







课程简介:
主要内容包括对线性分类及线性回归分析的简单回顾,以及对逻辑回归分析,误差测定与算法三方面的详细讲解,同时对非线性变换的泛化方法进行了剖析.
课程大纲:
2、Nonlinear Transform
3、The Model about Logistic regression
4、Error Measure about Logistic regression
5、Learning Algorithm about Logistic regression
6、Summarize
1、Review
线性模型分类:
1、Linear Classification(线性分类模型,感知器)
2、Linear Regression(线性回归模型)
3、Logistic Regression(符号逻辑回归模型)
4、Nonlinear Transforms(非线性转换)
其中我们已经学过 1 和 2。第四点:非线性转换也接触过。我们曾经说过 Nonlinear Transform 非常重要,但是对于该模型的讨论也就到此结束。下面将详细介绍该模型
2、Nonlinear Transform
定义:
通过转换函数φ 把在空间 X 下无法进行线性分割的数据转换到可以进行线性分割的 Z 空间的过程(理论上任何非线性可分的数据均可转换到更高阶的线性可分的空间)。
即:
X = {x0,x1,x2...xd} ---φ ---> Z = { z0,z1,z2....zk }; 其中 k > d
对于每个 zi 有 zi = φi(X).
对于感知器模型,在X空间下有 dvc = d + 1; 在 Z 空间下有 dvc <= k + 1。这里之所以出现小于号是因为 Z 空间是通过 X 空间变换而来的,zi 是与 X 相关的(zi = φi(X)),在此受限情况下,有可能出现 dvc < k+1 的情况■
代价:
由于 Nonlinear Transform 增加了参数的数量,因此需要更多的数据进行训练。在数据有限的情况下,这将是黑夜...
陷阱:
再利用 Nonlinear Transform 的时候我们要慎防一些存在的陷阱,避免算法失效。先看几个例子:
1、基本可分

