






 本文详细解析了JPA中N+1 SQL问题的产生机制,并介绍了多种解决方法,如批处理FetchSize、@Fetch注解、@NamedEntityGraph和自定义逻辑。通过实例展示了如何通过这些工具减少SQL查询次数,提高性能。
本文详细解析了JPA中N+1 SQL问题的产生机制,并介绍了多种解决方法,如批处理FetchSize、@Fetch注解、@NamedEntityGraph和自定义逻辑。通过实例展示了如何通过这些工具减少SQL查询次数,提高性能。
25 经典的 N+1 SQL 问题如何正确解决?(上)
在 JPA 的使用过程中,N+1 SQL 是很常见的问题,相信很多程序员都遇到过这一问题,我看见很多同事处理起来束手无策,那么它究竟真的有那么麻烦吗?这一讲我会帮助你梳理思路,看看到底如何解决这个经典问题。
注:由于内容较多,我将这部分内容拆分成两讲,方便你学习。
什么是 N+1 SQL 问题?
想要解决一个问题,必须要知道它是什么、如何产生的,这样才能有方法、有逻辑地去解决它。下面通过一个例子来看一下什么是 N+1 的 SQL 问题。
假设一个 UserInfo 实体对象和 Address 是一对多的关系,即一个用户有多个地址,我们首先看一下一般实体里面的关联关系会怎么写。两个实体对象如下述代码所示。
//UserInfo实体对象如下:
@Entity
@Data
@SuperBuilder
@AllArgsConstructor
@NoArgsConstructor
@Table
@ToString(exclude = "addressList")//exclued防止 toString打印日志的时候死循环
public class UserInfo extends BaseEntity {
private String name;
private String telephone;
// UserInfo实体对象的关联关系由Address对象里面的userInfo字段维护,默认是lazy加载模式,为了方便演示fetch取EAGER模式。此处是一对多关联关系
@OneToMany(mappedBy = "userInfo",fetch = FetchType.EAGER)
private List<Address> addressList;
}
//Address对象如下:
@Entity
@Table
@Data
@SuperBuilder
@AllArgsConstructor
@NoArgsConstructor
@ToString(exclude = "userInfo")
public class Address extends BaseEntity {
private String city;
//维护UserInfo和Address的外键关系,方便演示也采用EAGER模式;
@ManyToOne(fetch = FetchType.EAGER)
@JsonBackReference //此注解防止JSON死循环
private UserInfo userInfo;
}
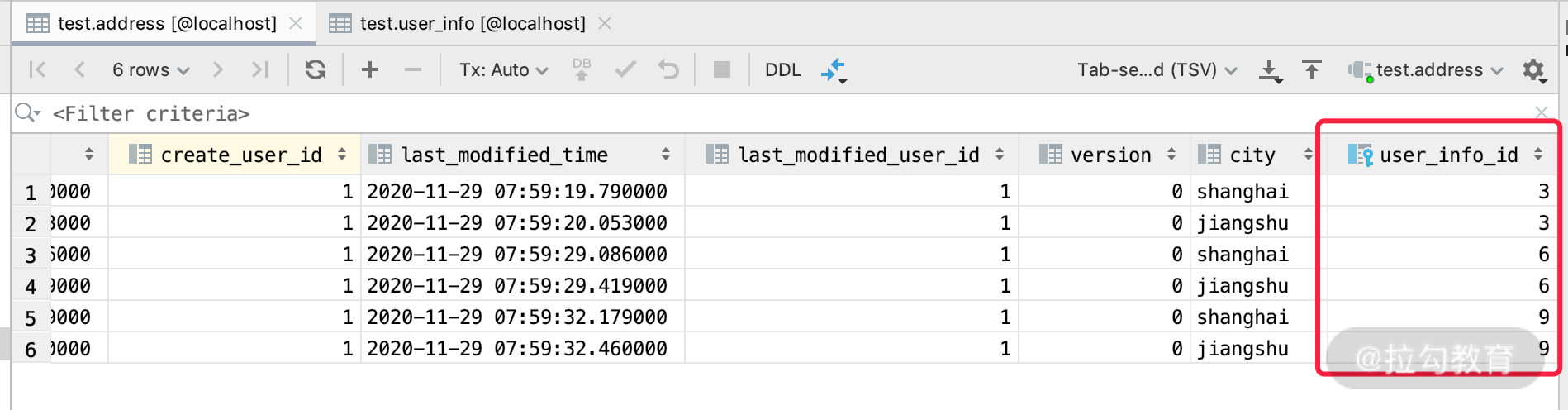
其次,我们假设数据库里面有三条 UserInfo 的数据,ID 分别为 3、6、9,如下图所示。

其中,每个 UserInfo 分别有两条 Address 数据,也就是一共 6 条 Address 的数据,如下图所示。
然后,我们请求通过 UserInfoRepository 查询所有的 UserInfo 信息,方法如下面这行代码所示。
userInfoRepository.findAll()
现在,我们的控制台将会得到四个 SQL,如下所示。
org.hibernate.SQL :
select userinfo0_.id as id1_1_,
userinfo0_.create_time as create_t2_1_,
userinfo0_.create_user_id as create_u3_1_,
userinfo0_.last_modified_time as last_mod4_1_,
userinfo0_.last_modified_user_id as last_mod5_1_,
userinfo0_.version as version6_1_,
userinfo0_.ages as ages7_1_,
userinfo0_.email_address as email_ad8_1_,
userinfo0_.last_name as last_nam9_1_,
userinfo0_.name as name10_1_,
userinfo0_.telephone as telepho11_1_
from user_info userinfo0_ org.hibernate.SQL :
select addresslis0_.user_info_id as user_inf8_0_0_,
addresslis0_.id as id1_0_0_,
addresslis0_.id as id1_0_1_,
addresslis0_.create_time as create_t2_0_1_,
addresslis0_.create_user_id as create_u3_0_1_,
addresslis0_.last_modified_time as last_mod4_0_1_,
addresslis0_.last_modified_user_id as last_mod5_0_1_,
addresslis0_.version as version6_0_1_,
addresslis0_.city as city7_0_1_,
addresslis0_.user_info_id as user_inf8_0_1_
from address addresslis0_
where addresslis0_.user_info_id = ? org.hibernate.SQL :
select addresslis0_.user_info_id as user_inf8_0_0_,
addresslis0_.id as id1_0_0_,
addresslis0_.id as id1_0_1_,
addresslis0_.create_time as create_t2_0_1_,
addresslis0_.create_user_id as create_u3_0_1_,
addresslis0_.last_modified_time as last_mod4_0_1_,
addresslis0_.last_modified_user_id as last_mod5_0_1_,
addresslis0_.version as version6_0_1_,
addresslis0_.city as city7_0_1_,
addresslis0_.user_info_id as user_inf8_0_1_
from address addresslis0_
where addresslis0_.user_info_id = ? org.hibernate.SQL :
select addresslis0_.user_info_id as user_inf8_0_0_,
addresslis0_.id as id1_0_0_,
addresslis0_.id as id1_0_1_,
addresslis0_.create_time as create_t2_0_1_,
addresslis0_.create_user_id as create_u3_0_1_,
addresslis0_.last_modified_time as last_mod4_0_1_,
addresslis0_.last_modified_user_id as last_mod5_0_1_,
addresslis0_.version as version6_0_1_,
addresslis0_.city as city7_0_1_,
addresslis0_.user_info_id as user_inf8_0_1_
from address addresslis0_
where addresslis0_.user_info_id = ?
