






 本文详细介绍了如何测试企业级SSD的性能,包括性能波动、预处理、随机读写、混合读写、顺序读写以及负载测试等方面。测试方法涵盖不同OIO、队列深度和混合比例,强调了低队列深度性能和延迟的重要性。企业级SSD性能差异显著,性能波动性影响其在RAID和其他聚合环境中的表现。测试结果有助于采购决策和理解SSD的实际性能。
本文详细介绍了如何测试企业级SSD的性能,包括性能波动、预处理、随机读写、混合读写、顺序读写以及负载测试等方面。测试方法涵盖不同OIO、队列深度和混合比例,强调了低队列深度性能和延迟的重要性。企业级SSD性能差异显著,性能波动性影响其在RAID和其他聚合环境中的表现。测试结果有助于采购决策和理解SSD的实际性能。
翻译原文来源
http://www.tomsitpro.com/articles/enterprise-ssd-testing,2-863.html
1. 方法
过去几十年来机械硬盘在企业级存储市场占据统治地位。HDD生产厂家少,不同厂商的产品之间性能差异非常小。采购HDD的考量因素集中在这么几点,每GB的价格,容量,可靠性和功耗指标。
和HDD不同,基于闪存的存储产品即使在同一级别的不同型号的产品间也有巨大的性能差异。SSD是已经固化的企业级存储市场的颠覆者,基于闪存的存储产品展现出了独特的指标和特性,在采购过程中需要分析这些指标。根据终端应用的不同,任何存储设备的性能都有区别,但闪存产品放大了这个性能差异。
SSD厂商很大程度上通过写寿命来区别产品类别,这个指标是由NAND有限寿命的特性而决定的。SSD产品分为三个级别,读为主,混合使用和写为主。我们的测试方法涵盖了从读为主的低价SSD,上到速度最快的PCIe和基于闪存通道的产品。我们从每个类别中选取代表性的产品进行不同的测试,这些测试项目根据写入寿命和价格的不同而设计。
2. 性能波动
在完美世界里,每个IO请求的触发都有相同的速度和延迟,几乎没有变化。不幸的是,所有的存储设备在运行中的性能都是波动的。SSD和其他基于闪存的设备和HDD相比,性能波动范围更大。性能稳定性的不同和许多因素有关,控制器,固件,NAND,错误处理算法,内部管理技术和OP。
根据多种影响因素去描述闪存设备性能波动的特性是非常重要的。性能波动对于应用性能和RAID扩展能力都有负面影响。出错的IO使得应用不得不等待某些关键数据。在一些情况下,后续操作依赖前一步请求的数据。这样的情况一旦发生,某些IO操作就会拖慢整个应用。
软件和硬件RAID,以及其他的聚合多个设备到一个整体的方法,只会加重波动性。RAID阵列的速度受限于最慢的设备,所以在大多数情况下,一个设备上的一个出错的IO会降低整个阵列的速度。出错IO的数量随着加入阵列的设备数量增加而增加,因为从更多的设备上产生了错误IO。
测量平均性能的方法展现了对于性能测试的基本理解,但几乎不可能体现IO QsS(服务质量)。为了展现性能的波动性,我们在测试程序中插入了高粒度。我们每隔1秒钟测量一次性能,然后标记到坐标上,这样能够观察到对于单个盘有趣的性能趋势。那些IO服务分布紧密的盘在应用中表现更好,同时在磁盘聚合环境中扩展性也更好。
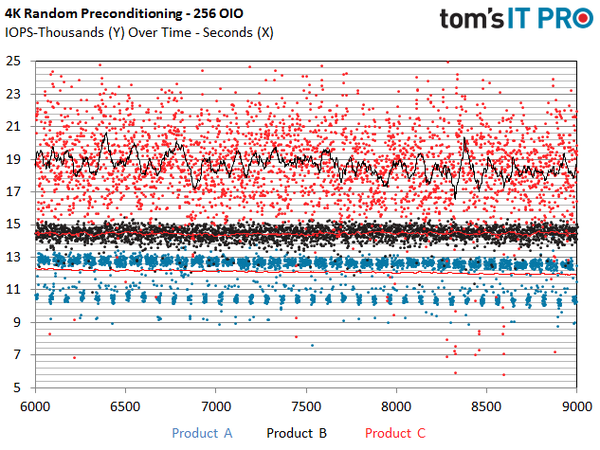
上图是三个盘做4k随机preconditioning时的IOPS随时间分布图。
读为主(或者说低端级别)的SSD和高端SSD相比波动性更大。我们简单地分析一下上面的图表,这个图表展现了三个市场上领先的2.5寸读为主的产品(都是读为主的低端SSD)在稳态下4k随机性能的稳定性。Y轴表示IOPS值,X轴表示我们在待测设备(DUT)上运行负载的时间长度。
通过这个图表我们立马就可以看到在样本库里不同产品之间在性能稳定性上有明显的差异。C产品平均速度高很多(黑色趋势线标记),但是我们的测试方法暴露了这个产品低于其他竞争对手的某些重要种类的特性。这个SSD由于更高的平均速度,可能更适合于单个盘的部署。然而,在RAID和其他磁盘聚合方案中,显著的性能波动性会随着加入阵列的磁盘数量增加而遭受越来越大的性能损失。
B产品展现了不错的性能稳定性,没有很多偏差现象,在与其他磁盘聚合的应用下扩展性线性增长。粒度在判断SSD内部管理功能的侧重点方面也很有用。A产品性能排布很紧密,间歇地有一些性能下降的脉冲,这种现象表明了后台正在进行的GC影响了性能。
3. 预处理(Preconditioning)
有效并且有竞争力的性能分析需要遵守工业界普遍接受的预处理基本理论。SINA(Storage Networking Industry Association)是一个标准体,消除了衡量闪存设备有效性能的障碍。Solid State Storage Performance Test Specification (PTS)Enterprise V1.1归纳了一些处理方法上的关键原则,以确保获得准确和可重复的测试结果。
我们的测试过程在执行处理协议后进行,同时,测试结果通过同样的方式线性展示出来。

