









之前的一篇文章感觉分析得不太完整,所以再记录点东西。
故障组合情况
对于多个节点且每个节点有多个可能状态参与的分布式系统来说,假设在有限的某个时间点上发生故障的概率为0,对于coordinator(proposer/master/leader等),在发送接收的一轮交互中,可能在发送消息前(t < t1),发送部分消息(t1 < t < t2),发送所有消息后并且接收消息前(t2 < t < t3),接收到部分消息(t3 < t < t4),接收到所有消息后发生故障(t > t4);对于每个participant(acceptor/follower/slave)来说,在接收发送的一轮交互中,可能在接收消息前(t’ < t1’),接收到消息且未发送应答(t1’ < t’ < t2’),发送应答后(t’ > t2’)发生故障。
coordinator和participants在不同的时间段发生故障的组合会有不同的能够保持全局事务状态一致的故障发生时行为以及恢复策略,而且可能不存在能保持全局事务状态一致的相应行为以及恢复策略。对于发生故障时的行为,在程序实现上我们必须用上面提到的时间段来分析,而且假定coordinator广播消息这个动作的过程中不会出现故障(这其实是比较合理的,因为即使只发送了部分消息也可以看做是有一部分participants没有收到消息,这两种情况对于最终的系统全局状态是一样的),这样程序实现上相应能简化不少。而对于故障恢复的策略以及正确性,我们可以从有节点发生故障后最终整个系统可能处于的全局状态来详细分析论证,虽然对于n个参与节点来说,其状态组合指数级增长,但是其中大多数状态可以用全称量词和存在量词描述,因为很多状态对于恢复策略是一样的。下面以2PC和3PC为例来分析,从中可以比较容易地看出2PC存在的问题,以及3PC为什么能够解决这个问题。2PC和3PC的正常流程可以参考相应的资料,这里不赘述。
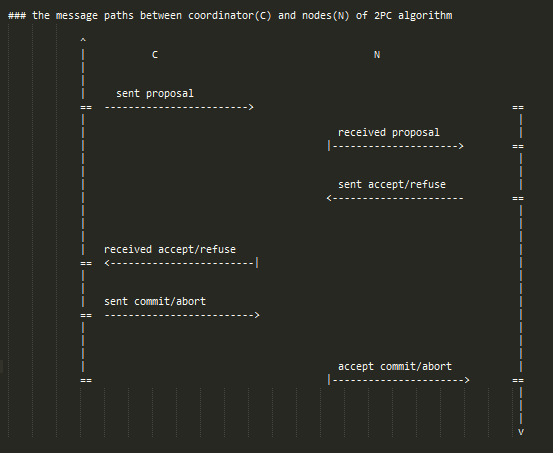
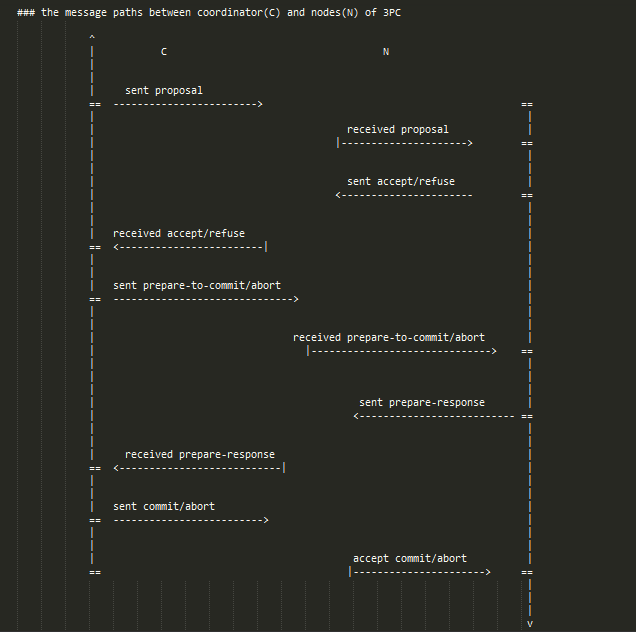
故障模型
首先我们这里只考虑fail-recover的故障模型
我们只考虑在有coordinator以及participant挂掉的情况,而且coordinator本身不具有participant的身份。对于没有participant挂掉但是coordinator挂掉的情况,只需要选择新的coordinator并向所有存活的participant发送最后一条日志记录的请求就可以确定发生故障时全局事务的状态,从而恢复,所以比较简单。对于有paticipant挂掉以及coordinator没有挂掉的情况,由于coordinator知道所有participants的响应消息,所以可以决定此次事务的最终状态,可能会阻塞等待participant的恢复,但不会造成不一致。
举一个coordinator没有故障但是paticipant故障的例子:对于2PC的阶段一(即有部分participant还未收到coordinator的proposal消息),如果coordinator未发生故障,但是有participant发生故障,这种情况下,只需要取消此次proposal即可,等到故障的participant恢复后询问coordinator要相应的日志记录,不会造成最终全局事务状态的不一致。(这里关于整个系统能不能progress可能有不同说法,如果我们将故障的participant移除coordinator活跃列表那么接下来的事务(如果这里的事务只是单纯的replication)可以正常进行,但是如果分布式事务本身必须要故障的participant参与,那么整个系统必须阻塞直到participant恢复,但总之不会造成恢复后系统全局状态的不一致)。
2PC故障恢复分析
下面考虑coordinator和participant故障的情况:
1.对于2PC的阶段一(即有部分participant还未收到coordinator的proposal消息)
- 此时新选出的coordinator询问剩余存活节点的消息后可以直接cancel,因为不可能有节点commit
2.对于2PC的阶段二,情况稍微复杂,故障发生时,所有剩余存活节点可能的状态只能是accept/refuse/commit/abort中的一个,并且只有以下组合
(1).存活节点中返回accept的数量满足0 <= n < N(存活节点总数)
a. n中除去accept的剩余全是commit => commit
b. n中除去accept的剩余全是abort => abort