通过 SQL 我们可以看得出来,当取 UserInfo 的时候,有多少条 UserInfo 数据就会触发多少条查询 Address 的 SQL。
那么所谓的 N+1 的 SQL,此时 1 代表的是一条 SQL 查询 UserInfo 信息;N 条 SQL 查询 Address 的信息。你可以想象一下,如果有 100 条 UserInfo 信息,可能会触发 100 条查询 Address 的 SQL,性能多差呀。
很简单,这就是我们常说的 N+1 SQL 问题。我们这里使用的是 EAGER 模式,当使用 LAZY 的时候也是一样的道理,只是生成 N 条 SQL 的时机是不一样的。
上面我演示了 @OneToMany 的情况,那么我们再看一下 @ManyToOne 的情况。利用 AddressRepository 查询所有的 Address 信息,方法如下面这行代码所示。
addressRepository.findAll();
这个时候我们再看一下控制台,会产生如下 SQL。
org.hibernate.SQL :
select address0_.id as id1_0_,
address0_.create_time as create_t2_0_,
address0_.create_user_id as create_u3_0_,
address0_.last_modified_time as last_mod4_0_,
address0_.last_modified_user_id as last_mod5_0_,
address0_.version as version6_0_,
address0_.city as city7_0_,
address0_.user_info_id as user_inf8_0_
from address address0_
org.hibernate.SQL :
select userinfo0_.id as id1_1_0_,
userinfo0_.create_time as create_t2_1_0_,
userinfo0_.create_user_id as create_u3_1_0_,
userinfo0_.last_modified_time as last_mod4_1_0_,
userinfo0_.last_modified_user_id as last_mod5_1_0_,
userinfo0_.version as version6_1_0_,
userinfo0_.ages as ages7_1_0_,
userinfo0_.email_address as email_ad8_1_0_,
userinfo0_.last_name as last_nam9_1_0_,
userinfo0_.name as name10_1_0_,
userinfo0_.telephone as telepho11_1_0_,
addresslis1_.user_info_id as user_inf8_0_1_,
addresslis1_.id as id1_0_1_,
addresslis1_.id as id1_0_2_,
addresslis1_.create_time as create_t2_0_2_,
addresslis1_.create_user_id as create_u3_0_2_,
addresslis1_.last_modified_time as last_mod4_0_2_,
addresslis1_.last_modified_user_id as last_mod5_0_2_,
addresslis1_.version as version6_0_2_,
addresslis1_.city as city7_0_2_,
addresslis1_.user_info_id as user_inf8_0_2_
from user_info userinfo0_
left outer join address addresslis1_ on userinfo0_.id = addresslis1_.user_info_id
where userinfo0_.id = ?
org.hibernate.SQL :
select userinfo0_.id as id1_1_0_,
userinfo0_.create_time as create_t2_1_0_,
userinfo0_.create_user_id as create_u3_1_0_,
userinfo0_.last_modified_time as last_mod4_1_0_,
userinfo0_.last_modified_user_id as last_mod5_1_0_,
userinfo0_.version as version6_1_0_,
userinfo0_.ages as ages7_1_0_,
userinfo0_.email_address as email_ad8_1_0_,
userinfo0_.last_name as last_nam9_1_0_,
userinfo0_.name as name10_1_0_,
userinfo0_.telephone as telepho11_1_0_,
addresslis1_.user_info_id as user_inf8_0_1_,
addresslis1_.id as id1_0_1_,
addresslis1_.id as id1_0_2_,
addresslis1_.create_time as create_t2_0_2_,
addresslis1_.create_user_id as create_u3_0_2_,
addresslis1_.last_modified_time as last_mod4_0_2_,
addresslis1_.last_modified_user_id as last_mod5_0_2_,
addresslis1_.version as version6_0_2_,
addresslis1_.city as city7_0_2_,
addresslis1_.user_info_id as user_inf8_0_2_
from user_info userinfo0_
left outer join address addresslis1_ on userinfo0_.id = addresslis1_.user_info_id
where userinfo0_.id = ?
org.hibernate.SQL :
select userinfo0_.id as id1_1_0_,
userinfo0_.create_time as create_t2_1_0_,
userinfo0_.create_user_id as create_u3_1_0_,
userinfo0_.last_modified_time as last_mod4_1_0_,
userinfo0_.last_modified_user_id as last_mod5_1_0_,
userinfo0_.version as version6_1_0_,
userinfo0_.ages as ages7_1_0_,
userinfo0_.email_address as email_ad8_1_0_,
userinfo0_.last_name as last_nam9_1_0_,
userinfo0_.name as name10_1_0_,
userinfo0_.telephone as telepho11_1_0_,
addresslis1_.user_info_id as user_inf8_0_1_,
addresslis1_.id as id1_0_1_,
addresslis1_.id as id1_0_2_,
addresslis1_.create_time as create_t2_0_2_,
addresslis1_.create_user_id as create_u3_0_2_,
addresslis1_.last_modified_time as last_mod4_0_2_,
addresslis1_.last_modified_user_id as last_mod5_0_2_,
addresslis1_.version as version6_0_2_,
addresslis1_.city as city7_0_2_,
addresslis1_.user_info_id as user_inf8_0_2_
from user_info userinfo0_
left outer join address addresslis1_ on userinfo0_.id = addresslis1_.user_info_id
where userinfo0_.id = ?
这里通过 SQL 我们可以看得出来,当取 Address 的时候,Address 里面有多少个 user_info_id,就会触发多少条查询 UserInfo 的 SQL。
那么所谓的 N+1 的 SQL,此时 1 就代表一条 SQL 查询 Address 信息;N 条 SQL 查询 UserInfo 的信息。同样,你可以想象一下,如果我们有 100 条 Address 信息,分别有不同的 user_info_id 可能会触发 100 条查询 UserInfo 的 SQL,性能依然很差。
这也是我们常说的 N+1 SQL 问题,我只是给你演示了 @OneToMany 和 @ManyToOne 的情况,@ManyToMany 和 @OneToOne 也是一样的道理,都是当我们查询主体信息时候,1 条 SQL 会衍生出来关联关系的 N 条 SQL。
现在你认识了这个问题,下一步该思考,怎么解决才更合理呢?有没有什么办法可以减少 SQL 条数呢?