刚拿到SSD的时候通常是全新开盒状态(FOB)。在FOB状态下,盘没有运行过持续的负载,最初的测试会看到很高的数据,这个数据是反常的。稳态指在待测的负载上获得最终水平的性能,只有在连续使用后才会达到。上面的图片展示了从性能FOB下降到稳态的过程。
随着测试的进展,我们注意到在状态变化过程中性能出现下降。这是因为运行的负载迫使SSD控制芯片对于每一个等待的写操作做"读-修改-写"(Read-modify-write, RMW)动作。SSD最后到达稳态,代表在长时间使用期间可以达到的性能指标。
SNIA定义了三个步骤以到达稳态。第一步是净化(Purge)待测设备(DUT)。这个步骤使得盘在预处理和性能测量前达到一个稳固状态。DUT的净化操作对于SATA设备需要ATA secure erase命令,对于SAS设备使用SCSI Format Unit命令。对于其他设备,比如PCIe SSD,则需要使用厂商自定义的工具来净化设备。
一旦盘处于干净的FOB状态(通过净化命令),我们便会启动两种类型的预处理。与负载无关的预处理(WIP,Workload Independent Preconditioning)包含一个与实际测试样本没有关系的负载。在WIP预处理阶段,我们用128K顺序写把整个磁盘空间写两遍。这个步骤做完后所有的LBA和OP空间都做了映射,填满了数据。
WIP阶段做完后,我们立即开始与负载相关的预处理(WDPC,Workload Dependent Preconditioning)。WDPC利用运行产生待测变量的测试负载,使得设备到达稳态,并且这个稳态和待测负载相关。到达稳态后,平均性能在性能测量窗口中不会变动。运行每个负载都需要一轮完整的预处理过程。到达稳态后,我们在一个测量时间窗口中记录性能数据。
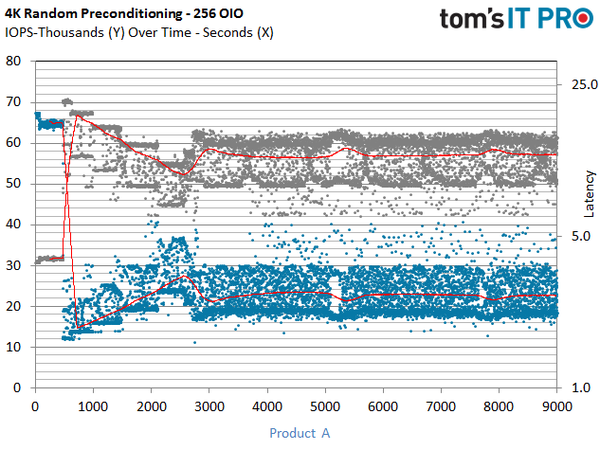
上面的图表展现了使用我们的测试方法,将一个盘状态转化为稳态。SSD展现出了不同级别的性能稳定性(先前的描述中已经包含)。在预处理过程中,我们每一秒钟记录性能数据以体现出性能波动。Y轴表示IOPS性能,X轴表示我们在DUT上运行负载的时间(图表中已经标注)。
整个预处理图表包含18000个数据点。蓝色点表示测量到的IOPS数据,灰色点表示延迟(latency)数据(右边的对数纵坐标)。数据点中的红色线代表预处理过程中的平均数据。延迟和IOPS有相反的观感,这是指在当我们看到性能越来越高时,延迟的分布也就越来越好(性能高,延迟小)。预处理阶对于一个正常使用的企业级SSD而言,在其生命周期中极少发生。我们把这个步骤包含进我们的测试方法是为了在运行每个负载前,让盘进入稳态。