在这个空间下,这些数据基本上线性可分,但是除了两个点。因此有 Ein > 0 如果我们坚持要:Ein = 0 ,则需要进行 Nonlinear Transform 。转换结果如下(转换到四阶空间):很明显,这种转换反而弱化了模型的泛化能力了。因此对于转换我们需要慎重。只有在当前空间中无法或难以进行线性分割的情况下进行转换。比如下面的第二个例子。
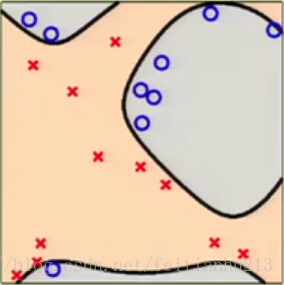
2、基本不可分:
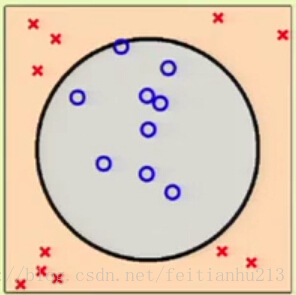
在二维空间下,这些数据无法进行线性分割。因此在该空间下很难利用线性模型进行近似和泛化。
我们假设在该空间下 X = {1,x1,x2}.
在 Z 空间下则有 Z = { 1,x1,x2,x1*x2,x1^2,x2^2 }
然而我们的参数由原来的 3 个变为 6 个,直观感觉我们需要3倍于原来的数据进行训练。但是,为什么我们不用如下的的空间呢:
Z = { 1, x1^2, x2^2 }// 变成 3 维了
或 Z = { 1, x1^2+x2^2 }// 噢,更少了,
甚至于 Z = { x1^2+x2^2 - 0.6 }// 嗯,只剩一维了.....
为什么不可以进行上述的转换?
请永远不要忘记我们的目标不是拟合样本内的数据,而是要找到能够反映样本外部数据的模型。利用上面的“改进”模型将会削弱其泛化能力。因为我们是根据已有的数据而进行模型选择的,因此数据已经影响了模型的选择。此外,如果我们把维数降了下来将会违背关于 dvc 的假设,因为现在 dvc 比在原始空间中的还要小。我们应该把这项工作交由机器学习来进行,通过学习,机器将告诉我们,哪些参数为 0,哪些参数不重要等等(如果我们的机器被设计的足够好)。上述行为被称作:Data Snooping( 数据偷窥)。
切记:在进行模型选择的时候我们不应该被数据影响,最好的方法就是不去看数据,
3、The Model about Logistic regression
在 Linear Classification 下我们的模型是:h(X) = sign(WX), 其中 W、X 是向量,sign 表示取符号。因此 h(X) = +1 or h(X) = -1.
在 Linear Regression 下我们的模型是:h(X) = WX。对于该模型,h(X) 的范围没有被限定,取决于 W 参数的选取。
而在 Logistic regression 模型下,我们选取的模型是:h(X) = θ(s) = e^s/(e^s+1) 其中 s = WX 。
有:θ(-s) = 1-θ(s) 且 0 < θ(s) < 1.函数图像如下所示。为什么选择这个模型而不是其它呢?主要是因为该模型在进行误差分析的时候会体现出很多优点,可以简化我们的分析。
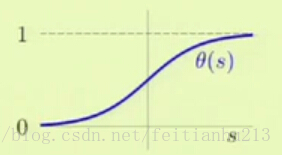
该模型也叫 soft threshold (软阀值),表示的是 uncertainty。有点像 Linear Regression 模型,只是结果被归一化到 0-1 之间。因此我们可以把该模型得到的值解释为一个概率值。趋于 0 表示预测结果接近 -1 类,趋于 1 表示预测结果接近 +1 类。因此该模型提供的信息要比 Linear Classification 要多。他只是告诉我们发生的可能性,而不是一个确却的结果。比如在预测病人心胀病在一年内复发的可能性的时候,我们就不应该 Linear Classification 模型。因为影响一个人心胀病复发的因素很多,我们没办法预测其一年中是否一定复发。
我们输入的数据是二分类,学习得到的结果却是一个概率值,那是因为存在噪声,在噪声的影响下,预测结果就会发生变化。
4、Error Measure about Logistic regression
为了得到一个关于概率的模型,考虑下面的等式:
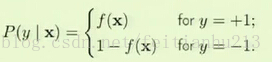
f(X) 表示我们需要学习的目标函数,P(y|X) 表示在 X 下,y 发生的概率。P(y|X) 越大,y 发生的可能性越大。
现在用 h(X) 来近似 f(X) 于是有:
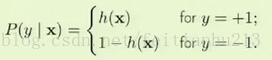
由 h(X) = θ(s) 及 θ(-s) = 1 - θ(s) 我们可以化简上述等式为:P(y|X) = θ( y WX )
对于整个数据集 D(X1,X2,X3...XN) ,事件发生的可能性为:(这里解释一下:事件发生的可能性是指预测的概率接近事件真实的概率的可能性,越大越接近)
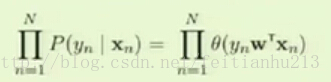
当然我们希望事件发生的可能性越大越好,因此我们需要最大化事件发生的可能性,这也是机器学习的指导方向,即找到一个 W 使得 整个等式最大化。当最大化上述函数的时候其实是在最小化误差:f(x)-h(x)
通过以下的等式变换,可以得到误差度量的方法:
为了最大化:
可以最大化:
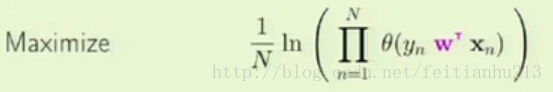
相当于最小化:
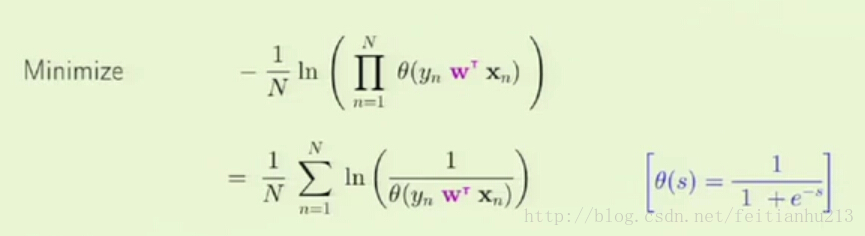
把 θ(s) 代入便可以得到误差度量函数:也叫 cross-entropy error (交叉熵误差度量)
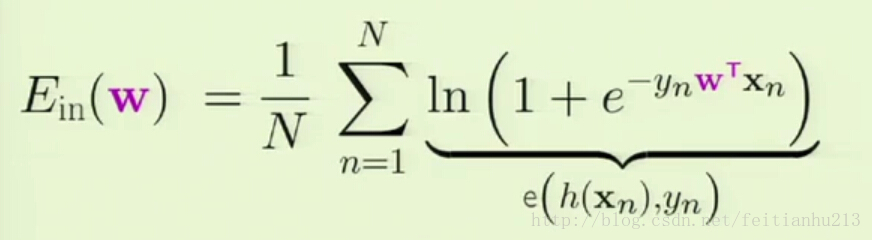
因为我们需要一个简单、简洁的误差度量方法,而在形式上要与原有的一致,因此上述的误差度量方法是合理的。
模型已经提出来了,误差度量方法也已经有了,剩下的就是学习算法了。
5、Learning Algorithm about Logistic regression
为了找到最好的 W,具体思路是先人为的为 W 设定一个初始值W(0),然后通过机器学习,不断迭代,最后找到一个“最好”的 W。在每次迭代的过程中令W(1) 是W(0) 一次迭代的结果。在这里我们利用的方法是梯度下降法:Ein(W(1)) = Ein(W(0)+ηV) 其中 η 表示每次移动的步长,V 是一个向量,表示的是移动的方向。为了方便起见,在这里设定 η 为一个常量,即每次移动步长保持不变,所以我们现在只需确定一个变量 V ,当 V 确定后,便可以进行下一次迭代。推导过程如下:

上面从第一步到第二步是通过泰勒公式转换完成的。第二步到第三步不等式成立是因为 V 是单位向量,所以当方向相反的时候就可以得到最小值,由于我们忽略了第二项,因此有不等式成立。因此可以确定 V 的值。
对于 η 的选取,如果太小的话,每次只移动一小步,可能导致算法无法终止(N 年后...),但是如果 η 过大,有可能会跳过最小值,出现不断地徘徊或往什么别的地方去了。只有当 η 的值适中才能在时间和性能之间取得平衡。这样就需要一定的经验和运气。因此不够理想,如果我们让 η 的值是动态变化的,当梯度变大的时候,η 变大,当梯度减少的时候 η 减少,那样就可以取得很好的平衡了。以上情况请参看如下图:
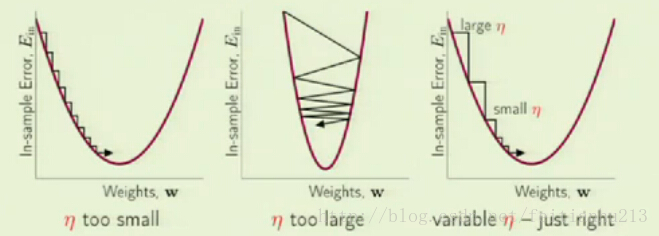
为了方便起见,我们让 η = k * ||▽Ein(W(0))|| ,其中 k 是一个比例常数,
于是 V = k * ▽Ein(W(0)),令 η = k,V = η * ▽Ein(W(0)).( 现在这个 η 表示的是学习率,跟以前的含义不一样了)
接下来我们用算法描述上面的过程
算法描述:

为了终止算法,可以有以下方法:
1、直到找到最好的 W,效果最好,但是无法确定什么时候会终止(有可能无限...)
2、设定一个阀值,当 Ein 小于该阀值的时候终止。
3、限定迭代次数,当 t 大于某个值的时候终止。
此外应该注意的是利用该方法每次只能找到局部最优值而非全局最优值,不过我们可以通过做多次试验,每次指定不同的初始值,然后取所有结果最小的作为输出。
6、总结:
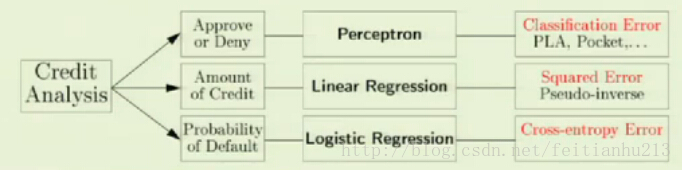
上图总结了三种线性模型在特定应用下的输出及用到的误差度量方法。不同的误差度量方法可能会导致完全不一样的结果,好的误差度量方法是机器学习的助推器。不少学者都在对误差度量方法进行研究,希望能够找到一个对于特定情况下最合适的误差度量方法。至此,线性模型的全部课程已经讲授完毕,接下来是神经网络部分。















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