减少 N+1 SQL 的条数
最容易想到,就是有没有什么机制可以减少 N 对应的 SQL 条数呢?从原理分析会知道,不管是 LAZY 还是 EAGER 都是没有用的,因为这两个只是决定了 N 条 SQL 的触发时机,而不能减少 SQL 的条数。
不知道你是否还记得在第 20 讲(Spring JPA 中的 Hibernate 加载过程与配置项是怎么回事)中,我们介绍过的 Hibernate 的配置项有哪些,如果你回过头去看,会发现有个配置可以改变每次批量取数据的大小。
hibernate.default_batch_fetch_size 配置
hibernate.default_batch_fetch_size 配置在 AvailableSettings.class 里面,指的是批量获取数据的大小,默认是 -1,表示默认没有匹配取数据。那么我们把这个值改成 20 看一下效果,只需要在 application.properties 里面增加如下配置即可。
# 更改批量取数据的大小为20
spring.jpa.properties.hibernate.default_batch_fetch_size= 20
在实体类不发生任何改变的前提下,我们再执行如下两个方法,分别看一下 SQL 的生成情况。
userInfoRepository.findAll();
还是先查询所有的 UserInfo 信息,看一下 SQL 的执行情况,代码如下所示。
org.hibernate.SQL :
select userinfo0_.id as id1_1_,
userinfo0_.create_time as create_t2_1_,
userinfo0_.create_user_id as create_u3_1_,
userinfo0_.last_modified_time as last_mod4_1_,
userinfo0_.last_modified_user_id as last_mod5_1_,
userinfo0_.version as version6_1_,
userinfo0_.ages as ages7_1_,
userinfo0_.email_address as email_ad8_1_,
userinfo0_.last_name as last_nam9_1_,
userinfo0_.name as name10_1_,
userinfo0_.telephone as telepho11_1_
from user_info userinfo0_ org.hibernate.SQL :
select addresslis0_.user_info_id as user_inf8_0_1_,
addresslis0_.id as id1_0_1_,
addresslis0_.id as id1_0_0_,
addresslis0_.create_time as create_t2_0_0_,
addresslis0_.create_user_id as create_u3_0_0_,
addresslis0_.last_modified_time as last_mod4_0_0_,
addresslis0_.last_modified_user_id as last_mod5_0_0_,
addresslis0_.version as version6_0_0_,
addresslis0_.city as city7_0_0_,
addresslis0_.user_info_id as user_inf8_0_0_
from address addresslis0_
where addresslis0_.user_info_id in (?, ?, ?)
我们可以看到 SQL 直接减少到两条了,其中查询 Address 的地方查询条件变成了 in(?,?,?)。
想象一下,如果我们有 20 条 UserInfo 信息,那么产生的 SQL 也是两条,此时要比 20+1 条 SQL 性能高太多了。
接着我们再执行另一个方法,看一下 @ManyToOne 的情况,代码如下所示。
addressRepository.findAll()
关于执行的 SQL 情况如下所示。
2020-11-29 23:11:27.381 DEBUG 30870 --- [nio-8087-exec-5] org.hibernate.SQL :
select address0_.id as id1_0_,
address0_.create_time as create_t2_0_,
address0_.create_user_id as create_u3_0_,
address0_.last_modified_time as last_mod4_0_,
address0_.last_modified_user_id as last_mod5_0_,
address0_.version as version6_0_,
address0_.city as city7_0_,
address0_.user_info_id as user_inf8_0_
from address address0_
2020-11-29 23:11:27.383 DEBUG 30870 --- [nio-8087-exec-5] org.hibernate.SQL :
select userinfo0_.id as id1_1_0_,
userinfo0_.create_time as create_t2_1_0_,
userinfo0_.create_user_id as create_u3_1_0_,
userinfo0_.last_modified_time as last_mod4_1_0_,
userinfo0_.last_modified_user_id as last_mod5_1_0_,
userinfo0_.version as version6_1_0_,
userinfo0_.ages as ages7_1_0_,
userinfo0_.email_address as email_ad8_1_0_,
userinfo0_.last_name as last_nam9_1_0_,
userinfo0_.name as name10_1_0_,
userinfo0_.telephone as telepho11_1_0_,
addresslis1_.user_info_id as user_inf8_0_1_,
addresslis1_.id as id1_0_1_,
addresslis1_.id as id1_0_2_,
addresslis1_.create_time as create_t2_0_2_,
addresslis1_.create_user_id as create_u3_0_2_,
addresslis1_.last_modified_time as last_mod4_0_2_,
addresslis1_.last_modified_user_id as last_mod5_0_2_,
addresslis1_.version as version6_0_2_,
addresslis1_.city as city7_0_2_,
addresslis1_.user_info_id as user_inf8_0_2_
from user_info userinfo0_
left outer join address addresslis1_ on userinfo0_.id = addresslis1_.user_info_id
where userinfo0_.id in (?, ?, ?)
从代码中可以看到,我们查询所有的 Address 信息也只产生了 2 条 SQL;而当我们查询 UserInfo 的时候,SQL 最后的查询条件也变成了 in (?,?,?),同样的道理这样也会提升不少性能。
而 hibernate.default_batch_fetch_size 的经验参考值,可以设置成 20、30、50、100 等,太高了也没有意义。一个请求执行一次,产生的 SQL 数量为 3-5 条基本上都算合理情况,这样通过设置 default_batch_fetch_size 就可以很好地避免大部分业务场景下的 N+1 条 SQL 的性能问题了。
此时你还需要注意一点就是,在实际工作中,一定要知道我们一次操作会产生多少 SQL,有没有预期之外的 SQL 参数,这是需要关注的重点,这种情况可以利用我们之前说过的如下配置来开启打印 SQL,请看代码。
## 显示sql的执行日志,如果开了这个,show_sql就可以不用了,show_sql没有上下文,多线程情况下,分不清楚是谁打印的,所有我推荐如下配置项:
logging.level.org.hibernate.SQL=debug
但是这种配置也有个缺陷,就是只能全局配置,没办法针对不通过的实体管理关系配置不同的 Fetch Size 的值。
而与之类似的 Hibernate 里面也提供了一个注解 @BatchSize 可以解决此问题。
@BatchSize 注解
@BatchSize 注解是 Hibernate 提供的用来解决查询关联关系的批量处理大小,默认无,可以配置在实体上,也可以配置在关联关系上面。此注解里面只有一个属性 size,用来指定关联关系 LAZY 或者是 EAGER 一次性取数据的大小。
我们还是将上面的例子中的 UserInfo 实体做一下改造,在里面增加两次 @BatchSize 注解,代码如下所示。
@Entity
@Data
@SuperBuilder
@AllArgsConstructor
@NoArgsConstructor
@Table
@ToString(exclude = "addressList")
@BatchSize(size = 2)//实体类上加@BatchSize注解,用来设置当被关联关系的时候一次查询的大小,我们设置成2,方便演示Address关联UserInfo的时候的效果
public class UserInfo extends BaseEntity {
private String name;
private String telephone;
@OneToMany(mappedBy = "userInfo",cascade = CascadeType.PERSIST,fetch = FetchType.EAGER)
@BatchSize(size = 20)//关联关系的属性上加@BatchSize注解,用来设置当通过UserInfo加载Address的时候一次取数据的大小
private List<Address> addressList;
}
我们通过改造 UserInfo 实体,可以直接演示 @BatchSize 应用在实体类和属性字段上的效果,所以 Address 实体可以不做任何改变,hibernate.default_batch_fetch_size 还改成默认值 -1,我们再分别执行一下两个 findAll 方法,看一下效果。
第一种:查询所有 UserInfo,代码如下面这行所示。
userInfoRepository.findAll()
我们看一下 SQL 控制台。
org.hibernate.SQL :
select userinfo0_.id as id1_1_,
userinfo0_.create_time as create_t2_1_,
userinfo0_.create_user_id as create_u3_1_,
userinfo0_.last_modified_time as last_mod4_1_,
userinfo0_.last_modified_user_id as last_mod5_1_,
userinfo0_.version as version6_1_,
userinfo0_.ages as ages7_1_,
userinfo0_.email_address as email_ad8_1_,
userinfo0_.last_name as last_nam9_1_,
userinfo0_.name as name10_1_,
userinfo0_.telephone as telepho11_1_
from user_info userinfo0_ org.hibernate.SQL :
select addresslis0_.user_info_id as user_inf8_0_1_,
addresslis0_.id as id1_0_1_,
addresslis0_.id as id1_0_0_,
addresslis0_.create_time as create_t2_0_0_,
addresslis0_.create_user_id as create_u3_0_0_,
addresslis0_.last_modified_time as last_mod4_0_0_,
addresslis0_.last_modified_user_id as last_mod5_0_0_,
addresslis0_.version as version6_0_0_,
addresslis0_.city as city7_0_0_,
addresslis0_.user_info_id as user_inf8_0_0_
from address addresslis0_
where addresslis0_.user_info_id in (?, ?, ?)
