下图所示。只有确认组件类型相同后,React 才会在保留组件对应 DOM 树(或子树)的基础上,尝试向更深层次去 Diff。
这样一来,便能够从很大程度上减少 Diff 过程中冗余的递归操作。
3. 重用节点的好帮手:key 属性帮 React “记住”节点
在上文中,我们提到了“key 属性能够帮助维持节点的稳定性”,这个结论从何而来呢?首先,我们来看看 React 对 key 属性的定义:
key 是用来帮助 React 识别哪些内容被更改、添加或者删除。key 需要写在用数组渲染出来的元素内部,并且需要赋予其一个稳定的值。稳定在这里很重要,因为如果 key 值发生了变更,React 则会触发 UI 的重渲染。这是一个非常有用的特性。
它试图解决的是同一层级下节点的重用问题。在展开分析之前,我们先结合到现在为止对 Diff 过程的理解,来思考这样一种情况,如下图所示:
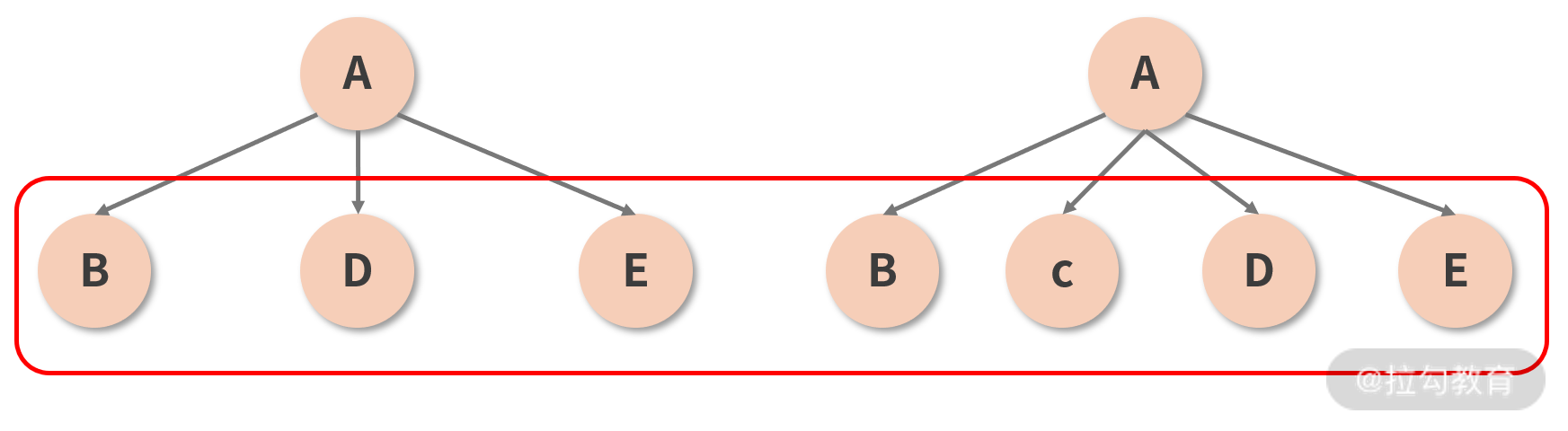
图中 A 组件在保持类型和其他属性均不变的情况下,在两个子节点(B 和 D)之间插入了一个新的节点(C)。按照已知的 Diff 原则,两棵树之间的 Diff 过程应该是这样的:
-
首先对比位于第 1 层的节点,发现两棵树的节点类型是一致的(都是 A),于是进一步 Diff;
-
开始对比位于第 2 层的节点,第 1 个接受比较的是 B 这个位置,对比下来发现两棵树这个位置上的节点都是 B,没毛病,放过它;
-
第 2 个接受比较的是 D 这个位置,对比 D 和 C,发现前后的类型不一致,直接删掉 D 重建 C;
-
第 3 个接受比较的是 E 这个位置,对比 E 和 D,发现前后的类型不一致,直接删掉 E 重建 D;
-
最后接受“比较”的是树 2 的 E 节点这个位置,这个位置在树 1 里是空的,也就是说树 2 的E 是一个新增节点,所以新增一个 E。
你看你看,奇怪的事情发生了:C、D、E 三个节点,其实都是可以直接拿来用的。原本新增 1 个节点就能搞定的事情,现在却又是删除又是重建地搞了半天,这也太蠢了吧?而且这个蠢操作和跨层级移动节点还不太一样,后者本来就属于低频操作,加以合理的最佳实践约束一下基本上可以完全规避掉;但图示的这种插入节点的形式,可是实打实的高频操作,你怎么躲也躲不过的。频繁增删节点必定拖垮性能,这时候就需要请出 key 属性来帮我们重用节点了。
key 属性的形式,我们肯定都不陌生。在基于数组动态生成节点时,我们一般都会给每个节点加装一个 key 属性(下面是一段代码示例):
const todoItems = todos.map((todo) =>
<li key={todo.id}>
{todo.text}
</li>
)
如果你忘记写 key,React 虽然不至于因此报错,但控制台标红是难免的,它会给你抛出一个“请给列表元素补齐 key 属性”的 warning,这个常见的 warning 也从侧面反映出了 key 的重要性。事实上,当我们没有设定 key 值的时候,Diff 的过程就正如上文所描述的一样惨烈。但只要你按照规范加装一个合适的 key,这个 key 就会像一个记号一样,帮助 React “记住”某一个节点,从而在后续的更新中实现对这个节点的追踪。比如说刚刚那棵虚拟 DOM 树,若我们给位于第 2 层的每一个子节点一个 key 值,如下图所示:
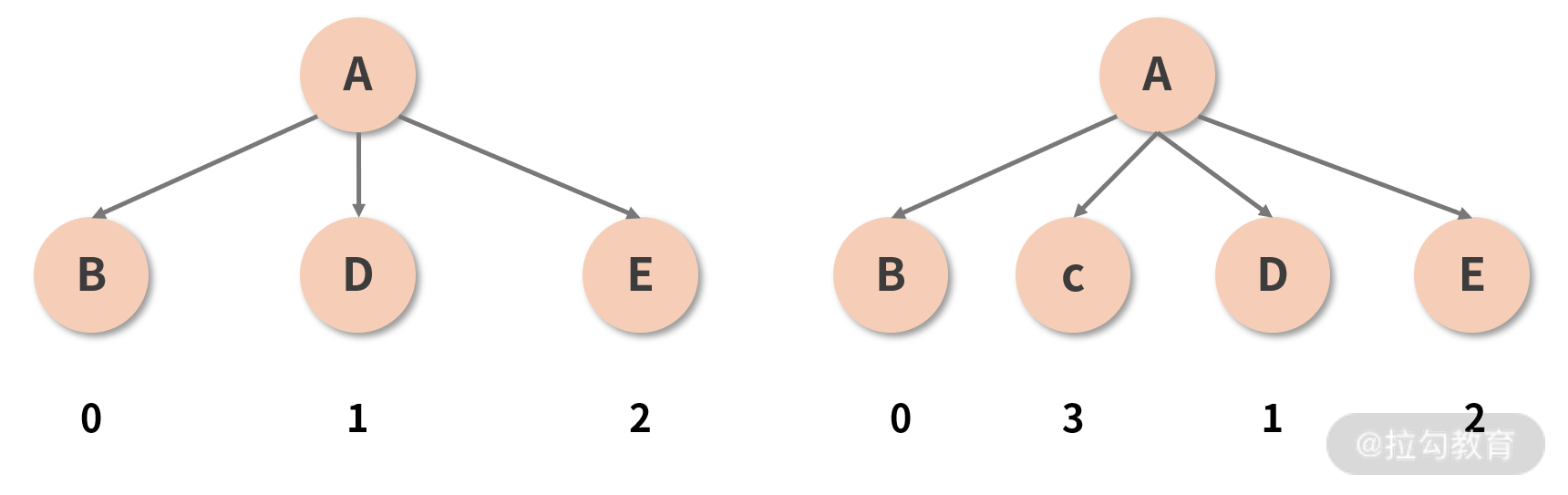
这个 key 就充当了每个节点的 ID(唯一标识),有了这个标识之后,当 C 被插入到 B 和 D 之间时,React 并不会再认为 C、D、E 这三个坑位都需要被重建——它会通过识别 ID,意识到 D 和 E 并没有发生变化(D 的 ID 仍然是 1,E 的 ID 仍然是 2),而只是被调整了顺序而已。接着,React 便能够轻松地重用它“追踪”到旧的节点,将 D 和 E 转移到新的位置,并完成对 C 的插入。这样一来,同层级下元素的操作成本便大大降低。
注:作为一个节点的唯一标识,在使用 key 之前,请务必确认 key 的唯一和稳定。
总结
行文至此,栈调和机制下 Diff 算法的核心逻辑其实已经讲完了。前面我曾经强调过,原理!==源码,这一点放在 Diff 算法这儿来看尤为应验——Diff 算法的源码调用链路很长,就 React 15 这一个大版本来说,我个人就断断续续花了好几天才真正读完;但若真的把源码中的逻辑要点作提取,你消化它们可能也就不过一杯茶的工夫。
对于 React 15 下的 Diff 过程,我个人的建议是你了解到逻辑这一层,把握住“树递归”这个特征,这就够了。专栏对调和过程的讨论,主要的发力点仍然是围绕 React 16 来展开的。若你学有余力,可以提前了解一下 React 16 对调和的实现,这将是我们整个第二模块的一个重中之重。
结束了对 React 15 时代下 Diff 的探讨,你可别忘了虚拟 DOM 中还有一个叫作“batch”的东西。“batch”描述的是“批处理”机制,这个机制和 Diff 一样,在 React 中都可以由 setState 来触发。在下一讲,我们就会深入 setState 工作流,对包括“批量更新”在内的一系列问题一探究竟。
11 setState 到底是同步的,还是异步的?
