







1、Deep Q Network
deep q network是基础是q_learning,里面的改善包含三个方面
1、深度神经网络逼近值函数
DQN利用深度卷积神经网络逼近值函数,DQN的行为值函数利用神经网络逼近,属于非线性逼近。虽然逼近方法不同,但都属于参数逼近。请记住,此处的值函数对应着一组参数,在神经网络,参数是每层网络的权重,我们![]() 表示。公式表示的话值函数为
表示。公式表示的话值函数为![]() 。请留意,此时更新值函数时其实是更新参数 ,当网络结构确定时,
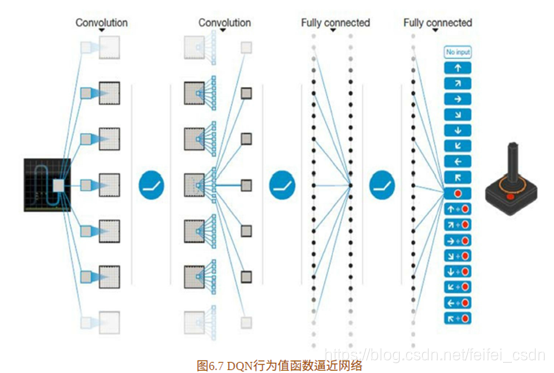
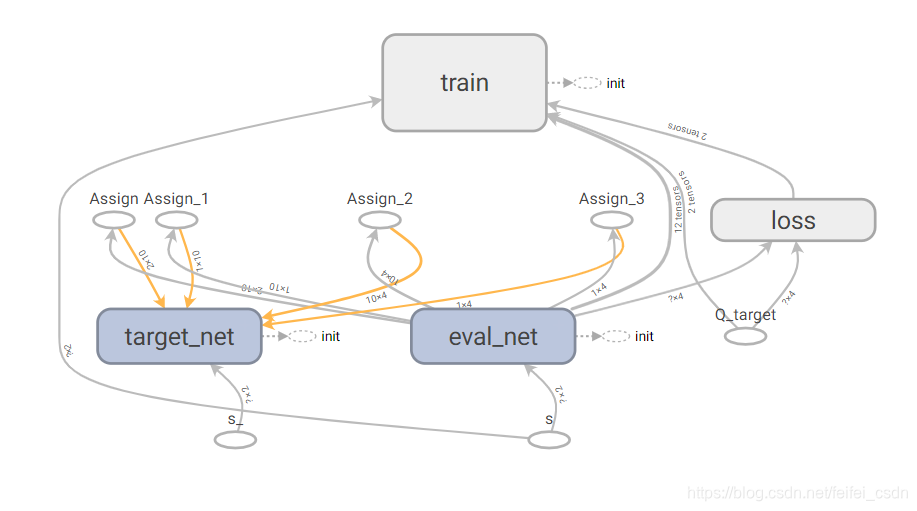
。请留意,此时更新值函数时其实是更新参数 ,当网络结构确定时,![]() 就代表值函数。DQN所示的网络结构是三个卷积层加两个全连接层【其实这里是存在疑问的,所以还需要去学习DQ的相关知识】,整体框架如图6.7所示。
就代表值函数。DQN所示的网络结构是三个卷积层加两个全连接层【其实这里是存在疑问的,所以还需要去学习DQ的相关知识】,整体框架如图6.7所示。
# ------------------ build evaluate_net ------------------
self.s = tf.placeholder(tf.float32, [None, self.n_features], name='s') # input
self.q_target = tf.placeholder(tf.float32, [None, self.n_actions], name='Q_target') # for calculating loss
with tf.variable_scope('eval_net'):
# c_names(collections_names) are the collections to store variables
c_names, n_l1, w_initializer, b_initializer = \
['eval_net_params', tf.GraphKeys.GLOBAL_VARIABLES], 10, \
tf.random_normal_initializer(0., 0.3), tf.constant_initializer(0.1) # config of layers
# first layer. collections is used later when assign to target net
with tf.variable_scope('l1'):
w1 = tf.get_variable('w1', [self.n_features, n_l1], initializer=w_initializer, collections=c_names)
b1 = tf.get_variable('b1', [1, n_l1], initializer=b_initializer, collections=c_names)
l1 = tf.nn.relu(tf.matmul(self.s, w1) + b1)
# second layer. collections is used later when assign to target net
with tf.variable_scope('l2'):
w2 = tf.get_variable('w2', [n_l1, self.n_actions], initializer=w_initializer, collections=c_names)
b2 = tf.get_variable('b2', [1, self.n_actions], initializer=b_initializer, collections=c_names)
self.q_eval = tf.matmul(l1, w2) + b2
with tf.variable_scope('loss'):
self.loss = tf.reduce_mean(tf.squared_difference(self.q_target, self.q_eval))
with tf.variable_scope('train'):
self._train_op = tf.train.RMSPropOptimizer(self.lr).minimize(self.loss)怎么觉得这里是三层全连接,两层卷积神经网络
2、经验回放
神经网络逼近值函数的做法在强化学习领域早就存在了,可以追溯到上个世纪 90 年代当时学者们发现利用神经网络,尤其是深度神经网络逼近值函数不太靠谱,因为常常出现不稳定不收敛的情况,所以在这个方向上一直没有突破,直到DeepMind的出现【deep mind的创始人去研究海马体】
通过经验回放为什么可以令神经网络的训练收敛且稳定?
原因是:训练神经网络时,存在的假设是训练数据是独立同分布的【在概率统计理论中,指随机过程中,任何时刻的取值都为随机变量,如果这些随机变量服从同一分布,并且互相独立,那么这些随机变量是独立同分布】,但是通过强化学习采集的数据之间存在着关联性,利⽤这些数据进⾏顺序训练,神经⽹络当然不稳定。经验回放可以打破数据间的关联。
 。
。
在强化学习过程中,智能体将数据存储到⼀个数据库中,再利用均匀随机采样的方法从数据库中抽取数据,然后利用抽取的数据训练神经网络。
经验存储
def store_transition(self, s, a, r, s_):
if not hasattr(self, 'memory_counter'):
self.memory_counter = 0
transition = np.hstack((s, [a, r], s_))
# replace the old memory with new memory
index = self.memory_counter % self.memory_size