和刚才设置 hibernate.default_batch_fetch_size=20 的效果一模一样,所以我们可以利用 @BatchSize 这个注解针对不同的关联关系,配置不同的大小,从而提升 N+1 SQL 的性能。
第二种:查询一下所有 Address,如下面这行代码所示。
addressRepository.findAll();
我们看一下控制台的 SQL 情况,如下所示。
org.hibernate.SQL :
select address0_.id as id1_0_,
address0_.create_time as create_t2_0_,
address0_.create_user_id as create_u3_0_,
address0_.last_modified_time as last_mod4_0_,
address0_.last_modified_user_id as last_mod5_0_,
address0_.version as version6_0_,
address0_.city as city7_0_,
address0_.user_info_id as user_inf8_0_
from address address0_
org.hibernate.SQL :
select userinfo0_.id as id1_1_0_,
userinfo0_.create_time as create_t2_1_0_,
userinfo0_.create_user_id as create_u3_1_0_,
userinfo0_.last_modified_time as last_mod4_1_0_,
userinfo0_.last_modified_user_id as last_mod5_1_0_,
userinfo0_.version as version6_1_0_,
userinfo0_.ages as ages7_1_0_,
userinfo0_.email_address as email_ad8_1_0_,
userinfo0_.last_name as last_nam9_1_0_,
userinfo0_.name as name10_1_0_,
userinfo0_.telephone as telepho11_1_0_,
addresslis1_.user_info_id as user_inf8_0_1_,
addresslis1_.id as id1_0_1_,
addresslis1_.id as id1_0_2_,
addresslis1_.create_time as create_t2_0_2_,
addresslis1_.create_user_id as create_u3_0_2_,
addresslis1_.last_modified_time as last_mod4_0_2_,
addresslis1_.last_modified_user_id as last_mod5_0_2_,
addresslis1_.version as version6_0_2_,
addresslis1_.city as city7_0_2_,
addresslis1_.user_info_id as user_inf8_0_2_
from user_info userinfo0_
left outer join address addresslis1_ on userinfo0_.id = addresslis1_.user_info_id
where userinfo0_.id in (?, ?)
org.hibernate.SQL :
select userinfo0_.id as id1_1_0_,
userinfo0_.create_time as create_t2_1_0_,
userinfo0_.create_user_id as create_u3_1_0_,
userinfo0_.last_modified_time as last_mod4_1_0_,
userinfo0_.last_modified_user_id as last_mod5_1_0_,
userinfo0_.version as version6_1_0_,
userinfo0_.ages as ages7_1_0_,
userinfo0_.email_address as email_ad8_1_0_,
userinfo0_.last_name as last_nam9_1_0_,
userinfo0_.name as name10_1_0_,
userinfo0_.telephone as telepho11_1_0_,
addresslis1_.user_info_id as user_inf8_0_1_,
addresslis1_.id as id1_0_1_,
addresslis1_.id as id1_0_2_,
addresslis1_.create_time as create_t2_0_2_,
addresslis1_.create_user_id as create_u3_0_2_,
addresslis1_.last_modified_time as last_mod4_0_2_,
addresslis1_.last_modified_user_id as last_mod5_0_2_,
addresslis1_.version as version6_0_2_,
addresslis1_.city as city7_0_2_,
addresslis1_.user_info_id as user_inf8_0_2_
from user_info userinfo0_
left outer join address addresslis1_ on userinfo0_.id = addresslis1_.user_info_id
where userinfo0_.id = ?
这里可以看到,由于我们在 UserInfo 的实体上设置了 @BatchSize(size = 2),表示所有关联关系到 UserInfo 的时候一次取两条数据,所以就会发现这次我查询 Address 加载 UserInfo 的时候,产生了 3 条 SQL。
其中通过关联关系查询 UserInfo 产生了 2 条 SQL,由于我们 UserInfo 在数据库里面有三条数据,所以第一条 UserInfo 的 SQL 受 @BatchSize(size = 2) 控制,从而 in (?,?) 只支持了两个参数,同时也产生了第二条查 UserInfo 的 SQL。
从上面的例子中我们可以看到 @BatchSize 和 hibernate.default_batch_fetch_size 的效果是一样的,只不过一个是全局配置、一个是局部设置,这是可以减少 N+1 SQL 最直接、最方便的两种方式。
注意事项:
@BatchSize 的使用具有局限性,不能作用于 @ManyToOne 和 @OneToOne 的关联关系上,那样代码是不起作用的,如下所示。
public class Address extends BaseEntity {
private String city;
@ManyToOne(cascade = CascadeType.PERSIST,fetch = FetchType.EAGER)
@BatchSize(size = 30) //由于是@ManyToOne的关联关系所有没有作用
private UserInfo userInfo;
}
因此,你要注意 @BatchSize 只能作用在 @ManyToMany、@OneToMany、实体类这三个地方。
此外,Hibernate 中还提供了一种 FetchMode 的策略,包含三种模式,分别为 FetchMode.SELECT、FetchMode.JOIN,以及 FetchMode.Subselect。由于内容较多,我怕你一次性不好消化,所以会在下一讲继续为你介绍。到时见。
26 经典的 N+1 SQL 问题如何正确解决?(下)
你好,上一讲我们介绍了什么是 N+1 的 SQL 问题,以及减少 N 对应 SQL 条数的机制有哪些,相信你对此已经有了大概的了解。那么这一讲我们接着说这个经典的 SQL 问题,看看还有没有其他的解决方式。
Hibernate 中 @Fetch 数据的策略
Hibernate 提供了一个 @Fetch 注解,用来改变获取数据的策略。我们来研究一下这一注解的语法,代码如下所示。
// fetch注解只能用在方法和字段上面
@Target({ElementType.METHOD, ElementType.FIELD})
@Retention(RetentionPolicy.RUNTIME)
public @interface Fetch {
//注解里面,只有一个属性获取数据的模式
FetchMode value();
}
//其中FetchMode的值有如下几种:
public enum FetchMode {
//默认模式,就是会有N+1 sql的问题;
SELECT,
//通过join的模式,用一个sql把主体数据和关联关系数据一口气查出来
JOIN,
//通过子查询的模式,查询关联关系的数据
SUBSELECT
}
需要注意的是,不要把这个注解和 JPA 协议里面的 FetchType.EAGER、FetchType.LAZY 搞混了,JPA 协议的关联关系中的 FetchTyp 解决的是取关联关系数据时机的问题,也就是说 EAGER 代表的是立即获得关联关系的数据,LAZY 是需要的时候再获得关联关系的数据。
这和 Hibernate 的 FetchMode 是两回事,FetchMode 解决的是获得数据策略的问题,也就是说,获得关联关系数据的策略有三种模式:SELECT(默认)、JOIN、SUBSELECT。下面我通过例子来分别介绍一下这三种模式有什么区别,分别起到什么作用。
FetchMode.SELECT
我们直接更改一下 UserInfo 实体,将 @Fetch(value = FetchMode.SELECT) 作为获取数据的策略,使用 FetchType.EAGER 作为获取数据的时机,代码如下所示。
@Entity
@Data
@SuperBuilder
@AllArgsConstructor
@NoArgsConstructor
@Table
@ToString(exclude = "addressList")
public class UserInfo extends BaseEntity {
private String name;
private String telephone;
@OneToMany(mappedBy = "userInfo",cascade = CascadeType.PERSIST,fetch = FetchType.EAGER)
@Fetch(value = FetchMode.SELECT)
private List<Address> addressList;
}
然后还是执行 userInfoRepository.findAll(); 这个方法,看一下打印的 SQL 有哪些。
org.hibernate.SQL :
select userinfo0_.id as id1_1_,
userinfo0_.create_time as create_t2_1_,
userinfo0_.create_user_id as create_u3_1_,
userinfo0_.last_modified_time as last_mod4_1_,
userinfo0_.last_modified_user_id as last_mod5_1_,