setState 对于许多的 React 开发者来说,像是一个“最熟悉的陌生人”:
-
当你入门 React 的时候,接触的第一波 API 里一定有 setState——数据驱动视图,没它就没法创造变化;
-
当你项目的数据流乱作一团的时候,层层排查到最后,始作俑者也往往是 setState——工作机制太复杂,文档又不说清楚,只能先“摸着石头过河”。
久而久之,setState 的工作机制渐渐与 React 调和算法并驾齐驱,成了 React 核心原理中区分度最高的知识模块之一。本讲我们就紧贴 React 源码和时下最高频的面试题目,帮你从根儿上理解 setState 工作流。
从一道面试题说起
这是一道变体繁多的面试题,在 BAT 等一线大厂的面试中考察频率非常高。首先题目会给出一个这样的 App 组件,在它的内部会有如下代码所示的几个不同的 setState 操作:
import React from "react";
import "./styles.css";
export default class App extends React.Component{
state = {
count: 0
}
increment = () => {
console.log('increment setState前的count', this.state.count)
this.setState({
count: this.state.count + 1
});
console.log('increment setState后的count', this.state.count)
}
triple = () => {
console.log('triple setState前的count', this.state.count)
this.setState({
count: this.state.count + 1
});
this.setState({
count: this.state.count + 1
});
this.setState({
count: this.state.count + 1
});
console.log('triple setState后的count', this.state.count)
}
reduce = () => {
setTimeout(() => {
console.log('reduce setState前的count', this.state.count)
this.setState({
count: this.state.count - 1
});
console.log('reduce setState后的count', this.state.count)
},0);
}
render(){
return <div>
<button onClick={this.increment}>点我增加</button>
<button onClick={this.triple}>点我增加三倍</button>
<button onClick={this.reduce}>点我减少</button>
</div>
}
}
接着我把组件挂载到 DOM 上:
import React from "react";
import ReactDOM from "react-dom";
import App from "./App";
const rootElement = document.getElementById("root");
ReactDOM.render(
<React.StrictMode>
<App />
</React.StrictMode>,
rootElement
);
此时浏览器里渲染出来的是如下图所示的三个按钮:

此时有个问题,若从左到右依次点击每个按钮,控制台的输出会是什么样的?读到这里,建议你先暂停 1 分钟在脑子里跑一下代码,看看和下图实际运行出来的结果是否有出入。
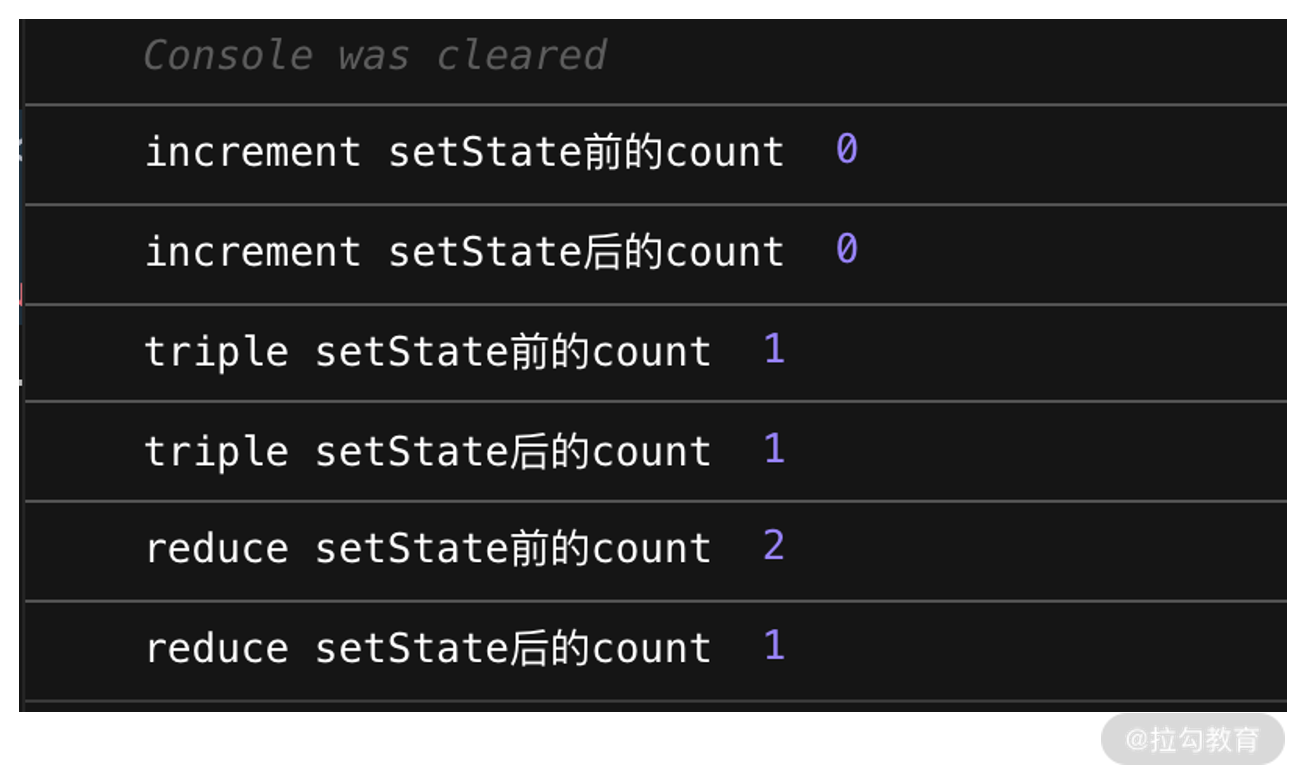
如果你是一个熟手 React 开发,那么 increment 这个方法的输出结果想必难不倒你——正如许许多多的 React 入门教学所声称的那样,“setState 是一个异步的方法”,这意味着当我们执行完 setState 后,state 本身并不会立刻发生改变。 因此紧跟在 setState 后面输出的 state 值,仍然会维持在它的初始状态(0)。在同步代码执行完毕后的某个“神奇时刻”,state 才会“恰恰好”地增加到 1。
但这个“神奇时刻”到底何时发生,所谓的“恰恰好”又如何界定呢?如果你对这个问题搞不太清楚,那么 triple 方法的输出对你来说就会有一定的迷惑性——setState 一次不好使, setState 三次也没用,state 到底是在哪个环节发生了变化呢?
带着这样的困惑,你决定先抛开一切去看看 reduce 方法里是什么光景,结果更令人大跌眼镜,reduce 方法里的 setState 竟然是同步更新的!这......到底是我们初学 React 时拿到了错误的基础教程,还是电脑坏了?