4. 随机读,随机写和混合读写
闪存存储设备有助于减小机械存储和系统内存之间的性能差异。SSD在运行随机负载上有巨大的优势,随机文件访问对于任何存储设备来说都是最困难的类型。机械硬盘的机制决定了其对于小文件随机操作处理不佳,任何一个SSD都能在随机性能上超越HDD。
在对于所有产品评估中,我们把4K(或者8K)读,写和混合读写的负载作为标准项目。4K随机访问是一个工业标准指标,会出现在市场宣传材料中,这个指标帮助我们判断一个存储设备是否物有所值。许多企业级应用很依赖8K随机性能,我们把它也包含在性能测试中,以展现在很多企业级应用中能见到的性能曲线。
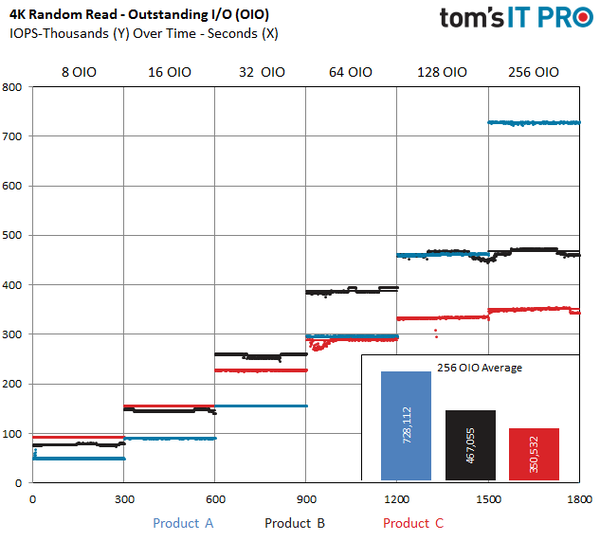
在运行写入负载的时候有性能下降是可以预期的,但是一些SSD在稳态下读性能甚至也有大幅下降。我们在读负载时同样使用在先前所有测试中使用的标准预处理协议。上图更清晰地展现出了主流PCIe SSD的4K随机读性能。Y轴表示IOPS性能,X轴表示我们在DUT上运行负载的时间(标注在图标中)。
未完成IO(OIO)表示在任一时刻,等待完成的待定操作的数量。我们在设计测试时把负载放到线程中。上图中8 OIO表示这个负载有8个不同的进程执行IO操作。例如,8个单独的工作进程每个都生成一个32队列深度的负载,这样就产生了256 OIO的测试。4 OIO表示4个工作进程单独产生QD1负载,2 OIO包含两个QD1进程,1 OIO就是单个OD1进程。如上图所示,我们对于每个不同的OIO测试300秒。
在真实世界的使用情况下,存储设备通常会操作16-64个OIO。在评估存储设备时,我们关注的是中段范围内的特性,也就是最佳比例范围。100%随机读负载比起100%写或者混合负载来说,波动性不那么大。但显然,100%随机读也不可避免地会有波动。
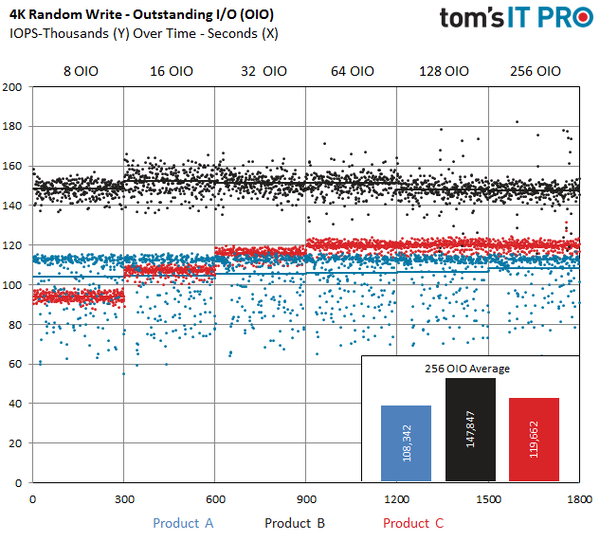
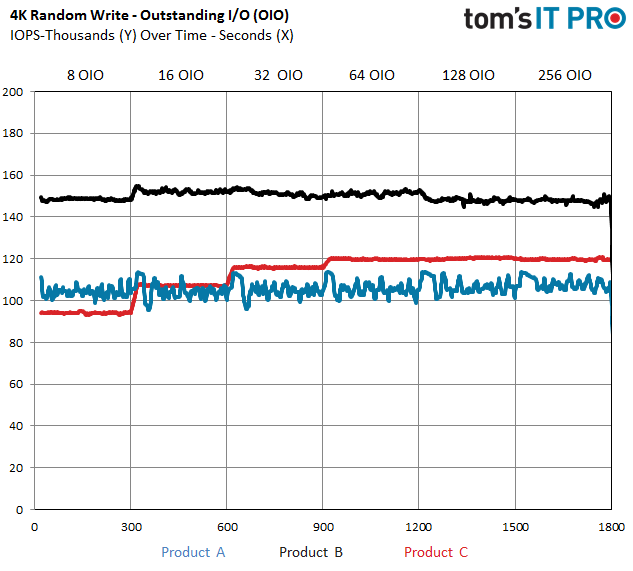
在这个测试池里,随机写测试波动性很大。我们每间隔300秒记录平均性能。同时在右下角有一个子图,用来表示最受关注的测试项目(256 OIO)的平均性能。这个测试池中有市场领先的PCIe SSD,不像经济型型号那样波动性那么大。当许多SSD展现出明显的不同性时,散点图看起来就会很混乱,对于经济型SSD更是明显。某些情况下,我们会使用趋势线(去除散点)图表。