userinfo0_.version as version6_1_,
userinfo0_.ages as ages7_1_,
userinfo0_.email_address as email_ad8_1_,
userinfo0_.last_name as last_nam9_1_,
userinfo0_.name as name10_1_,
userinfo0_.telephone as telepho11_1_
from user_info userinfo0_
org.hibernate.SQL :
select addresslis0_.user_info_id as user_inf8_0_0_,
addresslis0_.id as id1_0_0_,
addresslis0_.id as id1_0_1_,
addresslis0_.create_time as create_t2_0_1_,
addresslis0_.create_user_id as create_u3_0_1_,
addresslis0_.last_modified_time as last_mod4_0_1_,
addresslis0_.last_modified_user_id as last_mod5_0_1_,
addresslis0_.version as version6_0_1_,
addresslis0_.city as city7_0_1_,
addresslis0_.user_info_id as user_inf8_0_1_
from address addresslis0_
where addresslis0_.user_info_id = ?
org.hibernate.SQL :
select addresslis0_.user_info_id as user_inf8_0_0_,
addresslis0_.id as id1_0_0_,
addresslis0_.id as id1_0_1_,
addresslis0_.create_time as create_t2_0_1_,
addresslis0_.create_user_id as create_u3_0_1_,
addresslis0_.last_modified_time as last_mod4_0_1_,
addresslis0_.last_modified_user_id as last_mod5_0_1_,
addresslis0_.version as version6_0_1_,
addresslis0_.city as city7_0_1_,
addresslis0_.user_info_id as user_inf8_0_1_
from address addresslis0_
where addresslis0_.user_info_id = ?
org.hibernate.SQL :
select addresslis0_.user_info_id as user_inf8_0_0_,
addresslis0_.id as id1_0_0_,
addresslis0_.id as id1_0_1_,
addresslis0_.create_time as create_t2_0_1_,
addresslis0_.create_user_id as create_u3_0_1_,
addresslis0_.last_modified_time as last_mod4_0_1_,
addresslis0_.last_modified_user_id as last_mod5_0_1_,
addresslis0_.version as version6_0_1_,
addresslis0_.city as city7_0_1_,
addresslis0_.user_info_id as user_inf8_0_1_
from address addresslis0_
where addresslis0_.user_info_id = ?
从上述 SQL 中可以看出,这依然是 N+1 的 SQL 问题,FetchMode.Select 是默认策略,加与不加是同样的效果,代表获取关系的时候新开一个 SQL 进行查询。
FetchMode.JOIN
FetchMode.JOIN 的意思是主表信息和关联关系通过一个 SQL JOIN 的方式查出来,我们看一下例子。
首先,将 UserInfo 里面的 FetchMode 改成 JOIN 模式,关键代码如下。
public class UserInfo extends BaseEntity {
private String name;
private String telephone;
@OneToMany(mappedBy = "userInfo",cascade = CascadeType.PERSIST,fetch = FetchType.EAGER)
@Fetch(value = FetchMode.JOIN) //唯一变化的地方采用JOIN模式
private List<Address> addressList;
}
然后,调用一下 userInfoRepository.findAll(); 这个方法,发现依然是这三条 SQL,如下图所示。

这是因为 FetchMode.JOIN 只支持通过 ID 或者联合唯一键获取数据才有效,这正是 JOIN 策略模式的局限性所在。
那么我们再调用一下 userInfoRepository.findById(id),看看控制台的 SQL 执行情况,代码如下。
select userinfo0_.id as id1_1_0_,
userinfo0_.create_time as create_t2_1_0_,
userinfo0_.create_user_id as create_u3_1_0_,
userinfo0_.last_modified_time as last_mod4_1_0_,
userinfo0_.last_modified_user_id as last_mod5_1_0_,
userinfo0_.version as version6_1_0_,
userinfo0_.ages as ages7_1_0_,
userinfo0_.email_address as email_ad8_1_0_,
userinfo0_.last_name as last_nam9_1_0_,
userinfo0_.name as name10_1_0_,
userinfo0_.telephone as telepho11_1_0_,
addresslis1_.user_info_id as user_inf8_0_1_,
addresslis1_.id as id1_0_1_,
addresslis1_.id as id1_0_2_,
addresslis1_.create_time as create_t2_0_2_,
addresslis1_.create_user_id as create_u3_0_2_,
addresslis1_.last_modified_time as last_mod4_0_2_,
addresslis1_.last_modified_user_id as last_mod5_0_2_,
addresslis1_.version as version6_0_2_,
addresslis1_.city as city7_0_2_,
addresslis1_.user_info_id as user_inf8_0_2_
from user_info userinfo0_
left outer join address addresslis1_ on userinfo0_.id = addresslis1_.user_info_id
where userinfo0_.id = ?
这时我们会发现,当查询 UserInfo 的时候,它会通过 left outer join 把 Address 的信息也查询出来,虽然 SQL 上会有冗余信息,但是你会发现我们之前的 N+1 的 SQL 直接变成 1 条 SQL 了。
此时我们修改 UserInfo 里面的 @OneToMany,这个 @Fetch(value = FetchMode.JOIN) 同样适用于 @ManyToOne;然后再改一下 Address 实例,用 @Fetch(value = FetchMode.JOIN) 把 Adress 里面的 UserInfo 关联关系改成 JOIN 模式;接着我们用 LAZY 获取数据的时机,会发现其对获取数据的策略没有任何影响。
这里我只是给你演示获取数据时机的不同情况,关键代码如下。
@Entity
@Table
@Data
@SuperBuilder
@AllArgsConstructor
@NoArgsConstructor
@ToString(exclude = "userInfo")
public class Address extends BaseEntity {
private String city;
@ManyToOne(cascade = CascadeType.PERSIST,fetch = FetchType.LAZY)
@JsonBackReference
@Fetch(value = FetchMode.JOIN)
private UserInfo userInfo;
}
同样的道理,JOIN 对列表性的查询是没有效果的,我们调用一下 addressRepository.findById(id),产生的 SQL 如下所示。
org.hibernate.SQL :
select address0_.id as id1_0_0_,
address0_.create_time as create_t2_0_0_,
address0_.create_user_id as create_u3_0_0_,
address0_.last_modified_time as last_mod4_0_0_,
address0_.last_modified_user_id as last_mod5_0_0_,
address0_.version as version6_0_0_,
address0_.city as city7_0_0_,
address0_.user_info_id as user_inf8_0_0_,
userinfo1_.id as id1_1_1_,
userinfo1_.create_time as create_t2_1_1_,
userinfo1_.create_user_id as create_u3_1_1_,
userinfo1_.last_modified_time as last_mod4_1_1_,
userinfo1_.last_modified_user_id as last_mod5_1_1_,
userinfo1_.version as version6_1_1_,
userinfo1_.ages as ages7_1_1_,
userinfo1_.email_address as email_ad8_1_1_,
userinfo1_.last_name as last_nam9_1_1_,
userinfo1_.name as name10_1_1_,
userinfo1_.telephone as telepho11_1_1_
from address address0_
left outer join user_info userinfo1_ on address0_.user_info_id = userinfo1_.id
where address0_.id = ?