要想理解眼前发生的这魔幻的一切,我们还得从 setState 的工作机制里去找线索。
异步的动机和原理——批量更新的艺术
我们首先要认知的一个问题:在 setState 调用之后,都发生了哪些事情?基于截止到现在的专栏知识储备,你可能会更倾向于站在生命周期的角度去思考这个问题,得出一个如下图所示的结论:
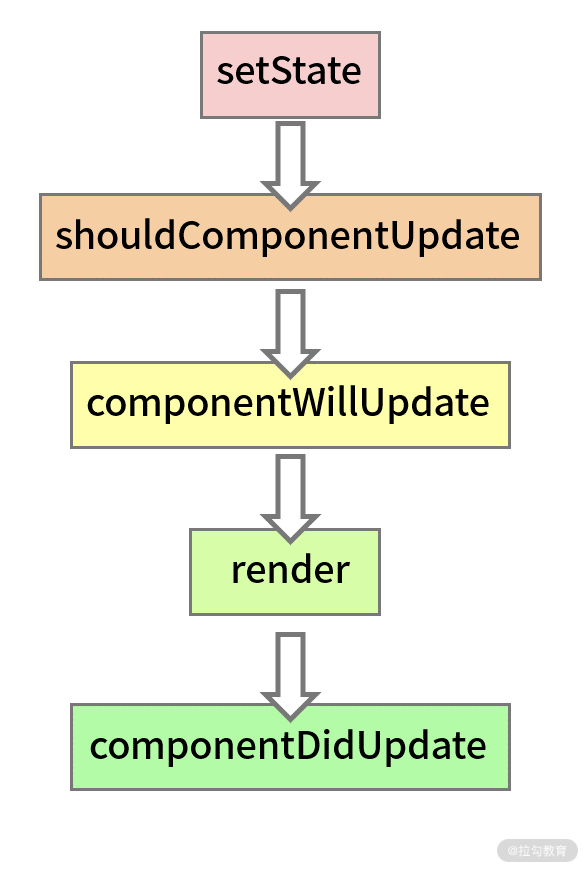
从图上我们可以看出,一个完整的更新流程,涉及了包括 re-render(重渲染) 在内的多个步骤。re-render 本身涉及对 DOM 的操作,它会带来较大的性能开销。假如说“一次 setState 就触发一个完整的更新流程”这个结论成立,那么每一次 setState 的调用都会触发一次 re-render,我们的视图很可能没刷新几次就卡死了。这个过程如我们下面代码中的箭头流程图所示:
this.setState({
count: this.state.count + 1 ===> shouldComponentUpdate->componentWillUpdate->render->componentDidUpdate
});
this.setState({
count: this.state.count + 1 ===> shouldComponentUpdate->componentWillUpdate->render->componentDidUpdate
});
this.setState({
count: this.state.count + 1 ===> shouldComponentUpdate->componentWillUpdate->render->componentDidUpdate
});
事实上,这正是 setState 异步的一个重要的动机——避免频繁的 re-render。
在实际的 React 运行时中,setState 异步的实现方式有点类似于 Vue 的 $nextTick 和浏览器里的 Event-Loop:每来一个 setState,就把它塞进一个队列里“攒起来”。等时机成熟,再把“攒起来”的 state 结果做合并,最后只针对最新的 state 值走一次更新流程。这个过程,叫作“批量更新”,批量更新的过程正如下面代码中的箭头流程图所示:
this.setState({
count: this.state.count + 1 ===> 入队,[count+1的任务]
});
this.setState({
count: this.state.count + 1 ===> 入队,[count+1的任务,count+1的任务]
});
this.setState({
count: this.state.count + 1 ===> 入队, [count+1的任务,count+1的任务, count+1的任务]
});
↓
合并 state,[count+1的任务]
↓
执行 count+1的任务
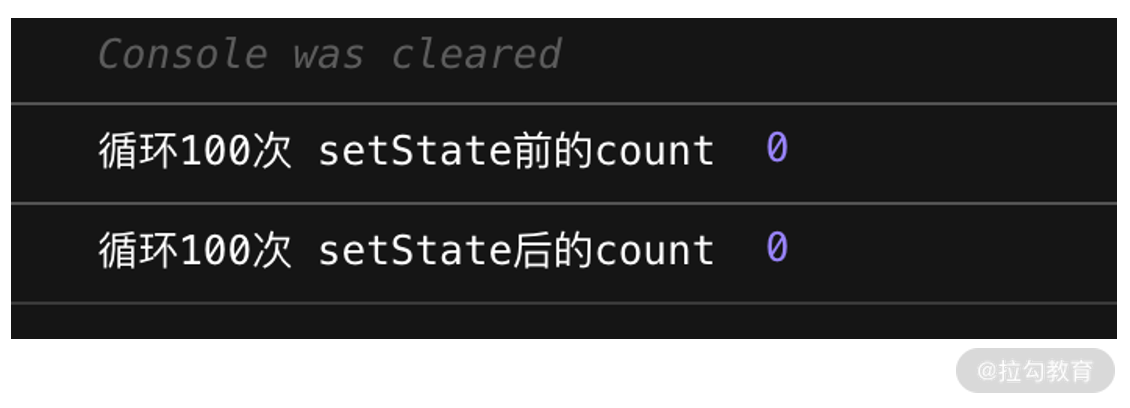
值得注意的是,只要我们的同步代码还在执行,“攒起来”这个动作就不会停止。(注:这里之所以多次 +1 最终只有一次生效,是因为在同一个方法中多次 setState 的合并动作不是单纯地将更新累加。比如这里对于相同属性的设置,React 只会为其保留最后一次的更新)。因此就算我们在 React 中写了这样一个 100 次的 setState 循环:
test = () => {
console.log('循环100次 setState前的count', this.state.count)
for(let i=0;i<100;i++) {
this.setState({
count: this.state.count + 1
})
}
console.log('循环100次 setState后的count', this.state.count)
}
也只是会增加 state 任务入队的次数,并不会带来频繁的 re-render。当 100 次调用结束后,仅仅是 state 的任务队列内容发生了变化, state 本身并不会立刻改变:
“同步现象”背后的故事:从源码角度看 setState 工作流
读到这里,相信你对异步这回事多少有些眉目了。接下来我们就要重点理解刚刚代码里最诡异的一部分——setState 的同步现象:
reduce = () => {
setTimeout(() => {
console.log('reduce setState前的count', this.state.count)
this.setState({
count: this.state.count - 1
});
console.log('reduce setState后的count', this.state.count)
},0);
}
从题目上看,setState 似乎是在 setTimeout 函数的“保护”之下,才有了同步这一“特异功能”。事实也的确如此,假如我们把 setTimeout 摘掉,setState 前后的 console 表现将会与 increment 方法中无异:
reduce = () => {
// setTimeout(() => {
console.log('reduce setState前的count', this.state.count)
this.setState({
count: this.state.count - 1
});
console.log('reduce setState后的count', this.state.count)
// },0);
}
点击后的输出结果如下图所示:
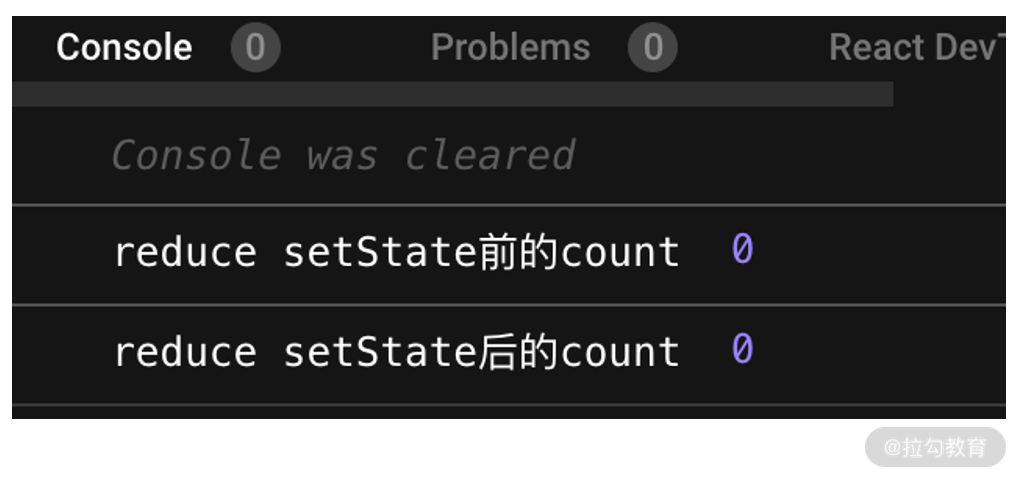
现在问题就变得清晰多了:为什么 setTimeout 可以将 setState 的执行顺序从异步变为同步?
