







eclipse jetty plugin 的热部署,会内存溢出,在MAC下开发还会CPU爆满假死;jetty自带的reload方案每次修改class,都会重启spring application,速度极慢。 JRebel (javarebel)热部署方案,目前支持大部分主流的 Java 容器,配置也相当简单,以下是JReBel 配置步骤:
下载 JRebel 包(破解版)地址
http://download.csdn.net/detail/thly1234/6840501
jrebel配置
jrebel毋须繁琐的配置,把jrebel-5.6.3-crack.zip解压放在磁盘目录即可。(笔者路径为:D:\coding-life\IDE\jrebel\jrebel-5.6.3-crack)该路径后续需要引用到
eclipse 内run配置;
1.找到maven run配置 界面

${project_loc}是eclipse的一个配置参数,即对当前选中的项目的路径执行Maven的jetty:run命令
Skip Test 表示启动项目是跳过Test实例测试
Resolve Workspace artifacts 表示在POM的依赖中,如果有工作区的依赖,则从工作区找到依赖,而不需要从Maven库中寻找或下载依赖包(该配置可支持项目在工作区中的依赖项目类修改的热部署)
Skip Test 表示启动项目是跳过Test实例测试
Resolve Workspace artifacts 表示在POM的依赖中,如果有工作区的依赖,则从工作区找到依赖,而不需要从Maven库中寻找或下载依赖包(该配置可支持项目在工作区中的依赖项目类修改的热部署)
2.jre配置:

简单配置:
-noverify
-javaagent:E:\jrebel-6.1.1-agent-crack\jrebel.jar
-Drebel.spring_plugin=true
-Xms256M -Xmx512M -XX:MaxPermSize=256m
-Drebel.profile_logfile=D:/jrebel-profile.log
-javaagent:E:\jrebel-6.1.1-agent-crack\jrebel.jar
-Drebel.spring_plugin=true
-Xms256M -Xmx512M -XX:MaxPermSize=256m
-Drebel.profile_logfile=D:/jrebel-profile.log
比较全的配置:
-noverify
-javaagent:D:\coding-life\IDE\jrebel\jrebel-5.6.3-crack\jrebel.jar
-Drebel.spring_plugin=true
-Drebel.struts2-plugin=true
-Xms256M -Xmx512M -XX:MaxPermSize=256m
-Drebel.profile_logfile=D:/jrebel-profile.log
-Drebel.dirs=D:\coding-life\workspace\insuranceService\target\classes
-javaagent:D:\coding-life\IDE\jrebel\jrebel-5.6.3-crack\jrebel.jar
-Drebel.spring_plugin=true
-Drebel.struts2-plugin=true
-Xms256M -Xmx512M -XX:MaxPermSize=256m
-Drebel.profile_logfile=D:/jrebel-profile.log
-Drebel.dirs=D:\coding-life\workspace\insuranceService\target\classes
配置说明:
-noverify
-javaagent:D:\coding-life\IDE\jrebel\
-javaagent:D:\coding-life\IDE\jrebel\
jrebel-5.6.3-crack\
jrebel.jar
-Drebel.spring_plugin=true
-Drebel.struts2-plugin=true
-Xms256M -Xmx512M -XX:MaxPermSize=256m
-Drebel.profile_logfile=D:/jrebel-profile.log
-Drebel.dirs=D:\coding-life\workspace\
insuranceService\target\classes
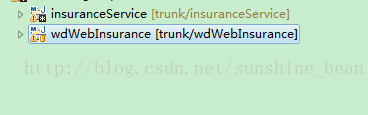
Drebel.dirs 是maven依赖的子项目依赖如图:;
-javaagent: 后面跟上的是jrebel.jar的存放路径, 路径中不允许包含中文、
空格、小数点等特殊符号
-Drebel.spring_plugin=true 表示为启动对spring热部署的支持,
-Drebel.spring_plugin=true 表示为启动对spring热部署的支持,
默认为true
-Drebel.struts2-plugin=true 表示为启动对struts2热部署的支持,
-Drebel.struts2-plugin=true 表示为启动对struts2热部署的支持,
默认为false,如果使用springmvc,该项可部配置
最后的内存配置按各自配置需要配置
最后的内存配置按各自配置需要配置
3.common配置

选择Debug表示在工具栏的Debug按钮下拉中可直接选择到该配置按钮,如果需要在Run中看到按钮,也可勾选Run
完美解决 mavne jetty 热部署















 209
209











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