我们发现此时只会产生一个 SQL,即通过 from address left outer join user_info 一次性把所有信息都查出来,然后 Hibernate 再根据查询出来的结果组合到不同的实体里面。
也就是说 FetchMode.JOIN 对于关联关系的查询 LAZY 是不起作用的,因为 JOIN 的模式是通过一条 SQL 查出来所有信息,所以 FetchMode.JOIN 会忽略 FetchType。
那么我们再来看第三种模式。
FetchMode.SUBSELECT
这种模式很简单,就是将关联关系通过子查询的形式查询出来,我们还是结合例子来理解一下。
首先,将 UserInfo 里面的关联关系改成 @Fetch(value = FetchMode.SUBSELECT),关键代码如下。
public class UserInfo extends BaseEntity {
@OneToMany(mappedBy = "userInfo",cascade = CascadeType.PERSIST,fetch = FetchType.LAZY) //我们这里测试一下LAZY情况
@Fetch(value = FetchMode.SUBSELECT) //唯一变化之处
private List<Address> addressList;
}
接着,像上面的做法一样,执行一下 userInfoRepository.findAll();方法,看一下控制台的 SQL 情况,如下所示。
org.hibernate.SQL :
select userinfo0_.id as id1_1_,
userinfo0_.create_time as create_t2_1_,
userinfo0_.create_user_id as create_u3_1_,
userinfo0_.last_modified_time as last_mod4_1_,
userinfo0_.last_modified_user_id as last_mod5_1_,
userinfo0_.version as version6_1_,
userinfo0_.ages as ages7_1_,
userinfo0_.email_address as email_ad8_1_,
userinfo0_.last_name as last_nam9_1_,
userinfo0_.name as name10_1_,
userinfo0_.telephone as telepho11_1_
from user_info userinfo0_
org.hibernate.SQL :
select addresslis0_.user_info_id as user_inf8_0_1_,
addresslis0_.id as id1_0_1_,
addresslis0_.id as id1_0_0_,
addresslis0_.create_time as create_t2_0_0_,
addresslis0_.create_user_id as create_u3_0_0_,
addresslis0_.last_modified_time as last_mod4_0_0_,
addresslis0_.last_modified_user_id as last_mod5_0_0_,
addresslis0_.version as version6_0_0_,
addresslis0_.city as city7_0_0_,
addresslis0_.user_info_id as user_inf8_0_0_
from address addresslis0_
where addresslis0_.user_info_id in (select userinfo0_.id from user_info userinfo0_)
这个时候会发现,查询 Address 信息是直接通过 addresslis0_.user_info_id in (select userinfo0_.id from user_info userinfo0_) 子查询的方式进行的,也就是说 N+1 SQL 变成了 1+1 的 SQL,这有点类似我们配置 @BatchSize 的效果。
FetchMode.SUBSELECT 支持 ID 查询和各种条件查询,唯一的缺点是只能配置在 @OneToMany 和 @ManyToMany 的关联关系上,不能配置在 @ManyToOne 和 @OneToOne 的关联关系上,所以我们在 Address 里面关联 UserInfo 的时候就没有办法做实验了。
总之,@Fetch 的不同模型,都有各自的优缺点:FetchMode.SELECT 默认,和不配置的效果一样;FetchMode.JOIN 只支持类似 findById(id) 的方法,只能根据 ID 查询才有效果;FetchMode.SUBSELECT 虽然不限使用方式,但是只支持 **ToMany 的关联关系。
所以你在使用 @Fetch 的时候需要注意一下它的局限性,我个人是比较推荐 @BatchSize 的方式。
那么除了上面的处理方式,我们也可以采用之前写 Mybatis 的思路来查询关联关系,下面来看一下该如何转变思路。
转化解决问题的思路
这时需要我们在思想上进行转变,利用 JPA 的优势,摒弃它的缺陷。想想我们没有用 JPA 的时候是怎么做的?难道一定要用实体之间的关联关系吗?如果用的是 Mybatis,你在给前端返回关联关系数据的时候一般怎么写呢?
答案肯定是写成 1+1 SQL 的形式,也就是一条主 SQL、一条查关联关系的 SQL。我们还用 UserInfo 和 Address 实体来演示,代码如下。
@Entity
@Data
@SuperBuilder
@AllArgsConstructor
@NoArgsConstructor
@Table
public class UserInfo extends BaseEntity {
private String name;
private String telephone;
@Transient //在UserInfo实体中,我们不利用JPA来关联实体的关联关系了,而是把它设置成@Transisent,只维护java对象的关系,不维护DB之间的关联关系
private List<Address> addressList;
}
@Entity
@Table
@Data
@SuperBuilder
@AllArgsConstructor
@NoArgsConstructor
@ToString(exclude = "userInfo")
public class Address extends BaseEntity {
private String city;
private String userId;
@Transient //同样Address里面也可以不维护UserInfo的关联关系
private UserInfo userInfo;
}
当我们查询所有 UserInfo 信息的时候,又想把每个 UserInfo 的 Address 信息都带上,应该怎么做呢?请看如下代码。
/**
* 自己实现一套 Batch fetch的逻辑
*/
@Transactional
public List<UserInfo> getAllUserWithAddress() {
//先查出来所有的UserInfo信息
List<UserInfo> userInfos = userInfoRepository.findAll();
//再查出来上面userInfos里面的所有userId列表,再查询出来上面的查询结果所对应的所有Address信息
List<Address> addresses = addressRepository.findByUserIdIn(userInfos.stream().map(userInfo -> userInfo.getId()).collect(Collectors.toList()));
//我们自己再写一个转化逻辑,把各自user info的address信息放置到响应的UserInfo实例里面;
Map<Long,List<Address>> addressMaps = addresses
.stream()
.collect(Collectors.groupingBy(Address::getUserId));//里面Map结构方便获取
return userInfos.stream().map(userInfo -> {
userInfo.setAddressList(addressMaps.get(userInfo.getId()));
return userInfo;
}).collect(Collectors.toList());
}
你会发现,这要比原来的方式稍微复杂一点,但是如果我们做框架的话,上面有些逻辑可以抽到一个 Util 类里面去。
不过需要注意的是,实际工作中我们肯定不是 findAll(),而是会根据一些业务逻辑查询一个 UserInfo 的 List 信息,然后再根据查询出来的 userInfo 的 ID 列表去二次查询 Address 信息,这样最多只需要 2 个 SQL 就可完成实际业务逻辑。
那么反向思考,我们通过 Address 对象查询 UserInfo 也是一样的道理,可以先查询出 List<Address>,再查询出 List<Address>里面包含的所有 UserInfoId 列表,然后再去查询 UserInfo 信息,通过 Map 组装到 Address 里面。
Tips:实体里面如果关联关系有非常多的请求,想维护关联关系是一件非常难的事情。我们可以利用 Mybatis 的思想、JPA 的快捷查询语法,来组装想要的任何关联关系的对象。这样的代码虽然比起原生的 JPA 语法较复杂,但是比起 Mybatis 还是要简单很多,理解起来也更容易,问题反倒会更少一点。
上面我们介绍完了 Hibernate 中的做法,其实 JPA 协议也提供了另外一种解题思路:利用 @EntityGraph 注解来解决,我们详细看一下。
@EntityGraph 使用详解