这里我先给出一个结论:并不是 setTimeout 改变了 setState,而是 setTimeout 帮助 setState “逃脱”了 React 对它的管控。只要是在 React 管控下的 setState,一定是异步的。
接下来我们就从 React 源码里,去寻求佐证这个结论的线索。
tips:时下虽然市场里的 React 16、React 17 十分火热,但就 setState 这块知识来说,React 15 仍然是最佳的学习素材。因此下文所有涉及源码的分析,都会围绕 React 15 展开。关于 React 16 之后 Fiber 机制给 setState 带来的改变,我们会有专门一讲来分析,不在本讲的讨论范围内。
解读 setState 工作流
我们阅读任何框架的源码,都应该带着问题、带着目的去读。React 中对于功能的拆分是比较细致的,setState 这部分涉及了多个方法。为了方便你理解,我这里先把主流程提取为一张大图:
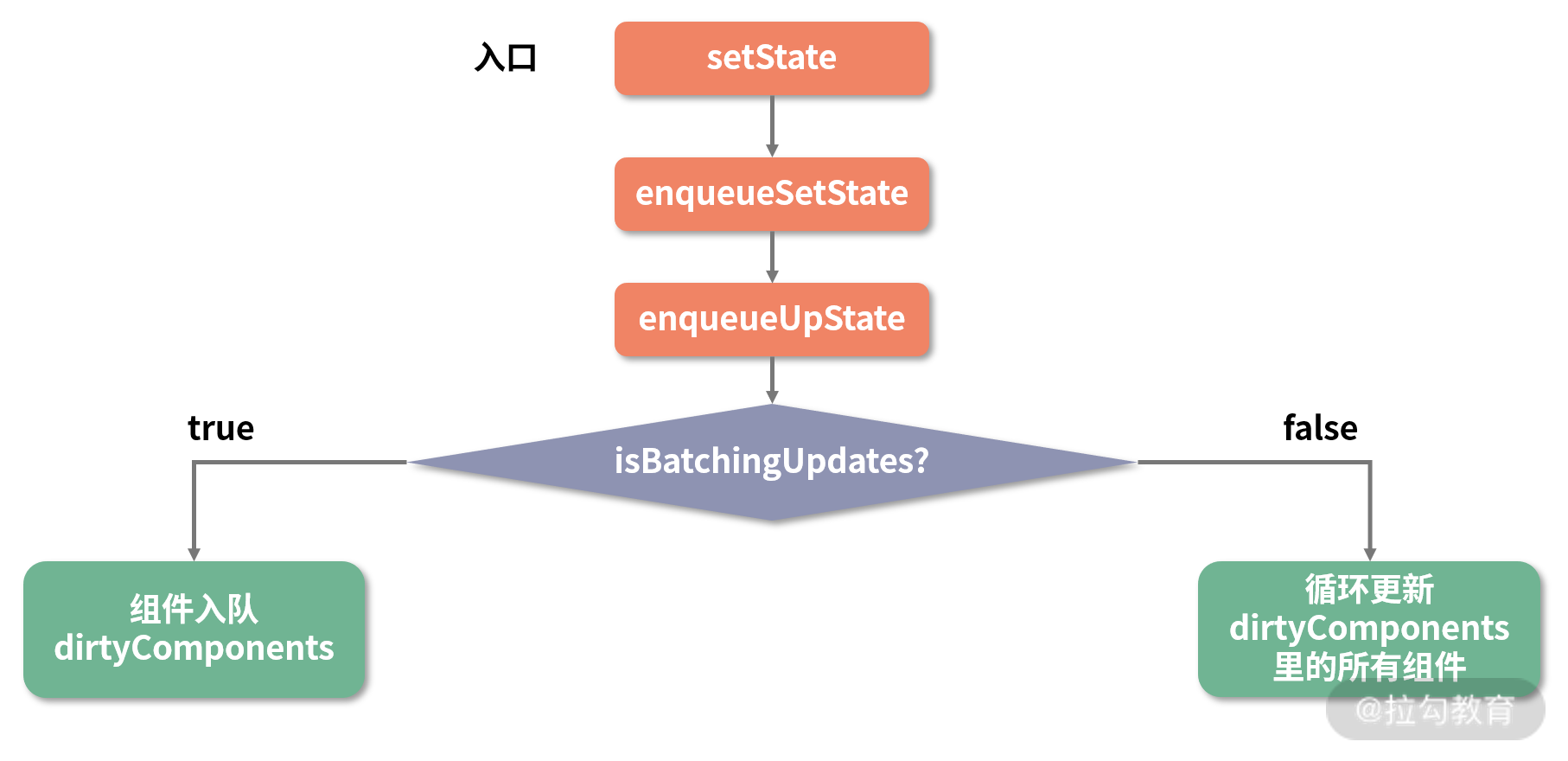
接下来我们就沿着这个流程,逐个在源码中对号入座。首先是 setState 入口函数:
ReactComponent.prototype.setState = function (partialState, callback) {
this.updater.enqueueSetState(this, partialState);
if (callback) {
this.updater.enqueueCallback(this, callback, 'setState');
}
};
入口函数在这里就是充当一个分发器的角色,根据入参的不同,将其分发到不同的功能函数中去。这里我们以对象形式的入参为例,可以看到它直接调用了 this.updater.enqueueSetState 这个方法:
enqueueSetState: function (publicInstance, partialState) {
// 根据 this 拿到对应的组件实例
var internalInstance = getInternalInstanceReadyForUpdate(publicInstance, 'setState');
// 这个 queue 对应的就是一个组件实例的 state 数组
var queue = internalInstance._pendingStateQueue || (internalInstance._pendingStateQueue = []);
queue.push(partialState);
// enqueueUpdate 用来处理当前的组件实例
enqueueUpdate(internalInstance);
}
这里我总结一下,enqueueSetState 做了两件事:
-
将新的 state 放进组件的状态队列里;
-
用 enqueueUpdate 来处理将要更新的实例对象。
继续往下走,看看 enqueueUpdate 做了什么:
function enqueueUpdate(component) {
ensureInjected();
// 注意这一句是问题的关键,isBatchingUpdates标识着当前是否处于批量创建/更新组件的阶段
if (!batchingStrategy.isBatchingUpdates) {
// 若当前没有处于批量创建/更新组件的阶段,则立即更新组件
batchingStrategy.batchedUpdates(enqueueUpdate, component);
return;
}
// 否则,先把组件塞入 dirtyComponents 队列里,让它“再等等”
dirtyComponents.push(component);
if (component._updateBatchNumber == null) {
component._updateBatchNumber = updateBatchNumber + 1;
}
}
这个 enqueueUpdate 非常有嚼头,它引出了一个关键的对象——batchingStrategy,该对象所具备的isBatchingUpdates属性直接决定了当下是要走更新流程,还是应该排队等待;其中的batchedUpdates 方法更是能够直接发起更新流程。由此我们可以大胆推测,batchingStrategy 或许正是 React 内部专门用于管控批量更新的对象。
接下来,我们就一起来研究研究这个 batchingStrategy。
/**
* batchingStrategy源码
**/
var ReactDefaultBatchingStrategy = {
// 全局唯一的锁标识
isBatchingUpdates: false,
// 发起更新动作的方法
batchedUpdates: function(callback, a, b, c, d, e) {
// 缓存锁变量
var alreadyBatchingStrategy = ReactDefaultBatchingStrategy. isBatchingUpdates
// 把锁“锁上”
ReactDefaultBatchingStrategy. isBatchingUpdates = true
<span class="hljs-title">if</span> <span class="hljs-params">(alreadyBatchingStrategy)</span> </span>{
callback(a, b, c, d, e)
} <span class="hljs-keyword">else</span> {
<span class="hljs-comment">// 启动事务,将 callback 放进事务里执行</span>
transaction.perform(callback, <span class="hljs-keyword">null</span>, a, b, c, d, e)
}
}
}
batchingStrategy 对象并不复杂,你可以理解为它是一个“锁管理器”。
这里的“锁”,是指 React 全局唯一的 isBatchingUpdates 变量,isBatchingUpdates 的初始值是 false,意味着“当前并未进行任何批量更新操作”。每当 React 调用 batchedUpdate 去执行更新动作时,会先把这个锁给“锁上”(置为 true),表明“现在正处于批量更新过程中”。当锁被“锁上”的时候,任何需要更新的组件都只能暂时进入 dirtyComponents 里排队等候下一次的批量更新,而不能随意“插队”。此处体现的“任务锁”的思想,是 React 面对大量状态仍然能够实现有序分批处理的基石。
理解了批量更新整体的管理机制,还需要注意 batchedUpdates 中,有一个引人注目的调用:
transaction.perform(callback, null, a, b, c, d, e)
这行代码为我们引出了一个更为硬核的概念——React 中的 Transaction(事务)机制。
理解 React 中的 Transaction(事务) 机制
Transaction 在 React 源码中的分布可以说非常广泛。如果你在 Debug React 项目的过程中,发现函数调用栈中出现了 initialize、perform、close、closeAll 或者 notifyAll 这样的方法名,那么很可能你当前就处于一个 Trasaction 中。
Transaction 在 React 源码中表现为一个核心类,React 官方曾经这样描述它:Transaction 是创建一个黑盒,该黑盒能够封装任何的方法。因此,那些需要在函数运行前、后运行的方法可以通过此方法封装(即使函数运行中有异常抛出,这些固定的方法仍可运行),实例化 Transaction 时只需提供相关的方法即可。
这段话初读有点拗口,这里我推荐你结合 React 源码中的一段针对 Transaction 的注释来理解它:
* <pre>
* wrappers (injected at creation time)
* + +
* | |
* +-----------------|--------|--------------+
* | v | |
* | +---------------+ | |
* | +--| wrapper1 |---|----+ |
* | | +---------------+ v | |
* | | +-------------+ | |
* | | +----| wrapper2 |--------+ |
* | | | +-------------+ | | |