self.memory[index, :] = transition
self.memory_counter += 1经验回放
# sample batch memory from all memory
if self.memory_counter > self.memory_size:
sample_index = np.random.choice(self.memory_size, size=self.batch_size)
else:
sample_index = np.random.choice(self.memory_counter, size=self.batch_size)
batch_memory = self.memory[sample_index, :]
q_next, q_eval = self.sess.run(
[self.q_next, self.q_eval],
feed_dict={
self.s_: batch_memory[:, -self.n_features:], # fixed params
self.s: batch_memory[:, :self.n_features], # newest params
})
# change q_target w.r.t q_eval's action
q_target = q_eval.copy()
batch_index = np.arange(self.batch_size, dtype=np.int32)
eval_act_index = batch_memory[:, self.n_features].astype(int)
reward = batch_memory[:, self.n_features + 1]
q_target[batch_index, eval_act_index] = reward + self.gamma * np.max(q_next, axis=1)
# train eval network
_, self.cost = self.sess.run([self._train_op, self.loss],
feed_dict={self.s: batch_memory[:, :self.n_features],
self.q_target: q_target})3、目标网络
2015 年的 Nature 论文则进⼀步提出了目标网络的概念,以进一步降低数据间的关联性。
DQN 利用了卷积神经网络。其更新方法是梯度下降法,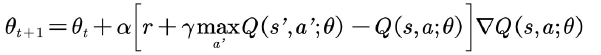
其中![]()
为TD目标,计算![]()
用到的网络参数称为目标网络,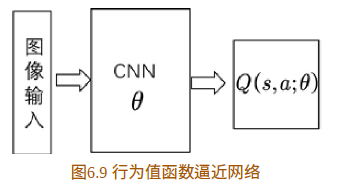
在DQN算法出现之前,利用神经网络逼近值函数时,计算 TD 目标的动作值函数所用的网络参数,与梯度计算中要逼近的值函数所在的网络络参数相同,这样就容易导致数据间存在关联性,从而使训练不稳定
用于动作值函数逼近的网络每单步都更新,用于计算 TD目标的网络则是每个固定的步数更新一次
# check to replace target parameters
if self.learn_step_counter % self.replace_target_iter == 0:
self.sess.run(self.replace_target_op)
print('\ntarget_params_replaced\n')DeepMind提出计算TD目标的网络表示为![]() ;计算值函数逼近的⽹络表⽰为
;计算值函数逼近的⽹络表⽰为![]() 。值函数更新为
。值函数更新为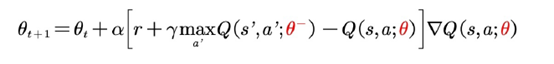
# ------------------ build target_net ------------------
self.s_ = tf.placeholder(tf.float32, [None, self.n_features], name='s_') # input
with tf.variable_scope('target_net'):
# c_names(collections_names) are the collections to store variables
c_names = ['target_net_params', tf.GraphKeys.GLOBAL_VARIABLES]
# first layer. collections is used later when assign to target net
with tf.variable_scope('l1'):
w1 = tf.get_variable('w1', [self.n_features, n_l1], initializer=w_initializer, collections=c_names)
b1 = tf.get_variable('b1', [1, n_l1], initializer=b_initializer, collections=c_names)
l1 = tf.nn.relu(tf.matmul(self.s_, w1) + b1)
# second layer. collections is used later when assign to target net
with tf.variable_scope('l2'):
w2 = tf.get_variable('w2', [n_l1, self.n_actions], initializer=w_initializer, collections=c_names)
b2 = tf.get_variable('b2', [1, self.n_actions], initializer=b_initializer, collections=c_names)
self.q_next = tf.matmul(l1, w2) + b2fade code