厂家列出的性能数据仅仅包含100%读或写的负载,但是随机纯读纯写在大部分实际场景下很少见。最常见的是混合负载,混合比例根据每个应用不同而不同。上图的测试是按读写混合比例每次增加10%而得到的性能数据。100%列表是纯随机读。图表渐渐向右直到最右端表示0/100的纯随机写。这个测试包含11个测量窗口。我们在每个测试窗口时显然设备稳定在稳态,然后只记录每个阶段最后300秒的数据。
这个测试特别适合展现标准测试方法不容易观察到的缺点。例如,产品A在60%到80%混合读写比例段表现出了显著的波动性,观察在此阶段中的延迟可以解释这个问题的原因。我们同时观察到产品B读性能不是最高,但随着我们推进到常见的混合读写比例,产品B表现出了切实的性能提高,对实际应用有益。
5. 低队列深度测试的重要性
和最新的SATA SSD相比,早期的SSD慢得多,更不用说当前的NVMe盘。由于成本降低,数据中心越来越多地在普通应用上部署SSD。性能的增加和成本的降低结合起来,改变了相关存储产品性能指标的评估方法。
厂商喜欢取悦我们,会展示一个不可思议的IOPS值,这个数值只有在重度负载情形才能下得到。但是,SSD在常规部署时候极少会触及性能指标的范围边界。在很少见的情况下,SSD会达到性能指标规定的上限,但是通常这时候延迟数据不好看,无法满足SLA要求。
大多数的测试技巧并不符合真实世界应用的需求,这样的差距最后归结(boil down to)为有效的队列深度(QD)。QD指有多少个向外发出的请求在排队等待处理。想象一个底部有一个小洞的空篮子。往篮子里以稳定的速度注水,并且注水速度快于篮子漏水速度时,篮子就会被注满水。这个比喻类似于SSD中建立队列。如果请求数据(水)的速度快于设备处理速度,那么这个放置外向请求的篮子就开始被填满。
我们的目标是永远保持篮子处于空状态,为达到此目的最方便的方法就是在篮子底部凿一个更大的洞。即使注水速度加快,由于漏水速度也更快,篮子中的水就不会那么满。更大的洞象征的更快的存储设备,这个设备能够更快更高效地处理请求。
如今的SSD达到了很高的性能水平,可以非常快地处理请求,由此降低了整体的队列深度(QD)。所以即使搭配优化不佳的应用和操作系统,对于大多数用户场景来说也不必要做高队列深度的测试。
上面的图表由Intel提供,展示了Intel自己的测试结果,基于SSD在不同应用中的真实负载。这个图标说明了即使数据中心处于最大负载,队列深度也极少超过64。
这不是我们观察到的体现低队列深度重要性的唯一数据。我们和不同厂商的多个性能工程部门交流中也印证了Intel的数据。我们在开发可靠的方法以测试数据库负载时,进行了内部测试。我们发现在我们的环境中进行TPC-E和TPC-C测试时,QD很好地保持在32以下,即使在RAM容量非常有限的情况下也是如此,这个现象证实了低队列性能的重要性。