* | | | | | |
* | v v v v | wrapper
* | +---+ +---+ +---------+ +---+ +---+ | invariants
* perform(anyMethod) | | | | | | | | | | | | maintained
* +----------------->|-|---|-|---|-->|anyMethod|---|---|-|---|-|-------->
* | | | | | | | | | | | |
* | | | | | | | | | | | |
* | | | | | | | | | | | |
* | +---+ +---+ +---------+ +---+ +---+ |
* | initialize close |
* +-----------------------------------------+
* </pre>
说白了,Transaction 就像是一个“壳子”,它首先会将目标函数用 wrapper(一组 initialize 及 close 方法称为一个 wrapper) 封装起来,同时需要使用 Transaction 类暴露的 perform 方法去执行它。如上面的注释所示,在 anyMethod 执行之前,perform 会先执行所有 wrapper 的 initialize 方法,执行完后,再执行所有 wrapper 的 close 方法。这就是 React 中的事务机制。
“同步现象”的本质
下面结合对事务机制的理解,我们继续来看在 ReactDefaultBatchingStrategy 这个对象。ReactDefaultBatchingStrategy 其实就是一个批量更新策略事务,它的 wrapper 有两个:FLUSH_BATCHED_UPDATES 和 RESET_BATCHED_UPDATES。
var RESET_BATCHED_UPDATES = {
initialize: emptyFunction,
close: function () {
ReactDefaultBatchingStrategy.isBatchingUpdates = false;
}
};
var FLUSH_BATCHED_UPDATES = {
initialize: emptyFunction,
close: ReactUpdates.flushBatchedUpdates.bind(ReactUpdates)
};
var TRANSACTION_WRAPPERS = [FLUSH_BATCHED_UPDATES, RESET_BATCHED_UPDATES];
我们把这两个 wrapper 套进 Transaction 的执行机制里,不难得出一个这样的流程:

到这里,相信你对 isBatchingUpdates 管控下的批量更新机制已经了然于胸。但是 setState 为何会表现同步这个问题,似乎还是没有从当前展示出来的源码里得到根本上的回答。这是因为 batchedUpdates 这个方法,不仅仅会在 setState 之后才被调用。若我们在 React 源码中全局搜索 batchedUpdates,会发现调用它的地方很多,但与更新流有关的只有这两个地方:
// ReactMount.js
_renderNewRootComponent: function( nextElement, container, shouldReuseMarkup, context ) {
// 实例化组件
var componentInstance = instantiateReactComponent(nextElement);
// 初始渲染直接调用 batchedUpdates 进行同步渲染
ReactUpdates.batchedUpdates(
batchedMountComponentIntoNode,
componentInstance,
container,
shouldReuseMarkup,
context
);
...
}
这段代码是在首次渲染组件时会执行的一个方法,我们看到它内部调用了一次 batchedUpdates,这是因为在组件的渲染过程中,会按照顺序调用各个生命周期函数。开发者很有可能在声明周期函数中调用 setState。因此,我们需要通过开启 batch 来确保所有的更新都能够进入 dirtyComponents 里去,进而确保初始渲染流程中所有的 setState 都是生效的。
下面代码是 React 事件系统的一部分。当我们在组件上绑定了事件之后,事件中也有可能会触发 setState。为了确保每一次 setState 都有效,React 同样会在此处手动开启批量更新。
// ReactEventListener.js
dispatchEvent: function (topLevelType, nativeEvent) {
...
try {
// 处理事件
ReactUpdates.batchedUpdates(handleTopLevelImpl, bookKeeping);
} finally {
TopLevelCallbackBookKeeping.release(bookKeeping);
}
}
话说到这里,一切都变得明朗了起来:isBatchingUpdates 这个变量,在 React 的生命周期函数以及合成事件执行前,已经被 React 悄悄修改为了 true,这时我们所做的 setState 操作自然不会立即生效。当函数执行完毕后,事务的 close 方法会再把 isBatchingUpdates 改为 false。
以开头示例中的 increment 方法为例,整个过程像是这样:
increment = () => {
// 进来先锁上
isBatchingUpdates = true
console.log('increment setState前的count', this.state.count)
this.setState({
count: this.state.count + 1
});
console.log('increment setState后的count', this.state.count)
// 执行完函数再放开
isBatchingUpdates = false
}
很明显,在 isBatchingUpdates 的约束下,setState 只能是异步的。而当 setTimeout 从中作祟时,事情就会发生一点点变化:
reduce = () => {
// 进来先锁上
isBatchingUpdates = true
setTimeout(() => {
console.log('reduce setState前的count', this.state.count)
this.setState({
count: this.state.count - 1
});
console.log('reduce setState后的count', this.state.count)
},0);
// 执行完函数再放开
isBatchingUpdates = false
}
会发现,咱们开头锁上的那个 isBatchingUpdates,对 setTimeout 内部的执行逻辑完全没有约束力。因为 isBatchingUpdates 是在同步代码中变化的,而 setTimeout 的逻辑是异步执行的。当 this.setState 调用真正发生的时候,isBatchingUpdates 早已经被重置为了 false,这就使得当前场景下的 setState 具备了立刻发起同步更新的能力。所以咱们前面说的没错——setState 并不是具备同步这种特性,只是在特定的情境下,它会从 React 的异步管控中“逃脱”掉。
总结
道理很简单,原理却很复杂。最后,我们再一次面对面回答一下标题提出的问题,对整个 setState 工作流做一个总结。
setState 并不是单纯同步/异步的,它的表现会因调用场景的不同而不同:在 React 钩子函数及合成事件中,它表现为异步;而在 setTimeout、setInterval 等函数中,包括在 DOM 原生事件中,它都表现为同步。这种差异,本质上是由 React 事务机制和批量更新机制的工作方式来决定的。
行文至此,相信你已经对 setState 有了知根知底的理解。我们整篇文章的讨论,目前都建立在 React 15 的基础上。React 16 以来,整个 React 核心算法被重写,setState 也不可避免地被“Fiber化”。那么到底什么是“Fiber”,它到底怎样改变着包括 setState 在内的 React 的各个核心技术模块,这就是我们下面两讲要重点讨论的问题了。
12 如何理解 Fiber 架构的迭代动机与设计思想?