result
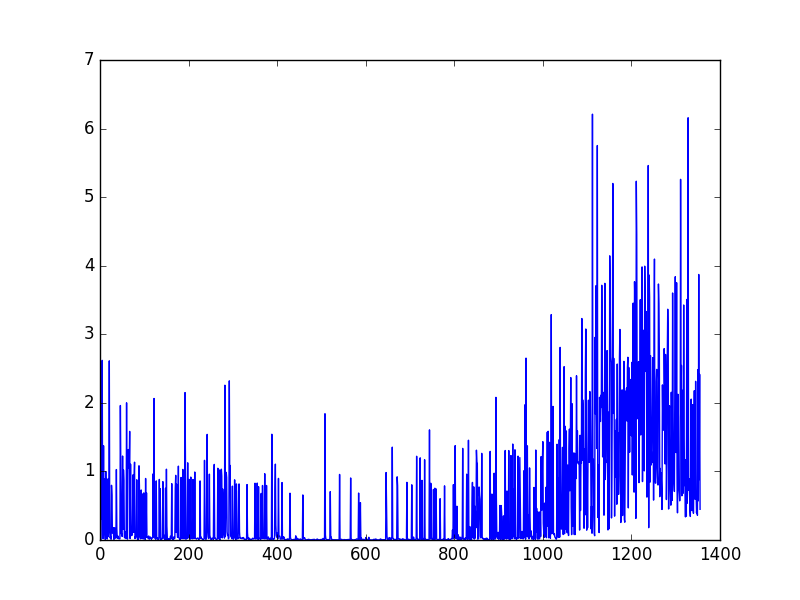
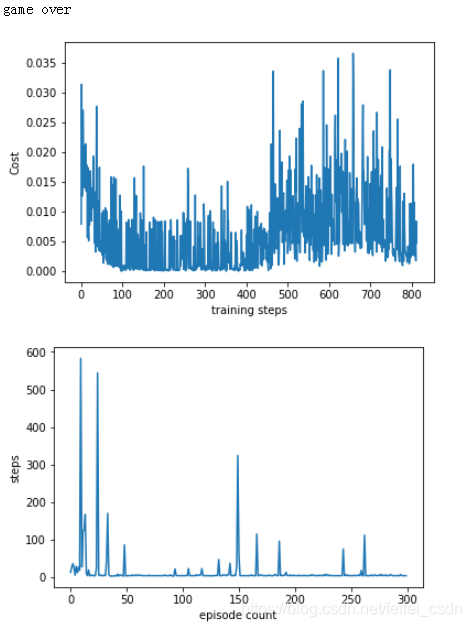
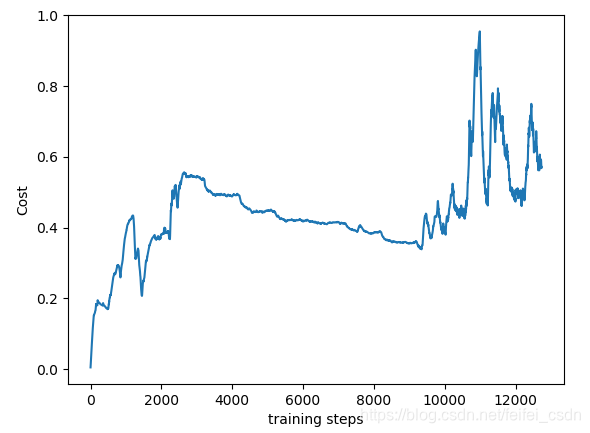
cost不收敛,关于loss值不收敛的问题有一段来自莫凡python教程里面的text:
“可以看出曲线并不是平滑下降的, 这是因为 DQN 中的 input 数据是一步步改变的, 而且会根据学习情况, 获取到不同的数据. 所以这并不像一般的监督学习, DQN 的 cost 曲线就有所不同了.”
这里的意思是loss值不能作为衡量是否最优或者次优的标准吗?如果不能的话,那在走迷宫的游戏里面就是最后走多少步来衡量是否已经达到次优。
choose action
选择q值最大的action,只是这里不再是搜索q table来查找,而是神经网络逼近的方式来得到。
去看他的q值,感觉也没有任何的变化,q值也是和他的输入数据相互关联的,所以也可能
dqn的常见形式:
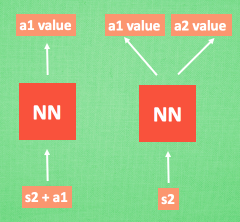
不过一般我们使用的是第二种形式:
2、Double Deep Q network
DQN无法克服Qlearning 本身所固有的缺点——过估计。
那么什么是过估计?Qlearning为何具有过估计的缺点呢?
过估计是指估计的值函数⽐真实值函数要高。一般来说,Qlearning之所以存在过估计的问题,根源在于Qlearning中的最大化操作。Qlearning评估值函数的数学公式如下有两类
●对于表格型,值函数评估的更新公式为
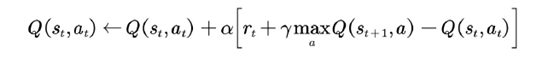
●对于基于函数逼近的⽅法的值函数更新公式为
![]()