通常来说,预期的SLA延迟范围是5-10ms。高强度的负载,比如实时竞价和金融服务要求小于5ms的相应时间,请求要快速生效。一些分析应用需要大约8ms,数据仓库需要小于10ms延迟。上面的图表说明了我们在评估过程中关注低队列深度(1-32 OIO)的性能。
6. 顺序读,顺序写和混合读写
机械硬盘实际上已经可以提供充分的顺序性能,在聚合成不同的RAID实现时更是如此。SSD在运行顺序负载是同样可以提供非常可观的速度,特别是在备份和复制数据时。
缓存和分层会试图在主轴层(spindled layers,纺椎体层)保持顺序访问,在闪存层保持随机访问。在把数据从闪存层搬移的过程中,仍然需要强大的顺序读写性能。许多其他的负载同样需要可靠的顺序性能,这使得顺序访问成为衡量一个SSD是否全面(well-arounded)的重要因素(ingredient)。
顺序读负载出现在OLAP(联机分析处理) ,批处理,内容发布,流和备份应用中。我们测试池中最快的设备峰值数据在128 OIO达到了大约3.1GB/s, 或3185MB/s 。

顺序写性能体现在诸如缓存,复制,HPC和数据记录负载中。总的来说,顺序写负载和随机读相比,种类要少得多。然而,在顺序写测试中,某些SSD和其他相比依然体现出了更大的波动性。另一个重要的分析顺序性能的方法是观察延迟数据,在第7页会涉及到。
混合负载的重要性不可过分夸大,这对于顺序访问来说同样如此。我们在这个图表中分析了高端PCIe SSD。这个测试也体现出了产品间显著的不同,对于2.5寸经济型市场来说更明显。许多2.5寸SSD在100%顺序读写时可以获得高分,但在中段范围内性能显著降低,我们的测试结果就体现出一条浴缸线。