在理解 Fiber 架构之前,我们先来看看 React 团队在“React 哲学”中对 React 的定位:
我们认为,React 是用 JavaScript 构建快速响应的大型 Web 应用程序的首选方式。它在 Facebook 和 Instagram 上表现优秀。
这段话里有 4 个字值得我们细细品味,那就是“快速响应”,这 4 个字可以说是 React 团队在用户体验方面最为要紧的一个追求。关于这点,在 React 15 时代已经可见一斑:正是出于对“快速响应”的执着,React 才会想方设法把原本 O(n3) 的 Diff 时间复杂度优化到了前无古人的 O(n)。
然而,随着时间的推移和业务复杂度的提升,React 曾经被人们津津乐道的 Stack Reconciler 也渐渐在体验方面显出疲态。为了更进一步贯彻“快速响应”的原则,React 团队“壮士断腕”,在 16.x 版本中将其最为核心的 Diff 算法整个重写,使其以“Fiber Reconciler”的全新面貌示人。
那么 Stack Reconciler 到底有着怎样根深蒂固的局限性,使得 React 不得不从架构层面做出改变?而 Fiber 架构又是何方神圣,基于它来实现的调和过程又有什么不同呢?本讲我们就围绕这两个大问题展开讨论。
前置知识:单线程的 JavaScript 与多线程的浏览器
大家在入门前端的时候,想必都听说过这样一个结论:JavaScript 是单线程的,浏览器是多线程的。
对于多线程的浏览器来说,它除了要处理 JavaScript 线程以外,还需要处理包括事件系统、定时器/延时器、网络请求等各种各样的任务线程,这其中,自然也包括负责处理 DOM 的UI 渲染线程。而 JavaScript 线程是可以操作 DOM 的。
这意味着什么呢?试想如果渲染线程和 JavaScript 线程同时在工作,那么渲染结果必然是难以预测的:比如渲染线程刚绘制好的画面,可能转头就会被一段 JavaScript 给改得面目全非。这就决定了JavaScript 线程和渲染线程必须是互斥的:这两个线程不能够穿插执行,必须串行。当其中一个线程执行时,另一个线程只能挂起等待。
具有相似特征的还有事件线程,浏览器的 Event-Loop 机制决定了事件任务是由一个异步队列来维持的。当事件被触发时,对应的任务不会立刻被执行,而是由事件线程把它添加到任务队列的末尾,等待 JavaScript 的同步代码执行完毕后,在空闲的时间里执行出队。
在这样的机制下,若 JavaScript 线程长时间地占用了主线程,那么渲染层面的更新就不得不长时间地等待,界面长时间不更新,带给用户的体验就是所谓的“卡顿”。一般页面卡顿的时候,你会做什么呢?我个人的习惯是更加频繁地在页面上点来点去,期望页面能够给我哪怕一点点的响应。遗憾的是,事件线程也在等待 JavaScript,这就导致你触发的事件也将是难以被响应的。
试想一下界面不更新、交互无反应的这种感觉,是不是非常令人抓狂?这其实正是 Stack Reconciler 后期所面临的困局。
为什么会产生“卡顿”这样的困局?
Stack Reconciler 所带来的一个无解的问题,正是JavaScript 对主线程的超时占用问题。为什么会出现这个问题?这就对应上了我们“第 10 讲”中所强调的一个关键知识点——Stack Reconciler 是一个同步的递归过程。
同步的递归过程,意味着不撞南墙不回头,意味着一旦更新开始,就像吃了炫迈一样,根本停不下来。这里我用一个案例来帮你复习一下这个过程,请先看下面这张图:
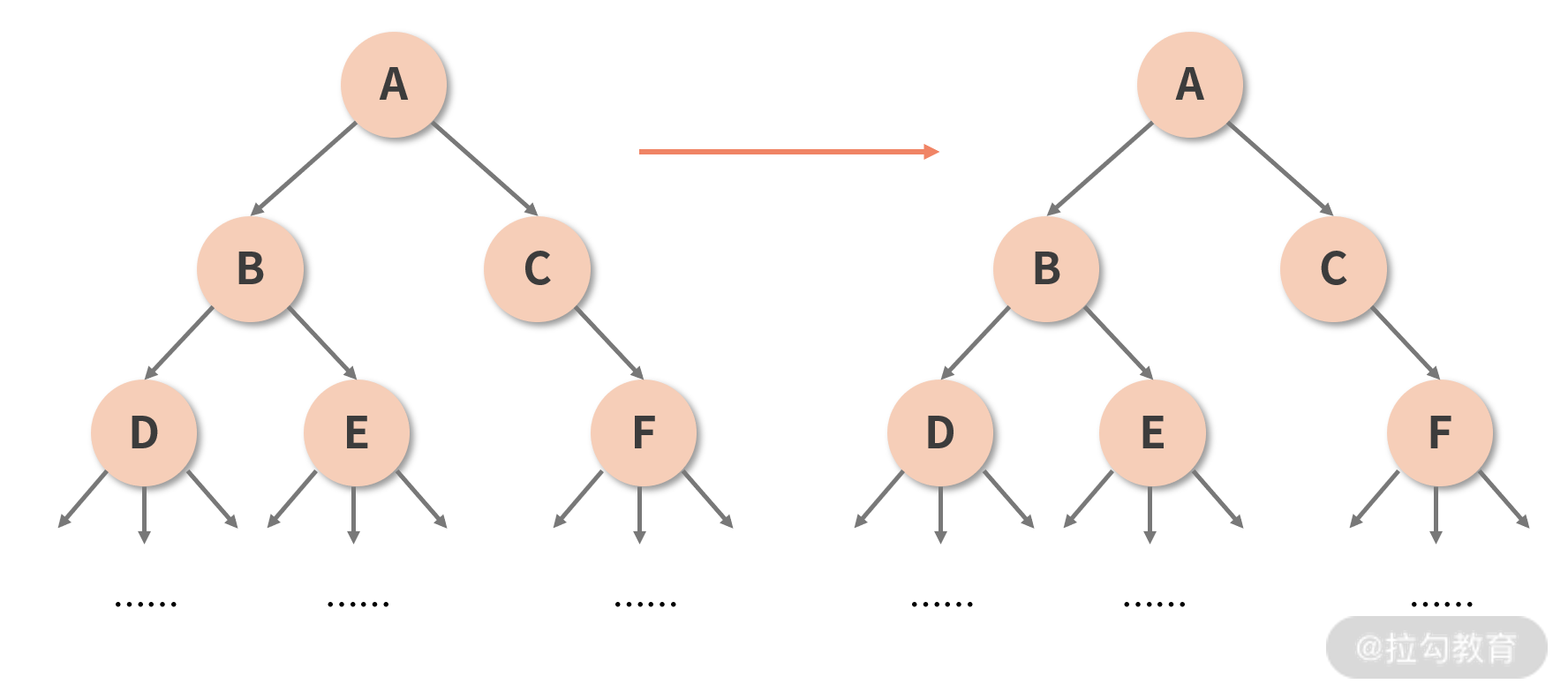
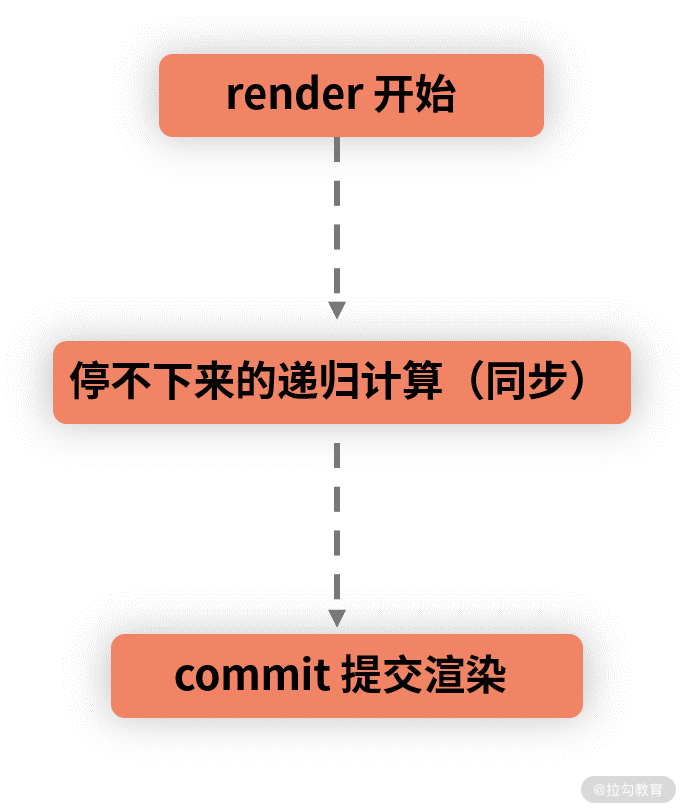