众所周知,实体与实体之间的关联关系错综复杂,就像一个大网图一样,网状分布交叉引用。而 JPA 协议在 2.1 版本之后企图用 Entity Graph 的方式,描绘出一个实体与实体之间的关联关系。
普通做法为,通过 @ManyToOne/@OneToMany/@ManyToMany/@OneToOne 这些关联关系注解表示它们之间的关系时,只能配置 EAGER 或者 LAZY,没办法根据不同的配置、不同的关联关系加载时机。
而 JPA 协议企图通过 @NamedEntityGraph 注解来描述实体之间的关联关系,当被 @EntityGraph 使用的时候进行 EAGER 加载,以减少 N+1 的 SQL,我们来看一下具体用法。
@NamedEntityGraph 和 @EntityGraph 用法
还是直接通过一个例子来说明,请看下面的代码。
//可以被@NamedEntityGraphs注解重复使用,只能配置在类上面,用来声明不同的EntityGraph;
@Repeatable(NamedEntityGraphs.class)
@Target({TYPE})
@Retention(RUNTIME)
public @interface NamedEntityGraph {
//指定一个名字
String name() default "";
//哪些关联关系属性可以被EntityGraph包含进去,默认一个没有。可以配置多个
NamedAttributeNode[] attributeNodes() default {};
<span class="hljs-comment">//是否所有的关联关系属性自动包含在内,默认false;</span>
<span class="hljs-function"><span class="hljs-keyword">boolean</span> <span class="hljs-title">includeAllAttributes</span><span class="hljs-params">()</span> <span class="hljs-keyword">default</span> <span class="hljs-keyword">false</span></span>;
<span class="hljs-comment">//配置subgraphs,子实体图(可以理解为关联关系实体图,即如果算层级,可以配置第二层级),可以被NamedAttributeNode引用</span>
NamedSubgraph[] subgraphs() <span class="hljs-keyword">default</span> {};
<span class="hljs-comment">//配置subclassSubgraphs的namedSubgraph有哪些。即如果算层级,可以配置第三层级</span>
NamedSubgraph[] subclassSubgraphs() <span class="hljs-keyword">default</span> {};
}
上述代码中,可以看到 @NamedEntityGraphs 能够配置多个 @NamedEntityGraph。我们接着往下看。
//只能使用在实体类上面
@Target({TYPE})
@Retention(RUNTIME)
public @interface NamedEntityGraphs{
NamedEntityGraph[] value();//可以同时指定多个NamedEntityGraph
}
上面这段代码中,NamedSubgraph 用来指定关联关系的策略,也就关联关系有两层。
我们再看一下 @NamedEntityGraph 里面的 NamedAttributeNode 属性有哪些值,代码如下。
// 用来进行属性节点的描述
@Target({})
@Retention(RUNTIME)
public @interface NamedAttributeNode {
//要包含的关联关系的属性的名字,必填
String value();
//如果我们在@NamedEntityGraph里面配置了子关联关系,这个是配置subgraph的名字
String subgraph() default "";
//当关联关系是被Map结构引用的时候,我们可以指定key的方式,一般很少用
String keySubgraph() default "";
}
上面就是对 @NamedAttributeNode 的介绍,我们再看一下 @EntityGraph 里面的 @NamedSubgraph 的结构,代码如下。
@Target({})
@Retention(RUNTIME)
public @interface NamedSubgraph {
//指定一个名字
String name();
//子关联关系的类的class
Class type() default void.class;
//二层关联关系的要包含的关联关系的属性的名字
NamedAttributeNode[] attributeNodes();
}
其中,@NamedEntityGraph 的注解都是配置在实体本身上面的,而 @EntityGraph 是用在 ***Repository 接口里的方法中的。
接着我们再来了解一下 @EntityGraph 注解的语法,如下所示。
@Retention(RetentionPolicy.RUNTIME)
@Target({ ElementType.METHOD, ElementType.ANNOTATION_TYPE })
//EntityGraph 作用在Repository的接口里面的方法上面
public @interface EntityGraph {
//指@EntityGraph注解引用的@NamedEntityGraph里面定义的name,如果是空EntityGraph就不会起作用,如果为空相当于没有配置;
String value() default "";
//EntityGraph的类型,默认是EntityGraphType.FETCH类型,我们接着往下看EntityGraphType一共有几个值
EntityGraphType type() default EntityGraphType.FETCH;
//可以指定attributePaths用来覆盖@NamedEntityGraph里面的attributeNodes的配置,默认配置是空,以@NamedEntityGraph里面的为准;
String[] attributePaths() default {};
//JPA 2.1支持的EntityGraphType对应的枚举值
public enum EntityGraphType {
//LOAD模式,当被指定了这种模式、被@EntityGraph管理的attributes的时候,原来的FetchType的类型直接忽略变成Eager模式,而不被@EntityGraph管理的attributes还是保持默认的FetchType
LOAD("javax.persistence.loadgraph"),
//FETCH模式,当被指定了这种模式、被@EntityGraph管理的attributes的时候,原来的FetchType的类型直接忽略变成Eager模式,而不被@EntityGraph管理的attributes将会变成Lazy模式,和LOAD的区别就是对不被@NamedEntityGraph配置的关联关系的属性的FetchType不一样;
FETCH("javax.persistence.fetchgraph");
private final String key;
private EntityGraphType(String value) {
this.key = value;
}
public String getKey() {
return key;
}
}
}
现在你知道这个注解的基本用法了,下面我们通过实例来具体操作一下。
@EntityGraph 使用实例
我们通过改造 Address 和 UserInfo 实体,来分别测试一下 @NamedEntityGraph 和 @EntityGraph 的用法。
第一步:在实体里面配置 @EntityGraph,关键代码如下。
@Entity
@Table
@Data
@SuperBuilder
@AllArgsConstructor
@NoArgsConstructor
@ToString(exclude = "userInfo")
//这里我们直接使用@NamedEntityGraph,因为只需要配置一个@NamedEntityGraph,我们指定一个名字getAllUserInfo,指定被这个名字的实体试图关联的关联关系属性是userInfo
@NamedEntityGraph(name = "getAllUserInfo",attributeNodes = @NamedAttributeNode(value = "userInfo"))
public class Address extends BaseEntity {
private String city;
@JsonBackReference //防止JSON死循环
@ManyToOne(cascade = CascadeType.PERSIST,fetch = FetchType.LAZY)//采用默认的lazy模式
private UserInfo userInfo;
}
@Entity
@Data
@SuperBuilder
@AllArgsConstructor
@NoArgsConstructor
@Table
@ToString(exclude = "addressList")
//UserInfo对应的关联关系,我们利用@NamedEntityGraphs配置了两个,一个是针对Address的关联关系,一个是name叫rooms的实体图包含了rooms属性;我们在UserInfo里面增加了两个关联关系;
@NamedEntityGraphs(value = {@NamedEntityGraph(name = "addressGraph",attributeNodes = @NamedAttributeNode(value = "addressList")),@NamedEntityGraph(name = "rooms",attributeNodes = @NamedAttributeNode(value = "rooms"))})