TD目标:

动作评估


print("q_next is {0}".format(q_next))
if self.double_q:
print("q_eval4next is {0}".format(q_eval4next))
max_act4next = np.argmax(q_eval4next, axis=1) # the action that brings the highest value is evaluated by q_eval
print("max_act4next is {0}".format(max_act4next))
selected_q_next = q_next[batch_index, max_act4next] # Double DQN, select q_next depending on above actions
print(" double_q selected_q_next is {0}".format(selected_q_next))
print(" yh_double_q selected_q_next is {0}".format(np.max(q_next, axis=1)))
else:
selected_q_next = np.max(q_next, axis=1) # the natural DQN
print(" natural_q selected_q_next is {0}".format(selected_q_next))
yh_max_act4next = np.argmax(q_eval4next, axis=1)
yh_selected_q_next = q_next[batch_index, yh_max_act4next]
print(" natural_q yh_selected_q_next is {0}".format(yh_selected_q_next))但是下面的参数打印出来是一样的,也就是先选最大action再去找对应的q值,和直接去找最大的q值是一样的啊!
这里q_eval为0表示什么意思呢?
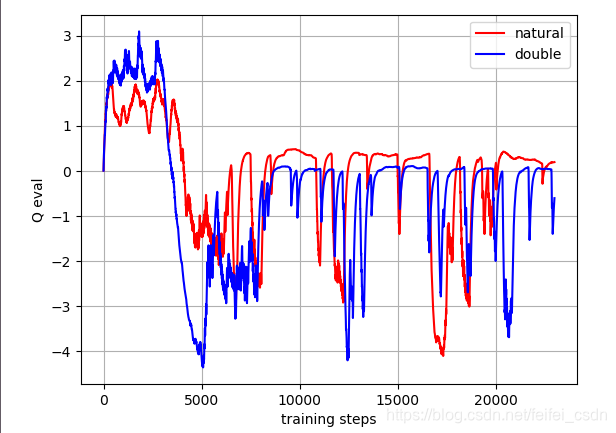
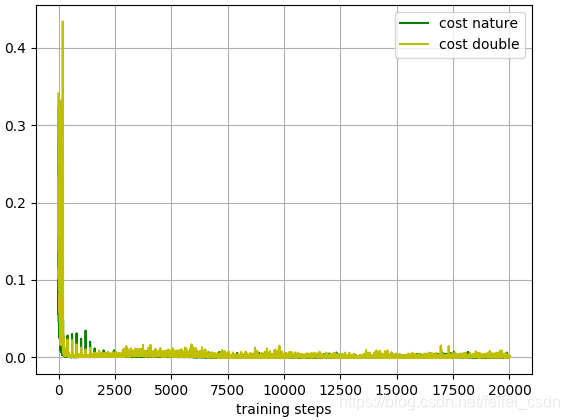
loss值的比较:















 7512
7512

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