c. n中除去accept的全是refuse => abort
d. n中除去accept的剩余部分是abort,部分是abort => abort
以上几种情况下新的coordinator的abort/commit选择在故障节点恢复后都不会造成不一致。
(2).存活节点全部返回accept,即n == N
此时故障的participant可能处于的状态有:
a. accept
b. refuse
c. commit
d. abort
可以看出,无论新的coordiantor选择commit还是abort,最终participant恢复时有可能是abort或者commit,这样会导致不一致,所以整个系统只有等故障participant恢复之后,新的coordinator才可能继续,整个系统才可能progress。这也是导致2PC缺陷的根本原因。
综合(1)(2)两种情况,在(2)中由于故障的节点可能成为唯一接收到commit/abort消息的节点,所以从剩余节点中我们没办法知道整个系统的状态。因此3PC引入了prepare-commit阶段,在真正提交(commit阶段)之前,让所有节点都能知道整个系统的状态是可以提交(即coordinator收到所有accept)还是cancel(abort,即coordinator没有收到所有accept),然后在commit阶段,如果有节点挂掉了,也可以通过其他其他节点得知整个系统此次事务投票的状态,从而progress。
3PC故障恢复分析
1.对于3PC的阶段一(即有部分participant还未收到coordinator的proposal消息)
- 此时新选出的coordinator询问剩余存活节点的消息后可以直接cancel,因为不可能有节点commit
2.对于3PC的阶段二和阶段三,情况比较复杂,故障发生时,所有剩余存活节点可能的状态只能是accept/refuse/prepare-commit/cancel/commit中的一个,并且只有以下组合
(1).存活节点中返回accept的数量满足0 <= n < N(存活节点总数)
a. n中除去accept的全是refuse => abort
b. n中除去accept的全是cancel => abort
c. n中除去accept的部分是refuse,部分是cancel => abort
d. n(==0)中除去accept的全是prepare-commit => commit
e. n(==0)中除去accept的全是commit => commit
f. n(==0)中除去accept的部分是commit,部分是prepare-commit => commit
可以看出,上述所有情况,新的coordinator都可以有确定的abort/commit选择,不会造成故障节点恢复后整个系统的不一致。
(2).存活节点全部返回accept,即n == N
- 此时故障节点可能处于的状态有:
- a. accept
- b. refuse
- c. prepare-commit
- d. cancel
- e. 不可能有commit(如果是commit那么必然所有存活的都是prepare-commit,这样就避免了2PC存在的问题!)
- 此时故障节点可能处于的状态有:
可以看出,3PC引入prepare-commit阶段后,(2)中解决了2PC的问题。(2)中a,b,c,d四种可能情况下由于不可能出现故障节点commit的情况,所以新的coordinator都可以采取abort,从而在故障节点恢复后不会造成不一致状态。但是3PC的一个局限在于无法容忍网络分区:比如如果发生了网络分区,其中一部分的coordinator收到那一部分所有存活节点都是prepare-commit,那么会决定commit;但是另外一部分的coordinator收到的存活节点中全是accept,那么会决定abort。这样导致了整个系统状态的不一致。
总结
本文对于每种恢复情况都做了一定考虑,对于只有一个coordinator和participant的情况,我们可以画出系统的全局状态图,从而判断不同故障组合是否会导致状态转换的不确定结果,即最终的全局状态既有commit又有abort,上述的分析本质上也是将一些状态分了类。但是对于多节点的组合,感觉始终没有太严格地形式证明,在思考代码实现的时候也是总感觉不具有百分之百的说服力…状态组合爆炸也是并发与分布式的一个比较难的问题吧。

















 2788
2788

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