public class UserInfo extends BaseEntity {
private String name;
private String telephone;
private Integer ages;
//默认LAZY模式
@OneToMany(mappedBy = "userInfo",cascade = CascadeType.PERSIST,fetch = FetchType.LAZY)
private List<Address> addressList;
//默认EAGER模式
@OneToMany(cascade = CascadeType.PERSIST,fetch = FetchType.EAGER)
private List<Room> rooms;
}
**第二步:在我们需要的 *Repository 的方法上面直接使用 @EntityGraph,关键代码如下。
//因为要用findAll()做测试,所以可以覆盖JpaRepository里面的findAll()方法,加上@EntityGraph注解
public interface UserInfoRepository extends JpaRepository<UserInfo, Long>{
@Override
//我们指定EntityGraph引用的是,在UserInfo实例里面配置的name=addressGraph的NamedEntityGraph;
// 这里采用的是LOAD的类型,也就是说被addressGraph配置的实体图属性address采用的fetch会变成 FetchType.EAGER模式,而没有被addressGraph实体图配置关联关系属性room还是采用默认的EAGER模式
@EntityGraph(value = "addressGraph",type = EntityGraph.EntityGraphType.LOAD)
List<UserInfo> findAll();
}}
同样的道理,其对于 AddressRepository 也是适用的,代码如下。
public interface AddressRepository extends JpaRepository<Address, Long>{
@Override //可以覆盖原始方法,添加上不同的@EntityGraph策略
//使用@EntityGraph查询所有Address的时候,指定name = "getAllUserInfo"的@NamedEntityGraph,采用默认的EntityGraphType.FETCH,如果Address里面有多个关联关系的时候,只有在name = "getAllUserInfo"的实体图配置的userInfo属性上采用Eager模式,其他关联关系属性没有指定,默认采用LAZY模式;
@EntityGraph(value = "getAllUserInfo")
List<Address> findAll();
}
第三步:看一下上面的两个方法执行的 SQL。
当我们再次执行 userInfoRepository.findAll(); 这个方法的时候会发现,被配置 EntityGraph 的 Address 和 user_info 通过 left join 一条 SQL 就把所有的信息都查出来了,SQL 如下所示。
org.hibernate.SQL :
select userinfo0_.id as id1_2_0_,
addresslis1_.id as id1_0_1_,
userinfo0_.create_time as create_t2_2_0_,
userinfo0_.create_user_id as create_u3_2_0_,
userinfo0_.last_modified_time as last_mod4_2_0_,
userinfo0_.last_modified_user_id as last_mod5_2_0_,
userinfo0_.version as version6_2_0_,
userinfo0_.ages as ages7_2_0_,
userinfo0_.email_address as email_ad8_2_0_,
userinfo0_.last_name as last_nam9_2_0_,
userinfo0_.name as name10_2_0_,
userinfo0_.telephone as telepho11_2_0_,
addresslis1_.create_time as create_t2_0_1_,
addresslis1_.create_user_id as create_u3_0_1_,
addresslis1_.last_modified_time as last_mod4_0_1_,
addresslis1_.last_modified_user_id as last_mod5_0_1_,
addresslis1_.version as version6_0_1_,
addresslis1_.city as city7_0_1_,
addresslis1_.user_info_id as user_inf8_0_1_,
addresslis1_.user_info_id as user_inf8_0_0__,
addresslis1_.id as id1_0_0__
from user_info userinfo0_
left outer join address addresslis1_ on userinfo0_.id = addresslis1_.user_info_id
而我们没有配置 rooms 这个关联关系的属性时,rooms 的查询还是会触发 N+1 的 SQL。
从中可以看到 @EntityGraph 的效果有点类似 Hibernate 里面提供的 FetchModel.JOIN 的模式,但不同的是 @EntityGraph 可以搭配任何的查询情况,只需要我们在查询方法上直接加 @EntityGraph 注解即可。
这种方法还有个优势就是 @EntityGraph 和 @NamedEntityGraph 是 JPA 协议规定的,这样可以对 Hibernate 无感。
那么我们再看一下 @ManyToOne 的模式是否同样奏效,访问 addressRepository.findAll() 这个方法看一下 SQL,如下所示。
org.hibernate.SQL :
select address0_.id as id1_0_0_,
userinfo1_.id as id1_2_1_,
address0_.create_time as create_t2_0_0_,
address0_.create_user_id as create_u3_0_0_,
address0_.last_modified_time as last_mod4_0_0_,
address0_.last_modified_user_id as last_mod5_0_0_,
address0_.version as version6_0_0_,
address0_.city as city7_0_0_,
address0_.user_info_id as user_inf8_0_0_,
userinfo1_.create_time as create_t2_2_1_,
userinfo1_.create_user_id as create_u3_2_1_,
userinfo1_.last_modified_time as last_mod4_2_1_,
userinfo1_.last_modified_user_id as last_mod5_2_1_,
userinfo1_.version as version6_2_1_,
userinfo1_.ages as ages7_2_1_,
userinfo1_.email_address as email_ad8_2_1_,
userinfo1_.last_name as last_nam9_2_1_,
userinfo1_.name as name10_2_1_,
userinfo1_.telephone as telepho11_2_1_
from address address0_
left outer join user_info userinfo1_ on address0_.user_info_id = userinfo1_.id
可以看到 address left join 的模式中,一个 SQL 把所有的 address 和 user_info 都查询出来了。
综上所述,@EntityGraph 可以用在任何 ***Repository 的查询方法上,针对不同的场景配置不同的关联关系策略,就可以减少 N+1 的 SQL,成为一条 SQL。
总结
通过这两讲的介绍,你可以知道关联关系在 Hibernate 的 JPA 中的优点就是使用方便、效率高;而缺点就是需要了解很多知识,才能知道最佳实践是什么。
关于这四种处理 N+1 SQL 的方法,你在使用的时候可以根据实际情况自由选择,不局限于某一种解决方式。
在我介绍的内容中,有一些方法不是 JPA 协议的标准,而是 Hibernate 的语法,所以你在用的时候要看一下注解或者配置的源码注释,看看是否有变化,再根据实际情况自由调整。不过思路上的转化可以不需要关心版本的变化。
好了,本讲到这里就结束了。全网最全的 N+1 SQL 处理方案,如果你觉得有用,就动动手指分享吧。下一讲我们来聊聊 SPEL 表达式的相关内容,再见。
点击下方链接查看源码(不定时更新)
https://github.com/zhangzhenhuajack/spring-boot-guide/tree/master/spring-data/spring-data-jpa


















 5248
5248

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