在 React 15 及之前的版本中,虚拟 DOM 树的数据结构载体是计算机科学中的“树”,其 Diff 算法的遍历思路,也是沿袭了传统计算机科学中“对比两棵树”的算法,在此基础上优化得来。因此从本质上来说,栈调和机制下的 Diff 算法,其实是树的深度优先遍历的过程。而树的深度优先遍历,总是和递归脱不了关系。
拿这棵树来举例,若 A 组件发生了更新,那么栈调和的工作过程是这样的:对比第 1 层的两个 A,确认节点可复用,继续 Diff 其子组件。当 Diff 到 B 的时候,对比前后的两个 B 节点,发现可复用,于是继续 Diff 其子节点 D、E。待 B 树最深层的 Diff 完成、逐层回溯后,再进入 C 节点的 Diff 逻辑......调和器会重复“父组件调用子组件”的过程,直到最深的一层节点更新完毕,才慢慢向上返回。
这个过程的致命性在于它是同步的,不可以被打断。当处理结构相对复杂、体量相对庞大的虚拟 DOM 树时,Stack Reconciler 需要的调和时间会很长,这就意味着 JavaScript 线程将长时间地霸占主线程,进而导致我们上文中所描述的渲染卡顿/卡死、交互长时间无响应等问题。
设计思想:Fiber 是如何解决问题的
什么是 Fiber?从字面上来理解,Fiber 这个单词翻译过来是“丝、纤维”的意思,是比线还要细的东西。在计算机科学里,我们有进程、线程之分,而 Fiber 就是比线程还要纤细的一个过程,也就是所谓的“纤程”。纤程的出现,意在对渲染过程实现更加精细的控制。
Fiber 是一个多义词。从架构角度来看,Fiber 是对 React 核心算法(即调和过程)的重写;从编码角度来看,Fiber 是 React 内部所定义的一种数据结构,它是 Fiber 树结构的节点单位,也就是 React 16 新架构下的“虚拟 DOM”;从工作流的角度来看,Fiber 节点保存了组件需要更新的状态和副作用,一个 Fiber 同时也对应着一个工作单元。
本讲我们将站在架构角度来理解 Fiber。
Fiber 架构的应用目的,按照 React 官方的说法,是实现“增量渲染”。所谓“增量渲染”,通俗来说就是把一个渲染任务分解为多个渲染任务,而后将其分散到多个帧里面。不过严格来说,增量渲染其实也只是一种手段,实现增量渲染的目的,是为了实现任务的可中断、可恢复,并给不同的任务赋予不同的优先级,最终达成更加顺滑的用户体验。
Fiber 架构核心:“可中断”“可恢复”与“优先级”
在 React 16 之前,React 的渲染和更新阶段依赖的是如下图所示的两层架构:
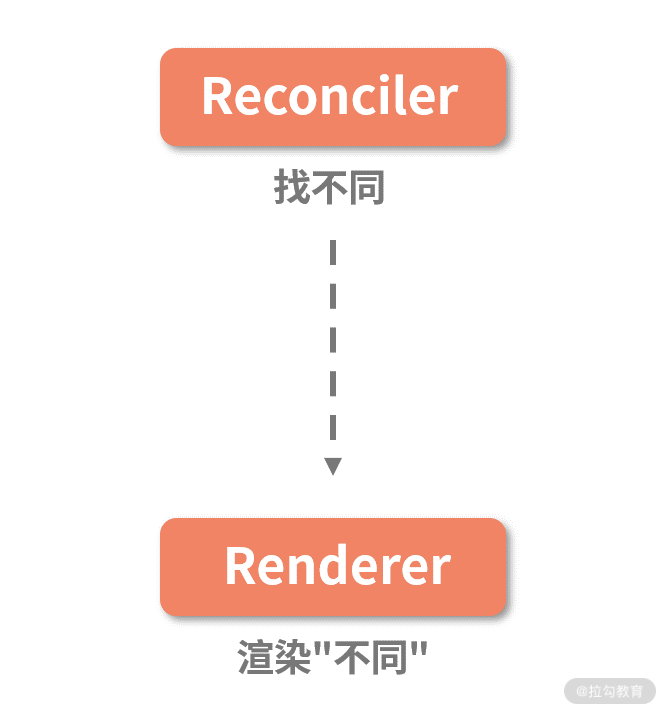
正如上文所分析的那样,Reconciler 这一层负责对比出新老虚拟 DOM 之间的变化,Renderer 这一层负责将变化的部分应用到视图上,从 Reconciler 到 Renderer 这个过程是严格同步的。
而在 React 16 中,为了实现“可中断”和“优先级”,两层架构变成了如下图所示的三层架构:
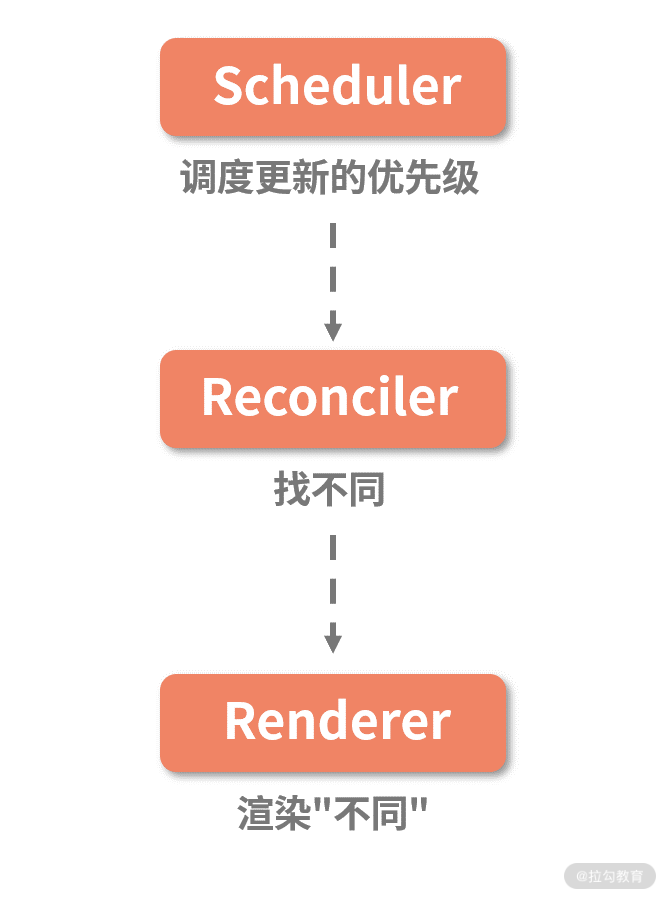
多出来的这层架构,叫作“Scheduler(调度器)”,调度器的作用是调度更新的优先级。
在这套架构模式下,更新的处理工作流变成了这样:首先,每个更新任务都会被赋予一个优先级。当更新任务抵达调度器时,高优先级的更新任务(记为 A)会更快地被调度进 Reconciler 层;此时若有新的更新任务(记为 B)抵达调度器,调度器会检查它的优先级,若发现 B 的优先级高于当前任务 A,那么当前处于 Reconciler 层的 A 任务就会被中断,调度器会将 B 任务推入 Reconciler 层。当 B 任务完成渲染后,新一轮的调度开始,之前被中断的 A 任务将会被重新推入 Reconciler 层,继续它的渲染之旅,这便是所谓“可恢复”。
以上,便是架构层面对“可中断”“可恢复”与“优先级”三个核心概念的处理。
Fiber 架构对生命周期的影响
