







首先看下以下代码
class VolatileBarrierExample {
int a;
volatile int v1 = 1;
volatile int v2 = 2;
void readAndWrite() {
int i = v1; //第一个volatile读
int j = v2; // 第二个volatile读
a = i + j; //普通写
v1 = i + 1; // 第一个volatile写
v2 = j * 2; //第二个 volatile写
}
… //其他方法
}
JMM层面对volatile的解释是:volatile读每次从主存获取最新值,jmm层面定义了StoreStore、StoreLoad、LoadLoad、LoadStore内存屏障防止指令重排
JMM针对编译器制定的volatile重排序规则如下:

举例来说,第三行最后一个单元格的意思是:在程序顺序中,当第一个操作为普通变量的读或写时,如果第二个操作为volatile写,则编译器不能重排序这两个操作。
从上表我们可以看出:
当第二个操作是volatile写时,不管第一个操作是什么,都不能重排序。这个规则确保volatile写之前的操作不会被编译器重排序到volatile写之后。
当第一个操作是volatile读时,不管第二个操作是什么,都不能重排序。这个规则确保volatile读之后的操作不会被编译器重排序到volatile读之前。
当第一个操作是volatile写,第二个操作是volatile读时,不能重排序。
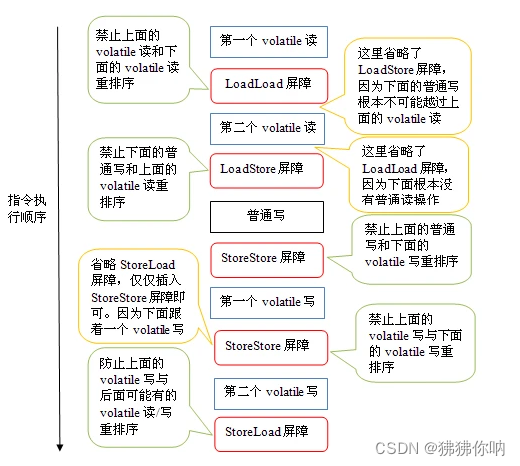
为了实现volatile的内存语义,编译器在生成字节码时,会在指令序列中插入内存屏障来禁止特定类型的处理器重排序。对于编译器来说,发现一个最优布置来最小化插入屏障的总数几乎不可能,为此,JMM采取保守策略。下面是基于保守策略的JMM内存屏障插入策略:
在每个volatile写操作的前面插入一个StoreStore屏障。
在每个volatile写操作的后面插入一个StoreLoad屏障。
在每个volatile读操作的后面插入一个LoadLoad屏障。
在每个volatile读操作的后面插入一个LoadStore屏障。
上述内存屏障插入策略非常保守,但它可以保证在任意处理器平台(屏蔽操作系统和硬件),任意的程序中都能得到正确的volatile内存语义。
针对readAndWrite()方法,编译器在生成字节码时可以做如下的优化:
编译成class字节码看一下,用javap -v -p class文件名(不要.class 后缀)运行
volatile int v1;
descriptor: I
flags: ACC_VOLATILE
.....
void readAndWrite();
descriptor: ()V
flags:
Code:
stack=3, locals=3, args_size=1
0: aload_0
1: getfield #52 // Field v1:I
4: istore_1
5: aload_0
6: getfield #54 // Field v2:I
9: istore_2
10: aload_0
11: iload_1
12: iload_2
13: iadd
14: putfield #72 // Field a:I
17: aload_0
18: iload_1
19: iconst_1
20: isub
21: putfield #52 // Field v1:I
24: aload_0
25: iload_2
26: iload_1
27: imul
28: putfield #54 // Field v2:I
31: return
除了其变量定义的时候有一个Volatile外,之后的字节码跟有无Volatile完全一样
使用hsdis插件,汇编成汇编码
运行
java -XX:+UnlockDiagnosticVMOptions -XX:+PrintAssembly -Xcomp -XX:CompileCommand=dontinline,*VolatileBarrierExample.readAndWrite -XX:CompileCommand=compileonly,*VolatileBarrierExample.readAndWrite com.earnfish.VolatileBarrierExample > out.put
其中*VolatileBarrierExample.readAndWrite表示你运行的类.函数, com.earnfish.VolatileBarrierExample表示你的包名.类名,注意需要有main函数来运行你所要执行的函数。得出汇编码如下
0x000000011214bb49: mov %rdi,%rax
0x000000011214bb4c: dec %eax
0x000000011214bb4e: mov %eax,0x10(%rsi)
0x000000011214bb51: lock addl $0x0,(%rsp) ;*putfield v1
; - com.earnfish.VolatileBarrierExample::readAndWrite@21 (line 35)
0x000000011214bb56: imul %edi,%ebx
0x000000011214bb59: mov %ebx,0x14(%rsi)
0x000000011214bb5c: lock addl $0x0,(%rsp) ;*putfield v2
; - com.earnfish.VolatileBarrierExample::readAndWrite@28 (line 36)
其对应的Java代码如下
v1 = i - 1; // 第一个volatile写
v2 = j * i; // 第二个volatile写
可见其本质是通过一个lock指令来实现的。
查 IA-32 架构软件开发者手册
https://www.felixcloutier.com/x86/lock
Lock前缀,Lock不是一种内存屏障,但是它能完成类似内存屏障的功能。Lock前缀,可以理解为CPU指令级的一种锁。它后面可以跟ADD, ADC, AND, BTC, BTR, BTS, CMPXCHG, CMPXCH8B, DEC, INC, NEG, NOT, OR, SBB, SUB, XOR, XADD, and XCHG等指令
Lock会对CPU总线和高速缓存加锁,可以理解为CPU指令级的一种锁
在x86架构上,CAS被翻译为”lock cmpxchg…“。cmpxchg是CAS的汇编指令。在CPU架构中依靠lock信号保证可见性并禁止重排序。
lock前缀是一个特殊的信号,执行过程如下:
对总线和缓存上锁。
强制所有lock信号之前的指令,都在此之前被执行,并同步相关缓存。
执行lock后的指令(如cmpxchg)。(修改的数据强制写入主存,通过缓存一致性协议使其它线程这个值的栈缓存失效)
释放对总线和缓存上的锁。
强制所有lock信号之后的指令,都在此之后被执行,并同步相关缓存。
因此,lock信号虽然不是内存屏障,但具有mfence的语义(当然,还有排他性的语义)。
与内存屏障相比,lock信号要额外对总线和缓存上锁,成本更高
参考:
https://segmentfault.com/a/1190000014315651
https://www.cnblogs.com/sunddenly/articles/14829255.html














 807
807











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