100%列表是纯读负载。随着图表右移,我们逐渐加入写操作,在最右边0/100纯写负载。这个测试由11个测量窗口组成。我们让存储设备在进行每个写混合比例测试前先达到稳态,并且在每个阶段中只记录最后300秒的数据。(前面有过同样的测试)
7. 负载测试
存储子系统性能受多种环境因素影响而变化。服务器,网卡,交换机,操作系统,驱动和每个设备的固件,这些测试环境中的因素都会对测量结果产生直接影响。这使得在实际应用负载下有效测量性能变得很难。同样就像人为制造的负载一样,即使在最好的,完全复制的环境下测得的结果也只能代表这个特定的环境。
我们的目标是把我们的测试扩展到应用测试。但在此期间,我们提供了许多负载案例,这些负载都经过业界接受的模拟应用测试。我们在直连配置下进行测试。这给所有存储设备提供了一个公平的环境,没有网络,协议或其他硬件来干扰我们的性能测试结果。这个测试方法从存储设备角度,清晰展现了和应用相关的性能,没有诸如过度CPU负载这样的人为阻碍。
OLTP/数据库测试代表了处理在线事务任务时带来的大量事物负载。测试模式为8k随机测试读67%,写33%。我们所有的应用测试都是用线程的方式运行负载任务。图表右下部分表示了在256 OIO时的平均性能。


邮件服务器负载更重一些,包含8k随机访问,50%读和50%写。这个结果表示了在高负荷随机混合负载时的性能表现。
Web服务器负载包含100%的随机读,文件大小不同,范围很大。在不固定的文件大小下进行多线程访问对于存储设备而已言是非常具有挑战的。

| Workload | Read | Write | 512B | 1KB | 2KB | 4KB | 8KB | 16KB | 32KB | 64KB | 128KB | 512KB |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Web Server | 100% | 0% | 22% | 15% | 8% | 23% | 15% | 2% | 6% | 7% | 1% | 1% |

文件服务器负载包含80%随机读和20%随机写,会访问各种大小的文件。写操作和不固定的文件大小,对于存储设备而言是很苛刻的测试。
| Workload | Read | Write | 512B | 1KB | 2KB | 4KB | 8KB | 16KB | 32KB | 64KB | 128KB | 512KB |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| File Server | 80% | 20% | 10% | 5% | 5% | 60% | 2% | 4% | 4% | 10% | - | - |
8. 测量延迟
性能数据如果不包含延迟测量是没有意义的。所有存储方案的目标就是提供稳定,可预测的延迟。但通常情况下并非如此。最大延迟指标只是量化了在一个测量窗口最差的单个I/O的数据。这样说会引起误解,但确实单个的错误I/O会掩盖对一个优秀存储设备的评价。标准离散测量量化了延迟的分布图,但为了获得更清晰的关于延迟服务质量(QoS)的数据,我们可以增加粒度,按照1秒间隔测量。
低延迟是内存设备的关键优势,同时对于应用而已,低延迟是最令人渴望的特性。我们的高粒度测试显示在不同负载情况下的延迟波动性。

我们的标准延迟图表包含在测量窗口中记录下来的所有延迟数据。我们为每个负载都包含这个图表,用以观测在不同的负载下的延迟。大部分的负载会落在16-64 OIO区域中。

OLTP/Database应用下的延迟-IOPS曲线
我们的延迟-IOPS图表展现了在某个特定延迟值时的IOPS性能。如果你熟悉应用的需求,这些图表用清晰易懂的格式展现了延迟和IOPS数值的相关性。图表的大图部分展现了上至256 OIO的延迟数据。许多设备,特别是2.5寸SSD,在高负荷情况下,远远超越正常延迟数据的边界。我们在左上角的小图中展现闪存设备在小于2ms延迟的情况下的IOPS性能。
奇怪的是,SSD出众的速度实际上限制了延迟-IOPS的性能。快速存储设备处理IO请求速度很快,使得设备更难达到一个对于许多SSD而说会产生最多IOPS的高负荷。许多应用要求响应时间落在特定延迟范围中,同时在低延迟情况下输出更多IOPS的能力也是一个令人渴望的特性。