在基础篇我们曾经探讨过,React 16 的生命周期分为这样三个阶段,如下图所示:
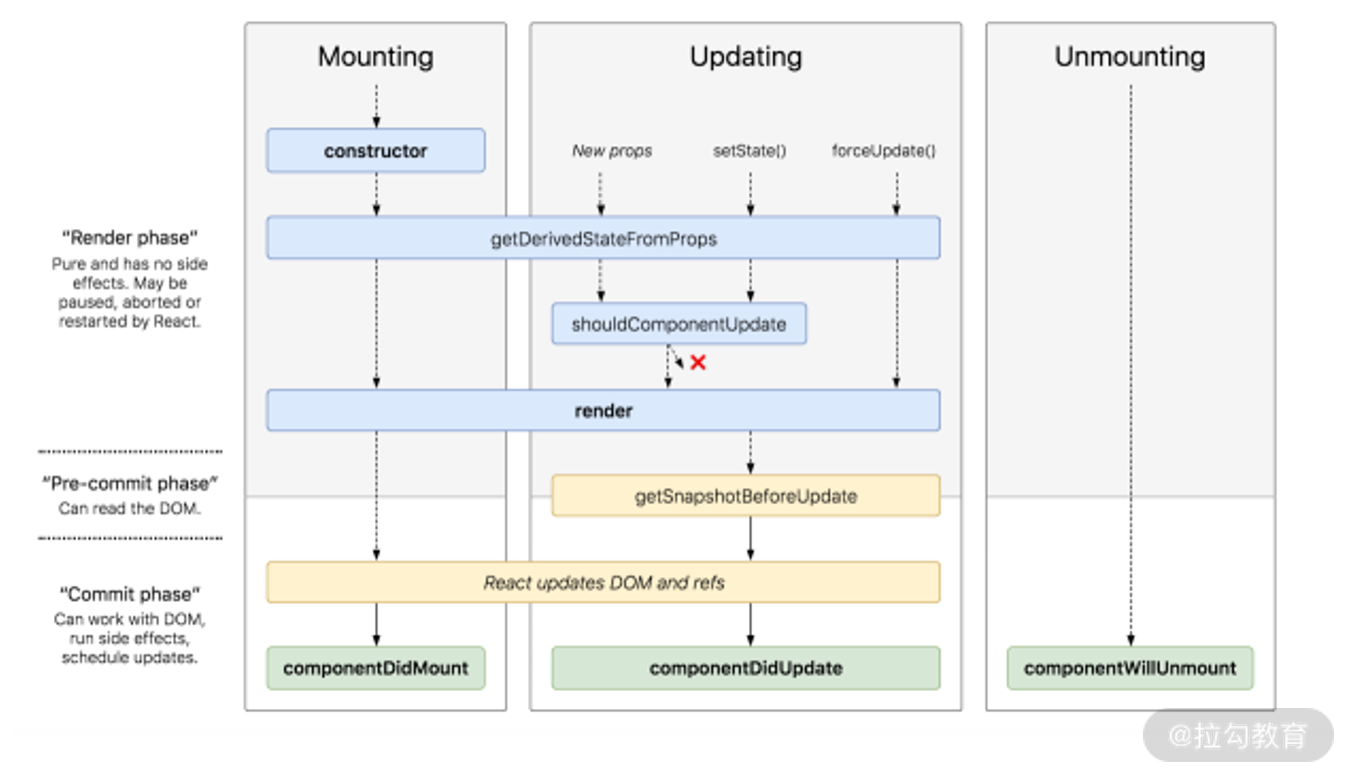
-
render 阶段:纯净且没有副作用,可能会被 React 暂停、终止或重新启动。
-
pre-commit 阶段:可以读取 DOM。
-
commit 阶段:可以使用 DOM,运行副作用,安排更新。
其中 pre-commit 和 commit 从大阶段上来看都属于 commit 阶段。
在 render 阶段,React 主要是在内存中做计算,明确 DOM 树的更新点;而 commit 阶段,则负责把 render 阶段生成的更新真正地执行掉。这两个阶段做的事情,非常适合和本讲刚刚讲过的 React 架构分层结合起来理解。
首先我们来看 React 15 中从 render 到 commit 的过程:
而在 React 16 中,render 到 commit 的过程变成了这样,如下图所示:
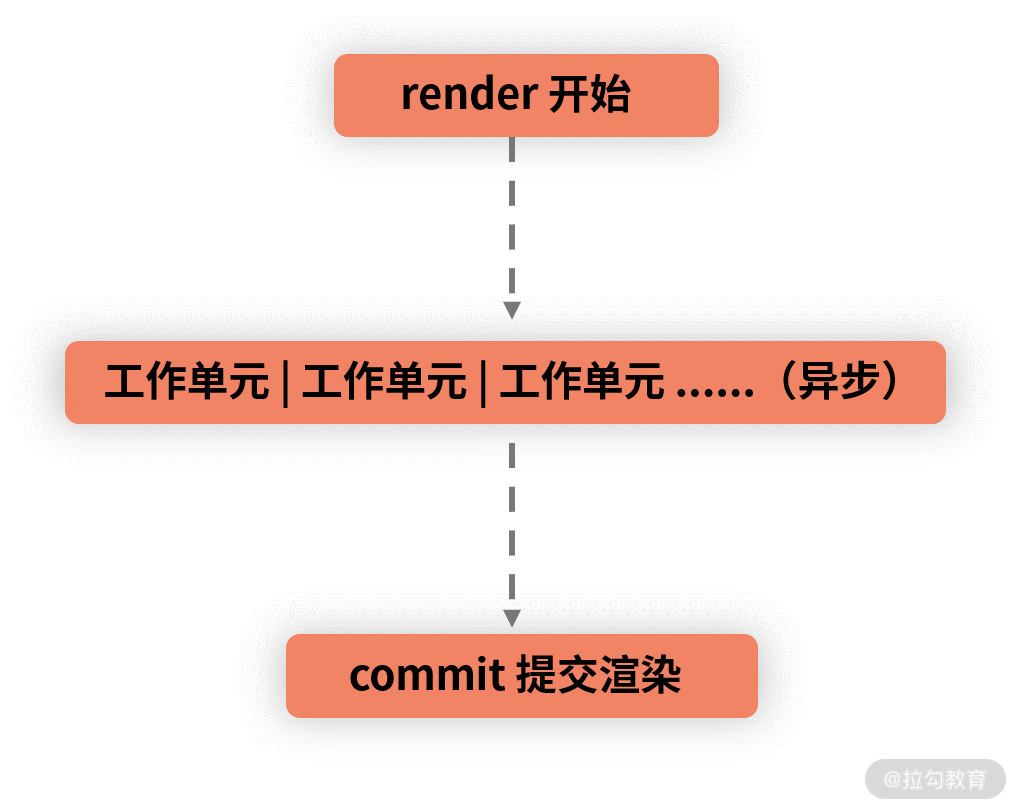
可以看出,新老两种架构对 React 生命周期的影响主要在 render 这个阶段,这个影响是通过增加 Scheduler 层和改写 Reconciler 层来实现的。
在 render 阶段,一个庞大的更新任务被分解为了一个个的工作单元,这些工作单元有着不同的优先级,React 可以根据优先级的高低去实现工作单元的打断和恢复。由于 render 阶段的操作对用户来说其实是“不可见”的,所以就算打断再重启,对用户来说也是 0 感知。但是,工作单元(也就是任务)的重启将会伴随着对部分生命周期的重复执行,这些生命周期是:
-
componentWillMount
-
componentWillUpdate
-
shouldComponentUpdate
-
componentWillReceiveProps
其中 shouldComponentUpdate 的作用是通过返回 true 或者 false,来帮助我们判断更新的必要性,一般在这个函数中不会进行副作用操作,因此风险不大。
而 “componentWill” 开头的三个生命周期,则常年被开发者以各种各样的姿势滥用,是副作用的“重灾区”。关于这点,我在第 03 讲“为什么 React 16 要更改组件的生命周期?(下) ”中已经有过非常细致的讲解,此处不再赘述。你在这里需要做的,是把 React 架构分层的变化与生命周期的变化建立联系,从而对两者的设计动机都形成更加深刻的理解。
总结
通过本讲的学习,你已经知道了 React 16 中 Fiber 架构的架构分层和宏观视角下的工作流。但这一切,都还只是我们学习 Fiber Reconciler 的一个起点。Fiber Reconciler 目前对于你来说仍然是一个黑盒,关于它,还有太多的谜题需要我们一一去探索,这些谜题包括但不限于:
-
React 16 在所有情况下都是异步渲染的吗?
-
Fiber 架构中的“可中断”“可恢复”到底是如何实现的?
-
Fiber 树和传统虚拟 DOM 树有何不同?
-
优先级调度又是如何实现的?
-
......
所有这些问题的答案,我们都需要从 Fiber 架构下的 React 源码中去寻找。
下一讲我们就将以 ReactDOM.render 串联起的渲染链路作为引子,切入对 Fiber 相关源码的探讨。
ReactDOM.render 之后到底发生了什么?this.setState 之后又发生了什么?我想,当你对这两个问题形成概念之后,上面罗列出的所有小问题都将迎刃而解。















 134
134











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