我们也贴出从随机混合负载测试测得的延迟数据。同样情况下,延迟特指在QD=1时的4K随机负载,这是一个可靠的基准测量方法。延迟测量在高负载和不同的写混合情况下会发生剧烈变化。我们注意到Mangstor MX6300波动性剧烈,和竞争对手比在20/80到0/100的写混合范围里延迟值更高。测试所有的随机写比例有助于发现对应用性能有不利影响的异常情况。在高负荷下测量所有读写比例点的延迟,对做有效的竞争性能分析的至关重要。
电源效率测试
耗电是数据中心令人头疼的事。耗电量的代价随着时间而累积,通常最后的花销会高于购置设备时候的预估 (up-front drive acquistion)。大部分闪存设备经由独特的设计(poised),可以缓解(alleviate)耗电限制。典型的SSD缺少转动部件,由此降低了耗电和发热。不是所有的数据中心都是设计成空气流通的方案,因此发热越低对冷却需设备的需求就越低,更加省电。
IOPS-Watt指标对于衡量SSD是否高效非常重要。一些高性能的PCIe SSD耗电比单个的HDD都高,但他们拥有极为出众的性能。这些SSD总能在IOPS-Watt指标上占上风(prevail),这个指标测量了每消耗一瓦特能量设备可以完成多少工作量。
许多决策者并不会特意分析SSD耗电,这仅仅是因为和有转动部件的同类HDD相比,SSD确实更高效。一些人看到了可观的省电量就认为SSD赢了。然而,单个SSD少量耗电区别对于一个典型的五年服务期的大规模SSD部署来说,意味着大量的节省。我们在不同的SSD型号间发现了耗电方面巨大的不同,我们设计了耗电测试,在余下的内容中(regimen 规则),这个测量方法代表了相同的高粒度测试。
长时间测量耗电非常困难。大部分功耗测量工具板载存储容量有限,限制了可测数量。我们使用Quarch XLC可编程电源模块来记录耗电数据,因为这个工具是流应用,提供了理论上无限的测量窗口。Quarch XLC同时特别灵活,它可以测量各种版型,包括SAS,SATA,PCIe AIC和U.2 2.5 PCIeSSD。我们对Quarch XLC PPM的完全测评。

我们的测试包含整个预处理阶段,测量每分钟的功耗。上面的图表包含了在一个典型的15000秒(4小时)的测试中得到的功耗。我们注意到像性能数值一样,功耗数据也是变化的。一旦SSD到达稳态功耗也会变化。我们从测试的最后五分钟计算出平均数字,放在右下角的图表中。
我们把预处理阶段的性能和功耗测量值综合起来看,得到了SSD的IOPS-Watt图。两个竞争型号之间的效率相差超过1000 IOPS/Watt。这说明某SSD在低功耗状态下可以完成更多的任务,在许多竞争型号之间,这个差距可能更大。在许多部署的整体架构中包含多个SSD,效率指标要综合起来看。

QoS多米诺效应 - QoS测试
“不考虑延迟的IOPS数据是没用的”这个说法没错。然而,实际应用中会涉及在运行中的延迟QoS(服务质量),会对应用性能有很大影响。我们的用1秒钟的粒度测试来观察延迟的波动,但是QoS指标让这个问题变得万众瞩目。
厂商用百分位定义QoS指标,比如说99.99th百分位延迟。开源的测试工具fio会测量在测试过程中每个IO的延迟,通常涉及到数十亿IO请求。例如,单次4K预处理通常包含四十亿个IO请求。
99.99th百分位延迟不包括所有的延迟测量数据,而仅仅是最慢的0.01%请求,这就给了我们一个平均值,用来衡量最差情况的延迟。
关注0.01%的IO可能看起来只是在整个请求数量里极小的一部分,但这相当于在一次4K预处理中,最差的4000万个IO的性能。这些有问题的IO通常称为“异常”或“长尾延迟”(远远偏离正常范围内的延迟)。异常延迟会快速累积,但实际多种因素的累加会导致QoS的多米诺效应。
应用通常会从前序操作中获得信息,继续进行后续操作。例如,一个数学公式需要得到一个解才能进行后续操作,每一个接下来的操作都会触发其他操作。单个的异常减慢了系列中的第一个操作,然后产生了连锁反应,影响了大量的后续操作。如果一个异常IO阻塞了单个操作,那么就会影响到上百个后续操作,每个接下来的操作都有可能碰到异常情况。
这个行为对应用性能产生了巨大的阻碍。更糟糕的是,应用会在同一时刻遇到大量异常,推到了其他后续操作行列的多米诺骨牌。
很多情况下,存储层几毫秒的延迟会导致应用层几秒的延迟。高速SSD每秒可以处理超过800k请求,异常情况会快速堆积。异常对于RAID实现而言更是灾难性的。一个RAID阵列受限于最慢速的IO,每个新增的设备同时会增加更多的异常,就像完美风暴,摧毁了RAID阵列的扩展性。

我们在每篇文章中都会包含QoS数据,同时还有额外的高粒度QoS分组。QoS-IOPS图表标记了随着负载增加,测得的99.99th延迟数值。我们把QoS(用延迟测量)标记在Y轴,IOPS性能标记在X轴。图标中最低值是最好的。在这个例子中,A产品QoS性能比最好。

延迟QoS图表测量32 OIO,涵盖了不同的百分位数值。上图在X轴标记了多种QoS,从最左边的1百分位递进到右边最苛刻(demanding)的99.99百分位。我们在纵轴上标记延迟数据(单位毫秒)。在这个例子中,Intel DC3700测试结果最低,在测试中表现出最佳性能。

标准差是另一种常用的测量方法,用于衡量性能波动性。不幸的是,标准差很难用清晰明了(coherent)的行为表示。例如,如果我们比较两个都能提供1ms标准差的设备,他们看起来应该是一样的。但是,其中一个SSD可能可以提供1M IOPS,而另一个只能有5000 IOPS。这个例子,哪个SSD速度很快一目了然。
为了更高效地比较标准差,我们对测量方法做了规范化。在上图中,产品A能在500k IOPS时提供0.05毫秒的偏差值(Y轴),产品B和D在500k IOPS是偏差值为0.075毫秒。每个IOPS数值对应的偏差值最低表示结果最好。

Y轴为IOPS百分比
直方图关注在32 OIO下,落在不同延迟范围中的操作数量比例。在上图中,产品C中72%的操作落在0.1至0.25延迟范围中。期望中的直方图同时和两个因素相关,落在每个区间中IOPS比例,和落在更低延迟区间中的操作数量。最佳结果指在最低延迟区间中有最高比例的操作。
测试环境
这个半高机架容纳了我们大部分的测试设备,但是我们还有留有其他服务器,方便在实验室繁忙时更容易地更换组件。在进行真正的性能测试前,我们用这些部署好的平台尝试了多种性能特性。我们用单台服务器专注于单个分类的待测设备,并记录和测量性能数据。
测试平台根据待测存储设备不同而不同,但用于DAS测试的关键服务器是一台Intel S2600GZ。这台服务器配置为两个至强E5-2680 v2处理器和128GB美光DRAM。我们使用Avago HBA做大部分直连测试。我们同时也使用不同的Avago和Adaptec的RAID卡做RAID测试。我们在对单个产品验证中会列出任何的硬件变化。为了公平起见,每个验证步骤中测得的所有测试数据都是在同样的服务器平台上获得。
10GbE Layer 3 Supermicro SSE-X3348TR交换机为我们的测试环境提供中央联网。这个交换机拥有48个10GbE Base-T接口和4个额外的40GbE包含QFSP连接的级联端口。QFSP到4x FSP+转换线给我们的实验室提供了充足的连接能力和可靠的功能,使得我们能用统一(cohesive)的方式管理整个测试环境。
SSE-X338TR交换机提供了大量的功能,包括24个连接聚合端口(每个端口最多支持8个成员),可配置的QoS特性,双热插拔PSU和冗余的风扇。这个交换机能够提供最高1284Gbps的非阻塞性能,丰富了我们的测试环境。
结论
通常情况下,你们的里程数都不同。性能通常依赖于部署的环境。我们的测试方法把所有设备放在一个标准的环境中测量性能,由此产生精准和可重复的测试结果。
企业级存储之间的细微差别决定了没有一个方案适用于所有的需求。虽然某些设备性能较低,但权衡功耗或低资产开销,仍然可以接受。关键是要确定每个解决方案的优势和缺点,引导我们的读者做出明智的(informed)采购决定。如果你有任何问题或需求,随时在评论区提出。

















 2819
2819

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









